
- Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
꽤나 재밌게 읽었는데,
- Llama 3 는 홀딩하고, Post Training 은 언제 읽을 지 미정이 되버렸다.
- Llama 3 이 나온지 4개월? 만에.. 속도가 너무 빠르다.
- DeepSeek 의 Janus paper 를 바로 봐야한다.
- 강화 학습과 관련 더 필요한 방법을 익혀볼 예정.
- 논문을 볼 때, 읽고 요약을 하는 것보다, 초보라서 한땀씩 읽는게 아직은 편한 것 같다.
- 좀 더 빠르게 읽을 때 까지 시간이 걸리겠지만, 한 문장 한 문장을 놓치면 맘에 걸린다.
- 빠르게, 요약하며 읽을 날을 기약하며..
Abstract
-
Supervised Fine-Tuning 없이 large-scale 강화 학습을 통해서 훈련된 모델인 DeepSeek-R1-Zero 는 놀랄 만한 추론 능력을 보여준다.
-
그러나 DeepSeek-R1-Zero 는 낮은 가독성과 다국어들이 섞여 나오는 문제들이 있다.
-
이러한 이슈들을 해결하고 추론 성능을 향상시키기 위해서 RL 이전의 multi-stage training 과 cold-start data 를 통합하는 DeepSeek-R1 을 소개한다.
- preliminary step
SFT 를 하기 전, 모델이 준비된 상태를 말함. 즉, 이미 pre-training 된 모델이 존재하는 단계.
- cold-start
prior knowledge, 사전 지식 없이 ( 학습된 가중치 없이 ) 학습을 시작할 때 사용하는 데이터.
Figure 1
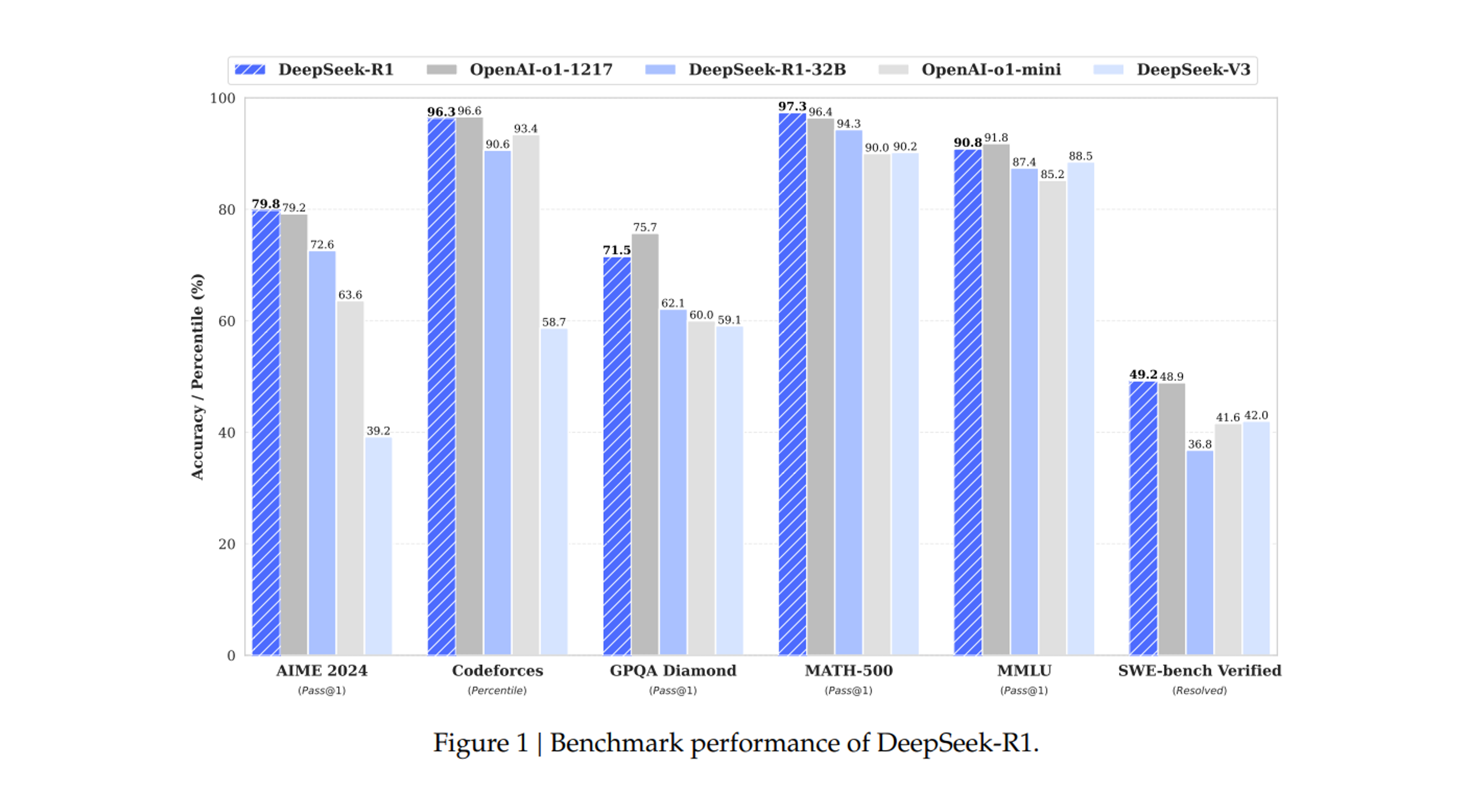
- DeepSeek-R1 의 Benchmark performance.
1. Introduction
-
순수 강화 학습 (RL) 을 사용하여 언어 모델 추론 능력을 향상 시키는 것을 소개한다.
-
RL 프로세스를 통한 self-evolution 에 중점을 두고, 어떠한 supervised data 없이 추론 기능을 개발할 수 있는 LLM 의 과정을 보여준다.
-
DeepSeek-V3-Base 를 기본 모델로 사용하고, GRPO (Shao et al., 2024) 를 RL 프레임워크로 사용하여 추론에서 모델 성능을 향상 시킨다.
-
DeepSeek-R1-Zero 는 낮은 가독성과 다국어들이 섞여 나오는 문제들이 있다.
-
이러한 이슈들을 해결하고 추론 성능을 향상 시키기 위해서 소량의 cold-start data 와 multi-stage training 파이프라인을 통합한 DeepSeek-R1 을 소개한다.
-
특히 DeepSeek-V3-Base model 을 fine-tune 하기 위해 수천 개의 cold-start data 를 수집하는 것 부터 시작한다.
RL Process 가 수렴에 가까워지면, RL checkpoint 에서 rejection sampling 을 통해 새로운 SFT 데이터를 생성하고, 글쓰기, 사실적인 QA 와 self-cognition (자가 인식) 과 같은 domain 에서 DeepSeek-V3 로부터의 supervised data 와 결합하여 DeepSeek-V3-Base model 을 retrain 한다.
-
새로운 데이터로 fine-tuning 후, checkpoint 는 모든 시나리오의 prompt 를 고려하는 (taking into account) 추가적인 강화학습 (RL) 과정을 거친다.
-
이러한 단계 후에, OpenAI-o1-1217 과 동등한 성능을 달성하는 DeepSeek-R1 이라는 checkpoint 를 얻었다.
- inference-time scaling
model 이 inference 를 할 때, CoT 의 길이를 조절하여 성능을 확장하는 기술. 고정된 구조가 아니라, inference step 에서 동적으로 조정된다.
- DeepSeek-V3-Base
Total param : 671B, MoE Activated Params : 37B
1.1 Contributions
Post-Training : Large-Scale Reinforcement Learning on the Base Model.
-
preliminary step 으로 Supervised Fine-Tuning (SFT) 를 사용하지 않고 기본 모델에 RL 을 직접 적용한다. 이 접근 방식을 통해 모델은 복잡한 문제를 해결하기 위해서 Chain-of-Thought (CoT) 를 탐구할 수 있도록 하며, 그 결과 DeepSeek-R1-Zero 가 개발되었다.
-
DeepSeekR1-Zero 는 self-verification (자가 검증), reflection (반영), 그리고 긴 CoT 생성과 같은 기능, 특히, 이것은 SFT 가 필요 없이 RL 을 통해서만 LLM 의 추론 능력이 향상 될 수 있음을 검증하기 위한 연구이다.
-
DeepSeek-R1 을 개발하기 위한 파이프라인을 소개한다.
- 향상된 추론 패턴을 발견하고, 인간 선호에 맞추는 것을 목표로 하는 2 개의 RL stage
- 모델의 추론 및 비추론 능력의 기초가 되는 2 개의 SFT 단계가
포함되어 있다.
Distillation : Smaller Models Can Be Powerful Too
-
더 큰 모델의 추론 패턴을 더 작은 모델로 distilled 할 수 있고, 작은 모델에 RL 을 직접적으로 이용하여 발견된 추론 패턴 보다 더 나은 성능을 얻을 수 있음을 보여준다.
-
DeepSeek-R1 에서 생성된 추론 데이터를 사용하여, research community 에서 널리 사용되는 여러 dense model 을 미세조정 하였다.
-
평가 결과는 distilled 된 더 작은 dense model 이 benchmarks 에서 예외적으로 더 좋은 성능을 나타내는 것을 보여준다.
-
DeepSeek-R1-Distill-Qwen-7B 는 AIME 2024 에서 55.5%를 달성하여 QwQ-32B-Preview 를 넘어섰다. 또한 deepSeek-R1-Distill-Qwen-32B 는 AIME 2024 에서 72.6%, MATH-500 에서 94.3%, LiveCodeBench 에서 57.2% 를 기록했다. 이러한 결과는 이전 open-source 모델들을 넘어서고, o1-mini 와 비교할 수 있다.
# Define tasks aime24 = LightevalTaskConfig( name="aime24", suite=["custom"], prompt_function=aime_prompt_fn, hf_repo="HuggingFaceH4/aime_2024", hf_subset="default", hf_avail_splits=["train"], evaluation_splits=["train"], few_shots_split=None, few_shots_select=None, generation_size=32768, metric=[expr_gold_metric], version=1, ) math_500 = LightevalTaskConfig( name="math_500", suite=["custom"], prompt_function=prompt_fn, hf_repo="HuggingFaceH4/MATH-500", hf_subset="default", hf_avail_splits=["test"], evaluation_splits=["test"], few_shots_split=None, few_shots_select=None, generation_size=32768, metric=[latex_gold_metric], version=1, ) -
Qwen2.5 와 Llama 3 시리즈를 기반한 distilled 된 1.5B, 7B, 8B, 14B, 32B 및 checkpoint 를 open-source 로 제공한다.
1.2 Summary of Evaluation Results
Resoning tasks
-
DeepSeek-R1 은 AIME 2024 에서 79.8% Pass@1 점수를 달성하여 OpenAI-o1-1217 을 약간 넘어섰다. MATH-500 에서는 97.3% 라는 인상적인 점수를 달성하여 OpenAI-o1-1217 과 동등한 성능을 발휘하고 다른 모델보다 상당히 뛰어난 성능을 발휘한다.
-
코딩 관련 task 에서 DeepSeek-R1 은 competition 에서 96.3% 의 인간 참가자들을 앞서는 Codeforces 의 2,029 Elo 등급을 달성하므로써, code competition task 에서 전문가 레벨을 보여준다.
Knowledge
-
MMLU, MMLU-Pro 및 GPQA Diamond 와 같은 벤치마크에서 DeepSeek-R1 은 뛰어난 결과를 달성하여, MMLU 에서 90.8%, MMLU-Pro 에서는 84.0%, 그리고 GPQA Diamond 에서는 71.5% 점수로 DeepSeek-V3 을 크게 앞선다.
-
이러한 벤치마크에서 성능은 OpenAI-o1-1217 보다 약간 낮지만, DeepSeek-R1 은 다른 closed-source 모델을 능아하여 educational tasks 에서 경쟁력을 보여준다.
-
사실 benchmark SimpleQA 에서, DeepSeek-R1 은 DeepSeek-V3 보다 성능이 뛰어나서 사실 기반 쿼리를 처리하는 능력을 입증했다. 이 벤치마크에서 OpenAI-o1 이 4o 를 뛰어넘는 경우에도 유사한 트랜드가 관찰 된다.
Others
-
DeepSeek-R1 은 또한 창의적인 글쓰기, 일반적인 질문과 답변, 편집, 요약 그리고 그 이상의 광범위한 작업에 뛰어난 모델이다.
-
AlpacaEval 2.0 에서 87.6% 의 인상적인 length-controlled win-rate (길이 제어 승률 )과 ArenaHard 에서 92.3% 의 승률을 달성하며, 시험 중심이 아닌 질문을 지능적으로 처리할 수 있는 강력한 능력을 보여준다.
-
또한 DeepSeek-R1 은 긴 context 이해가 요구되는 작업에서 뛰어난 성능을 보여서, long-context 벤치마크에서 DeepSeek-V3 보다 대체로 뛰어난 성능을 보여준다.
length-controlled win-rage
답변의 길이를 적절하게 조정하여 응답을 제공하는 능력.
2. Approach
2.1 Overview
-
이번 연구에서는 SFT (Supervised Fine-Tuning) 을 사용하지 않는 cold start 로써 대규모의 강화학습 (RL) 을 통해 추론 능력을 크게 향상 시킬 수 있음을 보여주었다.
-
무엇보다도, 작은 양의 cold-start 데이터를 포함하면 성능을 더욱 향상 시킬 수 있다.
- ( 1 ) SFT 데이터 없이 기본 모델에 직접 RL 을 적용하는 DeepSeek-R1-Zero 와
- ( 2 ) 수 천개의 긴 Chain-of-Thought (CoT) 예시를 가지고 fine-tuned 한 checkpoint 로 시작해 RL 을 적용한 DeepSeek-R1 을 소개한다.
- ( 3 ) DeepSeek-R1 의 추론 능력을 작은 dense models 에 distill 한다.
2.2 DeepSeek-R1-Zero : Reinforcement Learning on the Base Model
-
강화 학습은 이전 연구 (Shao et al., 2024; Wang et al., 2023) 에서 증명된 바와 같이, 추론 작업들에서 상당한 효율성을 보여주었다. 그러나 이러한 작업은 supervised data 에 크게 의존하여 수집하기 위한 시간이 많이 걸린다.
-
이 섹션에서는 순수 강화학습 프로세스를 통한 자가 진화 (self-evolution) 에 중점을 두고 어떠한 supervised data 없이 추론 능력을 개발할 수 있는 LLMs 의 잠재력을 탐구한다.
2.2.1 Reinforcement Learning Algorithm
Group Relative Policy Optimization
RL 의 훈련 비용을 절약하기 위해서 일반적으로 policy model 과 동일한 크기의 critic model 을 생략하고, 대신 group score 로부터 baseline 을 추정하는 Group Relative Policy Optimization (GRPO) (Shao et al., 2024), 를 채택한다. 구체적으로 각 질문 에 대해서 GRPO 는 이전 정책 에서 출력 group 을 sampling 후, 다음 아래의 목적 함수를 최대화 함으로써 policy model 를 최적화 한다.
여기서 과 는 hyper-parameter 이고, 는 각 그룹 내의 출력들을 대응하는 rewards 를 사용하여 계산된 Advantage 값이다.
GRPO 의 목적 함수 는 policy model 를 최적화 하여 성능을 향상시키는 역할을 한다.
Policy update
per_token_loss = torch.exp(per_token_logps - per_token_logps.detach()) * advantages.unsqueeze(1)-
는 이전 정책 이므로, detach 하여 gradient 계산에서 제외하도록 한다.
-
새로운 정책 와 이전 정책 에 따라서 질문 가 주어졌을 때 출력 을 선택할 확률 의 비율을 계산하여 가중치를 부여한다.
-
는 Advantage 값으로, 특정 행동 의 reward 값 가 평균적인 행동의 reward 보다 얼마나 좋은지를 나타낸다.
-
Policy update 항이 크면, 특정 행동 를 더 자주 선택하도록 학습을 진행한다.
Clipping
-
Policy 가 divergence 하거나 gradient 의 derivative 의 허용 범위를 넘어서서 불안정해 지는 것을 막기 위한 방법론이다.
-
policy 의 update 가 너무 크게 되면 기존 정책과 너무 다른 행동을 학습하거나, 이미 학습한 좋은 행동을 잃어버릴 가능성이 있다.
-
policy 비율의 변화가 너무 크지 않도록, 범위 내에서 제한하여 안정된 학습을 유도한다.
사실, hugging-face 팀에서 clipping 등은 내부적으로 잡아줄 것 이라 생각한다.
Penalty weight
# Compute the KL divergence between the model and the reference model
per_token_kl = torch.exp(ref_per_token_logps - per_token_logps) - (ref_per_token_logps - per_token_logps) - 1-
policy 가 reference policy 와 너무 다르게 변하지 않도록 조절한다.
-
값이 크면 두 분포가 많이 다르게 되므로, penalty 를 크게 줘서 기존 정책과의 차이를 줄이는 방향으로 학습이 되고, 값이 작아지면 적은 penalty 를 줘서 좀 더 자유로운 방향으로 학습 시킨다.
-
그러면 reference policy 가 중요한데, 바로 직전의 policy 혹은 이미 학습 해두고 잘 나왔던 policy 등을 기준으로 삼는다.
Advantage
# Normalize the rewards to compute the advantages
mean_grouped_rewards = mean_grouped_rewards.repeat_interleave(self.num_generations, dim=0)
std_grouped_rewards = std_grouped_rewards.repeat_interleave(self.num_generations, dim=0)
advantages = (rewards - mean_grouped_rewards) / (std_grouped_rewards + 1e-4)-
RL 에서는 Advantage 값을 사용하여 현재 선택된 행동이 얼마나 좋은지 측정하고 높을 수록 그 행동을 자주 선택하고 낮을 수록 선택하지 않게 학습한다.
-
GRPO 는 Critic 모델이 없다고 하는데, Actor-Critic 모델이라고 해서, Actor 는 State 가 주어졌을 때 Action 을 결정하는 모델이고, Critic 은 그 행동 시에 State 의 Value 를 평가하게 되는데, 평가 모델 대신에 reward 값 만을 사용하여 계산한다.
-
reward 값 만으로 평가하므로, 평가 모델을 따로 학습 하지 않아도 되므로, 계산 비용이 줄어든다.
# Initialize the GRPO trainer
trainer = GRPOTrainer(
model=model_args.model_name_or_path,
reward_funcs=reward_funcs,
args=training_args,
train_dataset=dataset[script_args.dataset_train_split],
eval_dataset=dataset[script_args.dataset_test_split] if training_args.eval_strategy != "no" else None,
peft_config=get_peft_config(model_args),
)
# Train and push the model to the Hub
trainer.train()
# Save and push to hub
trainer.save_model(training_args.output_dir)
if training_args.push_to_hub:
trainer.push_to_hub(dataset_name=script_args.dataset_name)그런데, hugging face 덕에
GRPO를 이렇게만 사용하여 사용할 수 있다는 것이 너무 놀라웠다.
2.2.2 Reward Modeling
reward 는 RL 의 최적화 방향을 결정하는 training signal 의 source 이다. DeepSeek-R1-Zero 를 훈련시키기 위해 주로 두 가지 유형의 reward 오 구성된 rule-based 기반 reward system 을 채택한다.
-
Accuarcy rewards
accuracy reward model 은 응답이 알맞는지, 올바른지 평가한다.
- 예를 들어서, deterministic 한 결과가 포함된 수학 문제의 경우, 모델은 지정된 형식 ( 예 : box 안에 ) 으로 최종 답을 제공해야 하므로, 믿을 수 있는 정확성의 rule-based 검증이 요구된다.
- 마찬가지로 LeetCode 문제의 경우, compiler 는 사전 정의된 테스트 사례를 기반으로 피드백을 생성하기 위해 사용할 수 있다.
def accuracy_reward(completions, solution, **kwargs): """Reward function that checks if the completion is the same as the ground truth.""" contents = [completion[0]["content"] for completion in completions] rewards = [] for content, sol in zip(contents, solution): gold_parsed = parse(sol, extraction_mode="first_match", extraction_config=[LatexExtractionConfig()]) if len(gold_parsed) != 0: # We require the answer to be provided in correct latex (no malformed operators) answer_parsed = parse( content, extraction_config=[ LatexExtractionConfig( normalization_config=NormalizationConfig( nits=False, malformed_operators=False, basic_latex=True, equations=True, boxed=True, units=True, ), # Ensures that boxed is tried first boxed_match_priority=0, try_extract_without_anchor=False, ) ], extraction_mode="first_match", ) # Reward 1 if the content is the same as the ground truth, 0 otherwise reward = float(verify(answer_parsed, gold_parsed)) else: # If the gold solution is not parseable, we reward 1 to skip this example reward = 1.0 print("Failed to parse gold solution: ", sol) rewards.append(reward) return rewards -
Format rewards
html 로 format reward 를 만든다는거지?
Accuarcy rewards 모델 외에도
<think>와</think>tag 사이에 thinking process 를 배치하도록 모델에 강제하는 format reward model 을 사용한다.def format_reward(completions, **kwargs): """Reward function that checks if the completion has a specific format.""" pattern = r"^<think>.*?</think><answer>.*?</answer>$" completion_contents = [completion[0]["content"] for completion in completions] matches = [re.match(pattern, content) for content in completion_contents] return [1.0 if match else 0.0 for match in matches] -
DeepSeek-R1-Zero 를 개발 시 outcome 또는 process neural reward model 을 적용하지 않는데,
- 대규모 강화학습 과정에서 neural reward model 이 reward hacking 으로 부터 취약할 수 있고,
- reward model 을 다시 훈련하려면 추가적인 training resource 가 필요하고,
- 전체 training pipeline 이 복잡해지기 때문이다.
- outcome reward model
최종 결과를 평가하는 모델
- process-based reward model
중간 과정의 품질을 평가하는 모델
- reward hacking
모델이 보상을 최대화 하려고 의도하지 않는 방식으로 학습하는 현상
이와 같은 이유로 위의 모델들을 사용하지 않아서 연산 비용이 절감되고, 학습 과정의 단순화가 된다.
기본이 되는 LLM 모델을 가지고 critic 모델 없이, reward 로만 구성하여 학습하니, 인건비와 리소스가 엄청 줄어드는구나.
2.2.3 Training Template
-
DeepSeek-R1-Zero 를 훈련하기 위해서 기본 모델이 specified instructions 를 준수하도록 가이드를 하는 간단한 템플릿을 설계하는 것부터 시작한다.
-
Table 1 에서 볼 수 있듯이, template 은 DeepSeek-R1-Zero 가 먼저 추론 과정을 생성한 후에 최종 답변을 생성하도록 요구한다.
Table 1

DeepSeek-R1-Zero 전용 Template. prompt 는 training 중에 구체적인 추론 질문으로 대체된다.
SYSTEM_PROMPT = (
"A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant "
"first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning "
"process and answer are enclosed within <think> </think> and <answer> </answer> tags, respectively, i.e., "
"<think> reasoning process here </think><answer> answer here </answer>"
)
# Format into conversation
def make_conversation(example):
return {
"prompt": [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": example["problem"]},
],
}
dataset = dataset.map(make_conversation)- RL 프로세스 중에서 모델의 자연스러운 진행을 정확하게 관찰할 수 있도록 하기 위해서,
- 이 구조적인 형식을 의도적으로 제한하며,
- reflective reasoning 을 요구하거나,
- 특정 problem-solving 전략을 유도하는 등의 content 특징적인 bias 를 피한다.
즉, 모델이 무조건 reasoning process 후에 final answer 를 단계적으로 생성하도록 강제한다는 의미.
그런데, hugging face 덕에 GRPO 를
# Initialize the GRPO trainer
trainer = GRPOTrainer(
model=model_args.model_name_or_path,
reward_funcs=reward_funcs,
args=training_args,
train_dataset=dataset[script_args.dataset_train_split],
eval_dataset=dataset[script_args.dataset_test_split] if training_args.eval_strategy != "no" else None,
peft_config=get_peft_config(model_args),
)
# Train and push the model to the Hub
trainer.train()
이렇게 만으로 쓸 수 있다는 것이 경이롭다.
2.2.4 Performance, self-evolution Process and Aha Moment of DeepSeek-R1-Zero
Performance of DeepSeek-R1-Zero
Table 2
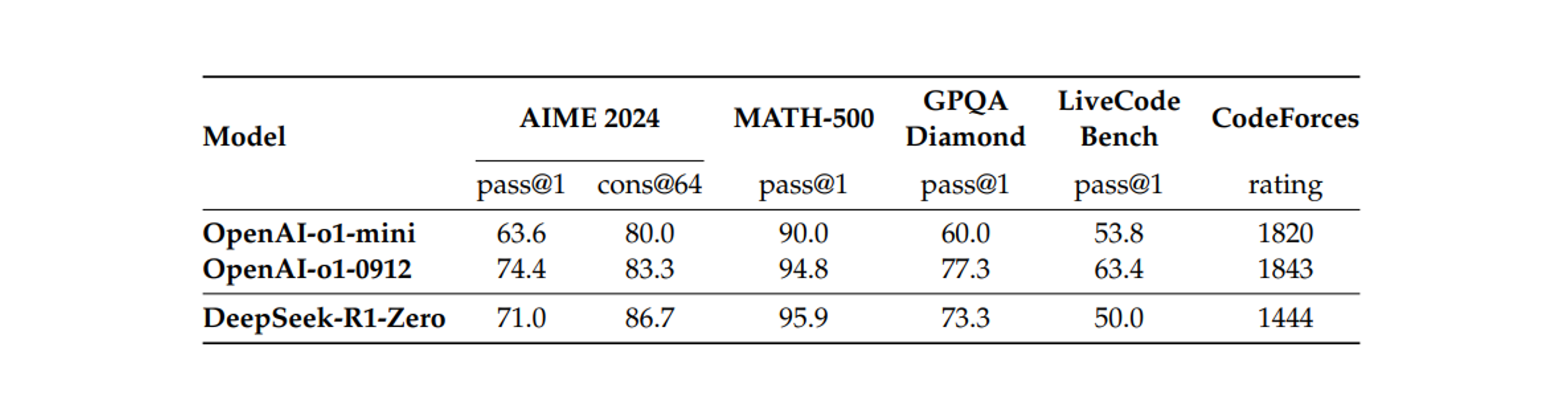
추론 관련 (reasoning-related) 벤치마크에서 DeepSeek-R1-Zero 와 OpenAI o1 모델을 비교.
Figure 2
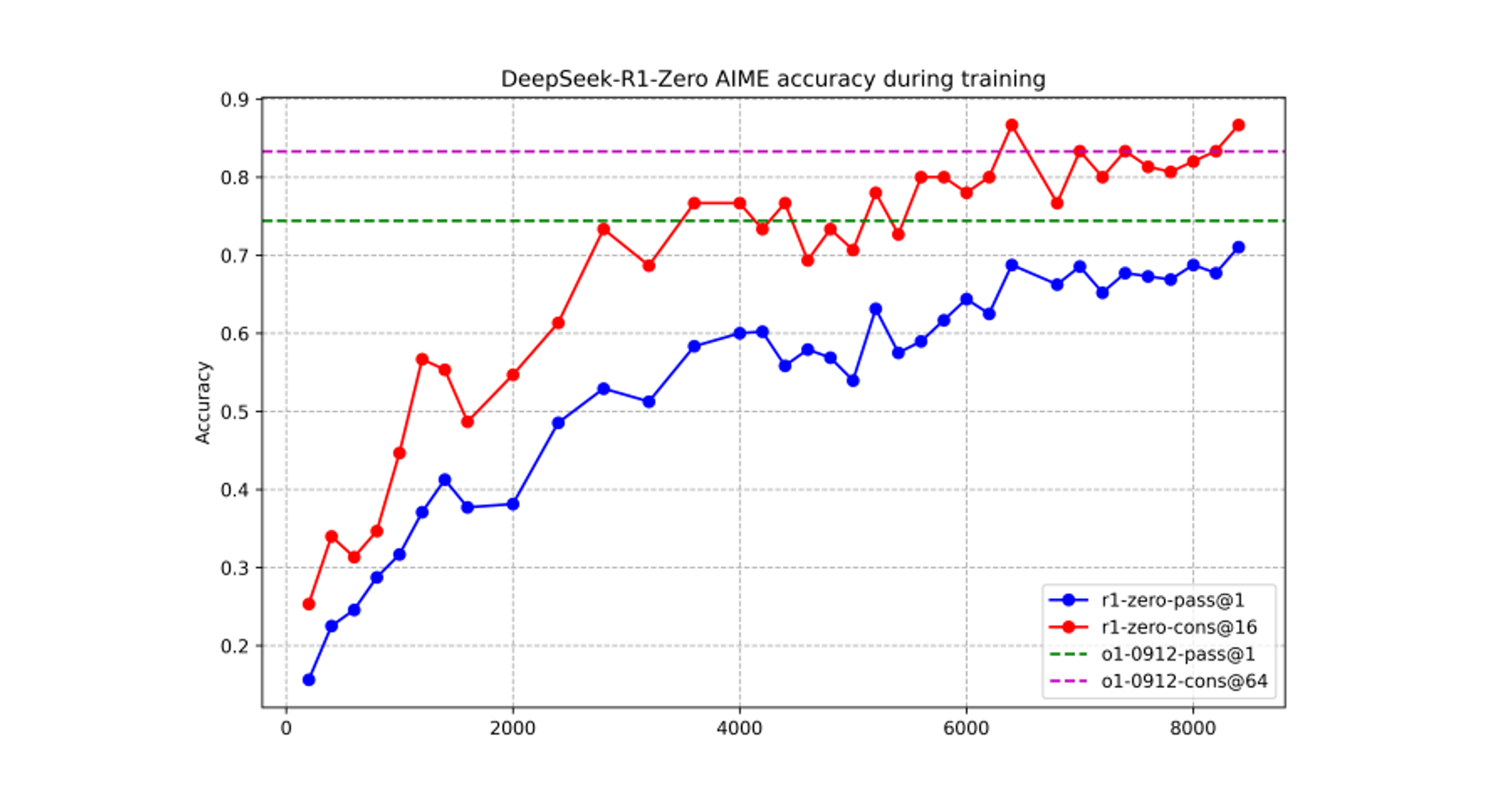
-
training 중인 DeepSeek-R1-Zero 의 AIME 정확도. 각 질문에 대해서 16 개의 응답을 샘플링 하고, 전체 평균 정확도를 계산하여 안정적인 평가를 보장한다.
-
Figure 2 는 RL training process 전반에 걸친 AIME 2024 벤치마크에서 DeepSeek-R1-Zero 의 performance trajectory 를 보여준다. 그림과 같이 DeepSeek-R1-Zero 는 RL 훈련이 진행됨에 따라서 꾸준하고 일관성 있게 성능 향상을 보여준다.
-
특히 AIME 2024 의 평균 pass@1 점수는 초기에 15.6% 에서 71.0% 로 크게 증가하며 OpenAI-o1-0912 와 비슷한 performance levels 에 도달했다. 이러한 상당한 향상은 시간이 지남에 따라 모델의 성능을 최적화 하는데 있어서 RL 알고리즘의 효과를 강조한다.
-
Table 2 는 다양한 추론-관계 (reasoning-related) 벤치마크에서 DeepSeek-R1-Zero 와 OpenAI 의 o1-0912 모델 간의 비교 분석을 제공한다. 연구 결과 에서는, RL 이 DeepSeek-R1-Zero 는 어떠한 supervised fine-tuning data 없이 robust 한 추론 능력을 달성한다는 것을 보여준다.
-
이것은 RL 혼자 만을 통해 효과적으로 학습하고, 일반화 하는 모델의 능력을 강조하므로 주목할 만한 성과 이다. 또한 DeepSeekR1-Zero 의 성능은 majority voting 을 적용하여 더욱 강화될 수 있다.
Self-evolution Process of DeepSeek-R1-Zero
-
DeepSeek-R1-Zero 의 자가 진화 (self-evolution) process 는 RL 이 어떻게 모델이 추론 기능을 자율적으로 향상시키도록 drive 할수 있다는 것을 보여주는 흥미로운 시연이다.
-
기본 모델에서 직접 RL 을 시작함으로써 supervised fine-tuning stage 의 영향 없이 모델의 진행 상황을 자세히 모니터링 할 수 있다. 이러한 접근 방식은 특히 복잡한 추론 작업을 처리하는 능력의 측면에서 모델이 시간이 지남에 따라서 어떻게 발전 하는 지에 대한 명확한 관점을 제공한다.
Figure 3
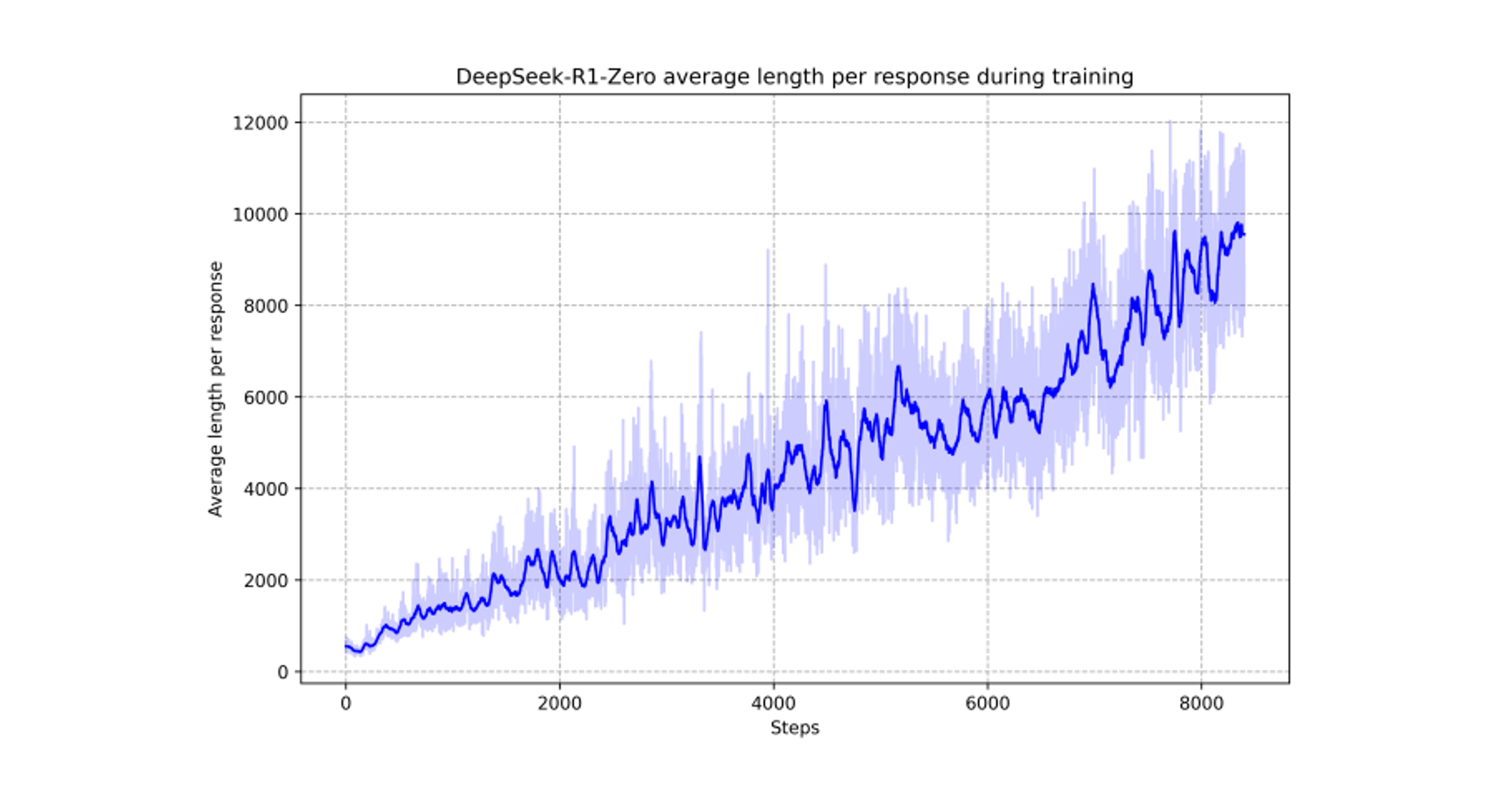
RL process 중에 training set 에 대한 DeepSeek-R1-Zero 의 평균 응답 길이 이다. DeepSeek-R1-Zero 는 더 많은 생각하는 시간을 통해서 추론 작업들을 해결하는 방법을 자연스럽게 배운다.
-
Figure 3 에서 볼 수 있듯이, DeepSeek-R1-Zero 의 사고 시간 (thinking time) 은 훈련 과정 전반에 걸쳐서 지속적으로 향상된다. 이러한 개선은 외부 조정의 결과가 아니라, 모델 안의 내재적 개발의 결과이다.
-
DeepSeek-R1-Zero 는 확장된 test-time 계산을 활용하여 점점 더 복잡해지는 추론 작업을 해결하는 능력을 자연스럽게 얻게 된다. 이 연산은 수백, 수천 개 의 추론 토큰들 생성하는 과정을 포함하고, 이를 통해서, 모델이 thought process 를 더 깊이 탐색하고 개선할 수 있도록 한다.
-
자가 진화 (self-evolution) 의 가장 주목할 만한 것들 중에 하나는 테스트 시간 계산이 증가함으로써 정교한 행동이 나타난다는 것이다. 모델이 이전 단계를 다시 검토하고 재평가하는 과정 (reflection) 이나, problem-solving 을 위한 대체 접근법 탐색 같은 행동이 자연스럽게 발생한다.
-
이러한 행동은 명시적으로 프로그래밍 되지는 않지만, 강화학습 환경과 모델의 상호작용의 결과로 나타난다. 이러한 자발적인 개발은 DeepSeek-R1-Zero 의 추론 능력을 크게 향상 시켜서 더욱 어려운 작업을 보다 효율적이고 정확하게 처리할 수 있게 해준다.
강화 학습의 장점으로, 상호 작용과 reward 를 통해서 정답을 외우게 하는 것이 아닌, 평가 에 따라서 문제가 많으면 강제하지만, 비슷한 결 이면, 자유롭게 풀어주는 것이 장점으로 보여진다.
Aha Moment of DeepSeek-R1-Zero
Table 3

DeepSeek-R1-Zero intermediate version 의 흥미로운 “aha moment”. 모델은 서람처럼 사고하는 방식(anthropomorphic tone) 으로 다시 생각하는법을 학습한다. 이것은 또한 강화 학습의 강력함과 아름다움을 목격할 수 있는 “aha moment” (깨달음을 주는 순간) 이다.
-
DeepSeek-R1-Zero 훈련 중에 관찰된 특별히 흥미로운 현상은 “아하 순간” 이 발생한다는 것이다. table 3 에서 설명된 대로 이 순간 “aha moment” 은 intermediate 버전에서 발생한다.
-
이 단계에서 DeepSeek-R1-Zero 는 초기 접근 방식을 재평가하여 문제에 더 많은 thinking time 을 할당하는 방법을 배운다. 이 동작은 모델의 추론 능력이 성장하고 있다는 증거일 뿐 아니라 강화학습이 어떻게 예상치 못한 정교한 결과 (추론) 로 이어질 수 있는지를 알려주는 매력적인 예시 이다.
-
문제 해결 방법에 대한 명시적으로 가르치는 대신에 간단히 올바른 인센티브 (reward 환경) 을 제공하기만 하면, 고급 problem-solving 전략을 자율적으로 개발한다.
-
“aha moment” 는 인공 시스템에서 지능의 새로운 레벨을 열어주는 RL 의 잠재력을 일깨워주는 역할을 하며, 미래에는 보다 자율적이고 적응 가능한 모델을 위한 길을 열어준다.
모델 뿐만 아니라, 행동을 관찰하는 연구자들 또한 “aha moment” 하는 순간이다...
나도 보면서 이랬다..
Drawback of DeepSeek-R1-Zero
-
DeepSeek-R1-Zero 는 강력한 추론 능력을 보여주고, 예상치 못한 강력한 추론 동작을 자율적으로 개발하지만, 몇 가지 이슈에 직면해 있다.
-
DeepSeek-R1-Zero 는 가독성이 좋지 않고, language mixing 과 같은 문제로 어려움을 겪는다.
2.3 DeepSeek-R1 : Reinforcement Learning with Cold Start
DeepSeek-R1-Zero 의 유망한 결과에서 영감을 받은 두 가지 자연스러운 질문이 떠오른다.
-
cold start 로써 소량의 고품질 데이터로 통합하여 추론 성능을 더욱 향상 시키거나, 수렴을 가속화 할 수 있을까?
-
명확하고 일관된 Chains of Thought (CoT) 를 생성할 뿐 아니라 강력한 일반 기능을 보여주는 사용자 친화적인 모델을 어떻게 training 할 수 있을까?
이러한 질문을 해결하기 위해 DeepSeek-R1 을 train 하기 위한 파이프라인을 설계한다. 파이프라인은 아래와 같이 4 단계로 구성된다.
2.3.1 Cold Start
-
DeepSeek-R1-Zero 와 달리, 기본 모델로부터 RL training 의 초기의 불안정한 cold start 단계를 방지하기 위해서, DeepSeek-R1 의 경우 작은 양의 긴 CoT 데이터를 구성 및 수집하여 초기 RL actor 로써 모델을 fine-tune 한다.
-
fine-tune 하기 위한 데이터를 수집하기 위해서
- 긴 CoT 를 사용한 few-shot prompting 을 사용하여
- 반성 (reflection) 및 검증을 통해 자세한 답변을 생성하도록 직접 prompting 하고,
- DeepSeek-R1-Zero 출력을 읽을 수 있는 형식으로 수집하여,
- human annotator 가 post-processing 을 통해 결과를 정제 (refining) 한다.
이 작업에서는 수천 개의 cold-start data 를 수집하여 DeepSeek-V3-Base 를 RL 의 시작접으로 fine-tune 한다. DeepSeek-R1-Zero 와 비교하여 cold start data 의 장점은 아래와 같다.
Readability
-
DeepSeek-R1-Zero 의 주요 제한 사항은 컨텐츠가 읽기가 적합하지 않은 경우가 종종 있다는 것이다. 응답에는 multiple 언어들이 혼합되어 있거나, 사용자에게 답변을 강조하기 위한 markdown 형식이 부족할 수 있다.
-
대조적으로, DeepSeek-R1 에 대해 cold-start data 를 생성할 때에는 각 응답의 끝에 요약을 포함하고, reader-friendly (사용자 친화적이지) 않은 응답을 필터링 하여 읽기 쉬운 패턴을 설계한다. 여기서는 출력 형식을 아래와 같이 정의한다.
|special_token|<reasoning_process>|special_token|<summary>여기서 추론 프로세스는 쿼리에 대한 CoT 이고, summary 는 추론 결과를 요약하는 데 사용한다.
Potential
-
인간의 사전 데이터 (data with human priors) 를 사용하여 cold-start data 의 패턴을 신충하게 설계함으로써, DeepSeek-R1-Zero 에 비해 더 나은 성능을 관찰한다.
-
반복적인 훈련이 모델을 추론하기 위한 더 나은 방법이라고 믿는다.
2.3.2 Reasoning-oriented Reinforcement Learning
-
cold start data 로 DeepSeek-V3-Base 를 fine-tuning 한 후에 DeepSeek-R1-Zero 에서 사용된 것과 동일한 대규모 강화 학습 훈련 프로세스를 적용한다.
-
이 단계는 모델의 추론 능력을 향상 시키는데 중점을 두고 있으며, 특히 코딩, 수학, 과학 그리고 논리적 추론과 같은 명확한 솔루션이 있는 잘 정의된 문제들과 같은 추론 중심 (reasoning-intensive) 작업에서 그 성능을 강화하는데 집중한다.
-
training process 에서 특히 RL prompt 에 다국어 가 포함될 때 CoT 가 language mixing 이 종종 나타나는 것을 관찰했다.
-
language mixing 이슈를 완화하기 위해서 RL training 중에 CoT 에서 목표 언어 (target language) 단어의 비율로 계산되는 언어 일관성 보상 (language consistency reward) 을 도입한다.
latex_gold_metric = multilingual_extractive_match_metric( language=Language.ENGLISH, fallback_mode="first_match", precision=5, gold_extraction_target=(LatexExtractionConfig(),), pred_extraction_target=(ExprExtractionConfig(), LatexExtractionConfig()), aggregation_function=max, )expr_gold_metric = multilingual_extractive_match_metric( language=Language.ENGLISH, fallback_mode="first_match", precision=5, gold_extraction_target=(ExprExtractionConfig(),), pred_extraction_target=(ExprExtractionConfig(), LatexExtractionConfig()), aggregation_function=max, ) -
절제 실험에서는 이러한 alignment 로 인해서 모델의 성능이 조금 저하 시킨다는 것으로 나타났지만, 이 보상은 인간의 선호도 (human preferences) 와 일치하여 더욱 가독성을 높이는 효과를 불러왔다.
-
마지막으로 추론 작업의 정확성과 언어 일관성에 대한 보상을 직접 합산하여 최종 보상을 구성한다. 추론 작업에 대해 수렴할 때까지 fine-tune 된 모델에 RL training 을 적용한다.
2.3.3 Rejection Sampling and Supervised Fine-Tuning
-
추론 중심 (reasoning-oriented) 의 강화학습 (RL) 이 수렴하면, 우리는 그 결과로 나온 checkpoint 를 활용하여 그 다음 단계의 SFT (Supervised Fine-Tuning) data 를 수집한다.
-
초기 cold-start data 는 주로 추론에 초점을 맞추는 것과 달리, 이 단계에서는 다른 도메인의 데이터를 통합하여, 모델의 글쓰기, 역할 수행 (role-playing), 그리고 다른 범용적인 작업 (general-purpose tasks) 능력을 강화한다.
구체적으로 아래 설명대로 데이터를 생성하고 모델을 fine-tune 한다.
Resoning data
-
추론 프롬프트 (reasoning prompts) 를 선별 (curate) 하고, 위에서의 RL training 으로 나온 checkpoint 로부터 rejection sampling 을 통해 , 추론 궤적 (reasoning trajectories) 을 생성한다.
-
이전 단계에서는 rule-based reward 를 사용하여 평가할 수 있는 데이터만 포함했다.
-
현재 단계에서는 추가적인 데이터를 포함하여 dataset 을 확장 하고, 그 중 일부는 ground-truth 와 모델 예측을 DeepSeek-V3 에 입력하여 평가 받도록 하고, 이것을 generative reward model 로 사용한다.
-
또한 모델 출력이 때때로 혼란스럽고, 읽기 어렵기 때문에 혼합 언어(mixed languaged) , 긴 문단 그리고 코드 블럭으로 Chain-of-Thought 를 필터링했다.
-
각 prompt 에 대해서 여러 응답을 샘플링하고, 올바른 것들만 유지한다. 전체적으로 약 600,000 개의 추론 관련 training sample 을 수집한다.
Non-Reasoning data
-
작문, 사실적 QA, 자가 인식 (self-cognition) 및 번역과 같은 비추론 데이터의 경우 DeepSeek-V3 파이프라인을 채택하고 DeepSeek-V3 의 SFT dataset 의 일부분을 재사용한다.
-
일부 비추론 작업의 경우, DeepSeek-V3 를 호출하여 질문에 답하기 전에, prompting 을 통해서 잠재적인 Chain-of-Thought 를 생성한다.
-
그러나 “hello” 와 같은 간단한 질문 의 경우, 응답으로 CoT 를 제공하지 않는다. 결국 추론과 관련없는 총 200,000 개의 훈련 샘플을 수집했다.
위에서 선별한 약 800,000 개의 샘플의 데이터 셋을 사용하여 DeepSeek-V3-Base 의 2 epochs 를 fine-tune 한다.
2.3.4 Reinforcement Learning for all Scenarios
- 모델을 인간 선호도에 더욱 맞추기 위해서 모델의 유용성 (helpfulness) 과 무해성 (harmlessness) 을 개선하는 동시에 추론 기능을 더욱 정교하게 다듬는 것을 목표로 하는 2차 강화 학습 단계 (secondary reinforcement learning) 를 구현한다.
구체적으로 보상 신호와 다양한 prompt 분포의 조합을 사용하여 모델을 훈련한다.
-
추론 데이터의 경우, rule-based 보상을 활용하여 수학, 코드, 그리고 논리적 추론 도메인의 학습 프로세스 (learning process) 를 가이드하는 DeepSeek-R1-Zero 에 설명된 방법론을 준수한다.
-
일반 데이터의 경우, 복잡하고 미묘한 시나리오에서 인간의 선호도를 잡아내기 위해서 보상 모델을 사용한다.
-
DeepSeek-V3 파이프라인을 기반으로 하며, 유사한 선호 쌍 과 training prompt 분포를 채택한다.
-
모델의 유용성 (helpfulness)
- 유용성 (helpfulness) 을 향상시키기 위해서 최종 요약에만 집중하여,
- 응답이 사용자에게 얼마나 유용하고 관련성이 높은지를 강조하는 동시에,
- 기본적인 추론 과정 (underlying reasoning process) 에 대한 간섭을 최소화 하도록 보장한다.
-
모델의 무해성 (harmlessness)
- 무해성 (harmlessness) 를 위해서 추론 과정과 요약을 모두 포함하여,
- 모델의 전체 응답을 평가하여,
- 생성 프로세스 (generation process) 중에 발생할 수 있는 잠재적인 위험, 편견, 또는 유해한 컨텐츠를 식별하고 완화한다.
-
궁극적으로 보상 신호 (reward signals) 와 다양한 데이터 분포 (diverse data distribution) 의 통합을 통해서 유용성과 무해함을 우선시하면서 추론이 뛰어난 모델을 train 할 수 있다.
2.4 Distillation : Empower Small Models with Reasoning Capability
-
DeepSeek-R1 과 같은 추론 기능을 더욱 효율적인 소형 모델에 장착하기 위해서 DeepSeek-R1 으로 선별된 800k sample 을 사용하여 Qwen(Qwen, 2024b) 및 Llama (AI@Meta, 2024) 와 같은 open-source 모델을 직접 fine-tune 했다.
-
연구 결과에 따르면, 이 간단한 distillation 방법은 더 작은 모델의 추론 능력을 크게 향상시킨다.
-
여기서 사용하는 기본 모델은 Qwen2.5-Math-1.5B, Qwen2.5-Math-7B, Qwen2.5-14B, Qwen2.5-32B, Llama-3.1-8B, 그리고 Llama-3.3-70B-Instruct 이다. Llama 3.3 은 Llama-3.1 보다 추론 능력이 약간 더 좋기 때문에 선택한다.
distilled 모델의 경우 SFT 만 적용하고, RL stage 를 포함하면 모델 성능이 크게 향상될 수 있음에도 불구하고 SFT 만 적용하고 RL 단계는 포함하지 않는다.
conclusion
실제 Experiment 도 추가로 읽어볼 예정이지만, 너무 길어져서 끊고 간다.
원래 강화학습의 environment 를 만드는게 일이고, critic model 에 대한 가치에 대한 평가 모델이 리소스로 많이 잡아먹지만, reward 로 끝낼 수 있는 이유가, LLM 이 만들어졌기 때문이다.
Aha Moment 도 유레카 느끼는 희열을 논문으로만 접한 나로써도 1/10000 정도 이겠지만, 꽤 충격적으로 보여졌다. Distillation, MoE 등 모두 경량화와 효율성을 모두 가져가는 방법론 들이여서, 점점 더 빠른 발전이 이루어 질듯 보인다.
cold-start 보다 약간의 SFT 힌트 데이터를 가지고 학습 한 후에 그 내용을 가지고 강화학습에 적용한다는 것도 아름다운 방법으로 보여진다. 단 약 800,000 만 데이터의 2epoch 을 자가 학습 후에 Q-A 쌍으로 하는 것이 아닌, reward 평가로 가는 것은 굉장히 센세이션으로 보여진다.
뒤에서 방법론으로 정리할 예정이지만, Supervised Learning 과 Reinforcement Learning 의 차이는 Loss 최소화 와 action 에 따른 reward 체계로 Policy 학습을 생각해 볼 수 있다. 예전부터 느끼는 부분은 인간처럼의 학습은 강화학습이 맞다고 생각한다.

감사합니다. 덕분에 GRPOTrainer 의 존재를 알게되었네요.
논문 정리도 간간히 들러서 참고하게 될 듯 합니다.