복습문제
# ML 알고리즘에 사용할 데이터는 결손 값이 있어서는 안되지만, 숫자열과 문자열 모두 가능하다 (ox)
O
# [출제자 답변]
X -- 문자열은 곤란하다
# 지도학습은 학습을 위한 다양한 피처(Y)와 분류결정값인 레이블(x) 데이터로 모델을 학습한다 (ox)
x --- 피처가 x
# 분류는 답이 정해져있고, 군집화는 답이 정해져있지 않다 (ox)
O
# 다음 괄호안에 알맞은 단어를 넣으세요
1) 사이킷런에서 분류 알고리즘을 구현하는 클래스 ( Classifier)
2) 사이킷런에서 회귀 알고리즘을 구현하는 클래스 ( Regressor )
3) 위 두 클래스를 합쳐서 지도학습의 모든 알고리즘을 구현한 클래스 ( Estimator )
# 사이킷런의 머신러닝 알고리즘은 문자열 값을 입력값으로 허용하지 않지만 NaN, Null 값은 허용한다 (ox)
X
import numpy as np
import pandas as pd
arr = np.array(['TV', '냉장고','전자레인지','컴퓨터','선풍기','선풍기','믹서','믹서']*10)
from sklearn.preprocessing import LabelEncoder
# fit, transform 하기
encoder = LabelEncoder()
labels = encoder.fit_transform(arr)
labels
from sklearn.datasets import load_iris
iris = load_iris()
# iris_data = _______
# iris_label = ______
iris_data = iris['data']
iris_label = iris.target
# 위를 DataFrame으로 만들고 싶다
iris_df = pd.DataFrame(data=iris_data, columns=iris.feature_names)
# iris_label 칼럼을 옆에 새로 추가하고 싶다.
iris_df['label'] = iris_label
# iris_df['label']에 있는 값을
# 0 = setosa / 1 = versicolor / 2 = virginica 로 변경해주세요
iris_df['label_tr'] = np.where(iris.target == 0, 'setosa', iris.target)
iris_df['label_tr'] = np.where(iris.target == 1, 'versicolor', iris.target)
iris_df['label_tr'] = np.where(iris.target == 2, 'virginica', iris.target)
# [출제자 답변]
iris_df['label_tr'] = iris_df['label'].map({0:'setosa', 1:'versicolor', 2:'virginica'})
iris_df
dict = {'col1': [1, 11], 'col2': [2, 22], 'col3': [3, 33]}
df_dict = pd.DataFrame(dict)
# 위 DataFrame을 리스트로 변환하세요
df_dict.values.tolist()
list(df_dict.values.flatten())
# 중첩리스트 말고 하나의 리스트 안에 넣어라
df_dict.values.flatten().tolist()
[y for x in df_dict.values.tolist() for y in x ]
# 행렬 정렬은 np.sort()와 같이 sort를 호출하는 방식과
# ndarray.sort() 와같이 행렬 자체에서 sort()를 호출하는 방식이 있다.
# 두 방식의 차이는?
np.sort()는 기존 행렬은 유지한 채로 정렬 값을 반환
ndarray.sort()는 기존 행렬을 변경해주고 반환값 x
# 데이터를 학습/테스트 데이터로 분리하는 함수는?
from sklearn.model_selection import train_test_split
train_test_split()
iris = load_iris()
iris_data = iris.data
iris_label = iris.target
# train 데이터와 test 데이터를 7:3으로 나눠주세요
x_train, x_test, y_train, y_test = train_test_split(iris_data, iris_label, test_size = 0.3, random_state = 1)(위키북스의 '파이썬 머신러닝 완벅 가이드' 개정 2판으로 공부하고 있습니다.)
데이터 전처리
머신러닝 알고리즘은 데이터를 기반으로 하고 있기 때문에 어떤 데이터를 가지느냐에 따라 결과가 크게 달라질 수 있다. 따라서 데이터 전처리는 알고리즘만큼 중요한 부분.
결손값, NaN, Null 값은 허용되지 않으며, 이러한 값은 고정된 다른 값으로 변환해주어야 한다. 또한 문자열 값을 입력값으로 허용하지 않기 때문에 인코딩하여 숫자형으로 변환해야 한다.(텍스트형 피처는 피처 벡터화(feature vectorization)등의 기법으로)
데이터 인코딩
머신러닝을 위한 대표적인 인코딩 방식은 레이블 인코딩(Label encoding)과 원-핫 인코딩(One Hot encoding)
레이블 인코딩
카테고리를 코드형 숫자값으로 변환하는 것이다. 사이킷런의 레이블인코딩은 LabelEncoder 클래스로 구현하며, 객체 생성 후 fit과 transform 혹은 fit_transform 으로 레이블 인코딩을 수행한다.
from sklearn.preprocessing import LabelEncoder
items = ['TV', '냉장고','전자레인지','컴퓨터','선풍기','선풍기','믹서','믹서']
# LabelEncoder를 객체로 생성한 후, fit과 transform()으로 레이블인코딩 수행
encoder = LabelEncoder()
encoder.fit_transform(items)
# array([0, 1, 4, 5, 3, 3, 2, 2], dtype=int64)위처럼 예를 들은 데이터의 구분이 ['TV', '냉장고','전자레인지','컴퓨터','선풍기','선풍기','믹서','믹서'] 로 되어있다면 tv:1/냉장고:2 ... 와 같은 숫자형 값으로 변환하는 것이다.
LabelEncoder객체의 classes_ 속성값으로 인코딩 클래스를 확인할 수도 있다. 이 속성은 0번부터 순서대로 변환된 인코딩 값에 대한 원본값을 가지고 있음을 알수 있게 한다.
encoder.classes_
# array(['TV', '냉장고', '믹서', '선풍기', '전자레인지', '컴퓨터'], dtype='<U5')inverse_transform()을 통해 인코딩 된 값을 다시 디코딩 할 수도 있다.
encoder.inverse_transform([0, 1, 4, 5, 3, 3, 2, 2])
# array(['TV', '냉장고', '전자레인지', '컴퓨터', '선풍기', '선풍기', '믹서', '믹서'], dtype='<U5')원-핫 인코딩
피처값의 유형에 따라 새로운 피처를 추가해 '고유값'에 해당하는 컬럼만 1을 표시하고 나머지는 0을 표시하는 방식이다.
사이킷런에서 One-Hot 인코딩은 OneHotEncoder 클래스로 변환이 가능하며, 입력값으로 2차원 데이터가 필요하다는 것과 변환값이 희소행렬(Sparse Matrix) 형태이므로 이를 다시 toarray() 메서드를 이용해 밀집행렬(Dense Matrix)로 변환해야 한다는 주의점이 있다.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
items = ['TV', '냉장고','전자레인지','컴퓨터','선풍기','선풍기','믹서','믹서']
# 2차원 ndarray로 변환
items = np.array(items).reshape(-1, 1)
# 원 핫 인코딩을 적용
onehot_encoder = OneHotEncoder()
onehot_encoder.fit(items)
onehot_labels = onehot_encoder.transform(items)
# OneHotEncoder로 변환한 결과는 희소행렬이므로 toarray()를 이용해 밀집 행렬로 변환
print('One-Hot Encoding Data')
print(onehot_labels.toarray())
print('One-Hot Encoding 데이터 차원')
print(onehot_labels.shape)
# One-Hot Encoding Data
# [[1. 0. 0. 0. 0. 0.]
# [0. 1. 0. 0. 0. 0.]
# [0. 0. 0. 0. 1. 0.]
# [0. 0. 0. 0. 0. 1.]
# [0. 0. 0. 1. 0. 0.]
# [0. 0. 0. 1. 0. 0.]
# [0. 0. 1. 0. 0. 0.]
# [0. 0. 1. 0. 0. 0.]]
# One-Hot Encoding 데이터 차원
# (8, 6)8개의 레코드와 1개의 칼럼을 가진 원본데이터가 8개의 레코드와 6개의 칼럼을 가진 데이터로 변환되었다. 첫번째 칼럼이 TV, 두번째 칼럼이 냉장고 로 items에 넣어준 순서를 따라 칼럼의 순서가 되었다.
데이터의 두 번째 레코드인 냉장고를 확인하면, 변환된 데이터의 두 번째 레코드에서 냉장고에 해당하는 칼럼만 1 값으로 나머지 칼럼은 0 값으로 변환된것을 확인할 수 있다.
pandas one-hot
판다스에서는 get_dummis() 를 사용하여 더욱 쉽게 변환할 수 있다.
import pandas as pd
df = pd.DataFrame({'items' : ['TV', '냉장고','전자레인지','컴퓨터','선풍기','선풍기','믹서','믹서']})
pd.get_dummies(df)피처 스케일링과 정규화
변수는 자신만의 값 범위를 가질 수 있지만 이렇게 제각각인 범위는 값에 따라 영향력이 달라지기 때문에 알고리즘에 치명적인 영향을 줄 수 있다. 따라서 서로 다른 변수의 값 범위를 일정한 수준으로 맞추는 작업이 필요하고 이를 feature scaling이라고 한다. 대표적인 방법으로는 표준화(Standardizaion)와 정규화(Normalizaion)가 있다.
혼선을 방지하기 위해 일반적인 의미의 표준화와 정규화를 피처 스케일링으로 통칭하고, 선형대수 개념의 정규화를 벡터 정규화로 지칭
사이킷런에는 대표적인 피처 스케일링 클래스로 StandardScaler와 MinMaxScaler 가 있다.
표준화
데이터의 피처 각각의 평균이 0이고 분산이 1인 가우시안 정규분포를 가진 값으로 변환하는 것을 의미한다.
def standardize(x) :
result = (x - x.mean()) / x.std()
return result
iris_df.apply(standardize)StandardScaler
표준화를 지원하는 클래스. 개별 피처를 평균이 0이고 분산이 1인 값으로 변환해준다. 특히 사이킷런에서 구현한 RBF 커널을 이용하는 서포트 벡터머신(Support Vector Machine) 이나 선형회귀(Linear Regression), 로지스틱 회귀(Logistic Regression) 은 데이터가 가우시안 분포를 가지고 있다고 가정하고 구현되었기 때문에 사전에 표준화를 적용하는 것은 예측 성능 향상에 중요한 요소가 될 수 있다.
from sklearn.preprocessing import StandardScaler
# 객체 생성
scaler = StandardScaler()
# StandardScaler 로 데이터 셋 변환
iris_scaled = scaler.fit_transform(iris_df)
# transform() 시 스케일 변환된 데이터 셋이 Numpy ndarray 로 반환되어 이를 DF형으로 변환
iris_df_scaled = pd.DataFrame(data = iris_scaled, columns = iris.feature_names)
# print()
# print
print('feature 들의 평균값: ', iris_df_scaled.mean())
print()
print('feature 들의 분산값: ', iris_df_scaled.var())
# feature 들의 평균값: sepal length (cm) -1.690315e-15
# sepal width (cm) -1.842970e-15
# petal length (cm) -1.698641e-15
# petal width (cm) -1.409243e-15
# dtype: float64
# feature 들의 분산값: sepal length (cm) 1.006711
# sepal width (cm) 1.006711
# petal length (cm) 1.006711
# petal width (cm) 1.006711
# dtype: float64정규화(Normalizaion)
일반적으로 서로 다른 피처의 크기를 통일하기 위해 크기를 변환해주는 개념이다. 개별 데이터의 크기를 모두 0~1 사이의 값으로, 크기를 모두 동일한 단위로 변경하는 것이다.
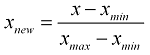
def min_max(x) :
result = (x - x.min()) / (x.max() - x.min())
return result
iris_df.apply(min_max)
# 혹은
iris_df.apply(lambda x:(x - x.min()) / (x.max() - x.min()))MinMaxScaler
데이터 값을 0과 1사이의 범위값으로 변환(음수값이 있다면 -1에서 1값으로 변환)
from sklearn.preprocessing import MinMaxScaler
# 객체 생성
scaler = MinMaxScaler()
# MinMaxScaler 로 데이터 셋 변환
iris_scaled = scaler.fit_transform(iris_df)
# transform() 시 스케일 변환된 데이터 셋이 Numpy ndarray 로 반환되어 이를 DF형으로 변환
iris_df_scaled = pd.DataFrame(data = iris_scaled, columns = iris.feature_names)
# print
print('feature 들의 최소값: ', iris_df_scaled.min())
print()
print('feature 들의 최대값: ', iris_df_scaled.max())
# feature 들의 최소값: sepal length (cm) 0.0
# sepal width (cm) 0.0
# petal length (cm) 0.0
# petal width (cm) 0.0
# dtype: float64
# feature 들의 최대값: sepal length (cm) 1.0
# sepal width (cm) 1.0
# petal length (cm) 1.0
# petal width (cm) 1.0
# dtype: float64train / test data의 스케일링 변환 시 유의점
Scaler 객체 이용해 데이터 스케일링 변환 시 fit(), transform(), fit_transform() 메소드를 이용한다.
fit() : 데이터 변환을 위한 기준 정보 설정(예: 데이터셋의 최대/최소값 설정 등)
transform() : 설정된 정보를 이용해 데이터 변환
fit_transform() : 두 메소드를 한 번에 적용하는 학습 데이터로 fit()이 적용된 스케일링 기준 정보를 그대로 테스트 데이터에 적용해야 함
머신러닝 모델은 학습 데이터를 기반으로 학습되기 때문에 반드시 test data는 train data의 스케일링 기준에 따라야 하기 때문에, test data에 다시 fit을 적용해서는 안된다. train data로 이미 fit()이 적용된 Scaler 객체를 이용하여 transform()으로 변환해야 한다.
∴
1. 가능하다면 전체 데이터의 스케일링 변환을 적용한 뒤에 train과 test 데이터로 분리
2. 그것이 여의치 않다면 test data 변환시에는 fit() 이나 fit_transform()을 적용하지 않고, 학습데이터로 이미 fit()된 Scaler 객체를 이용하여 transform() 변환해야한다.
타이타닉 생존자 예측(1)
캐글에서 제공하는 타이타닉 탑승자 데이터를 기반으로 생존자 예측 수행. matplotlib과 seaborn을 사용해 시각화도 같이 진행하며 데이터 분석
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
titianic_df = pd.read_csv('titanic_train.csv')
titianic_df[:3]
PassengerId : 탑승자 데이터 일련번호
suvived : 생존 여부(0=사망/1=생존)
Pclass : 티켓의 선실 등급(1=일등석/2=이등석/3=삼등석)
sex : 탑승자 성별
name : 탑승자 이름
Age : 탑승자 나이
sibsp : 같이 탑승한 형제자매 또는 배우자 인원수
parch : 같이 탑승한 부모님 또는 어린이 인원수
ticket : 티켓번호
fare : 요금
cabin : 선실 번호
embarked : 중간 정착항구(C=Cherbourg/Q=Queenstown/S=Southampton)
titianic_df.info()
>
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KBRangeIndex : 전체 로우수
Data columns (total 12 columns) : 칼럼 수 12개
판다스에서의 object Type은 string 타입으로 봐도 무방
titianic_df.isna().sum()
>
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64사이킷런 머신러닝 알고리즘은 Null 값이 있으면 안되기 때문에 확인해보니, Age와 Cabin, Embarked에 결손값이 있는 것이 확인 되었다.
# Age의 Null 값은 평균값으로
titianic_df['Age'].fillna(titianic_df['Age'].mean(), inplace = True)
# 나머지 Null 값은 'N'으로 채우기
titianic_df['Cabin'].fillna('N', inplace = True)
titianic_df['Embarked'].fillna('N', inplace = True)
titianic_df.isnull().sum().sum()
# 0Sex 보다 gender 표현을 많이 사용해서 그런가 컬럼이름을 바꿔주고 싶었다.
titianic_df = titianic_df.rename(columns = {'Sex' : 'Gender'})
titianic_df특이점이 없는지 값 분포를 살펴보기로 한다
print('gender 분포 : \n', titianic_df['Gender'].value_counts())
print()
print('Cabin 값 분포 : \n', titianic_df['Cabin'].value_counts())
print()
print('Embarked 값 분포 : \n', titianic_df['Embarked'].value_counts())
>
gender 분포 :
male 577
female 314
Name: Gender, dtype: int64
Cabin 값 분포 :
N 687
C23 C25 C27 4
G6 4
B96 B98 4
C22 C26 3
...
E34 1
C7 1
C54 1
E36 1
C148 1
Name: Cabin, Length: 148, dtype: int64
Embarked 값 분포 :
S 644
C 168
Q 77
N 2
Name: Embarked, dtype: int64isna()로 확인했을 때도 그랬지만 Cabin(선실)의 경우 N이 너무 많다. 무엇보다 C23 C25 C27 값과 같이 여러 선실이 한꺼번에 표기된 이상한경우가(...) 꽤 나왔기 때문에 등급을 나타내는 앞 문자만 추출하기로 한다.
titianic_df['Cabin'] = titianic_df['Cabin'].str[:1]
print(titianic_df['Cabin'][:3])
>
0 N
1 C
2 N
Name: Cabin, dtype: object데이터 탐색
- 어떤 유형의 승객의 생존확률이 더 높았는가?
1-1
성별에 따른 생존확률
titianic_df.groupby(['Gender', 'Survived'])['Survived'].count()
# Gender Survived
# female 0 81
# 1 233
# male 0 468
# 1 109
# Name: Survived, dtype: int64상대적으로 여성의 생존이 더 많았음을 확인할 수 있었는데, 그래프로 시각화하여 한눈에 비교해보겠다.
sns.barplot(titianic_df, x='Gender', y='Survived')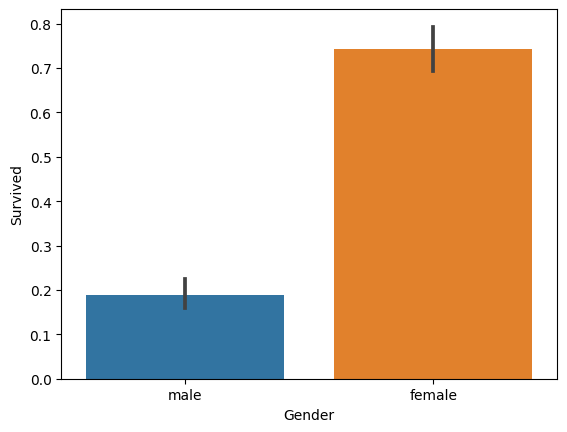
여기에 부를 대략적으로 예상해볼 수 있는 객실 등급 조건을 추가하여 생존확률을 시각화하면
sns.barplot(titianic_df, x='Pclass', y='Survived', hue='Gender')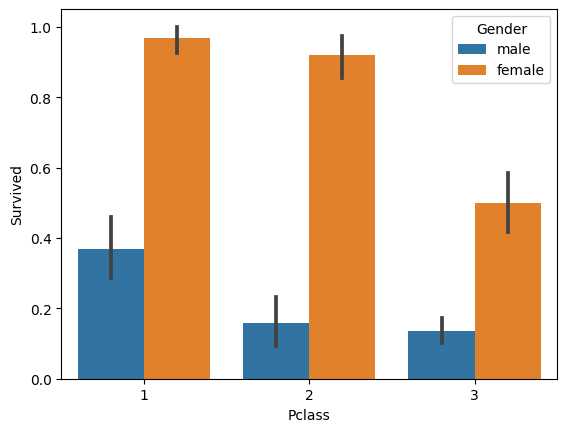
1. 대체적으로 여성의 생존률은 높았던 반면, 남성의 생존률은 낮다.
2. 1, 2등급 선실의 여성 생존률은 크게 차이가 나지 않지만 3등급 선실의 경우 훅 떨어졌다.
3. 남성의 경우 그나마 1등급 선실의 생존확률이 높다.
1-2
나이에 따른 생존 확률
값의 종류가 굉장히 세세하게 분포되어있기 때문에 간격을 정해준 뒤 확인해본다.
# 입력된 age에 따라 구분값을 반환하는 함수 작성
def get_category(age) :
cat = ''
if age <= -1 : cat = 'Unknown'
elif age <= 5 : cat = 'Baby'
elif age <= 12 : cat = 'Child'
elif age <= 18 : cat = 'Tennager'
elif age <= 25 : cat = 'Student'
elif age <= 35 : cat = 'Young Adult'
elif age <= 60 : cat = 'Adult'
return cat그래프 그리기
plt.figure(figsize = (10, 6))
group_names = ['Unknown', 'Baby', 'Child', 'Tennager', 'Student', 'Young Adult', 'Adult', 'Elderly']
titianic_df['Age_cat'] = titianic_df['Age'].apply(lambda x : get_category(x))
sns.barplot(x = 'Age_cat', y = 'Survived', hue = 'Gender', data = titianic_df, order = group_names)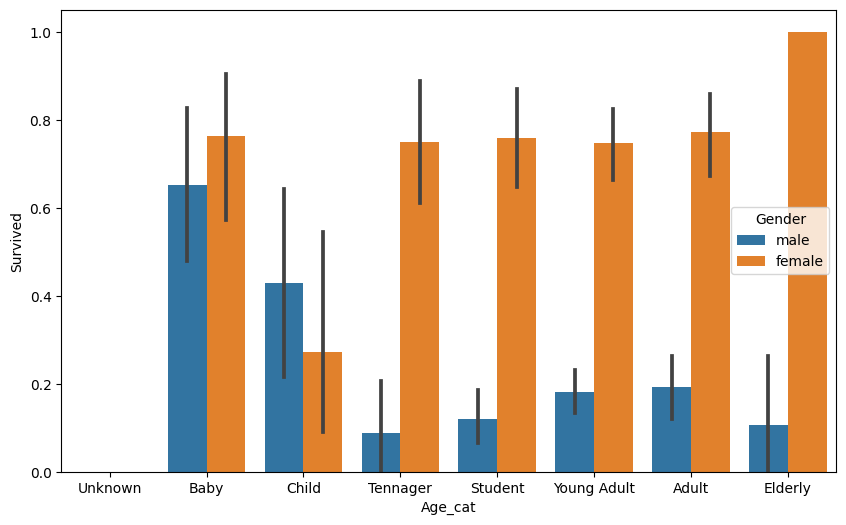
- 여성의 경우 Child를 제외한 다른 연령대들은 고르게 생존률이 높다.
- 여성 Elderly의 경우 다른 연령대보다도 높다.
- 남성의 경우 Baby의 경우가 가장 높고 그 다음은 Child 이외의 연령대들은 고르게 낮은 모습 확인.
# 사용해준 'Age_cat' 칼럼은 삭제해준다
titianic_df.drop('Age_cat', axis=1, inplace=True)문자열 카테고리를 LabelEncoder 클래스를 사용하여 레이블 인코딩을 적용해 숫자형 카테고리로 변환한다.
from sklearn.preprocessing import LabelEncoder
def encode_features(dataDF) :
# 변환해줄 칼럼 명
features = ['Cabin', 'Gender', 'Embarked']
for feature in features :
le = LabelEncoder()
le = le.fit(dataDF[feature])
dataDF[feature] = le.transform(dataDF[feature])
return dataDF
titianic_df = encode_features(titianic_df)
titianic_df[:3]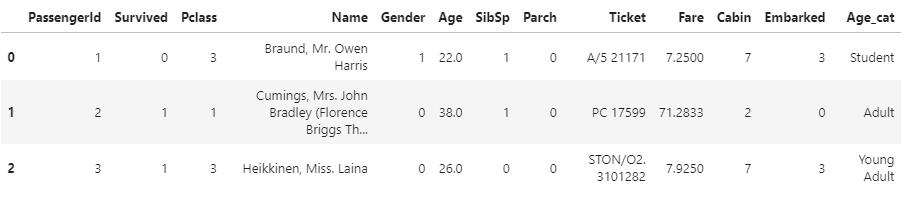
# for문을 돌리지 않고 하나하나 지정해줘도 괜찮다
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
titianic_df['Cabin'] = encoder.fit_transform(titanic['Cabin']).tolist()
titianic_df['Gender'] = encoder.fit_transform(titanic['Gender']).tolist()
titianic_df['Embarked'] = encoder.fit_transform(titanic['Embarked']).tolist()