복습 문제
# 2022년 마지막 날까지 며칠 남았는지 계산해주세요
from datetime import datetime
n = datetime.now()
last = datetime(2022, 12, 31)
result = last - n
# 87일
# datetime index를 원하는 주기로 나누어주는 메소드는?
resample() ------------------------------------- 찾아보기
import pandas as pd
string_data = pd.Series(['aardvark','artichoke','nap.nan','avocado'])
string_data
# 위 데이터에 결측치가 있는지 없는지 찾아봐라
string_data.isna()
string_data.isnull()
pd.isna(string_data)
import numpy as np
data = pd.DataFrame(np.arange(12).reshape((3,4)),
index=['ohio','colorado','NewYork'],
columns=['one','two','three','four'])
data
# 인덱스의 첫글자만 대문자로 바꾸어주세요
data.index = data.index.str.title()
data.index = [x.title() for x in data.index]
data.rename(index =str.title)
# 시계열은 2022년 8월 23일부터 시작하여 7일씩 늘어나는 데이터를 10개 만들어주세요.
pd.date_range('2022-08-23', periods = 10, freq = '7D')
import pydataset
titanic = pydataset.data('titanic')
titanic
# 클래스 별로 생존자 빈도수를 구하고 부분합을 구하세요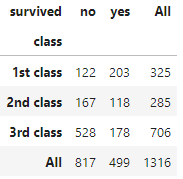
pd.crosstab(titanic['class'], titanic['survived'], margins=True)
# .categories / .codes
categories = ['one','two','three']
codes = [0,1,1,2,0,2,2,1,2,1,2,0]
# 위를 이용하여 범주형 데이터를 생성하고 순서를 지정하세요
pd.Categorical.from_codes(codes, categories, ordered = True)
# 현재 시간을 str 형으로 (연 월 일 시간 분 초) 의 형태로 나타내세요
now.strftime('%Y-%m-%d-%H-%M-%S')
ts = pd.Series(np.random.randn(100), index = pd.date_range('1/1/2000' , periods=100))
# ts 데이터 중 2000년 2월 1일부터 2월 15일까지만 보고싶다면
ts['2000-02-01' : '2000-02-15']
# 문자열을 datetime 으로 변환하는 방법 세가지를 써주세요
# ex '03/11/2004'
datetime.strptime
from dateutil.parser import parse
parse('2011-01-03')
pd.to_datetime제주 맛집 지도 시각화
- 파일 읽어오기
import pandas as pd
import openpyxl
GwanGwang = pd.read_excel('jejudoGwanGwang.xlsx')
jejudoMatJip = pd.read_excel('jejudoMatJip.xlsx')
jejuMatJip = pd.read_excel('jejuMatJip.xlsx')
jejuYeoHang = pd.read_excel('jejuYeoHang.xlsx')- 파이 결합하기
concat으로 해줘도 되는데.. 뭔가 중복되는 게 있을 것만 같아서combine_first로 해주었다
# 중복데이터는 거르고 결합..하고 싶다
# df1.combine_first(df2) ====> df1을 기준으로 df2를 중복없이 결합하겠다.
jejuGwanGwang1 = GwanGwang.combine_first(jejudoMatJip)
jejuGwanGwang1 = jejuGwanGwang1.combine_first(jejuMatJip)
jejuGwanGwang1 = jejuGwanGwang1.combine_first(jejuYeoHang)- 세어보기
jejuGwanGwang1['place'].value_counts()- 카카오 API 접속
import requests
def place_find(s) :
# 접속 url
url = 'http://dapi.kakao.com/v2/local/search/keyword.json?query={}'.format(s)
# headers 입력
headers = {
# 카카오지도 접속
"Authorization" : "KakaoAK 개인 API 키"
}
# API 요청
palces = requests.get(url, headers=headers).json()['documents']
try :
palces = palces[0]
jejuGwanGwang1_name = palces['place_name']
위도 = palces['y']
경도 = palces['x']
result = [jejuGwanGwang1_name, 위도, 경도]
return palces
except:
pass- 테스트
place_find('청초수물회&섭국 [신관]')- 위 경도 가져오기
# 위경도 가져오기
jeju_palce_list = []
for a in a :
try :
# 카카오 API사용한 사용자 함수로 던지기
data = place_find(a)
jeju_palce_list.append(data)
except :
pass7
# 복사
jeju_palce_list_1 = jeju_palce_list
# None 값 삭제
jeju_palce_list_1 = [x for x in jeju_palce_list_1 if x is not None]
# 확인
jeju_palce_list_1- DataFrame
jeju_palce = pd.DataFrame(jeju_palce_list_1)
# 컬럼 명 지정해주기
jeju_palce.columns = ['place_name', '위도', '경도']
# '제주도'는 의미 없을거 같아서 제거
jeju_palce = jeju_palce[(jeju_palce['place_name'] != '제주도')]
jeju_palce- 배경이 될 제주 지도 만들기
# 제주도 지도
import folium
jejuMap = folium.Map(location=[33.36, 126.52], zoom_start = 10)- MarkerCluster 찍기
from folium.plugins import MarkerCluster
marker_cluster = MarkerCluster().add_to(jejuMap)
for i in range(len(jeju_palce)):
folium.Marker(
location = [jeju_palce.iloc[i]['위도'], jeju_palce.iloc[i]['경도']],
popup = jeju_palce.iloc[i]['place_name'],
icon = folium.Icon(color='blue',icon='ok'),
).add_to(marker_cluster)
jejuMap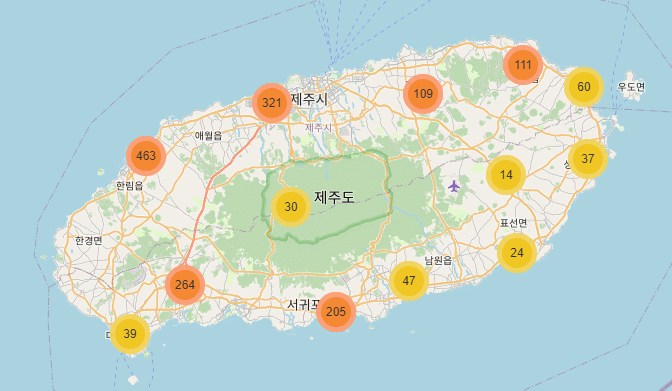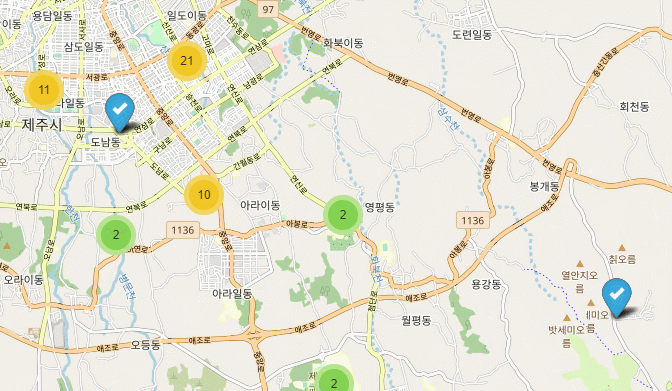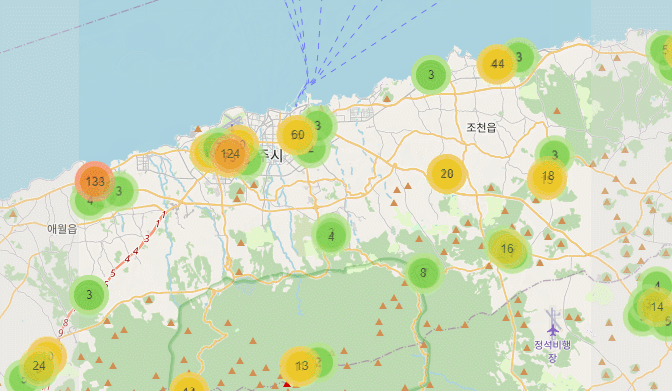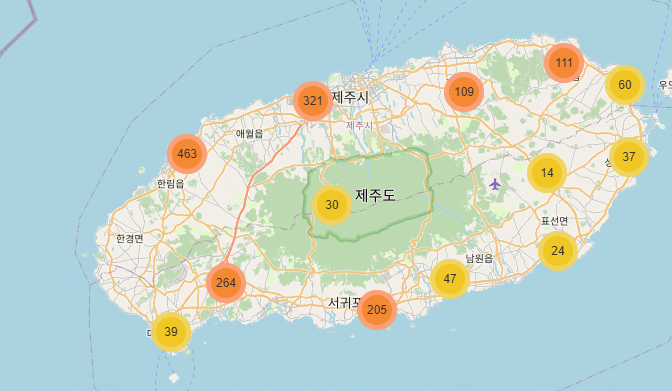
+) 지도 시각화 example이라고 뒤에 주신것
import pandas as pd
# 여러 개의 저장파일 통합하기
jeju_insta_df = pd.DataFrame( [ ] )
folder = './files/'
f_list = ['jejudoGwanGwang.xlsx', 'jejudoMatJip.xlsx', 'jejuMatJip.xlsx', 'jejuYeoHang.xlsx']
for fname in f_list:
fpath = folder + fname
temp = pd.read_excel(fpath)
jeju_insta_df = pd.concat([jeju_insta_df, temp])
jeju_insta_df.columns =['content','data','like','place','tags']
jeju_insta_df.info()
jeju_insta_df.drop_duplicates(subset = [ "content"] , inplace = True)
jeju_insta_df.tags
jeju_insta_df['place'] # 빈도수 상위 500개를 뽑는다.
# 위치정보 가져오기
location_counts = jeju_insta_df['place'].value_counts( )
location_counts
# 등록된 위치정보별 빈도수 데이터
location_counts_df = pd.DataFrame(location_counts)
location_counts_df.head()
list(location_counts_df.index)
locations = list( location_counts.index )
locations
# 카카오 검색 API 사용 예시
import requests
searching = '합정 스타벅스'
url = '
https://dapi.kakao.com/v2/local/search/keyword.json?query={}
'.format(searching)
headers = {
"Authorization": "KakaoAK _________________________"
# 입력시 반드시 KakaoAK 뒤에 한 칸 띄우고 API키 값을 적어야 합니다.
}
places = requests.get(url, headers = headers).json()['documents']
places
# 카카오 로컬 API를 활용한 장소 검색 함수 만들기
def find_places(searching):
# ① 접속URL 만들기
url = '
https://dapi.kakao.com/v2/local/search/keyword.json?query={}
'.format(searching)
# ② headers 입력하기
headers = {
"Authorization": "KakaoAK 3004e67678252b2b6c227e7c9d258681"
}
# ③ API 요청&정보 받기
places = requests.get(url, headers = headers).json()['documents']
# ④ 필요한 정보 선택하기
place = places[0]
name = place['place_name']
x=place['x']
y=place['y']
data = [name, x, y, searching]
return data
# 제주공항 검색 예시
data = find_places('제주공항')
data
# 반복작업 진행시 진행바 표시하기위한 라이브러리 tqdm 활용하기
# ! pip install tqdm
from tqdm.notebook import tqdm
import time
locations_inform = [ ]
for location in tqdm(locations):
try:
data = find_places(location)
locations_inform.append(data)
time.sleep(0.5)
except:
pass
locations_inform
# 위치정보 저장하기
locations_inform_df = pd.DataFrame(locations_inform)
location_counts_df
# 위치 데이터 병합하기
location_data = pd.merge(locations_inform_df, location_counts_df,
how = 'inner', left_on = 'name_official', right_index=True)
location_data.head()
# 데이터 중복 점검하기
location_data['name_official'].value_counts()
# 장소 이름 기준 병합하기
location_data = location_data.pivot_table(index = ['name_official','경도','위도'], values = 'place', aggfunc='sum')
location_data.head()
### 5.3.6 folium을 이용한 지도 시각화 ① - 개별 표시
# 데이터 불러오기
location_data.info()
# 지도 표시하기
import folium
Mt_Hanla =[33.362500, 126.533694]
map_jeju =
folium.Map
(location = Mt_Hanla, zoom_start = 11)
for i in range(len(location_data)):
name = location_data ['name_official'][i] # 공식명칭
count = location_data ['place'][i] # 게시글 개수
size = int(count)*2
long = float(location_data['위도'][i])
lat = float(location_data['경도'][i])
folium.CircleMarker((long,lat), radius = size, color='red', popup=name).add_to(map_jeju)
map_jeju
### folium을 이용한 지도 시각화 ② - 그룹으로 표시
# 지도 표시하기(마커 집합)
from folium.plugins import MarkerCluster
locations = []
names = []
for i in range(len(location_data)):
data = location_data.iloc[i] # 행 하나씩
locations.append((float(data['위도']),float(data['경도']))) # 위도 , 경도 순으로..
names.append(data['name_official'])
Mt_Hanla =[33.362500, 126.533694]
map_jeju2 =
folium.Map
(location = Mt_Hanla, zoom_start = 11)
marker_cluster = MarkerCluster(
locations=locations, popups=names,
name='Jeju',
overlay=True,
control=True )
marker_cluster.add_to(map_jeju2)
folium.LayerControl().add_to(map_jeju2)
map_jeju2 pivot_table
Pandas 기초 피벗 테이블(pivot_table)과 멀티인덱스(MultiIndex)
그룹핑을 사용하지 않고도 편리하게 활용할 수 있는 장점
# 예시로 사용할 데이터
import pandas as pd
import pydataset as py
df = py.data('titanic')
df.head()
pdf1 = pd.pivot_table(df, # 피벗할 데이터프레임
index = 'class', # 행 위치에 들어갈 열
columns = 'sex', # 열 위치에 들어갈 열
values = 'age', # 데이터로 사용할 열
aggfunc = 'mean') # 데이터 집계함수
pdf1Counter()
항목의 갯수를 셀때 사용하는 클래스. 리스트나 set을 인자로 넘기면 각 항목을 키로 하여 개수를 알려준다.
from collections import Counter
strr = 'adfasdfadfasdfaggggadf'
Counter(strr)
# Counter({'a': 6, 'd': 5, 'f': 5, 's': 2, 'g': 4})값이 큰것부터 작은 것까지 순서를 매겨 내림차순으로 갯수가 출력된다.