복습문제
# 실루엣 계수는 -1~1 사이의 값을 가지며
# 1에 가까워질수록 군집끼리 멀리 떨어져있고, 0보다 작으면 가까운것이다.
O
# 군집과 분류의 차이점은?
군집 : 비지도 학습
분류 : 지도학습
# K-평균은 거리기반 알고리즘이므로 속성의 개수가 많아질수록
# 군집화 정확도가 떨여져 PCA로 차원감소를 적용해 이를 보완한다.
O
# silhouette_score의 값이 클수록 군집화가 더 잘된것이다
X
[출제자 답변]
단정을 하면 안되고 개별 군집의 평균값 편차도 크지 않아야 하기 때문에
x 이지만 대체적으로 맞는 이야기이긴 한다.
# 실루엣계수를 표현하는 수식을 쓰세요
# a(i) : 각 집단 내 거리 평균
# b(i) : 각 집단간 거리 평균
a(i) - b(i) / max(a(i), b(i))
# 평균이동(Mean Shift)의 파라미터 중 bandwidth의 설정값을 작게할 수록
# 군집의 개수는 어떻게 변화되는가?
많아진다
# K_Means는 중심에 소속된 데이터의 평균 거리의 중심으로 이동하는데 반해
# Mean Shift는 중심을 데이터가 모여있는 ()가 가장 높은 곳으로 이동시킨다
밀도
# 사이킷런 데이터 셋에서 임의의 데이터를 생성하는 방법 2가지
# 1. 같은 성질을 가지는 정규 분포를 이용해 가장 데이터 생성
# 2. 작은 원이 큰 원에 포함되도록 데이터 분포를 이루면서 생성
1 - make_blobs
2 - make_circles
# DBSCAN의 데이터 포인트 4가지
핵심(core), 이웃(neighbor), 경계(border), 잡음(noise)
# KMeans 알고리즘의 파라미터가 아닌것은?
# n_clusters(몇 개의 군집을 찾을 것인가)
# init(초기 군집 중심점을 설정하는 방식)
# max_iter(중심점을 찾기 위한 최대 반복 횟수)
# n_target(데이터의 라벨/타겟)
n_target
# PCA는 무엇의 약자입니까?
Principal Component Analysis
주성분 분석이라고도 함
+) 데이터의 분산이 가장 잘 구별되는 새로운 축을 찾는다
# LDA는 무엇의 약자입니까?
Linear Discriminant Analysis
+) 지도학습
+) 데이터의 클래스/라벨이 가장 잘 구별되는 새로운 축을 찾는다.
# K-평균은 중심에 소속된 데이터의 () 중심으로 이동하고
# 평균이동은 중심을 데이터가 모여있는 ()가 가장 높은 곳으로 이동
평균 거리, 밀도
# K-means군집 분석에서 군집수 (k) 결정방법 중 여러가지 k에 대한 군집 분석결과
# 군집 내에 얼마나 밀집되어 있는가를 나타내는 통계량 합을 기준으로
# 크기의 변화가 작아진는 지점을 적정 군집수로 결정하는 방법은?
팔꿈치 이론, elbow 기법
import pandas as pd
import numpy as np
import pydataset as py
mpg = py.data('mpg')
# 제조사 : audi, ford ,jeep, lincol 만 뽑아주세요
# [방법 1]
li = ['audi','ford','jeep','lincoln']
mpg_df_1 = mpg[mpg['manufacturer'].isin(li)]
mpg_df_1
# [방법 2]
mpg_df_2 = mpg.query("manufacturer in ['audi', 'ford', 'jeep', 'lincoln']")
# 제조사 별로 drv에 따른 cty의 최대값을 sn
import seaborn as sns
drv_cty = mpg_df_1.groupby(['manufacturer', 'drv'])['cty'].max()
drv_cty = drv_cty.reset_index()
# 위 두줄을 한번에 하려면
# mpg_df_1.groupby(['manufacturer', 'drv'], as_index=False)['cty'].max()
drv_cty
# manufacturer drv cty
# 0 audi 4 20
# 1 audi f 21
# 2 ford 4 15
# 3 ford r 18
# 4 jeep 4 17
# 5 lincoln r 12
# [그래프]
sns.barplot(drv_cty, x = 'manufacturer', y = 'cty', hue = 'drv') 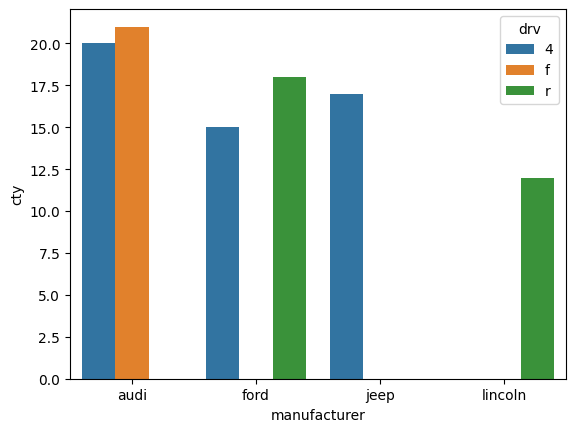
텍스트 분석
NLP? text 분석?
머신러닝이 보편화 되면서 NLP(natural language processing)와 텍스트 분석(Text Analytics, 이하 TA)을 구분하는 것이 큰 의미는 없어보이지만, 굳이 구분하자면 NLP는 머신이 인간의 언어를 이해하고 해석하는 데 더 중점을 두고 기술이 발전해왔으며, 덱스트 마이닝(Text Mining)이라고도 불리는 텍스트 분석은 비정형 텍스트에서 의미있는 정볼르 추출하는 것에 조금 더 중점을 두고 기술이 발전해 왔다.
텍스트 분류
- Text Classification
- 문서가 특정 분류 또는 카테고리에 속하는 것을 예측하는 기법
예를 들어 특정 신문기사 내용이 어떤 카테고리(연애/정치/사회 등)에 속하는 지 자동으로 분류하거나 스팸 메일 검출 같은 프로그램이 이에 속한다 - 지도 학습을 적용
감성분석
- 텍스트에서 나타나는 감정/판단/믿음/의견/기분 등의 주관적인 요소를 분석하는 기법 통칭
- SNS 감정분석, 영화나 제품에 대한 긍종 또는 부정 리뷰, 여론조사 의견 분석 등의 영역에서 활용
- 지도학습, 비지도 학습 모두 가능하다.
텍스트 요약
- 텍스트 내에서 중요하다고 생각되는 주제나 중심 사상을 추출하는 기법
- 대표적으로 토픽 모델링이 있다.
텍스트 군집화와 유사도 측정
- 비슷한 유형의 문서에 대해 군집활르 수행하는 기법
- 텍스트 분류를 비지도 학습으로 수행하는 방법의 일종으로 사용될 수 있다.
- 유사도 측정 역시 문서들간 유사도를 측정해 비슷한 문서끼리 모을 수 있는 방법이다.
텍스트 분석 이해
텍스트 분석은 비정형 데이터인 텍스트를 분석하는 것이다. 머신러닝 알고리즘은 숫자형의 피처 기반 데이터만 입력 받을 수 있기 때문에, 비정형 텍스트 데이터를 어떻게 피처 형태로 추출하고 추출된 피처에 의미있는 값을 부여하는 가 하는 것은 매우 중요한 요소이다.
텍스트를 word(또는 word의 일부) 기반의 다수 피처로 추출하고 이 피처에 단어 빈도수와 같은 숫자 값을 부여하면 텍스트는 단어의 조합인 벡터값으로 표현 될 수 있는데, 이렇게 텍스트를 변환하는 것을 피처 벡터화(Feature Vectorization) 또는 피처 추출(Feature Extraction) 이라한다.
프로세스
머신러닝 기반의 텍스트 분석 프로세스는 다음과 같은 프로세스 순으로 수행한다
텍스트 사전 준비작업(텍스트 전처리)
-텍스트를 피처로 만들기 전에 미리 클렌징, 대소문자 변경, 특수문자 삭제 등의 클렌징 작업
-단어(word)등의 토큰화 작업, 의미없는 단어(Stop word)제거 작업, 어근 추출(Stemming/Lemmatization) 등의 텍스트 정규화 작업수행을 통칭피처 벡터화/추출
-사전 준비작업으로 가공된 텍스트에서 피처를 추출하고 벡터 값을 할당한다.
-대표적으로 BOW(Bag of Words)와 Word2Vec방법이 있으며, BOW는 Count기반과 Tf-IDF 기반 벡터화가 있다.ML모델 수립 및 학습/예측/평가
-피처 벡터화된 데이터 셋에 ML 모델을 적용해 수행한다.
텍스트 분석 패키지
- NLTK(Natural Language Toolkit for Python) : 파이썬의 가장 대표적인 NLP 패키지. 방대한 양의 데이터 셋과 서브 모듈을 가지고 있다. 많은 NLP패키지가 NLTK의 영향을 받아 작성되고 있지만, 수행 속도 측면에서는 아쉬운 부분이 있어 실제 대량의 데이터 기반에서는 제대로 활용되지 못하는 듯하다.
- Gensim : 토픽 모델링 분야에서 가장 두각을 나타내는 패키지. 오래전부터 토픽 모델링을 쉽게 구현할 수 있는 기능을 제공해왔으며, Word2Vec 구현등 다양한 신기능도 제공한다. SpaCy와 함께 가장 많이 사용되는 패키지
- SpaCy : 뛰어난 수행 성능으로 최근 가장 주목을 받는 패키지이다. 많은 NLP 애플리케이션에서 사용 중
text 전처리 - text 정규화
텍스트 자체를 바로 피처로 만들수가 없기에 이를 위해 사전에 텍스트를 가공하는 준비 작업이 필요하다.
클렌징
분석에 오히려 방해되는 불필요한 문자, 기호 등을 사전에 제거하는 작업이다.
예를들어 HTML, XML태그나 특정기호 등을 사전에 제거
텍스트 토큰화
주어진 코퍼스(corpus; 말뭉치;)에서 토큰이라불리는 단위로 나누는 작업을 뜻한다. 토큰의 단위는 상황에 따라 다르지만 보통 의미있는 단위로 토큰을 정의한다.
문장/단어 토큰화로 유형을 나눠볼 수 있다.
NLTK는 이를 위해 다양한 API를 제공하며, 사용하기 위한 install 설치는 아래와 같이 할 수 있다.
pip install nltk문장 토큰화
문장 토큰화(sentence tokenization)은 문장의 마침표, 개행문자(\n) 등 문장의 마지막을 뜻하는 기호에 따라 분리하는 것이 일반적이다. 정규 표현식에 따른 문장 토큰화도 가능하지만 NLTK는 많이 쓰이는 sent_tokenize를 이용해 수행해보자
from nltk import sent_tokenize
import nltk
# 마침표, 개행 문자등의 데이터 세트를 다운로드
nltk.download('punkt')
text_sample = 'The Matrix is everywhere its all around us, here even in this room. \
You can see it out your window or on your television. \
You feel it when you go to work, or go to church or pay your taxes'
# 문장 토큰화를 진행할 text를 sent_tokenize안에 넣어준다.
sentences = sent_tokenize(text=text_sample)
print(type(sentences), len(sentences))
print(sentences)<class 'list'> 3
['The Matrix is everywhere its all around us, here even in this room.', 'You can see it out your window or on your television.', 'You feel it when you go to work, or go to church or pay your taxes']반환되는 것은 각각의 문장으로 구성된 list 객체
단어 토큰화
문장을 단어로 토큰화 하는것. 기본적으로 공백, 콤마, 마침표, 개행문자 등으로 단어를 분리하지만 정규 표현식을 이용해 다양한 유형으로 토큰화를 수행할 수 있다.
from nltk import word_tokenize
words = word_tokenize(text_sample)
print(type(words), len(words))
print(words)<class 'list'> 44
['The', 'Matrix', 'is', 'everywhere', 'its', 'all', 'around', 'us', ',', 'here', 'even', 'in', 'this', 'room', '.', 'You', 'can', 'see', 'it', 'out', 'your', 'window', 'or', 'on', 'your', 'television', '.', 'You', 'feel', 'it', 'when', 'you', 'go', 'to', 'work', ',', 'or', 'go', 'to', 'church', 'or', 'pay', 'your', 'taxes']조합하여
word_tokenize, sent_tokenize를 조합하여 문서에 대해 모든 단어를 토큰화해 보자. 위에서 만들어줬던 (3개의 문장으로 된) text_sample을 문장으로 나누고, 개별 문장을 다시 단어로 토큰화 하면 되는 것이다.
from nltk import word_tokenize, sent_tokenize
# 빈 리스트 생성
li = []
# text_sample을 문장별로 쪼개기
sentences = sent_tokenize(text=text_sample)
# for 문을 돌리면서 문장별로 단어 쪼개기
for sentences in sentences :
li.append(word_tokenize(sentences))
li[['The', 'Matrix', 'is', 'everywhere', 'its', 'all', 'around', 'us', ',', 'here', 'even', 'in', 'this', 'room', '.']
, ['You', 'can', 'see', 'it', 'out', 'your', 'window', 'or', 'on', 'your', 'television', '.']
, ['You', 'feel', 'it', 'when', 'you', 'go', 'to', 'work', ',', 'or', 'go', 'to', 'church', 'or', 'pay', 'your', 'taxes']]당연히 list 컴프리핸션으로도 가능하다
sentences = sent_tokenize(text=text_sample)
[word_tokenize(sentences) for sentences in sentences]이와같은 식으로. 결과는 같아 보기 때문에 옮겨오지 않았다.
3개의 문장을 문장별로 먼저 토큰화 했으므로 word_tokens 변수는 3개의 리스트 객체를 내포하는 리스트가 되었다. 그리고 내포된 개별 리스트 객체는 각각 문장별로 토큰화된 단어를 요소로 가지고 있다.
하지만 2개의 단어가 뭉쳐서 하나의 의미를 나타내는 경우를 2-gram(bi-gram)이라 하며, 문장을 단어별로 토큰화 할 경우 문맥적인 의미는 무시될 수 밖에 없다. 이러한 문제를 조금이라도 해결해보고자 도입된 n-gram 이라는 것도 있다.
1-gram : uni-gram
2-gram : bi-gram
3-gram : trigram
...
n-gram스톱워드(Stop word) 제거
분석에 큰 의미가 없는 단어를 지칭한다. 가령 영어에서 is, the, a, will등 문장을 구성하는 문법 요소는 맞지만 문맥적으로는 큰 의미가 없는 단어가 이에 해당한다.이 단어는 빈번하게 텍스트에 나타나므로 이것들을 사전에 제거하지 않으면 그 빈번함으로 인해 중요한 단어로 인지 될 수 있기 때문에 이전에 제거해야한다.
import nltk
nltk.download('stopwords')
print(nltk.corpus.stopwords.words('english')[:20])['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his']여러 문장을 문장별로 토큰화 후 stopword제거를 해본다면
sentences = sent_tokenize(text_sample)
word_tokens = [word_tokenize(sentence) for sentence in sentences]
# 영어 stopword
stopwords = nltk.corpus.stopwords.words('english')
# 문장별 단어 토큰화 + stopword 제거
all_tokens = []
for sentence in word_tokens:
filtered_words=[]
# 문장 토큰의 각 단어 토큰
for word in sentence:
# 소문자 변환
word = word.lower()
# stopword 미포함
if word not in stopwords:
filtered_words.append(word)
all_tokens.append(filtered_words)
print(all_tokens)[['matrix', 'everywhere', 'around', 'us', ',', 'even', 'room', '.'], ['see', 'window', 'television', '.'], ['feel', 'go', 'work', ',', 'go', 'church', 'pay', 'taxes']]Stemming과 Lemmatization
Steam : 어간
Stemming
- 어간추출
- 단어의 원형을 찾는데, 원형 단어로 변환 시 일반적인 방법을 적용하거나 더 단순화된 방법을 적용해 원래 단어에서 일부 철자가 훼손된 어근단어를 추출하는 경향이 있다.
- plays -> play
Lemmatization
- 표제어 추출
- 품사와 같은 문법적인 요소와 더 의미적인 부분을 감안해 정확한 철자로 된 어근 단어를 찾아준다.
- is, was -> be
Lemmatizaiton이 Stemming보다 의미론적인 기반에서 원형을 찾기 때문에 더 정교하다고 볼 수 있다.
Stemming
# Stemming
from nltk.stem import LancasterStemmer
stemmer = LancasterStemmer()
print(stemmer.stem('plays'), stemmer.stem('playing'), stemmer.stem('played'))
print(stemmer.stem('working'), stemmer.stem('works'), stemmer.stem('worked'))
print(stemmer.stem('amusing'),stemmer.stem('amuses'),stemmer.stem('amused'))
print(stemmer.stem('happier'),stemmer.stem('happiest'))
print(stemmer.stem('fancier'),stemmer.stem('fanciest'))play play play
work work work
amus amus amus
happy happiest
fant fanciestplay나 work의 경우 기본단어로 잘 되돌아왔으나, amuse의 경우 기본단어에 ing, s, ed가 붙었다는 이유로 정확한 단어가 아닌 amus로 되돌린 모습을 확인할 수 있었다. 형용사인 happy와 fancy이 경우도 비교형, 최상급형으로 변형된 단어의 정확한 원형을 찾지 못하고 원형 단어에서 철자가 다른 어근 단어로 인식하는 경우가 발생했다.
Lemmatization
# Lemmatization
from nltk.stem import WordNetLemmatizer
lemma = WordNetLemmatizer()
# 책에서는 'wordnet'이였지만 바뀐듯 하다
nltk.download('omw-1.4')
# 동사: v, 형용사: a
print(lemma.lemmatize('plays', 'v'))
print(lemma.lemmatize('is', 'v'), lemma.lemmatize('was', 'v'), lemma.lemmatize('being', 'v'))
print(lemma.lemmatize('amusing','v'),lemma.lemmatize('amuses','v'),lemma.lemmatize('amused','v'))
print(lemma.lemmatize('happier','a'),lemma.lemmatize('happiest','a'))
print(lemma.lemmatize('fancier','a'),lemma.lemmatize('fanciest','a'))play
be be be
amuse amuse amuse
happy happy
fancy fancyLemmatization에선 정확한 원형 단어 추출을 위해 품사를 기입하여야 하는 귀찮음이 있지만, Stemming보다는 정확하게 원형 단어를 추출해내는 걸 볼 수 있었다. 사전을 기반으로 단어를 처리하기 때문에 오류는 적은 편이나 새로운 단어는 처리 할 수 없다는 단점이 있다.
피처 벡터화 (Bag of Words - BOW)
문서가 가지는 모든 단어(words)를 문맥이나 순서를 무시하고 일괄적으로 단어에 대해 빈도 값을 부여 한 뒤 피처 값을 추출하는 모델이다. 쉽고 빠른 구축이 가능하지만 단어의 순서를 고려하지 않으므로 문맥적인 의미 반영이 부족하고 희소 행렬(대부분의 값이 0)의 문제가 있다.
Count 벡터화
- 단어 피처에 값을 부여할 때 각 문서에서 해당 단어가 나타나는 횟수
- 단순하게 모든 단어의 빈도로 피처 벡터화를 진행한다.
- 카운트 벡터화에서는 카운트 값이 높을 수록 중요한 단어로 인식하는 문제
- CountVectorizer()는 다음과 같이 작업을 수행한다.
→ 소문자 일괄 변환, 각 단어를 토큰화, 텍스트 전처리(스톱 워드 제거), 피처 벡터화
TF-IDF 벡터화
- Term Frequency Inverse Document Frequency
- 개별 문서에서 자주 나타내는 단어에 높은 가중치를 주되, 모든 문서에서 전반적으로 자주 나타나는 단어에 대해서는 페널티를 주는 방식으로 값을 부여한다.
희소 행렬
모든 문서의 단어를 피처로 벡터화 하면 컬럼이 많아질 수 밖에 없다. 하지만 행렬은 대규모로 생성되어도 단어의 종류에 비해 각 문서가 가지는 단어의 수는 제한적이기 때문에 이 행렬의 값은 대부분 0이 차지할 수 밖에 없다. 이처럼 대규모 행렬의 대부분 값을 0이 차지하는 행렬을 가리켜 희소행렬이라 한다.
BOW 형태를 가진 언어 모델의 피처 벡터화는 대부분 희소행렬이다. 희소 행렬은 불필요한 0값이 너무 많아 메모리 공간이 많이 필요하며 연산 시간도 오래 걸리게 되는 단점이 있는데, 이러한 희소행렬이 적은 메모리 공간을 차지하게 변환하는 2가지 방법이 있다.
COO 형식
COO(Coordinate: 좌표) 형식은 0이 아닌 데이터만 별도의 배열에 저장하고, 그 데이터가 가리키는 행과 열의 위치를 별도의 배열로 저장하는 방식이다.
sparse 패키지의 coo_matrix를 이용해 COO형식으로 희소 행렬 생성할수 있다.
from scipy import sparse
# 희소행렬 만들기
data = np.array([3, 1, 2])
row = np.array([0, 0, 1])
col = np.array([0, 2, 1])
# sparse 패키지의 coo_matrix를 이용해 COO형식으로 희소 행렬 생성
# coo_matrix((M, N), [dtype])
sparse_coo = sparse.coo_matrix((data, (row, col)))
sparse_coo.toarray()array([[3, 0, 1],
[0, 2, 0]])위와같이 넣으려면 (())의 형태로 넣어야 하는 점을 명시하자. sparse_coo로 담아준 것의 COO형식의 희소 행렬 객체이고, toarray()를 이용해주면 다시 밀집 형태의 행렬로 출력 가능하다.
CSR 형식
COO 형식은 행과 열의 위치를 나타내기 위해 반복적으로 위치 데이터를 사용하는데 이를 해결한 방식이 CSR(Compressed Sparse Row) 형식이다. 간단하게 말하자면 COO에서 행 위치 배열을 다시 위치 시작 배열로 생성하는 것이다.
# dense2를 위처럼 생성하세요
# dense2 = np.array([[0,0,1,0,0,5],
# [1,4,0,3,2,5],
# [0,6,0,3,0,0],
# [2,0,0,0,0,0],
# [0,0,0,7,0,8],
# [1,0,0,0,0,0]])
# 0이 아닌 데이터
data = np.array([1, 5, 1, 4, 3, 2, 5, 6, 3, 2, 7, 8, 1])
# 행과 열 위치를 각각 배열로 생성
row = np.array([0, 0, 1, 1, 1, 1, 1, 2, 2, 3, 4, 4, 5])
col = np.array([2, 5, 0, 1, 3, 4, 5, 1, 3, 0, 3, 5, 0])
#
sparse.coo_matrix((data, (row, col))).toarray()array([[0, 0, 1, 0, 0, 5],
[1, 4, 0, 3, 2, 5],
[0, 6, 0, 3, 0, 0],
[2, 0, 0, 0, 0, 0],
[0, 0, 0, 7, 0, 8],
[1, 0, 0, 0, 0, 0]])위가 COO형식의 변환이라면
# 행 위치 배열의 고유한 값에 시작 위치 인덱스를 배열로 생성
row_index = np.array([0, 2, 7, 9, 10, 12, 13])
sparse_csr = sparse.csr_matrix((data, col, row_index))
sparse_csr.toarray()array([[0, 0, 1, 0, 0, 5],
[1, 4, 0, 3, 2, 5],
[0, 6, 0, 3, 0, 0],
[2, 0, 0, 0, 0, 0],
[0, 0, 0, 7, 0, 8],
[1, 0, 0, 0, 0, 0]])이것이 CSR형식의 변환이다. 방법이 조금 헷갈렸는데 교재의 아래 사진을 보면 이해가 쉽다.
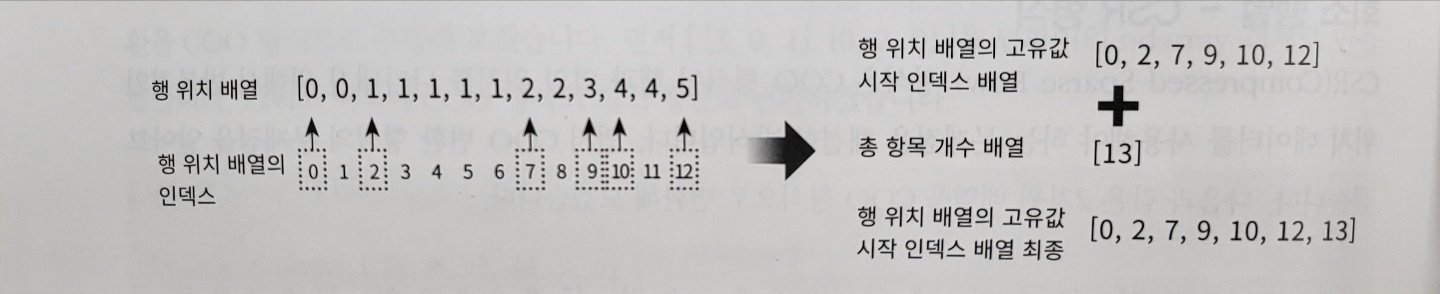
이렇게 고유값의 시작위치만 알고 있으면 얼마든지 행 위치 배열을 다시 만들수 있기에 COO방식보다 메모리가 적게 들고 빠른 연산이 가능하다.
텍스트 분류 실습
사이킷런은 fetch_20newsgroups API를 이용해 뉴스그룹의 분류를 수행해 볼 수 있는 예제 데이터를 제공한다. 이 데이터 셋을 이용해 어떤 뉴스 그룹인지 텍스트 분류를 적용해봅시다.
from sklearn.datasets import fetch_20newsgroups
new_data = fetch_20newsgroups(subset='all', random_state=15)
new_data
잘.. 가져왔다. 옆에 스크롤 크기가 보이는가? 생각보다 더 양이 많았기에 그만큼 가져오는데 시간이 꽤나 걸렸다.
fetch_20newsgroups은 사이킷런의 다른 데이터 셋 예제와 같이 파이썬 딕셔너리와 유사한 Bunch 객체를 반환한다.
new_data.keys()dict_keys(['data', 'filenames', 'target_names', 'target', 'DESCR'])import pandas as pd
print("target 클래스의 값과 분포도")
print(pd.Series(new_data.target).value_counts().sort_index())
print('target 클래스의 이름들')
print(new_data.target_names)target 클래스의 값과 분포도
0 799
1 973
2 985
3 982
4 963
5 988
6 975
7 990
8 996
9 994
10 999
11 991
12 984
13 990
14 987
15 997
16 910
17 940
18 775
19 628
dtype: int64
target 클래스의 이름들
['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']타깃은 0부터 19까지 20개로 구성되어 있는 모습이다. 데이터 한 개만 추출해 어떤 모습인지 확인
new_data.data[0]From: matt@centerline.com (Matt Landau)
Subject: Re: Asynchronous X Windows?
Organization: CenterLine Software, Inc.
Lines: 45
Distribution: inet
NNTP-Posting-Host: 140.239.1.32
In <ellis.735675321@nova> ellis@nova.gmi.edu (R. Stewart Ellis) writes:
>>Is there anyway to use X Windows over an async line? Clearly you could use
> x
>It is X window.
No, it isn't. It is the "X Window System", or "X11", or "X" or any of
a number of other designations accepted by the X Consortium. In fact,
doing "man X" on pretty much any X11 machine will tell you:
The X Consortium requests that the following names be used
when referring to this software:
X
X Window System
X Version 11
X Window System, Version 11
X11
There is no such thing as "X Windows" or "X Window", despite the repeated
misuse of the forms by the trade rags. This probably tells you something
about how much to trust the trade rags -- if they can't even get the NAME
of the window system right, why should one trust anything else they have
to say?
...
이하 생략텍스트 데이터를 확인해보면 뉴스 그룹 기사의 내용뿐 아니라 뉴스그룹 제목, 작성자, 소속, 이메일 등의 다양한 정보를 가지고 있다. 이 중에서 순수한 텍스트만으로 구성된 기사내용으로 어떤 뉴스 그룹에 속하는 지 분류할 것이기 때문에 파라미터를 이용해 헤더와 푸터 등을 제거하자
# subset='train'으로 학습용 데이터만 추출
# remove=('headers', 'footers', 'quotes')로 내용만 추출
train_news = fetch_20newsgroups(subset='train', remove=('headers', 'footers', 'quotes'), random_state=15)
X_train = train_news.data
y_train = train_news.target
X_train[0]I live at sea-level, and am called-upon to travel to high-altitude cities
quite frequently, on business. The cities in question are at 7000 to 9000
feet of altitude. One of them especially is very polluted...
Often I feel faint the first two or three days. I feel lightheaded, and
my heart seems to pound a lot more than at sea-level. Also, it is very
dry in these cities, so I will tend to drink a lot of water, and keep
away from dehydrating drinks, such as those containing caffeine or alcohol.
Thing is, I still have symptoms. How can I ensure that my short trips there
(no, I don't usually have a week to acclimatize) are as comfortable as possible?
Is there something else that I could do?
A long time ago (possibly two years ago) there was a discussion here about
altitude adjustment. Has anyone saved the messages?
Many thanks,train으로 추출된 데이터 하나만 살펴보면, 아까 봤던 내용보다는 훨씬 정돈된 것을 확인해볼 수 있다.
# subset='test'으로 테스트용 데이터만 추출
# remove=('headers', 'footers', 'quotes')로 내용만 추출
test_news = fetch_20newsgroups(subset='test', remove=('headers', 'footers', 'quotes'), random_state=15)
X_test = test_news.data
y_test = test_news.target
print(f'학습 데이터 크기 : {len(train_news.data)}, 테스트 데이터 크기 : {len(test_news.data)}')학습 데이터 크기 : 11314, 테스트 데이터 크기 : 7532피처 벡터화 변환
먼저 CountVectorizer를 이용해 학습 데이터의 텍스트를 피처 벡터화 해보자. 한가지 유의해야할 점은 테스트 데이터에서 CountVectorizer 를 적용할 때는 반드시 학습 데이터를 이용해 fit()이 수행된 CountVectorizer 객체를 이용해 테스트 데이터를 변환해야 한다는 것이다.
테스트 데이터의 피처 벡터화 시 fit_transform 을 사용하면 안된다는 점도 유의 사항이다.
from sklearn.feature_extraction.text import CountVectorizer
# Count Vectorization으로 피처 벡터화 변환 수행
cnt_vect = CountVectorizer()
cnt_vect.fit(X_train)
X_train_cnt_vect = cnt_vect.transform(X_train)
# 학습 데이터로 fit()된 CountVectorizer를 이용해 테스트 데이터를 피처 벡터화 변환수행
X_test_cnt_vect = cnt_vect.transform(X_test)
print(f'학습 데이터 텍스트의 CountVectorizer Shape : {X_train_cnt_vect.shape}')학습 데이터 텍스트의 CountVectorizer Shape : (11314, 101631)X_test_cnt_vect<7532x101631 sparse matrix of type '<class 'numpy.int64'>'
with 665738 stored elements in Compressed Sparse Row format>11314 개의 문서에서 피처(단어)가 101631개 만들어졌다. 이제 이렇게 피처 벡터화된 데이터에 로지스틱 회귀를 적용해 뉴스그룹에 대한 분류를 예측해보면
모델 학습/예측/평가
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 로지스틱을 이용하여 학습/예측/평가 수행
lr_clf = LogisticRegression(solver='liblinear')
lr_clf.fit(X_train_cnt_vect, y_train)
pred = lr_clf.predict(X_test_cnt_vect)
print(f'CountVectorized Logistic Regression의 예측 정확도는 {accuracy_score(y_test, pred):.3f} 이다.')CountVectorized Logistic Regression의 예측 정확도는 0.617 이다.Count 기반으로 피처 벡터화가 적용된 데이터 세트에 대한 로지스틱 회귀 예측의 정확도는 약 0.617이다. 이번에는 TF-IDF 기반으로 벡터화를 변경해 예측 모델을 수행해보자.
from sklearn.feature_extraction.text import TfidfVectorizer
# TF-IDF 벡터화를 적용해 줬을 때 학습 데이터와 테스트 데이터 셋 변환
tfidf_vect = TfidfVectorizer()
tfidf_vect.fit(X_train)
X_train_tfidf_vect = tfidf_vect.transform(X_train)
X_test_tfidf_vect = tfidf_vect.transform(X_test)
# 로지스틱 회귀를 이용해 학습/예측 평가
lr_clf = LogisticRegression(solver='liblinear')
lr_clf.fit(X_train_tfidf_vect, y_train)
pred = lr_clf.predict(X_test_tfidf_vect)
print(f'TR-IDF Logistic Regression의 예측 정확도는 {accuracy_score(y_test, pred):.3f}')TR-IDF Logistic Regression의 예측 정확도는 0.678단순 카운트보다 높은 예측 정확도가 나왔다. 일반적으로 문서 내에 텍스트가 많고, 문서가 많은 경우에는 TF_IDF 벡터화가 더 좋은 예측 결과를 도출
파라미터 조정
텍스트 분석에서 머신러닝 모델의 성능을 향상시키는 방법 중 하나는 피처 전처리를 수행하는 것이다. 앞의 TF-IDF 벡터화는 기본 파라미터만 적용했지만, 좀 더 다양한 파라미터를 적용해보자
- 피처 벡터화에서
stop_words를 기존 None에서 'english'로 지정한다. ngram_range로 단어를 2개씩 묶어서 피처로 추출한다max_df로 전체 문서를 통틀어 300번 이상 존재하는 단어는 제외
# stop words 필터링을 추가하고
# ngram을 기본 (1, 1)에서 (1, 2)로 변경해 피처 벡터화 적용
tfidf_vect = TfidfVectorizer(stop_words='english', ngram_range=(1, 2), max_df=300)
tfidf_vect.fit(X_train)
X_train_tfidf_vect = tfidf_vect.transform(X_train)
X_test_tfidf_vect = tfidf_vect.transform(X_test)
lr_clf = LogisticRegression(solver='liblinear')
lr_clf.fit(X_train_tfidf_vect, y_train)
pred = lr_clf.predict(X_test_tfidf_vect)
print(f'TF-IDF Vectorized Logistic Regression의 예측 정확도는 {accuracy_score(y_test, pred)}')TF-IDF Vectorized Logistic Regression의 예측 정확도는 0.6901221455124801앞서 파라미터를 디폴트로 설정하고 돌렸을 때보다는 정확도가 조금 더 증가했다.
로지스틱 하이퍼 파라미터
이번에는 GridSearchCV를 이용해 로지스틱 회귀의 최적 하이퍼 파라미터를 찾아보자
from sklearn.model_selection import GridSearchCV
# 최적 C값 도출 튜닝 수행
# CV는 3 폴드 셋
params = {'C' : [0.01, 0.1, 1, 5, 10]}
grid_cv_lr = GridSearchCV(lr_clf, param_grid=params, cv=3, scoring='accuracy', verbose=1)
grid_cv_lr.fit(X_train_tfidf_vect, y_train)# 최적 C값 도출 튜닝 수행
# CV는 3 폴드 셋
params = {'C' : [0.01, 0.1, 1, 5, 10]}
grid_cv_lr = GridSearchCV(lr_clf, param_grid=params, cv=3, scoring='accuracy', verbose=1)
grid_cv_lr.fit(X_train_tfidf_vect, y_train)print(f'Best C parameter : {grid_cv_lr.best_params_}')Best C parameter : {'C': 10}C가 10일 때 그리드서치CV의 교차 검증 테스트 셋에서 가장 좋은 성능을 나타냈다.
# Best C값으로 학습된 grid_cv로 예측 및 정확도 평가
pred = grid_cv_lr.predict(X_test_tfidf_vect)
print(f'예측 정확도는 {accuracy_score(y_test, pred):.3f}')예측 정확도는 0.704이를 테스트 데이터 세트에 적용했더니 약 0.704로 이전보다 수치가 향상되었다. 시간이 꽤 오래 걸리니 유의해서 돌리자..
파이프라인(Pipeline) 사용
pipeline()은 전처리와 ML 학습을 한번에 수행 가능하다. 피처 벡터화 결과를 별도 데이터로 저장하지 않고 바로 ML데이터로 입력되어 수행시간 절약이 가능하고 직관적인 모델 코드를 생성할 수 있다.
from sklearn.pipeline import Pipeline
pipeline = Pipeline([('tfidf_vect', TfidfVectorizer(stop_words='english')),
('lr_clf', LogisticRegression(random_state=156))])
# 별도의 TfidVectorizer 객체의 fit(), transform()과
# LogisticRegression의 fit(), predict()가 필요 없다
# pipeline의 fit()과 predict()만으로 한꺼번에 피처 벡터화와 ML 학습/예측이 가능하다
pipeline.fit(X_train, y_train)
pred = pipeline.predict(X_test)
print(f'Pipeline을 통한 Logistic Regression의 예측 정확도는 {accuracy_score(y_test, pred):.3f}')Pipeline을 통한 Logistic Regression의 예측 정확도는 0.691사이킷런은 GridSearchCV 클래스의 생성 파라미터로 Pipeline을 입력해 하이퍼 파라미터 튜닝을 GridSearchCV 방식으로 진행할 수 있게 해준다.
from sklearn.pipeline import Pipeline
pipeline = Pipeline([('tfidf_vect', TfidfVectorizer(stop_words='english')),
('lr_clf', LogisticRegression())])
# Pipeline에 기술된 각각의 객체 변수에 언더바(_) 2개를 연달아 붙여 GridSearchCV에 사용될
# 파라미터/하이퍼 파라미터 이름과 값을 설정
params = { 'tfidf_vect__ngram_range': [(1,1), (1,2), (1,3)],
'tfidf_vect__max_df': [100, 300, 700],
'lr_clf__C': [1,5,10]
}
# GridSearchCV의 생성자에 Estimator가 아닌 Pipeline 객체 입력
grid_cv_pipe = GridSearchCV(pipeline, param_grid=params, cv=3, scoring='accuracy', verbose=1)
grid_cv_pipe.fit(X_train, y_train)
print(grid_cv_pipe.best_params_, grid_cv_pipe.best_score_)
pred = grid_cv_pipe.predict(X_test)
lr_acc = accuracy_score(y_test, pred)
print(f'Pipeline을 통한 Logistic Regression 의 예측 정확도: {lr_acc:.3f}')실행 시간이 정말 오래 걸린다. 결국 결과를 보지 못했다 다음에 다시 시도해 보는 것으로
로지스틱 회귀 외에도 텍스트 분류에는 서포트 벡터머신(Support Vector Machine)이나 나이브 베이즈(Naive Bayes)알고리즘도 희소 행렬 기반의 텍스트 분류에 자주 사용되는 머신러닝 알고리즘이다.
감성 분석
감성 분석(Sentiment Analysis)은 문서의 주관적인 감정/의견/감성/판단 등을 주관적인 요소를 파악하기 위한 기법.
SNS, 여론조사, 온라인 리뷰, 피드백 등 다양한 분야에서 활용되고 있다. 여러가지 주관적인 단어와 문맥을 기반으로 감성 수치를 계산하는데 지도학습, 비지도 학습 모두가 가능하다
지도학습
-학습 데이터와 타깃 레이블 값을 기반으로 감성 분석 학습을 수행한 뒤 이를 기반으로 다른 데이터의 감성 분석을 예측하는 방법
-일반적으로 적용해온 학습/예측 과정으로 텍스트 기반의 분류와 거의 동일하다
비지도 학습
-감성분석을 위한 용어와 문맥에 대한 다양한 정보를 가지고 있는, 'Lexicon'라는 일종의 감성 어휘 사전을 이용해 문서의 긍정적, 부정적 감성 여부를 판단한다.
지도학습 기반 감성 분석 실습(IMDB 영화평)
IMDB 영화 데이터를 실습 데이터로 사용할 것이다.
데이터 로드 및 구조
# 데이터 로드
import pandas as pd
review_df = pd.read_csv('./labeledTrainData.tsv', header=0, sep='\t', quoting=3)
review_df[:3]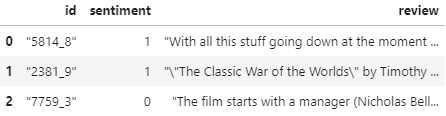
가져온 데이터의 구조를 살펴보면
- id : 각 데이터의 id
- sentiment : 영화평(review)의 결과값(Target Label). 1은 긍정적 평가 0은 부정적 평가
- review : 영화평 텍스트
텍스트 전처리
review_df["review"][0]'"With all this stuff going down at the moment with MJ i\'ve started listening to his music, watching the odd documentary here and there, watched T
...
이하 생략하나만 뽑아서 확인해보니, 해당 데이터는 HTML형식에서 추출했기 때문에 <br> 태그가 존재하는 것을 확인할 수 있었다. 이는 피처로 만들 필요가 없기 때문에 삭제
또한 영어가 아닌 숫자/특수문자 역시 피처로는 별 의미가 없어 보이기 때문에 이를 정규표현식을 이용하여 공란으로 변경하려 한다.
import re
# <br> html 태그는 replace 함수를 사용해 공백으로 변환
review_df['review'] = review_df['review'].str.replace('<br />', ' ')
review_df['review'] = review_df['review'].apply(lambda x : re.sub("[^a-zA-Z]", " ", x))
review_df['review']0 With all this stuff going down at the moment ...
1 The Classic War of the Worlds by Timothy ...
2 The film starts with a manager Nicholas Bell...
3 It must be assumed that those who praised thi...
4 Superbly trashy and wondrously unpretentious ...
...
24995 It seems like more consideration has gone int...
24996 I don t believe they made this film Complete...
24997 Guy is a loser Can t get girls needs to bui...
24998 This minute documentary Bu uel made in the...
24999 I saw this movie as a child and it broke my h...
Name: review, Length: 25000, dtype: object이제 결정 값 클래스인 sentiment 칼럼을 별도로 추출해 결정 값 데이터 셋을 만들고, 원본 데이터 세트에서 id와 sentiment 칼럼을 삭제해 피처 데이터 셋을 생성 후 split해주자
from sklearn.model_selection import train_test_split
class_df = y_target = review_df["sentiment"]
feature_df = X_feature = review_df.drop(['id', 'sentiment'], axis=1, inplace=False)
X_train, X_test, y_train, y_test= train_test_split(X_feature, y_target, test_size=0.3, random_state=156)
X_train.shape, X_test.shape((17500, 1), (7500, 1))학습용/테스트용 데이터가 175000/7500개로 나눠졌다.
피처 벡터화 및 ML
이제 감상평 텍스트를 피처 벡터화한 후 ML 분류 알고리즘을 적용해 예측 성능을 측정하려 한다. Pipeline객체를 이용해 두 가지를 한번에 수행하려 한다.
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, roc_auc_score
# 피처 벡터화: CountVectorizer, ML: LogisticRegression
pipeline = Pipeline([("cnt_vect", CountVectorizer(stop_words="english", ngram_range=(1,2) ) ),
("LR", LogisticRegression(solver='liblinear', C=10) )
])
# 학습
pipeline.fit(X_train['review'], y_train)
# 예측
pred = pipeline.predict(X_test['review'])
pred_probs = pipeline.predict_proba(X_test['review'])[:,1]
# 평가
acc = accuracy_score(y_test, pred)
auc = roc_auc_score(y_test, pred_probs)
print(f"예측 정확도: {acc:.4f}, ROC-AUC: {auc:.4f}")예측 정확도: 0.8859, ROC-AUC: 0.9503꽤 높게 나왔다.
피처 벡터화는 카운트 벡터화를 적용, ML은 로지스틱을 이용하였다.
이번에는 TF-IDF 벡터화를 적용한 뒤 다시 예측 성능을 측정해보려한다.
# 피처 벡터화: TfidfVectorizer, ML: LogisticRegression
pipeline = Pipeline([("tfidf_vect", TfidfVectorizer(stop_words="english", ngram_range=(1,2) ) ),
("LR", LogisticRegression(C=10) )
])
# 학습
pipeline.fit(X_train['review'], y_train)
# 예측
pred = pipeline.predict(X_test['review'])
pred_probs = pipeline.predict_proba(X_test['review'])[:,1]
# 평가
acc = accuracy_score(y_test, pred)
auc = roc_auc_score(y_test, pred_probs)
print(f"예측 정확도: {acc:.4f}, ROC-AUC: {auc:.4f}")예측 정확도: 0.8936, ROC-AUC: 0.9598Count기반 피처 벡터화의 예측 정확도는 0.8859
TF-IDF기반 피처 벡터화의 예측 정확도는 0.8936
으로 조금이지만 피처 벡터화의 예측 성능이 조금 더 좋게 나왔다.
read_csv 옵션 - \t
위에서 사용한 labeledTrainData.tsv는 탭(\t) 문자로 분리된 파일인데, 판다스의 read_csv() 의 인자로 sep='\t' 을 명시해주면 무리없이 읽어올 수 있다.
read_csv 옵션 - quoting
값을 읽거나 쓸 때 둘러쌀 문자 컨벤션
| 값 | 설명 |
|---|---|
| 0 | QUOTE_MINIMAL 기본값 최소한의 데이터만 묶겠다. (예를 들어 쉽표가 포함된 데이터만 묶음) |
| 1 | QUOTE_ALL 모든 데이터를 자료형에 상관없이 묶겠다. 모든 데이터를 문자열형으로 처리 |
| 2 | QUOTE_NONNUMERIC 숫자 데이터가 아닌 경우에만 묶는다. 데이터를 읽어올 때 묶이지 않은 데이터는 csv 객체에 의해 실수형으로 읽어오게 됨 |
| 3 | QUOTE_NONE 데이터를 묶는 작업 하지 않음 큰 따옴표를 무시한다 |