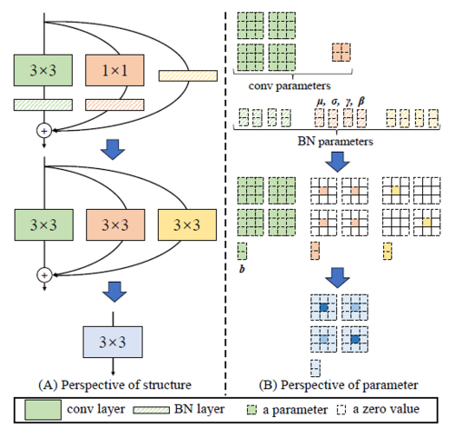
1. RepVGG
-
Architecture
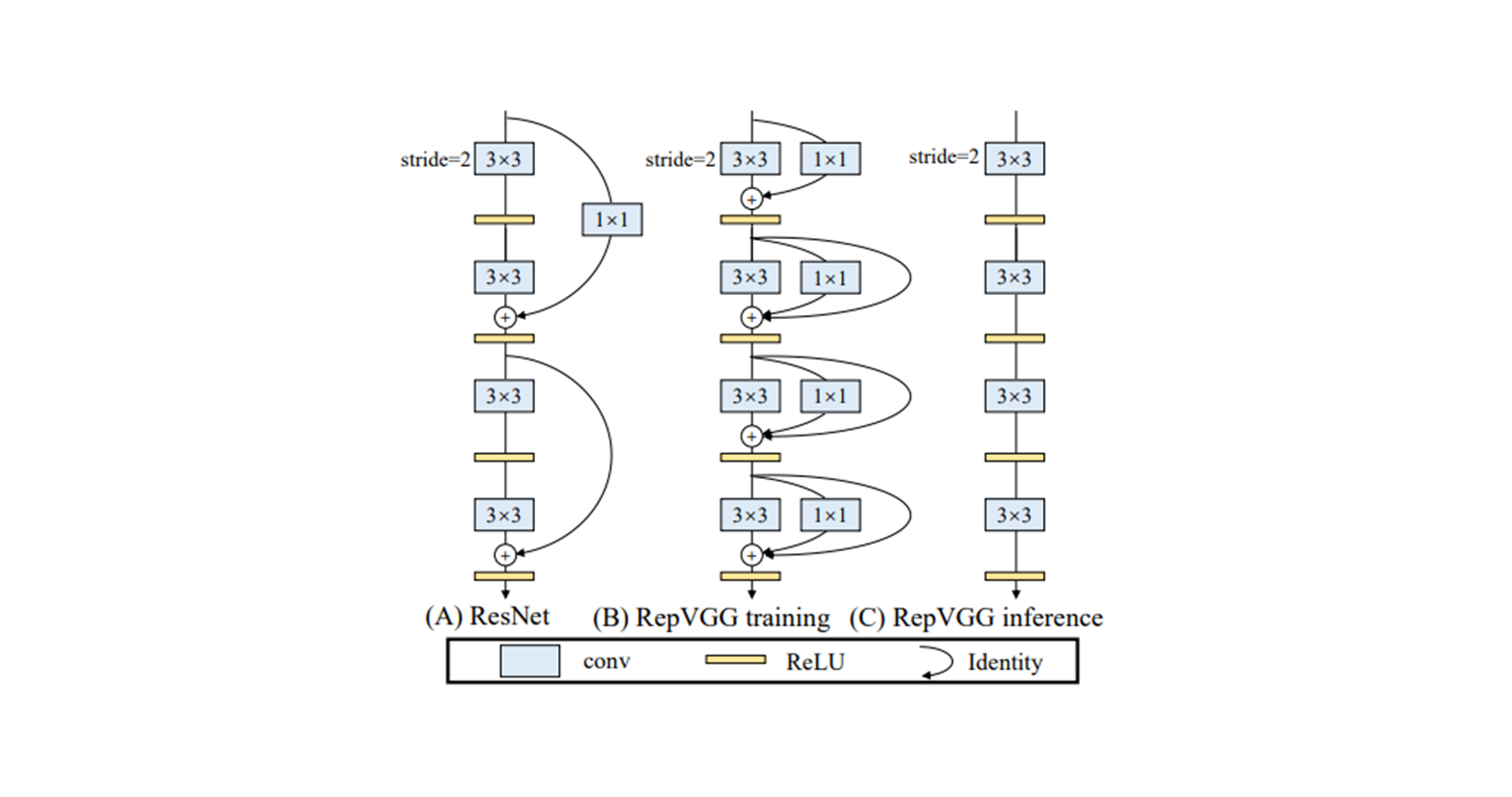
-
re-parameterize
- training time : multi-branched architecture
- inference time : a plain CNN-like structure
-
Review blog
2. MobileOne
-
Architecture
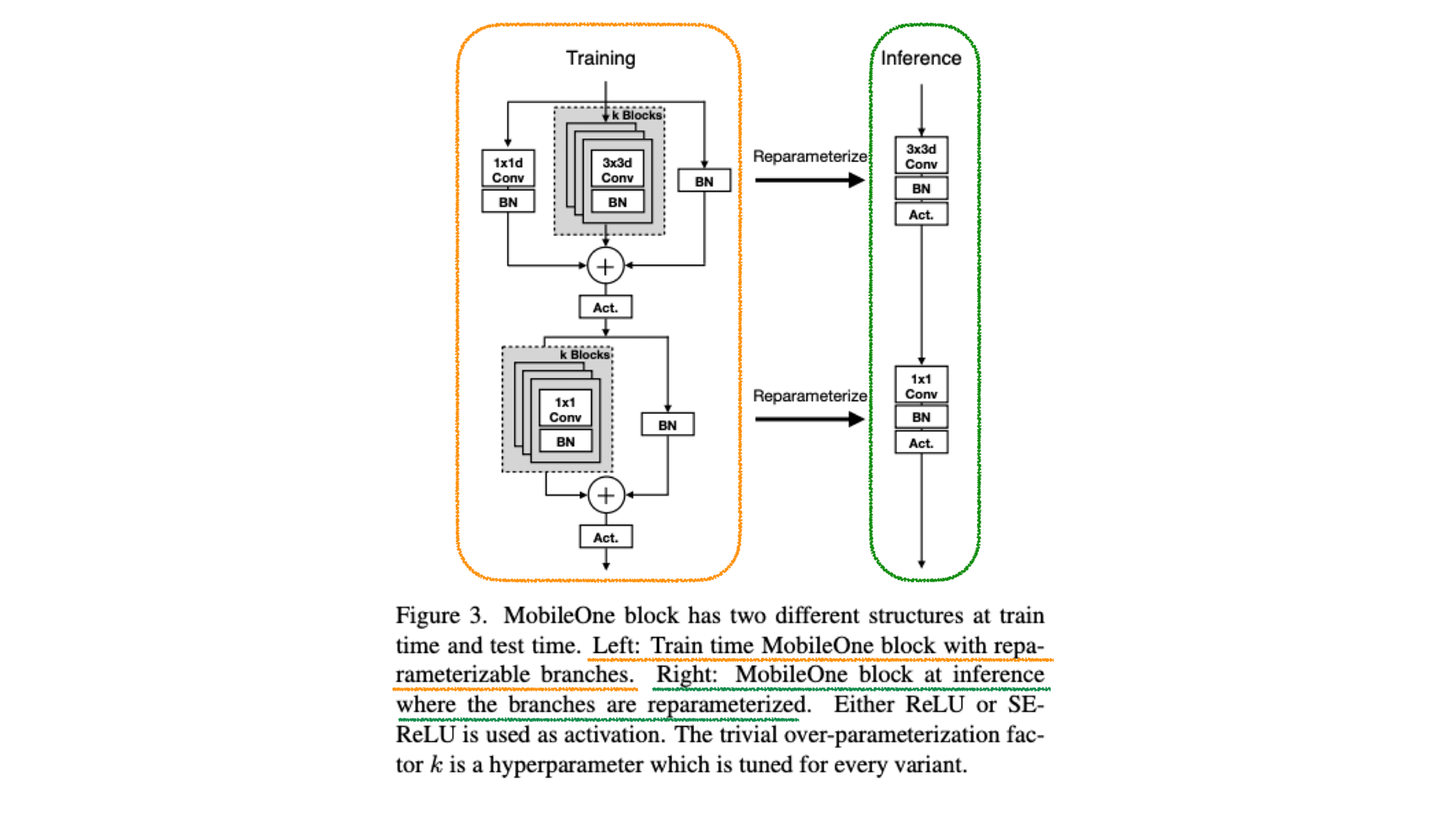
- Left : Train time MobileOne block with reparameterizable branches.
- Right : MobileOne block at inference where the branches are reparameterized.
- Up : depth-wise conv
- Down : point-wise conv
-
Conv-BN 이야기. ( 수식 - update 예정.)
3. MetaFormer
-
Architecture
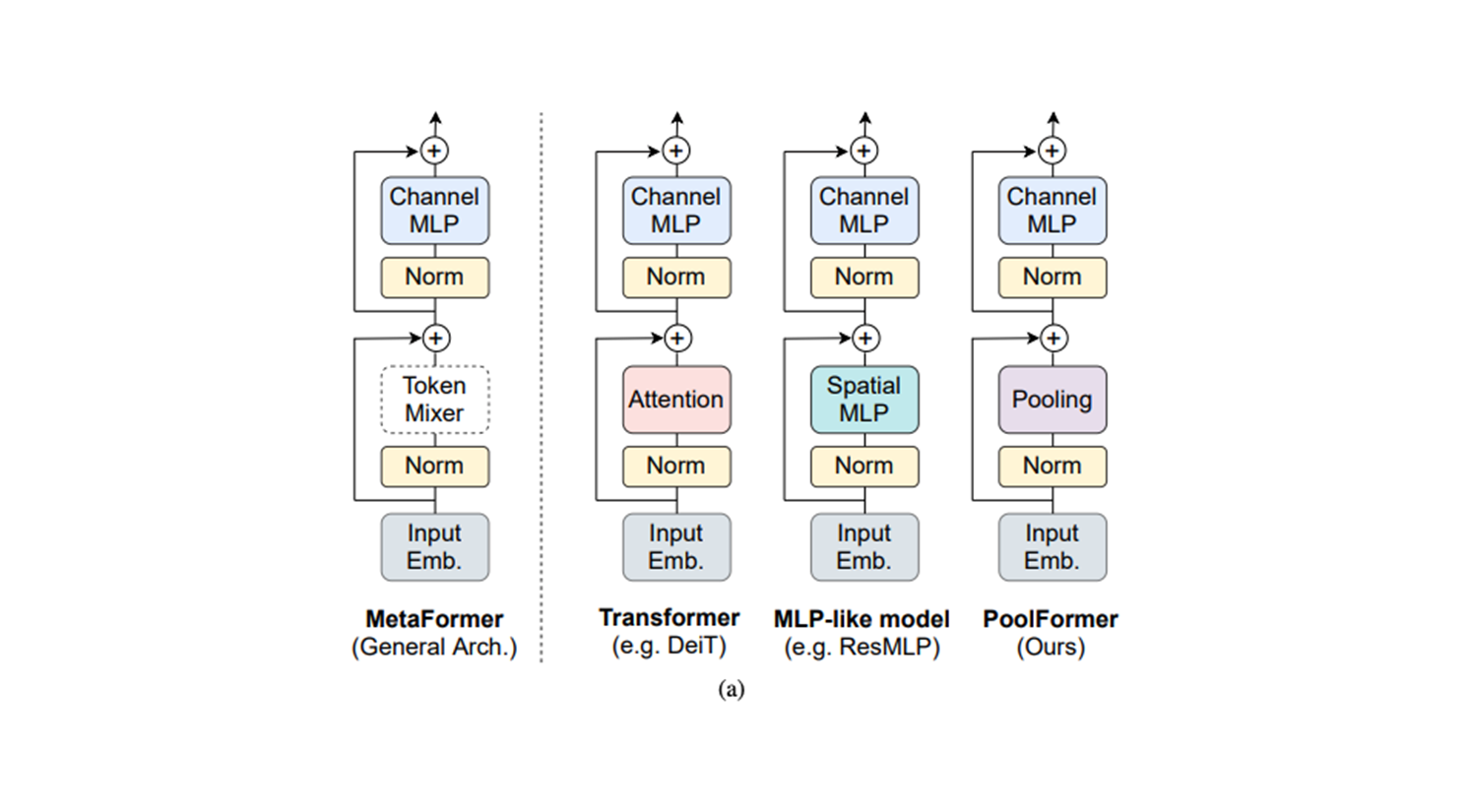
- Token Mixer ( via Fast-ViT )
token_mixers = ("repmixer", "repmixer", "repmixer", "attention")
4. MLP-Mixer
- Architecture
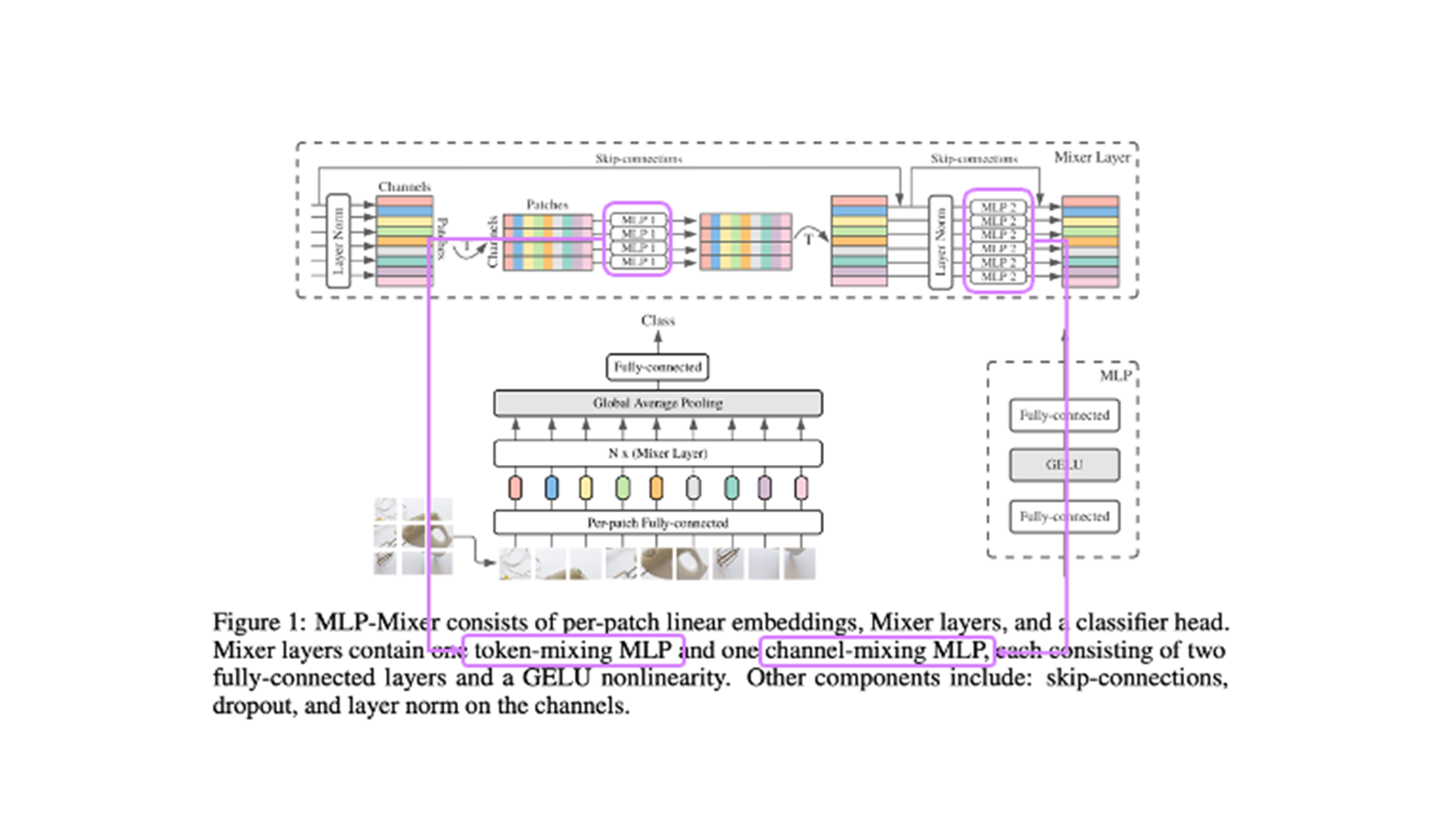
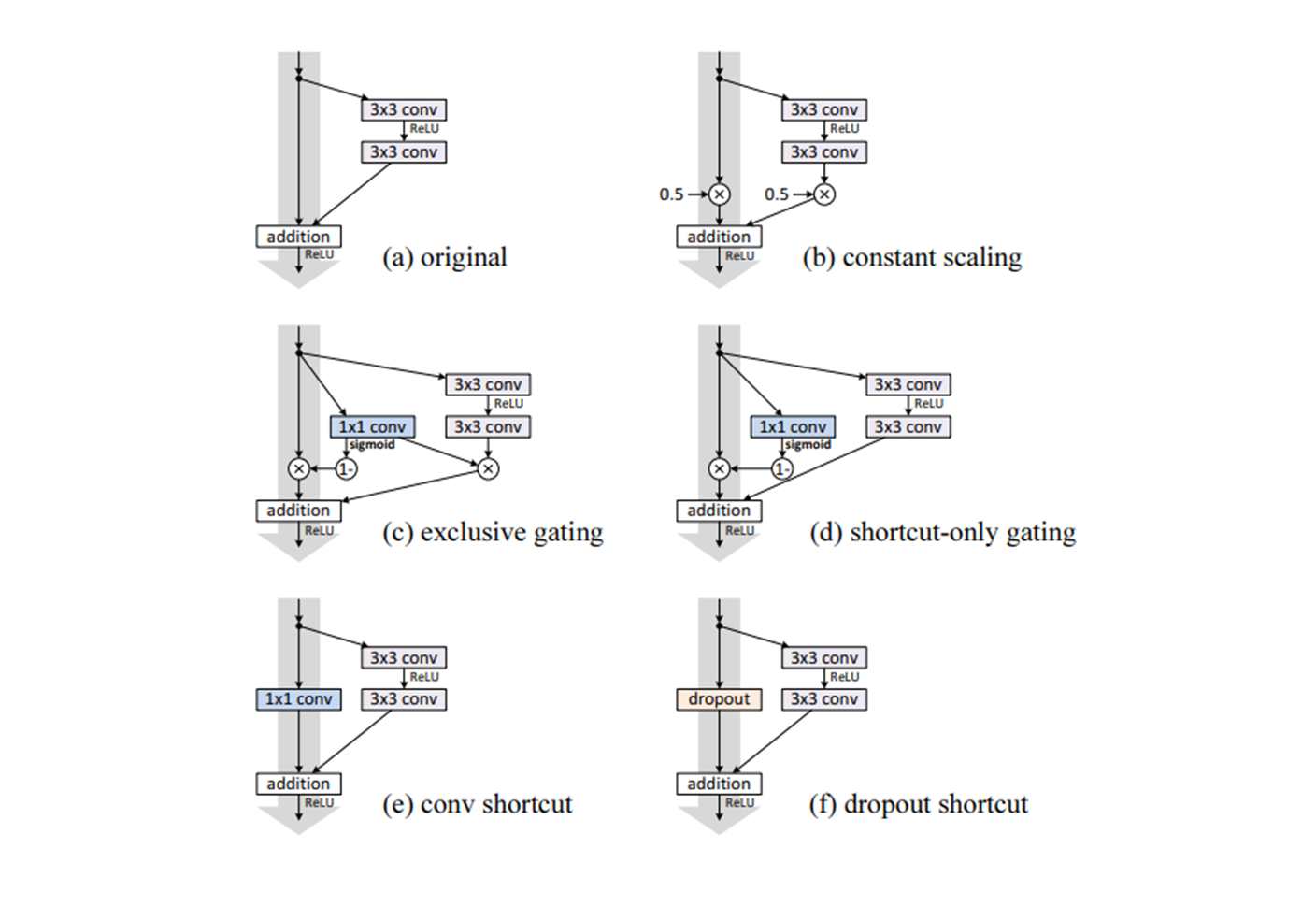
5. ResNet-v2
- Architecture
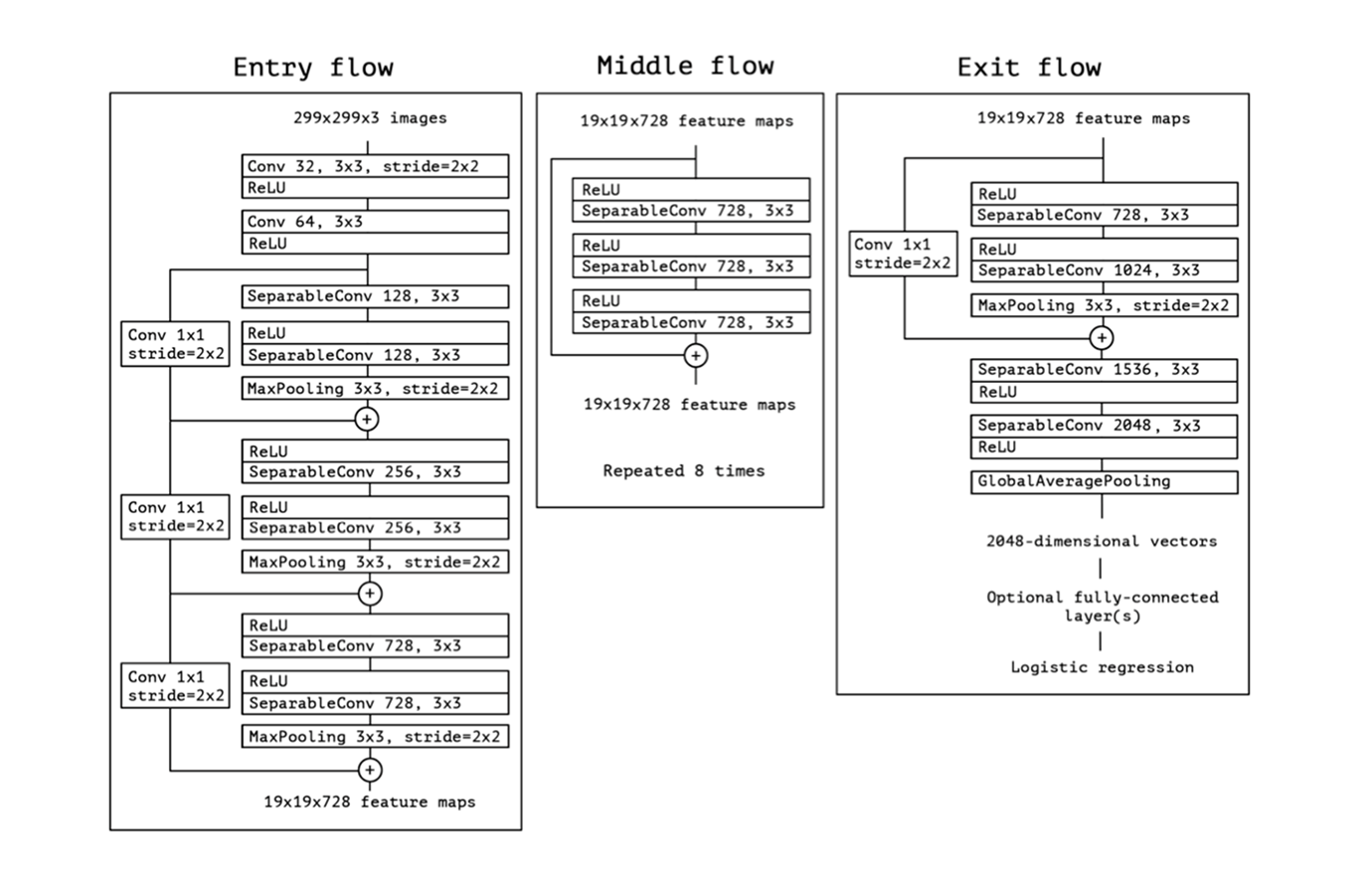
6. Xception
-
Architecture
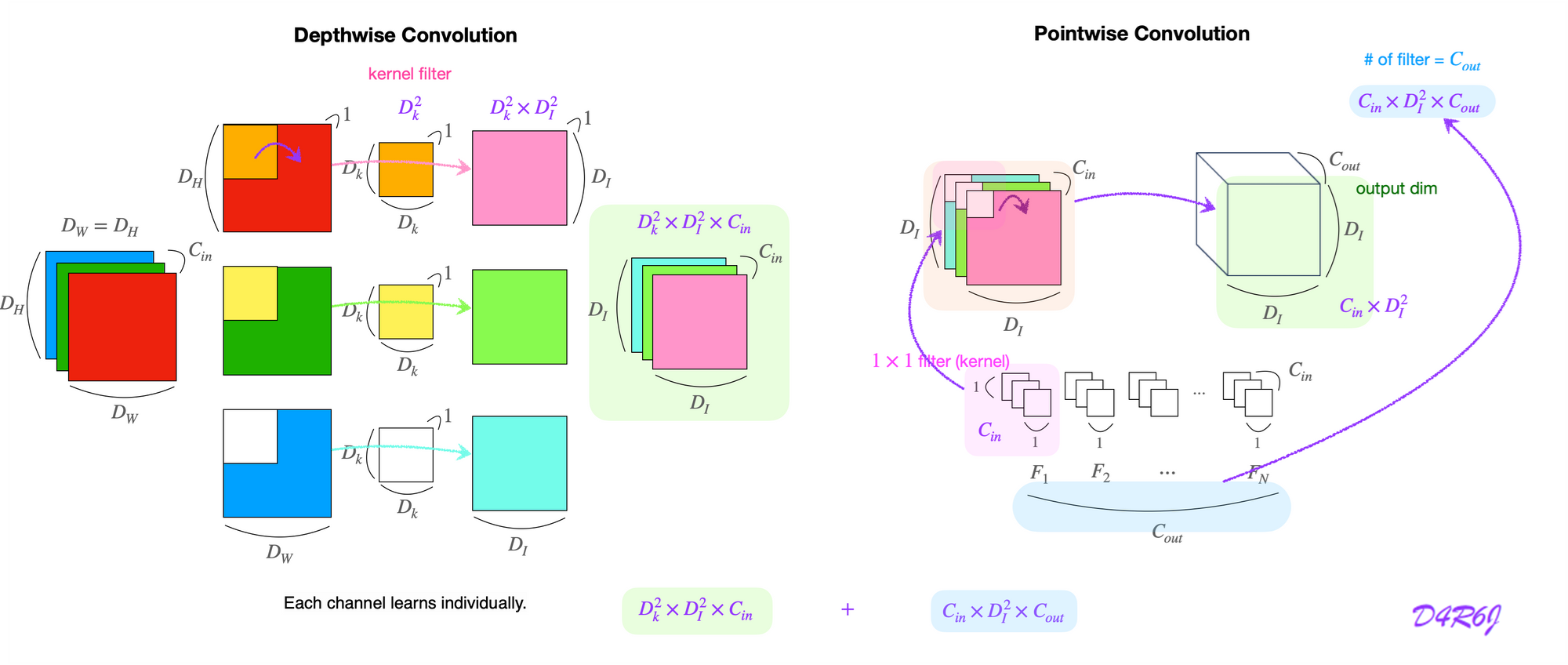
-
Depthwise Separable Conv
7. DeiT
- Architecture
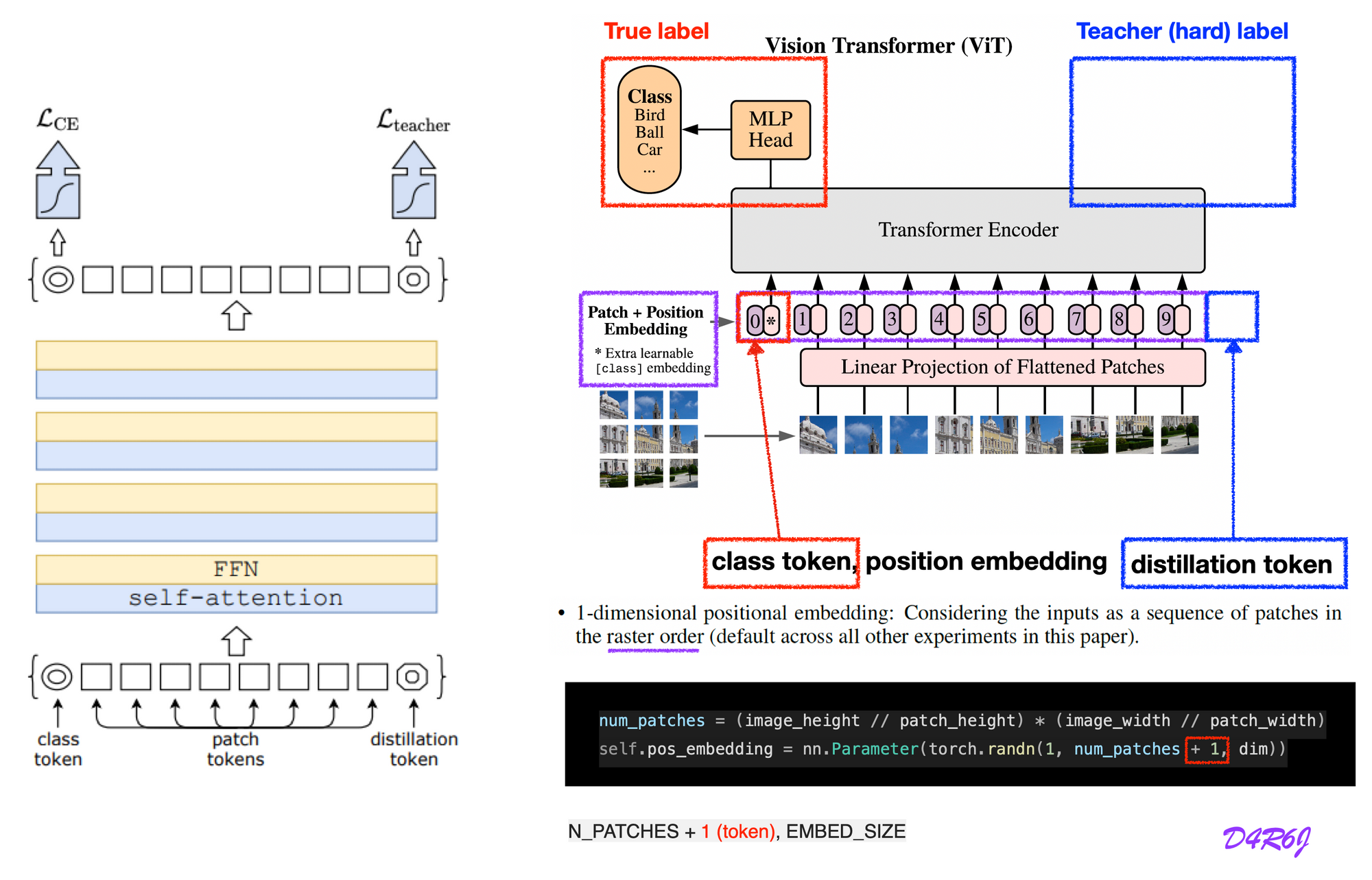
- ViT 에 distillation token 을 추가한다. 그것은 self-attention layer들을 통해 class 와 patch token 과 함께 interact 한다.
- 이 distillation token 은 class token 과 유사한 방법 (similar fashion) 으로 이용하는데, nework 의 출력으로 true label 대신에 teacher 에 의해 예측된 (hard) label 을 reproduce 하는 것이 목적.
- transformer 에 입력된 class 와 distillation 두 토큰은 back-propagation 에 의해 학습된다.
-
Notation
notation description the logits of the teacher model. the logits of the student model. the temperature for the distillation the coefficient balancing the KL divergence loss cross-entropy ground truth labels softmax function
Soft distillation
minimizes the Kullback-Leibler divergence between the softmax of the teacher and the softmax of the student model.
Hard-label distillation
We introduce a variant of distillation where we take the hard decision of the teacher as a true label. Let be the hard decision of the teacher, the objective associated with this hard-label distillation
