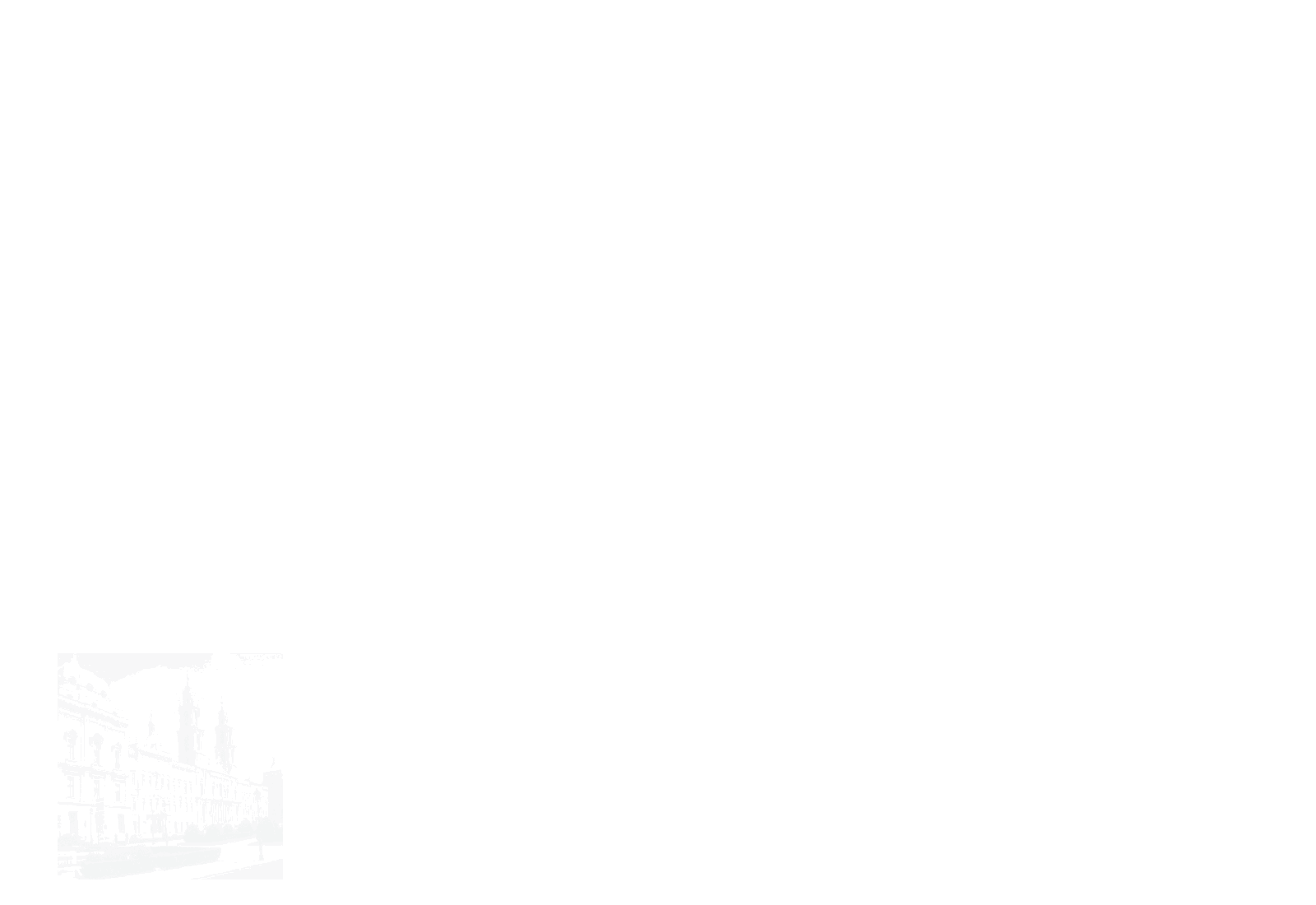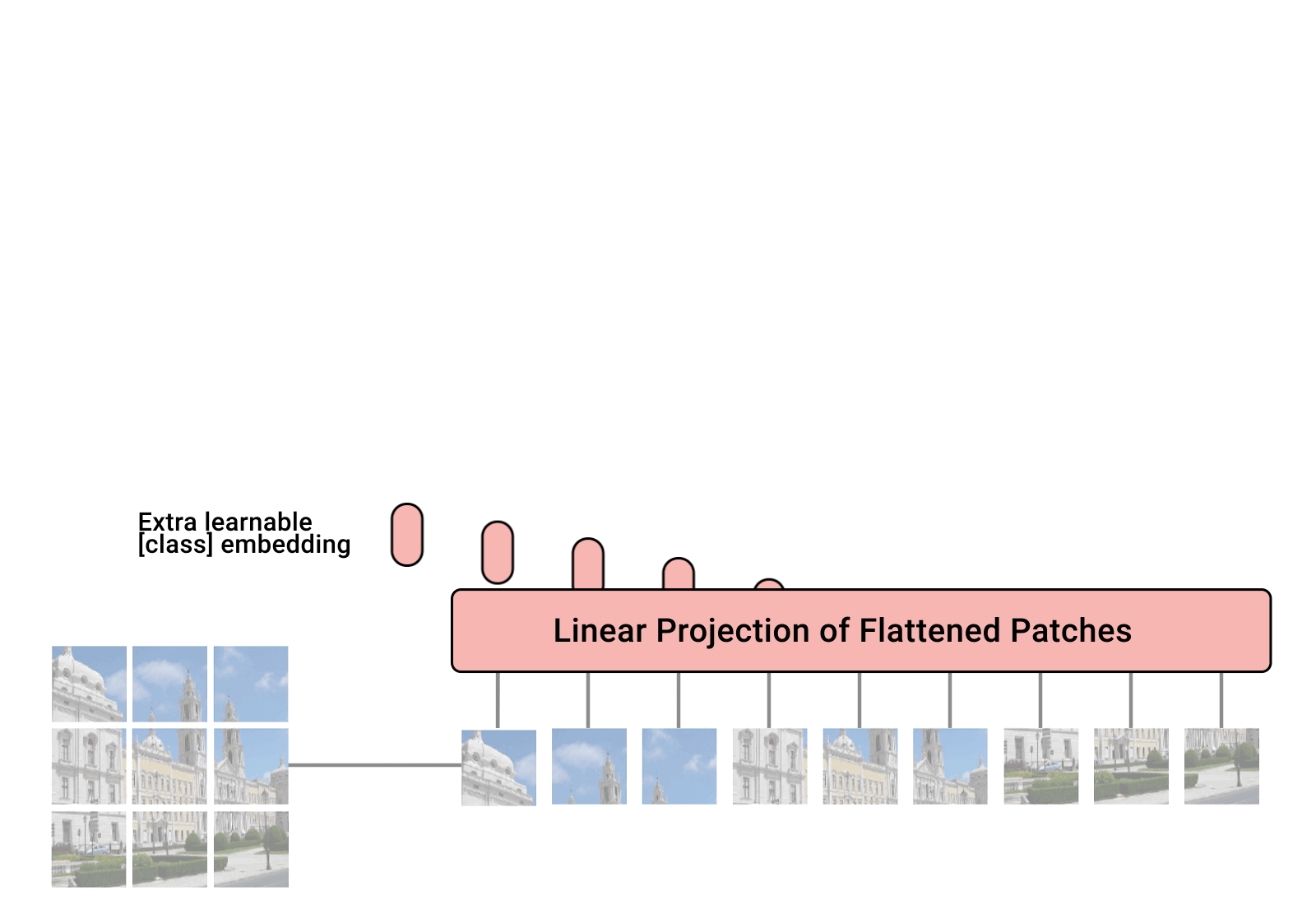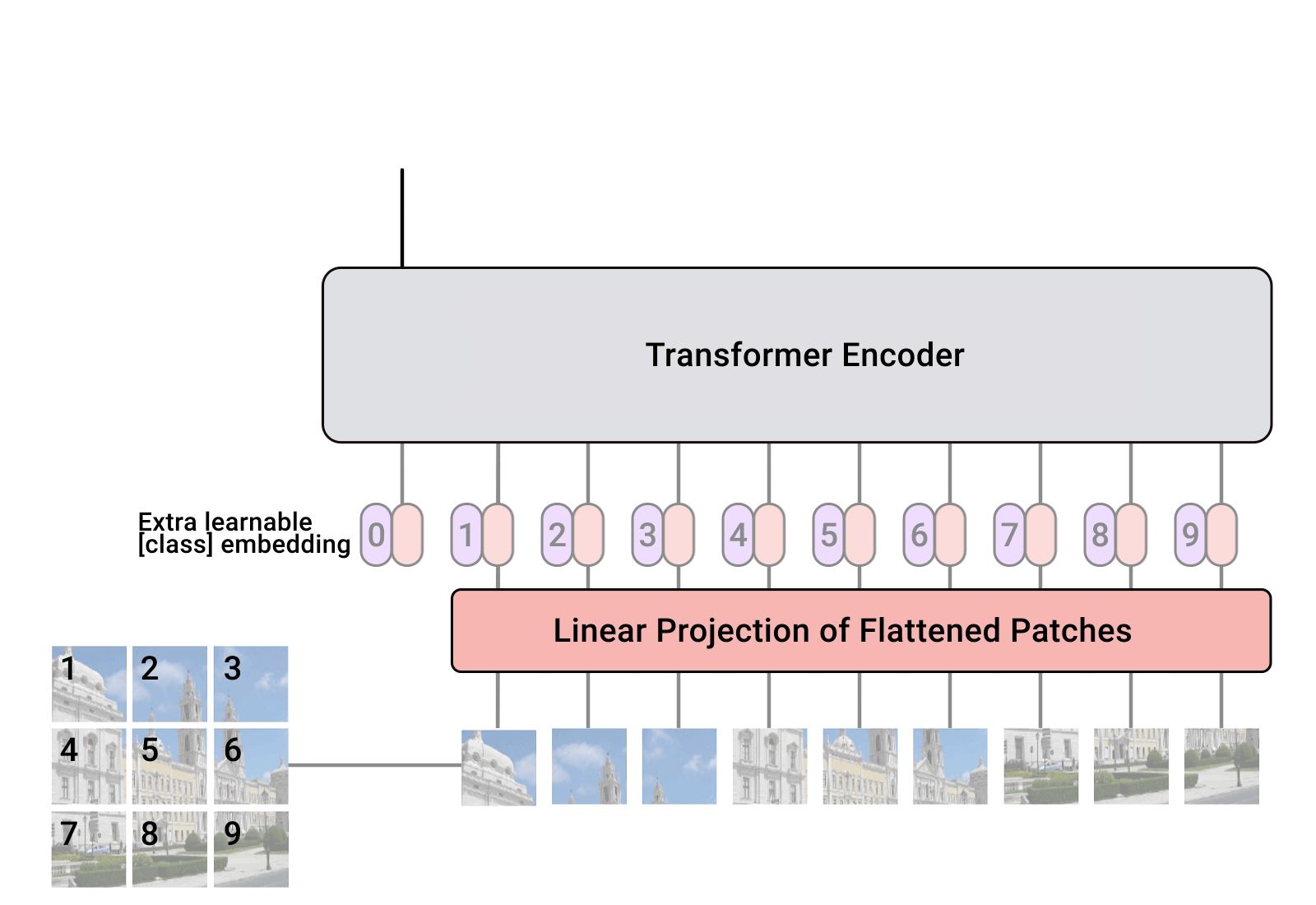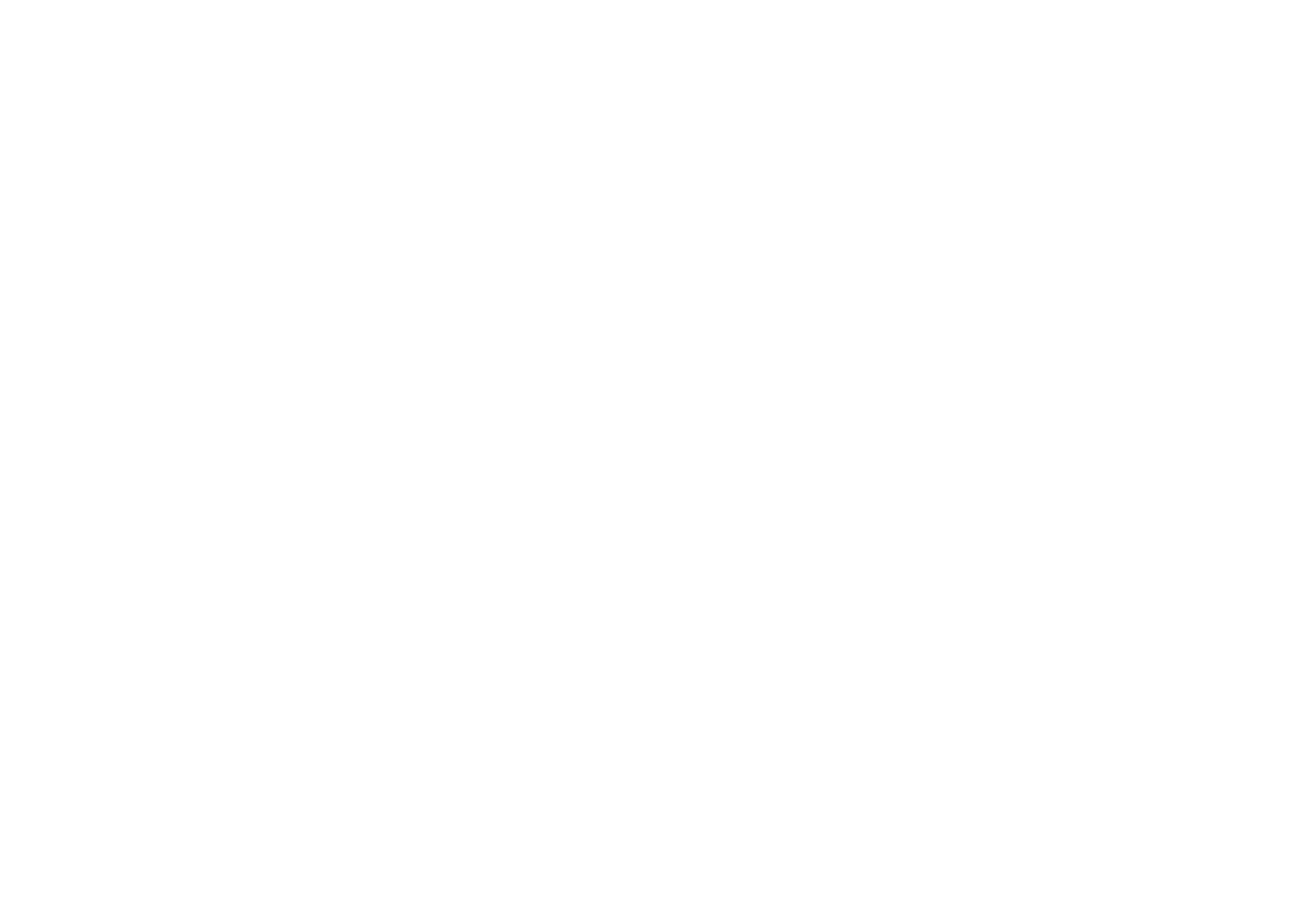
link : https://github.com/lucidrains/vit-pytorch/blob/main/images/vit.gif
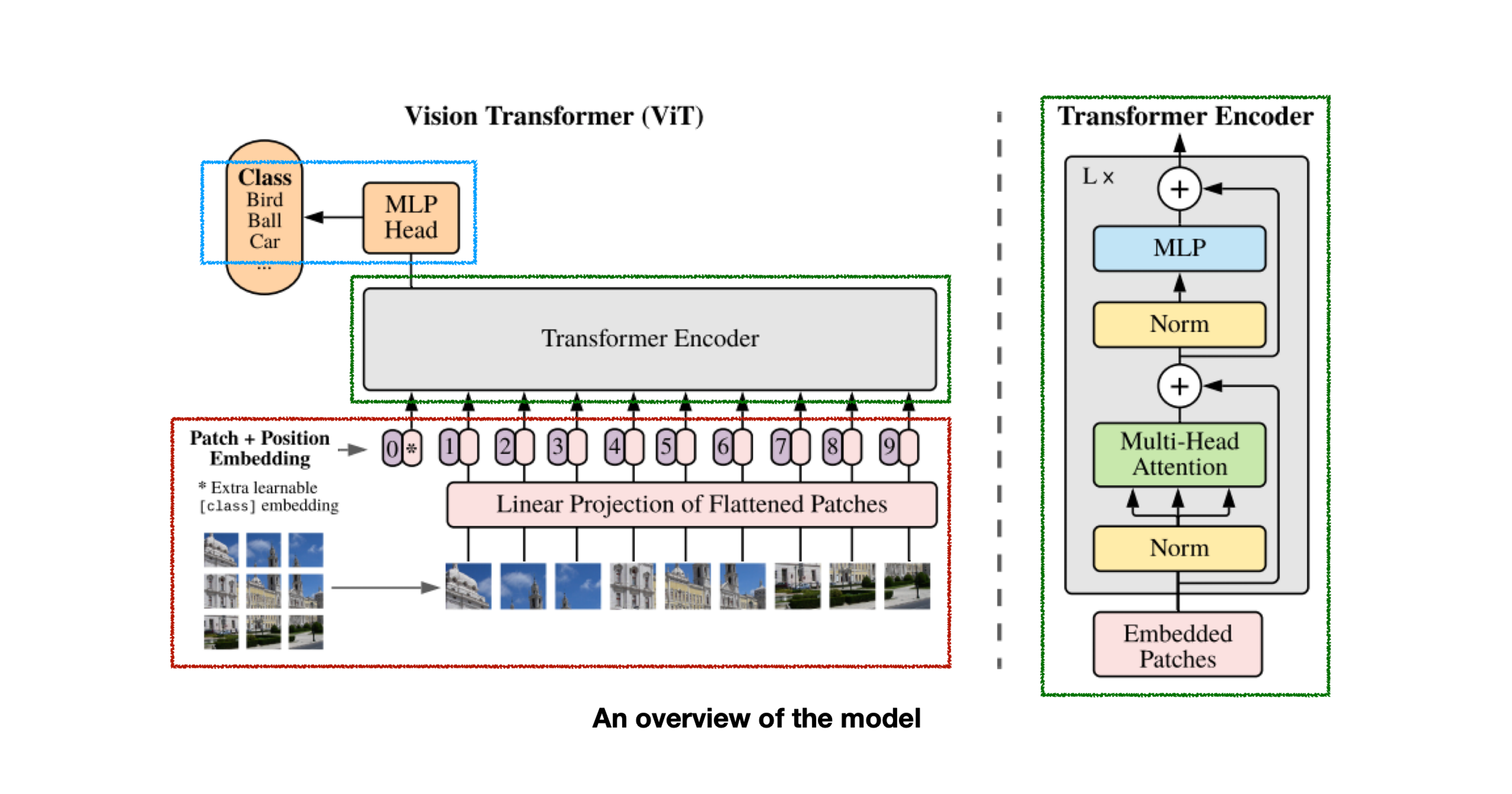
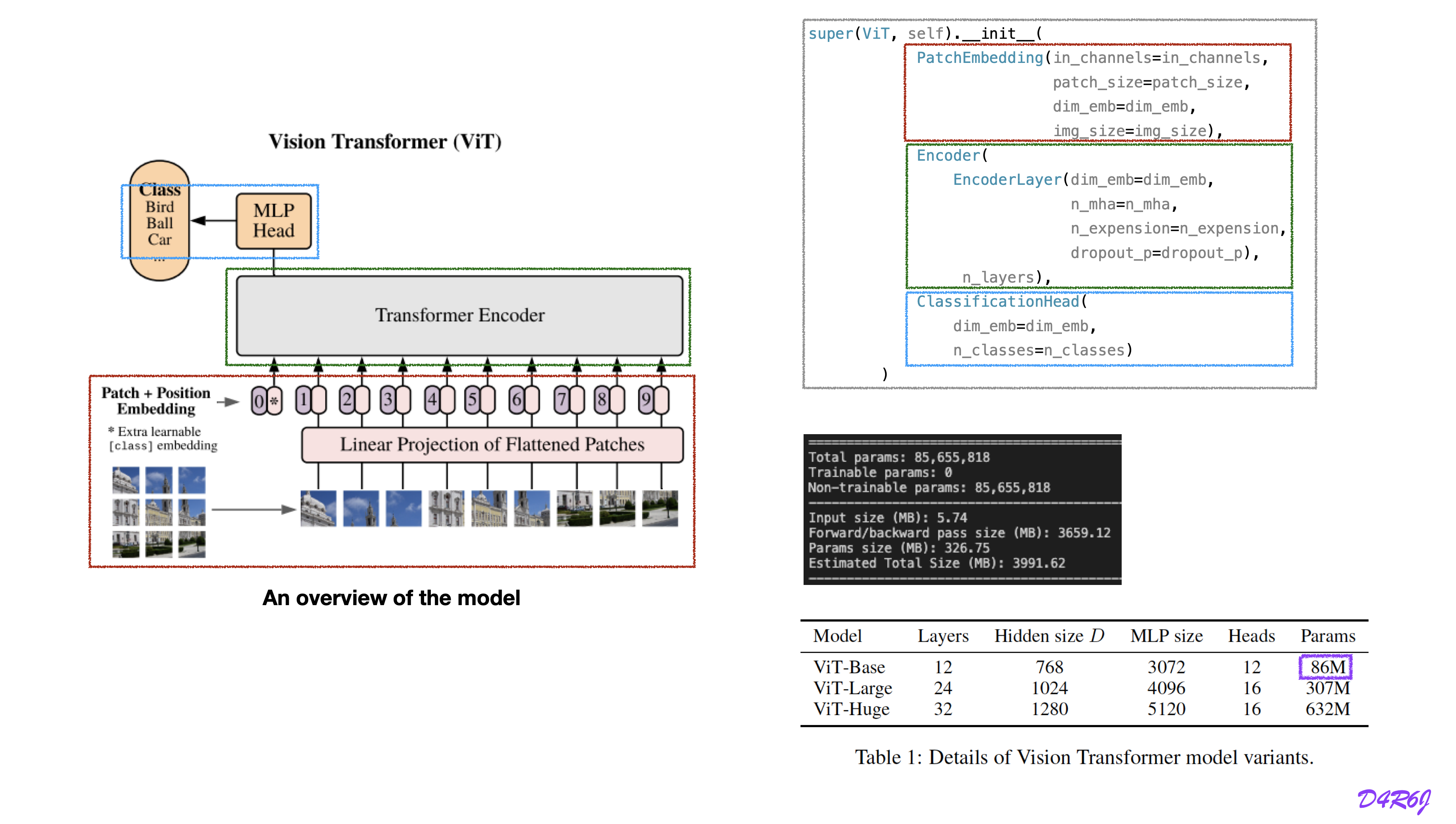
overview of the ViT

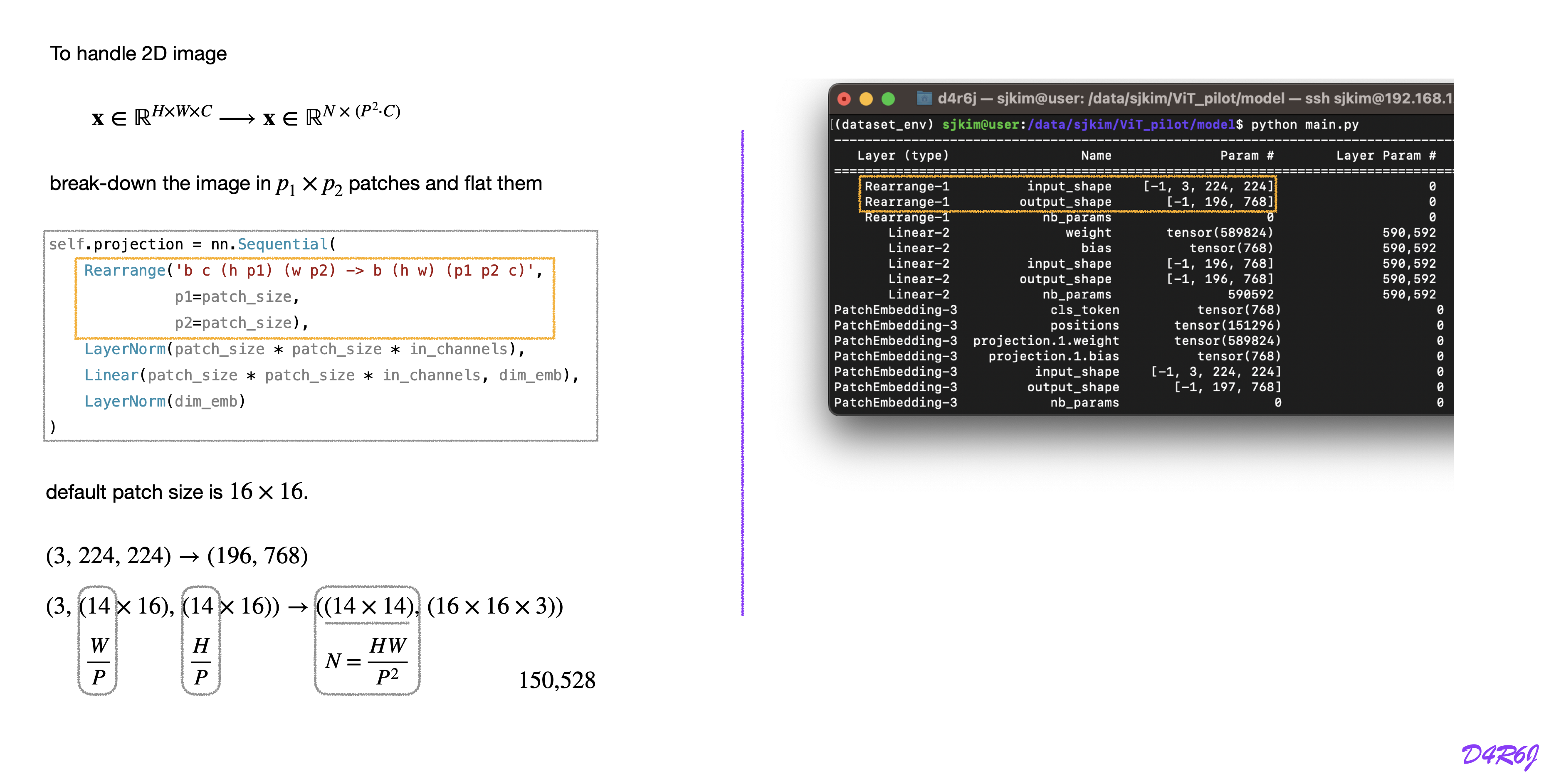
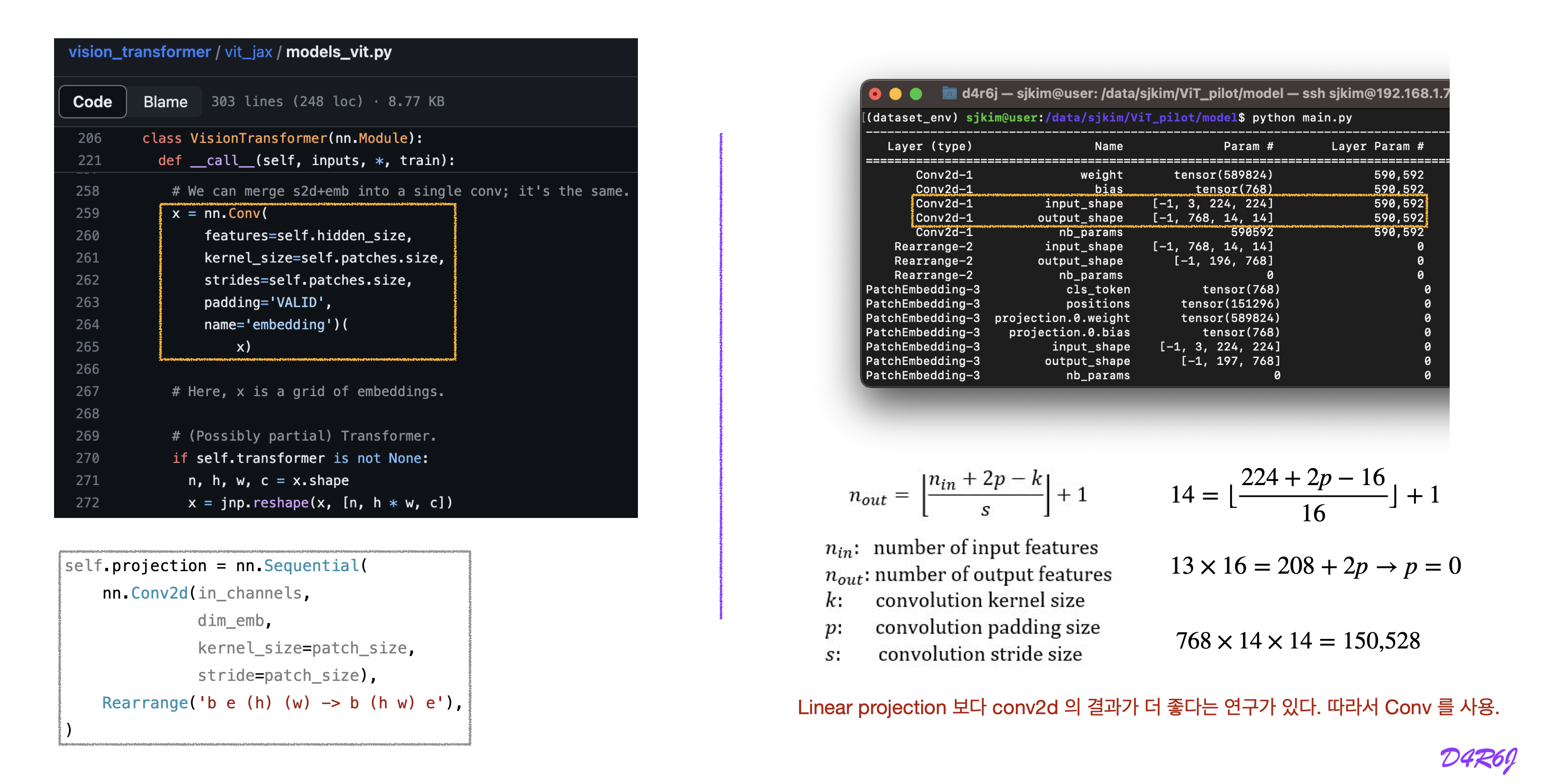
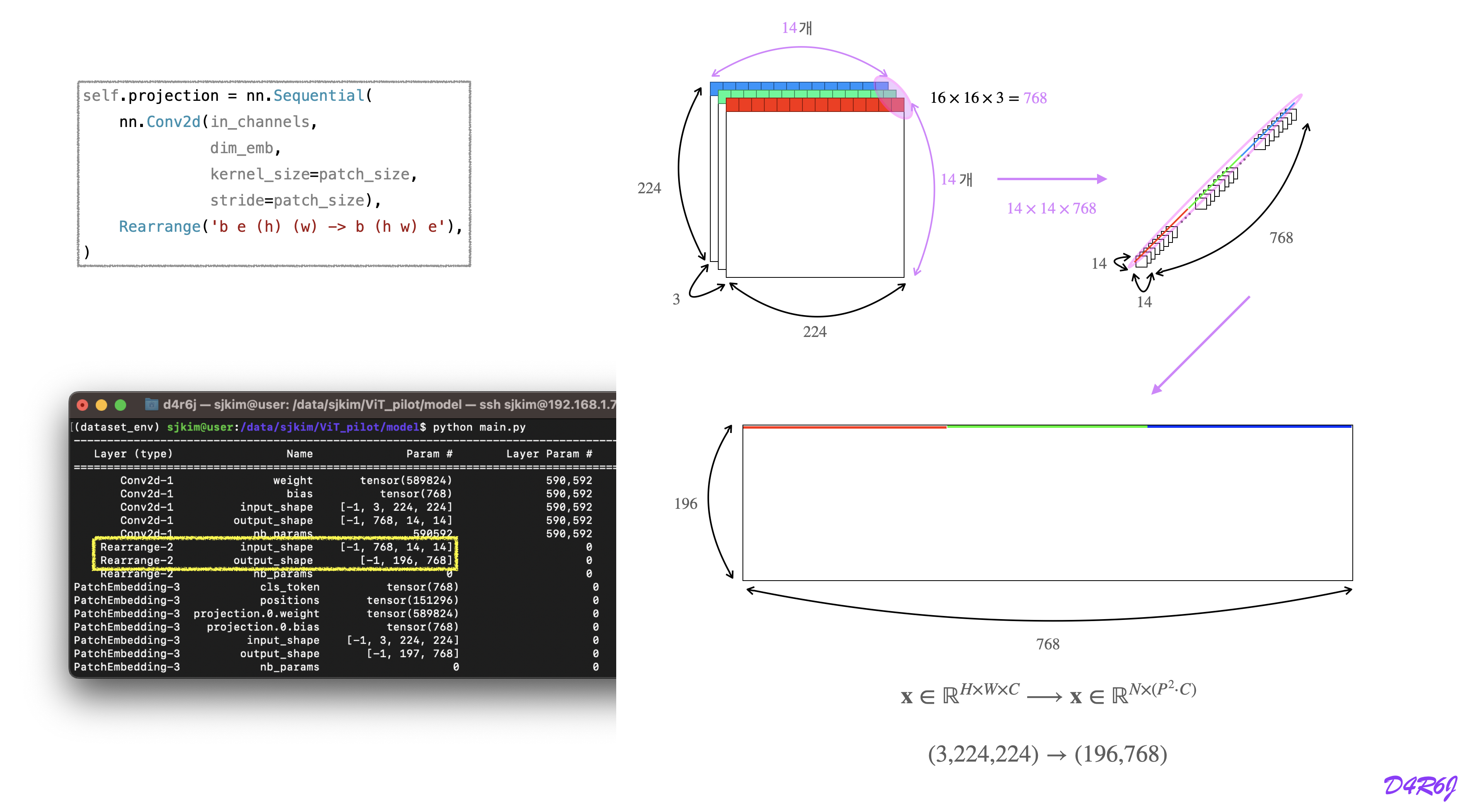
patch embedding
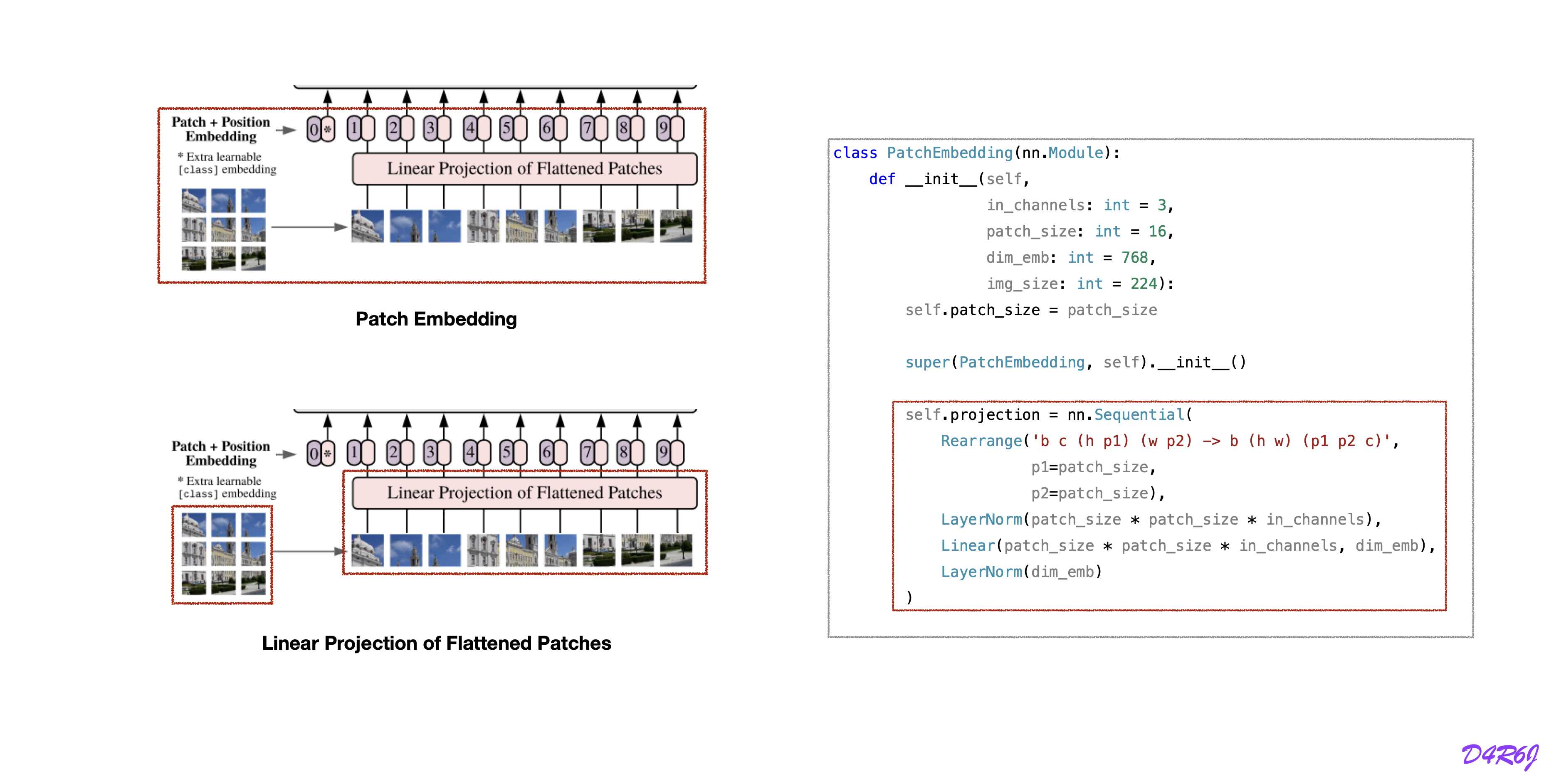
linear projection
conv2d instead of linear
conv2d layer structure
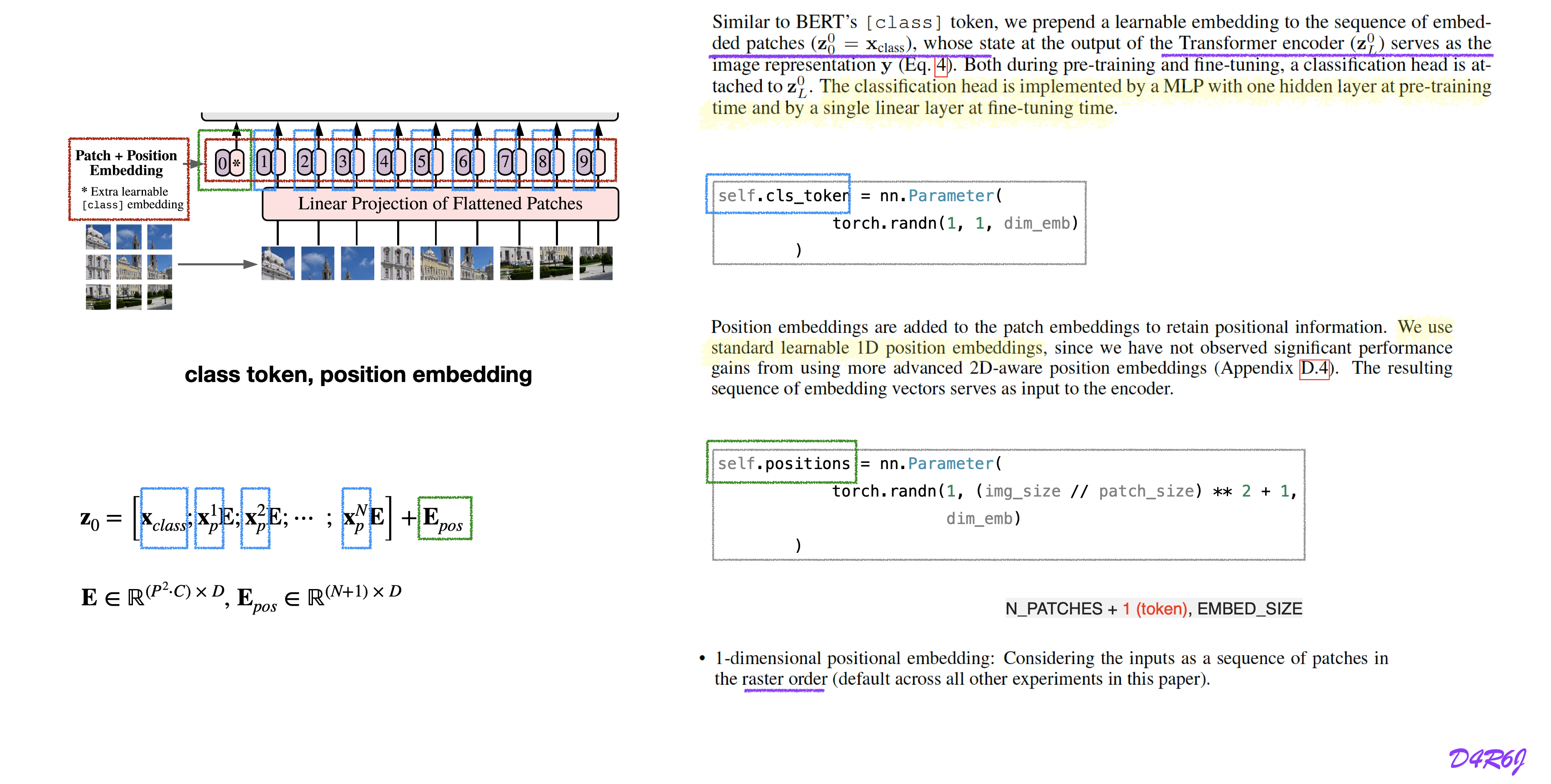
cls[class] token, position embedding
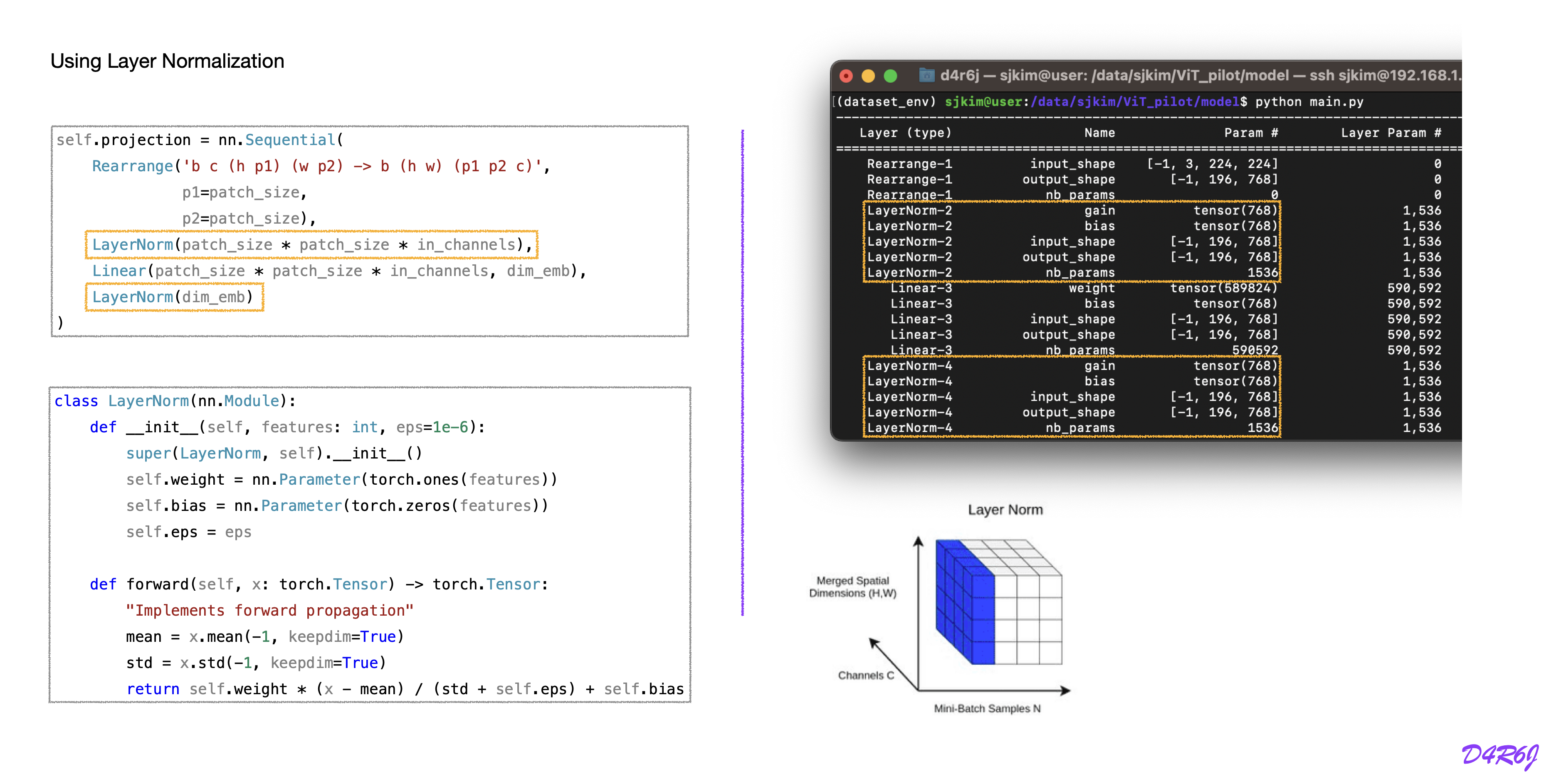
patch embedding code

connect transformer encoder

참고로 Encoder stack 은
(Link) The Annotated Transformer 를 참고 하였으며,
(Post) Transformer paper, code review 를 토대로 stack 사용.
feed-forward network

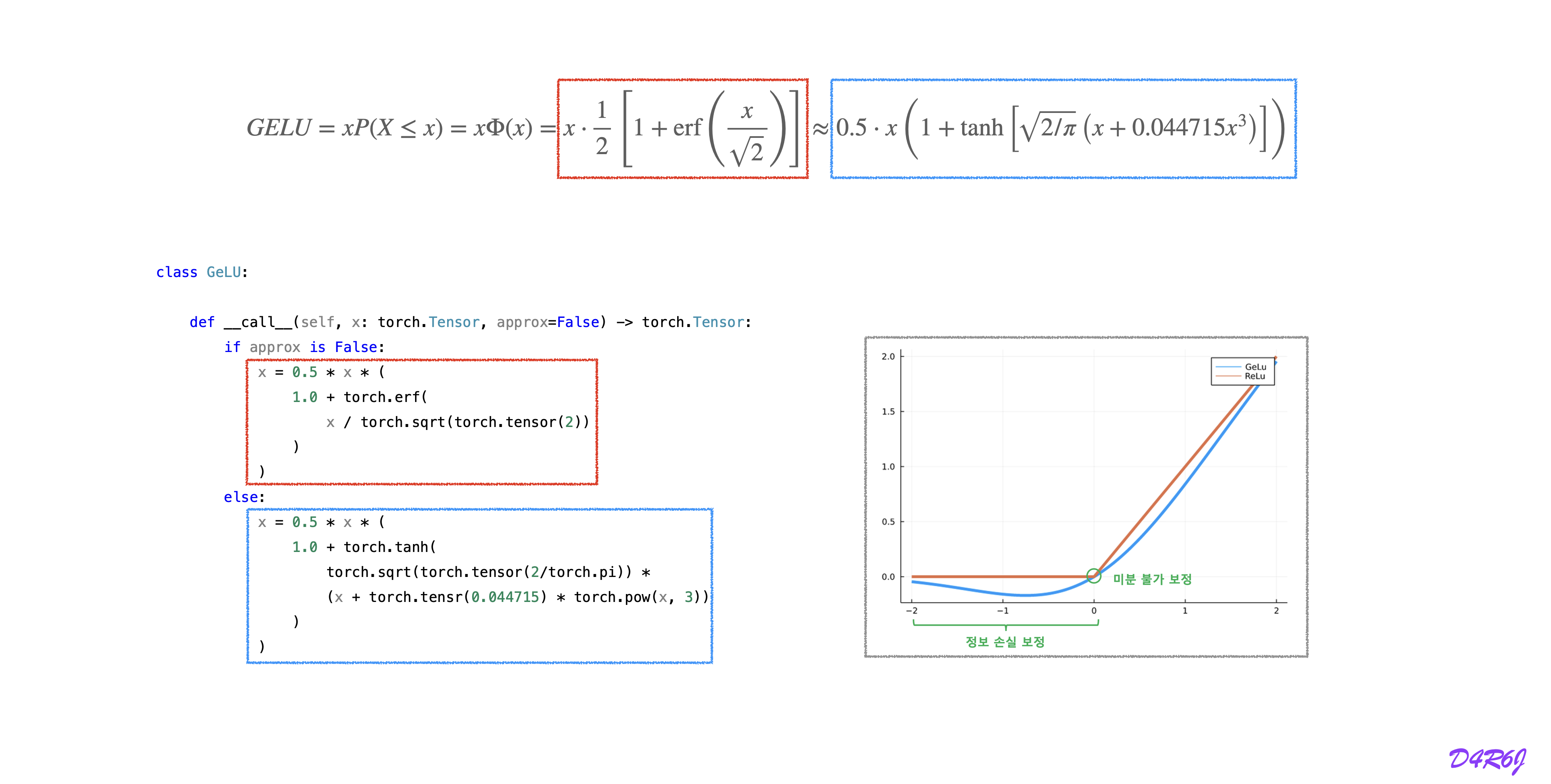
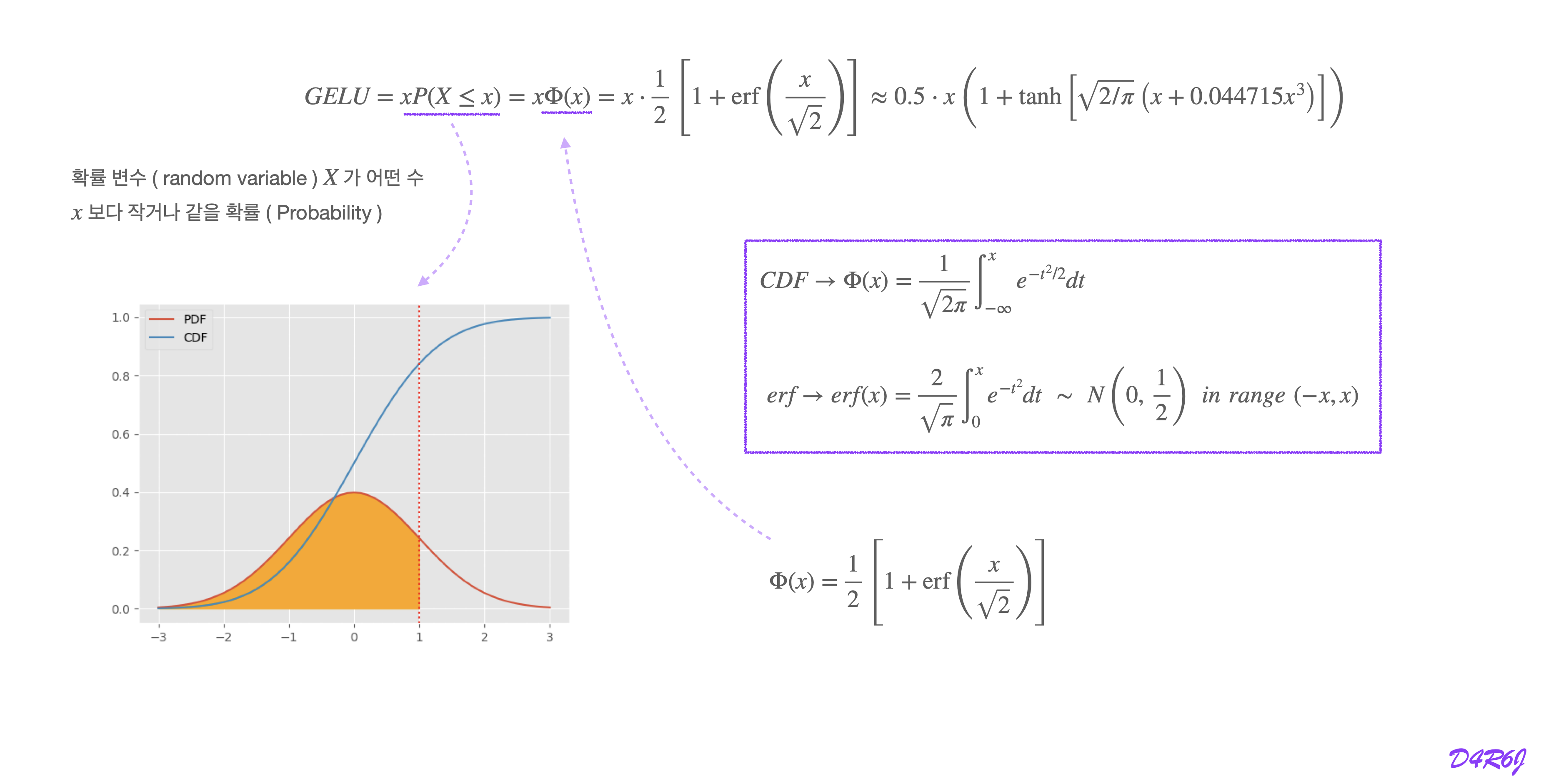
GELU (Gaussian Error Linear Unit)
classification head

ViT structure complete
Ref
-
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
https://arxiv.org/pdf/2010.11929.pdf -
ViT torch review
https://github.com/FrancescoSaverioZuppichini/ViT -
The annotated transformer
https://nlp.seas.harvard.edu/2018/04/03/attention.html

{kind=link}