복습문제
import pydataset as py
computers = py.data('Computers')
computers
# 위 데이터 셋에서 pivot_table을 사용하여 'screen'과 'ram'에 따른
# price의 최대 최소 평균값을 나타내는 dataframe을 만드세요
pd.pivot_table(computers, index = ['screen', 'ram'],
values = 'price',
aggfunc = ['min', 'max', 'mean'])
pd.pivot_table(computers, index = 'ram',
columns = 'screen',
values = 'price',
aggfunc = ['min', 'max', 'mean'])
# 2000/01/01부터 현재까지 일단위로 range 하여 'index'라는 변수명으로 저장해주세요
from datetime import datetime
index = pd.date_range('2000/01/01', datetime.now(), freq='D')
# 위에서 나온 값을 시리즈로 만들어주세요 (data = 난수값)
ser = pd.Series(data = np.random.randn(8315), index = index)
# 2001년 1월 1일부터 2010년 12월 31일까지의 각열의 합을 더하면
ser['2001-01-01': '2010-12-31'].sum()
# 오홍 그냥 뒤에 sum 을 붙여서 계산해주면 되는구나 우와아
df = pd.DataFrame({0 : ['아', '야', '어', '여'],
1 : ['안녕$하세요', '반a갑a습니다', '오5랜만10000입니다', '다음에:뵈요']})
# 1번 칼럼만 선택하려면
df[1]
df.iloc[:,1]
# 위 df 1번 컬럼에서 한글만 남기고 제거하고 싶다면
df.iloc[:,1].str.replace('[^가-힣]', "")
# pandas 객체에 딕셔너리를 적용시켜 데이터에 매핑시키려한다. 어떤함수를 사용해야 하는가?
# 1. apply 2. applymap 3. map 4. agg
2 ---- x
3 ---- o
# pydataset에서 mpg데이터를 받아
# 제조사와 모델별로 cty와 hwy의 최대값과 최소값
# displ의 평균을 pivot_table로 구하세요
mpg.pivot_table(index = ['manufacturer', 'model'],
values = ['cty', 'hwy', 'displ'],
aggfunc = {'cty' : ['max', 'min'],
'hwy' : ['max', 'min'],
'displ' : 'mean'})과제
대통령에 따른 남북 인적교류 자료와 외래객 입국의 관계성
분석 이유
대한민국은 전 세계 유일 분단국가이기 때문에 외국인들에게 전쟁에 대한 위협이 있지 않을까 싶었기 때문에 대통령에 따른 남북 인적교류 현황과 그에 따른 외래객의 변화도 보려함.
대통령과 외래객 입국 자료(2010.01 - 2020.05) 정리
import pandas as pd
import numpy as np
# 2010년 1월부터 2019년 8월까지 총 116개 엑셀파일 통합하기(전처리 과정 포함)
# create_kto_data 함수 생성
def kto_data(yy, mm):
# 불러올 엑셀 파일 경로 지정
file_path = '1005_data/kto_{}{}.xlsx'.format(yy, mm)
# 엑셀 파일 불러오기
# 1번 컬럼을 header로 보냄
# 가장 아래쪽 4개의 통계를 skip함
df = pd.read_excel(file_path, header = 1, skipfooter = 4, usecols = 'A:G')
# '년월' 컬럼 추가
df['년월'] = '{}-{}'.format(yy, mm)
# '국적' 컬럼에서 대륙 데이터 제거
del_list = ['아시아주', '구주', '구주 기타', '대양주 기타', '아프리카주', '미주', '대양주', '교포소계']
condition = (df['국적'].isin(del_list) == False) #대륙정보 미포함 조건
df_country = df[condition].reset_index(drop = True) #대륙정보 제거
# 대륙별로 볼 것이기 때문에 '대륙' 컬럼을 따로 추가
continents = ['아시아']*25 + ['아메리카']*5 + ['유럽']*22 + ['오세아니아']*2 + ['아프리카']*3 + ['기타대륙']*1 + ['교포']*1
df_country['대륙'] = continents
# 대통령 컬럼 추가
if (2008 <= int(yy) and int(yy) < 2013 ) :
df_country['대통령'] = "이명박"
elif (2013 <= int(yy) and int(yy) < 2017 ) :
df_country['대통령'] = "박근혜 "
else :
df_country['대통령'] = "문재인 "
# 6. 결과 출력
return(df_country)
# 담아줄 빈 프레임생성
kto_data_df = pd.DataFrame()
# 2010년부터 2021년까지 이중 for문
for yy in range(2010, 2021):
for mm in range(1, 13):
try:
# zfill : 2자리 수로 맞추기
# 1의 경우 01로 맞춰주는 것
temp = kto_data(str(yy), str(mm).zfill(2))
kto_data_df = pd.concat([kto_data_df, temp], ignore_index=True)
except:
# 2020년은 5월까지만 있으니까 아마도 여기서 Pass
pass
# 데이터 확인
kto_data_df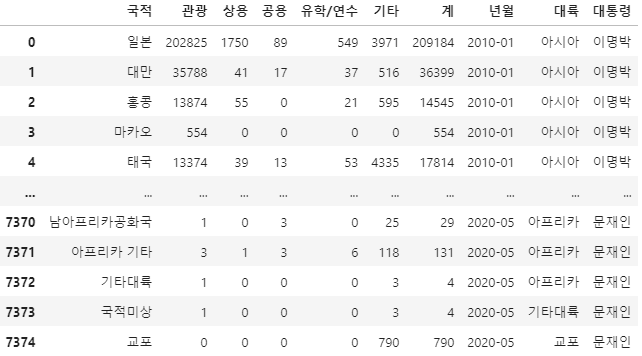
import matplotlib.pyplot as plt
from datetime import datetime
# year 컬럼 추가
kto_data_df['year'] = kto_data_df['년월'].str.slice(0,4)
kto_data_df[:10]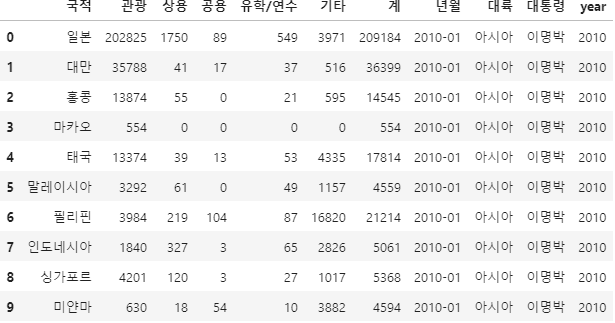
# 데이터 정리
# 필요 데이터
# 국적, 계, 년월, 대륙, 대통령, year
kto_data_df_trim = kto_data_df.iloc[ :,[0, 6, 7, 8, 9, 10]]
kto_data_df_trim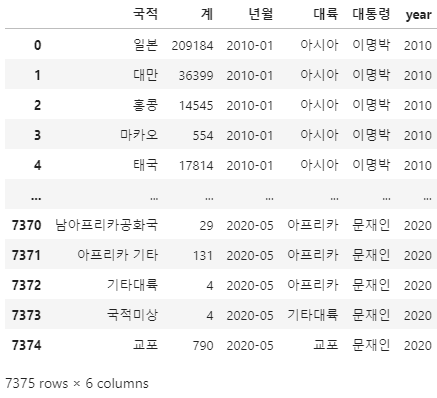
남북 인적교류현황(2009.11 - 2021.01) 정리
exchange_data = pd.read_csv('exchange_20221006113742.csv', engine='python', encoding='cp949')
# 보기 편하도록 전치
exchange_data = exchange_data.T
# 1번 데이터를 끌어올려 컬럼으로 만들어주려한다.
exchange_data = exchange_data.rename(columns = exchange_data.iloc[0])
exchange_data = exchange_data.drop(exchange_data.index[0])
# 인덱스로 들어가있는 날짜를 컬럼으로 변환하려함
# 외래객 입국자료와 합치기 위하여
exchange_data['년월'] = exchange_data.index
exchange_data['년월'] = exchange_data['년월'].str.replace('.','-')
from datetime import datetime
# 데이터 검색을 위해 datetime 형으로 변환
exchange_data['년월'] = pd.to_datetime(exchange_data['년월'])
exchange_data['년월']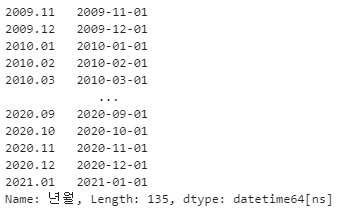
exchange_data_query = exchange_data.query('"2010-01" <= 년월 <= "2020-05"')
exchange_data_query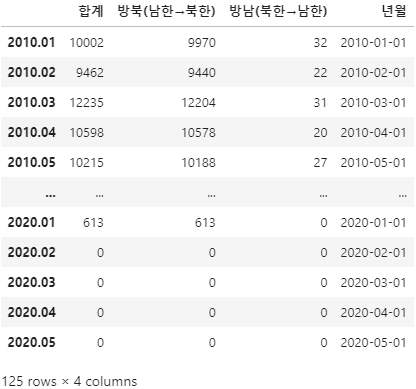
두 데이터 합쳐주기
외래객 입국 데이터에 교류 컬럼을 추가해주기로 함.
일단 교류 데이터의 합계만 있으면 될거 같다.
# [년월] 컬럼을 기준으로 합쳐줄 것이기 때문에 타입 맞춰주기
kto_data_df['년월'].info() # object
exchange_data_query['년월'].info() # datetime64
exchange_data_query['년월'] = exchange_data_query['년월'].astype(str)
exchange_data_query['년월'] = exchange_data_query['년월'].str.slice(0, 7)
exchange_data_query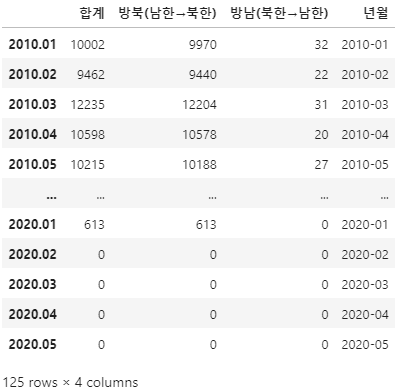
# join 시키기
combined_data = pd.DataFrame()
combined_data = pd.merge(kto_data_df_trim, exchange_data_query, left_on = '년월', right_on = '년월', how = 'inner')
combined_data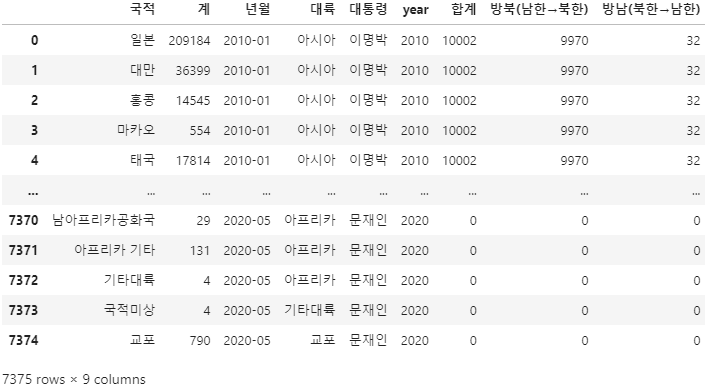
그래프 그리기
ploty로 그려보기로 했다.
import plotly.express as px
px.bar(data_frame = combined_data, x = '년월', y = '계', color='대통령')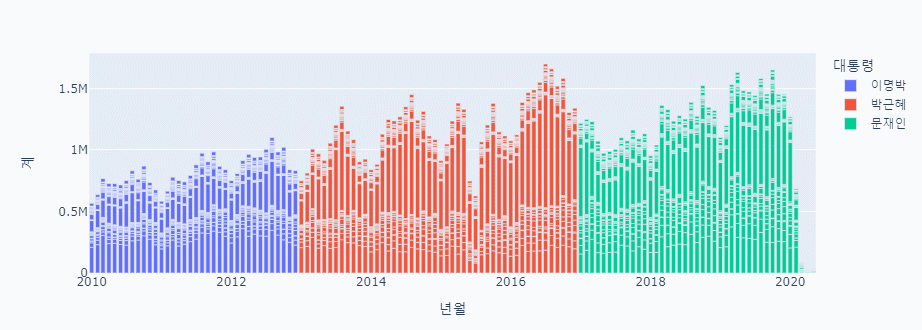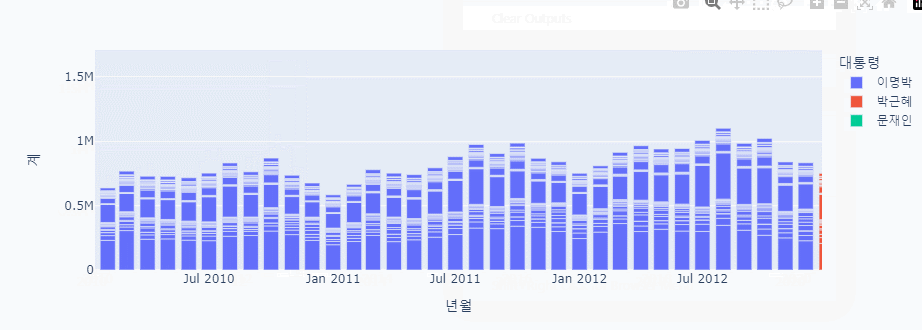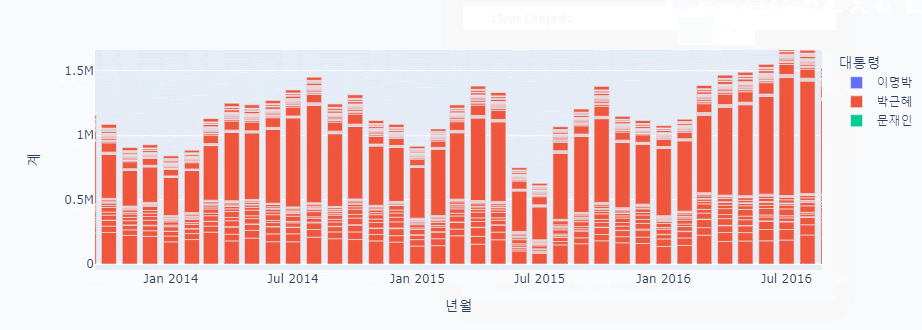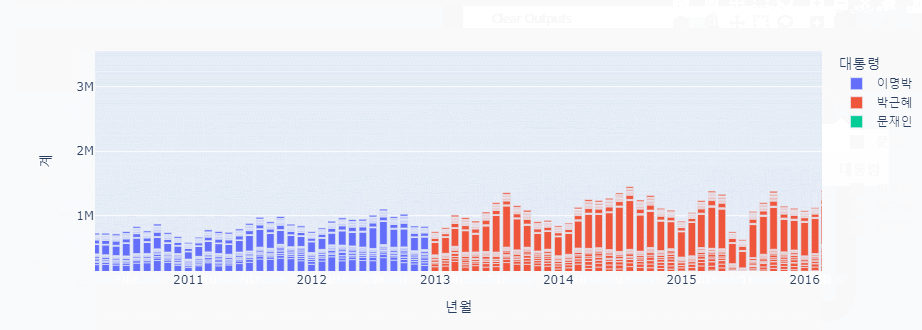
px.line(data_frame = combined_data, x = '년월', y='합계', color='대통령')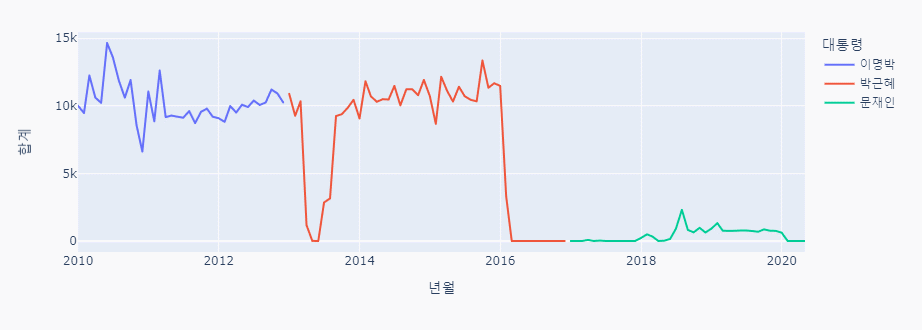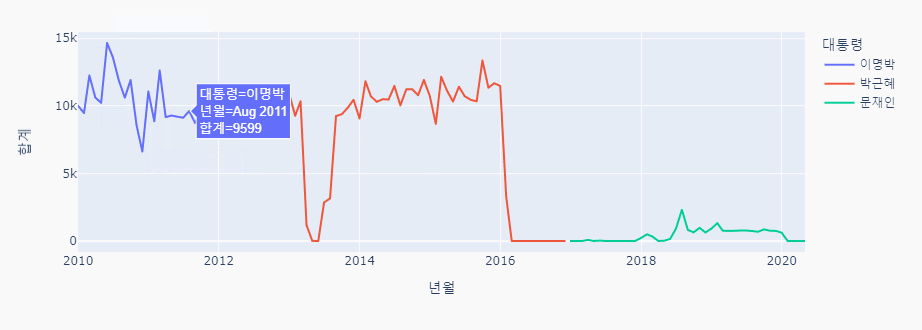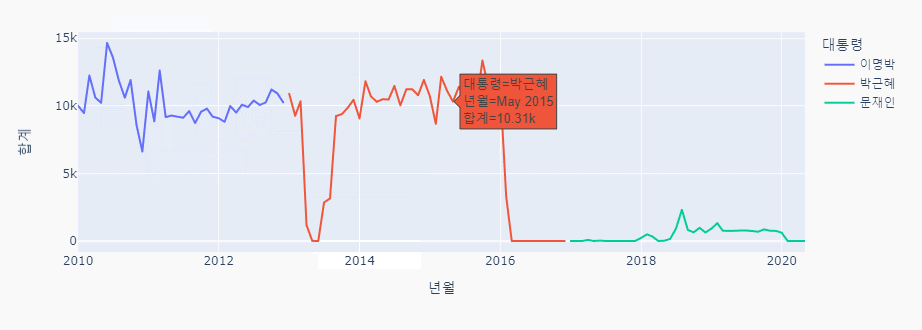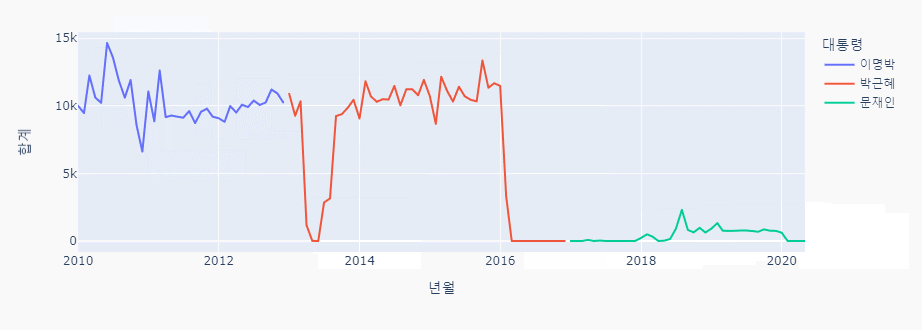
남북 교류 그래프 분석
급격히 내려가는 부분
- 2010 천안함 피격 사건, 연평도 포격전
- 2013년 2월 3차 핵실험
- 2016년 개성공단 폐쇄
2018년 남북 정상회담으로 교류가 지속되는 듯 싶었으나
- 2020년 6월 남북 공동연락사무소 폭파정리
유의미한 상관관계를 보이지는 않는 것으로 보인다.
남북 인적 교류는 굉장히 많은 변화를 보이는데
외래객은 그와 상관 없이 꾸준한 상승세를 보이는 것으로 보아
북한과의 관계보다는 다른 요인이 더 큰 외래객 유입의 중심이 되는 것으로 보인다.
법정 감염병 발생현황에 따른 외래객 입국 차이
법정 감염병 자료 내에는 많은 감염병 종류가 있다. 그 중 유의미하다고 생각하는 (내가 알 정도로 크게 유행하였던) 몇 가지만 추려 살펴보기로 했다.
코로나 - 신종감염병
(새로 유입되는 감염병들은 일단 신종감염병으로 분류되어 카운팅 되었기 때문에
코로나만 보고 싶다면 일단 2020년 자료에서만 뽑는 것이 어떨까 싶었다)
메르스 - 중동호흡기증후군
신종플루 - 신종인플루엔자
지바바이러스 - 지카바이러스감염증(2020년 자료x)외래객 입국 자료 정리 위와 동일
법정 감염병 발생현황 월별 정리
# 엑셀 읽기
!pip install openpyxl
disease_data_1 = pd.read_excel('disease_data_1.xlsx', engine='openpyxl')
disease_data_2 = pd.read_excel('disease_data_2.xlsx', engine='openpyxl')
# 원하는 모양으로 돌리기 위해 전치
disease_data_1 = disease_data_1.T
disease_data_2 = disease_data_2.T
# 데이터 프레임 정리
disease_data_1 = disease_data_1.rename(columns = disease_data_1.iloc[1])
disease_data_1 = disease_data_1.drop(disease_data_1.index[0])
disease_data_1 = disease_data_1.drop(disease_data_1.index[0])
disease_data_1
disease_data_2 = disease_data_2.rename(columns = disease_data_2.iloc[1])
disease_data_2 = disease_data_2.drop(disease_data_2.index[0])
disease_data_2 = disease_data_2.drop(disease_data_2.index[0])
disease_data_2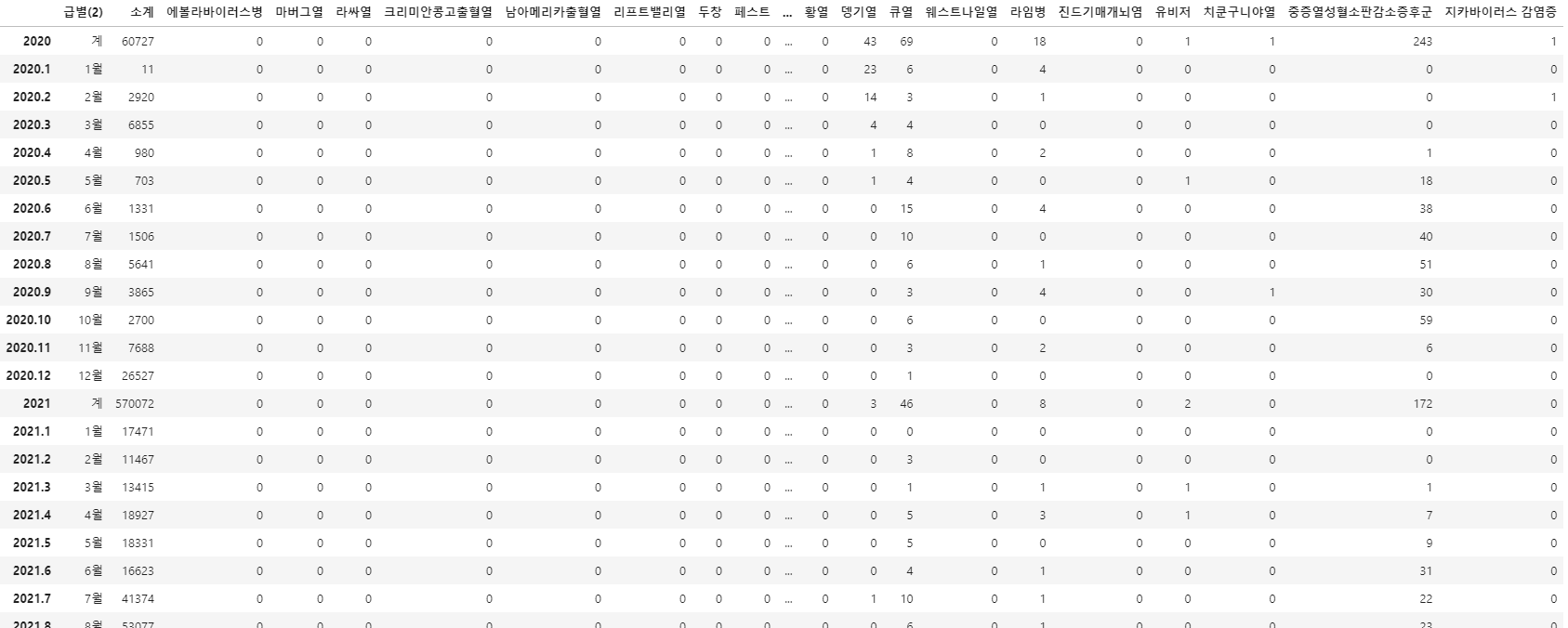
# 필요한 값들만 뽑아내기
disease_data_1 = disease_data_1[["지카바이러스감염증", "중동호흡기증후군", "신종인플루엔자"]]
disease_data_2 = disease_data_2[["중동호흡기증후군", "신종인플루엔자", "신종감염병증후군"]]
# 두 데이터 합하기
disease_data = pd.concat([disease_data_1, disease_data_2])
# 결측치는 모두 0으로 대체
disease_data = disease_data.fillna(0)
disease_data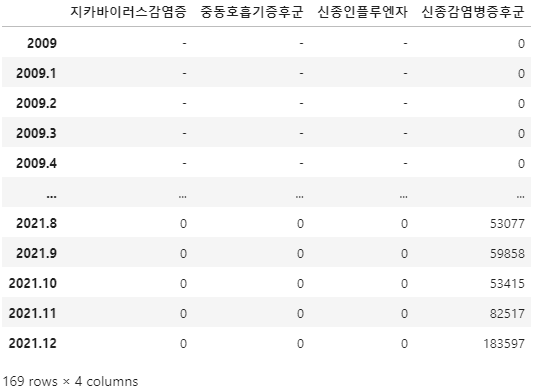
# index에 있는 년월 컬럼으로 추가하기
disease_data['년월'] = disease_data.index
disease_data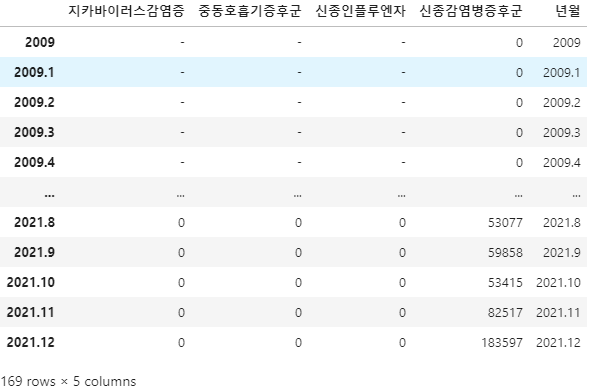
# 각 년도마다 총 계가 계산되어 있는 '년도' 값이 있다.
# 그걸 제거
disease_data['년월'] = disease_data['년월'][disease_data['년월'].map(len) != 4]
disease_data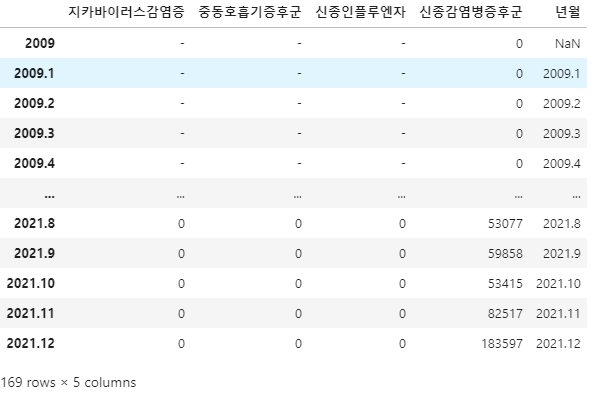
# 외래객 입국 데이터와 합쳐주기 위해 컬럼 형식 맞춰주기
# 년월 컬럼을 날짜 형식으로
disease_data['년월'] = pd.to_datetime(disease_data['년월'])
disease_data = disease_data.query('"2010-01" <= 년월 <= "2020-05"')
disease_data['년월'] = disease_data['년월'].astype(str)
disease_data['년월'] = disease_data['년월'].str.slice(0, 7)
disease_data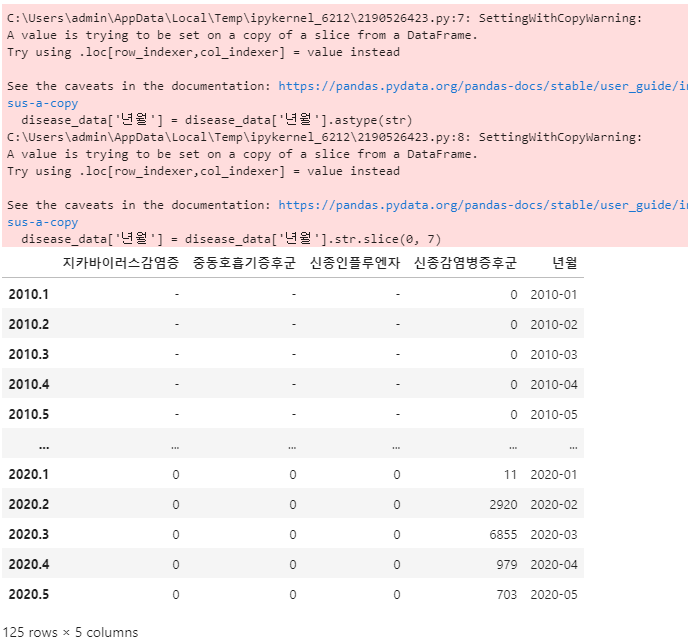
경고 혹은 권유가 뜨지만 일단 무시한다
combined_data = pd.DataFrame()
combined_data = pd.merge(kto_data_df_trim, disease_data, left_on = '년월', right_on = '년월', how = 'inner')
combined_data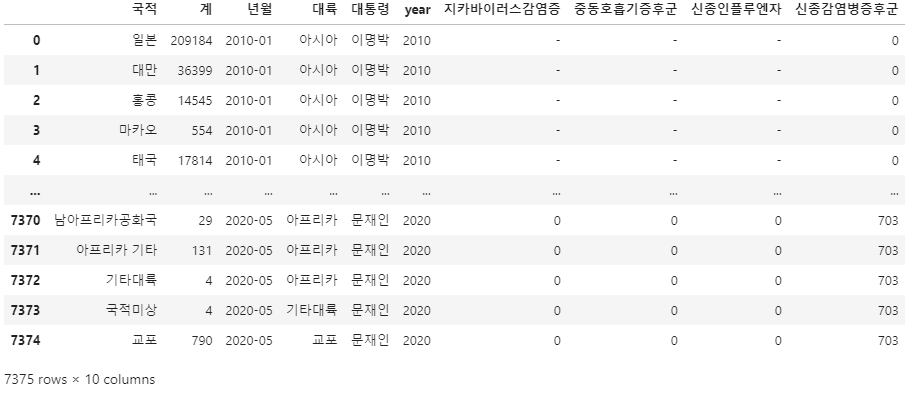
그래프 그리기
먼저 코로나(2020 자료의 신종감염병 증후군) 만 외래객 입국 자료와 비교하고 싶었다.
# 3. 그래프 그리기
fig, ax1 = plt.subplots()
ax1.plot(combined_data['년월'], combined_data['신종감염병증후군'], color='green', linewidth=1, alpha=0.7)
ax1.set_xlabel('Year')
ax2 = ax1.twinx()
ax2.bar(combined_data['년월'], combined_data['계'], color='blue', label='Demand', alpha=0.7, width=0.7)
plt.xticks(["2010-01", "2011-01", "2012-01", "2013-01", "2014-01", "2015-01", "2016-01", "2017-01", "2018-01", "2019-01", "2020-01"])
plt.show()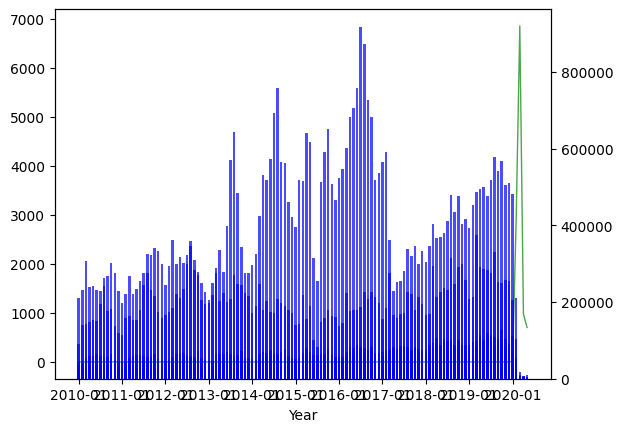
막대 그래프가 외래객 입국 현황, 선 그래프가 2020자료의 신종감염병 증후군(대략 코로나)의 수치이다. 확실히 외래객 입국이 줄어든 때에 선 그래프의 수치가 치솟아 있는 모습을 확인할 수 있었다.