Object Detection
- Input: 하나의 RGB 이미지
- Output: 탐지된 물체들 한 세트
- 각 object 예측:
- Category label
- Bounding box
Challenge
- 다중 출력: 이미지 당 오브젝트의 다양한 수를 출력할 필요
- 출력의 다중 형태: 어디(bounding box) 무엇(category label)을 예측 필요
- 큰 이미지: 224x224에서 분류 작업을 함, 800x600 정도의 고해상도에서도 detection 필요
Bounding box
- 보통 axis-aligned
- Oriented box는 덜 흔함.
- Bounding box는 object의 보이는 부분만 cover한다.
Intersection over Unit(IoU)
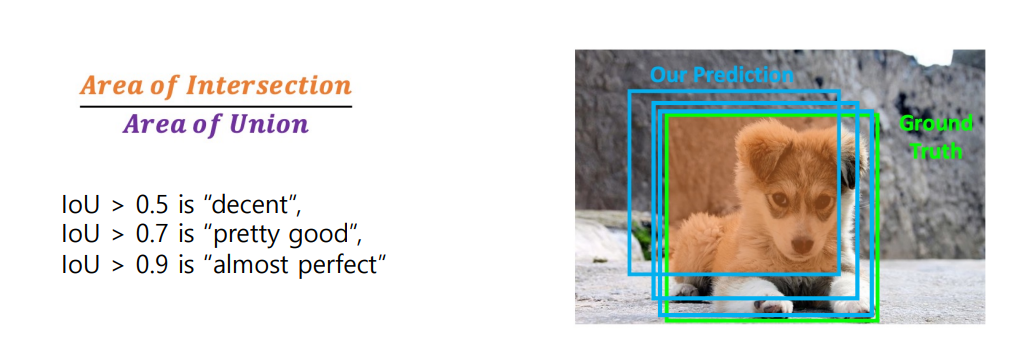
- ground-truth box 예측을 어떻게 비교할 수 있을까
- 하나의 오브젝트를 탐지할 때는 이런데 여러 오브젝트는 어떻게 할까?
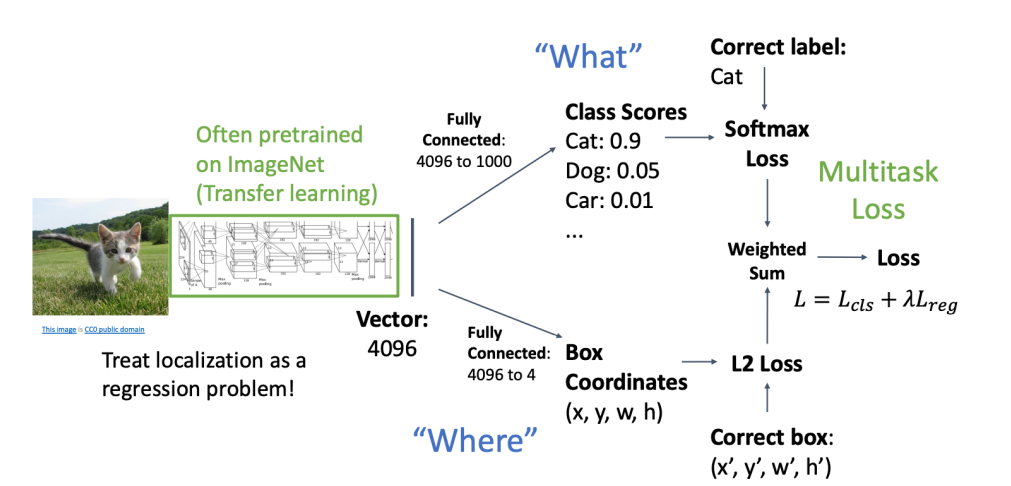

- 이미지의 여러 다른 크롭에 CNN을 적용하면, CNN은 각 크롭을 객체 또는 배경으로 분류합니다
Region Proposals
- 모든 오브젝트를 커버할 수 있을 것 같은 박스의 작은 세트를 찾음
- 상대적으로 빠른 실행
- 선택 탐색은 CPU 위에서 몇 초 내로 2000 지역 제안을 준다.
R-CNN: Region-Based CNN
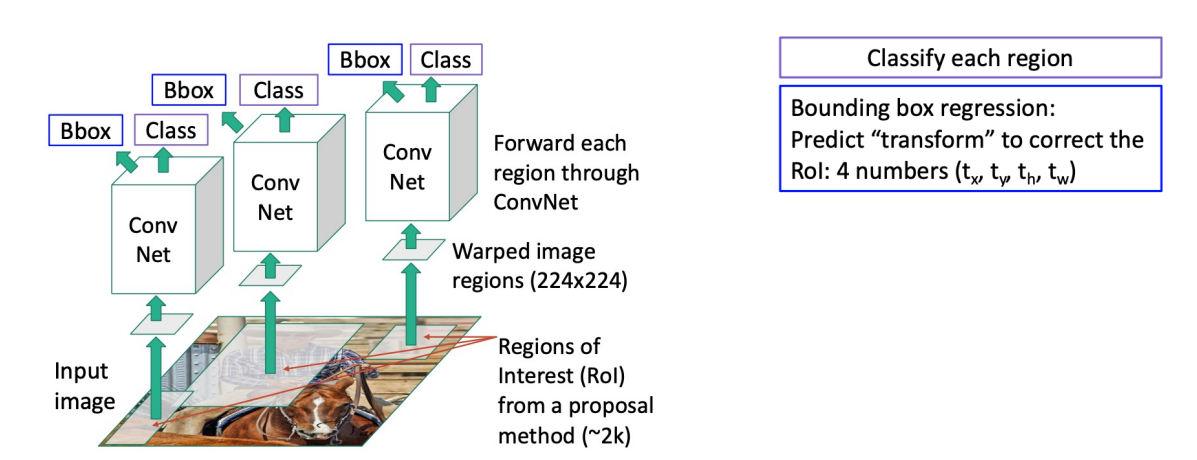
1. 이미지에 있는 데이터와 레이블을 투입한 후 카테고리에 무관하게 물체의 영역을 찾는 Region Proposal.
2. 그리고 proposal 된 영역으로부터 고정된 크기의 Feature Vector를 warping/crop 하여 CNN의 인풋으로 사용한다. 여기서 CNN은 이미 ImageNet을 활용한 사전훈련된 네트워크를 사용한다.
3. CNN을 통해 나온 feature map을 활용하여 선형 지도학습 모델인 SVM(Support Vector Machine)을 통한 분류, 그리고
4. Regressor를 통한 bounding box regression을 진행한다.
Box Regression
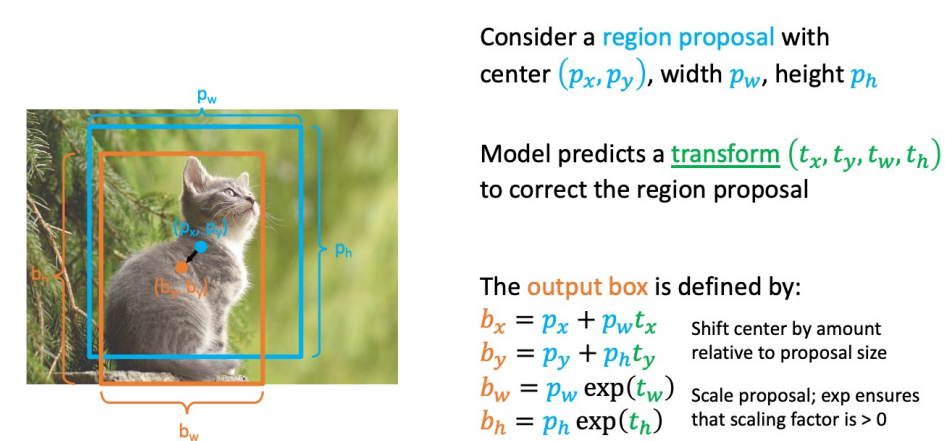
- Scale / Translation 불변:
- proposal과 output 사이의 상대적 차이를 인코딩하는 변환
- CNN은 cropping 후 절대적인 크기나 위치를 볼 수 없기 때문에 중요
학습 과정

- IoU를 기준으로 각 region proposal을 분류함

- 각 positive, negative proposal에서 pixel을 크롭함 -> 224x224로 만든다

- CNN을 통해 각 지역을 실행
- Positive region: 클래스 예측 및 변환
- Negative region: 클래스 예측만 진행
Test
- Run proposal method
- Run CNN on each proposal to get class scores, transforms
- Threshold class scores to get a set of detections
2가지 문제점이 있음
- CNN은 종종 겹치는 박스를 출력함
- threshold를 어떻게 설정할 것인가?
Overlapping Boxes: Non-Max Suppression(NMS)
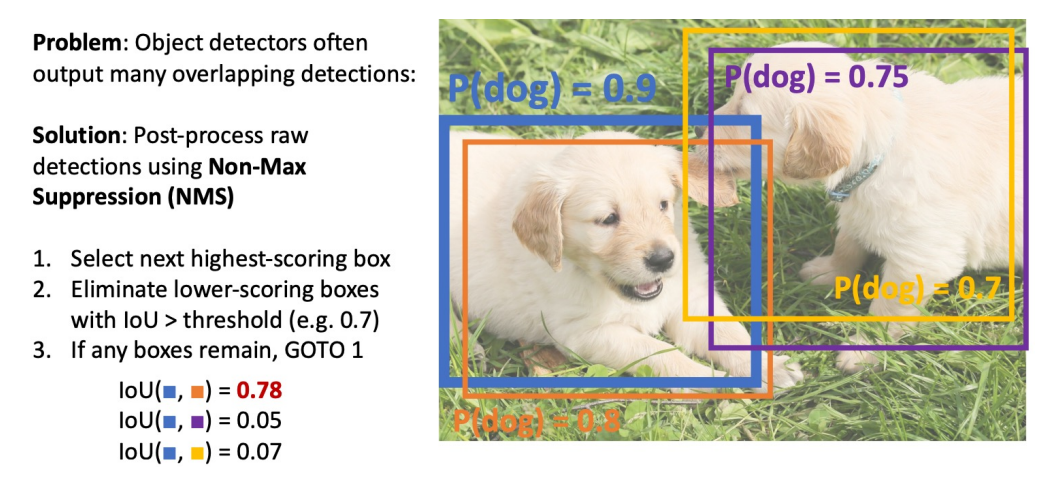
- 문제: 물체 탐지기는 종종 겹치는 박스들을 출력함
- 해결: NMS를 이용해 후처리를 해주자
- 가장 높은 점수의 박스를 골라
- IoU > threshold 인 작은 점수의 상자들을 제거
- 박스가 남아있다면 위 과정 반복
근데, NMS는 overlapping이 높게 되어 있을 때 좋은 box들도 제거할 수 있음 -> 그래서 좋은 방법은 아님
Evaluating Object Detectors: Mean Average Precision(mAP)
1. 모든 테스트 이미지에 대해 object detector를 실행(NMS이용)
2. 각 카테고리에 대해, 평균 정확도(AP)를 계산.(Precision vs Recall)
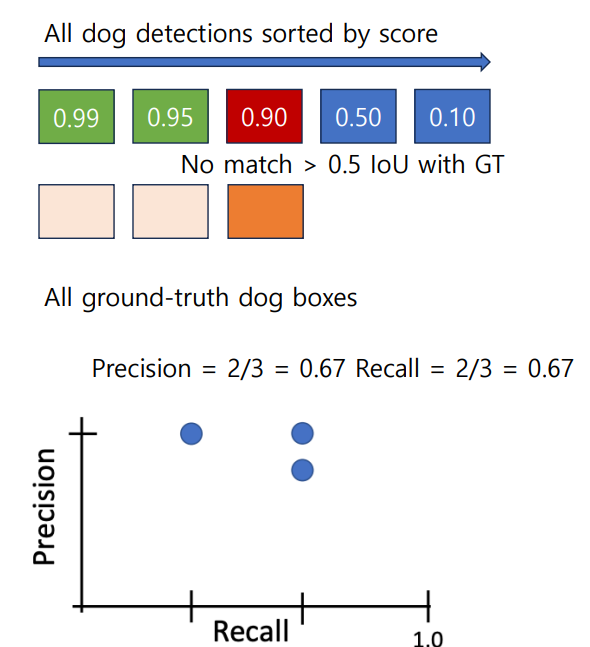
- 높은 점수에서 낮은 점수로 탐지
- 만약 GT box와 IoU > 0.5 이상이라 하면, positive로 마킹하고 GT는 제거
- 해당 GT에 대해 가장 유사한 것을 찾았으니 다른 GT에서 추출하라는 의미인 듯?
- 아니라면 negative로 마킹
- PR Curve에 점 찍음
- 만약 GT box와 IoU > 0.5 이상이라 하면, positive로 마킹하고 GT는 제거
대충 다른 자료들 봐서 보면,
confidence: 대충 알고리즘이 이거 맞다고 자신하는 정도
레벨 내림차순으로 정렬한 순으로 맞는지 아닌지를 판단함
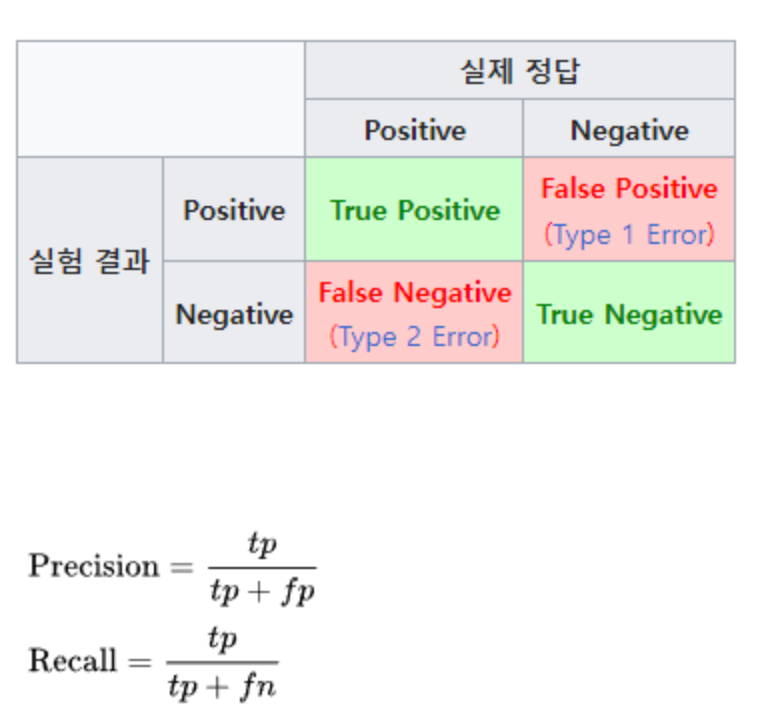
Precision: 정확도, 옳다고 한 것중 진양성인 비율
Recall: 검출율, 실제 옳은 것중 옳다고 판정한 비율
- AP = 1.0을 어떻게 얻을까?
- IoU > 0.5 이상인 GT box 모두 맞추고 false positive가 true positive보다 높지 않으면 됨.
3. mAP = 각 카테고리의 AP의 평균
4. "COCO mAP": mAP@ 각 IoU threshold의 임계치 계산하고 평균 계산

Fast R-CNN
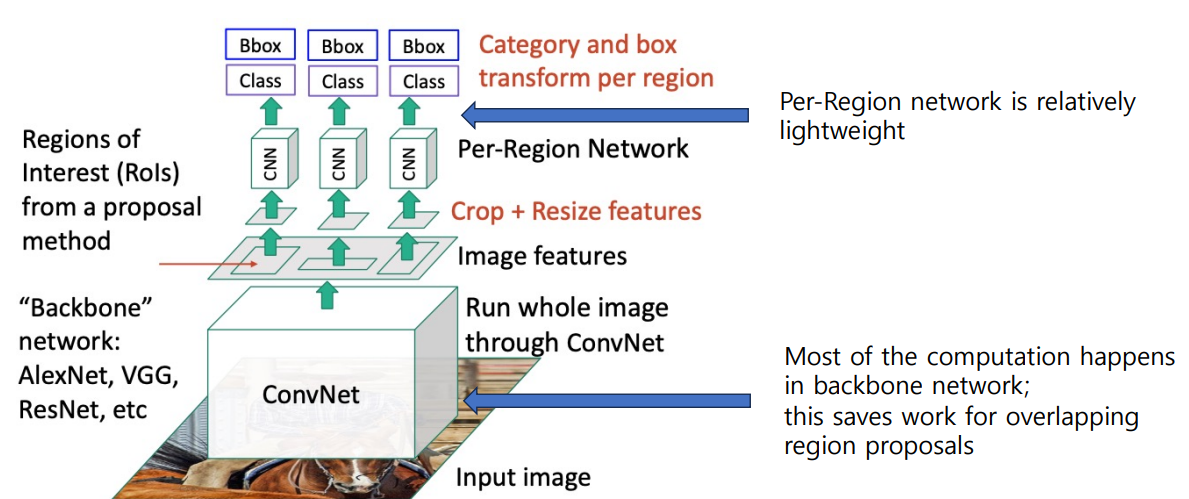
- AlexNet을 detection으로 사용할 때 5개의 conv 계층은 backbone으로 사용되고 2개의 FC 레이어는 per region network에서 사용됨
- ResNet에서는 마지막 stage가 per-region network로 사용됨, 나머지가 backbone으로 사용됨
- 근데 위 사진에 따르면 특징을 crop한다는데 어떻게 할까?
Cropping Features: RoI Pool
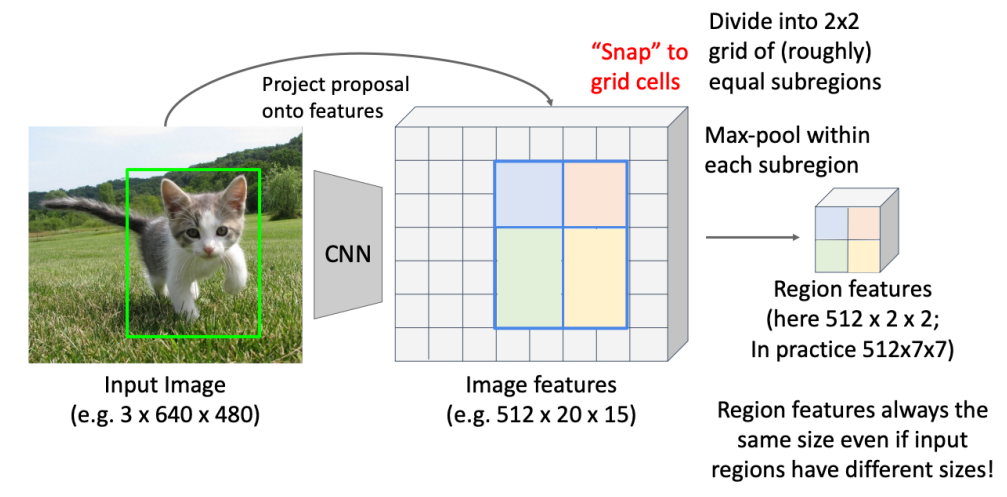
- 고정된 크기의 특징을 담은 박스를 원함.
- Input image를 CNN에 통과시켜 feature map을 얻어냄
- 물체가 있는 박스를 grid 상에 위치 시켜 박스를 snap 하여 grid의 격자에 맞춰 위치시킨다.
- 4등분하여 2x2의 새로운 region이 나온다
Fast R-CNN vs "Slow" R-CNN
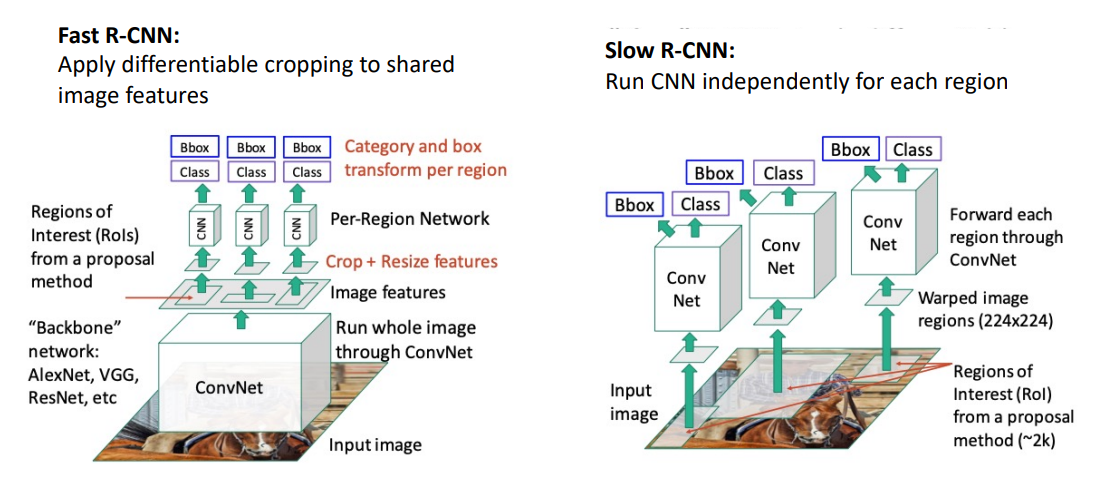
- Fast R-CNN은 input 이미지에서 feature를 뽑아낸 feature image를 한번에 CNN을 통과시키는데(ROI pooling) 이후 feature map을 얻고 이 region proposal들을 하나씩 CNN에 넣어 classification 하면 됨. (이미 CNN을 한번씩 겪었기 때문에 연산이 빠름)
- Slow R-CNN의 경우에는 proposal마다 CNN을 실행
이 방식이 빠른 이유는 대부분의 계산이 아래 Backbone network에서 일어나는데, 이렇게 하면 overlapping region proposals에 대해 반복적으로 계산할 필요없이 한번 계산하면 끝나기 때문이다.
그리고 위의 CNN인 per-region entwork는 상대적으로 매우 가볍고 작다.

- 문제점: region proposal에 의해 런타임이 지배됨
- Recall: CPU 위에서 heuristic 선택 탐색에 의해 Region proposal이 계산됨. - CNN 대신.
Faster R-CNN
Learnable Region Proposals
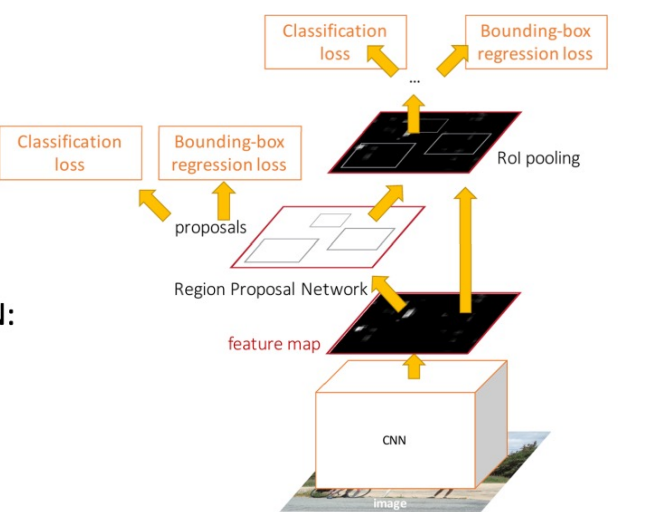
- feature로부터 proposal을 예측하기 위해 Region Proposal Network(RPN)을 삽입
- 다른 건 Fast R-CNN과 동일하게: 각 proposal의 특징 crop, 분류함
Region Proposal Network(RPN)

- 입력 이미지에 정렬된 특징을 얻기 위해 Backbone CNN을 실행
- 각 특징은 인풋에서 점에 상응함
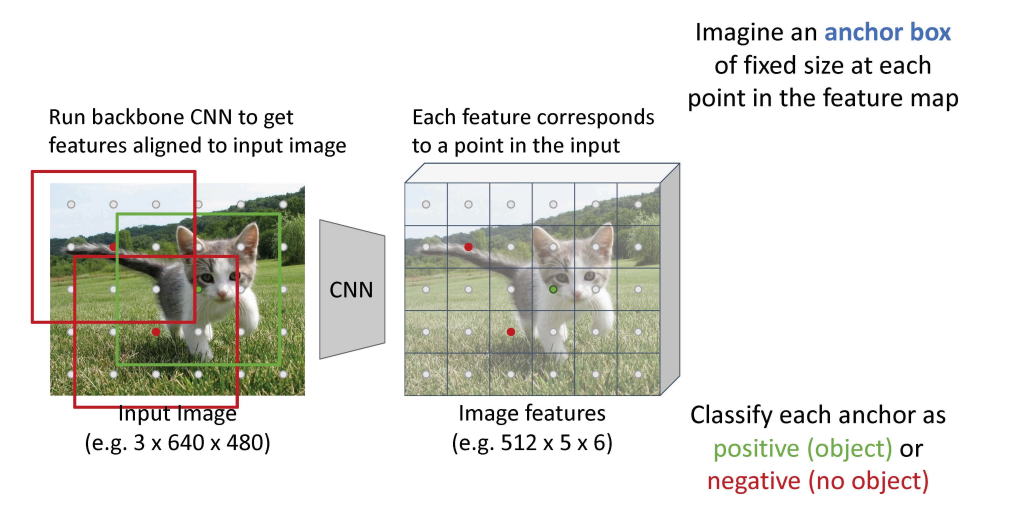
- feature map에서 각 점에 고정된 크기의 anchor box를 상상함.
- 각 앵커를 분류함 positive(object) 혹은 negative(no object)로
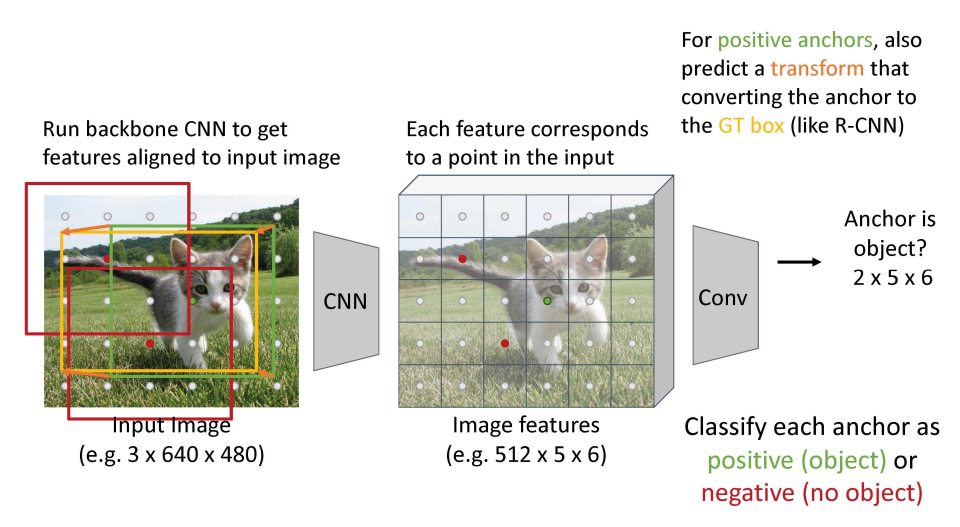
- positive 앵커에서, 또한 앵커가 GT box로 변환하는 transform을 예측함
- anchor 박스를 이용해 물체 판단은
- 가장 높은 IoU를 가지는 anchor
- IoU > 0.7을 만족하는 anchor
로 positive labeling 처리할 수 있음
- positive box에 대해서는 regression을 통해 더 정확한 위치를 찾을 수 있게 함
- Negative anchor는 IoU가 0.3보다 작으면 판단한다.
- 어떠한 변환도 하지 않음
- 0.3 ~ 0.7 사이는 Neutral Anchor로 학습 동안 무시된다.
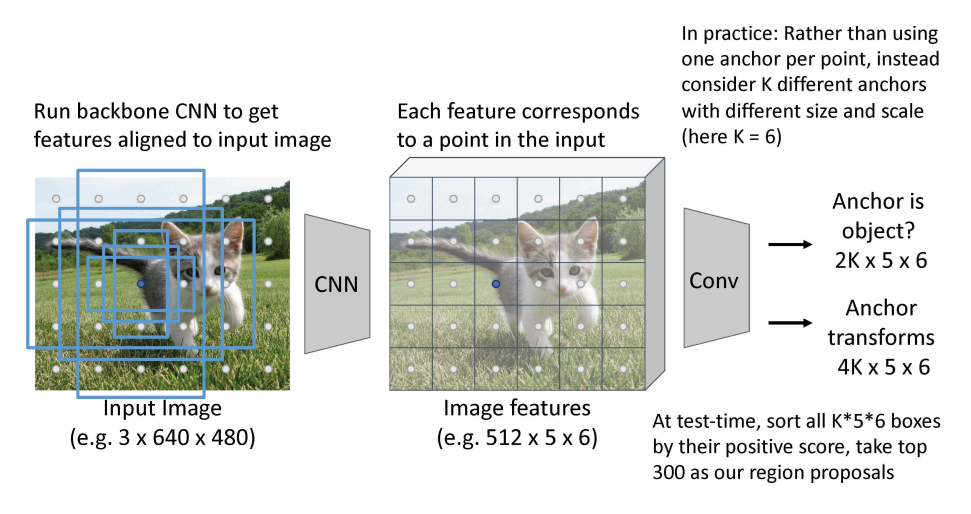
- 점 당 하나의 앵커를 사용하는 대신, 다른 사이즈와 규모를 가진 앵커들을 K라고 함
- 이 때 2k 개의 classfication 출력과 4k 개의 박스의 위치를 조정하는 regression 출력을 얻는다
- 테스트 할 때 k56 박스들이을 얻음(TOP 300)
4 Losses
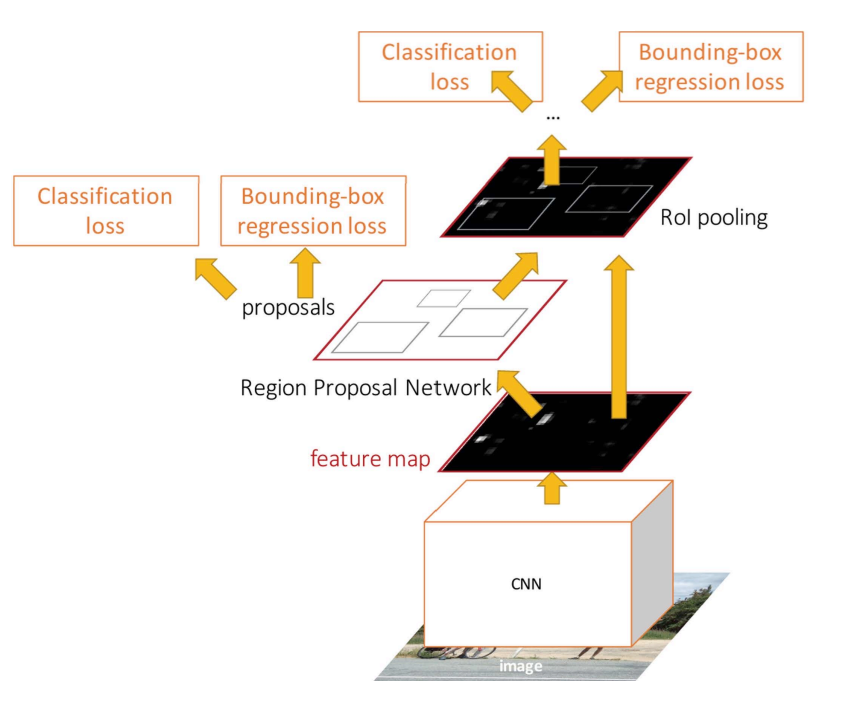
- 아래에 대해 학습을 진행함
- RPN classification Loss : anchor box가 object를 포함하는지 안하는지
- RPN regression Loss : anchor box를 proposal box로 regress시키는 transforms를 학습
- Object classification Loss : background / objects 의 class를 분류
- Object regression Loss : proposal box를 최종 object box로 regress시키는 transforms를 학습
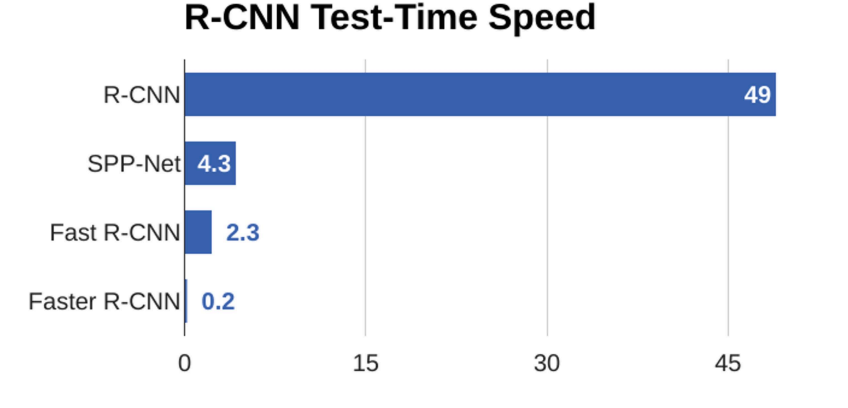
- 속도 차이 심하다
- 최신기술이 좋긴 하다.
요약
- Transfer learning은 새로운 작업에 대해 이미 학습한 네트워크 재사용 가능하게 해준다
- Object Detection은 bounding box를 가지고 object를 위치화하는 작업이다
- Intersection over Union(IoU)는 bounding box 사이의 차이를 측량한 것
- 테스트 시간에, non-max suppression(NMS)를 이용하여 겹치는 탐지를 제거한다
- mean average precision(mAP)를 이용하야 물체 탐지기를 평가한다
R-CNN: 각 region에 독립적으로 CNN 실행
Fast R-CNN: 공유된 이미지 특징들에 다른 cropping을 적용
Faster R-CNN: CNN을 가지고 proposal 계산
Ref.
https://younghk.github.io/machine-learning/2019-11-19---cs231n-lec12-detection-and-segmentation/
