복습문제
# IQR의 범위
IQR = 75% - 25%
IQR = 3/4 - 1/4
# 이상치의 범위
- Q_75 + (1.5 * IQR) < 정상범주 < Q_25 - (1.5 * IQR)
- 정상범주를 벗어난 값
# 언더 샘플링
# 오버 샘플링
언더샘플링 - 많은 데이터를 적은 데이터 쪽에 맞춤
오버샘플링 - 적은 데이터를 많은 데이터의 수에 맞춤
# 여러 알고리즘을 사용하여 예측 결과를 만들고
# 그 예측 결과들을 모아 다시 학습하여 최종 예측 결과물을 도출하는 앙상블 기법
스태킹
# SMOTE 기법은 정밀도 지표보다 재현율 지표를 높일 때 더 효율적이다
x
# mpg 데이터를 불러오세요
mpg = pydataset.data('mpg')
mpg
# 'fl'에서 값이 적은 edc를 제거해주세요
a=['e','d','c']
mpg = mpg[~mpg['fl'].isin(a)]
mpg['fl'].value_counts()
# 'cty'를 표준화해주세요
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit_transform(mpg['cty'].values.reshape(-1,1))
# [출제자 답변]
scaler.fit_transform(mpg[['cty']].values)
#위키북스의 '파이썬 머신러닝 완벅 가이드' 개정 2판으로 공부하고 있습니다. 실습 과정과 이해에 따라 내용의 누락 및 코드의 변형이 있을 수 있습니다.
회귀(regression)
데이터 값이 평균과 같은 일정한 값으로 돌아가려는 경향을 이용한 통계적 기법이며, 여러 개의 독립변수와 한 개의 종속변수 간 상관관계를 모델링하는 기법을 통칭한다.

예를 들어 위와 같은 선형회귀 식을 예로 들면 Y는 종속변수 즉, 아파트 가격을 뜻한다.
그리고 X1, X2, X3 ... Xn은 방 개수, 방 크기, 주변 학군등의 독립변수를 의미
W1, W2 ... Wn은 이 독립변수 값에 영향을 미치는 회귀계수독립변수가 한개라면 단일회귀, 여러개라면 다중회귀이며 독립 변수의 결합방식이 선형이나 비선형이냐에 따라 선형회귀와 비선형 회귀로 분류됩니다.
| 독립변수 개수 | 회귀 계수의 결합 |
|---|---|
| 1개 : 단일 회귀 | 선형 : 선형 회귀 |
| 여러 개 : 다중회귀 | 비선형 : 비선형 회귀 |
지도학습의 양대 산맥인 분류와 회귀의 가장 큰 차이는 예측값의 결과인데, 분류는 예측값이 카테고리와 같은 이산형 클래스 값이고 회귀는 연속되는 숫자값으로 나온다는 점이다.
[ 대표적인 선형회귀 모델 ]
- 일반 선형 회귀 : 예측값과 실제값의 RSS(Residual Sum of Suqares)를 최소화할 수 있도록 회귀 계수를 최소화하며, 규제(Regularization)을 사용하지 않는 모델
- 릿지(Ridge) : 선형회귀에 L2 규제를 추가한 회귀 모델, 규제를 추가함으로 상대적으로 큰 회귀 계수 값의 예측 영향도 감소
- 라쏘(Lasso) : 선형회귀에 L1 규제를 추가한 모델. 예측 영향력이 작은 회귀 계수를 0으로 만들어 회귀 예측 시 피처가 선택되지 않게 한다 → 피처 선택(selection)기능으로도 불린다.
- 엘라스틱넷 : 선형회귀에 L1과 L2 규제를 결합한 모델. 주로 피처가 많은 데이터 셋에 적용되며 L1규제로 피처의 개수를 줄이면서 L2 규제로 계수 값의 크기를 조정한다
- 로지스틱 회귀 : 회귀라는 이름이지만 사실 분류에 사용되는 선형 모델. 매우 강력한 분류 알고리즘으로 일반적으로 이진 분류 뿐 아니라 희소 영역의 분류(ex. 텍스트 분류)와 같은 영역에서 뛰어난 예측 성능을 보인다.
회귀에 대한 이해
단순 선형 회귀는 독립변수도 하나, 종속변수도 하나인 경우로 주택가격이 주택의 크기로만 결정 된다고 할 때를 예로 들 수 있다.
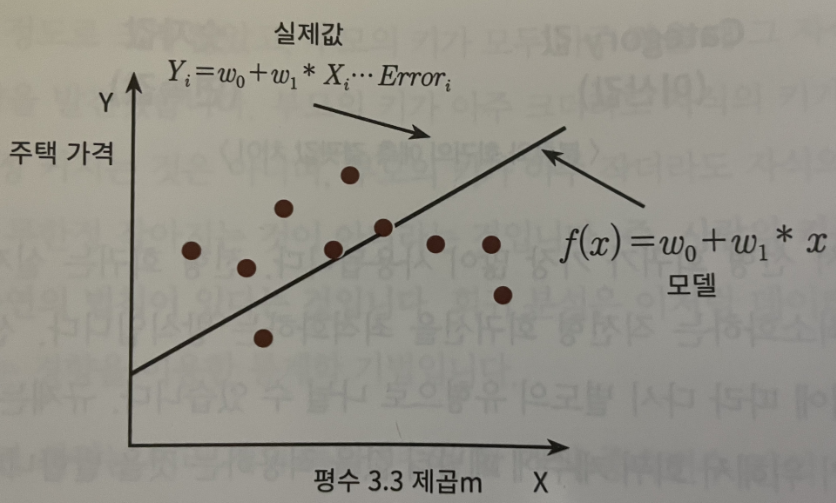
그리고 회귀 모델을 이러한 Ŷ = w0+w1*X 와 같은 1차 함수로 모델링했다면 실제 주택 가격은 이러한 1차 함수 값에서 실제 값 만큼의 오류값을 뺀(혹은 더한)값이 된다(w0+w1*X+오류값)
이렇게 실제 값과 회귀 모델의 차이에 따른 오류값을 남은 오류, 즉 잔차라 부르며, 최적의 회귀 모델을 만든다는 것은 바로 전체 데이터의 잔차(오류 값) 합이 최소가 되는 모델을 만든다는 의미이기도 하다. 동시에 오류 값 합이 최소가 될 수 있는 최적의 회귀 계수를 찾는 다는 의미도 된다.
잔차는 + 혹은 - 값을 모두 가질 수 있기 때문에 단순히 전체 데이터에 대한 오류를 계산하기 위하여 단순히 합을 한다면 오류의 값이 크게 줄어들 수 있다. 따라서 보통 절대값을 취하여 더하는 방식인 MAE(Mean Absolute Error), 오류 값의 제곱을 구해서 더하는 방식(Error² = RSS)인 RSS(Residual Sum of Square) 방식을 사용한다.
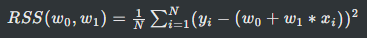
위처럼 RSS는 변수가 W0 w1인 식으로 표현할 수 있으며, 이 RSS를 최소로 하는 회귀계수(W0 W1) 학습을 통해서 찾는 것이 머신러닝 기반 회귀의 핵심 사항이다.
회귀에서 RSS는 비용(Cost)이며 w변수(회귀 계수)로 구성되는 RSS를 비용함수라 한다. 머신러닝에서 회귀 알고리즘은 데이터를 계속 학습하면서 이 비용함수(=손실함수=loss function)가 반환하는 값(=오류값)을 지속해서 감소시키고 최종적으로는 더 이상 감소하지 않는 최소의 오류값을 구하는 것이다.
비용 최소화 - 경사하강법
어떻게 하면 오류가 작아지는 방향으로 회귀계수를 보정할 수 있을까 하며 나온 방법이다. 고차원 방정식에 대한 문제를 해결해 주면서 비용함수를 최소화 할 수 있는 방안을 직관적으로 제공하는 방식. 마치 어두운 밤 산 정상에서 아래로 내려갈때, 현 위치보다 낮은 위치로 이동하다보면 지상에 도착하는 것과 마찬가지로 회귀계수를 보정한다.
결론만 보자면, 오차함수의 1차 미분값의 기울기가 최소인 점을 찾으면 된다. 아래에서 자세히 알아보겠다.
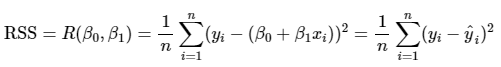
RSS는 회귀계수(위 그림에서는 β0, β1)의 2차 함수로서 포물선 형태를 가질 것이며, 이 형태의 2차함수 최저점은 2차 함수의 미분값인 1차 함수의 기울기가 가장 최소일 때다. 경사하강법은 최초의 β에서부터 미분을 적용한 뒤 이 미분값이 감소하는 방향으로 β를 업데이트 한다.
- 만약 최초의 β에서 기울기(미분값)이 양수라면 포물선을 고려하였을 때 최초의 β는 2차함수 최저점의 우측에 있을 것이다
→ 따라서 최초 β에서 왼쪽으로 이동하면 2차함수 최저점에 조금 더 가까워질것이다
→ 즉 미분값의 부호 반대방향으로 이동하면서 점차 미분값을 감소시킨다
→ 더이상 감소하지 않는 지점을 비용이 최소가 되는 지점으로 간주하고 그때 β를 반환한다.
경사 하강법 종류
배치 경사 하강법(Batch Gradient Descent:BGD)
- 전체 학습 데이터를 하나의 배치로 묶어 학습시키는 방법으로 수행 시간이 오래 걸리고 많은 메모리가 필요하다.
- Global Optima로 수렴이 안정적이지만 Local Optima에 수렴될 경우 탈출하기 어려울 수도 있다.
local optimum
아직 최종목표(비용함수 최소값(=Global Optima)에 도달하지 않았음에도 불구하고,
특정 지점에 들어가니 '진행시 loss가 증가하기 때문에' w를 멈추는 현상을
보이는 지점(Local Local 이라고도 한다)
Optimization(최적화)을 잘못한 경우 로컬옵티마에 빠지기 쉽다고 함- GPU를 활용한 병렬처리에 유리하다
확률적 경사 하강법(Stochastic Gradient Descent:SGD)
- 전체 학습 데이터 중 랜덤하게 선택된 하나의 데이터를 하나의 배치로 학습한다.
- 하나의 데이터만 사용하므로 Shooting이 발생하여 Local Optima에 빠질 위험은 적어지지만 Global Optima로 수렴이 어려울 수 있다.
- 하나의 데이터만 사용하므로 GPU 전부 활용이 불가하다
미니 배치 확률적 경사 하강법(Mini-Batch Stochastic Gradient Descent:MSGD)
- BGD와 SGD의 절충안으로 전체 데이터를 Batch_size만큼 나누어 Mini-Batch를 구성 후 학습한다.
- BGD보다는 local optima에 빠질 리스크가 적고 메모리도 적게 사용한다
- SGD보다는 GPU 성능을 활용한 병렬 처리가 가능하여 속도면에서 유리
구현하며 이해하기
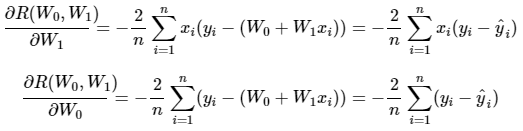
yi = 실제값 i
ŷi = 예측값i
위 수식은 R(w)를 W1, W0로 편미분한 결과이다.
앞에서 언급한 비용함수 RSS(W0, W1)을 편의상 R(w)로 지징한다- 먼저 임의의 초기 W0, W1 값을 설정한 후 그 값에 대한 편미분이 구해지면 다음 W0, W1는 해당 편미분 값에
-를 곱하여 업데이트 한다.
※ 다만 이 편미분 값이 너무 클 수도 있기 때문에 보정계수 n을 곱해주는데 이를 학습률이라 함
즉, 새로운 W0, W1 값은 이전 W0W1 값 - 학습률 * 편미분 값이 된다. 새로운 값으로 다시 비용을 계산하다가 비용이 감소하면 계속 업데이트를 진행하고, 더이상 진전이 없으면(감소하지 않으면) 반복을 중지하고 그 때의 W0, W1를 반환한다.
미니배치 구현해보기
간단한 회귀 식인 y=4X+6을 근사하기 위해 100개의 임의(랜덤)데이터 셋을 만들고, 여기에 경사 하강법을 이용하여 회귀계수(W0, W1)을 도출 할 것이다.
데이터 셋 만들기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
np.random.seed(0)
x = 2*np.random.rand(100,1)
# y = 4x + 6을 근사
# w1=4, w0은 6
y = 6 + 4*x + np.random.rand(100,1)산점도로 시각화
plt.scatter(x, y)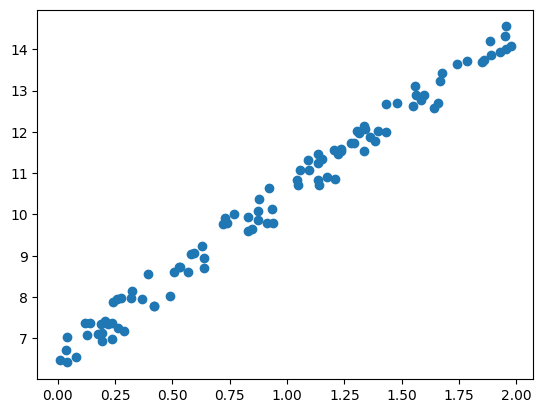
데이터가 y = 4x + 6 을 중심으로 무작위로 퍼저 있는 모습이다.
선형모델을 학습시켜 기울기 파라미터를 확인해보자. 기울기 파라미터는 가중치(weight) 또는 계수(coefficient)라고 하며 객체의 coef_ 속성에 저장되어 있다.
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=True)
lr = model.fit(x, y)array([[3.96827553]])편향(offset)또는 절편(intercept) 파라미터 값은 intercept_ 속성에 저장되어 있다.
lr.intercept_array([6.55808002])비용을 구하는 사용자 함수 정의
def get_cost(y, y_hat):
n = len(y)
cost = np.sum( np.square(y - y_hat) ) / n
return cost미니 배치를 사용하는 사용자 함수 정의
# Mini-Batch Stochastic Gradient Descent: MSGD
def mini_stochastic_gradient_descent(w1, w0, X, y, learning_rate = 0.01, iters = 10000, batch_size=10):
n = batch_size
for i in range(iters):
# batch_size만큼 랜덤으로 데이터 추출
np.random.seed(i)
stochastic_random_index = np.random.permutation(X.shape[0]) # permutation은 정수를 arange 후 셔플
sample_X = X[ stochastic_random_index[0:batch_size] ]
sample_y = y[ stochastic_random_index[0:batch_size] ]
# 예측값 nx1
y_hat = w0 + w1*sample_X
# 학습률 * 편미분
w1_update = learning_rate * -(2/n) * sample_X.T @ (sample_y - y_hat)
w0_update = learning_rate * -(2/n) * np.sum(sample_y - y_hat)
# 파라미터 업데이트
w1 = w1 - w1_update
w0 = w0 - w0_update
return w1, w0배치사이즈를 10으로 잡고 실행해보기
w1, w0 = mini_stochastic_gradient_descent(0, 0, X, y, iters=1000, batch_size=10)
y_hat = w0 + w1[0,0]*X
cost = get_cost(y, y_hat)
print(f"w1: {w1[0,0]:.3f}, w0: {b0:.3f}")
print(f"Mini Stochastic Gradient Descent Total Cost: {cost:.4f}")w1: 4.031, w0: 6.486
Mini Stochastic Gradient Descent Total Cost: 0.0777회귀 평가 지표
회귀의 평가를 위한 지표는 실제 값과 회귀 예측값의 차이 값을 기반으로 한 지표가 중심이다. 실제 값과 예측값의 차이를 그냥 더한다면 음수와 양수가 섞여있기 때문에 오류가 상쇄되고 정확한 지표가 될 수 없다. 이 때문에 절대값으로 변환한 뒤 평균을 구하거나 제곱 혹은 제곱 후 다시 루트를 씌운 평균값을 구한다.
- MAE : 실제값과 예측값의 차이를 절대값으로 변환해 평균 값을 구한다
- MSE : 실제값과 예측값이 차이를 제곱한 뒤 평균한 값
- RMSE : MSE 값은 오차를 제곱하기 때문에 실제 오차모다 더 커지는 특성이 있다. 그렇기 때문에 MSE에 루트를 씌운 것이 RMSE이다.
- R² : 분산 기반으로 예측 성능을 평가한다. 실제 값의 분산 대비 예측 값의 분산 비율을 지표로 하여 1에 가까운 값일 수록 예측 정확도가 높다고 본다.
[MSE - MSE]
MSE는 오차의 제곱을 더하기 때문에 오차값이 커지는 이상치 데이터에MAE보다 크게 반응을 하게 된다MAE를 사용하는 것이MSE보다 이상치 데이터에 좀 더 좋은 결과를 만들 수는 있지만 작은 loss value의 변화에도 큰 기울기 값을 가지게 된다.
보스턴 주택 가격 예측
사이킷 런의 LinearRegression을 이용하여 보스턴 주택 가격을 예측해보자.
LinearRegression 클래스는 예측 값과 실제 값의 RSS를 최소화해 OLS(Ordinary Least Squares) 추정 방식으로 구현한 클래스이다. fit() 메서드로 X, y 배열을 입력받으면 회귀계수인 W 를 coef_ 속성에 저장한다.
데이터 로드
import warnings
warnings.filterwarnings('ignore')
from scipy import stats
from sklearn.datasets import load_boston
# 데이터 셋 로드
boston = load_boston()
# boston 데이터 셋 DataFrame 변환
boston_df = pd.DataFrame(boston.data, columns = boston.feature_names)
boston_df
주택 가격 컬럼에 추가
# boston 데이터 셋의 target 은 주택 가격이다. 이를 price 칼럼으로 DataFrame에 추가
boston_df['PRICE'] = boston.target
print(f'Boston Dataset 크기 : {boston_df.shape}')
boston_df[:3]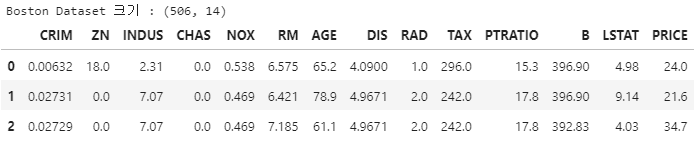
데이터 살펴보기
boston_df.describe()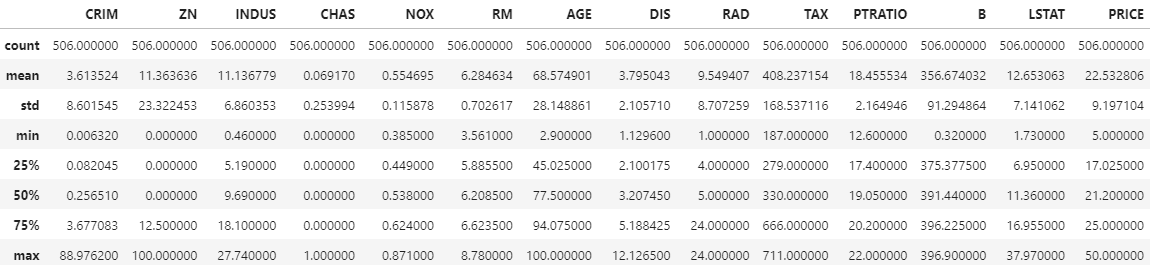
'price' 컬럼이 생긴것을 확인하였고, 크게 튀는 값은 안보인다. 각 컬럼이 회귀 결과에 미치는 영향이 어느정도인지 그래프로 시각화 하여 본다.
import seaborn as sns
# 2개의 행과 4개의 열을 가진 subplots를 이용
# axs는 4x2의 ax를 가짐
fig, axs = plt.subplots(figsize=(16, 8), ncols=4, nrows=2)
lm_features = ['RM', 'ZN', 'INDUS', 'NOX', 'AGE', 'PTRATIO', 'LSTAT', 'RAD']
for i, feature in enumerate(lm_features) :
row = int(i/4)
col = i%4
# seaborn의 regplot를 이용하여 산점도와 선형회귀 직선을 함께 표현
sns.regplot(x=feature, y='PRICE', data=boston_df, ax=axs[row][col])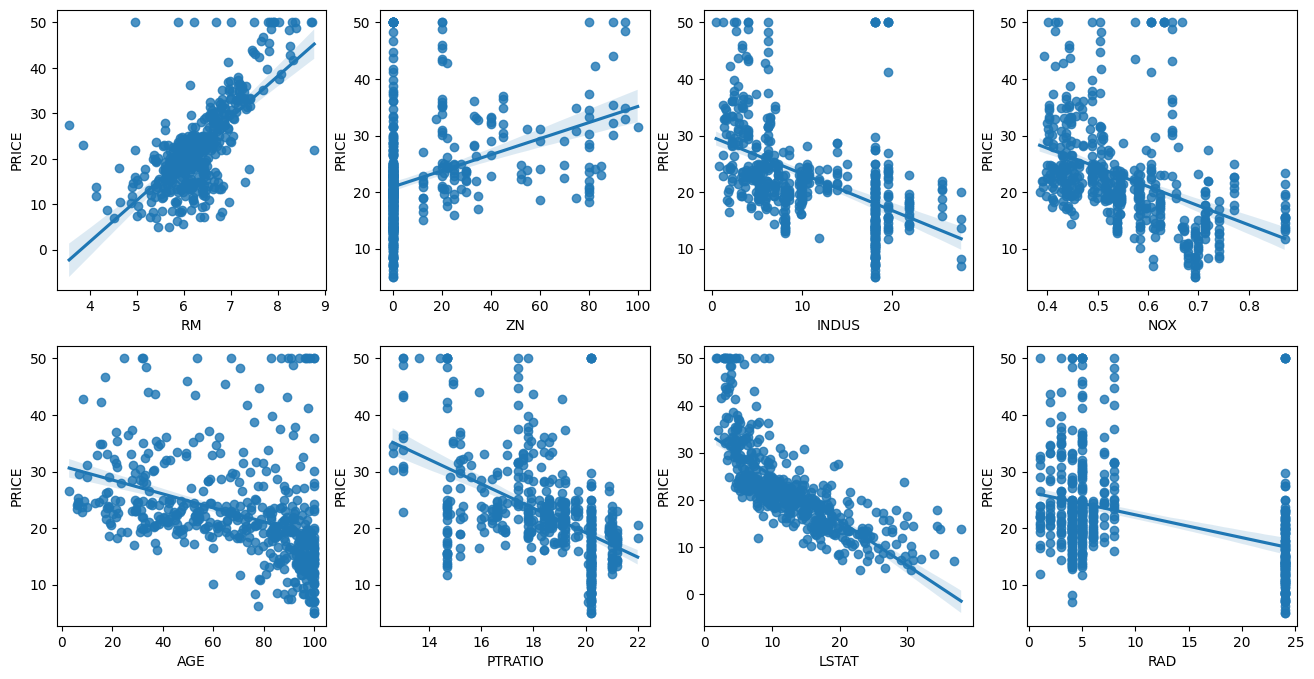
matplotlib.subplots()은 여러개의 그래프를 한 번에 표현하기 위해 자주 사용된다. 인자로 입력되는 ncols는 열 방향으로 위치할 그래프의 개수이며 nrows는 행 방향으로 위치할 그래프의 갯수이다.
시각화한 결과 다른 column들 보다 'RM'과 'LSTAT'의 'PRICE'영향도가 가장 두드러지게 나타나고 있음을 확인 할수 있다(선형회귀 직선과 모양이 비슷하게 분포 되어있는 모습)
→ 방의 크기(RM)가 클수록 가격도 증가, LSTAT(하위 계층의 비율)은 적을수록 PRICE가 증가하니, 음의 방향으로 선형성이 보이는 모습이다.
LinearRegression 클래스를 이용해 회귀 모델 만들기
metrics 모듈의 mean_squared_error()와 r2_score() API를 이용하여 MSE와 R2 SCORE를 측정해보자
# LinearRegression 클래스를 이용해 회귀 모델 만들기
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# 데이터 x, y로 분리하기
y_target = boston_df['PRICE']
X_data = boston_df.drop(['PRICE'], axis=1, inplace=False)
# train_test_split으로 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X_data, y_target, test_size=0.3, random_state=156)
# 선형회귀 OLS로 학습
lr = LinearRegression()
lr.fit(X_train, y_train)
# 예측
y_preds = lr.predict(X_test)
# mean_squared_error : 평균 오차 계산
mse = mean_squared_error(y_test, y_preds)
# sqrt에 넣어줌 = 평균 제곱근 오차 계산(rmse)
rmse = np.sqrt(mse)
print(f'MSE : {mse:.3f}, RMSE : {rmse:.3f}')
print(f'Variance score:{r2_score(y_test, y_pred=y_preds)}')MSE : 17.297, RMSE : 4.159
Variance score:0.757226332313895LinearRegression으로 생성한 주택 가격 모델의 intercept(절편)의 coefficients(회귀 계수) 값을 살펴보자
print(f'절편 값: {lr.intercept_}')
print(f'회귀 계수 값 : {np.round(lr.coef_,1)}')절편 값: 40.995595172164435
회귀 계수 값 : [ -0.1 0.1 0. 3. -19.8 3.4 0. -1.7 0.4 -0. -0.9 0. -0.6]회귀 계수
coeff = pd.Series(data=np.round(lr.coef_, 1), index=X_data.columns)
coeff.sort_values(ascending=False)RM 3.4
CHAS 3.0
RAD 0.4
ZN 0.1
INDUS 0.0
AGE 0.0
TAX -0.0
B 0.0
CRIM -0.1
LSTAT -0.6
PTRATIO -0.9
DIS -1.7
NOX -19.8
dtype: float64+) RMSE - mean_squared_error
- RMSE(Root Mean Squared Error)
- 표준편차와 동일하다. 특정 수치에 대한 예측의 정확도를 표현할 때, Accuracy로 판단하기에는 정확도를 올바르게 표기할 수 없어 RMSE 수치로 정확도 판단을 하고는 한다. 일반적으로 해당 수치가 '낮을수록' 정확도가 높다고 판단한다.
- 예측한 값과 실제 환경에서 관찰되는 값의 차이를 다룰 때 많이 사용하는 측도이다.
from sklearn.metrics import mean_squared_error
RMSE = mean_squared_error(y, y_pred)**0.5
#혹은
mse = mean_squared_error(y, y_pred)
RMSE = np.sqrt(mse)+) 결정계수 - r2_score
'결정계수'는 상관계수를 제곱한 값으로 보면된다. 변수간 영향을 주는 정도 또는 인과 관계의 정도를 정량화 하여 나타낸 수치이며 회귀 분석에서 사용한다. 주어진 데이터들에 기반해 만들어진 선형(linear)이 주어진 데이터들을 얼마나 잘 설명하는가에 대한 수치
r2_score은 결정계수를 나타내며 회귀 모델 성능에 대한 평가 지표이다. 회귀모델이 얼마나 '설명력'있느냐를 의미
→ 설명력은 SSR/SST 식으로 확인할 수 있는데 요약하자면 '실제 값의 분산 대비 예측값의 분산 비율'이고
→ 이는 예측모델과 실제 모델이 얼마나 강한 상관관계(Correlated)를 가지는 가 로 생각해볼 수 있다.
다항 회귀와 과(대)적합/과소적합
다항회귀는 회귀가 독립변수의 단항식이 아니라 2차, 3차 방정식과 같은 다항식으로 표현되는 것을 말한다. 비선형 회귀로 혼동하기 쉽지만, 분명히 선형회귀라는 점을 주의해야한다.
피처의 직선적관계가 아닌 복잡한 다항 관계를 모델링 할 수 있다. 다항식의 차수가 높아질 수록 더욱 복잡한 관계로 모델링이 가능하다는 것인데, 차수(degree)가 높아질 수록 Train데이터에만 잘 맞는 학습이 이루어져 정작 Test Data 환경에서는 오히려 예측 정확도가 떨어지는 현상이 발생할 수 있다(=과적합)
반면 차수가 너무 낮으면 Train 데이터에도 잘 맞지 않는 학습이 이루어 질 수 있는데 이를 과소적합이라 한다.
다항 회귀
사이킷런은 PolynomialFeatures 클래스를 통해 피처를 Polynomial(다항식) 피처로 변환한다. 해당 클래스는 입력받은 단항식 피처를 입력받은 degree 파라이터에 해당하는 다항식 피처로 변환한다.
단항식을 2차 다항값으로 변환해본다. 변환 형태는 아래와 같다 [단항식→2차 다항식]
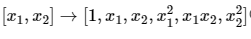
from sklearn.preprocessing import PolynomialFeatures
import numpy as np
# 다항식으로 변활할 단항식 만들기
X = np.arange(4).reshape(2,2)
print('일차 단항식 계수 피처\n', X)
# (degree=2) : 2차 다항식으로 변환하겠다.
poly = PolynomialFeatures(degree=2)
poly_ftr = poly.fit_transform(X)
print('2차 다항식으로 변환된 계수 피처\n', poly_ftr)일차 단항식 계수 피처
[[0 1]
[2 3]]
2차 다항식으로 변환된 계수 피처
[[1. 0. 1. 0. 0. 1.]
[1. 2. 3. 4. 6. 9.]]3차 다항식으로 변환할 때에도 degree부분을 변경해주면 된다. [단항식→3차 다항식]의 변환형태는 아래와 같다.
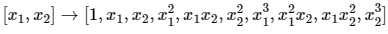
poly3 = PolynomialFeatures(degree=3)
poly_ftr_3 = poly3.fit_transform(X)
print('3차 다항식으로 변환된 계수 피처\n', poly_ftr_3)3차 다항식으로 변환된 계수 피처
[[ 1. 0. 1. 0. 0. 1. 0. 0. 0. 1.]
[ 1. 2. 3. 4. 6. 9. 8. 12. 18. 27.]]피처 변환과 선형 회귀 적용을 각각 별도로 하는 것 보다는 사이킷런의 Pipeline객체를 이용해 한 번에 다항 회귀를 구현하는 것이 코드를 더 명료하게 작성하는 방법이다.
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline
import numpy as np
def polynomial_func(X) :
y = 1 + 2*X[:,0] + 3*X[:,0]**2 + 4*X[:,1]**3
return y
# pipeline 객체로 Streamline하게 Polynomial Feature 변환과 Linear Ression연결
model = Pipeline([('poly', PolynomialFeatures(degree=3)),
('linear', LinearRegression())])
x = np.arange(4).reshape(2, 2)
y = polynomial_func(x)
model = model.fit(x, y)
print('Polynomial 절편 \n', np.round(model.named_steps.linear.intercept_, 2))
print('Polynomial 회귀 계수 \n', np.round(model.named_steps['linear'].coef_,2))Polynomial 절편
1.76
Polynomial 회귀 계수
[0. 0.18 0.18 0.36 0.54 0.72 0.72 1.08 1.62 2.34]과적합/과소적합
다항 회귀는 피처의 직선적 관계가 아닌 복잡한 다항 관계를 모델링 할 수 있다.
데이터 만들기
def true_fun(X) :
# 임의의 값으로 구성된 X값에 대해 코사인 변환 값을 반환
return np.cos(1.5*np.pi*X)
# X는 0부터 1까지 30개의 임의 값을 샘플링한 데이터
np.random.seed(0)
n_samples = 30
X = np.sort(np.random.rand(n_samples))책에서 약간의 노이즈 변동값을 y값 생성시 더하라고 되어있는데 하지 않으면 어떻게 되는 지 모습을 보려한다.
y = true_fun(X)
plt.scatter(X, y)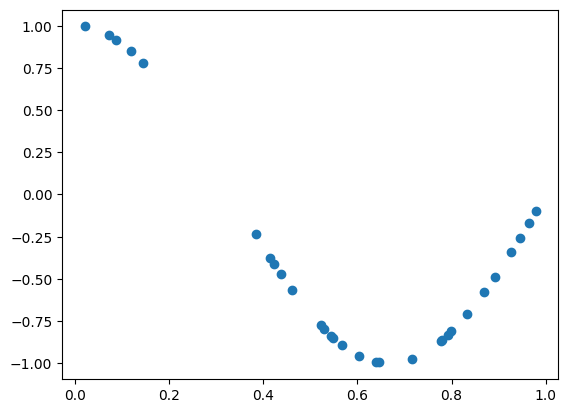
그래프가 정말 깔끔하다.
y = true_fun(X)+ np.random.randn(n_samples)*0.1
plt.scatter(X, y)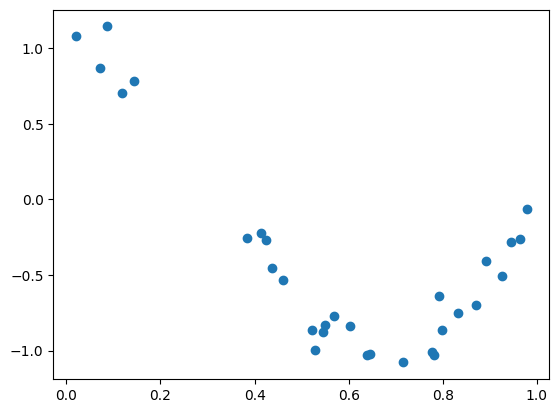
이제 생성된 데이터를 가지고 다항식으로 변환 후 예측 결과를 비교하겠다. 0부터 1까지 균일하게 구성된 100개의 테스트용 데이터 셋을 이용해 차수별 회귀 예측 곡선을 그려보자
plt.figure(figsize=(14, 5))
degrees = [1, 4, 15]
# 다항 회귀의 차수(degree)를 1, 4, 15로 각각 변화시키면서 비교한다.
for i in range(len(degrees)) :
ax = plt.subplot(1, len(degrees), i+1)
plt.setp(ax, xticks=(), yticks=())
# 개별 degree 별로 Polynomial 변환
polynomial_features = PolynomialFeatures(degree=degrees[i], include_bias=False)
linear_regression = LinearRegression()
pipeline = Pipeline([('polynomial_features', polynomial_features),
('linear_regression', linear_regression)])
pipeline.fit(X.reshape(-1, 1), y)
# 교차 검증으로 다항회귀를 평가
scores = cross_val_score(pipeline, X.reshape(-1, 1), y, scoring='neg_mean_squared_error', cv=10)
# Pipeline을 구성하는 세부 객체를 접근하는 named_steps['객체명']을 이용해 회귀계수 추출
coefficients = pipeline.named_steps['linear_regression'].coef_
print(f'\nDegree {degrees[i]} 회귀 계수는 {np.round(coefficients, 2)}')
print(f'Degree {degrees[i]}, MSE는 {-1*np.mean(scores)}')
# 테스트 데이터 셋에 회귀 예측을 수행하고 예측 곡선과 실제 곡선을 그려서 비교한다.
# 0부터 1까지 테스트 데이터 셋을 100개로 나누어 예측을 수행한다.
X_test = np.linspace(0, 1, 100)
# 예측값 곡선
plt.plot(X_test, pipeline.predict(X_test[:,np.newaxis]), label='Model')
# 실제값 곡선
plt.plot(X_test, true_fun(X_test), '-', label='True function')
plt.scatter(X, y, edgecolor='b', s=20, label='Samples')
plt.xlabel('x');
plt.ylabel('y');
plt.ylim((-2, 2));
plt.legend(loc='best')
plt.title(f'Degree {degrees[i]}\nMSE={-scores.mean():.2e}(+/- {scores.std():.2e})')
plt.show()Degree 1 회귀 계수는 [-1.49]
Degree 1, MSE는 0.40749914882743843
Degree 4 회귀 계수는 [ 2.7 -27.43 38.45 -14.59]
Degree 4, MSE는 0.00782197333136253
Degree 15 회귀 계수는 [-1.46900000e+02 3.70899000e+03 -4.16930500e+04 2.03111560e+05
1.17495890e+05 -7.23987037e+06 4.55980728e+07 -1.61271287e+08
3.76483176e+08 -6.09306953e+08 6.90821140e+08 -5.40216956e+08
2.78152767e+08 -8.49854729e+07 1.16829064e+07]
Degree 15, MSE는 341762296.3729119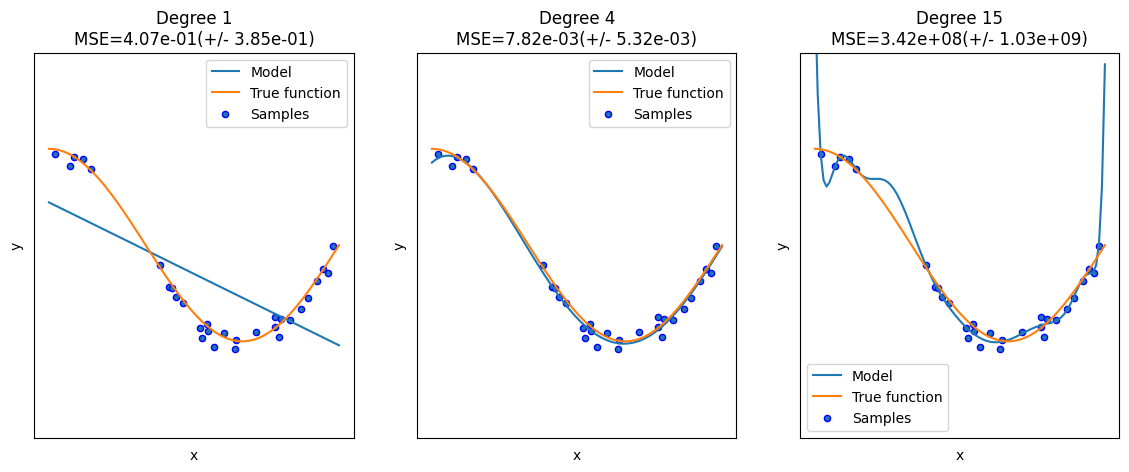
다항식 차수를 각각 [1, 4, 15]로 변경하면서 예측 결과를 비교했다.
- Degree 1 : 단순 선형 회귀로 실제 코사인 데이터를 예측하기에는 단순하여(직선) 패턴을 잘 파악하지 못한 과소적합 모델이다. MSE는 약 0.407이다.
- Degree 4 : 예측 곡선과 매우 유사하며 MSE는 약 0.007이다. 셋 중 가장 작은 값이 나왔다.
- Degree 15 : 학습 데이터에 과적합 하여 학습 데이터는 잘 예측 했지만 새로운 데이터는 잘 예측하지 못한다. MSE가 압도적으로 크게 나왔다.
편향-분산 트레이드 오프(Bias-Variance Trade Off)
편향-분산 트레이드 오프는 머신러닝이 극복해야 할 가장 중요한 이슈 중의 하나이다. 차수가 1인 모델은 매우 단순화된 모델로 지나치게 한 방향성으로 치우치는 경향이 있다. 이러한 모양의 모델은 고편향(High Variance)성을 가졌다고 표현한다.
반면 차수가 15와 같은 모델은 학습 데이터 하나하나의 특성을 반영하면서 매우 복잡한 모델이 생성되고, 지나치게 높은 변동성을 가지게 되는데 이러한 모델은 고분산(High Variance)성을 가진다고 표현한다.
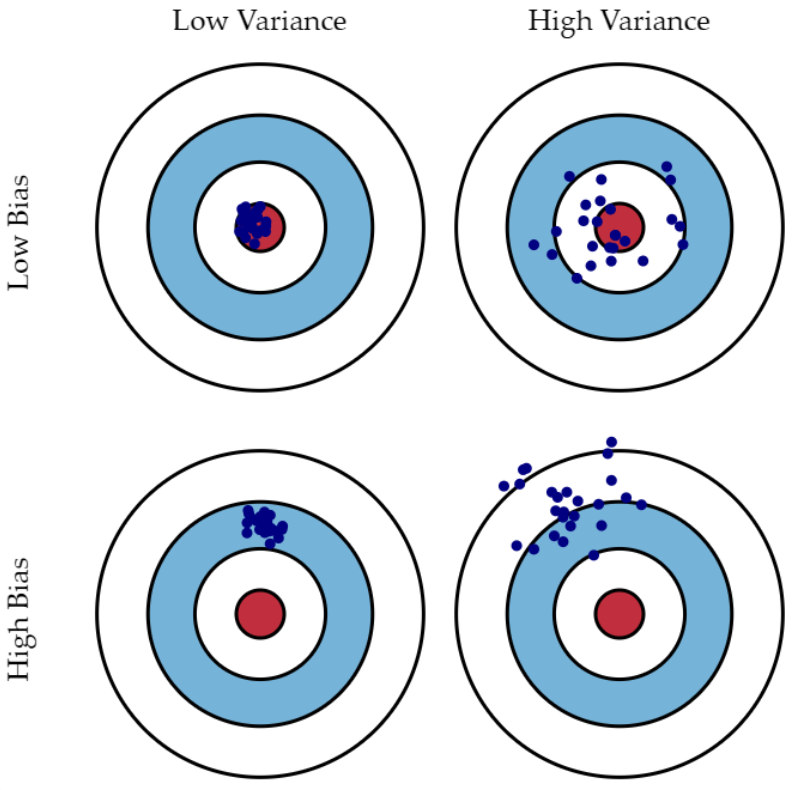
위의 양궁과녁을 보면 편향과 분산의 의미를 직관적으로 잘 표현하고 있다. Bias가 낮을 수록 정답에 가까운 결과를 내고 Variance가 낮을 수록 예측 값들의 변동성이 적어 한데 모여있는 결과를 보여준다는 것을 알 수 있다.
일반적으로 편향과 분산은 한쪽이 높으면 한쪽이 낮아지는 경향이 있다 → 편향이 높으면 분산은 낮아지고(과소적합) / 분산이 높으면 편향이 낮아진다(과적합)
∴ 무조건 한쪽을 줄인다고 해결되는 문제는 아니다. 오류를 최소화하려면 편향과 분산의 합이 최소가 되는 적당한 지점을 찾아야 한다.
규제 선형 모델
회귀 모델은 적절히 데이터에 적합하면서도 회귀 계수가 기하급수적으로 커지는 것을 제어할 수 있다면 좋다. 이전까지 선형 모델의 비용함수를 최소화하는 것(예측값과 실제값의 차이를 최소화 하는 것)만 고려했다.
→ 그 결과 학습 데이터에만 지나치게 맞고, 회귀계수가 쉽게 커지는 경향이 발생했다. 이럴경우 변동성이 오히려 심해져서 테스트 데이터 세트에서는 예측 성능이 저하되기가 쉽다.
이를 반영하기 위해 비용함수는 학습 데이터의 잔차 오류값을 최소로 하는 RSS 최소화 방법과 과적합을 방지하기 위해 회귀 계수 값이 커지지 않도록 하는 방법이 서로 균형을 이뤄야 한다.
규제 선형 모델은 선형회귀 계수에 대한 제약 조건을 추가함으로 과최적화를 막는 방법이다. 모형이 너무 과도하게 최적화되면 모형 계수의 크기도 과도하게 증가하는 경향이 나타나기 때문에, 규제 선형 모델에서 추가하는 제약 조건은 일반적으로 계수의 크기를 제한하는 방법이다.

alpha는 여기서 학습데이터 적합 정도와 회귀 계수 값의 크기를 제어하는 파라미터로 적절한 값을 설정해야 한다. alpha가 너무 작으면 결귝 (Error(W)+0)과 같아지며 없는 것과 다를게 없고, 너무 크면 a*||W||2/2 값이 너무 커지게 되기 때문에 이때는 W를 0 또는 매우 작은 값으로 수렴하게 만들어야 한다.
위와 같이 α값을 이용해 회귀 계수 값의 크기를 적절히 조절하며 과적합을 개선하는 방식을 규제(Regularization)이라 부르며 크게 L1방식과 L2방식이 있다.
- L1
W의 절대값에 대해 페널티를 부여한다.
L2규제를 적용하면 영향력이 크지 않은 회귀 계수 값을 0으로 변환
라쏘(Lasso)회귀에 적용되어 있다.
- L2
W의 제곱에 대해 페널티를 부여하는 방식
릿지(Ridge) 회귀에 적용되어 있다.릿지(Ridge) 회귀
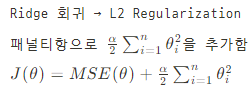
Ridge 회귀 모형에서는 가중치(회귀 계수)들의 제곱합을 최소화하는 것을 추가적인 제약 조건(L2 규제)로 한다.
사이킷런은 Ridge 클래스를 통해 구혀할 수 있으며 주요 생성 파라미터는 alpha이며, 이는 릿지 회귀의 alpha L2 규제 계수에 해당한다.
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
# alpha=10으로 설정해 릿지 회귀 수행
ridge = Ridge(alpha=10)
neg_mse_scores = cross_val_score(ridge, X_data, y_target, scoring="neg_mean_squared_error", cv=5)
rmse_scores = np.sqrt(-1*neg_mse_scores)
avg_rmse = np.mean(rmse_scores)
# (cv = 5) = 5 folds
print(f'5 folds의 개별 Negative MSE scores : {np.round(neg_mse_scores, 3)}')
print(f'5 folds의 개별 RMSE scores : {np.round(rmse_scores, 3)}')
print(f'5 folds의 평균 RMSE : {avg_rmse}')5 folds의 개별 Negative MSE scores : [-11.422 -24.294 -28.144 -74.599 -28.517]
5 folds의 개별 RMSE scores : [3.38 4.929 5.305 8.637 5.34 ]
5 folds의 평균 RMSE : 5.518166280868977이번에는 릿지의 알파 값을 [ 0, 0.1, 1, 10, 100 ] 으로 변화시키면서 RMSE와 회귀 계수 값의 변화를 살펴보겠다.
# 릿지에 사용될 alpha 파라미터의 값을 정의
alphas = [0, 0.1, 1, 10, 100]
# 알파 리스트 값을 반복하면서 알파에 따른 평균 RMSE를 구한다
for alpha in alphas :
ridge = Ridge(alpha = alpha)
# cross_val_score를 이용해 5 folds의 평균 RMSE를 계산
neg_mse_scores = cross_val_score(ridge, X_data, y_target, scoring="neg_mean_squared_error", cv=5)
avg_rmse = np.mean(np.sqrt(-1*neg_mse_scores))
print(f'알파값이 {alpha}일 때, 5 folds의 평균 RMSE : {avg_rmse:.3f}')알파값이 0일 때, 5 folds의 평균 RMSE : 5.829
알파값이 0.1일 때, 5 folds의 평균 RMSE : 5.788
알파값이 1일 때, 5 folds의 평균 RMSE : 5.653
알파값이 10일 때, 5 folds의 평균 RMSE : 5.518
알파값이 100일 때, 5 folds의 평균 RMSE : 5.330릿지 회귀는 알파 값이 커질수록 회귀 계수 값을 작게 만든다. 결과적으로 값이 100일때 평균 RMSE가 5.330으로 가장 좋게 나온것을 보면 알수 있다.
# 각 알파에 따른 회귀 계수 값을 시각화 하기 위해 5개의 열로 된 matplot 축 생성
fig, axs = plt.subplots(1,5, figsize=(18,6))
# 각 알파에 따른 회귀 계수 값을 데이터로 저장하기 위한 DataFrame 생성
coeff_df = pd.DataFrame()
# 위에서 설정한 알파 리스트 값을 차례로 입력해 회귀 계수 값 시각화 및 데이터 저장을 진행한다
for i, alpha in enumerate(alphas):
ridge = Ridge(alpha = alpha)
ridge.fit(X_data, y_target)
# 회귀 계수 데이터프레임
# 알파에 따른 피처별로 회귀 계수를 Series 변환 후 dataframe 칼럼으로 추가하는 것
coef_series = pd.Series(data = ridge.coef_, index = X_data.columns)
colname='alpha:'+str(alpha)
coeff_df[colname] = coeff
# 회귀 계수 plot
coef_series = coef_series.sort_values(ascending=False)
sns.barplot(x = coef_series.values, y = coef_series.index, ax = axs[i])
axs[i].set_title(f"alpha: {alpha}")
axs[i].set_xlim(-3,6)
plt.show()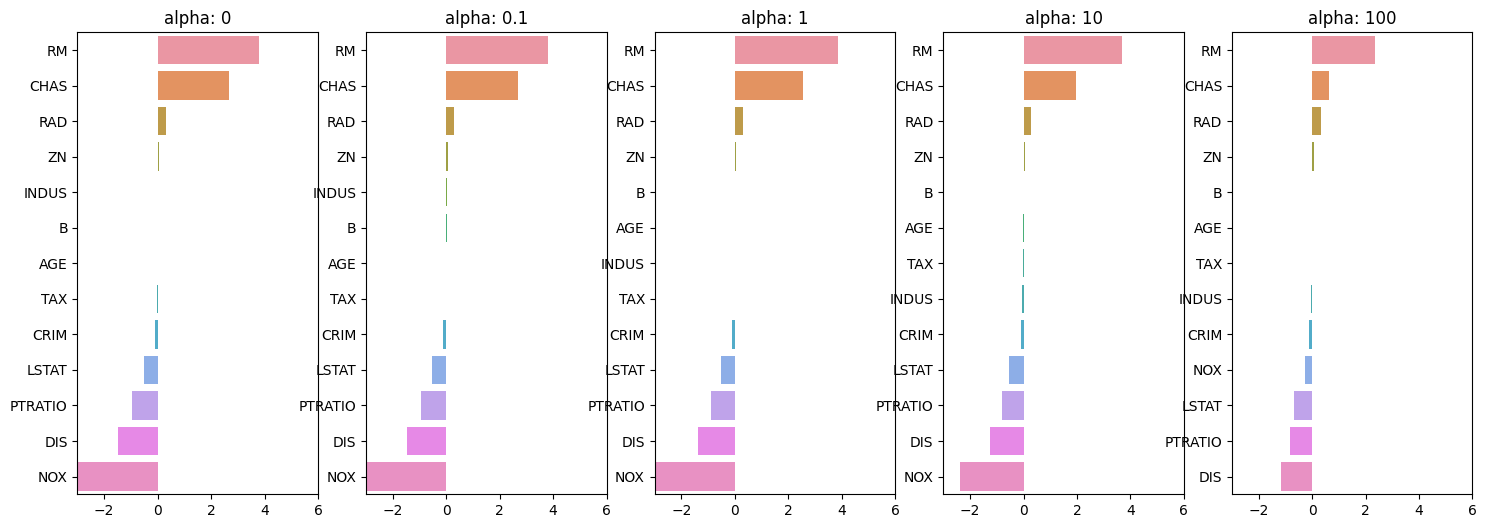
alpha 값을 계속 증가시킬수록 회귀 계수 값은 지속적으로 작아지는 모습을 볼 수 있다. 특히 NOX피처의 경우 알파 값을 계속 증가시킴에 따라 회귀 계수가 크게 작아지고 있는 모습이 보인다.