LoRA (Low-Rank Adaptation)
paper review
understanding
-
Pretrained LLM 은 다양한 task 에 걸쳐서 다재다능 하기 때문에 foundation 모델 이라고 말한다. 그러나 특정 dataset 이나 tasks 를 위해 Pretrained LLM 을 조정하는 것이 유용한 경우가 많으며, 그것은 finetuning 을 통해 수행할 수 있다.
-
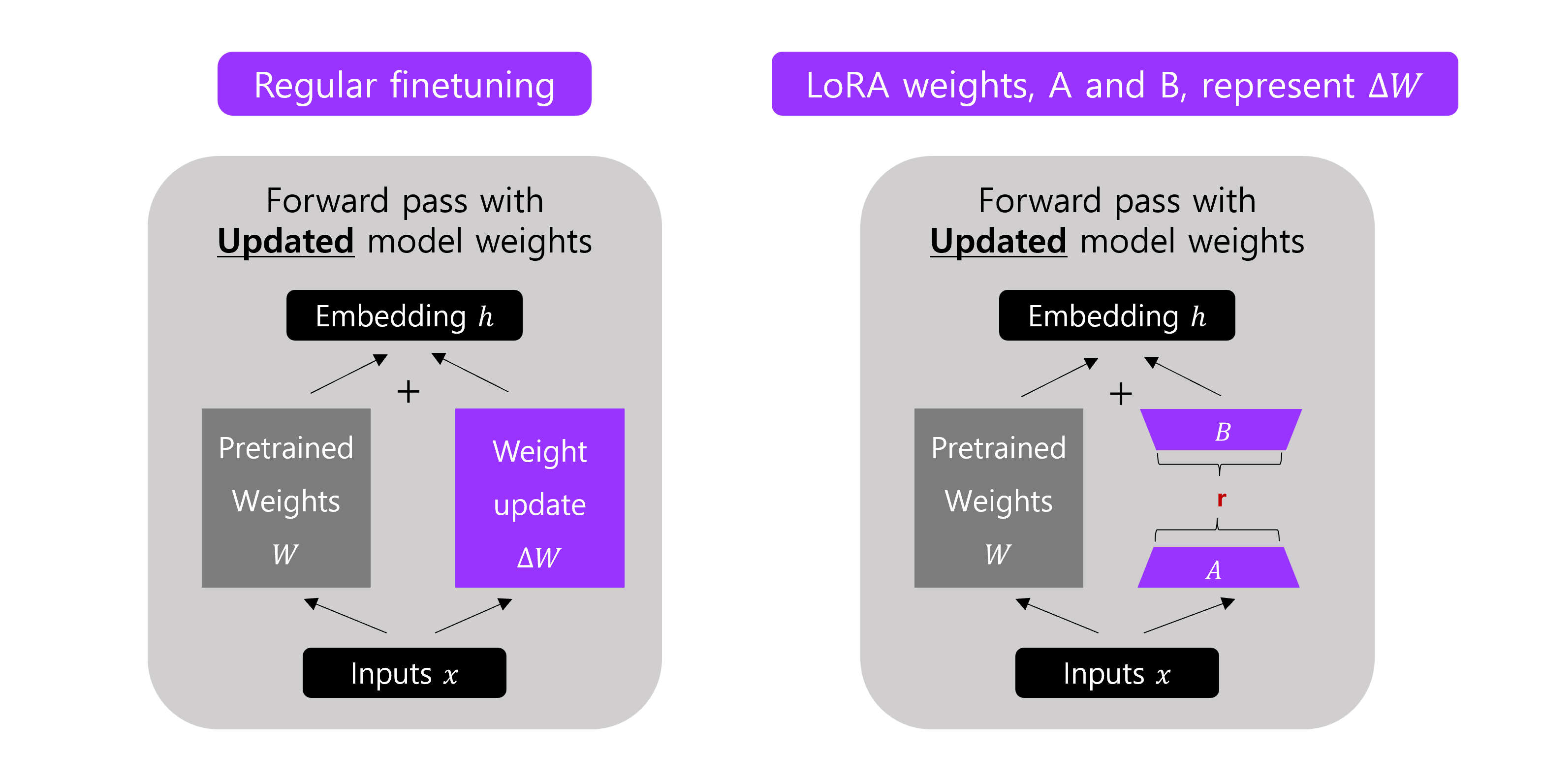
Finetuning 은 많은 비용이 드는 사전 학습 없이 특정 도메인에서 적응할 수 있지만, 특히 아주 큰 모델의 경우에는 모든 레이어들을 업데이트 하는 것은 여전히 비용이 너무 비싸다.
-
LoRA 는 LLMs 를 더 효율적으로 finetune 하기 위한 유명한 기술이다. DNN 의 모든 parameter 를 조정하는 대신, low-rank matrices 의 작은 집합만 update 하는데 focus 를 둔다. LoRA 는 훈련하는 동안 레이어 가중치 변화 를 low-rank 형태로 근사한다.
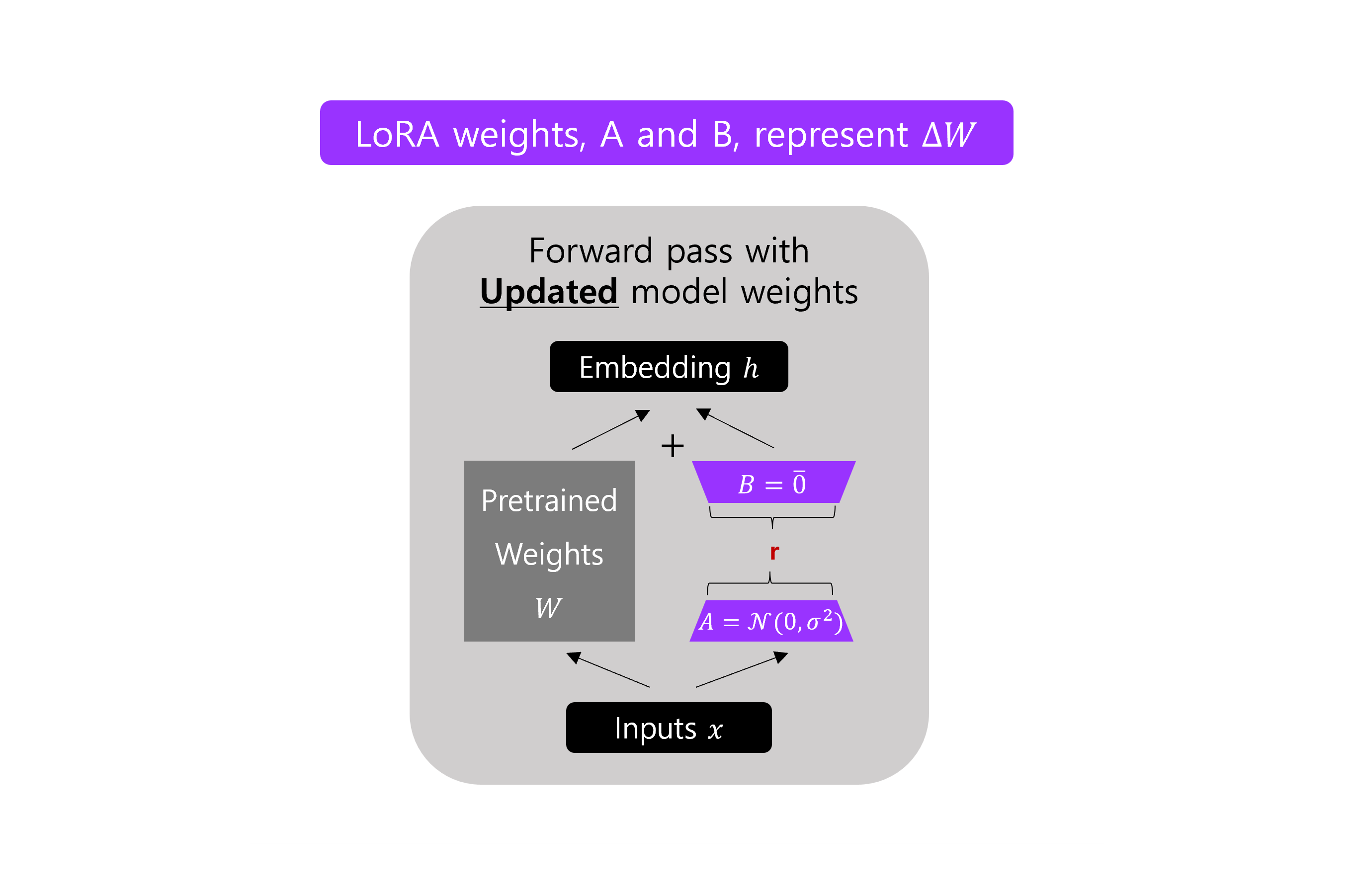
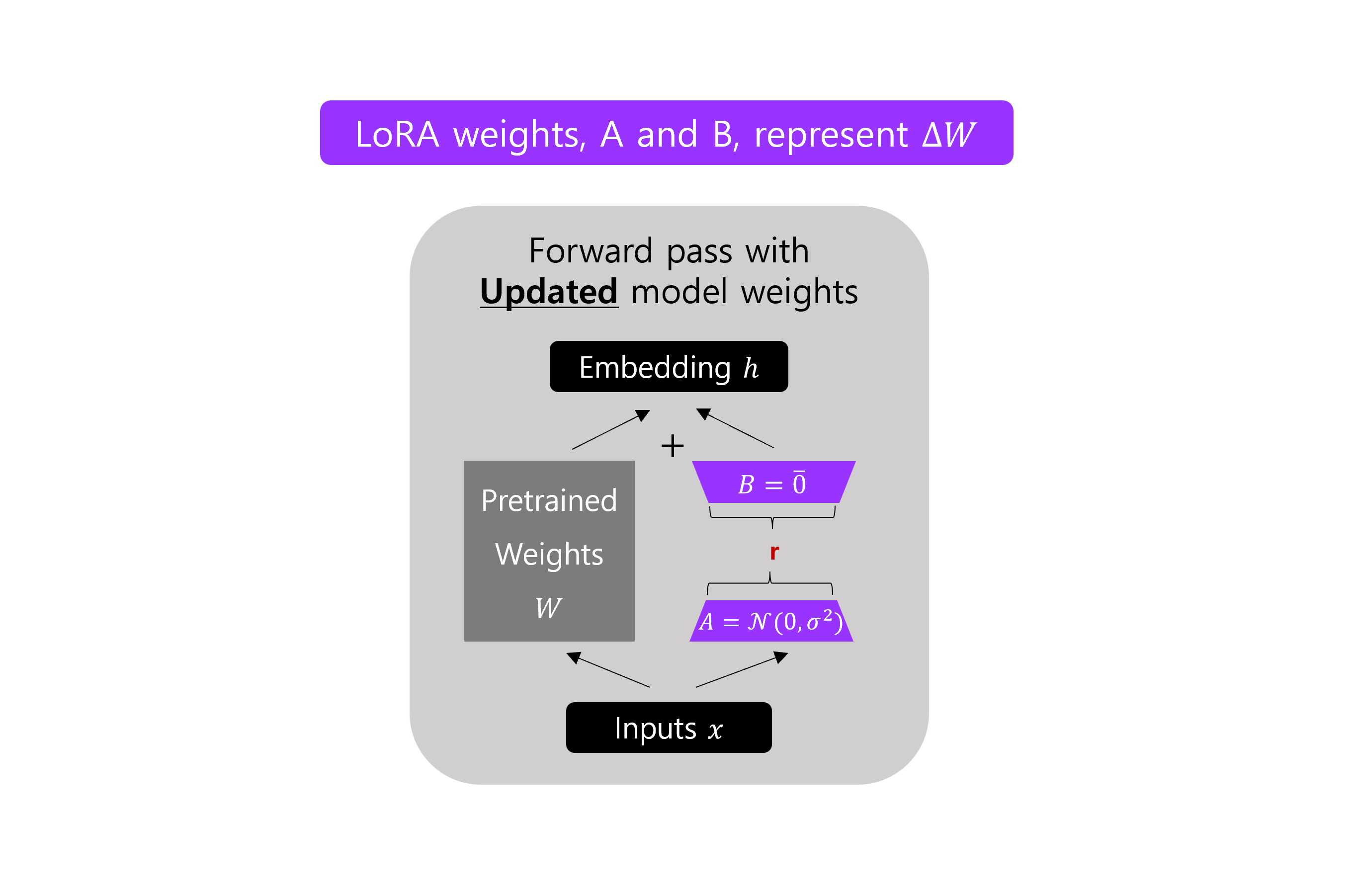
-
예를 들어, 일반적인 finetuning 은 가중치 행렬 의 업데이트를 로 계산하는데, LoRA 에서는 위의 그림에서처럼 두 개의 작은 matrix 의 곱 를 통해서 로 근사한다. 만약
PCA나SVD가 익숙하다면, 는 와 로 분해하는 것을 고려한다. -
위 그림에서의
r은 adaptation 에 사용되는 low-rank 행렬들의 rank 를 지정하기 위해 사용할 수 있는 하이퍼파라미터 이다.r이 작을 수록 더 간단한 low-rank 행렬이 생성 되어서, adaptation 하는 동안 훈련 파라미터들이 더 적다. 이것은 훈련 시간을 빠르게 하고, 계산적인 요구 사항이 잠재적으로 줄어들 수 있다. 그러나 더 작은r은 작업별 특정 정보를 캡쳐하는 low-rank matrix 의 용량이 줄어든다. -
구체적인 (concrete) 예를 제공하기 위해서, 주어진 layer 의 가중치 행렬 의 크기가 (전체 50M 파라미터) 라고 가정한다. 만약 rank
r=8을 선택했다면, 두 행렬들 차원의 행렬 와 차원의 행렬 로 초기화 한다. 와 둘을 더하면 파라미터 이고, 를 통한 일반적인 finetuning 인 파라미터 보다 400 배 더 작게 된다. -
실제로, 새로운 작업에 원하는 성능을 성취하기 위해서, right balance 를 찾기 위한 다양한
r값들을 실험하는 것이 중요하다.
several key advantages
-
pre-trained 모델을 공유할 수 있고, 다른 task 들을 위해 작은 LoRA 모듈 들을 build 하는 데 사용할 수 있다. 공유된 pre-trained 모델 을 freeze 하고 매트릭스 와 로 대체 함으로써 효율적으로 task 를 switch 하여 storage 요구 사항과 task-switching 에 발생하는 overhead 를 크게 줄일 수 있다.
-
거의 대부분의 parameter 에서 gradient 들을 계산하거나 최적화 상태를 유지할 필요가 없기 때문에 LoRA 는 adaptive optimizer 를 사용할 때, 훈련은 더욱 효율적으로 만들고, hardware barrier (장벽.. “훈련을 위한 고 비용의 하드웨어” 로 이해) 를 3배 까지 낮춘다.
-
간단한 linear design 를 배포할 때 훈련 가능한 행렬의 고정된 weights 와 병합 하여, 구조적으로 전체 fine-tuned 모델과 비교하여 inferecne latency 가 발생하지 않는다.
-
많은 사전 방법들과 orthogonal (직교 한다는 뜻인데 아마 독립적이라고 표현하고 싶은 것 같다.) 하고 prefix-tuning (접두어 튜닝?) 과 같은 많은 방법들과 조합할 수 있다.
problem statement
-
로 parametrized 된 사전학습 자기 회귀적 언어모델 가 주어졌다고 가정하자. 는 Transformer 구조 기반의 GPT 와 같은 일반적인 다양한 작업 모델 일 수 있다. 요약, 기계 독해, 그리고 자연어를 SQL 로 변환하는 등의 다운스트림 조건부 문장 생성 태스크에 이 사전 학습된 모델들 적용하는것을 고려해보자.
-
각 다운스트림 태스크는 문장-타겟 쌍들의 훈련 데이터 로 표시 며, 여기서 는 둘다 token 의 sequence 이다. 예를 들어서 NL2SQL 에서는 는 자연어 이고 는 자연어 와 일치하는 SQL command 이다.
-
전체 fine-tuning 하는 동안, 모델은 사전 학습된 가중치 로 초기화 되고, 조건 언어 모델링 목적을 최대화 하기 위해서, gradient 에 따라 반복적으로 를 업데이트 한다.
-
전체 fine-tuning 의 주요 단점 중 하나는 각 downstream 태스크에 대해 와 같은 차원 인 파라미터 파라미터들의 셋을 학습한다는 것이다. 따라서 사전 학습 모델이 아주 큰 경우 ( GPT-3 과 같은 경우 Billion ) fine-tuned 모델들의 많은 독립적인 인스턴스들이 저장하고 배포하는 것이 가능하더라도 여려울 수 있다.
-
작업 별 매개변수 증가 가 인 좀 더 작은 크기의 파라미터 집합 에 의해서 인코딩 되는 것 보다 좀 더 파라미터 효율적인 접근 방식을 채택한다. 를 찾는 작업은 에 대해 최적화된다.
- 계산과 메모리 모두 향상 시키는 을 encode 하기 위해서 low-rank 표현을 사용할 것을 제안한다. 사전 학습된 모델이 GPT-3 175B 일 때, 학습 가능한 파라미터들 의 수는 수의 보다 작을 수 있다.
low-rank parameterized update matrices
-
LoRA 의 간단한 설계와 현실적인 이점들에 대해 설명한다. 신경망에는 행렬 곱을 수행하는 수많은 dense layer 들을 포함한다. 이 레이어들에 있는 가중치 행렬들은 전형적으로 full-rank 를 갖는다.
-
특정 작업에 맞출 때, 사전 훈련 된 언어 모델들은 “intrinsic dimension” (본질적 차원) 이 낮고 더 작은 부분 공간에 대한 무작위 projection 임에도 불구하고 여전히 효율적으로 학습할 수 있음을 보여준다. 이것에 영감을 받아서 가중치에 대한 업데이트도 맞추는 중에도 낮은 “본질적 rank” 를 갖는다고 가정한다.
-
pre-trained 가중치 행렬 의 경우 low-rank 로 분해를 이고 rank 인 로 표현하여 업데이트를 제한한다. 훈련 하는 동안, 는 훈련 가능한 매개변수가 포함되어 있고, 는 frozen 하고 gradient update 를 받지 않는다.
-
와 둘 다 동일한 입력과 곱해지고, 그들 각각의 출력 벡터들은 좌표별로 합한다. 일 경우에 forward pass 는 아래와 같이 수정되었다.
-
에 대해 random Gaussian 초기화를 사용하고, 에 대해서는 zero 를 사용하여서 training 의 시작에는 가 이 되게 한다. 를 로 scale 한다.
-
여기서 는 에서의 상수이다. Adam 으로 최적화 할 때, 튜닝은 초기화를 적절하게 scale 을 하는 경우, learning rate 을 튜닝 하는 것과 거의 같다. 결과적으로 간단하게 첫 번째 에 를 조정하거나 시도하지 않는다.
applying LoRA to transformer
근본적으로 훈련 가능한 파라미터들의 수를 줄이기 위해서 신경망에 있는 가중치 행렬들의 모든 부분집합을 LoRA 로 적용할 수 있다. Transformer 구조에는 self-attention module 4 개 MLP module 에 있는 2개의 가중치 행렬들이 있다. 출력 차원이 보통 attention heads 로 슬라이스 되더라도 차원 차원의 단일 행렬 로써 처리된다. 단순성과 파라미터의 효율성 모두를 위해서 downstream 작업들을 위한 attention 가중치들에만 적용하고 MLP module 들에는 freeze 하는 것 (MLP module 들이 downstream tasks 에서 훈련되지 않도록) 으로 연구를 제한한다.
pseudo code review
methodology from scratch
개념적인 설명은 때때로 추상적일 수 있으므로, 그것이 얼마나 잘 동작 하는지 더 잘 알기 위해서 LoRA 를 직접 개발해보자.
코드에서 다음 과 같이 LoRA layer 를 개발 할 수 있다.
class LoRALayer(nn.Module):
def __init__(self, in_dim, out_dim, rank, alpha):
super().__init__()
std_dev = 1 / torch.sqrt(torch.tensor(rank).float())
self.A = nn.Parameter(torch.randn(in_dim, rank) * std_dev)
self.B = nn.Parameter(torch.zeros(rank, out_dim))
self.alpha = alpha
def forward(self, x):
x = self.alpha * (x @ self.A @ self.B)
return xin_dim : LoRA 를 사용하여 수정하기를 원하는 layer 의 input 차원.
out_dim : 해당 layer 의 output 차원
행렬 의 r ( rank ) 는 LoRA 에 의해 도입된, 추가적인 매개변수의 수와 복잡성을 제어하는 하이퍼 파라미터이다. 여기서 또 다른 하이퍼파라미터, scaling factor alpha 를 더한다.
alpha : LoRA layer 에 의한 도입으로 모델의 존재하는 가중치에 대한 변화의 크기를 결정.
self.alpha * ( x @ self.A @ self.B )의 값이 높을수록 모델의 behavior 가 더 크게 조정이 되고, 값이 낮을수록 결과에 더 미묘한 변화가 생긴다.
또 하나 주의할 점은, 를 random 분포로부터 작은 값으로 초기화를 시킨다. 여기서 이 분포의 표준 편차는 (sqaure root of the rank) 에 의해 결정된다. (이 선택은 가 너무 크지 않게 초기 값을 보장한다.) 그러나 는 이다.
이론적 근거는, 훈련 초기에 와 가 backpropagtion 을 통해 업데이트 되기 전, 이면 으로 LoRALayer 는 원래의 가중치에 영향을 가하지 않기 위해서 이다.
LoRA 는 보통 신경망의 linear (feedforward) layer 들에 적용한다. 예를 들어서 간단한 PyTorch 모델이나 2 linear layer 를 포함한 module 을 가지고 있다고 가정한다. (예를 들어, 이것은 transformer 블럭의 feedforward module 일 수 있다.) 그리고 이 모듈의 forward method 가 아래와 같다고 가정한다.
def forward(self, x):
x = self.linear_1(x)
x = F.relu(x)
x = self.linear_2(x)
return x만약 LoRA 를 사용하면, 이 linear layer 출력에 LoRA 업데이트를 더한다.
def forward(self, x):
x = self.linear_1(x) + self.lora_1(x)
x = F.relu(x)
x = self.linear_2(x) + self.lora_2(x)
return x기존의 PyTorch 모델들을 수정하여 LoRA 를 구현할 때, linear layers 의 LoRA-modification 과 같은 것을 구현하는 쉬운 방법은 기존에 개발한 LoRALayer 와 Linear layer 를 조합한 LinearWithLoRA layer 로 Linear layer 를 대체하는 것이다.
class LinearWithLoRA(nn.Module):
def __init__(self, linear, rank, alpha):
super().__init__()
self.linear = linear
self.lora = LoRALayer(
linear.in_features, linear.out_features, rank, alpha
)
def forward(self, x):
return self.linear(x) + self.lora(x)summarized
-
이 간단한 예시 module 의 각 linear layer 에 LoRA module 을 더하기를 원한다.
class FeedForwardNetwork(nn.Module): def __init__(self, embedding_dim): super().__init__() self.network = nn.Sequential( nn.Linear(embedding_dim, 4 * embedding_dim), nn.ReLU(), nn.Linear(4 * embedding_dim, embedding_dim), nn.Dropout(0.2) ) def forward(self, x): return self.network(x) -
기본의 linear 는
LinearWithLoRAlayer 의 입력 변수로 제공된다. -
LinearWithLoRAlayer 는 원래의 linear layer 와 LoRA 가중치 매트릭스들을 포함하는 LoRALayer 로 구성된다.class LinearWithLoRA(nn.Module): def __init__(self, linear, rank, alpha): super().__init__() self.linear = linear self.lora = LoRALayer( linear.in_features, linear.out_features, rank, alpha ) def forward(self, x): return self.linear(x) + self.lora(x) -
새로운
LinearWithLoRA레이어 에서는 forward pass 동안 linear 와 LoRA layer 출력을 더한다.
실제로, LoRA 를 모델에 장착하고, finetune 하기 위해서, 해야할 일은 모든 pretrained Linear layer 들을 새로운 LinearWithLoRA layer 로 바꾸는 것이다.
testing LoRALayer
- LoRALayer.py
import torch
import torch.nn as nn
class LoRALayer(nn.Module):
def __init__(self, in_dim, out_dim, rank, alpha):
super(LoRALayer, self).__init__()
std_dev = 1 / torch.sqrt(torch.tensor(rank).float())
self.W_a = nn.Parameter(torch.randn(in_dim, rank) * std_dev)
self.W_b = nn.Parameter(torch.zeros(rank, out_dim))
self.alpha = alpha
def forward(self, x):
x = self.alpha * (x @ self.W_a @ self.W_b)
return x
class LinearWithLoRA(nn.Module):
def __init__(self, linear, rank, alpha):
super(LinearWithLoRA, self).__init__()
self.linear = linear
self.lora = LoRALayer(
linear.in_features, linear.out_features, rank, alpha
)
def forward(self, x):
return self.linear(x) + self.lora(x)- main.py
import torch
from LoRALayer import LinearWithLoRA
torch.manual_seed(777)
linear_layer = torch.nn.Linear(10, 1)
x = torch.rand((1, 10))
print(linear_layer(x))
# tensor([[0.1863]], grad_fn=<AddmmBackward0>)linear layer 대신 LoRA layer 로 대신하자.
lora_layer = LinearWithLoRA(
linear=linear_layer,
rank=7,
alpha=1)
# lora_layer.lora.W_a.shape : torch.Size([10, 7])
# lora_layer.lora.W_b.shape : torch.Size([7, 1])
print(lora_layer(x))
W_a x W_b-> in_dim : 10, out_dim : 1tensor([[0.1863]], grad_fn=<AddBackward0>)
간단한 가중치 업데이트를 simulate 하자.
# x[0].shape : torch.Size([10])
lora_layer.lora.W_b = torch.nn.Parameter(
lora_layer.lora.W_b + 0.01 * x[0]
)
# lora_layer.lora.W_a.shape : torch.Size([10, 7])
# lora_layer.lora.W_b.shape : torch.Size([7, 10])
print(lora_layer(x))-
W_a x W_b-> in_dim : 10, out_dim : 10tensor([[0.1945, 0.1878, 0.1949, 0.1964, 0.1999, 0.1989, 0.1908, 0.1983, 0.1985, 0.1987]], grad_fn=<AddBackward0>)가중치 업데이트로 output 을
1에서10으로 변경하였다.
