복습문제
# pydataset에 있는 tips를 이용하여 요일별로 흡연자/비흡연자가 몇 명식 방문하였는지 출력하세요
import pydataset as py
tips = py.data('tips')
tips.groupby('day')['smoker'].value_counts()
tips.groupby(['day', 'smoker'])[['size']].sum()
import pandas as pd
import numpy as np
df = pd.DataFrame({'key1': ['a', 'a', 'b',' b', 'a'],
'key2': ['one', 'two', 'one', 'two', 'one'],
'data1': np.random.randn(5),
'data2': np.random.randn(5)})
# key1으로 묶고 각 그룹에서 data1의 평균을 구해주세요
df.groupby('key1')['data1'].mean()
mpg = py.data('mpg')
mpg
# class별 manufacturer의 빈도수를 구하세요
df1 = pd.crosstab(index = mpg['class'], columns = mpg['manufacturer'])
# 위의 mpg 데이터프레임에서 class를 컬럼으로 만드세요
df1 = df1.reset_index()
# melt를 사용하여 class 별로 녹이세요
df1 = df1.melt(id_vars = 'class', value_vars = df1.columns[2:])
# pd.cut을 사용하여 value가 0-9는 few, 10-19는 many라는 새로운 열 frequency를 추가시켜라
df1['frequency'] = pd.cut(x = df1['value'], bins = [0, 9, 19], labels = ['few', 'many'])
# mpg 데이터 프레임에서 manufacturer year별로 평균과 최대값을 구해보세요
mpg.groupby(['manufacturer','year']).agg(['mean', max])
new_mpg = mpg.iloc[:5, 2:5]
# new_mpg를 배열로 바꿔주세요
new_mpg.values
# new_mpg를 딕셔너리 형태로 바꿔주세요
new_mpg.to_dict()
# new_mpg의 displ을 리스트 형태로 바꿔주세요
new_mpg['displ'].tolist()
# new_mpg를 리스트 형태로 바꿔주세요
new_mpg.values.tolist()
# 하나의 리스트 안에 new_mpg의 것들을 넣어주세요
# new_mpg.values
li = []
new_mpg.applymap(lambda x : li.append(x))
li
# [출제자 답변]
[y for x in new_mpg.values.tolist() for y in x ]scikit-learn 설치하기
환경 : jupyter lab
!pip install scikit-learn
import sklearn
print(sklearn.__version__)
# 1.1.2붓꽃 품종 분류하기
- data set 을 train data 와 test data로 분류
- 학습 데이터를 기반으로 머신러닝 알고리즘을 적용해 모델 학습
- 학습된 머신러닝 모델을 이용하여 data set 분류 (예측)
- 예측된 결과값과 실제 결과값을 비교하여 모델 성능을 평가
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
iris = load_iris()
iris.keys()
# dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
type(iris)
# sklearn.utils._bunch.Bunch
# feature 만으로 된 데이터 numpy 를 가진 'data' 를 따로 변수에 저장
iris_data = iris['data']
iris_data
# lable 데이터 numpy를 가진 'target' 데이터를 따로 변수에 저장
iris_label = iris.target
print('target값 : ', iris_label)
print('target명 : ', iris.target_names)
# target값 : [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
# 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
# 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
# 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
# 2 2]
# target명 : ['setosa' 'versicolor' 'virginica']
import pandas as pd
import numpy as np
# 붓꽃 데이터 셋을 자세히 보기위해 DataFrame으로 변환
iris_df = pd.DataFrame(data=iris_data, columns=iris.feature_names)
iris_df['label'] = iris.target
iris_df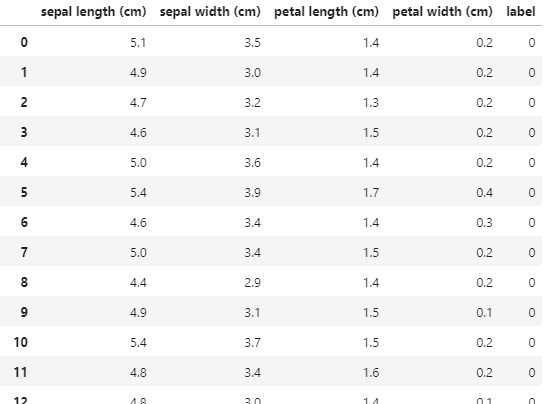
# 학습 데이터와 테스트 데이터를 test_size의 비율로 나누겠다.
# 0.2 = 테스트 데이터로 사용할건 전체에서 20% 이다.
# 기본값은 0.24 즉 25% 이다
# random_state = random 값을 만드는 seed 와 같은 의미. 일정한 결과를 얻기위해 필요하다
x_train, x_test, y_train, y_test = train_test_split(iris_data, iris_label, test_size = 0.2, random_state = 1)
# DecisionTreeClassifier : 의사결정 트리 클래스
# random_state로 코드를 수행할 때마다 동일한 학습/예측 결과를 출력할 수 있게끔 설정한다.
dt_clf = DecisionTreeClassifier(random_state = 11)
# 학습 수행
# DecisionTreeClassifier의 fit 메서드 사용
# fit(학습용 데이터 속성, 결정값 데이터 속성)
# fitting = 적합하다, 학습한다, 훈련한다.
dt_clf.fit(x_train, y_train)
# 학습이 완료된 DecisionTreeClassifier 객체에서 test data set으로 예측을 수행한다
# DecisionTreeClassifier 객체의 predict() 메서드 이용
pred = dt_clf.predict(x_test)
# 예측 결과를 기반으로 의사결정 트리(DecisionTreeClassifier)의 예측 성능을 평가
# 정확도를 측정할 것이다
# accuracy_score(테스트(실제) 레이블 데이터 셋, 예측 레이블 데이터 셋)
from sklearn.metrics import accuracy_score
print('예측 정확도:{0:.4f}'.format(accuracy_score(y_test, pred)))
# 예측 정확도:0.9667예측 정확도 0.9967 로 꽤나 잘 훈련된 모습.
+) 🌱 사이킷 런 프레임워크 익히기
지도학습의 두 축인 분류와 회귀의 다양한 알고리즘을 구현한 모든 사이킷런 클래스는 fit()과 predict()로 학습과 예측결과를 반환한다.
-
모델의 학습을 위한
fit(), 학습된 모델의 예측을 위해 제공되는 메서드predict() -
분류 알고리즘
Classifier, 회귀 알고리즘Regressor-> 두 가지를 합쳐서Estimator -
평가함수
cross_val_score와 하이퍼 파라미터 튜닝 같은GridSearchCV을 지원하는 클래스는Estimator을 인자로 받는다. -
train_test_split()
from sklearn.model_selection import train_test_split
train_test_split(arrays, test_size, train_size, random_state, shuffle, stratify)
arrays : 분할시킬 데이터를 입력 (Python list, Numpy array, Pandas dataframe 등..)
test_size : 테스트 데이터셋의 비율(float)이나 갯수(int) (default = 0.25)
train_size : 학습 데이터셋의 비율(float)이나 갯수(int) (default = test_size의 나머지)
random_state : 데이터 분할시 셔플이 이루어지는데 이를 위한 시드값 (int나 RandomState로 입력)
shuffle : 셔플여부설정 (default = True)
stratify : 지정한 Data의 비율을 유지한다. 예를 들어, Label Set인 Y가 25%의 0과 75%의 1로 이루어진 Binary Set일 때, stratify=Y로 설정하면 나누어진 데이터셋들도 0과 1을 각각 25%, 75%로 유지한 채 분할된다.+) 🌱 교차검증
학습을 너무 많이 하게 되면 모델이 과하게 학습 데이터에만 최적화되어 실제 데이터를 넣었을 때 오히려 성능이 떨어지는 문제가 생길 수 있다. 따라서 교차 검증이라는게 필요하다.
데이터의 편증을 막기 위해서 여러 세트로 구성된 학습데이터와 검증데이터로 학습과 검증(평가)를 반복 수행하게 되는 것을 말한다.
K 폴드 교차 검증
가장 보편적으로 사용되는 교차 검증 기법이다. K개의 데이터 폴드 세트를 만들어서 K번만큼 각 폴드 세트에 학습과 검증 평가를 반복적으로 수행하는 방법.
사이킷런에는 KFold 와 Stratified-KFold 클래스를 제공한다.
-> Stratified-KFold
불균형한(imbalanced) 분포도를 가진 레이블(결정 클래스) 데이터 집합을 위한 K 폴드 방식이다. 불균형한 분포도를 가진 레이블 데이터 집합은 특정 레이블 값이 특이하게 많거나 매우 적어서 값의 분포가 한쪽으로 치우치는 것을 말한다.
Stratified-KFold 는 원본 데이터의 레이블 분포를 먼저 고려한 뒤 이 분포와 동일하게 학습과 검증 데이터 세트를 분배하며 KFold가 레이블 데이터 집합이 원본 데이터 집합의 레이블 분포를 학습 및 테스트 세트에 제대로 분배하지 못하는 문제를 해결해준다.
KFold
from sklearn.model_selection import KFold
iris = load_iris() # 파일부르기
iris_data = iris.data # data(정보)와 target(매치대상) 저장
iris_label= iris.target
dt_clf = DecisionTreeClassifier() # 의사결정 트리
kfold = KFold(n_splits=5)
cv_accuracy = []
# KFold객체의 split( ) 호출하면 폴드 별 학습용, 검증용 테스트의 인덱스를 반환한다. 이거 중요함.
for train_index, test_index in kfold.split(iris_data):
# print(train_index, test_index)
# print("---"*10)
# kfold.split( )으로 반환된 인덱스를 이용하여 학습용, 검증용 테스트 데이터 추출
X_train, X_test = iris_data[train_index], iris_data[test_index]
y_train, y_test = iris_label[train_index], iris_label[test_index]
dt_clf.fit(X_train , y_train)
pred = dt_clf.predict(X_test)
accuracy = accuracy_score(y_test,pred)
cv_accuracy.append(accuracy)
print("개별 검증 정확도: ", cv_accuracy)
print('평균 검증 정확도:', np.mean(cv_accuracy))
# 개별 검증 정확도: [1.0]
# 개별 검증 정확도: [1.0, 1.0]
# 개별 검증 정확도: [1.0, 1.0, 0.9]
# 개별 검증 정확도: [1.0, 1.0, 0.9, 0.9333333333333333]
# 개별 검증 정확도: [1.0, 1.0, 0.9, 0.9333333333333333, 0.8]
# 평균 검증 정확도: 0.9266666666666665Stratified KFlod
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import StratifiedKFold
iris = load_iris()
features = iris_data = iris.data
labels = iris_label= iris.target
dct_clf = DecisionTreeClassifier()
s_fold = StratifiedKFold(n_splits=3)
n_iter = 0
for train_index, test_index in s_fold.split(features, labels) :
# print(train_index, test_index)
x_train, x_test = iris_data[train_index], features[test_index]
y_train, y_test = labels[train_index], labels[test_index]
dt_clf.fit(x_train, y_train)
pred = dt_clf.predict(x_test)
acc = accuracy_score(y_test, pred)
cv_accuracy.append(acc)
print("개별 검증 정확도: ", acc)
print('평균 검증 정확도:', np.mean(cv_accuracy))
# 개별 검증 정확도: 0.98
# 개별 검증 정확도: 0.94
# 개별 검증 정확도: 0.96
# 평균 검증 정확도: 0.9484848484848485cross_val_score()
교차검증을 보다 쉽게 할수 있도록 제공되는 사이킷런의 API 중 대표적인 것이다. classifier가 입력되면 Stratified K Flod 방식으로 레이블값의 분포에 따라 학습/테스트 셋을 분할한다. 회귀의 경우에는 그 방식으로 분할할수 없으므로 KFold 방식으로 분할
cross_val_score(estimator, X, y=None, scoring=None, cv=None, n_jobs=1, verbose=0, fit_params=None, pre_dispatch='2*n_jobs')
estimator : 사이킷런의 분류 알고리즘 클래스인 Clasifier 도는 회귀 알고리즘 클래스인 Regressor
X : 피처 데이터 셋
y : 레이블 데이터 셋
scoring : 예측 성능 평가 지표
cv : 교차 검증 폴드 수
수행 후 반환 값 : cv로 지정된 횟수만큼 scoring 파라미터로 지정된 평가 지표로 평가 결과값을 배열로 반환
일반적으로 그 값을 평균하여 평가 수치로 사용한다.cross_val_score() 는 estimator를 학습(fit), 예측(predict), 평가(evaluation) 시켜주기 때문에 간단하게 교차검증을 수행할 수 있는 것이다.
# 교차검증
from sklearn.model_selection import cross_val_score, cross_validate
iris_data1 = load_iris()
data = iris_data1.data
label = iris_data1.target
dt_clf = DecisionTreeClassifier()
scores = cross_val_score(dt_clf, data, label, scoring = 'accuracy', cv = 3)
print('교차 검증별 정확도 : ', np.round(scores, 4))
print('평균 검증 정확도 : ', np.round(np.mean(scores), 4))
# 교차 검증별 정확도 : [0.98 0.92 0.98]
# 평균 검증 정확도 : 0.96GridSearchCV
교차검증과 최적의 하이퍼 파라미터 튜닝을 한번에 해주는 API. Classifier 나 Regressor 과 같은 알고리즘에 사용되는 하이퍼 파라미터를 순차적으로 입력하면서 편리하게 최적의 파라미터를 도출할 수 있는 방안을 제공한다.
GridSearchCV(estimator, param_grid, *, scoring=None, n_jobs=None, refit=True, cv=None, verbose=0, pre_dispatch='2*n_jobs', error_score=nan, return_train_score=False)[
estimator : classifier, regressor, pipeline 등이 사용될 수 있다.
param_grid : estimator의 튜닝을 위하여 파라미터, 사용될 파라미터를 dictionary 형태로 만들어서 넣는다.
scoring : 예측 성능을 측정할 평가 방법을 넣는다. 보통 accuracy 로 지정하여서 정확도로 성능 평가를 한다.
cv : 교차 검증에서 몇개로 분할되는지 지정한다.
refit : True가 디폴트로 True로 하면 최적의 하이퍼 파라미터를 찾아서 재학습 시킨다.알고리즘에 사용되는 하이퍼파라미터를 순차적으로 입력하면서 편리하게 최적의 파라미터를 도출할 수 있는 방안을 제공. (Grid=격자)
from sklearn.model_selection import GridSearchCV
# 데이터를 로딩하고 학습데이터와 테스트 데이터 분리
iris_data2 = load_iris()
data = iris_data2.data
label = iris_data2.target
x_train, x_test, y_train, y_test = train_test_split(data, iris_data2.target, test_size=0.2, random_state=121)
# 테스트할 하이퍼 파라미터 세트는 딕셔너리 형태로
## 하이퍼파라미터의 명칭은 문자열 key 값으로, 하이퍼 파라미터의 값은 리스트형으로 설정
parameters = {'max_depth' : [1,2,3], 'min_samples_split' : [2, 3]}
# DecisionTreeClassifier : 의사결정 트리 클래스
dtree = DecisionTreeClassifier()
# param_grid의 하이퍼 파라미터를 3개의 train, test set fold로 나누어 테스트를 수행할 것이다
# refit = True는 기본값. 가장 좋은 파라미터 설정으로 재학습 시키겠다는 옵션이다.
grid_dtree = GridSearchCV(dtree, param_grid=parameters, cv=3, refit=True)
# 학습 데이터 세트를 fit 메서드에 인자로 입력
# 학습 데이터를 (grid_dtree의) cv에 기술된 폴딩세트만큼 분할하여 param_grid에 기술된 하이퍼 파라미터를
# 순차적으로 변경하면서 학습 및 평가를 수행하고 그 결과를 cv_result 속성에 기록한다.
# 붓꽃 학습 데이터로 param_grid의 하이퍼 파라미터를 순차적으로 학습 및 평가
grid_dtree.fit(x_train, y_train)
# 결과를 추출해 DF형으로 변환
scores_df = pd.DataFrame(grid_dtree.cv_results_)
scores_df[['params', 'mean_test_score', 'rank_test_score', 'split0_test_score', 'split1_test_score', 'split2_test_score']]
scores_df
params 칼럼 : 수행할 때마다 적용된 개별 하이퍼 파라미터 값
rank_test_score : 하이퍼 파라미터별로 성능이 좋은 score순위. 1이 가장 뛰어난 순위미며 이때의 파라미터가 최적의 하이퍼 파라미터
mean_test_score : 개별 하이퍼 파라미터 별로 cv의 폴딩 테스트 세트에 대해 총 수행한 평가 기준값
print('GridSerachCV 최적의 파라미터 : ', grid_dtree.best_params_)
print(f'GridSerachCV 최고 정확도 : {grid_dtree.best_score_:.4f}')
# GridSerachCV 최적의 파라미터 : {'max_depth': 3, 'min_samples_split': 2}
# GridSerachCV 최고 정확도 : 0.9750
# refit으로 이미 학습된 estimator 반환
estimator = grid_dtree.best_estimator_
pred = estimator.predict(x_test)
print('{0:.4f}'.format(accuracy_score(y_test, pred)))
# 0.9667일반적으로 학습 데이터를 GridSearchCV를 이용해 최적 하이퍼 파라미터 튜닝을 수행한 뒤에 별도의 테스트 세트에서 이를 평가하는 것이 일반적인 머신러닝 모델 적용방법이다.
🌱 머신러닝 모델을 구축하는 주요 프로세스
일반적으로 머신러닝 모델을 구축하는 주요 프로세스는 피처의 가공, 변경, 추출을 수행하는 피처 처리(feature processing), ML 알고리즘 학습/예측 수행, 그리고 모델 평가의 단계를 반복적으로 수행하는 것이다.
🧃 set_index()
DataFrame 내의 열을 이용한 인덱스 설정이다. 이 메서드는 열의 label 혹은 lable list를 입력받는다.
DF.set_index(keys, drop = True, append = False, inplace = Flase)
keys : 인덱스로 세팅하려는 열
-> 복수개의 열 입력시 멀티 인덱스가 된다.
drop : 인덱스로 세팅한 열을 DataFrame내에서 삭제할지 여부 결정
append : 기존에 존재하던 인덱스를 삭제할지 여부 결정
inplace : 원본 객체를 변경할지의 여부 선택
# 예시로 사용할 DataFrame
import pydataset
mpg = pydataset.data('mpg')
new_mpg = mpg.iloc[:5, 2:5]
print(new_mpg)
# displ year cyl
# 1 1.8 1999 4
# 2 1.8 1999 4
# 3 2.0 2008 4
# 4 2.0 2008 4
# 5 2.8 1999 6'displ' 컬럼을 인덱스로 만들어보겠다
print(new_mpg.set_index('displ'))
# year cyl
# displ
# 1.8 1999 4
# 1.8 1999 4
# 2.0 2008 4
# 2.0 2008 4
# 2.8 1999 6index화 시킬 'displ' 컬럼을 keys로 적어주었다. 다른 옵션들은 기재하지 않아 디폴트 값으로 출력된 모습이다.
drop = False 값으로 설정할 경우
print(new_mpg.set_index(keys = 'displ', drop = False ))
# displ year cyl
# displ
# 1.8 1.8 1999 4
# 1.8 1.8 1999 4
# 2.0 2.0 2008 4
# 2.0 2.0 2008 4
# 2.8 2.8 1999 6'displ' 컬럼이 인덱스가 되었음에도 삭제되지 않고 그대로 남아있는 것을 확인
append = True 의 경우
print(new_mpg.set_index(keys = 'displ', append = True ))
# year cyl
# displ
# 1 1.8 1999 4
# 2 1.8 1999 4
# 3 2.0 2008 4
# 4 2.0 2008 4
# 5 2.8 1999 6원래 있던 인덱스가 삭제되지 않은 상태로 새롭게 'displ' 컬럼이 인덱스화 되었음을 확인 할 수 있었다(멀티 인덱스)
🧃 reset_index()
기본값으로 인덱스 값을 컬럼화 시키는 데 사용한다. 즉, set_index() 의 기능을 역으로 수행하는 것에 가깝다.
DF.reset_index(drop = False, inplace = False)
drop : 인덱스로 세팅한 열을 DataFrame 내에서 삭제할지 결정한다
inplace : 원본 객체를 이대로 변경할지 결정한다.
예시로 사용할 데이터의 현재 모습이다.
print(new_mpg)
# displ year cyl
# 1 1.8 1999 4
# 2 1.8 1999 4
# 3 2.0 2008 4
# 4 2.0 2008 4
# 5 2.8 1999 6괄호안에 아무런 값을 적지 않고 메서드를 사용할 수 있다.
print(new_mpg.reset_index())
# index displ year cyl
# 0 1 1.8 1999 4
# 1 2 1.8 1999 4
# 2 3 2.0 2008 4
# 3 4 2.0 2008 4
# 4 5 2.8 1999 6인덱스였던 값들이 자동으로 생긴 'index' 컬럼 안으로 밀려들어간 모습을 확인 할 수 있다. info()로 데이터 타입을 확인하면 'int64' 으로 나온다.
drop = True 인 경우
# 그냥 하면 차이가 눈에 보이지 않을 수 있으니 displ 컬럼을 인덱스화 시켜주겠다
new_mpg.set_index(keys = 'displ', inplace=True)
print(new_mpg)
# year cyl
# displ
# 1.8 1999 4
# 1.8 1999 4
# 2.0 2008 4
# 2.0 2008 4
# 2.8 1999 6
# displ 컬럼이 인덱스가 된 모습을 확인할 수 있다. 이 상태에서 drop을 해보면
print(new_mpg.reset_index(drop = True))
# year cyl
# 0 1999 4
# 1 1999 4
# 2 2008 4
# 3 2008 4
# 4 1999 6인덱스였던 displ이 삭제되고 정수형 index가 남아있는 모습을 확인할 수 있었다
loc[] 연산자
- 개별 또는 여러 칼럼 값 전체를 추출하고자 한다면
iloc[]나loc[]를 사용하지 않고data_df['칼럼명']으로도 충분하다. 하지만 행과 열을 함께 사용하여 데이터를 추출해야 한다면iloc[]나loc[]를 사용하는 것이 좋다. iloc[]와loc[]를 이해하기 위해서는 명칭 기반 인덱싱과 위치 기반 인덱싱의 차이를 먼저 이해해야 한다. DataFrame의 인덱스나 칼럼명으로 데이터에 접근하는 것은 명칭 기반 인덱싱이다. 0부터 시작하는 행, 열의 위치 좌표만 의존하는 것이 위치 기반 인덱싱iloc[]는 위치 기반 인덱싱만 가능하다. 따라서 행과 열 위치 값으로 정수형 값을 지정해 원하는 데이터를 반환loc[]는 명칭기반 인덱싱만 가능하다. 따라서 행 위치에 DataFrame 인덱스가 오며, 열 위치에는 칼럼명을 지정해 원하는 데이터를 반환- 명칭 기반 인덱싱에서 슬라이싱을
시작점:종료점으로 지정할 때 시작점에서 종료점을 포함한 위치에 있는 데이터가 반환
df.loc['three', 'Name'] : 인덱스가 'three'인 행의 'Name' 칼럼 값을 반환. 단일값
df.loc['one':'three', 'Name':'Gender'] : 인덱스값 one 부터 three 까지 / 컬럼은 Name 부터 Gender 까지 DataFrame이 반환
df.loc[df['year']>2014] : bool형 가능. year칼럼값이 2014 초과인 데이터만 인덱싱으로 추출
df.iloc[1,0] : 인덱스 1번의 0번 칼럼 값 반환, 단일 값
df.iloc[0:2, [0, 1]] : 0:2 슬라이싱 범위의 첫번째(0)~두번째행(1) / 첫번째(0)~두번째 열(1)에 해당하는 DataFrame 반환
df.iloc[0:2, 0:3] : 0:2 슬라이싱 값 부터 0:3 슬라이싱 값 사이의 모든 DataFrame값 반환