복습문제
# categorical 객체는 ___와 ___ 속성을 갖는다
codes, categories
import pydataset
train = pydataset.data('Train')
# 에서 데이터 타입이 object 인 choice 컬럼을 카테고리 형으로 바꿔주세요
train.info()
train['choice'] = train['choice'].astype('category')
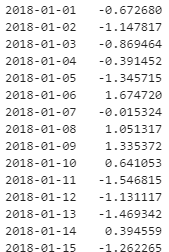
# 위 사진과 같은 형태의 값 100개를 뽑아주세요
import pandas as pd
import numpy as np
# pd.date_range('2018-01-01', freq='1m', periods=100)
ts = pd.Series(np.random.randn(100),
index = pd.date_range('2018-01-01', freq = 'D', periods=100))
# 만들어진 ts 데이터 간격을 2주로 잡고 그 값들의 평균을 구해보세요
ts.resample('2W').mean()
tips = pydataset.data('tips')
# tips 데이터로 흡연자와 요일 별 평균을 구해주세요?
tips.groupby(['smoker', 'day']).mean()
# pivot_table 로 구해보세요
pd.pivot_table(tips, index = ['smoker', 'day'], aggfunc = 'mean')
tips.pivot_table(index = ['smoker', 'day'])
# DataFrame 의 칼럼을 categorical으로 변환해주는 이유는?
메모리가 적게 들어 처리(연산) 속도가 빠름
titanic = sns.load_dataset('titanic')
titanic
# 클래스별 성별 평균 나이를 구해주세요
pd.pivot_table(titanic, index = ['class', 'sex'],
values = 'age',
aggfunc = 'mean')
# mpg 데이터를 불러와 hwy와 cty값을 manufacturer index 기준으로
# year를 col하여 pivot table을 만드세요
mpg = pydataset.data('mpg')
mpg.pivot_table(index = ['manufacturer'], values = ['hwy', 'cty'], columns='year')
df = pd.DataFrame({'info' : ['홍길동/1/46', '전우치/1/27', '김철수/1/33', '이민수/1/51',
'홍길순/2/46', '전영희/2/22', '김철순/2/39', '이유리/2/31'],
'visit_year' : [2020,2020,2020,2021,2021,2021,2022,2022],
'visit_month' : [1, 3, 4, 4, 8, 11, 7, 10],
'visit_day' : [29, 22, 16, 6, 2, 11, 26, 7]})
# 위 데이터에서 info 컬럼의 값을 분리해주세요
# info/성별/age
1.
df['sex'] = df['info'].str.split('/').str[1]
df['age'] = df['info'].str.split('/').str[2]
df['info'] = df['info'].str.split('/').str[0]
2.
pd.DataFrame(df['info'].str.split('/').tolist(),
columns=['info', 'gender', 'age'])
3.
name = []
gender = []
age = []
for x in df['info']:
x = x.split('/')
name.append(x[0])
gender.append(x[1])
age.append(x[2])
df['name'] = name
df['gender'] = gender
df['age'] = age
4.
for i in range(len(df['info'])):
gender = df['info'][i][4]
age = df['info'][i][6:]
df.loc[i,'gender'] = gender
df.loc[i,'age'] = age
# 방문 년/월/일 각각의 칼럼을 하나로 합쳐 'visit' 칼럼을 만들어주세요
1.
df['visit'] = df['visit_year'].astype(str) + '/' + df['visit_month'].astype(str) + '/' + df['visit_day'].astype(str)
2.
visit = []
for a,b,c in zip(df['visit_year'],df['visit_month'],df['visit_day']):
visit.append(f'{a}/{b}/{c}')
df['visit']=visit
# visit 칼럼을 Datetime형으로 바꾸어주세요
df['visit'] = pd.to_datetime(df['visit'])
df.info()
# visit 8 non-null datetime64[ns]
# 필요없는 열 삭제
df.drop(['visit_year', 'visit_month', 'visit_day'], axis=1)
# 1은 남 / 2는 여 로 내용을 바꾸어주세요
df['sex'] = np.where(df['sex'] == '1', '남', '여')
과제
외래객 입국-목적별/국적별 데이터 분석
주어진 내용에 기간별 대통령 컬럼을 추가
-> 각 시기에 대륙별로 입국객 차이를 알아보자.
주어진 엑셀파일 하나 읽어보기
import pandas as pd
import numpy as np
df1 = pd.read_excel('1005_data/kto_201001.xlsx')
df1 = df1.rename(columns = df1.iloc[0])
df1 = df1.drop(df1.index[0])
df1['년월'] = '2010/01'
df1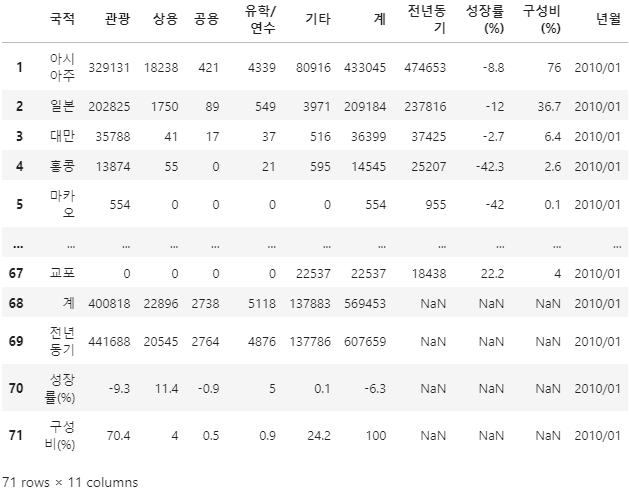
사용할 함수 작성
- 엑셀파일의 특정 구간을 불러와야하고
- 사용하기 위한 년월 컬럼을 추가해야하고
- 국적 컬럼에 함께 있는 '대륙' 데이터를 제거해야한다.
--> 제거한 데이터는 따로 컬럼을 만들어 추가 - 대통령(기간) 별로 확인하고 싶기 때문에 해당 연도에 맞는 대통령 컬럼 추가
# 2010년 1월부터 2019년 8월까지 총 116개 엑셀파일 통합하기(전처리 과정 포함)
# create_kto_data 함수 생성
def kto_data(yy, mm):
# 불러올 엑셀 파일 경로 지정
file_path = '1005_data/kto_{}{}.xlsx'.format(yy, mm)
# 엑셀 파일 불러오기
# 1번 컬럼을 header로 보냄
# 가장 아래쪽 4개의 통계를 skip함
df = pd.read_excel(file_path, header = 1, skipfooter = 4, usecols = 'A:G')
# '기준년월' 컬럼 추가
df['년월'] = '{}-{}'.format(yy, mm)
# '국적' 컬럼에서 대륙 데이터 제거
ignore_list = ['아시아주', '구주', '구주 기타', '대양주 기타', '아프리카주', '미주', '대양주', '교포소계']
condition = (df['국적'].isin(ignore_list) == False) #대륙정보 미포함 조건
df_country = df[condition].reset_index(drop = True) #대륙정보 제거
# '대륙' 컬럼 추가
continents = ['아시아']*25 + ['아메리카']*5 + ['유럽']*22 + ['오세아니아']*2 + ['아프리카']*3 + ['기타대륙']*1 + ['교포']*1
df_country['대륙'] = continents
# 대통령 컬럼 추가
if (2008 <= int(yy) and int(yy) < 2013 ) :
df_country['대통령'] = "이명박"
elif (2013 <= int(yy) and int(yy) < 2017 ) :
df_country['대통령'] = "박근혜 "
else :
df_country['대통령'] = "문재인 "
# 6. 결과 출력
return(df_country)테스트
# 테스트
kto_data('2020', '05')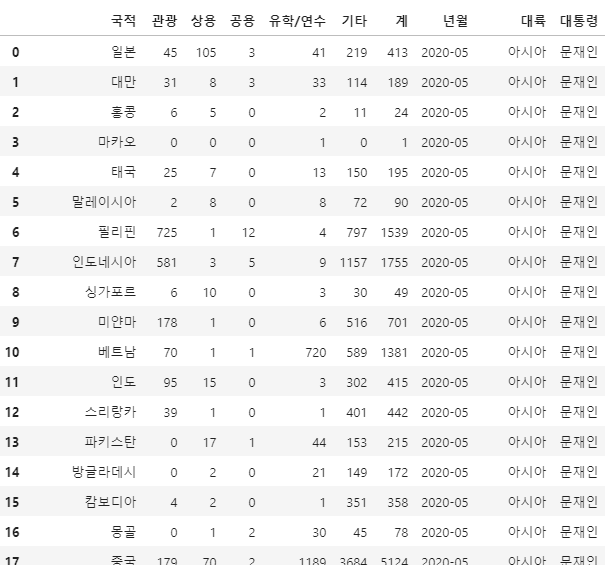
엑셀을 가져와 담아주기
빈 프레임 생성 후, 함수로 읽어준 내용을 차곡차곡 담아준다
# 담아줄 빈 프레임
kto_data_df = pd.DataFrame()
for yy in range(2010, 2021):
for mm in range(1, 13):
try:
# zfill : 2자리 수로 맞추기
# 1의 경우 01로 맞춰주는 것
temp = kto_data(str(yy), str(mm).zfill(2))
kto_data_df = kto_data_df.append(temp, ignore_index = True)
except:
# 2020년은 5월까지만 있으니까 아마도 여기서 Pass
pass확인
# 데이터 프레임 확인
kto_data_df[:20]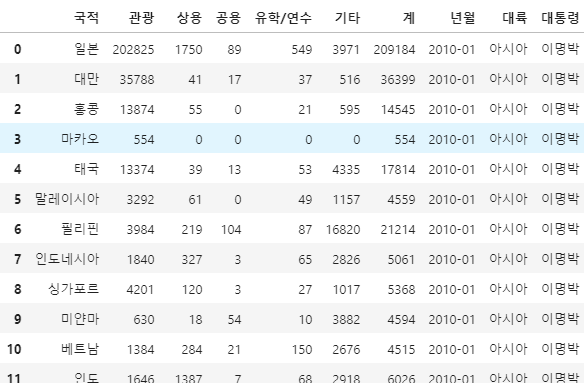
kto_data_df[::-1]
year 컬럼 추가
import matplotlib.pyplot as plt
from datetime import datetime
#한글 폰트 설정
plt.rcParams['font.family'] = 'Malgun Gothic'
# year 컬럼 추가
kto_data_df['일자'] = pd.to_datetime(kto_data_df['년월'], format = '%Y-%m').dt.to_period('M')
kto_data_df['year'] = kto_data_df['년월'].str.slice(0,4)
kto_data_df[:10]
히트맵 그리기
import matplotlib.pyplot as plt
import seaborn as sns
country_list = ['아시아', '아메리카', '유럽', '오세아니아', '아프리카']
for country in country_list:
condition = (kto_data_df['대륙'] == country)
df_filter = kto_data_df[condition]
df_pivot = df_filter.pivot_table(values='관광', index='일자', columns='대통령')
plt.figure(figsize = (16, 10))
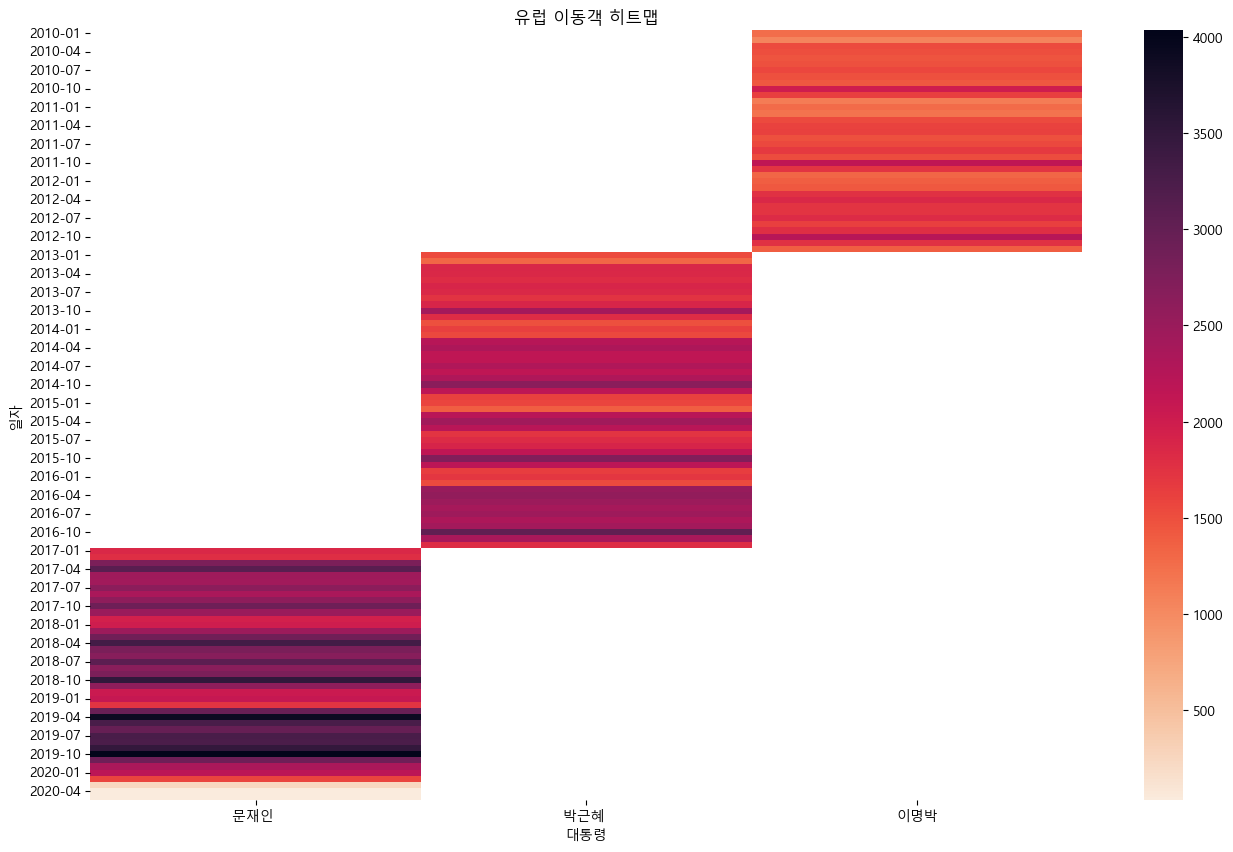
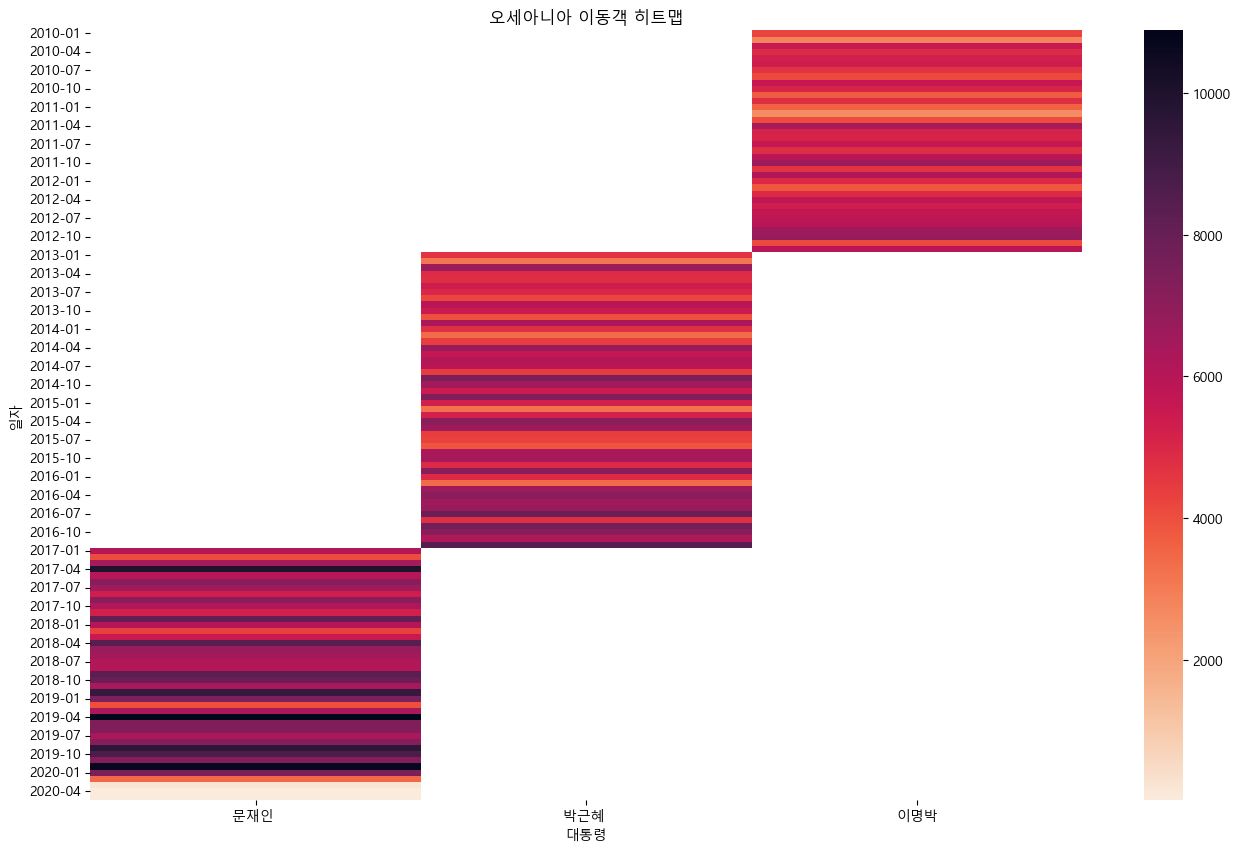
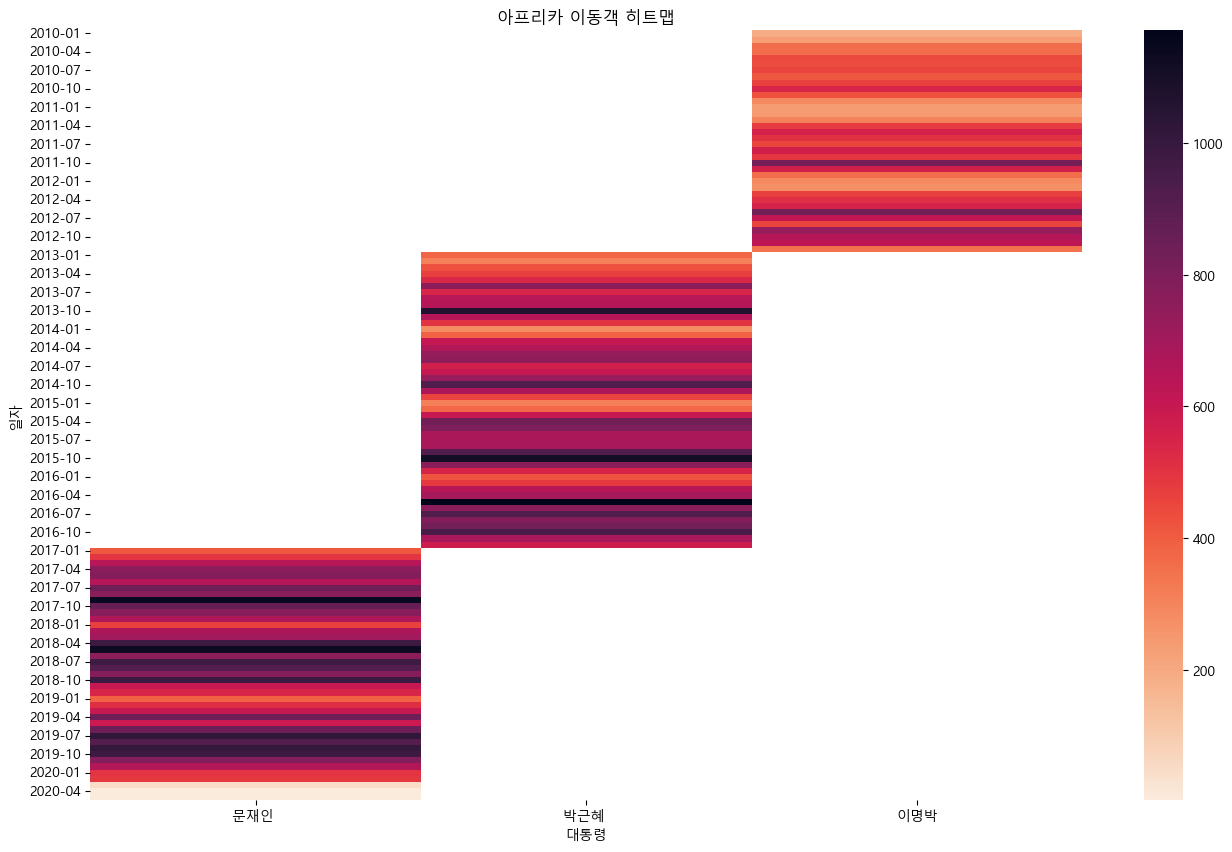
sns.heatmap(df_pivot, fmt = '.0f', cmap = 'rocket_r')
plt.title('{} 이동객 히트맵'.format(country))
plt.show()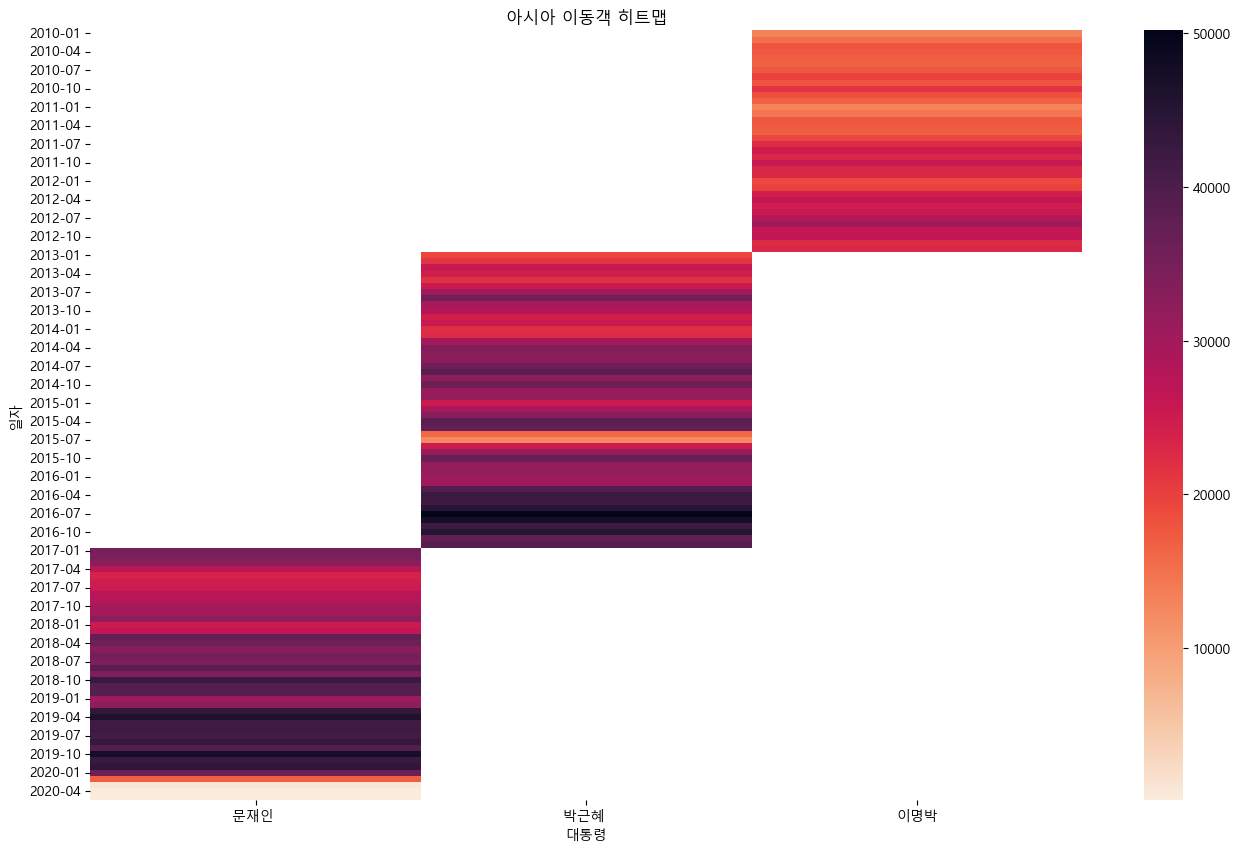
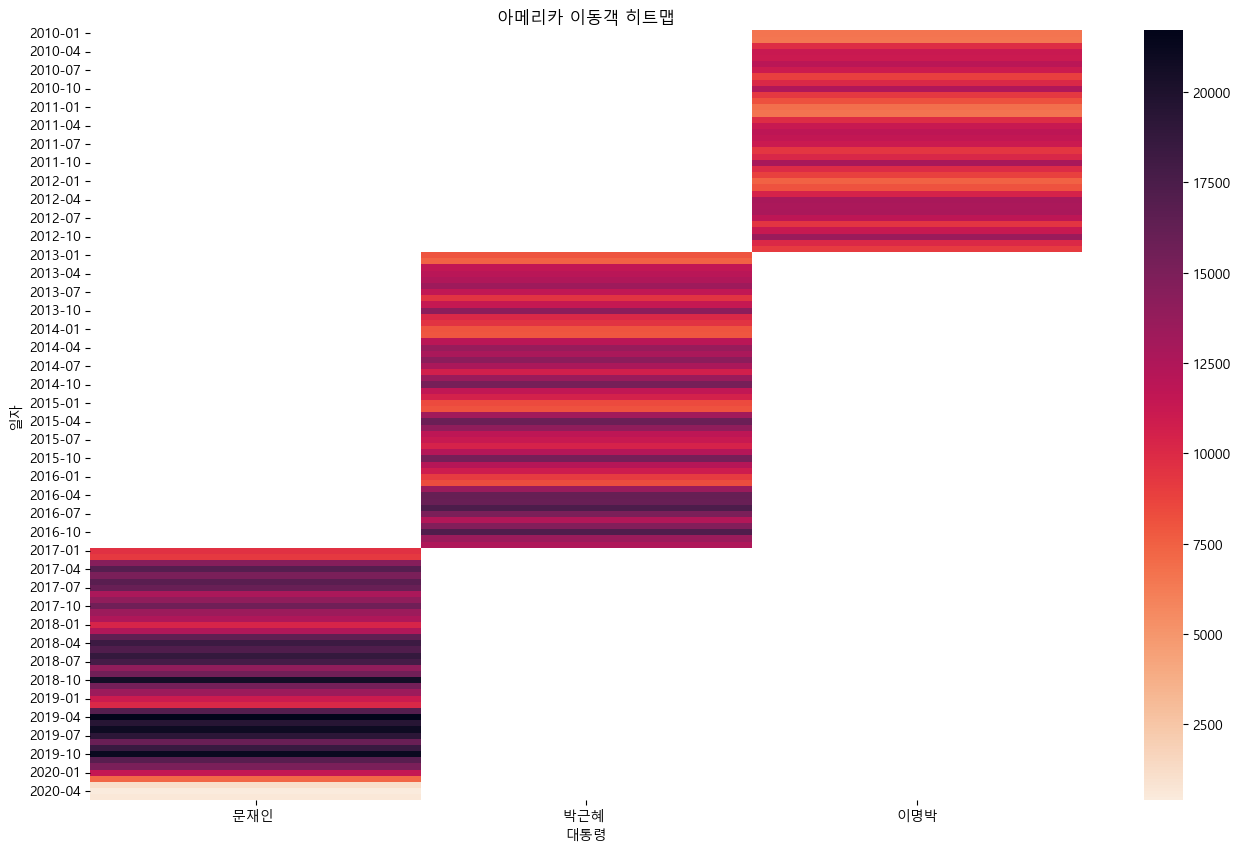
import matplotlib.pyplot as plt
import seaborn as sns
country_list = ['아시아', '아메리카', '유럽', '오세아니아', '아프리카']
for country in country_list:
condition = (kto_data_df['대륙'] == country)
df_filter = kto_data_df[condition]
df_pivot = df_filter.pivot_table(values='관광', index='year', columns='대통령')
plt.figure(figsize = (16, 10))
sns.heatmap(df_pivot, annot = True, fmt = '.0f', center=25000)
plt.title('{} 이동객 히트맵'.format(country))
plt.show()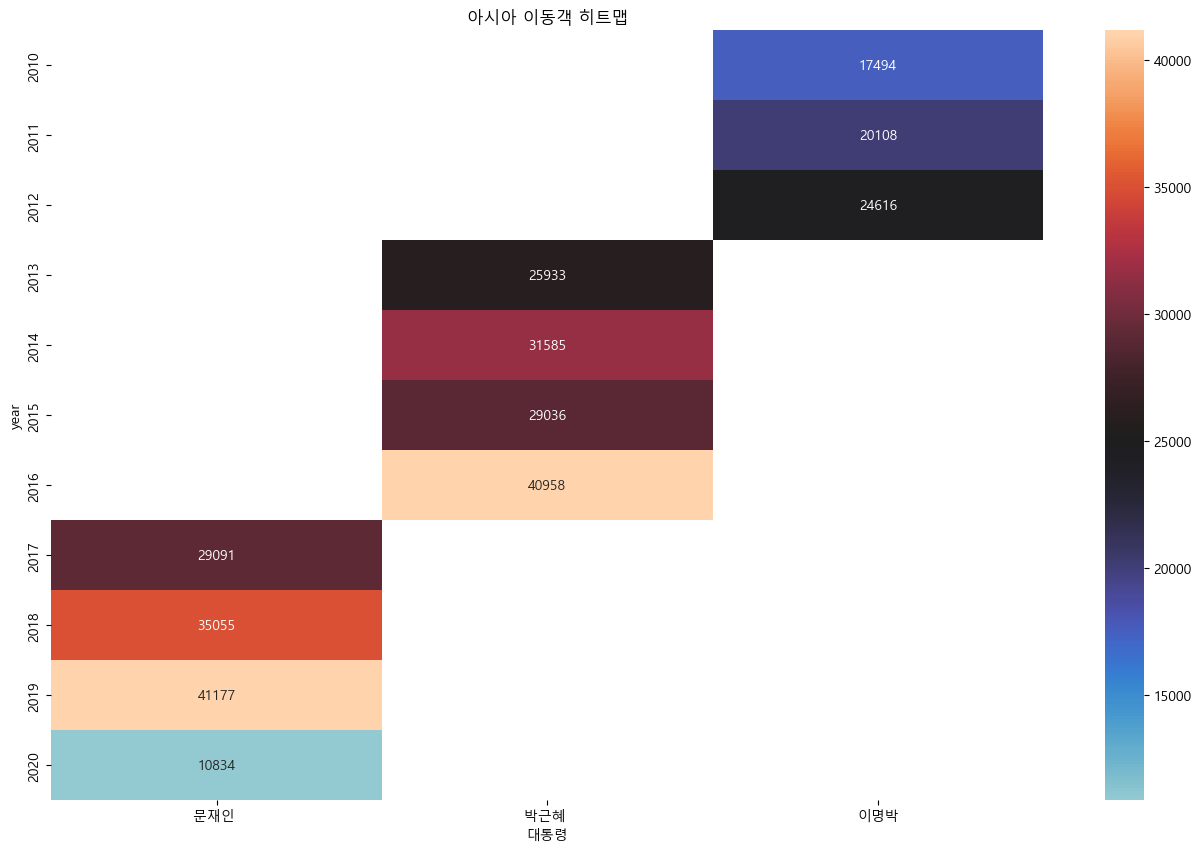
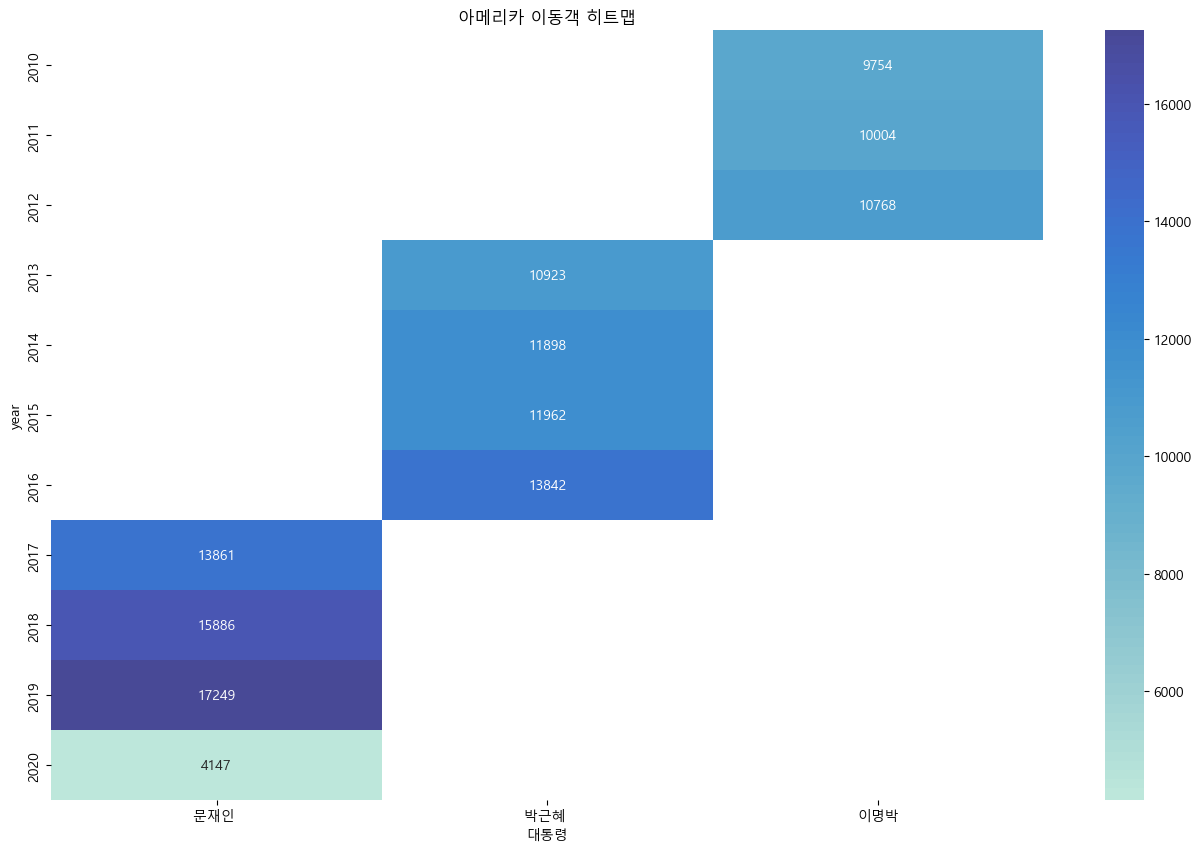
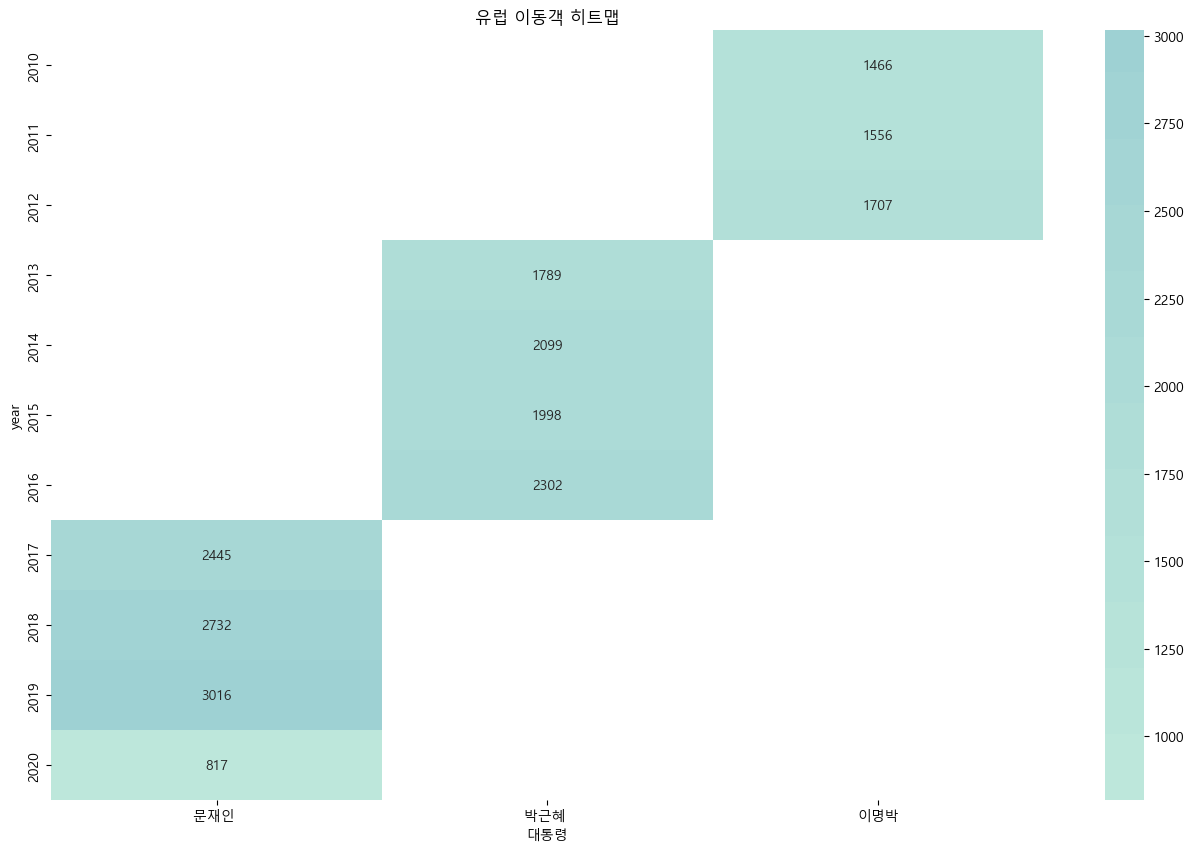
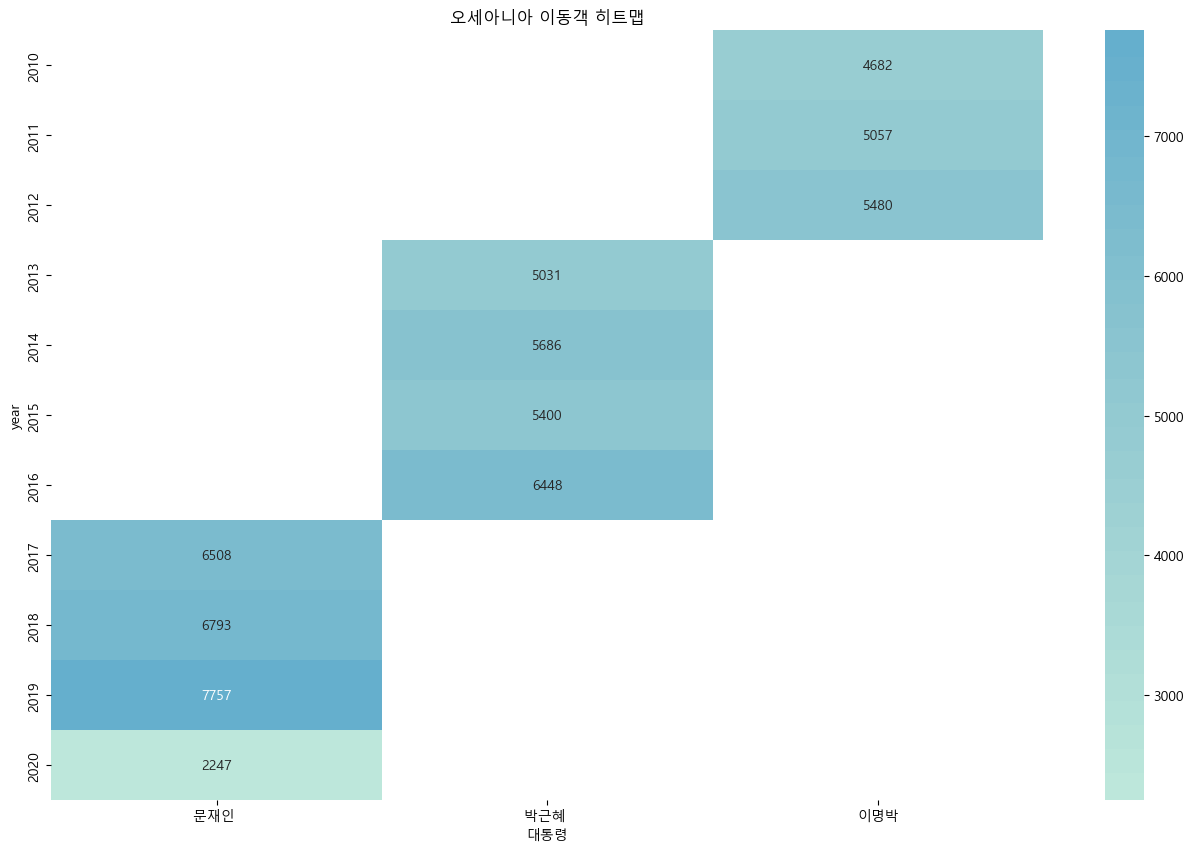
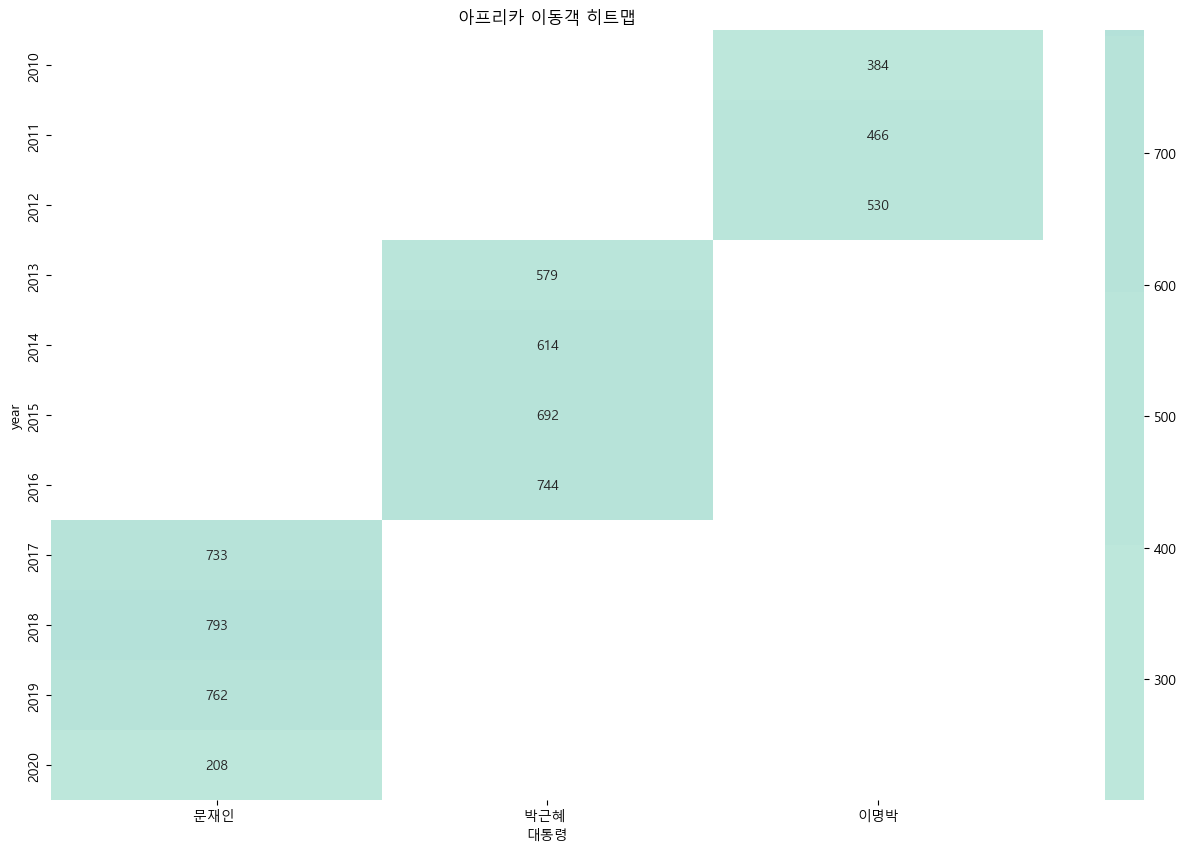
- 모든 대륙에서 코로나 이후 이동객이 줄어들었다.
- 대체적으로 이명박 대통력 시기에 이동객이 적었다
전반적으로 아시아 이동객이 가장 많았다.
엄청 많다
코로나 시기(2020) 수가 급감
메르스 시기(2015-2016) 감소
아시아 이동객 2017년도에 감소가 보이는데 사드배치 영항으로 보임
Seaborn 으로 heatmap 그리기
heatmap
데이터의 배열을 색상으로 표현해주는 그래프
- 두 개의 카테고리 값에 대한 값 변화를 한눈에 알기 쉽다.
- 대용량 데이터도 heatmap을 사용하여 시각화한다면 이미지 몇 장으로 표현이 가능하다
필요 모듈과 라이브러리
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns기본문법
sns.heatmap(df, # 데이터
vmin = 100, # 최솟값
vmax = 700, # 최대값
cbar = True, # colorbar의 유무
center = 400, # 중앙값 선정
linewidths = 0.5 # cell 사이에 선을 집어넣는다
annot = True, fmt = "d" # 각 cell의 값 표기 유무, 그 값의 데이터 타입 설정
cmap = 'Blues' # 히드맵의 색 설정
)vmin, vmax
색으로 표현하려는 최대값 최소값
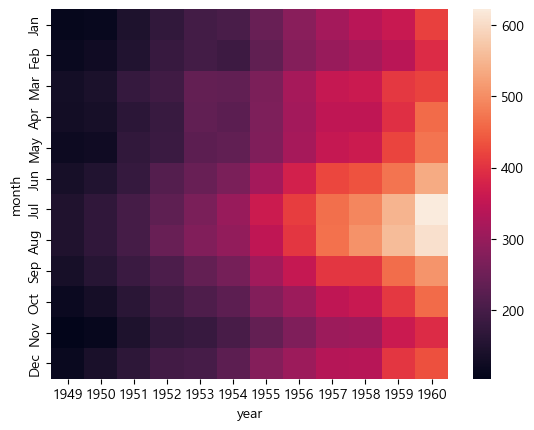
flights = sns.load_dataset('flights')
flights = flights.pivot('month', 'year', 'passengers')
sns.heatmap(flights, vmin = 300, vmax = 500)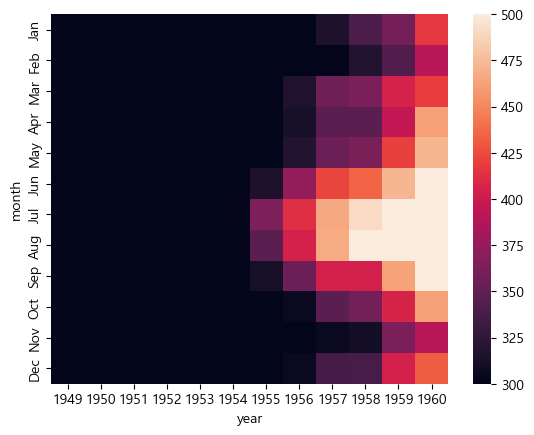
최소값으로 설정한 300이하는 모두 검은색으로, 최대값으로 설정한 500이상은 모두 흰색이 되었다.
cbar
colorbar의 유무, 기본은 True이다
sns.heatmap(flights, cbar = False)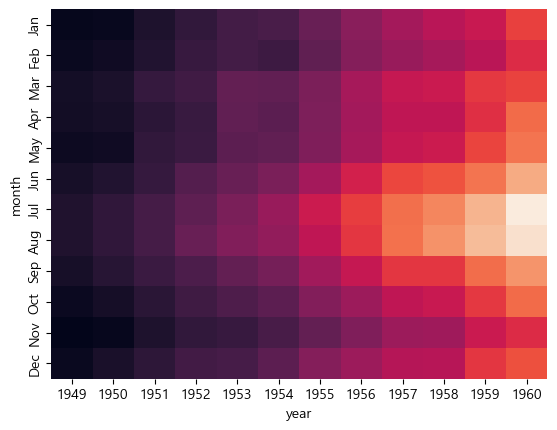
center
중앙값. 설정한값이 중간이 되어 그보다 크면 붉은색 작으면 푸른색으로 표현된다.
sns.heatmap(flights, center = 300)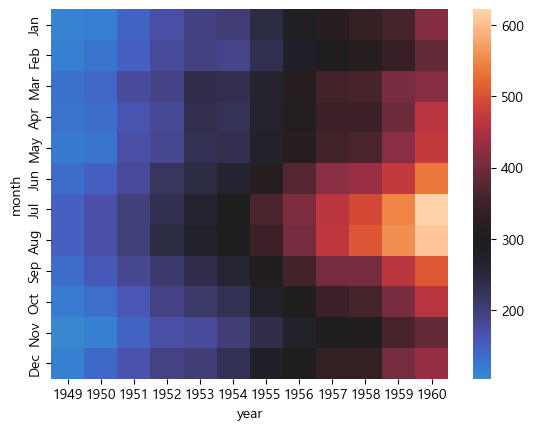
linewidths
cell 사이의 선. 굵기를 정해줄 수 있다.
sns.heatmap(flights, linewidths = 1)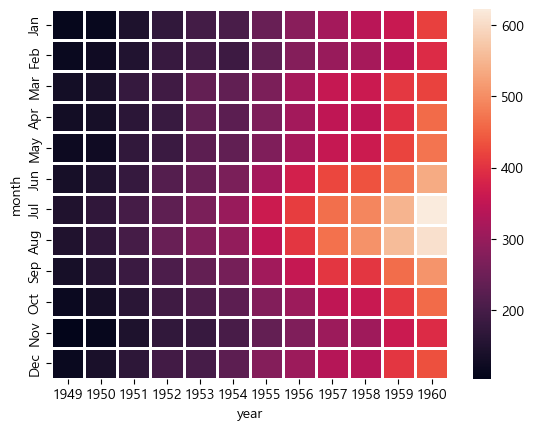
sns.heatmap(flights, linewidths = 0.5)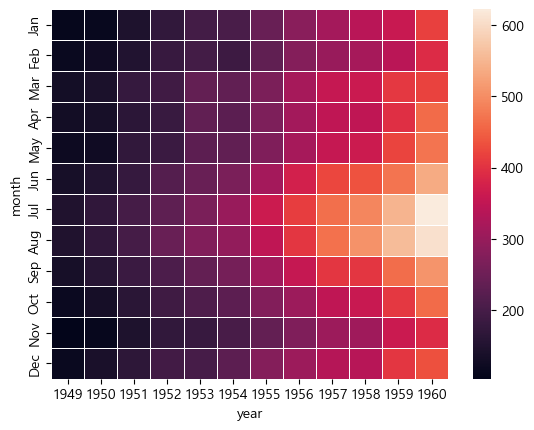
annot
cell 의 값 보기. fmt를 이용하여 데이터 형태를 지정해주어야 한다.
sns.heatmap(flights, annot = True, fmt = 'd')
데이터타입이 정수형이기 때문에 fmt = d 로 코드를 짜주었고, 소수 2번째 자리까지 나타내고 싶다면 .2f로 해주면 된다.