
Large-Language-Model 관련한 Technical Report 는 한 번 읽어보고 싶었다.
Llama2 읽어보려다가, Llama3 기다렸고, 이제 한 번 천천히 정독하여 읽어 보려 한다.
review 는 순서대로 진행 될 예정인데, 몇 부분으로 나눌 것이다.
1. Introduction
2. Pre-Training
3. Post-Training
4. Vision Experiments
5. Speech Experiments
로 천천히 다루어볼 예정이다.
3. Pre-Training
언어 모델 pre-training 은 다음이 포함 된다.
- 대규모 훈련 corpus 의 선별 및 필터링
- 모델 architecture 의 개발과 모델 크기를 결정하기 위한 scaling 법칙의 개발
- 대규모에서 효율적인 pre-training 을 위한 기술 개발
- pre-training 을 위한 recipe 개발
이 각 구성 요소를 별도로 설명한다.
3.1 Pre-Training Data
2023 말 까지의 지식이 포함된 다양한 데이터 소스들로부터 language model 을 pre-training 하기 위한 데이터 셋을 만들었다. 고품질의 tokens 를 얻기 위해서 각 데이터 소스에 여러가지 중복 제거 방법과 데이터 정리 메커니즘을 적용한다. 대량의 개인 식별 정보 (PII) 가 포함된 도메인과 잘 알려진 성인 컨텐츠 들을 제거한다.
3.1.1 Web Data Curation
활용하는 데이터의 대부분은 웹에서 얻은 것이고, cleaning 과정은 아래에 설명한다.
PII (Personally Identifiable Information) and safety filtering.
- 다른 안전 장치들 중에서 안전하지 않은 컨텐츠 또는 많은 양의 PII.
- 다양한 “Meta” 안전 기준에 따라 유해한 것으로 ranked 된 도메인.
- 성인 컨텐츠를 포함하는 것으로 알려진 도메인을 포함할 가능성 있는 websites 로부터 데이터를 제거하도록 설계된 필터를 개발.
아예 가저오기 전부터, 데이터를 집어 오기 전에 domain, dns 등의 정보를 보고 필터링 하여 가져오는구나.
Text extraction and cleaning
- non-truncated (잘리지 않은) raw HTML 컨텐츠를 처리하여 고품질의 다양한 text 를 추출.
- 이를 위해서 HTML 컨텐츠를 추출하고 불필요한 요소 (boilerplate) 를 제거하는 정확성.
- 컨텐츠 회수를 최적화한 맞춤형 파서를 구축.
boilerplate removal : 웹페이지에서 광고, 메뉴, 디자인 요소 제거, content recall 은 중요 컨텐츠를 정확하게 추출하는 것을 의미. 크롤러가 중요하다는 거지.
- 사람의 평가를 통해서 parser 의 질을 평가하고, 기사와 같은 컨텐츠에 최적화된 third-party HTML parser 와 비교하고, 그것이 좋은 성능을 보이는 것을 확인했다.
여전히 사람의 평가는 중요한 듯 보인다. 그런데, 점점 쌓이게 되면.. 사람의 개성이라는 것도 그저 하나의 기 학습된 데이터중 하나로 될 것 같다는 막연한 생각이다. 특성을 정말 잘 살렸다.
- 컨텐츠의 구조를 보존하기 위해서 수학 과 코드 컨텐츠를 포함한 HTML 페이지를 조심스럽게 처리한다.
- 수학 컨텐츠는 자주 pre-rendered 된 이미지 로 표시되며 여기서 수학 식은 이미지의 alt 속성에도 제공되므로, 이미지의 alt 속성 텍스트를 유지하는 것이 중요.
- 마크다운이 일반 텍스트 와 비교해서 웹 데이터로 주로 훈련하는 모델의 성능에 좋지 않다는 것을 확인하여 모든 마크다운 markers ( 마크다운 문법 요소 ) 를 제거한다.
markdown 은 확실히 빼는게 좋다고 생각한다. 코드도 아니고, "강조" 를 할 때도 쓰이긴 하지만, 그것이 pre-training 에서는 noise 로 보일 듯 하다.
image 를 OCR 로 뽑아내는 경향이 있는데, 수학 기호 처럼 문자가 아닌 기호는 인식이 어렵다. 따라서, 수학 컨텐츠 이미지 그 자체로 alt 를 유지하는 것이 좋다고 본다.
De-duplication
URL 문서 및 라인 수준에서 여러 차례 중복을 제거한다.
- URL-level de-duplication.
전체 데이터 셋 에 대해서 URL 수준 중복 제거를 수행한다. 각 URL 에 해당하는 페이지는 최신 버전을 유지한다. - Document-level de-duplication.
거의 중복된 문서를 제거하기 위해서 전체 데이터 셋에 걸쳐서 global MinHash 중복 제거를 수행한다. - Line-level de-duplication.
ccNet과 같은 공격적인 (aggressive) 한 line-level 중복 제거를 수행한다. 30M document (3천만개의 문서) 의 각 bucket 에서 6번 이상 나타나는 line 을 제거한다.
중복 제거에 공을 들이는 이유는, 같은 데이터를 여러 번 반복해서 넣으면 편향 되기 때문으로 이해를 하지만서도, 이전에 The Pile 의 논문을 볼 때, Wiki 같이 잘 구성된 데이터는 여러 번 중복해서 넣는 시도도 있었다.
수동적인 질적 분석에서는 line-level 중복 제거를 통해
- navigation 메뉴
- 쿠키 경고 등
다양한 웹사이트들 로부터 남은 상용구 뿐 아니라,
- 자주 사용되는 고품질의 텍스트도 제거하는 것으로 나타났지만,
실질적인 평가에서는 크게 향상 된 것으로 나타났다.
manual qualitative analysis 를 이해한건, 수동적으로 직접 데이터를 보고 주관적으로 판단하여 그 질적인 특성을 분석한다는 의미로 이해했다.
Heuristic filtering.
추가적인 저품질의 문서, outlier, 과도한 반복이 있는 문서를 제거하기 위해서 Heuristic 을 개발한다. heuristic 의 몇 가지 예시는 다음과 같다.
-
중복된 n-gram 적용 비율 을 사용하여 logging 이나 에러 메시지와 같은 반복적인 컨텐츠로 구성된 줄을 제거한다.
n-gram 을 이렇게 사용하는구나..
-
해당 라인들은 매우 길고 유니크 할 수 있으므로, line-dedup (라인 중복) 으로 필터링 할 수 없다.
-
dirty word를 사용하여 도메인 차단 목록에 커버되지 않는 성인 웹사이트를 필터링한다.
사실 이러한 경험적인 filtering 은 그 어떤 기업 보다도 잘 되있겠지.. Facebook 과 Instagram 을 가지고 있는데..
X(구 twitter) 도 너무 필터가 안되서 문제가 있었지.. 이건 다시 말하면 두 기업 모두 filter 에 대한 데이터가 확실히 있다는 것을 의미한다.
- 토큰 분포 Kullback-Leibler divergence 를 사용하여 훈련 corpus 분포에 비해 과도한 수의 outlier token 을 포함하는 문서를 필터링한다.
KL divergence 가지고 outlier token 을 포함하는 문서를 필터링한다니.. 재밌는 시도 같다. corpus 의 분포는 대체 어떤 분포일까 .. 나와 너는 분포 어디에 있을까? I 와 You 는?
Model-based quality filtering.
다양한 모델 기반 품질 분류기를 적용하여 고품질의 토큰을 하위 선택하는 실험을 진행한다.
- 주어진 텍스트가 Wikipedia 에서 참조하는지 인식하도록 훈련된
fasttext와 같은 빠른 분류기를 사용한다. - Llama2 의 예측을 기반으로 훈련된 Roberta 기반 분류기처럼 계산 집약적인 방법도 포함된다.
- Llama2 기반으로 한 quality classifier 를 훈련시키기 위해서 정리된 웹 문서의 훈련 세트를 만들고, 품질 요구사항을 설명한다.
- Llama2 의 chat model 에 지시하여 문서가 이러한 요구사항을 충족하는지 확인한다.
- 효율성을 위해서
DistilRoberta를 사용하여 각 문서의 품질 점수를 생성한다. - 다양한 품질 필터링 구성의 효율성을 실험적으로 평가한다.
Code and reasoning data.
DeepSeek-AI와 유사하게 코드와 수학 관련 웹페이를 추출하는 도메인 별 (domain-specific) 파이프라인을 구축한다.- 코드와 추론 classifiers 는 모두 Llama2 에 의해 주석이 추가된 웹 데이터에 대해 훈련된 DistilRoberta 모델이다.
- 위에서 언급한 일반적인 품질 분류기와 달리 수학 추론이나 STEM (과학, 기술, 공학, 수학) 영역의 추론, 그리고 자연어와 함께 interleave 된 코드가 포함된 웹 페이지를 대상으로 prompt 튜닝을 진행한다.
code interleaved with natural language 는 코드가 자연어와 교차하여 섞여있는 것으로 볼 수 있다.
- code 와 수학의 token 분포는 자연어의 token 분포보다 상당히 다르기 때문에 이러한 파이프라인은 도메인별 HTML 추출, 사용자 정의 text 기능 및 필터링을 위한 heuristic 을 구현한다.
Multilingual data.
- 영어 처리 파이프라인과 유사하게 PII 또는 안전하지 않은 content 가 포함될 가능성이 있는 웹사이트에서 데이터를 제거하는 필터를 구현한다.
- 다국어 텍스트 처리 파이프라인은 몇 가지 고유한 기능들이 있다.
fasttext기반의 언어 식별 모델을 사용하여 문서를 176 개의 언어로 categorize 한다.- 각 언어 데이터 내에서
document-level과line-level중복 제거를 수행한다. - 품질이 낮은 문서를 제거하기 위해서 언어 별 경험적 방법과 모델 기반의 필터를 적용한다.
또한 고품질의 컨텐츠가 우선순위가 되도록 보장하기 위해서 다국어 Llama 2 기반 classifier 를 사용하여 다국어 문서의 품질 순위를 수행한다. pre-training 에 사용되는 다국어 토큰의 양을 실험적으로 결정하여 영어와 다국어 벤치마크들에 대한 모델 성능의 균형을 맞춘다.
여기서 생각해 볼 수 있는 것은, 영어와 비영어로 나누면, 영어가 압도적으로 많을 것이고, 어순에 따라서 영어권 어순과 비슷한 언어는 쉽겠지만 다른 어순을 가진 언어는 어려울 듯 보인다. 앞에서도 말한 언어의 구조를 학습을 하면서 배우기 때문에..
3.1.2 Determining the Data Mix
고품질의 언어 모델을 얻으려면 pre-training 데이터 mix 에서 다양한 데이터 소스의 비율을 신중하게 결정하는 것이 중요하다. 이 데이터 mix 를 결정하는 주요 도구는 knowledge classification 과 scaling law 실험이다.
knowledge classificaion 은 데이터에서 어떤 지식을 포함하고 있는지 분류하는 과정이고, scaling law 실험은 모델의 크기, 데이터 양, 성능 간의 관계를 탐구하는 실험.
Knowledge classification
data mix 를 보다 더 효과적으로 결정하기 위해서 우리의 web data 에서 포함된 정보 유형을 분류하는 classifier 를 개발한다. 이 classifier 를 사용하여 arts 와 entertainment 등 웹에서 과도하게 표현되는 데이터 카테고리들을 다운샘플링한다.
생각해보면 예술 분야는 web 에서 보여주려면 강조해서 보여줄 것 같다. 웹 데이터에 대한 노하우가 아닐까 싶다. 관련 데이터가 너무 많기도 하고, 광고 데이터도 많을 것 같다는 생각..
Scaling laws for data mix
- 최상의 data mix 를 결정하기 위해, 여러 작은 모델들을 다양한 data mix 로 훈련하고 이것들을 사용하여 해당 mix 에 대한 큰 모델의 성능을 예측하는 scaling law 실험을 수행한다.
- 새로운 데이터 mix candidate 를 선택하기 위해서 다양한 data mix 에 이 과정을 여러 번 반복한다.
- 그 후에 이 candidate data mix 로 더 큰 모델을 훈련하고, 여러 주요 벤치마크들에 해당 모델의 성능을 평가한다.
Data mix summary.
최종 data mix 에는 러프하게 보면 일반적인 지식에 해당하는 토큰이 50%, 수학적이고 추론적인 토큰이 25%, 코드 토큰이 17% 그리고 다국어 언어 토큰이 8% 정도 된다.
3.1.3 Annealing Data
단계적으로 데이터를 변화시키거나 최적화 시키는 방법이다.
- 경험적으로 작은 양의 고품질 코드와 수학적 데이터에 대한 annealing 은 주요 벤치마크에서 pre-trained 모델의 성능을 향상시킬 수 있음을 발견했다.
- DataComp-LM 에서 선택한 도메인에서 고품질의 데이터를 업 샘플링하는 data mix 를 사용하여 annealing 을 수행한다.
- annealing data 에는 일반적으로 사용되는 벤치마크의 훈련 세트가 포함되지 않는다. 이것은 Llama 3 의 few-shot 학습 능력과 domain 외에 일반화 성능을 평가할 수 있게 해준다.
OpenAI 에 이어서 GSM8k 및 MATH 훈련 세트에 대한 Annealing 의 효율성을 평가한다.
- annealing 은 pre-trained Llama 3 의 8B 모델의 성능을 각각 24% 및 6.4% 향상 시켰다. 그러나 405B 모델의 개선사항은 무시해도 될 정도로 작다.
- 이것은 주력 모델이 강력한 상황 내의 학습 및 추론 기능을 갖추고 있으며, 강력한 성능을 얻기 위해 특정 도메인 내 훈련 샘플이 필요하지 않는다.
405B 모델은 robust 하며, 많은 양의 데이터를 흡수하고 있고, 전반적인 언어 구조와 global domain 에 대한 이해를 하고 있다고 볼 수 있다고 생각한다.
Using annealing to assess data quality.
- annealing 이 작은 특정 도메인 데이터셋의 가치를 평가할 수 있게 해준다는 것을 알아냈다.
- 50% 훈련된 Llama 3 8B 모델에서 선형적으로 0 까지 40B 토큰에서 annealing 시켜서 이러한 데이터 셋의 가치를 측정한다.
- 여기서 annealing 은 데이터 처리나 모델 훈련에서 점진적으로 조정하는 과정을 의미하는 것이다.
- 이 실험에서 새 데이터 셋트에 30% 의 가중치를 할당하고, 기존의 data mix 에 70% 의 가중치를 할당한다.
- annealing 을 사용하여 새로운 data sorce 를 평가하는 것은 모든 작은 데이터 세트에 대해 scaling law 실험을 수행하는 것 보다 더 효율적이다.
여기서 궁금했다. 새 데이터 세트를 30% 의 가중치를 할당하고, 기존의 data mix 에 70% 의 가중치를 할당한다는 말은 어떻게 코드로 짤 수 있을까?
import torch
from torch.utils.data import Dataset, DataLoader, WeightedRandomSampler, ConcatDataset
# Design default data set
class DefaultDataset(Dataset):
def __init__(self, output_dim=10):
self.data = torch.zeros(output_dim, 1)
self.labels = torch.zeros(output_dim)
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx], self.labels[idx]
# Design new data set
class NewDataset(Dataset):
def __init__(self, output_dim=10):
self.data = torch.ones(output_dim, 1)
self.labels = torch.ones(output_dim)
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx], self.labels[idx]
default_dataset = DefaultDataset(output_dim=200)
new_dataset = NewDataset(output_dim=100)
# Concatenate default and new datasets.
concat_dataset = ConcatDataset([default_dataset, new_dataset])
# set weight ratios for each dataset
# default_dataset: 0.7, new_dataset: 0.3
weights = [0.7] * len(default_dataset) + [0.3] * len(new_dataset)
# Use WeightedRandomSampler to sample according to the ratio
# replacement=True means that the sample can be repeated
sampler = WeightedRandomSampler(weights, num_samples=len(concat_dataset), replacement=True)
dataloader = DataLoader(concat_dataset, sampler=sampler, batch_size=16)
# verify the ratio
loop = 100
all_sum = sum(labels.sum() for _ in range(loop) for _, labels in dataloader)
average = all_sum / loop
print(all_sum/loop)3.2 Model Architecture
Llama 3 은 표준적이고 dense Transformer 구조를 사용한다. architecture 모델의 측면에서 Llama 와 Llama 2 가 크게 벗어나지 않는다. 성능 향상은 주로 데이터 품질 과 다양성의 개선 뿐 아니라 training scale 증가에 의해 구동 된다.
- Llama 2 Architecture.
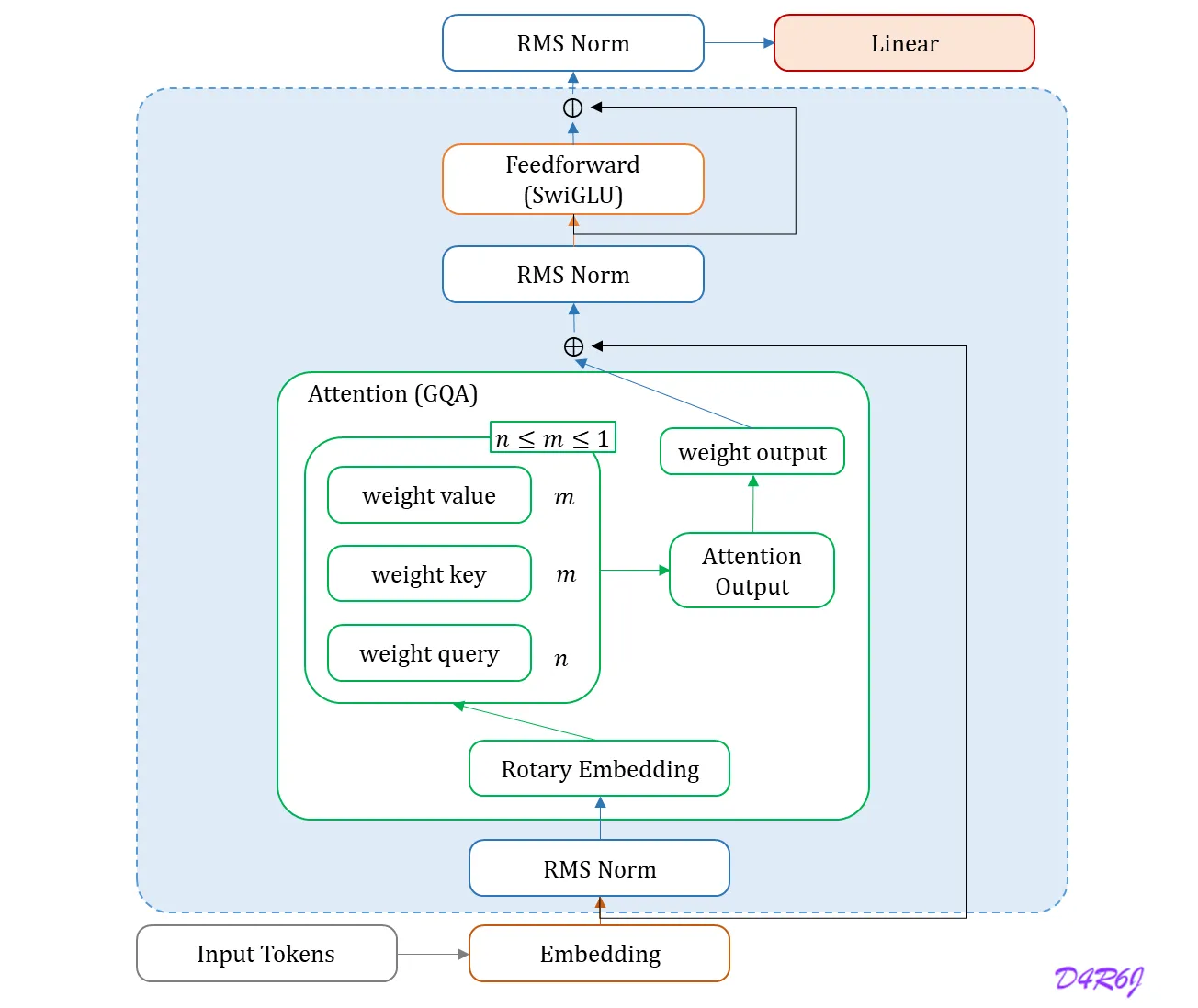
Llama 2 와 비교하여 몇 가지 작은 수정을 한다.
- 추론 속도를 향상 시키고, 디코딩 하는 동안 key-value 캐시 사이즈를 줄이기 위해서 8 key-value 가 있는 GQA (Grouped Query Attention) 을 사용한다.
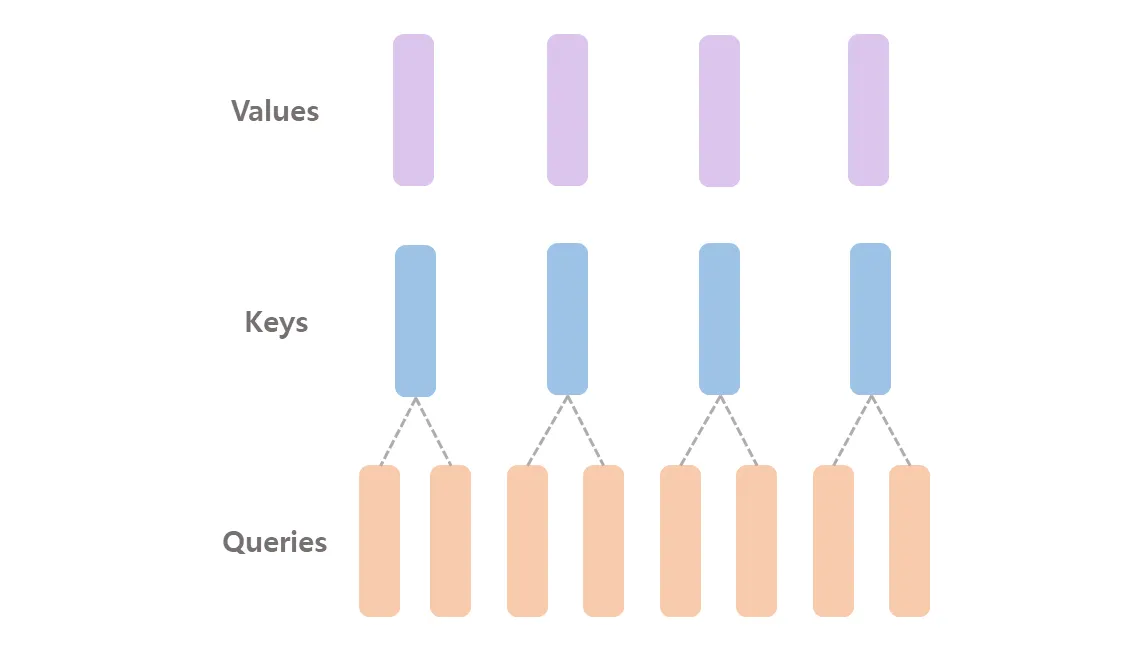
그런데,
-
Llama 3 의 주요 hyperparameters
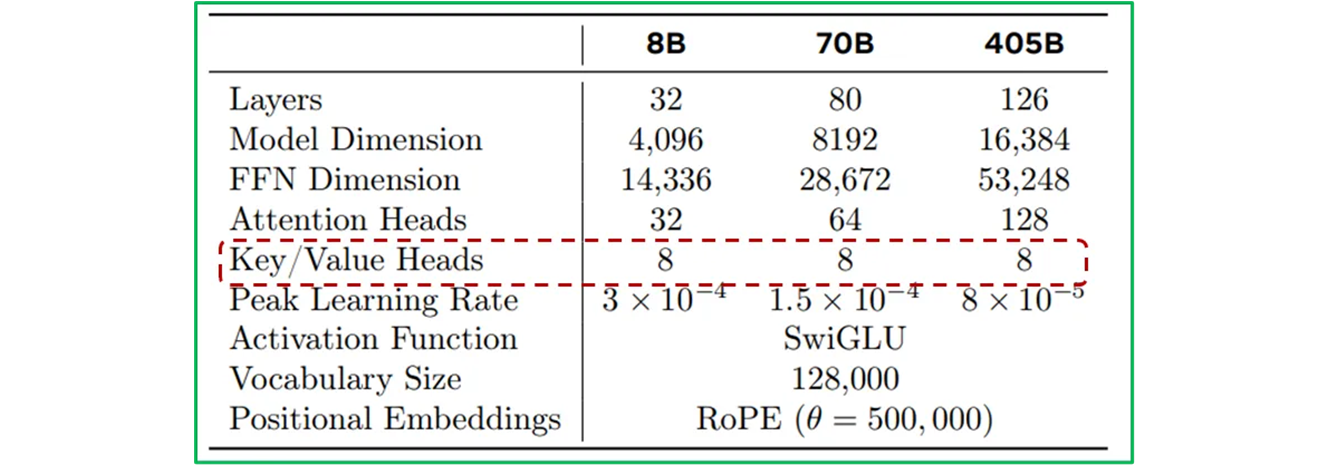
그런데, 실제 llama2_base_model 도
n_kv_heads는 “8” 이다. 그리고 간혹 “16” 설정을 할 때가 있는데, 405B 에BF16을 사용할 때이다.Model( core_model_id=CoreModelId.llama3_1_405b, description="Llama 3.1 405b model (BF16 weights for mp16)", huggingface_repo="meta-llama/Llama-3.1-405B", recommended_sampling_params=recommended_sampling_params(), arch_args={ ... "n_kv_heads": 16, ... }, pth_file_count=16, ), -
동일한 sequence 내에서, 다른 문서들 사이에 self-attention 을 방지하는 attention mask 를 사용한다.
-
이 변화는 standard pre-training 을 하는 동안에는 제한적으로 영향을 미치지만, 매우 긴 sequence 에 대한 지속적인 pre-training 에서는 중요하다는 것을 알았다.
-
128K token 으로 vocabulary 를 사용한다. 우리의 token vocabulary 는 tiktoken tokenizer 100K 토큰에 28K 토큰을 더 붙여서 영어 이외의 언어를 더 효과적으로 지원한다.
아니.. 영어 token 을 100K 쓰고, 나머지 non-eng token 을 28K 쓰면.. 영어 어순과 다른 비 영어권 즉, 한글은 정말 인식하기 어려울 듯 하다.
LLAMA2_VOCAB_SIZE = 32000 LLAMA3_VOCAB_SIZE = 128256 -
Llama2 tokenizer 와 비교 시 새로운 tokenizer 는 영어 데이터 샘플의 압축률을 3.17 에서 3.94 로 향상 시킨다. 이것은 동일한 양의 training comput 에 대해 더 많은 text 를 “read” 할 수 있다.
-
또한 영어 이외의 언어에서 28K tokens 를 추가하면 영어 tokenization 에 영향을 주지 않고 압축 비율과 downstream 성능이 모두 향상 된다는 사실을 발견했다.
독립적으로 분리하여 token 을 관리하여 붙여서 사용하는 것은 하나의 팁으로 볼 수 있다. corpus 자체가 다를 뿐더러, 그 빈도수 또한 영어와 전혀 다른 distribution, 더 나아가 space 를 구성하고 있기 때문.
-
RoPE 기본 주파수의 hyperparameter 를 500,000 으로 증가 시킨다. 이를 통해서 더 긴 컨텍스트를 더 효과적으로 지원할 수 있다. 이 값이 최대 컨텍스트 길이에 대해 효과적인 것으로 나타났다.
-
Llama 3
405B는 126 개의 layer 를 갖는 구조를 사용하고, token representation 차원을 및 attention head 이다.Model( core_model_id=CoreModelId.llama3_1_405b, is_default_variant=False, description="Llama 3.1 405b model (BF16 weights for mp16)", huggingface_repo="meta-llama/Llama-3.1-405B", recommended_sampling_params=recommended_sampling_params(), arch_args={ "dim": 16384, "n_layers": 126, "n_heads": 128, "n_kv_heads": 16, "vocab_size": LLAMA3_VOCAB_SIZE, "ffn_dim_multiplier": 1.2, "multiple_of": 4096, "norm_eps": 1e-05, "rope_theta": 500000.0, "use_scaled_rope": True, }, pth_file_count=16, ),
이것으로 FLOPs 의 훈련 예산에 대한 데이터의 확장 법칙에 따라 대략적으로 compute-optimal 에 대략적인 모델 크기가 생성된다.
정령.. 내가 보고 있는 이 값들이 현존하는 모델의 값 들인가?
3.2.1 Scaling Laws
- pre-training 컴퓨팅 예산을 고려하여 주력 모델에 대한 최적의 모델 크기를 결정하기 위해서 scaling laws 를 개발한다. 최적의 모델 크기를 결정하는 것 외에
-
기존의 존재하고 있는 scaling laws 는 일반적으로 특정 벤치마크 성능이 아닌 next-token prediction loss 로만 예측한다.
-
기존의 존재하고 있는 scaling laws 는 작은 컴퓨텅 예산으로 실행된 pre-training 기반으로 개발 되기 때문에, 잡음이 많고, 신뢰할 수 없다.
-
위와 같은 몇 가지 문제로 인해, downstream 벤치마크 작업에서 주력 모델의 성능을 예측하는 것이 major challenge 이다.
- 이러한 challenges 를 해결하기 위해서, downstream 벤치마크 성능을 정확하게 예측하는 scaling laws 를 개발하기 위한 two-stage 방법론을 구현한다.
-
다운스트림 tasks 에서 계산-최적화 모델의 negative log-likelihood 와 training FLOPs 사이의 상관관계를 설정한다.
-
scaling law 모델과 더 높은 compute FLOPs 로 훈련된 예전 모델 모두 활용하여 downstream 작업의 negative log-likelihood 를 작업 정확도와 연관시킨다. 이 단계에서 특별히 Llama 2 모델의 제품군을 활용한다.
이 접근 방식을 사용하면 컴퓨터 최적화 모델에 대한 특정 수의 training FLOPs 에 따라 downstream 작업 성능을 예측 가능하게 한다. 이와 유사한 방법을 사용하여 pre-training data mix 를 선택한다.
즉, 이말을 보자면, Scaling 의 법칙.. 한번에 얼마나 많이 받아들여서 얼마나 처리 가능하느냐의 개념인것이고, 이것이 모델 크기와 data mix 도 결정짓는 아주 중요한 요인이 된다는.. 어쩌면 당연하지만.. 써있는 것을 보니 놀랍다..
Scaling law experiments
-
구체적으로 FLOP 에서 FLOP 사이의 컴퓨팅 예산을 사용하여 model 을 pre-training 함으로써, scaling law 를 구성한다.
-
각 컴퓨팅 예산에서 모델 크기의 subset 을 사용하여 40M 에서 16B 파라미터 크기 범위의 모델을 pre-train 한다. 이러한 training runs 에서는 2000 개의 training steps 에 대해서 linear 가 포함된 cosine learning rate 을 사용한다.
- learning rate 의 최대 값은 모델 크기에 따라서 와 사이로 설정된다.
- cosine decay 는 peak value 의 로 설정된다.
- 각 step 에서의 weight decay 는 해당 step 의 learning rate 의 10% 로 설정된다.
- 각 compute scale 에 대해서 고정된 batch size 를 사용하며 250K 에서 4M 사이로 설정한다.
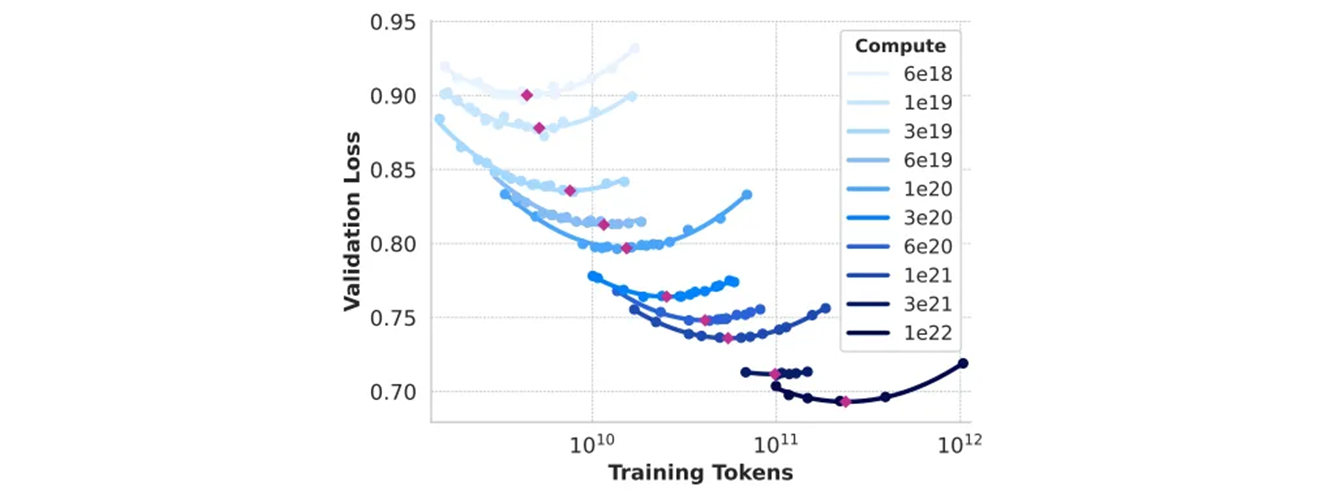
- Scaling law IsoFLOPs 곡선은 과 FLOPs 사이 이다.
- loss 는 따로 떼어둔 validation set 의 negative log-likelihood 이다.
- 2차 다항식을 사용하여 각 compute scale 에서 측정 값을 approximate 한다.
훈련 할때 같이 사용하는 validation set 이 아니라, 따로 떼어서 둔 validation set 이 존재한다. test set 과는 별도의 set 이다. 데이터 셋을 분리할 때, 정말 신중하게 분리해야 한다. 딥러닝도 데이터 싸움 이라고 생각한다.
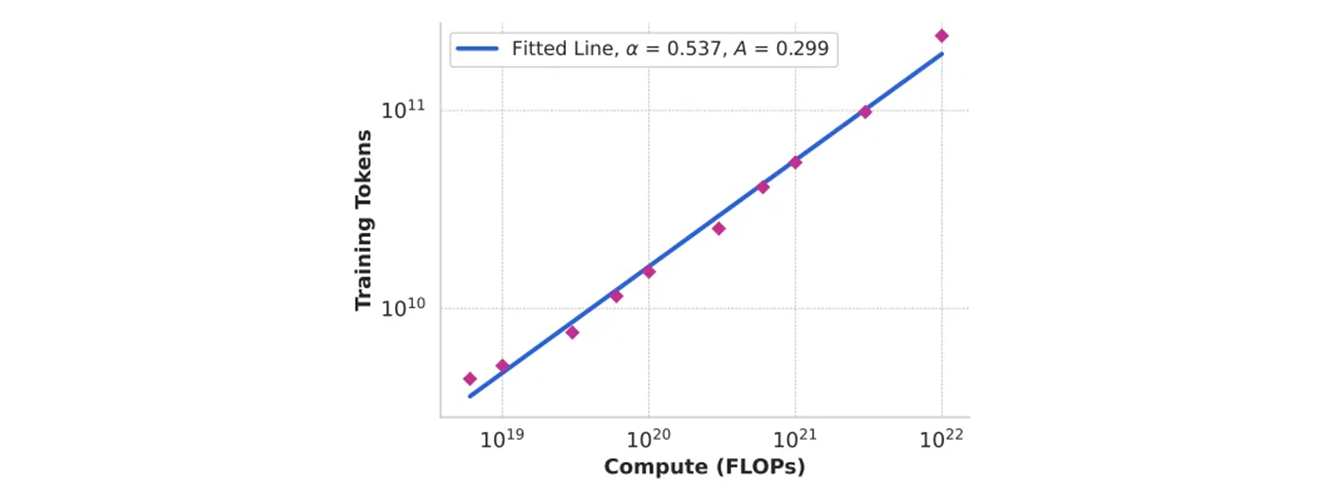
- pre-training compute budget 에 따른 compute-optimal model 의 학습 토큰 수. 적합한 scaling-law 예측도 포함한다.
- compute-optimal 모델은 위 Scaling law IsoFLOPs 곡선의 포물선(parabola) 최소값에 일치한다. 이러한 실험들은 IsoFLOPs 곡선을 생성한다.
- 이 커브들에 있는 loss 는 별도의 validation set 으로 측정한다.
여기서는 separate 를 사용하였지만, 위에서 held-out (따로 떼어둔) validation set 이라고 썼다.
- 2 차 다항식을 사용하여 측정된 loss 값을 맞추고, 각 포물선의 최소값을 식별한다.
이 2차 다항식은 validation loss 로 보면 내려갔다가 위로 튀어 오르는 위치를 잡아서 최적의 모델을 평가한다.
- pre-training 된 compute budget 에서 포물선의 최소 값을 compute-optimal 모델을 사용한다.
특정 compute budget 에 대한 training 토큰의 최적 수를 예측하기 위해서 위와 같은 방식으로 식별한 compute-optimal 모델들을 사용한다. 이것을 위해서 compute budget 와 training token 의 최적의 수 사이의 거듭제곱 관계로 가정한다.
Scaling law IsoFLOPs 에서의 데이터를 사용한 와 를 fit 한다. 로 해당 fit 은 위 그림에서 보여준다. scaling law 의 결과를 FLOPs 로 Extrapolation 제시하면, 토큰들에서 파라미터 모델을 훈련한다.
0.29 * math.pow(3.8 * 1e+25, 0.53)
# 10,463,652,401,050.807주어진 숫자로만 계산해보면, 10.45T 가 나온다. 6T 정도는 어디서 나오는지 모르겠지만, 조금 더 다른 상수나 변경된 값이 적용될 수 있다.
- 중요한 발견은 compute budget 이 증가함에 따라서 IsoFLOPs 곡선이 최소값 주변에서 좀 더 평평해진다는 것이다.
- 이것은 주력 모델의 성능이 모델의 크기와 훈련 토큰 간 trade-off (균형) 의 작은 변화에 상대적으로 robust 하다는 것을 의미한다.
이 개념을 보자면, FLOPs 로 보면 16.55T 토큰까지 받아내고, 따라서 모델의 크기도 정해진다는 의미인듯. 그렇다면 의 FLOPs 기준만 잡으면 될듯.
이러한 발견을 기반으로 궁극적으로 매개변수를 사용하여 주력 모델을 훈련하기로 결정한다.
FLOPS 가 (FLoating point Operations Per Second) 로 초당 부동소수점 연산 횟수 인데.. 이면 이상해서 찾아보니 s 가 소문자여서 모델을 훈련하는 전체 과정에서의 총 계산량을 FLOPs 로 표현한 것으로 본다고 한다. 따라서 전체 학습에 걸쳐 수행된 총 연산 회수를 나타내며, 모델 size 와 학습에 필요한 token 수에 따라 계산된 값이다.
Predicting performance on downstream tasks.
벤치마크 data set 들에서 주력 Llama 3 모델의 성능을 예측하기 위해 결과로 얻은 compute-optimal 모델들을 사용한다.
-
우선, 벤치마크에서 올바른 답의 negtive log-likelihood 와 training FLOPs 를 선형적으로 상관관계 시킨다. 이번 분석은 위에서 설명한 data mix 에 대해서 최대 FLOPs 까지의 훈련된 scaling law 모델들을 사용한다.
-
Llama 2 data mix 와 tokenizer 를 사용하여 훈련된 Llama 2 모델들과 scaling law model 들을 모두 사용하여 log-likelihood 와 accuracy 사이의 sigmoid 관계를 설정한다.
-
아래와 같은 ARC Challenge 벤치마크에서 이와같은 실험의 결과를 보여준다.
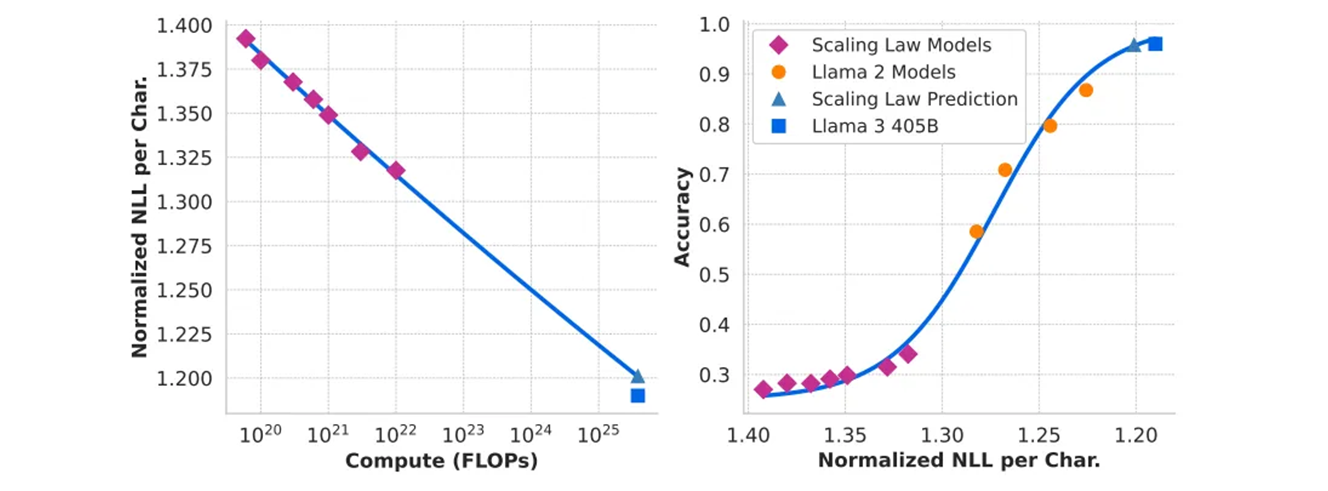
- 왼쪽 : pre-training FLOPs 의 함수로써 ARC Challenge 벤치마크에서 정답의 Normalized negative log-likelihood.
- 오른쪽 : 정답의 nomalized negative log-likelihood 에 따른 ARC Challenge 벤치마크의 정확도.
- 이 분석은 pre-training 이 시작되기 전에 ARC Challenge benchmark 에서 모델 성능을 예측.
ARC Challenge 는 AI2 Reasoning Challenge 즉 AI 의 논리적 추론과 문맥 이해 능력의 Challenge 인데, 비슷한 이전 구조의 Llama2 는 있으니까 그것으로 평가하고, 확장된 Llama3 의 성능을 예측한다는 것 으로 이해했다.
4배 이상의 크기를 추정하는 two-step 확정 법칙 예측이 매우 정확하다는 것을 알았다. 이것은 주력 제품인 Llama 3 모델의 최종 성능을 약간 과소 평가할 뿐이다.
3.3 Infrastructure, Scaling, and Efficiency
Llama 3 405B 사전 훈련을 대규모로 지원하는 하두웨어 및 infra 를 설명하고, 훈련의 효율성을 향상 시키는 몇 가지 최적화에 대해 논의한다.
3.3.1 Training Infrastructure
Llama 1 과 2 모델은 Meta 의 AI Research SuperCluster 에서 훈련했다. 규모가 더 확장됨에 따라서 Llama 3 에 대한 교육이 Meta 의 production cluster 로 migrated 되었다.
이 설정은 training 을 확장할 때 필수적인 production-grade 안정성에 대한 최적화이다.
여기서부터는 GPU 등 하드웨어 이야기. 특히 GPU 컨트롤 하는 부분은 굉장히 흥미롭다. 역시 CUDA 와 NCCL 같은 parallelism 같은 코드 및 흐름은 분석해 볼 만한 가치가 충분히 있다.
Compute
- Llama 3
405B는 최대 16K H100 GPU 로 훈련하고, Meta’s Grand Teton AI server platform 을 사용하여 80GB HBM3 과 함께 700W TDP 로 돌린다. - 각 서버에는 8개의 gpu 와 2개의 cpu 가 장착되어 있다. 각 서버마다 8 개의 GPU 를 NVLink 를 통해 연결했다.
- Training job 들은 Meta 의 global-scale 훈련 스케줄러 (MAST) 를 사용하여 schedule 했다.
16K H100 GPU .. 다양한 테스트, 다양한 모델, 다양한 평가, 그리고 다양한 경험..
Storage
- Meta 의 범용 분산 파일 시스템인 Tectonic 은 Llama 3 사전 훈련을 위한 fabric 저장소를 구축하는데 사용된다.
- SSD 가 장착된 7500 개의 서버는 240PB 를 제공하고, 2TB/s 의 지속 가능한 처리량과 7TB/s 의 최대 처리량을 지원한다.
- major challenge 는 짧은 기간동안 storage fabric 을 포화 (saturate) 시키는 매우 폭발적인 checkpoint 쓰기를 지원한다.
- Checkpoint 는 복구 및 디버깅을 위해 GPU 당 1MB ~ 4GB 범위로부터 각 GPU 의 모델 상태를 저장한다.
주로 발생할 수 있는 문제들은 하드웨어 문제 (GPU, 전력, 메모리), 소프트웨어 문제 (훈련 중단, 네트워크 문제), 모델 훈련 (과적합, 오류 전파 문제), 리소스 할당 및 스케줄링 문제 등으로 볼 수 있다.
checkpoint 중 일시 중지 기간을 최소화하고 checkpoint 빈도를 증가시켜서 복구 후의 손실된 작업량을 줄이는것을 목표로 한다.
SSD 도 7500 개에 놀랍지만,
405B의 checkpoint 를 저장하기 위해서는 모든 리소스를 끌어 당겨서 write 할 듯, load 할 때도 마찬가지..
Network
- Llama 3
405B는 Arista 7800 과 Minipack2 Open Compute Project OCP rack 스위치를 기반으로 하는 RoCE (RDMA over Converged Ethernet) fabric 을 사용했다. - Llama 3 제품군의 작은 모델은 Nvidia Quantum2 Infiniband fabric 을 사용하여 훈련되었다.
- RoCE 와 Infiniband cluster 들은 모두 GPU 간의 400Gbps 상호 연결을 활용한다.
- 이러한 클러스터들 간의 기본 네트워크 기술 차이에도 불구하고, 이러한 대규모 training workloads 에 대해 동일한 성능을 제공하기 위해 두 클러스터 모두 조정한다.
RoCE 네트워크의 설계를 완전히 소유하고 있으므로, RoCE 네트워크에 대해서 자세히 설명한다.
Network topology.
RoCE 기반의 AI 클러스터는 three-layer Clos network 로 연결된 24K GPUs 로 구성된다.
- bottom layer 에서 각 rack 은 두 서버 간에 분할되고 단일 Minipack2 Top-of-the-Rack (ToR) 스위치로 연결된 16 개의 GPU 를 호스팅한다.
- middle layer 에서는 이러한 rack 192 개가 Cluster Switches 에 의해서 연결되어 3,072 GPU 의 pod 를 형성하므로, 전체 대역폭 (Full bisection bandwidth - 모든 장치들의 대역폭을 균등하게) 을 확보하여 네트워크 병목 현상이 발생하지 않도록 보장한다.
bisection 은 절반 이라는 뜻이긴하나, 네트워크를 절반으로 나누어서 한쪽 절반에서 다른쪽 절반으로 가게 하여 병목 현상 없이 간다는 의미로 사용.
- top layer 에서는 동일한 데이터 센터 건물 내의 8개 pod 가 Aggregation Switches 를 통해 연결되어 24000 GPU 의 클러스터를 형성한다.
- 그러나 aggregation layer 의 네트워크 연결은 full bisection bandwidth 를 유지하지 않고 대신 1:7 의 oversubscription 을 갖는다.
모델 병렬화 방법 (Section 3.3.2) 과 훈련 작업 스케쥴러는 모두 네트워크 topology 를 인식하도록 최적화되어 pod 들 간의 네트워크 통신을 최소화 하는 것을 목표로 한다.
Load balancing
LLM 훈련은 Equal-Cost Multi-Path (ECMP) routing 과 같은 기존 방법을 사용하여 사용 가능한 모든 네트워크 경로에서 load balance 가 어려운 network 흐름을 생성한다. 이 문제를 해결하기 위해서 두 가지 기술을 사용한다.
-
우선, collective library 는 2개의 GPU 사이에 16 개의 network flows 를 생성하여 각 흐름의 트래픽을 줄이고, 더 많은 흐름을 로드 밸런싱에 사용할 수 있게 한다.
-
향상된 ECMP (E-ECMP) 프로토콜은 패킷의 RoCE 해더의 추가 필드들을 해싱하여 이 16개의 흐름을 서로 다른 네트워크 경로에 효과적으로 분산 시킨다.
ECMP 는 네트워크가 병목 현상 없이 여러 경로로 데이터를 분산해서 전송할 수 있도록 돕는 기술이다. 여러 경로로 트래픽을 나누어 분산 시켜 병목 현상을 줄인다.
Congestion control
- collective communication patterns 에 의해 발생하는 일시적인 혼잡과 버퍼링을 수용하기 위해서 spine 의 deep-buffer 스위치를 사용한다.
- 이 설정은 training 에서 흔하게 발생하는 느린 서버로 인하여 발생하는 지속적인 혼잡과 네트워크 백프레셔의 영향을 제한하는데 도움을 준다.
네트워크 백프레셔는 네트워크 흐름이 느려지거나 막히는 상황을 가리키며, 느린 서버가 병목을 일으키면 데이터 전송이 차단되거나 지연되는 현상을 말한다.
- 마지막으로 E-ECMP 를 통한 더 나은 load balancing 은 혼잡 가능성을 상당히 줄여준다.
이러한 최적화를 통해서 Data Center Quantized Congestion Notification (DCQCN) 과 같은 전통적인 혼잡 제어 방식 없이 24000 GPU 클러스터를 성공적으로 실행한다.
3.3.2 Parallelism for Model Scaling
largest models 를 훈련을 확장하기 위해서 — 4 가지 다른 유형의 병렬 처리 방법을 조합한 — 4D 병렬 처리를 사용하여 모델을 분할한다.
- 이 접근 방식은 계산을 여러 GPU 의 모델 매개변수, 최적화 상태, 기울기 및 activations 가 HBM 에 적합하도록 보장한다. 4D 병렬의 구현은 아래와 같다.
-
tensor parallelism :
TP
individual weight tensors 를 서로 다른 장치의 multiple chunks 로 분할한다. -
pipeline parallelism :
PP
model 을 vertically 로, layer 별로 여러 단계로 분할하여, 다른 장치들이 full model pipeline 의 다른 stage 를 병렬로 처리할 수 있도록 한다. -
context parallelism :
CP
입력 context 를 segments 로 나누어서, 매우 긴 sequence 길이 입력에 대한 메모리 bottleneck 현상을 줄여준다. -
data parallelism :
DP
완전 분할 데이터 병렬 처리 ( Fully Sharded Data Parallelism ) 를 사용하는데, 이 방식은 model, optimizer, 그리고 gradient 를 조각내어 분할한 후, 여러 GPU 에서 데이터를 병렬 처리를 수행하면서, 각 학습 단계 후에 동기화를 수행한다.
Llama 3 shard 최적화 상태 와 gradient 에 FSDP ( Fully Sharded Data Parallelism ) 를 사용하지만, 모델 분할의 경우에는 backward passes 중에 추가적인 all-gather communicaion ( 분산된 데이터를 GPU 로부터 모아서 전체 장치에 공유하는 통신 ) 을 피하기 위해서 forward 계산 후에 다시 분할 하지 않는다.
GPU utilization.
- 병렬성 구성, 하드웨어 및 소프트웨어를 신중하게 튜닝하여 아래 표에 표시된 구성에 대해 전체 BF16 모델 FLOP 활용률 (Model FLOPs Utilization : MFU) 를 38 ~ 43% 달성했다.

Llama 3 : 405B pre-training 의 각 stage 에 대한 scaling 구성 과 MFU.
-
인 8K GPU 의 MFU 가 43% 와 비교하여 인 16K GPU 의 MFU 가 41% 로 약간 감소한 것은 학습 도중에 global token 을 일정하게 유지하는데 필요한 DP 그룹당 batch size 가 더 낮아졌기 때문이다.
이 문장은 parallelism 에서 DP 그룹당 batch size 가 왜 더 낮아졌는지를 설명하는 내용이다.
-
DP 로 데이터를 더 많이 나누게 되면, 그 한 그룹이 작아지고, 따라서 처리해야 하는 데이터 양이 작아진다. 따라서 batch size 가 낮아지게 되므로, 연산이 줄게 되어 MFU 가 악간 감소하게 된다.
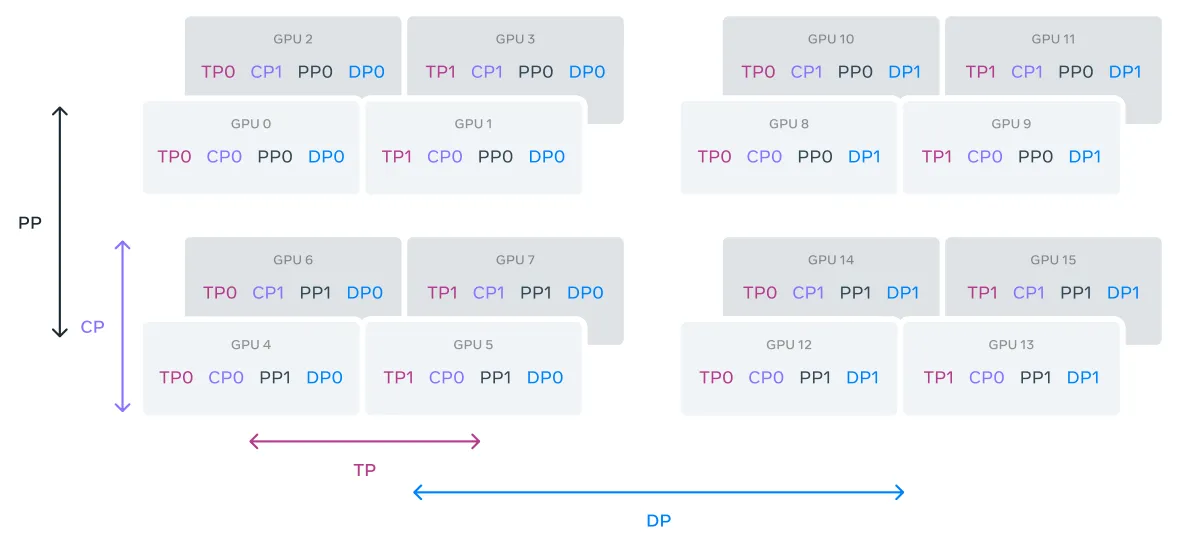
Illustration of 4D parallelism.
GPU 들은 TP, CP, PP, DP 순서로 병렬적 그룹들로 나누어지고, 여기서 DP 는 FSDP 를 나타낸다. 예를 들어, 16 GPU 는 TP, CP, PP, DP 는 2 의 group size 로 구성된다. 의 병렬 처리에서 GPU 의 position 은 vector 로 표현하고, 여기서 는 번째 병렬적 차원에 대한 index 이다.
- same TP group - GPU0 : [
TP0, CP0, PP0, DP0], GPU1 : [TP1, CP0, PP0, DP0] - same CP group - GPU0 : [TP0,
CP0, PP0, DP0], GPU2 : [TP0,CP1, PP0, DP0] - same PP group - GPU0 : [TP0, CP0, PP0, DP0], GPU4 : [TP0, CP0,
PP1, DP0] - same DP group - GPU0 : [TP0, CP0, PP0, DP0], GPU8 : [TP0, CP0, PP0,
DP1]
Illustration of pipeline parallelism in Llama 3.

stage 0~3 와 4~7 forward 로 나누고, stage 별로 쪼개서 순차적으로 넣고, M 은 micro-batch.
1. one batch 를 10 micro batch 로 나눈다.
2. 0 m-batch 가 stage 0~3 을 타고 간다.
3. 0 m-batch 가 stage 4~7 을 타고 간다.
4. 0 m-batch 의 backward 를 7 부터 거꾸로 시작하는데, backward 가 연산량이 높으므로 2개씩 잡고 처리한다.
5. 틈새 처리를 진행하고, 전체 flow 를 꽉 차게 연산한다.
- pipeline parallelism 은 8 개의 pipeline stage (0 ~ 7) 를 4 개의 pipeline rank 를 (PP rank 0 ~ 3) 까지 나눈다.
- 여기서 rank 0 을 가진 GPU 들은 0 번과 4번 단계를 실행하고, rank 1 을 가진 GPU 들은 1 번과 5번 단계를 실행한다.
이와 같은 방식으로 나머지 GPU 들도 할당된다.
- 색상이 지정된 block ( 0 ~ 9 ) 는 일련의 micro-batches 를 나타낸다.
- 여기서 은 micro-batch 의 총 개수이고, 은 같은 stage 의 forward 또는 backward 에 대한 연속적인 micro-batch 수 이다.
key insight 는 을 조정하게 만드는 것.
Pipeline parallelism improvements. 기존 구현에 몇 가지 문제에 마주쳤다.
Batch size constraint.
-
현재 구현은 gpu 당 지원되는 배치 사이즈에 대한 제약이 있으므로, pipeline stage 수로 나누는 것이 요구된다.
-
pipeline parallelism 의 depth-first schedule (DFS) 에는 를 요구하며, 반면에 breadth-first schedule (BFS) 에는 을 요구한다.
-
여기서 은 전체 micro-batch 의 수이고, 은 동일한 stage 의 forward 또는 backward 에 대해 연속적인 micro-batch 의 수를 나타낸다.
그러나 pre-training 에서는 batch size 를 조정할 수 있는 유연성이 필요한 경우가 많다.
-
DFS 방식에서는 하나의 pipeline stage 에서 모든 micro batch 가 처리된 후에 다음으로 넘어가는 방식. 는, 4 개의 pipeline 단계 가 있다는 것을 의미한다.
-
BFS 방식에서는 한번에 여러 단계를 동시에 처리하는 방식. N = M 이라는 의미는, M 이 전체 micro-batch 수를 나타내며, 이 방식에서는 모든 micro-batch 로 배치가 동시에 처리된다는 것을 의미한다.
Memory imbalance.
- 기존 pipeline parallelism 구현으로 인해 resource 소비 불균형이 발생한다. 첫 번째 stage 에서 embedding 및 warm-up micro-batches 로 인해 더 많은 메모리를 소비한다.
Computation imbalance.
-
모델의 마지막 layer 이후에 output 과 loss 를 계산하는 것이 필요하며, 이 단계 에서 실행 지연 병목 현상이 만들어진다.
-
이러한 이슈들을 해결하기 위해서, pipeline schedule 를 수정하여 N 을 유연하게 설정 할 수 있다. 이 경우 로 각 배치에서 임의의 수의 micro-batch 를 실행할 수 있다.
- large scale 의 batch size 가 제한이 있을 때, stage 의 수 보다 더 적은 micro-batch 수 이다.
- 더 많은 micro-batch 를 사용하여 point-to-point 통신을 숨기고, 최고의 통신 및 메모리의 효율성을 위해서 DFS 와 BFS 사이 의 최적 지점을 찾는다.
pipeline 의 균형을 맞추기 위해서 first 에서 last stage 에서 각각 하나의 Transformer layer 로 줄인다.
-
이것은 첫 번째 stage 의 첫 번째 모델 chunk 에는 embedding 만 있고, 마지막 stage 의 마지막 chunk 에는 output projection 과 loss calculation 만 있음을 의미한다.
-
pipeline bubble 을 줄이기 위해서 하나의 pipeline rank 에 V 개의 pipeline stage 가 있는 interleaved (번갈아가며 섞여 있는 상태) schedule 을 사용한다.
pipeline 처리 단계가 순차적이 아니라, 교차된 방식으로 처리되도록 설계된 스케줄이다. 비활성 시간을 줄이고, 파이프라인이 더 효율적으로 동작한다.
-
V 개의 pipeline stage 를 한 rank 에 할당한다는 것을 의미.
-
pipeline rank 는 각 GPU 가 처리하는 모델의 특정 단계를 나타낸다. V 개의 pipeline stage 는 한 pipeline rank 가 처리하는 stage 의 수
전체 pipeline bubble 비율 이다.
또한, PP 에서는 비동기식 point-to-point 통신을 채택하여, 특히 문서 마스크로 인한 추가 계산 불균형이 발생하는 경우, 훈련 속도가 상당히 빨라진다. 비동기 point-to-point 간의 통신에서 메모리 사용을 줄이기 위해 TORCH_NCCL_AVOID_RECORD_STREAM 을 활성화 한다.
마지막으로, 메모리 비용을 줄이기 위해서,
- 세부적인 메모리 할당 프로파일링을 기반으로 각 pipeline stage 의 input and output 텐서를 포함하여 향후 계산에 사용되지 않을 텐서를 미리 할당 해제한다.
- 아마 backpropagation 연산을 말하는 것 같고, framework 단에서 해주는 부분도 있다.
이런 최적화를 통해서 activation checkpoint 없이 8K token sequence 에 대해 Llama 3 을 사전 훈련할 수 있다.
Context parallelism for long sequences.
-
Llama 3 의 context 길이를 scaling 할 때, memory 효율성을 향상시키고, 최대 128K 길이의 매우 긴 sequences 에 대한 훈련을 가능하게 하기 위해 context parallelism 을 활용한다.
-
CP 에서는 sequence 차원에 걸쳐 분할하고, 구체적으로 입력 시퀀스를 chunk 로 분할하여 더 나은 load balancing 을 위해 각 CP rank 가 2 개의 chunk 를 받도록 한다.
-
번째 CP rank 는 번째와 번째 chunk 를 받도록 한다.
기존 CP 구현 방식은 링 구조 에서 communication 과 computation 을 겹치게 하지만, 현재의 CP 구현 방식은 all-gather 기반의 방법을 채택하여, 먼저 key (K) 와 value (V) 텐서들을 all-gather 로 모으고, local query (Q) 텐서 chunk 에 대해서 attention 출력을 계산한다.
all-gather communication 대기 시간이 중요한 경로 (critical path) 에 노출 되지만, 여전히 두 가지 주요 이유로 이 접근 방식을 채택한다.
-
all-gather 기반의 CP attention 에서 문서 마스크와 같은 다양한 유형의 attention mask 를 서포트 하는 것이 더 쉽고 유연하다.
-
노출된 all-gather 지연은 작다. 이유는 GQA (Grouped Query Attention) 을 사용하기 때문에, 통신되는 K 와 V 텐서들은 Q 텐서보다 훨씬 작기 때문이다.
따라서 attention 연산의 연산의 시간 복잡도는 all-gather 연산 보다 한 차수 (order of magnitude) 더 크다.
- attention 연산은 이고, all-gather 연산은 이다. 여기서 는 전체 causal mask 에서의 sequence length 를 나타낸다.
이로 인해서, all-gather 의 오버헤드는 무시할 수 있을 정도로 작다.
Network-aware parallelism configuration
-
parallelism dimension 의 순서인 는 network 통신에 최적화 되어 있다.
-
가장 안쪽의 parallelism 에는 가장 높은 네트워크 bandwidth 와 가장 낮은 latency 가 필요하므로, 동일한 서버 내로 제한된다.
-
가장 바깥쪽의 parallelism 은 multi-hop 네트워크를 통해서 분산 될 수 있고, 더 높은 네트워크의 대기 시간을 기다려야 한다.
-
그러므로, 네트워크 bandwidth 와 latency 요구사항을 기반으로 parallelism 차원을 [TP, CP, PP, DP] 순서로 배치한다.
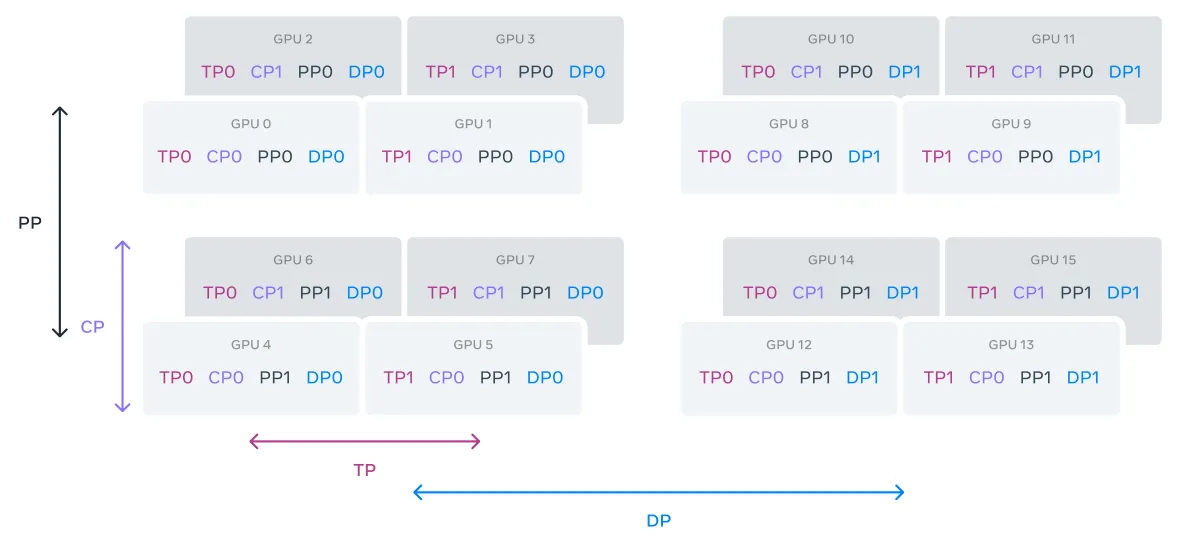
DP ( FSDP ) 는 가장 바깥쪽의 parallelism 인데, 샤딩된 (sharded) 모델 가중치를 비동기 적으로 미리 가져오고 ( prefetching ), 기울기 gradient 를 줄이는 방식으로 더 긴 network 지연을 견딜 수 있기 때문이다.
DP 는 동일한 모델을 여러 GPU 에 복제하고, 데이터 조각을 처리한다면, FSDP 는 모델의 가중치를 sharded 하여 각 GPU에 나누어 분배하여, 각 GPU 가 모델의 전체를 복제하지 않고, 자신에게 할당된 부분만 처리하는 방식. outermost parallelism 으로, 가장 큰 단위로 사용된다. 이로 인해서 더 긴 네트워크 latency 를 비동기적으로 미리 가져오고, 기울기 축소를 통해서 효율적으로 처리.
-
GPU 메모리 overflow 를 피하면서, 최소한의 통신 overhead 로 최적의 parallelism 을 식별하는 것은 도전적인 것 이다.
-
다양한 parallelism 구성을 탐색하고, 전반적인 훈련 성능을 계획하며 메모리 gap 을 효과적으로 식별하는데 도움이 되는 메모리 consumption estimator 와 performance-projection 툴을 개발한다.
Numerical stability.
-
다양한 parallelism setups 사이의 training loss 를 비교하여 training 안정성에 영향을 미치는 몇 가지 수치 이슈를 수정하였다.
-
training 수렴을 보장하기 위해서, micro-batch 에 대한 backward 계산 중에 FP32 gradient accumulation 을 사용하고 FSDP 의 data parallel worker 들 간에서 FP32 에 대한 gradient 를 reduce-scatter 방식으로 처리한다.
Reduce-scatter gradient 는 gradient 를 reduce 하면서 동시에 GPU 에 scatter 하는 통신 방식이다. DP 시에는 데이터가 분할되서 각 GPU 모델에 따로 들어가기 때문에 다른 데이터 조각을 사용해 계산된 기울기를 서로 결합하는 과정.
- forward 계산에서 여러 번 사용되는 vision encoder 출력과 같은 intermediate tensor 의 경우, backward gradients 도 FP32 에 누적된다.
3.3.3 Collective Communication
Llama 3 을 위한 collective communication library 는 NCCLX 라고 불리는 Nvidia’s NCCL 라이브러리의 fork 기반으로 한다. NCCLX 는 특히 latency 가 긴 network 의 경우 NCCL 성능을 크게 향상 시킨다.
- parallelism 차원의 순서는 [TP, CP, PP, DP] 이며, 여기서 DP 는 FSDP 에 해당한다.
- 가장 바깥쪽의 parallelism dimension 인 PP 와 DP 는 최대 수십 microseconds 의 latency 로 multi-hop network 를 통해서 통신할 수 있다.
원래 NCCL collectives — FSDP 의 all-gather 과 reduce-scatter 그리고 point-to-point 간의 PP (pipeline parallelism) 에는 data chunking 및 staged data copy 가 필요하다. 이 접근 방식은
- 데이터 전송을 가능하게 하기 위해서
- 네트워크를 통해 많은 수의 small control messages 를 교환해야 하고,
- 추가 메모리 복사 작업이 필요하고,
- 통신을 위한 추가 GPU 사이클을 사용하는 등
여러가지 비효율성이 발생한다.
-
Llama 3 training 의 경우, 대규모 cluster 에서는 수십 microsecond 가 될 수 있는 네트워크 대기 시간에 fit 하기 위해 chunking 과 data transfer 를 튜닝하여 이러한 비효율성의 하위 집합을 해결한다.
-
또한 small control message 가 더 높은 우선순위로 네트워크를 통과 할 수 있도록 허용하며, 특히 deep-buffer 를 가진 core switch 에서
head-of-line이 차단되는 것을 피하도록 한다.
항후에 Llama version 에 대한 지속적인 작업에는 앞에서 말한 모든 문제를 전체적으로 해결하기 위해서 NCCLX 를 더 깊게 변경하는 작업이 포함된다.
3.3.4 Reliability and Operational Challenges
16K GPU 훈련의 복잡성과 잠재적인 실패 시나리오는 운영해 온 훨씬 더 큰 CPU 클러스터 보다도 더 복잡하다. 게다가 훈련의 동기적인 특성으로 인하여 fault-tolerant 능력이 낮다.
GPU 한대가 실패해도 전체 작업을 다시 시작해야 할 수 있다. 이러한 challenges 에도 불구하고, Llama 3 의 경우 펌웨어 및 리눅스 커널 업그레이드와 같은 자동화된 cluster 유지 관리를 지원하면서, 90% 이상의 효과적인 training time 을 달성했으며, 이것은 하루에 적어도 한 번씩 훈련 중단이 발생했다. 효과적인 training time 은 경과 시간 동안, 실제로 유용한 훈련에 사용된 시간을 측정한 것이다.
54일간의 pre-training snap-shot 기간 동안, 총 466 번의 작업 중단을 경험했다.
생각 했던 것보다 작업 중단의 숫자가 많다.
이 중에서 47 번은 펌웨어 업그레이드 와 같은 자동 유지보수 operation 또는 데이터 셋 업데이트와 같은 운영자가 시작한 작업으로 인해 계획된 중단 이었다. 나머지 419 번은 예기치 않은 중단 이었고, 이 내역은 아래 표와 같다.
Root-cause categorization of unexpected interruptions during a 54-day period of Llama 3 405B pre-trainig.
- 예상하지 못한 중단의 약 78% 가 확인되거나, 의심되는 하드웨어 이슈 문제로 인해 발생하였다.
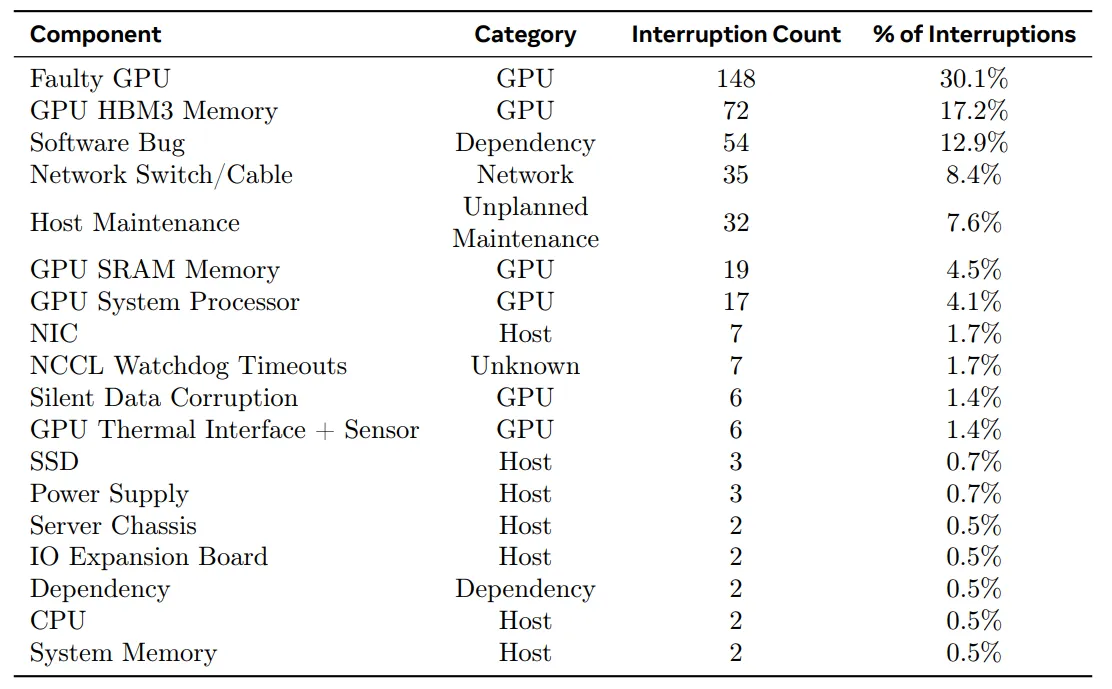
-
예기치 못한 training interruption 의 78%는 GPU 또는 호스트 컴포넌트 실패와 같은 확인된 하드웨어 문제, 또는 조용한 데이터 손상 (silent data corruption) 이나 계획되지 않은 호스트 개별 유지보수 이벤트와 같은 하드웨어 관련 문제로 인해 발생한 것으로 추정한다.
-
GPU 문제가 가장 큰 비중을 차지하고, 전혀 예기치 않은 문제의 58.7% 를 차지한다. 많은 수의 실패가 발생했음에도 불구하고, 이 기간 동안 특별한 수동 개입은 단지 3번 밖에 없었고, 나머지 문제는 자동화로 처리되었다.
-
효과적인 시간을 늘리기 위해서, 작업 시간과 체크포인트 시간을 줄이고, 빠른 진단과 문제 해결을 위해서 도구들을 개발했다. PyTorch 에 내장된 NCCL flight recorder 를 광범위하게 사용한다.
-
이 기능은 collective metadata 를 캡쳐하고, stack trace 를 링 버퍼에 캡처하여, 특히 NCCLX 에 관하여 문제에 대해 대규모의 정지와 성능 이슈를 빠르게 진단할 수 있게 해준다.
-
이것을 사용하여, 모든 통신 이벤트와 각 collective operation 의 지속 시간을 효율적으로 기록하며, NCCLX watchdog 또는 heartbeat 타임 아웃 발생 시에 자동적으로 tracing data 를 dump 할 수 있다.
-
코드 release 나 작업 재시작 필요 없이, 온라인으로 구성 변경을 통해서 production 환경에서 필요에 따라, 보다 더 계산 집중적인 연산들과 metadata 수집을 선택적으로 활성화 가능하다.
NVLink and RoCE
네트워크에서 NVLink 와 RoCE 를 섞어서 사용하면, large-scale training 시에 디버깅 이슈들이 복잡해진다.
-
NVLink를 통한 데이터 전송은 알반적으로 CUDA 커널에 의해 실행되는 load/store 연산을 통해 발생하고, 원격 GPU 또는 NVLink 통신 실패시에 자주 명확한 에러 코드를 리턴하지 않고, CUDA 커널 내에서의 load/store 작업이 정지되는 것으로 나타난다. -
NCCLX 는 PyTorch 와 긴밀한 공동 설계 (tight co-design) 를 통해서 실패 감지 및 위치 를 빠르고 정확하게 향상 시켜서, PyTorch 가 NCCLX 의 내부 상태에 접속하고 관련 정보를 추적할 수 있도록 허용한다.
-
NVLink 장애로 인해 중단을 완전히 예방할 수는 없지만, 통신 라이브러리의 상태를 모니터링하고, 이와 같은 중단이 감지될때 자동적으로 time out 이 된다.
-
NCCLX 는 각 NCCLX 통신의 kernel 및 network 활동을 추적하고, 모든 rank 간의 완료 및 대기중인 데이터 전송을 포함하여 실패한 NCCLX 집단의 내부 상태에 대한 snapshot 을 제공한다. NCCLX scaling 문제를 디버깅 하기 위해서 이 데이터를 분석한다.
stragglers
때때로, 하드웨어 이슈로 인해서 여전히 작동하지만, 탐지하기 어렵고 다른 작업들 보다 훨씬 느리게 수행하는 낙오자가 발생할 수 있다.
-
단 한개의 낙오자가 다른 GPU 들의 수천개를 느리게 할 수 있고, 종종 동착하는 것 처럼 보이지만, 늦게 통신한다.
-
선택된 process groups 에서 잠재적으로 문제가 있는 통신들의 우선순위를 정하는 도구들을 개발했다. 소수의 주요 용의자를 조사함으로써, 낙오자들의 증명을 효율적으로 식별할 수 있다.
environmental factors
한 가지 흥미로운 관찰은 환경 요인이 규모에 따르는 훈련 성능에 영향을 미치는 것이다.
-
Llama 3 405B 의 경우 하루 중 시간대에 따라서 1~2% 정도의 처리량 변동이 있음을 확인했다. 이러한 변동은 정오의 높은 온도가 GPU 동적 전압과 주파수 크기 조정에 영향을 미치는 결과다.
-
훈련 중에, 예를 들어, checkpoint 또는 집단 통신이 완료되기를 모든 GPU 들이 대기 하거나 전체 training 작업을 시작하거나 종료할 때 수만개의 GPU 가 동시에 전력 소비를 늘리거나 줄일 수 있다.
-
이러한 일이 발생하면, 데이터 센터 전체의 전력 소비가 수십 메가 와트로 즉시 변동되어 전력망의 제한이 풀어질 수 있다.
이것은 미래의 더 큰 Llama 모델에 대한 교육을 확장함에 따라서 지속되는 과제이다.
3.4 Training Recipe
Llama 3 405B 를 pre-train 하는데 사용되는 레시피는 3 가지 주요 단계로 구성된다.
- initial pre-training
- long-context pretraining
- annealing.
8B 와 70B 모델들을 pre-train 하기 위해 비슷하게 사용한다.
3.4.1 Initial Pre-Training
-
최대 learning rate 인 AdamW, 8000 스탭의 선형 warm up, 그리고 1,200,000 스텝에 걸쳐서 로 감소하는 cosine learning rate 을 사용하여 Llama 3 405B 를 pre-train 한다.
-
훈련 초기에 더 낮는 batch size 를 사용하여 training 의 안전성을 향상 시키고, 나중에 효과적인 학습을 위해 batch aise 를 증가시킨다.
-
구체적으로 4M 토큰의 초기 배치 사이즈와 길이 4,096 토큰의 sequence 를 사용하여, 252M 토큰을 pre-training 한 후에 8M 토큰의 배치 사이즈와 길이 8,192 토큰의 sequence 로 두배 늘린다.
-
2.87T 토큰을 pre-training 한 후에 batch size 를 16M 으로 두 배 늘린다. 이 training recipe 가 매우 안정적임을 찾았다. loss 급증이 거의 관찰되지 않았고, model training 발산을 수정하기 위한 개입이 요구되지 않았다.
여기서 놀란건, pre-training 하면서, 어느 정도 학습 후에 batch size 를 늘려서 이어서 학습한다는 점이다. dynamic batch size 정도 되려나..?
Adjusting the data mix.
특정 downstream 작업에 대한 모델 성능을 향상시키기 위해서 training 중에 pre-training 데이터 mix 를 여러 가지 조정했다.
-
특히 Llama 3 의 다국어 성능 향상을 위해서 pre-training 하는 동안 영어가 아닌 데이터의 비율을 증가 시켰다.
-
또한 모델의 수학적 추론 성능을 향상 시키기 위해서 수학적 데이터를 upsample 하고, pre-training 의 later 단계에서 최신 웹 데이터를 추가하여 모델의 지식 차단을 향상시켰고, 나중에 낮은 quality 로 확인된 pre-training 데이터는 하위 집합으로 downsample 했다.
3.4.2 Long Context Pre-Training
pre-training 의 마지막 스테이지에서 최대 128K 토큰의 context window 를 지원하기 위해서 long sequences 를 훈련한다.
-
self-attention layer 들의 계산은 sequence 길이에 2차적으로 증가하기 때문에 long sequences 에 대해 일찍 훈련하지 않는다.
-
모델이 증가된 컨텍스트 길이에 성공적으로 적응할 때 까지 pre-training 을 통해 지원되는 context 길이를 increments (2 의 제곱) 만큼 증가시킨다. 그리고 성공적인 적응 여부를 측정한다.
-
short-context 평가에서 모델 성능이 완전히 회복 되었는지.
짧은 길이의 입력 sequence 에서 모델이 얼마나 잘 동작하는지 평가하는 것. -
모델이 해당 길이 까지의 “needle in a haystack” 작업을 완벽하게 해결 하는지 여부.
건초 더미에서 바늘 찾기 : 매우 복잡하고 찾기 어려운 정보를 정확하게 찾아내는 과제.
- Llama 3 405B pre-training 에서는 원래 8K context window 에서 시작하여 128K context window 로 끝나는 6 단계에 걸쳐서 context 길이를 점진적으로 증가시켰다.
이 long-context 의 pre-training 단계는 근접하게는 800B training token 수를 사용하여 수행하게 되었다.
3.4.3 Annealing
마지막으로 40M tokens 을 pre-training 하는 동안, learning rate 을 선형적으로 0 까지 줄였으며, 128K token 들을 context 길이로 유지한다. 이 annealing 단계 동안 아주 높은 품질의 데이터 소스를 upsample 하기 위해서 data mix 를 조정했다. 마지막으로 pre-train 된 모델을 생성하기 위해서 annealing 하는 동안, 모델 체크포인트들의 평균을 계산한다.
