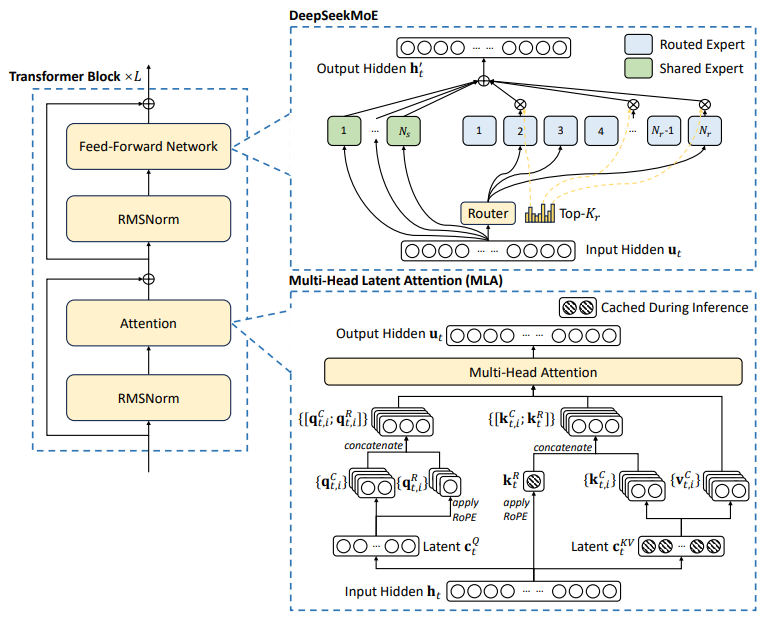
실제 DeepSeek 구조에서 4 가지만 집고 넘어가보자.
1. MLA (Multi-Head Latent Attention)
Understanding architecture
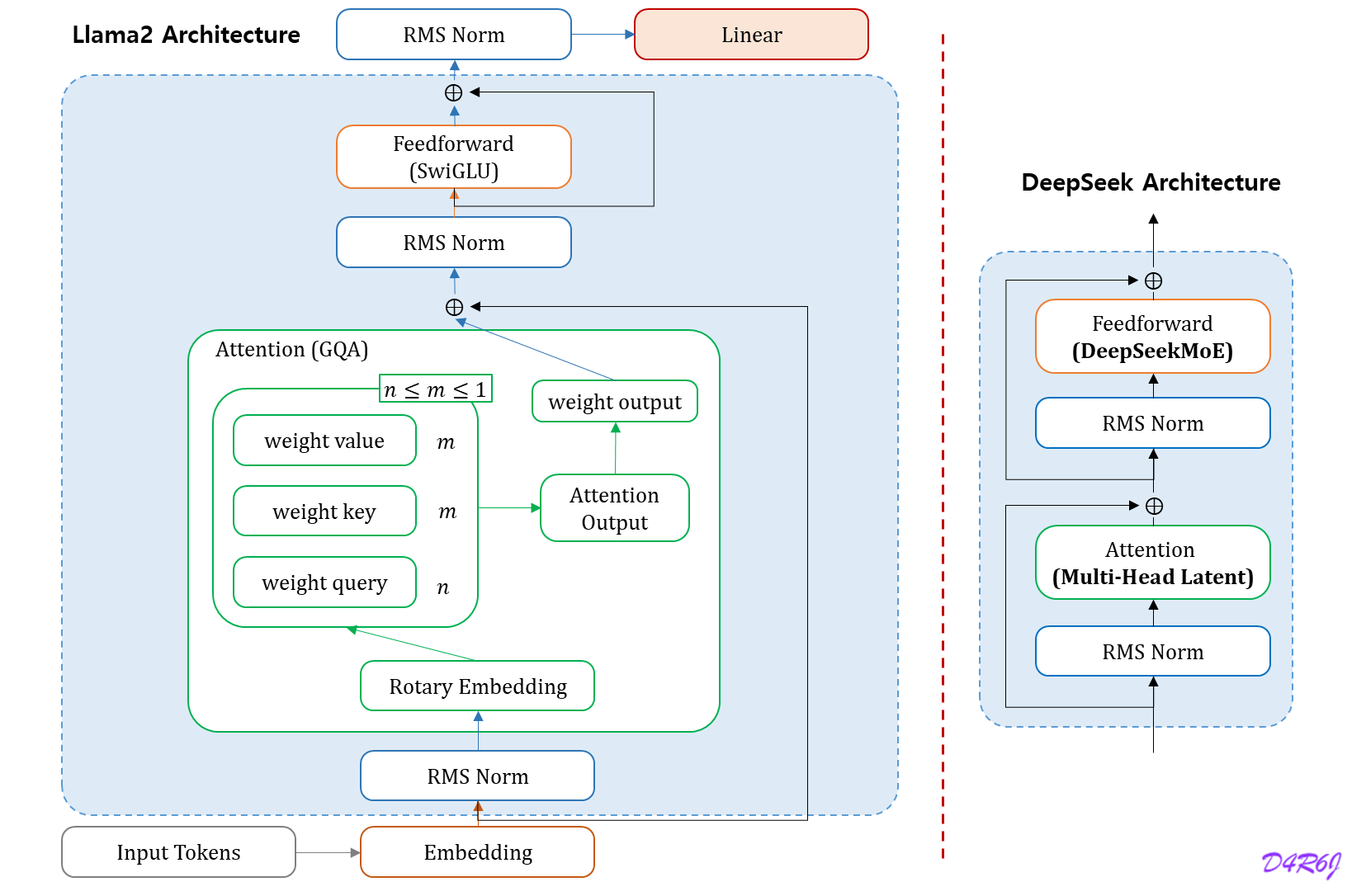
Llama 2 의 구조를 살펴보면, 현재도 Transformer Block 은 변하지 않았다.
[ Llama 2 ] model analysis and code review. 참고.
DeepSeek 전체 구조도 별반 다르지 않지만, 내부 블록들이 어떻게 추가/변경 되었는지 알아보자.
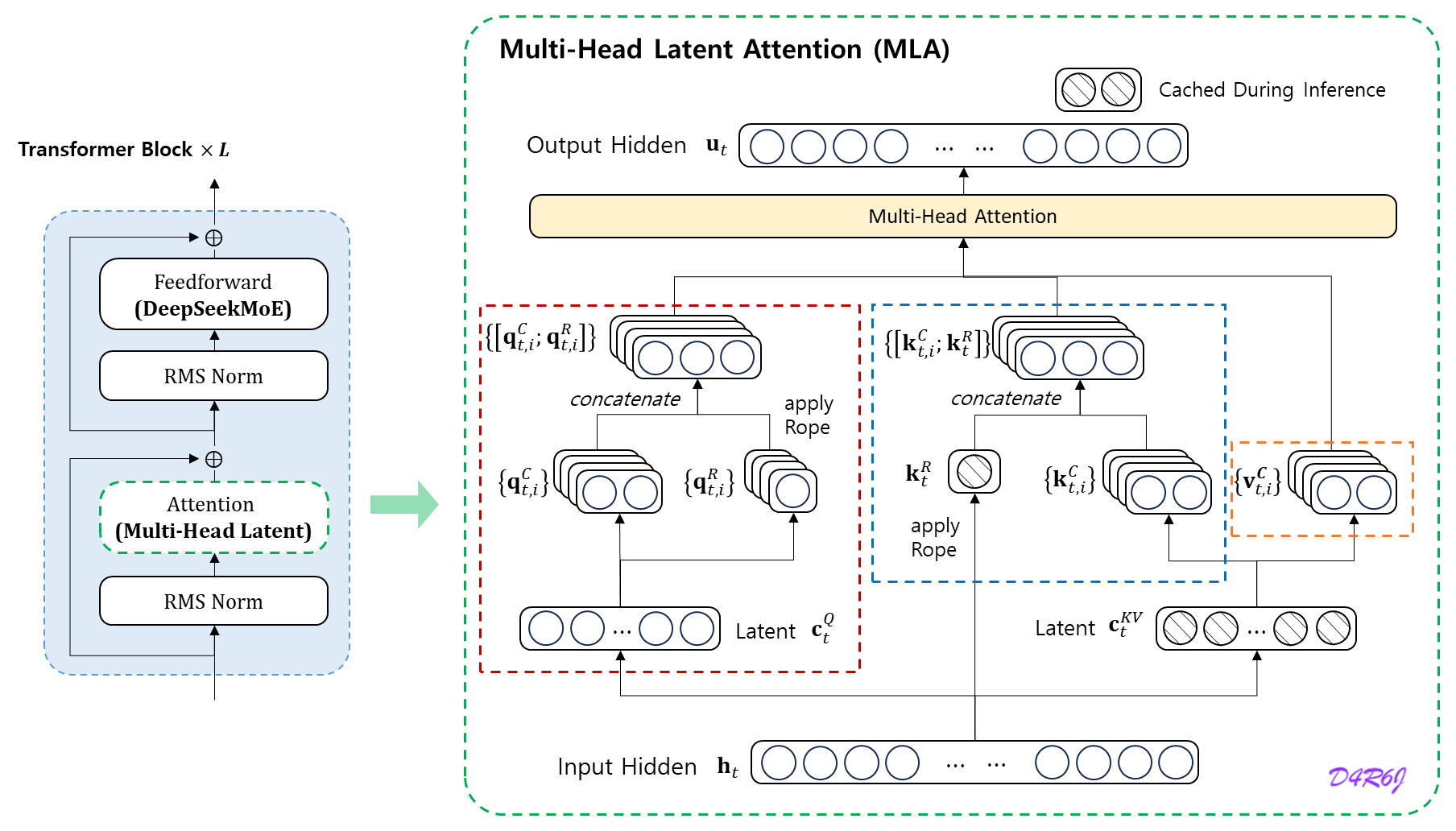
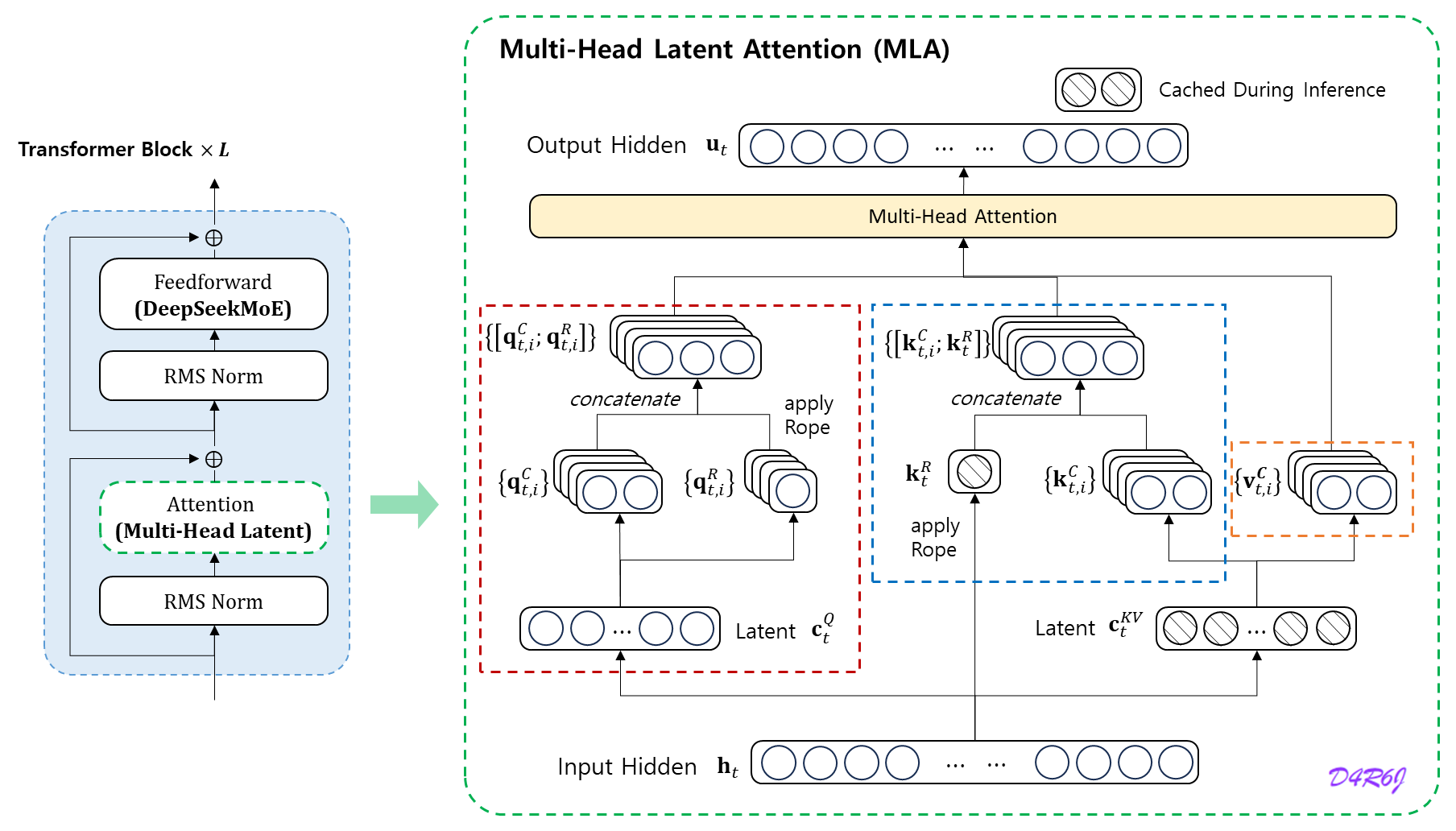
MLA (Multi-Head Latent Attention)
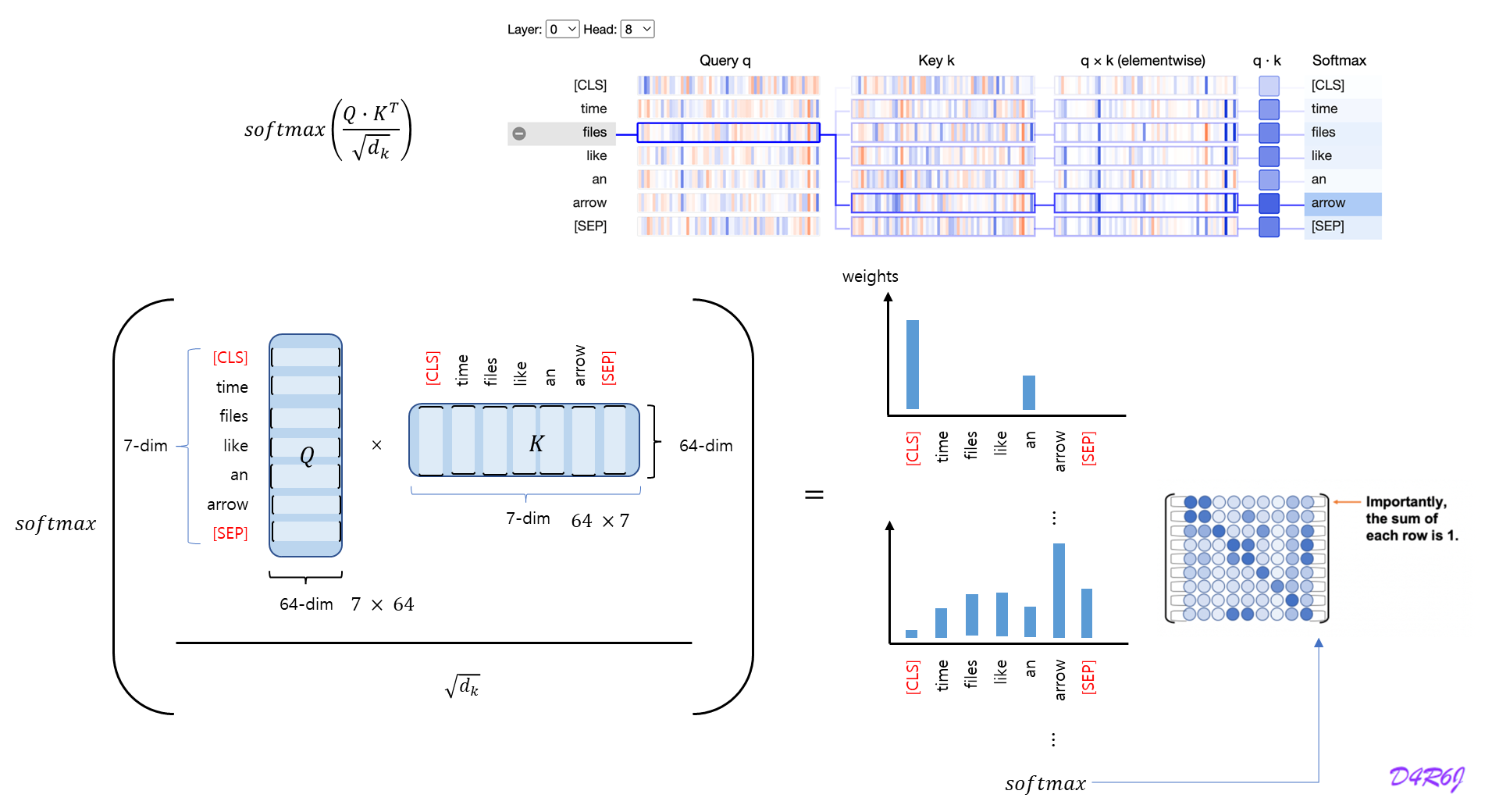
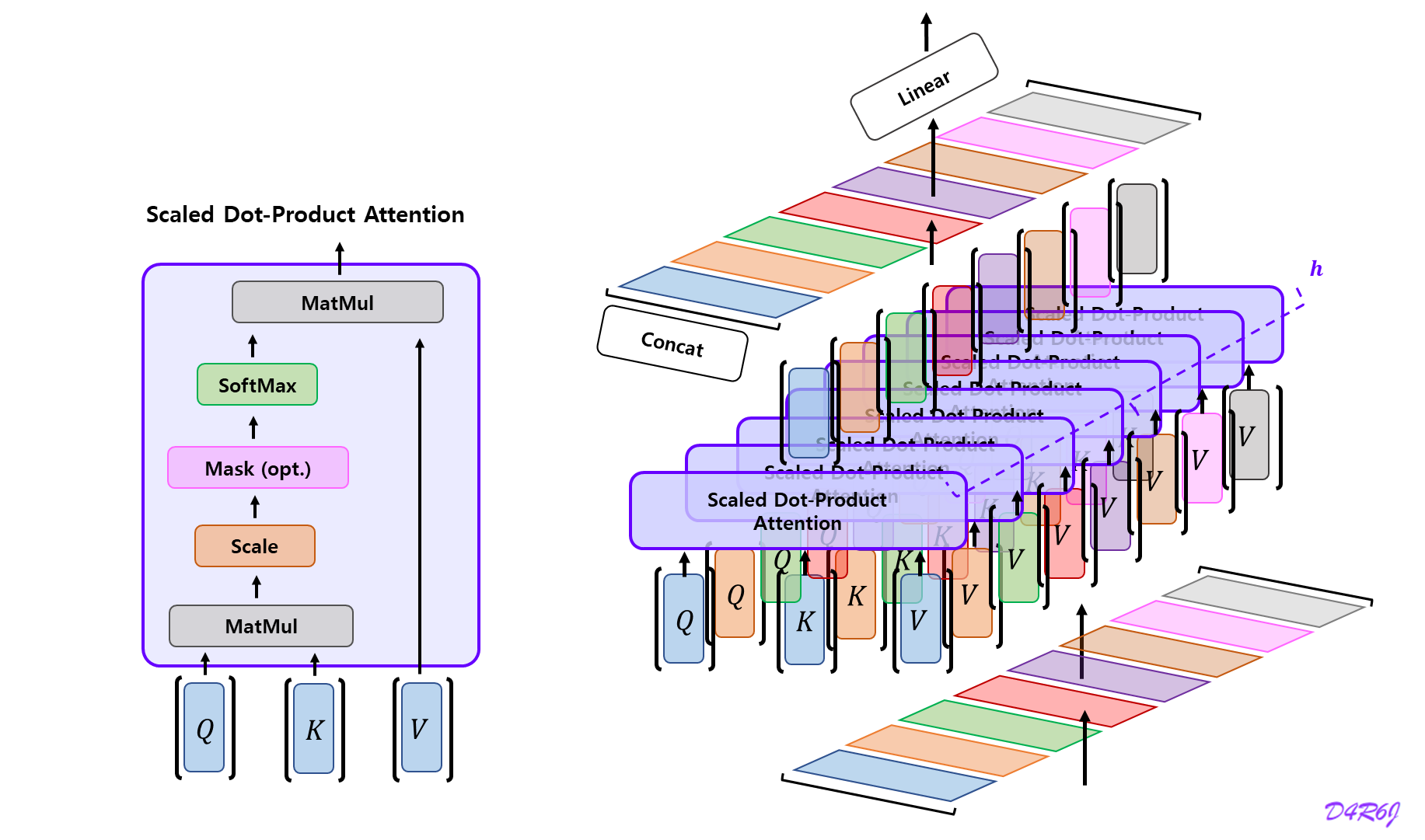
Standard Multi-Head Attention
d d d n h n_h n h d n d_n d n h t ∈ R d {\rm h}_t \in \mathbb{R}^{d} h t ∈ R d t t t
으로 설정한다.
표준 MHA 는 먼저 세계의 행렬 W Q , W k , W V ∈ R d h n h × d W^Q, W^{k}, W^{V} \in \mathbb{R}^{d_hn_h \times d} W Q , W k , W V ∈ R d h n h × d q t , q t , v t ∈ R d h , n h \mathbf{q}_t, \mathbf{q}_t, \mathbf{v}_t \in \mathbb{R}^{d_h, n_h} q t , q t , v t ∈ R d h , n h
q t = W Q h t k t = W K h t v t = W V h t \mathbf{q}_t = W^{Q}\mathbf{h}_t\\ \mathbf{k}_t = W^{K}\mathbf{h}_t\\ \mathbf{v}_t = W^{V}\mathbf{h}_t q t = W Q h t k t = W K h t v t = W V h t
그런 다음 multi-head attention 계산을 위해서 q t , k t , v t \mathbf{q}_t, \mathbf{k}_t, \mathbf{v}_t q t , k t , v t n h \mathbf{n}_h n h
[ q t , 1 ; q t , 2 ; ⋯ ; q t , n h ] = q t , [ k t , 1 ; k t , 2 ; ⋯ ; k t , n h ] = k t , [ v t , 1 ; v t , 2 ; ⋯ ; v t , n h ] = v t , o t , i = ∑ j = 1 t S o f t m a x j ( q t , i T k j , i d h ) v j , i , u t = W O [ o t , 1 ; o t , 2 ; ⋯ ; o t , n h ] , [\mathbf{q}_{t, 1};\mathbf{q}_{t, 2}; \cdots; \mathbf{q}_{t, n_h}] = \mathbf{q}_t, \\ [\mathbf{k}_{t, 1};\mathbf{k}_{t, 2}; \cdots; \mathbf{k}_{t, n_h}] = \mathbf{k}_t, \\ [\mathbf{v}_{t, 1};\mathbf{v}_{t, 2}; \cdots; \mathbf{v}_{t, n_h}] = \mathbf{v}_t, \\ \\ \; \\ \begin{aligned} \mathbf{o}_{t,i} &= \sum^{t}_{j=1} {\rm Softmax}_j\left( \frac{\mathbf{q}^{T}_{t,i}\mathbf{k}_{j,i}}{\sqrt{d_h}} \right)\mathbf{v}_{j,i}, \\ \mathbf{u}_t &= W^{O}\left[\mathbf{o}_{t,1};\mathbf{o}_{t,2};\cdots;\mathbf{o}_{t,n_h}\right], \end{aligned} [ q t , 1 ; q t , 2 ; ⋯ ; q t , n h ] = q t , [ k t , 1 ; k t , 2 ; ⋯ ; k t , n h ] = k t , [ v t , 1 ; v t , 2 ; ⋯ ; v t , n h ] = v t , o t , i u t = j = 1 ∑ t S o f t m a x j ( d h q t , i T k j , i ) v j , i , = W O [ o t , 1 ; o t , 2 ; ⋯ ; o t , n h ] ,
q t , i , k t , i , v t , i ∈ R d h \mathbf{q}_{t,i}, \mathbf{k}_{t,i}, \mathbf{v}_{t,i} \in \mathbb{R}^{d_h} q t , i , k t , i , v t , i ∈ R d h i i i W O ∈ R d × d h n h W^{O} \in \mathbb{R}^{d \times d_hn_h} W O ∈ R d × d h n h
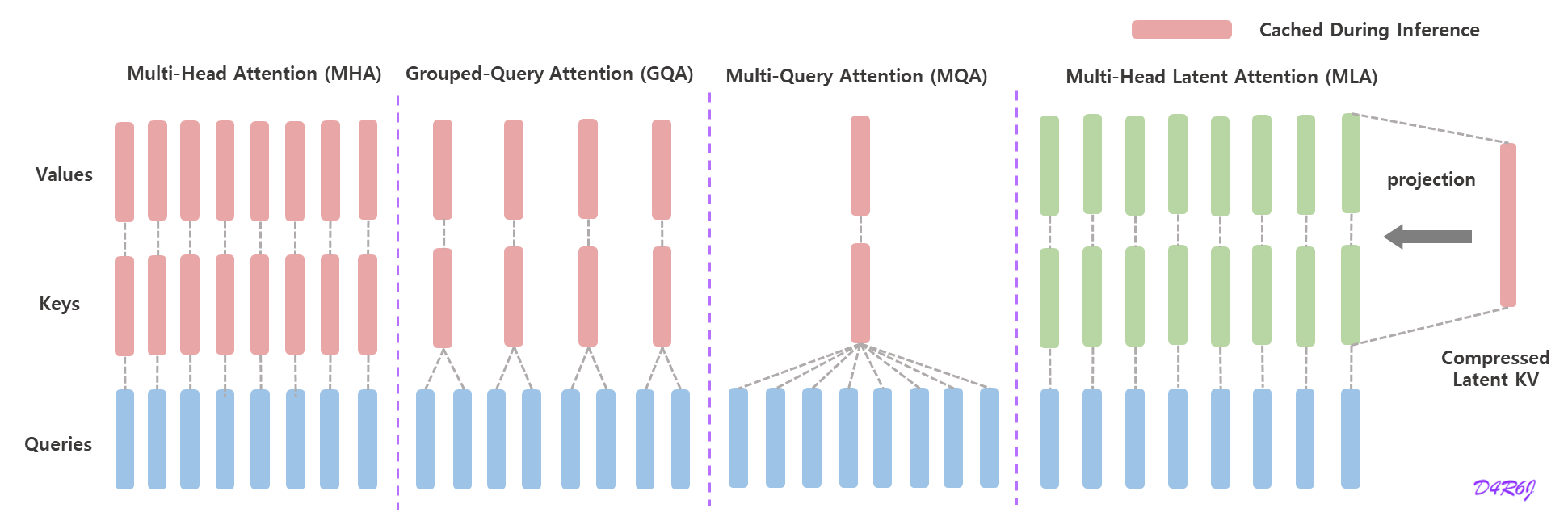
추론을 가속화 하기 위해서는 모든 key 와 value 를 cache 해야 하므로, MHA 는 각 토큰에 대해 2 n h d h l 2n_hd_hl 2 n h d h l K V KV K V
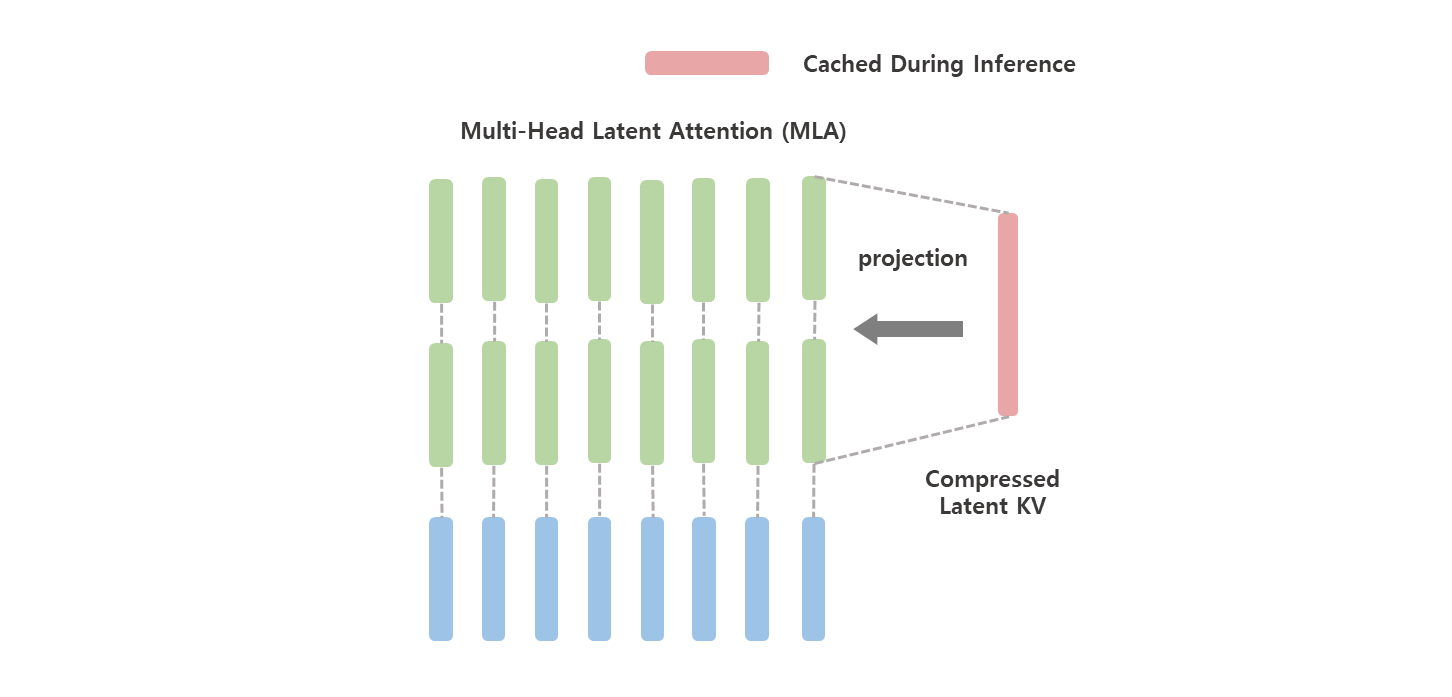
Low-Rank Key-Value Joint Compression
Multi-head Latent Attention (MLA) 는 키와 값을 latent vector 로 압축하여, 추론 중에 KV 캐시를 상당히 줄인다. MLA 의 핵심은 K V KV K V
d d d n h n_h n h d h d_h d h h t ∈ R d \mathbf{h}_t \in \mathbb{R}^{d} h t ∈ R d t t t
MLA 의 핵심 (core) 은 추론 중에 Key-Value (KV) 캐시를 줄이기 위해서 attention Key와 Value 에 대한 low-rank joint compression 이다.
c t K V = W D K V h t , k t C = W U K c t K V , v t C = W U V c t K V , \mathbf{c}_{t}^{KV} = W^{DKV}\mathbf{h}_{t}, \\ \mathbf{k}_{t}^{C} = W^{UK}\mathbf{c}_{t}^{KV}, \\ \mathbf{v}_{t}^{C} = W^{UV}\mathbf{c}_{t}^{KV}, \\ c t K V = W D K V h t , k t C = W U K c t K V , v t C = W U V c t K V ,
c t K V ∈ R d c \mathbf{c}_{t}^{KV} \in \mathbb{R}^{d_c} c t K V ∈ R d c
d c ( ≪ d h n h ) d_c \; ( \ll d_hn_h) d c ( ≪ d h n h ) K V KV K V W D K V ∈ R d c × d W^{DKV} \in \mathbb{R}^{d_c \times d} W D K V ∈ R d c × d W U K , W U V ∈ R d h n h × d c W^{UK}, W^{UV} \in \mathbb{R}^{d_hn_h \times d_c} W U K , W U V ∈ R d h n h × d c 추론 중에 MLA 는 c t K V c_{t}^{KV} c t K V K V KV K V d c l d_cl d c l
low-rank key-value 의 joint compression 을 갖춘 MLA 는 MHA 보다 더 성능이 좋지만, K V KV K V W U K W^{UK} W U K W Q W^{Q} W Q W U V W^{UV} W U V W O W^{O} W O
training 하는 동안 activation memory (활성화 메모리) 를 줄이기 위해서, K V KV K V
c t Q = W D Q h t , q t C = W U Q c t Q , \mathbf{c}^{Q}_{t} = W^{DQ}\mathbf{h}_t, \\ \mathbf{q}^{C}_{t} = W^{UQ}\mathbf{c}_{t}^{Q}, c t Q = W D Q h t , q t C = W U Q c t Q ,
여기서 c t Q ∈ R d c ′ \mathbf{c}^{Q}_{t} \in \mathbb{R}^{d_c'} c t Q ∈ R d c ′
Query 압축 차원은 d c ′ ( ≪ d h n h ) d_{c}' (\ll d_hn_h) d c ′ ( ≪ d h n h )
W D Q ∈ R d c ′ × d W^{DQ} \in \mathbb{R}^{d_c' \times d} W D Q ∈ R d c ′ × d W U Q ∈ R d h n h × d c ′ W^{UQ} \in \mathbb{R}^{d_hn_h \times d_c'} W U Q ∈ R d h n h × d c ′
행렬 곱의 결합 법칙에 의해서 W U K W^{UK} W U K W U Q W^{UQ} W U Q W U V W^{UV} W U V W O W^{O} W O
Decoupled Rotary Position Embedding
RoPE 는 low-rank K V KV K V
key k t C \mathbf{k}^{C}_{t} k t C W U K W^{UK} W U K
k t C = W U K c t K V , \mathbf{k}_{t}^{C} = W^{UK}\mathbf{c}_{t}^{KV}, k t C = W U K c t K V ,
이러한 방식으로 W U K W^{UK} W U K W Q W^{Q} W Q
현재 생성되는 token 과 관련된 RoPE 행렬은 W Q W^{Q} W Q W U K W^{UK} W U K
행렬 곱셈은 교환 법칙을 따르지 않기 때문에,
inference 도중, 모든 prefix token 을 다시 계산해야 하며, 이것은 inference 성능을 크게 저해 한다.
해결책으로
Multi-Head 쿼리 q t , i R ∈ R d h r \mathbf{q}^{R}_{t, i} \in \mathbb{R}^{d^{r}_{h}} q t , i R ∈ R d h r k t R ∈ R d h R \mathbf{k}^{R}_{t} \in \mathbb{R}^{d^{R}_{h}} k t R ∈ R d h R
RoPE 를 전달하는 decoupled RoPE 를 제안한다.
여기서 h h h
decoupled Rope 전략을 갖는 MLA 는 아래와 같은 연산을 수행한다.
[ q t , 1 R ; q t , 2 R ; ⋯ ; q t , n h R ] = q t R = R o P E ( W Q R c t Q ) , k t R = R o P E ( W K R h t ) , q t , i = [ q t , i C ; q t , i R ] , k t , i = [ k t , i C ; k t R ] , o t , i = ∑ j = 1 t S o f t m a x j ( q t , i T k j , i d h + d h R ) v j , i C , u t = W O [ o t , 1 ; o t , 2 ; ⋯ ; o t , n h ] , \begin{aligned} \left[ \mathbf{q}_{t, 1}^{R}; \mathbf{q}_{t,2}^{R}; \cdots ; \mathbf{q}^{R}_{t, n_h} \right] &= \mathbf{q}_{t}^{R} = {\rm RoPE}(W^{QR}\mathbf{c}_{t}^{Q}),\\ \mathbf{k}_{t}^{R}&={\rm RoPE}(W^{KR}\mathbf{h}_t),\\ \mathbf{q}_{t, i} &= \left[\mathbf{q}^{C}_{t,i}; \mathbf{q}^{R}_{t,i}\right], \\ \mathbf{k}_{t, i} &= \left[\mathbf{k}^{C}_{t,i}; \mathbf{k}^{R}_{t}\right], \\ \mathbf{o}_{t,i} &= \sum^{t}_{j=1}{\rm Softmax}_j\left(\frac{\mathbf{q}^{T}_{t,i}\mathbf{k}_{j,i}}{\sqrt{d_h + d^{R}_{h}}} \right)\mathbf{v}^{C}_{j,i}, \\ \mathbf{u}_{t} &= W^{O}\left[\mathbf{o}_{t,1};\mathbf{o}_{t,2}; \cdots ; \mathbf{o}_{t, n_h} \right], \end{aligned} [ q t , 1 R ; q t , 2 R ; ⋯ ; q t , n h R ] k t R q t , i k t , i o t , i u t = q t R = R o P E ( W Q R c t Q ) , = R o P E ( W K R h t ) , = [ q t , i C ; q t , i R ] , = [ k t , i C ; k t R ] , = j = 1 ∑ t S o f t m a x j ⎝ ⎜ ⎛ d h + d h R q t , i T k j , i ⎠ ⎟ ⎞ v j , i C , = W O [ o t , 1 ; o t , 2 ; ⋯ ; o t , n h ] ,
W Q R ∈ R d h R n h × d c ′ W^{QR} \in \mathbb{R}^{d^{R}_{h}n_h \times d'_c} W Q R ∈ R d h R n h × d c ′ W K R ∈ R d h R × d W^{KR} \in \mathbb{R}^{d^{R}_{h}\times d} W K R ∈ R d h R × d RoPE 는 RoPE 행렬을 적용한 연산을 나타내고, [ ⋅ ; ⋅ ] [ \; \cdot \; ; \;\cdot\;] [ ⋅ ; ⋅ ]
추론 중에는 decoupled key 도 캐시 되어야 한다. 따라서 ( d c + d h R ) l \left( d_c + d_h^{R} \right)l ( d c + d h R ) l
RoPE 를 분리하여 연산을 하고, 따라서 Attention weight (score matrix) 를 만들 때도, 각기 dot-product 후에 summation 으로 구하는 부분, softmax scale 의 distance 도 decoupled 된 각기 합이 되는 포인트도 챙겨야 한다.
MLA 의 전체 computation process 를 보여주기 위해 아래와 같은 전체 formula 를 제공한다.
c t K V \mathbf{c}^{KV}_{t} c t K V k t R \mathbf{k}_{t}^{R} k t R 추론 중에, naive formula 는 attention 연산을 위해 c t K V \mathbf{c}_{t}^{KV} c t K V k t C \mathbf{k}_{t}^{C} k t C v t C \mathbf{v}_{t}^{C} v t C
다행히, 행렬 곱의 결합 법칙에 의해서 W U K W^{UK} W U K W U Q W^{UQ} W U Q W U V W^{UV} W U V W O W^{O} W O
따라서 각 query 에 대한 key 와 value 를 계산할 필요가 없다.
이런 최적화를 통해서 추론 중에 k t C \mathbf{k}_{t}^{C} k t C v t C \mathbf{v}_{t}^{C} v t C
확실히, Query, Key, Value 에 Low-Rank Projection 을 쳐서, PEFT 방법의 LoRA 의 방법을 훈련 하면서 inference 할 때 뽑아내는 건 더 안정적이게 dimension 을 reduction 하는 것으로 보였다.
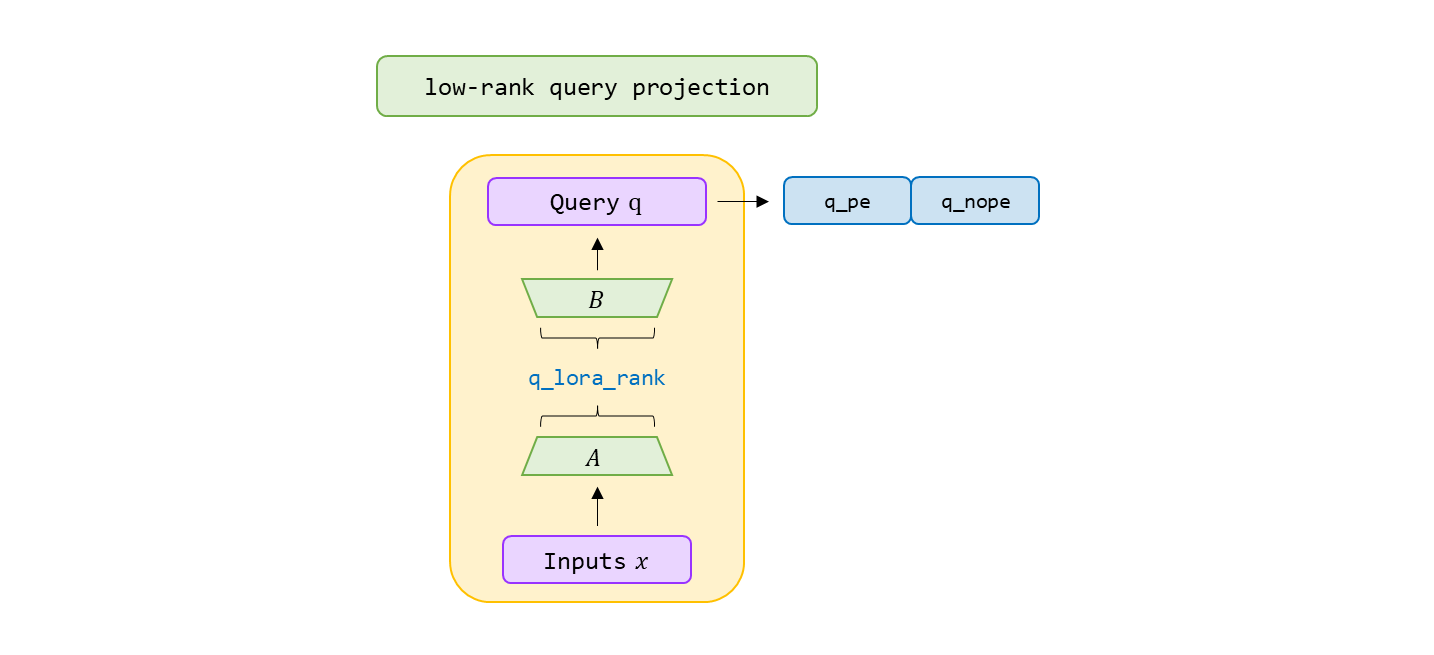
c t Q = W D Q h t , [ q t , 1 C ; q t , 2 C ; ⋯ ; q t , n h C ] = q t C = W U Q c t Q , \begin{aligned} \mathbf{c}^{Q}_{t}&=W^{DQ}\mathbf{h}_t, \\ \left[ \mathbf{q}_{t,1}^{C}; \mathbf{q}_{t,2}^{C}; \cdots; \mathbf{q}_{t,n_{h}}^{C}\right] = \mathbf{q}_{t}^{C}&=W^{UQ}\mathbf{c}_{t}^{Q}, \\ \end{aligned} c t Q [ q t , 1 C ; q t , 2 C ; ⋯ ; q t , n h C ] = q t C = W D Q h t , = W U Q c t Q , """
dim (int): Dimensionality of the input features.
q_lora_rank (int): Rank for low-rank query projection.
qk_head_dim (int): Total dimensionality of query/key projections.
qk_rope_head_dim (int): Dimensionality of rotary-positional query/key projections.
"""
self. q_lora_rank = args. q_lora_rank
self. wq_a = Linear( self. dim, self. q_lora_rank)
self. wq_b = ColumnParallelLinear( self. q_lora_rank, self. n_heads * self. qk_head_dim)
self. q_norm = RMSNorm( self. q_lora_rank)
q = self. wq_b( self. q_norm( self. wq_a( x) ) )
q = q. view( bsz, seqlen, self. n_local_heads, self. qk_head_dim) [ q t , 1 R ; q t , 2 R ; ⋯ ; q t , n h R ] = q t R = R o P E ( W Q R c t Q ) , q t , i = [ q t , i C ; q t , i R ] \begin{aligned} \left[\mathbf{q}^{R}_{t,1};\mathbf{q}^{R}_{t,2};\cdots;\mathbf{q}^{R}_{t,n_h} \right] = \mathbf{q}^{R}_{t} &= {\rm RoPE}\left(W^{QR}\mathbf{c}_{t}^{Q}\right),\\ \mathbf{q}_{t,i} &= \left[\mathbf{q}^{C}_{t,i};\mathbf{q}^{R}_{t,i}\right] \end{aligned} [ q t , 1 R ; q t , 2 R ; ⋯ ; q t , n h R ] = q t R q t , i = R o P E ( W Q R c t Q ) , = [ q t , i C ; q t , i R ]
q_nope, q_pe = torch. split( q, [ self. qk_nope_head_dim, self. qk_rope_head_dim] , dim= - 1 )
q_pe = apply_rotary_emb( q_pe, freqs_cis)
원래의 Key/Value 생성 행렬은
W K V ∈ R d h n h × d W^{KV} \in \mathbb{R}^{d_hn_h \times d} W K V ∈ R d h n h × d
여기서 d h d_h d h
n h n_h n h d d d
W D K V ∈ R d c × d W^{DKV} \in \mathbb{R}^{d_c \times d} W D K V ∈ R d c × d 낮은 차원 d c d_c d c
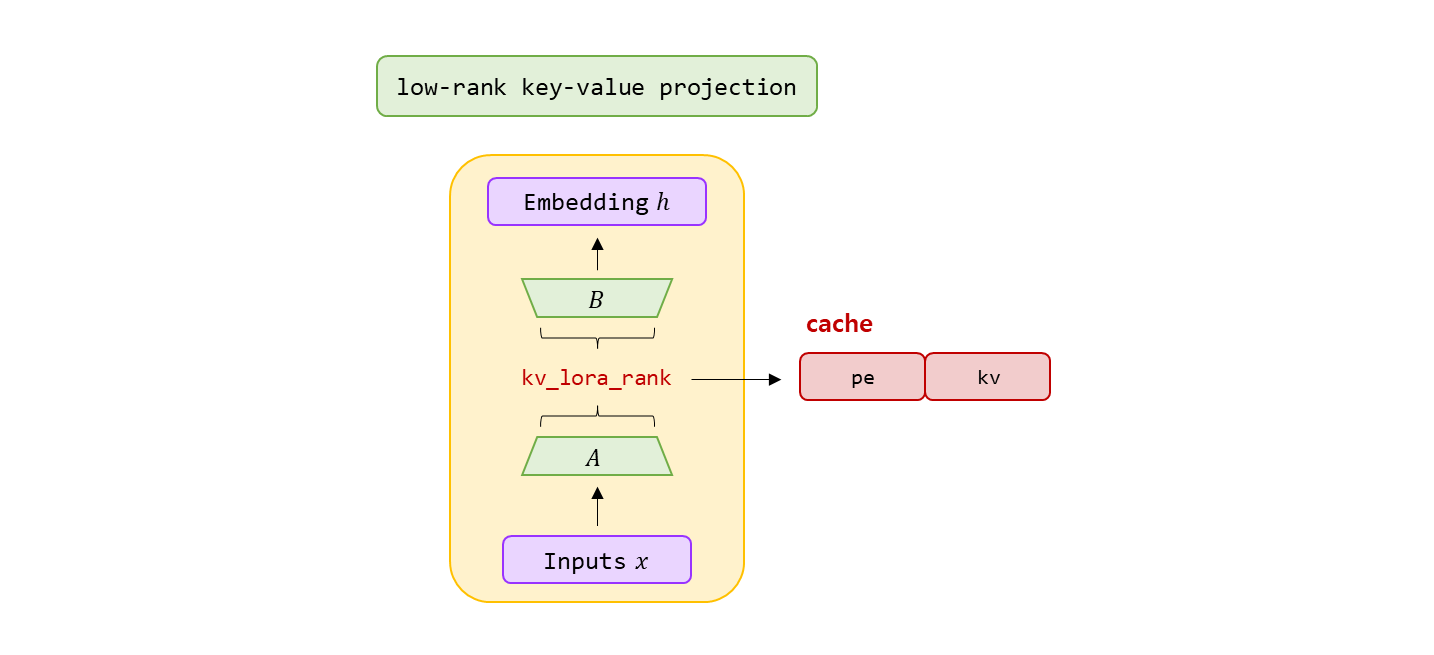
c t K V = W D K V h t , \mathbf{c}^{KV}_{t} = W^{DKV}\mathbf{h}_t, c t K V = W D K V h t , """
dim (int): Dimensionality of the input features.
kv_lora_rank (int): Rank for low-rank key/value projection.
qk_rope_head_dim (int): Dimensionality of rotary-positional query/key projections.
"""
self. wkv_a = Linear( self. dim, self. kv_lora_rank + self. qk_rope_head_dim)
kv = self. wkv_a( x) k t R = R o P E ( W K R h t ) \mathbf{k}^{R}_{t} = {\rm RoPE}\left(W^{KR}\mathbf{h}_t\right) k t R = R o P E ( W K R h t ) kv, k_pe = torch. split( kv, [ self. kv_lora_rank, self. qk_rope_head_dim] , dim= - 1 )
k_pe = apply_rotary_emb( k_pe. unsqueeze( 2 ) , freqs_cis)
Latent K V KV K V
W U K , W U V ∈ R d n n h × d c W^{UK}, W^{UV} \in \mathbb{R}^{d_nn_h \times d_c} W U K , W U V ∈ R d n n h × d c [ k t , 1 C ; k t , 2 C ; ⋯ ; k t , n h C ] = k t C = W U K c t K V \left[ \mathbf{k}_{t,1}^{C};\mathbf{k}_{t,2}^{C};\cdots;\mathbf{k}^{C}_{t,n_h} \right] = \mathbf{k}_{t}^{C} = W^{UK}\mathbf{c}_{t}^{KV} [ k t , 1 C ; k t , 2 C ; ⋯ ; k t , n h C ] = k t C = W U K c t K V 높은 차원 d h n h d_hn_h d h n h
wkv_b = self. wkv_b. weight if self. wkv_b. scale is None else weight_dequant( self. wkv_b. weight, self. wkv_b. scale, block_size)
wkv_b = wkv_b. view( self. n_local_heads, - 1 , self. kv_lora_rank)
기존엔 k 와 v 를 따로 가지고 매번 계산. W U K W^{UK} W U K W U V W^{UV} W U V self.wkv_b 로 같이 사용.
c t K V \mathbf{c}_{t}^{KV} c t K V self.kv_norm(kv)k t R \mathbf{k}_{t}^{R} k t R k_pe.squeeze(2)
self. kv_cache[ : bsz, start_pos: end_pos] = self. kv_norm( kv)
self. pe_cache[ : bsz, start_pos: end_pos] = k_pe. squeeze( 2 ) ∑ j = 1 t S o f t m a x j ( q t , i T k j , i d h + d h R ) \sum^{t}_{j=1}{\rm Softmax}_j\left( \frac{\mathbf{q}_{t,i}^{T}\mathbf{k}_{j,i}}{\sqrt{d_{h} + d^{R}_{h}}}\right) j = 1 ∑ t S o f t m a x j ⎝ ⎜ ⎛ d h + d h R q t , i T k j , i ⎠ ⎟ ⎞ """
self.qk_head_dim = args.qk_nope_head_dim + args.qk_rope_head_dim
self.softmax_scale = self.qk_head_dim ** -0.5
"""
q_nope = torch. einsum( "bshd,hdc->bshc" , q_nope, wkv_b[ : , : self. qk_nope_head_dim] )
scores = ( torch. einsum( "bshc,btc->bsht" , q_nope, self. kv_cache[ : bsz, : end_pos] ) +
torch. einsum( "bshr,btr->bsht" , q_pe, self. pe_cache[ : bsz, : end_pos] ) ) *
self. softmax_scale
scores = scores. softmax( dim= - 1 , dtype= torch. float32) . type_as( x) q t , i = [ q t , i C ; q t , i R ] k t , i = [ k t , i C ; k t R ] \begin{aligned} \mathbf{q}_{t,i} &= \left[ \mathbf{q}^{C}_{t,i}; \mathbf{q}^{R}_{t,i} \right] \\ \mathbf{k}_{t,i} &= \left[ \mathbf{k}_{t,i}^{C}; \mathbf{k}_{t}^{R} \right] \end{aligned} q t , i k t , i = [ q t , i C ; q t , i R ] = [ k t , i C ; k t R ]
q_nope ( q t , i C ) \left( \mathbf{q}^{C}_{t,i} \right) ( q t , i C ) kv_cache ( k t , i C ) \left( \mathbf{k}^{C}_{t,i} \right) ( k t , i C ) q_pe ( q t , i R ) \left(\mathbf{q}_{t,i}^{R}\right) ( q t , i R ) pe_cache ( k t R ) \left(\mathbf{k}_{t}^{R} \right) ( k t R ) Query 와 Key 로 만든 score matrix 인데 positional encoding 고려됨.
Softmax 적용 전에 scaling 함. 이후 Softmax 의 결과 값이 학습되는 핵심 값. Attention weight.
Query 가 특정 Key 를 얼마나 중요하게 보는 지 학습.
Softmax 결과로 Attention weight 이 계속 업데이트.
o t , i = ∑ j = 1 t S o f t m a x j ( q t , i T k j , i d h + d h R ) v j , i C \mathbf{o}_{t,i} = \sum^{t}_{j=1}{\rm Softmax}_j\left( \frac{\mathbf{q}_{t,i}^{T}\mathbf{k}_{j,i}}{\sqrt{d_{h} + d^{R}_{h}}}\right)\mathbf{v}^{C}_{j,i} o t , i = j = 1 ∑ t S o f t m a x j ⎝ ⎜ ⎛ d h + d h R q t , i T k j , i ⎠ ⎟ ⎞ v j , i C x = torch. einsum( "bsht,btc->bshc" , scores, self. kv_cache[ : bsz, : end_pos] )
Softmax 적용 후
( v j , i C ) \left(\mathbf{v}_{j,i}^{C} \right) ( v j , i C ) score matrix 의 차원 : b atchsize, s eq_len, n h eads, t arget_seq
kv_cache 의 차원 : b atch_size, t arget_seq, (c )kv_lora_rank
연산 후에 t arget_seq_len 이 사라지고 (c )kv_lora_rank 가 남는다.
이후 결과와 맞추고 loss 값으로 Backpropagation 을 통해서 Optimizer 에 맞게 q, k, v 모두 학습.
학습 중 어떤 Key 가 중요한지를 학습하고, grad-cam 등으로 시각화.
u t = W O [ o t , 1 ; o t , 2 ; ⋯ ; o t , n h ] \mathbf{u}_t = W^{O}\left[\mathbf{o}_{t,1};\mathbf{o}_{t,2}; \cdots;\mathbf{o}_{t,n_h}\right] u t = W O [ o t , 1 ; o t , 2 ; ⋯ ; o t , n h ] x = torch. einsum( "bshc,hdc->bshd" , x, wkv_b[ : , - self. v_head_dim: ] )
self. wo = RowParallelLinear( self. n_heads * self. v_head_dim, self. dim)
x = self. wo( x. flatten( 2 ) )
Output matrix 에서 원래의 Value 의 차원으로 변환.
이전 연산의 (c )kv_lora_rank 로 축소된 key/value 를 사용.
Transformer 의 Attention 에서는 v_head_dim 을 사용하므로, 차원 변환 하는 것.
Low-Rank 로 압축 된 Value 를 해당 차원을 맞추기 위해 차원 복원.
W O W^{O} W O self.dim 로 차원을 맞춘다.
c t K V = W D K V h t [ k t , 1 C ; k t , 2 C ; ⋯ ; k t , n h C ] = k t C = W U K c t K V k t R = R o P E ( W K R h t ) k t , i = [ k t , i C ; k t R ] [ [ v ] t , 1 C ; v t , 2 C ; ⋯ ; v t , n h C ] = v t C = W U V c t K V \begin{aligned} \mathbf{c}_{t}^{KV} &= W^{DKV}\mathbf{h}_{t} \\ \left[ \mathbf{k}_{t,1}^{C};\mathbf{k}_{t,2}^{C};\cdots;\mathbf{k}^{C}_{t,n_h} \right] = \mathbf{k}_{t}^{C} &= W^{UK}\mathbf{c}_{t}^{KV} \\ \mathbf{k}^{R}_{t} &= {\rm RoPE}\left(W^{KR}\mathbf{h}_t\right)\\ \mathbf{k}_{t,i}&=\left[\mathbf{k}_{t,i}^{C};\mathbf{k}_{t}^{R}\right]\\ \left[\mathbf[v]^{C}_{t,1};\mathbf{v}^{C}_{t,2};\cdots;\mathbf{v}^{C}_{t,n_h} \right] = \mathbf{v}_{t}^{C}&=W^{UV}\mathbf{c}^{KV}_{t} \end{aligned} c t K V [ k t , 1 C ; k t , 2 C ; ⋯ ; k t , n h C ] = k t C k t R k t , i [ [ v ] t , 1 C ; v t , 2 C ; ⋯ ; v t , n h C ] = v t C = W D K V h t = W U K c t K V = R o P E ( W K R h t ) = [ k t , i C ; k t R ] = W U V c t K V
c t K V ∈ R d c \mathbf{c}_{t}^{KV} \in \mathbb{R}^{d_c} c t K V ∈ R d c d c ( ≪ d h n h ) d_c \left( \ll d_hn_h\right) d c ( ≪ d h n h ) K V KV K V W D K V ∈ R d c × d W^{DKV} \in \mathbb{R}^{d_c \times d} W D K V ∈ R d c × d W U K , W U V ∈ R d h n h × d c W^{UK}, W^{UV} \in \mathbf{R}^{d_hn_h \times d_c} W U K , W U V ∈ R d h n h × d c W K R ∈ R d h R × d W^{KR} \in \mathbb{R}^{d^{R}_{h}\times d} W K R ∈ R d h R × d R o P E ( ⋅ ) {\rm RoPE(\cdot)} R o P E ( ⋅ ) [ ⋅ ; ⋅ ] [\;\cdot \; ; \; \cdot \; ] [ ⋅ ; ⋅ ] MLA 의 경우 generation 중에 c t K V \mathbf{c}^{KV}_{t} c t K V k t R \mathbf{k}_{t}^{R} k t R K V KV K V
c t Q = W D Q h t [ q t , 1 C ; q t , 2 C ; ⋯ ; q t , n h C ] = q t C = W U Q c t Q [ q t , 1 R ; q t , 2 R ; ⋯ ; q t , n h R ] = q t R = R o P E ( W Q R c t Q ) q t , i = [ q t , i C ; q t , i R ] \begin{aligned} \mathbf{c}_{t}^{Q} &= W^{DQ}\mathbf{h}_t \\ \left[\mathbf{q}_{t,1}^{C}; \mathbf{q}_{t,2}^{C}; \cdots ; \mathbf{q}_{t, n_h}^{C}\right] = \mathbf{q}_{t}^{C} &= W^{UQ}\mathbf{c}_{t}^{Q} \\ \left[\mathbf{q}_{t,1}^{R}; \mathbf{q}_{t,2}^{R}; \cdots; \mathbf{q}_{t, n_h}^{R}\right] = \mathbf{q}_{t}^{R} &= {\rm RoPE\left(W^{QR}\mathbf{c}_{t}^{Q}\right)}\\ \mathbf{q}_{t,i} &= \left[\mathbf{q}_{t,i}^{C}; \mathbf{q}_{t,i}^{R}\right] \end{aligned} c t Q [ q t , 1 C ; q t , 2 C ; ⋯ ; q t , n h C ] = q t C [ q t , 1 R ; q t , 2 R ; ⋯ ; q t , n h R ] = q t R q t , i = W D Q h t = W U Q c t Q = R o P E ( W Q R c t Q ) = [ q t , i C ; q t , i R ]
c t Q ∈ R c d ′ \mathbf{c}^{Q}_{t} \in \mathbb{R}^{d'}_c c t Q ∈ R c d ′ d c ′ ( ≪ d n n h ) d'_{c}\left(\ll d_nn_h \right) d c ′ ( ≪ d n n h ) W D Q ∈ R c d ′ × d W^{DQ} \in \mathbb{R}^{d'\times d}_c W D Q ∈ R c d ′ × d W U Q ∈ R d h n h × d c ′ W^{UQ} \in \mathbb{R}^{d_hn_h \times d'_{c}} W U Q ∈ R d h n h × d c ′ W Q R ∈ R d h R × d c ′ W^{QR} \in \mathbb{R}^{d^{R}_{h} \times d'_c} W Q R ∈ R d h R × d c ′
궁국적으로, Attention 의 Query ( q t , i ) \left( \mathbf{q}_{t,i} \right) ( q t , i ) ( k j , i ) \left(\mathbf{k}_{j,i} \right) ( k j , i ) ( v j , i c ) \left( \mathbf{v}^{c}_{j,i} \right) ( v j , i c ) u t \mathbf{u}_t u t
o t , i = ∑ j = 1 t S o f t m a x j ( q t , i T k j , i d h + d h R ) v j , i C u t = W O [ o t , 1 ; o t , 2 ; ⋯ ; o t , n h ] \begin{aligned} \mathbf{o}_{t,i} &= \sum^{t}_{j=1}{\rm Softmax}_j\left( \frac{\mathbf{q}_{t,i}^{T}\mathbf{k}_{j,i}}{\sqrt{d_{h} + d^{R}_{h}}}\right)\mathbf{v}^{C}_{j,i} \\ \mathbf{u}_t &= W^{O}\left[\mathbf{o}_{t,1};\mathbf{o}_{t,2}; \cdots;\mathbf{o}_{t,n_h}\right] \end{aligned} o t , i u t = j = 1 ∑ t S o f t m a x j ⎝ ⎜ ⎛ d h + d h R q t , i T k j , i ⎠ ⎟ ⎞ v j , i C = W O [ o t , 1 ; o t , 2 ; ⋯ ; o t , n h ] 여기서 W O ∈ R d × d h n h W^{O} \in \mathbb{R}^{d \times d_hn_h} W O ∈ R d × d h n h
layer 만으로 auto-encoder, denoising 구조를 이루고, RoLA 와 같이 학습된 matrix 를 분리하는 것이 아닌 자연스럽게 reduction 하는 것으로 이해했고, cache 가 있는데 하나로 합쳐서 메모리에 떠있기만 하면 되니 inference 시 많이 절약 되는 구조로 이해가 되었다.
Ref
DeepSeekV2 paper DeepSeekV3 paper github code