
Large-Language-Model 관련한 Technical Report 는 한 번 읽어보고 싶었다.
Llama2 읽어보려다가, Llama3 기다렸고, 이제 한 번 천천히 정독하여 읽어 보려 한다.
review 는 순서대로 진행 될 예정인데, 몇 부분으로 나눌 것이다.
1. Introduction
2. Pre-Training
3. Post-Training
4. Vision Experiments
5. Speech Experiments
로 천천히 다루어볼 예정이다.
Abstract
-
현대 AI 시스템은 foundation models 를 기초로 하고 있다. 이 논문은 Llama 3 이라고 불리는 foundation model 이라는 새로운 set 을 제시한다.
-
multilinguality, coding, 추론 과 도구 사용을 기본적으로 지원하는 언어 모델의 무리 (Herd) 이다.
-
가장 큰 모델은 405B 파라미터들과 128K 토큰들의 context window 를 가진 dense Transformer 이다.
405 Billion 의 파라미터와 128,000 의 corpus torken 을 사용한다는 것은, 모델 크기와 데이터 크기가 넘사벽이라는 생각이 든다.
- Llama 3 는 405B parameter 언어 모델의 pre-trained 와 post-trained 버전과 input 과 output 의 안전을 위한 Llama Guard 3 model 을 포함하여 Llama 3 을 공개적으로 release 한다.
Guard 는 더 봐야 되겠지만, 언어의 안전에 대한 언어 방화벽으로 생각해본다.
- 구성적 접근 방식을 통해 (via a compositional approach) 이미지, 비디오 및 음성 기능을 Llama 3 을 통합한 실험 결과를 제시한다.
논문을 하나나 뜯어 보면서 Multimodal 방식을 어떻게 처리했는지 구경 좀 할 예정이다.
1. Introduction
-
Foundation model 들은 AI tasks 의 매우 크고 다양하게 지원하기 위해 설계된 Language, Vision, Speech (and/or) 다른 modalities 의 일반 모델 이다.
-
현재 foundation model 들은 2 가지 main stage 구성으로 개발한다.
-
Pre-Training: 다음 단어 예측 또는 captioning 과 같은 간단한 작업을 사용하여 모델이 대규모로 훈련되는 pre-training 단계.
-
Post-Training : 모델이 인간 선호도에 맞는 instruction 을 따르도록 조정 되고, 특정 기능 ( 예를 들어, 코딩과 추론 )을 향상시키는 post-training 단계.
-
Post-Training 부분이 꽤 흥미롭다. 실제 다량의 corpus 로 Pre-Training 한 후에 instruction 을 하기 위한 데이터 셋 부터, 그 과정이 이전 부터 궁금했었다.
- 가장 큰 모델은 405B parameter 을 가지고 있는 dense Transformer 모델로, 최대 128K tokens 의 context window 에서 정보를 처리한다.
big-tech 의 computation 는 무시 못하지만, 405B 에 context window 가 128,000 토큰 갯수 라니..
-
Data
Llama 의 이전 version 과 비교했을 때, 우리가 pre-training 과 post-training 에 사용하는 데이터의 양과 질을 향상 시켰다. 이러한 개선 사항에는 아래 내용이 포함 된다.- 사전 학습 데이터를 위한 보다 신중한 사전 처리 큐레이션 파이프라인 개발
- 사후 학습 데이터를 위한 보다 엄밀한 품질 보증 및 필터링 접근 방식의 개발
Llama 2 의 1.8 Token 과 비교하여 15T 의 다국어 토큰 corpus 에서 Llama 3 을 pre-train 한다.
Llama 2 에서도 corpus 의 총 token 의 수가 1.8T 였다. 분명 많았었는데.. 거의 10배가 늘었다..
-
Scale
- 이전 Llama 모델들 보다 더 큰 scale 의 모델을 훈련한다.
- 우리의 주력 언어 모델은 Llama 2 의 가장 큰 version 보다 50배 더 큰 FLOP 을 사용하여 pre-trained 한다.
- 구체적으로 15.6T text tokens 에 대해 405B 훈련 가능한 parameters 를 사용하여 주력 모델을 pre-trained 한다.
- scaling 법칙 에 따르면 주력 모델은 우리의 훈련 예산에 대해 계산적으로 최적 크기에 가깝지만, 작은 모델들은 계산적으로 최적인 시간 보다 좀 더 길게 훈련한다.
모델은 같은 추론 예산에 대해 계산적으로 최적인 모델 보다 더 좋은 성능이 나온다. post-training 하는 동안 작은 모델들의 품질을 향상시키기 위해서 주력 모델을 사용한다.
모델 코드는 거의 90% 같다고 봐도 된다. scale 만 커진건데.. 그 크기가 50배. Llama 2 도 크기가 작았던 것이 아니다. 재밌는 부분은, 작은 모델은 최적의 훈련 시간보다 좀 더 해야 한다는 것.
-
Managing complexity
- 모델 개발 프로세스를 확장하는 능력을 극대화 하는 설계를 선택한다.
- 훈련의 안정성을 극대화 하기 위해 MOE ( mixture-of-experts ) 모델 대신 약간의 조정이 들어간 표준 dense Transformer 모델 아키텍처를 선택한다.
- 덜 안정적이고 확장이 어려운 더 복잡한 강화학습 알고리즘 보다 SFT ( supervised finetuing ), RS ( rejection sampling ), 그리고 DPO ( direct preference optimization ) 기반으로 비교적 간단한 post-training 과정을 채택한다.
모델의 안정성보다 확장 능력을 보고, 좀더 robust 한 모델을 선호하게 된다. 그런데 이걸 보고 있으면 Minimum-Variance Unbiased Estimator 보다 약간의 편향이 있을 때 robust 한 모델, 성능에 더 유리할 수 있다는게 생각난다.
- Llama3 은 8B, 70B, 405B 파라미터를 갖는 3가지 다중언어 모델들의 무리(herd) 이다.
- 광범위한 언어 이해 작업을 포함하는 수많은 benchmark 데이터 셋 에서 Llama 3 의 성능을 평가한다.
- 게다가 llama 3 를 경쟁 모델과 비교하는 광범위한 인간 평가를 수행한다.
주요 벤치마크에서 주력 Llama 3 모델의 수행 능력은 Table 에 나와 있다.
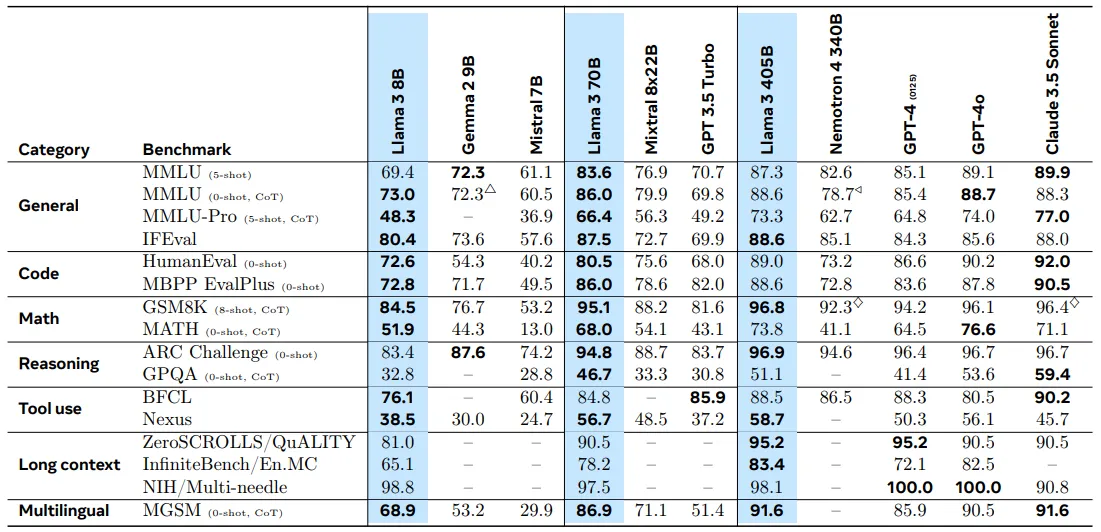
Llama 3 Community License 에 업데이트된 version 에 따라서 세 가지 Llama 3 모델을 공개적으로 출시한다.
-
405B 파라미터 언어 모델의 pre-trained 와 post-trained 버전 과 input, output 의 안정성을 위한 Llama Guard model 의 세로운 버전을 포함된다.
-
Llama 3 개발 프로세스의 부분으로 모델에 대한 multimodal 확장도 개발하여, 이미지 인식, 비디오 인식 및 음성 이해 기능을 지원한다.
Llama Guard 모델은, 앞단에서 언어 패턴의 방어를 해주는 모델 같은데, 나쁘지 않을 듯 하다.
2. General Overview
-
Llama 3 의 전반적인 구조와 훈련에 대한 Illustration.

Llama 3 은 textual sequence 의 다음 토큰을 예측하기 위해 훈련된 Transformer 언어 모델이다.
아 이넘들.. 모델 Llama 2 와 똑같고, 사실 옆그레이드 한건 알겠는데 너무 대충 그렸다.. 그런데 또 구조는 틀린건 아니다.
Llama 3 언어모델의 개발은 2 가지 주요 stage 로 구성된다.
-
Language model pre-training
- 대규모 다국어 text corpus 를 개별 token 으로 변환,
- 결과 데이터에 대해 LLM 을 사전 학습
- 다음 token 예측을 수행하는 것 부터 시작한다.
- 언어 모델 pre-training 단계에서 모델은 자신이
reading하고 있는 text 로부터 언어 구조를 학습하고, 세상에 대한 많은 지식을 얻는다.
이와 같은 표현을 보면 기분이 묘하다. 사실, Attention 의 구조만 봐도 단어들과의 유사도를 큰 matrix 에 압축하여 저장하고 있고, 언어학적인 구조가 아닌, 데이터 학습으로 그 유사도에 맞게 문장을 이어 나간다.
이것을 효과적으로 하기 위해서 pre-training 은 대규모로 수행된다.
-
405B 파라미터가 있는 모델은 8K tokens 의 context window 를 사용하여 총 15.6T tokens 에 대한 pre-train 을 한다.
-
standard pre-training 단계에서 지원되는 context 창을 128K tokens 으로 늘려서 지속적인 pre-training 단계가 이어진다.
-
Language model post-training.
-
pre-train 된 모델은 언어의 풍부한 이해를 같지만, 아직 instruction 을 따르거나, assistant 가 기대하는 방법으로 행동하지는 못한다.
-
여러 round 를 통해서 human feedback 에 맞춰서 모델을 조정하고, Instruction tuning 데이터와 Direct Preference Optimization 을 사용한 Supervised Finetuning 이 이루어진다.
그러니까.. “이 문장을 요약해줘”, 또는 “이 데이터를 분석해줘” 와 같은 명령을 제대로 이해하고 적절한 반응을 학습시키는데 사용되는 데이터.
-
이 post-training 단계 에서는 도구 사용과 같은 새로운 능력을 통합하고, 코딩 과 추론과 같은 다른 영역에서도 강한 능력 향상이 보여진다.
-
자세한 내용은
4. Post-Training을 참고. 마지막으로 안전 장치들도 post-training 단계에서 모델에 통합된다. 자세한 내용은5.4 Safety에 설명 되어있다.
-
결과 모델은 다양한 기능의 능력을 갖는다.
- 그들은 적어도 8 개의 언어로 답을 할 수 있고,
- high-quality 코드를 쓸수 있으며,
- 복잡한 추론 문제를 해결하고
- 사전 설정이나 추가적인 준비 과정 또는 별도의 학습 없이 도구를 사용할 수 있다.
- 또한 이미지, 비디오 그리고 말하는 능력을 더하는 실험을 수행한다.
사실 요새 들어, 더 익숙해진 AI tool 들을 보면서 경각심도 들고, 기존 나의 Legacy 코드를 보면서 많은 생각에 잠기게 된다. Trend 는 변화하고 있고, Idea 는 더 이상 나만의 Idea 가 아닌 공통의 Idea 가 되고 있다. 월 2$ 로..
연구되는 접근 방식은 그림에서 설명된 세 가지 추가 단계로 구성된다.
-
Llama 3 의 multimodal 기능을 추가하는 구성적 접근 방식.
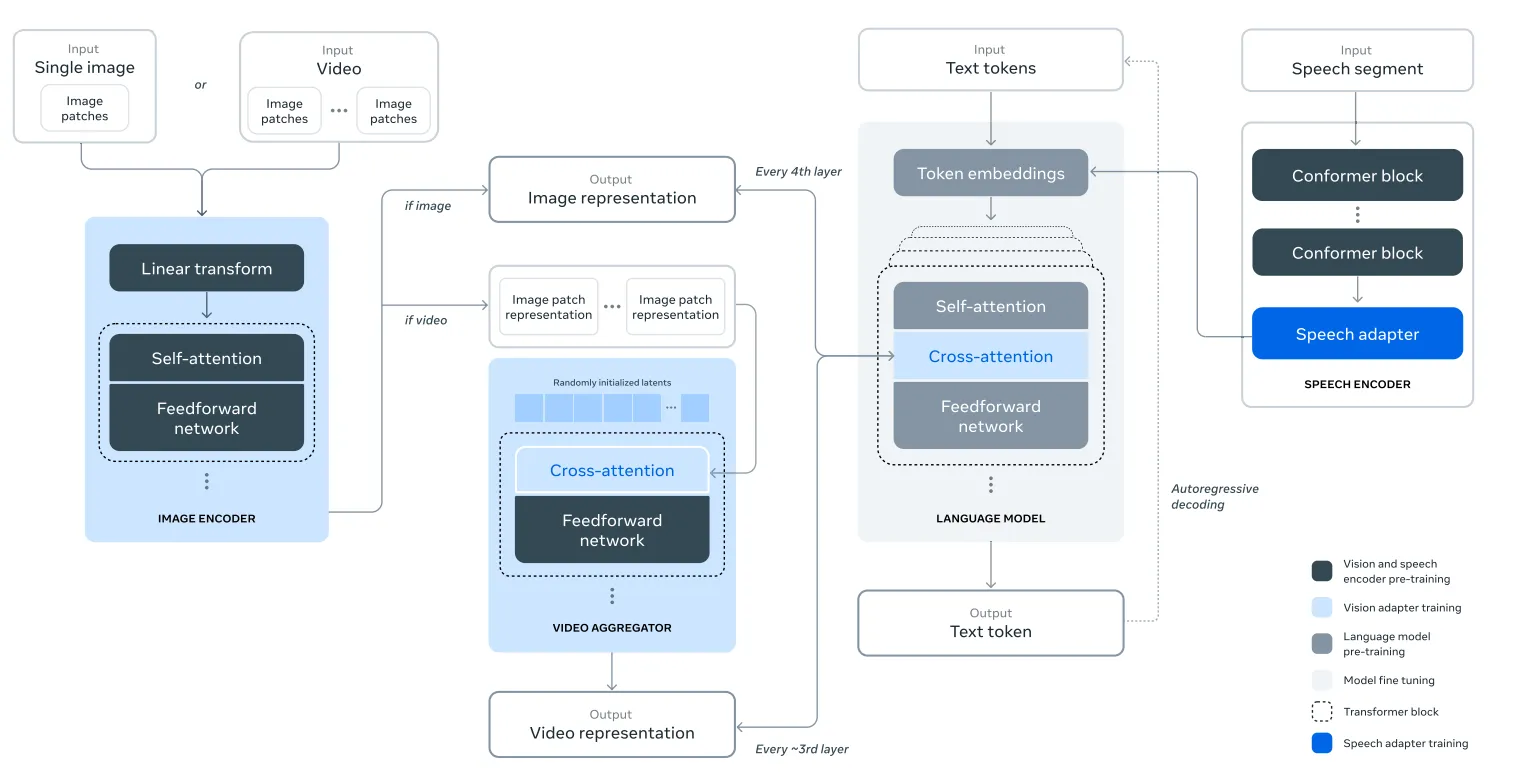
이 접근 방식은 5 단계로 훈련되는 multimodal model.
- language pre-training
- multi-modal encoder pre-training
- vision adapter training
- model finetuning
- speech adapter training
-
Multi-model encoder pre-training
- image 와 speech 에 대해 별도의 encoder 를 학습한다.
- 대량의 image-text 상에 대해 image encoder 를 훈련한다.
- 이 시각적인 content 와 해당 content 에 대한 자연어 설명 과의 관계를 모델에게 가르친다.
- speech encoder 는 inputs speech 의 일부분을 마스킹 처리하고, discrete-token 표현을 통하여 복원하려고 시도하는 self-supervised approach (자기 지도 학습) 을 사용하여 훈련한다.
여기서 말하는 discrete-token 은, 이해하자면, encoder 를 가지고 수치화된 continuous 한 vector 를 가지고 있는데, 그것을 discrete 하여 음성 구조화를 시킨다는 의미. 그러니까 vector quantization 을 하여 speech struct 를 이해하겠다는 것으로 해석.
결과적으로 모델은 음성 신호의 구조를 학습하게 된다.
7. Vision Experiments와8.Speech Exprements에 자세히 나와있다.
-
Vision adapter training
- pre-trained 이미지 인코더를 pre-trained 언어 모델에 통합하는 adapter 를 훈련한다.
- adapter 는 image encoder 표현을 language model 에 제공하는 cross-attention layer 들로 구성된다. 이 adapter 는 text-image pairs 이다.
- 이미지 표현을 언어 표현과 일치 시킨다. adapter 를 훈련하는 동안, 이미지 인코더의 parameter 도 업데이트 하지만, 언어 모델 parameter 는 의도적으로 update 하지 않는다.
언어 모델은 압도적인 데이터로 충분히 훈련되고 있는 상태이므로, image encoder 만 조정하여 두 모델간의 representation (표현) 을 맞추는 과정.
- 또한, 쌍을 이루고 있는 video-text 데이터에 대해서 image adapter 의 위에 video adapter 를 훈련한다. 이를 통해서 모델이 연속된 frame 에 걸친 정보를 집계할 수 있게 한다.
- 즉, 시간적 순서에 따라 이어지는 여러 프레임간의 정보를 집계하여 비디오를 만든다.
-
Speech adapter training
- 마지막으로 speech encoder 를 모델에 통합하여, speech encoding 을 token 표현으로 변환하고, 이것을 finetuned language model 에 직접 공급할수 있도록 한다.
따라서 음성 데이터를 언어 모델의 입력으로 사용할 수 있도록 변환하는 과정. 여기서의 token 은 LLM token 을 말한다.
- adapter 와 encoder 의 parameter 들은 supervised finetuning stage 에서 같이 업데이트 되어서 고품질의 음성 이해가 가능해진다.
- speech adapter 가 훈련 하는 동안, language model 은 변하지 않는다. 또한, text-to-speech 시스템을 통합한다.
8.Speech Exprements에 자세히 나와있다.
multimodal 실험은 이미지들과 비디오의 content 를 인식하고 speech interface 를 통한 상호 작용을 지원할 수 있는 모델로 이어진다.
