복습문제
# matplotlib 말고 그래프를 그릴 때 사용하는 패키지는?
[답변]
seaborn
# 데이터의 summary 를 돌려주는 함수는?
[답변]
descibe()
# 빈도수 그래프를 보기 위한 함수는?
[답변]
countplot
# value_counts는 한개의 칼럼에만 적용된다 (o x)
[답변]
x
[출제자 답변]
o
데이터 프레임과 시리즈 형태에 모두 적용할 수 있는 count()와 다르게
value_counts()는 데이터 프레임에 적용할 수 없다.
보통 시리즈(한줄)에 대해서만 하며, 값을 세고 싶은 특정 컬럼을 설정하여 사용해야한다.
# 아래 예시에서 immutable 과 mutable 타입으로 각각 분류하시오
(dic, int, float, list, str, tuple)
[답변]
immutable : int, float, str, tuple
mutable : list, dict
[추가 설명]
수정이 불가능한 객체를 immutable 객체
수정이 가능한 객체를 mutable 객체라고 부른다.
# pandas를 이용하여 아래의 데이터 프레임을 만들어 보세요
# v1 v2
# 0 1 5
# 1 2 3
# 2 1 2
[답변]
import pandas as pd
pd.DataFrame({'v1': [1, 2, 1], 'v2': [5, 3, 2]})
pd.DataFrame({'v1':(1,2,1),'v2':(5,3,2)})
# 위에서 만들어진 데이터 프레임에 칼럼명을 대문자로 바꿔주세요
[답변]
# 만들어진 값을 일단 어딘가에 저장한 후
a = pd.DataFrame({'v1':(1,2,1),'v2':(5,3,2)})
# rename 사용
a.rename({'v1' : 'V1', 'v2' : 'V2'},axis=1)
# 종강일은 2023년 2월 24일이다.
# datatime lib를 사용하여 종강일까지 남은 일수를 구해보세요
[답변]
import datetime
end = datetime.datetime(2023, 2, 24)
today = datetime.datetime.now()
end - today
# datetime.timedelta(days=155, seconds=52888, microseconds=349137)
# 155일 남았다
# 아래와 같은 데이터 프레임을 만들어보세요
# a b
# 0 1 4
# 1 2 5
# 2 3 6
[답변]
a = pd.DataFrame({'a' : [1, 2, 3], 'b' : [4, 5, 6]})
pd.DataFrame(np.array([[1, 4], [2, 5], [3, 6]]), columns=['a', 'b'])
pd.DataFrame([[1, 4], [2, 5], [3, 6]], columns=['a', 'b'])
# 위 데이터 프레임에서 컬럼명을 대문자로 바꿔주세요
[답변]
df = pd.DataFrame(np.array([[1, 4], [2, 5], [3, 6]]), columns=['a', 'b'])
df.rename({'a':'A', 'b':'B'}, axis=1)
# 위 데이터 프레임에서 두 열의 합을 구해 새로운 열을 만들어주세요
[답변]
df['hap'] = df['A'] + df['B']
# Interable 객체에 대하여 틀린 것을 고르시오
# 1 )순회가능한 반복되는 객체이다
# 2) int형 객체를 포함한다
# 3) for 반복문에 넣어 사용 가능하다
# 4) tuple형 객체를 포함한다
[답변]
2
# 동적 타이핑의 한 종류로 객체가 어떠한 타입에 걸맞는 변수와 메소드를 지닌다면
# 이 객체를 해당 타입에 속하는 것으로 간주하는 것을 무엇이라 하는가
[답변]
덕 타이핑
# -별로 색을 넣으려 할때 color 안에 무엇이 들어가야 하는가
# sns.countplot(data = df, x = , color = )
[답변]
hue
# 데이터 프레임의 구조를 알아보기 위해 사용하는 함수는?
[답변]
info()
# excel_exam.xlsx 파일을 df 로 읽어라
[답변]
df = pd.read_excel("excel_exam.xlsx")
# 읽어온 파일에서 수학, 영어, 과학의 평균을 구한후, 평균 칼럼을 만들어보세요
[답변]
df['평균'] = (df['math'] + df['english'] + df['science']) / 3
# 평균 칼럼의 그래프를 그려보세요
[답변]
df = pd.read_excel("excel_exam.xlsx")
df['평균'] = (df['math'] + df['english'] + df['science']) / 3
df['평균'].plot(kind = 'hist')
# 합격 여부라는 열을 만들어 평균 칼럼의 값이
# 60이 넘는 학생에게는 합격, 그 외에는 불합격을 부여하시오
[답변]
df['합격여부'] = np.where(df['평균']>60, '합격', '불합격')
# 만들어진 합격여부 열을 countplot을 사용해 그래프로 그려주세요
[답변]
import seaborn as sns
sns.countplot(data= df, x='합격여부')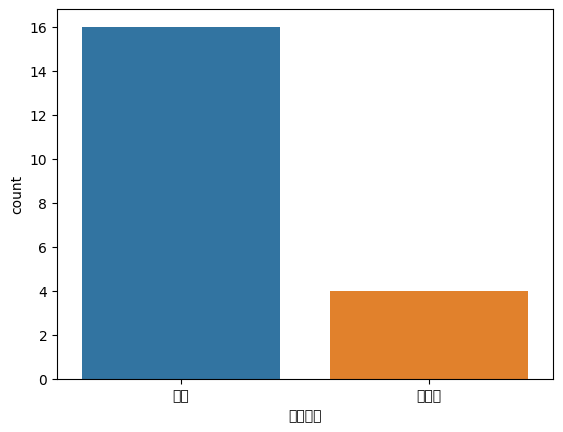
유니버셜 함수
배열의 각 원소를 빠르게 처리하는 함수를 유니버셜 함수라 부른다. ufunc라고 불리기도 하는데, ndarray 안에 있는 데이터 원소별로 연산을 수행한다.
단항 유니버셜 함수는 간단한 변형을 전체 원소에 적용할 수 있다.
이항 유니버셜 함수는 2개의 인자를 취해 단일 배열을 반환한다.
# 단항 유니버셜 함수 예시
arr = np.arange(10)
# 간단한 변형을 전체 원소에 적용
np.sqrt(arr)
# 이항 유니버션 함수 예시
x = np.random.randn(8)
y = np.random.randn(8)
np.add(x, y)단항 유니버설 함수
| 함수 | 설명 |
|---|---|
| abs, fabs | 각 원소(정수, 부동소수점수, 복소수)의 절댓값을 구한다. 복소수가 아닌 경우에는 빠른 연산을 위해서 fabs를 사용한다. |
| sqrt | 각 원소의 제곱근을 계산한다. arr **0.5 와 동일 |
| square | 각 원소에서 제곱을 계산한다. arr **2와 동일 |
| exp | 각 원소에서 지수를 계산한다 |
| log, log10, log2, log1p | 각각 자연로그, 로그10, 로그2, 로그(1+x) |
| sign | 각 원소의 부호를 계산한다 |
| ceil | 각 원소의 소수자리를 올린다. 각 원소의 값보다 같거나 큰 정수 중 가장 작은 정수를 반환한다. |
| floor | 각 원소의 소수자리를 내린다. 각 원소의 값보다 작거나 같은 정수 중 가장 작은 수를 반환한다. |
| rint | 각 원소의 소수자리를 반올림한다. dtype은 유지된다. |
| modf | 각 원소의 몫과 나머지를 각각의 배열로 반환한다 |
| isnan | 각 원소가 숫자가 아닌지를 나타내는 불리언 배열을 반환 |
| isfinite, isinf | 각각 배열의 각 원소가 유한한지 무한한지 나타내는 불리언 배열을 반환한다. |
| cos, cosh, sin, sinh, tan, tanh | 일반 삼각함수와 쌍곡삼각함수 |
| arccos, arccosh, arcsin, arcsinh, arctan, arctanh | 역삼각함수 |
| logical_not | 각 원소의 논리 부정(not)값을 계산한다 ~arr과 동일 |
이항 유니버설 함수
| add | 두 배열에서 같은 위치의 원소끼리 더한다 |
|---|---|
| subtract | 첫 번째 배열의 원소에서 두 번째 배열의 원소를 뺀다 |
| multiply | 배열의 원소끼리 곱한다 |
| divide, floor_divide | 첫 번째 배열의 원소를 두 번째 배열의 원소로 나눈다 floor_divide는 몫만 취한다. |
| power | 첫 번째 배열의 원소를 두 번째 배열의 원소만큼 제곱한다 |
| maximum, fmax | 각 배열의 두 원소 중 큰 값을 반환한다. fmax는 NaN을 무시한다 |
| minimum, fmin | 각 배열의 두 원소 중 작은 값을 반환한다. fmin은 NaN을 무시한다 |
| mod | 첫 번째 배열의 원소를 두 번째 배열의 원소로 나눈 나머지를 구한다. |
| copysign | 첫번째 배열의 원소와 기호를 두번째 배열의 원소 기호로 바꾼다 |
데이터 전처리
조건에 맞는 데이터 추출하기. 예시를 보자
exam = pd.read_excel("excel_exam.xlsx")
# pandas의 query()를 이용해 조건 하나 걸기
# 수학점수가 50 이상인 경우 출력
exam.query('math >= 50')
# 조건 두개 걸기
# 수학점수가 50이상 영어점수는 90 초과
exam.query('math >= 50 and english > 90')그런데 처리를 하다보면 나는 class==1 의 조건을 걸고 싶은데 python keyword not valid identifier in numexpr query pandas 오류가 뜨는 것을 확인할 수 있다. 이는 class가 예약어이기 때문임으로 이름을 변경하여 주면 무리 없이 사용 가능하다.
# 1반이고 수학이 50점 이상
exam = exam.rename({'class':'nclass'}, axis=1)
exam.query('nclass == 1 and math >= 50')| 기호 혹은 in[]을 이용하여 여러 조건을 나열할 수도 있다.
# ex) 1, 3, 5 반에 해당하는 값들을 추출하고 싶다
exam.query('nclass == 1 | nclass == 3 | nclass == 5')
exam.query('nclass in [1, 3, 5]')함수를 조합해서 검색하는 것도 가능하다
exam.query('nclass == 1')['english']문자 검색도 가능하다. 단 query()에 전체 조건을 감싸는 따옴표와 문자를 감싸는 따옴표를 서로 다른 모양 으로 입력해야 합니다.
# 예시로 사용할 데이터 프레임 생성
df = pd.DataFrame({'sex' : ['F', 'M', 'F', 'M'],
'country' : ['Korea', 'China', 'Japan', 'USA']})
# 검색
df.query('sex == "F" & country == "Korea"')
df.query("sex == 'F' and country == 'Korea'")변수 제거하기
df.drop()을 이용하면 됩니다. 제거할 변수명을 columns 에 입력하면 입력한 변수만 제외하고 모든 변수를 추출한다.
exam.drop(columns='math')
# 여러 변수 제거시 `[]` 안에 제거할 변수명을 나열하면 된다.
exam.drop(columns=['id', 'nclass'])정렬하기
df.sort_values()에 정렬 기준으로 삼을 변수를 입력하면 기준에 따라 오름차순으로 정렬된다.
# 수학 점수가 낮을 사람부터 높은 사람 순으로 출력
exam.sort_values('math')내림차순으로 정렬하려면 ascending = False 로 기능을 꺼주면된다.
exam.sort_values('math', ascending = False)정렬기준으로 삼을 변수를 여러 개 지정하려면 [] 안에 변수명을 나열하면 된다. 이때, 왼쪽에서 오른쪽에 쓰인 순으로 정렬한다.
# nclass를 기준으로 오름차순 정렬한 다음
# 정렬된 기준(각 반)에서 수학점수를 기준으로 오름차순 정렬
exam.sort_values(['nclass', 'math'])
# 변수별로 정렬 순서를 다르게 지정하려면
# `ascending`도 []를 사용해 묶어주면 된다
exam.sort_values(['nclass', 'math'], ascending=[True, False])assign 으로 새로운 칼럼 만들기
새 변수명 = 변수를 만드는 공식 을 입력하면 되는데, 이때 새로 만들 변수명에는 따옴표를 입력하지 않는다.
# 따옴표 하지 않는 total
exam.assign(total = exam['math']+exam['english']+exam['science'])집단별로 요약하기
'집단별 평균' 과 같이 각 집단을 요약한 값을 구할 때는.groupby()와 .agg()를 사용한다.
# 수학 평균 구하기
# 행 이름 = (계산할 컬럼, '어떤 값을 얻고 싶은가')
# 수학 점수의 평균을 구하고 싶다
exam.agg(mean_1 = ('math', 'mean'))
# 각 집단별로 묶어서 각각에 대하여 최솟값
exam.groupby('nclass').min()
# id math english science
# nclass
# 1 1 30 86 50
# 2 5 25 78 25
# 3 9 20 65 15
# 4 13 46 56 12
# 5 17 65 68 58
# 그런데 위를 보면 nclass가 인덱스가 되어있다.
# goupby()는 안에 들어간 기본값을 인덱스로 사용하며
# 이게 싫다면 as_index=False 옵션을 달아주면 된다.
# nclass id math english science
# 0 1 1 30 86 50
# 1 2 5 25 78 25
# 2 3 9 20 65 15
# 3 4 13 46 56 12
# 4 5 17 65 68 58
# 만약 구해진 값을 모두 보지 않고 특정 열만 보고싶다면
exam.groupby('nclass').min()[['math', 'science']]
# 혹은 전체값은 필요없고 몇 열만 필요한 경우라면
exam[['nclass', 'math', 'science']].groupby('nclass').min()집단 별 요약 통계량을 구해보자
df.groupby()에 변수를 지정하면 변수의 범주별로 데이터를 분리한다. 여기에 agg()를 적용하면 집단별 요약 통계량을 구할 수 있다.
# \ = 이어주는 기호. 이래 위는 한줄이다라는 표시
# nclass 별로 먼저 분리하고
# math 평균을 구했다.
exam.groupby('nclass') \
.agg(mean_math = ('math', 'mean'))
# 만약 여러 통계랑을 한번에 구하고 싶다면
exam.groupby('nclass') \
.agg(mean_math = ('math', 'mean'),
sum_math = ('math', 'sum'))다음은 agg() 에 자주 사용하는 요약 통계량 함수이다
| 함수() | 통계량 |
|---|---|
| mean() | 평균 |
| std() | 표준편차 |
| sum() | 합계 |
| median() | 중앙값 |
| min() | 최소값 |
| max() | 최대값 |
| count() | 빈도(개수) |
집단별로 다시 나누기
groupby()에 여러 변수를 지정하면 집단을 나눈 다음 다시 하위 집단으로 또 나눌수 있다. 예를 들어 성적데이터를 반별로 나눈다음 / 다시 성별로 나누어 평균 점수를 구할 수 있다는 말이다.
# drv 와 class로 그룹을 짓고, 각 그룹 별 cty의 min()
mpg.groupby(['drv', 'class']).min()[['cty']] 데이터프레임 합치기
pd.merge()
# 데이터 만들기
test1 = pd.DataFrame({'id' : [1, 2, 3, 4, 5],
'midterm' : [60, 80, 70, 90, 95]})
test2 = pd.DataFrame({'id' : [1, 2, 3, 4, 5],
'final' : [70, 83, 65, 95, 80]})데이터를 가로로 합칠때는 pd.merge()를 이용합니다. pd.merge(열1, 열2) 이 기본 모양이다. 여기서 만약 열1은 모두 살리고 싶다면 how = "left" 를 하고 공통되는 부분이 많다면 on = 데이터를 합칠 때 기준으로 삼을 변수명 을 표기해주는 게 좋다.
# test
total = pd.merge(test1, test2, how = 'left', on = 'id')
print(total)
# id midterm final
# 0 1 60 70
# 1 2 80 83
# 2 3 70 65
# 3 4 90 95
# 4 5 95 80다른 데이터를 활용해 변수 추가하기도 가능하다
teacher = pd.DataFrame({'nclass' : [1, 2, 3, 4, 5],
'teacher' : ['kim', 'lee', 'park', 'choi', 'jung']})
exam_new = pd.merge(exam, teacher)pd.concat()
세로로 합치는 방법도 있다. pd.concat()에 결합할 데이터 프레임명을 [] 를 이용해 나열하면 된다.
pd.concat([test1, test2])
# id midterm final
# 0 0 60.0 NaN
# 1 1 80.0 NaN
# 2 2 70.0 NaN
# 3 3 90.0 NaN
# 4 6 95.0 NaN
# 0 1 NaN 70.0
# 1 2 NaN 83.0
# 2 3 NaN 65.0
# 3 5 NaN 95.0
# 4 7 NaN 80.0결과를 보면 알겠지만 열2가 열1의 아래에 그냥 붙는 것을 알 수 있다. 만약 굳이 axis=1 을 추가하여 옆에 붙인다고 해도
print(pd.concat([test1, test2], axis=1))
# id midterm id final
# 0 0 60 1 70
# 1 1 80 2 83
# 2 2 70 3 65
# 3 3 90 5 95
# 4 6 95 7 80이런식으로.. 공통되는 부분(id) 마저 그대로 살아 옆에 그냥 붙어 있는 것을 확인 할 수 있다. join 옵션도 있는데.
print(pd.concat([test1, test2], join = 'inner'))
# id
# 0 0
# 1 1
# 2 2
# 3 3
# 4 6
# 0 1
# 1 2
# 2 3
# 3 5
# 4 7이런식으로 사용할 수 있다.
# 문제를 하나 풀어보자
# test2의 final 컬럼명을 midterm 으로 바꾸고 test3라고 명명해라
test3 = test2.rename({'final':'midterm'}, axis=1)
# 만들어진 test3와 test1을 붙여라. 기준열은 test1이다
group_test = pd.concat([test1, test3])
# id 별로 group_test의 평균값을 구해라
group_test.groupby('id')['midterm'].mean()
group_test.groupby('id').agg(mean_t = ('midterm', 'mean'))
group_test.groupby('id').agg(np.mean)결측치 정제하기
# 먼저 사용해줄 결측치를 만들자
exam.iloc[[0, 1, 2], [2, 3, 4]] = np.nan결측치 확인을 위해서는 pd.isna() 를 사용할 수 있다. 결측치는 True, 결측치가 아닌 값은 False로 표시해 데이터를 출력한다.
df = exam.copy()
pd.isna(df).sum()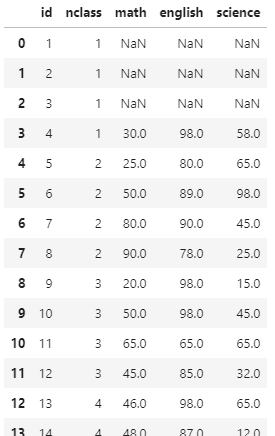
결측치 빈도를 확인하고 싶으면 .sum()을 사용해주면 된다.
pd.isna(df).sum()
# id 0
# nclass 0
# math 3
# english 3
# science 3
# dtype: int64결측치를 제거하기 위해서는 .dropna(subset = ) 을 사용해 줄 수 있다.
# 만약 수학 열에 있는 결측치만 제거하고 싶다면
df.dropna(subset='math')
# 모든 변수에서 결측치가 없는 행만 추출한다
df.dropna()+) 각각의 칼럼에 대해서 평균값 구해보기
# apply all columns
df.apply(np.mean)
# id 10.500000
# nclass 3.000000
# math 58.470588
# english 83.352941
# science 58.882353
# dtype: float64결측치 대체하기
결측치가 너무 많거나 데이터가 작을 때 결측치가 있는 값들을 제거 시 너무 많은 데이터가 손실되어 분석 결과가 왜곡되는 문제가 생길 수 있다.
평균으로 결측치를 대체하려면 fillna() 를 이용할 수 있다. 괄호 안에 대체할 값을 입력하면 된다.
# 수학열을 수학열의 평균으로 채우겠다
m = df['math'].mean()
df['math'] = df['math'].fillna(m)
# 과학열을 과학열의 평균값으로 채우겠다면
df['science'].fillna(df['science'].mean(), inplace=True)
# 만약 english NaN 이 있다면 55로 대체하겠다
df['english'] = df['english'].fillna(55)
# bfill로 할경우 결측값을 바로 아래 값과 동일하게 변경하겠다
df['english'].fillna(method = 'bfill', inplace=True)fillan는 DataFrame에서 결측값을 원하는 값으로 변경하는 메서드이다.
# 기본 사용법
df.fillna(value= , method=, axis= , inplace= , limit=, downcast=)
value : 결측값을 대체할 값. dict 형태로도 가능하다
method : 결측값을 변경할 방식이다
- bfill : 결측값을 바로 아래 값과 동일하게 변경
- ffill : 결측값을 바로 위 값과 동일하게 변경
axis : (0:index/1:columns) fillna 메서드를 적용할 레이블
inplace : 원본을 변경할지 여부
limit : 결측값을 변경할 횟수. 위에서부터 limit로 지정된 갯수만큼 변경한다.
지정값이 없으면 None이 기본으로 전체 다 변경된다.
downcast : 다운캐스트를 할것인지 묻습니다.
ex) downcast='infer'일 경우 float64를 int64로 변경한다. 이상치 정제
이상치는 정상 범위에서 크게 벗어난 값을 뜻한다. 오류는 아니지만 분석 결과가 왜곡 될 수 있으므로 분석에 앞서 이상치를 제거하는 것이 좋다.
import pandas as pd
# 예제로 사용할 데이터
# 1,2 중 한 번호로 이루어져있어야하는 sex 변수
# 1~5 중 한 번호로 이루어져있어야하는 num 변수
df = pd.DataFrame({'sex' : [1, 2, 1, 3, 2, 1],
'num' : [5, 4, 3, 4, 2, 6]})df.value_counts()를 이용해 빈도표를 출력해보면 이상치를 확인할 수 있다.
df['sex'].value_counts().sort_index()
# 1 3
# 2 2
# 3 1
# Name: sex, dtype: int64
df['num'].value_counts().sort_index()
# 2 1
# 3 1
# 4 2
# 5 1
# 6 1
# Name: num, dtype: int64보면 예상하지 못한 값이 끼어있는 것을 확인 할 수 있다. 이 이상치를 결측치로 처리하려면 np.where 을 이용할 수 있다. 이상치일 경우 NaN 처리를 하는 것이다.
import numpy as np
df['sex'] = np.where(df['sex'] == 3, np.nan, df['sex'])
df['num'] = np.where((1 <= df['num'])&(df['num'] <= 5), np.nan, df['num'])
# 빈도수 출력해보기
df['sex'].value_counts().sort_index()
# 1.0 3
# 2.0 2
# Name: sex, dtype: int64
df['num'].value_counts().sort_index()
# 2.0 1
# 3.0 1
# 4.0 2
# 5.0 1
# Name: num, dtype: int64np.where 사용시 주의할 점
반환하는 값 중 문자가 있으면 np.nan 을 이용하더라도 결측치 NaN이 아니라 nan 이 반환된다.
df = pd.DataFrame({'x1' : [1, 2, 1, 1]})
df['x2'] = np.where(df['x1'] == 1, 'a', np.nan)
print(df.isna())
# x1 x2
# 0 False False
# 1 False False
# 2 False False
# 3 False False문자 nan 이 된 값을 .replace를 이용해 NaN으로 변경해 주어야 정상적으로 결측치 처리가 된다
df['x2'] = df['x2'].replace('nan', np.nan)
print(df.isna())
# x1 x2
# 0 False False
# 1 False True
# 2 False False
# 3 False Falsenp.where() 여러조건 넣기
& 혹은 | 연산자를 사용하여 다중 조건 구현. 각 조건을 괄호 쌍으로 묶고 그 사이에 & 연산자를 사용하는 것이다.
arr = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
arr[np.where((arr>3) & (arr<8))]사소하지만 재밌는 단축어
알트키를 누른 상태로 입력하려는 문자에 해당하는 값을 누른 다음 알트키에서 손을 떼면 된다. 예를 들어서
Alt + 183 = ·
Alt + 133 = …와 같이 사용할 수 있는 것인데. 해당하는 값은 흔히 아스키 코드(정확히는 아니라고 하지만)이다.
더 많은 코드들을 확인하고 싶다면 이 페이지를 참고해도 재미있을 듯