
LLAMA FACTORY
Unified Efficient Fine-Tuning of 100+ Language Models
이번 논문은 리뷰가 아닌 번역, 해석에 가깝고, 각 논문 링크를 따로 모두 달았다. 현재 trend 의 집합 솔루션 으로 인식했고, 현재의 trend 에 따라가기 위해서.. 여기서 사용하는 것들이 현재 사용되고 있는 유명한 방법론이라고 생각했다. 따라서 코드를 뜯기 전에 한 번 쭉, 번역을 했다.
1. Introduction
Large language models (LLMs) 은 현재 remarkable (놀랄만한) 추론 능력 과 질문-답변, 기계 번역 과 정보 추출 과 같은 넓은 범위의 application 을 할 수 있는 능력이 있다.
- A Survey of Large Language Models paper-link
- Document-Level Machine Translation with Large Language Models paper-link
- Instruct and Extract: Instruction Tuning for On-Demand Information Extraction paper-link
그 후에 (Subsequently) open-source 커뮤니티들을 통해서 상상수의 LLMs 가 개발되었고, 접근하기 쉬워졌다. 예를 들어 Hugging Face’s open LLM leaderboard
Open LLM Leaderboard - a Hugging Face Space by HuggingFaceH4
는 5000 개 이상의 모델을 자랑하며, LLMs 의 power 를 사용 하기를 원하는 개인들을 위해 편의를 제공하고 있다. 제한적인 리소스를 가지고 매우 큰 수의 parameters 를 fine-tuning 하는 것이 LLM 의 downstream 작업에 적용하는 main challenge 가 되었다.
효율적인 fine-tuning 방법.
- Parameter-Efficient Transfer Learning for NLP paper-link
- LoRA: Low-Rank Adaptation of Large Language Models paper-link
- BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models paper-link
- QLoRA: Efficient Finetuning of Quantized LLMs paper-link
- GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection paper-link
다양한 task 들을 적용할 때 llm 들의 훈련 비용을 줄여준다. 그러나 커뮤니티는 효율적인 fine-tuning 을 위한 다양한 방법들에 기여하지만, 다른 LLM 들에 이 방법들을 적용, 통합 하고 유저 커스터마이즈를 위한 인터페이스를 제공하는 체계적인 프레임워크가 부족하다.
위와 같은 문제들을 해결하기 위해 LlamaFactory 를 개발하여 LLMs 의 fine-tunig 을 자유롭게 할 수 있는 framework 를 개발한다. scalable module 을 통한 효율적인 미세조정의 방법들을 통합하여 최소한의 리소스와 높은 처리량으로 수백개의 LLM 을 fine-tuning 할 수 있다.
게다가 그것은
- Improving Language Understanding by Generative Pre-Training (GPT - 1) paper-link
- Finetuned Language Models Are Zero-Shot Learners paper-link
- Training language models to follow instructions with human feedback (RLHF) paper-link
- Direct Preference Optimization: Your Language Model is Secretly a Reward Model (DPO) paper-link
을 포함한 보통 사용되는 훈련 접근법을 간소화 시킨다. 사용자는 command-line 이나 web interface 를 사용하여 coding 을 최소화 하거나 노력 없이 LLMs 를 customize 와 fine-tune 을 할 수 있다.
LlamaFactory 는 3 가지 main module
Model Loader, Data Worker, Trainer
로 구성되어 있다. 특정 models 및 datasets 에 대해 이러한 모듈들의 종속성을 최소화하여 framework 가 수백개의 models 와 datasets 를 유연하게 확장시킬 수 있다.
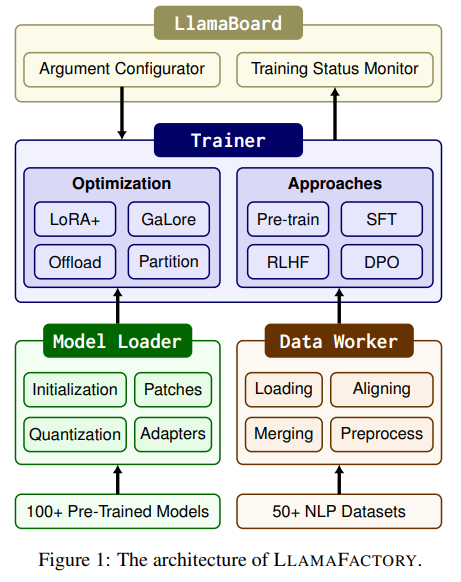
구체적으로,
-
Model Loader가 정확한 layers 를 식별하여 pre-trained 된 모델에 adpaters 를 정확하게 연결할 수 있는 model registery 를 설정한다. -
Data Worker가 일치하는 열을 정렬 하여 데이터 셋 들을 수집할 수 있도록 데이터 description specification 을 개발한다. -
Trainer가 default ones (이건 각 framework 의 trainer 같다..) 을 대체하여 활성화 할 수 있는 효율적인 fine-tuning 방법들을 하기 위한 plug-and-play 구현을 제공한다.
우리의 설계는 이 module 들 ( Model Loader , Data Worker , Trainer ) 을 다양한 training approaches 재사용하여 새로운 방법의 통합 비용을 줄인다.
LlamaFactory 는 Pytorch 로 구현되었고,
- Attention Is All You Need paper-link
- Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning paper-link, github
- Transformer Reinforcement Learning TRL - Transformer Reinforcement Learning, github
와 같은 오픈 소스 library 의 이점을 상당히 가져올 수 있다. 이것을 바탕으로 더 높은 레벨의 추상화를 갖는 out-of-the-box framework 을 제공한다.
Gradio 를 사용하여 LlamaBoard 를 만들어서 coding 작업 없이 LLMs 를 fine-tuning 할 수 있다. 예를 들어, 잘 알려진 모델 GemSUra-7B 은 LlamaFactory 에 기반하여 만들어졌는데, Gemma 의 cross-lingual 능력을 처음 드러냈다. (GemSura-7B 모델은 Gemma 7B 를 Finetuned 하였고, LlamaFactory 사용)
- Gemma: Open Models Based on Gemini Research and Technology paper-link
- GemSUra-7B ura-hcmut/GemSUra-7B · Hugging Face
2. Efficient Fine-Tuning Techniques
효율적인 LLM fine-tuning 기술들은 두 가지 main categories : 최적화에 초점을 맞추거나, computation 에 목표를 두는 것으 나눌 수 있다.
- Efficient Optimization 의 주요 목적은 최소화의 비용을 유지하는 동안 LLMs 의 parameter 들을 조정하는 것이다.
- Efficient computation 은 LLM 에서 요구되는 계산에 요구되는 시간 이나 공간을 줄이는데 목표를 둔다.
그 방법들은 Llama Factory 에 포함되어있다.

이런 효율적인 fine-tuning 기술들을 제시하고, framework 로 그들을 통합 함으로써, 실질적으로 상당히 효과적으로 개선됨을 보여줄 것이다.
Mixed precision
fp16, fp32 를 섞어서 학습하는 방법.
Mixed-Precision Training of Deep Neural Networks | NVIDIA Technical Blog
fp16 은 메모리는 작게, 처리속도는 빠르게, reduction 느낌이고, fp32 는 reduction 을 다하면 손실이 많이 나니 정보 유지를 위해서 둘을 섞어 쓰는 느낌.
Checkpointing
현재 상황의 weight parameter (과정) 을 저장하는 로직.
Flash attention
쉽게 말해 hbm 메모리에서 큰 덩어리로 토막내어 가져와서 sram 으로 보내주겠다는 이야기. 하드웨어 사용까지 고민하면서 접근하려는 방향이 신선했다. 코드 상으로 cuda 에서 __shared__ 로 사용하면 sram 을 사용하는 것이고, 여기서 smem_[] 으로 선언 함을 알 수 있다.
- v1 paper paper-link
// flash-attention\csrc\flash_attn\flash_api.cpp // flash-attention\csrc\flash_attn\src\flash_fwd_kernel.htemplate<typename Kernel_traits, bool Is_dropout, bool Is_causal, bool Is_local, bool Has_alibi, bool Is_even_MN, bool Is_even_K, bool Return_softmax, typename Params> inline __device__ void compute_attn(const Params ¶ms) { const int m_block = blockIdx.x; // The block index for the batch. const int bidb = blockIdx.y; // The block index for the head. const int bidh = blockIdx.z; // We want the fwd and bwd to generate the same dropout pattern (RNG), without restricting // them to have the same number of threads or have to traverse the attention matrix // in the same order. // In the Philox RNG, we use the offset to store the batch, head, and the lane id // (within a warp). We use the subsequence to store the location of the 16 x 32 blocks within // the attention matrix. This way, as long as we have the batch, head, and the location of // the 16 x 32 block within the attention matrix, we can generate the exact same dropout pattern. flash::compute_attn_1rowblock<Kernel_traits, Is_dropout, Is_causal, Is_local, Has_alibi, Is_even_MN, Is_even_K, Return_softmax>(params, bidb, bidh, m_block); } Tensor sQ = make_tensor(make_smem_ptr(reinterpret_cast<Element *>(smem_)), typename Kernel_traits::SmemLayoutQ{});template<typename Kernel_traits, bool Is_dropout, bool Is_causal, bool Is_local, bool Has_alibi, bool Is_even_MN, bool Is_even_K, bool Return_softmax, typename Params> inline __device__ void compute_attn_1rowblock(const Params ¶ms, const int bidb, const int bidh, const int m_block) { using Element = typename Kernel_traits::Element; using ElementAccum = typename Kernel_traits::ElementAccum; using index_t = typename Kernel_traits::index_t; // Shared memory. extern __shared__ char smem_[]; ... Tensor sQ = make_tensor(make_smem_ptr(reinterpret_cast<Element *>(smem_)), typename Kernel_traits::SmemLayoutQ{}); // Careful we're using the same smem for sQ and sK | sV if Share_Q_K_smem; Tensor sK = make_tensor(sQ.data() + (Kernel_traits::Share_Q_K_smem ? 0 : size(sQ)), typename Kernel_traits::SmemLayoutKV{}); Tensor sV = make_tensor(sK.data() + size(sK), typename Kernel_traits::SmemLayoutKV{}); - v2 paper paper-link
attention ( system 2 attention )
한 단계 걸러서 내용 정리 혹은 noise 내용을 제거하고 키워드를 좀 부각시켜서 요약해 주겠다는 이야기. paper-link
Quantization
실제 continuous 를 discrete 하게 바꾸는 내용이지만, 딥러닝 계열에서는 FP (Floating-Point) → INT (Integer) 를 말하기도 한다.
Unsloth
Unsloth AI | Finetune AI & LLMs faster
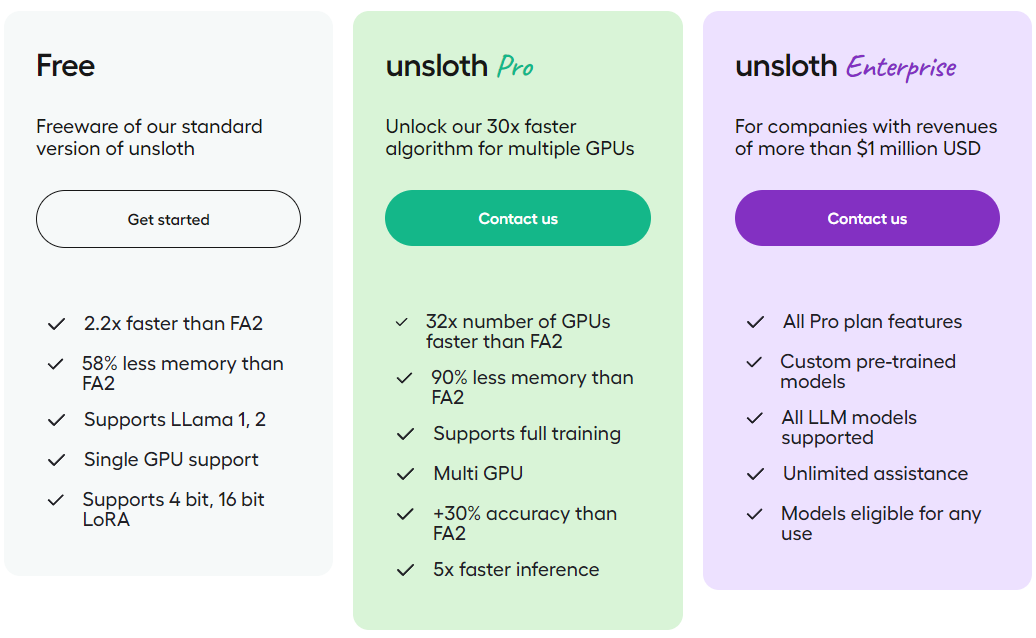
속도가 빠르고, memory 도 적게 먹으면서 무료버전은 Llama 1, 2 와 GPU 도 서포트 해주는 시스템 으로 보여진다.
2.1 Efficient Optimization
LlamaFactory 에서 활용하는 효율적인 최적화 기술의 개요를 제공한다.
-
freeze-tuning 방법은
- Parameter-Efficient Transfer Learning for NLP paper-link
다수의 파라미터들을 freezing 하고 디코더 레이어들의 작은 하위 집합에서 나머지 파라미터들을 fine-tuning 하는 것을 포함한다.
-
gradient low-rank projection (GaLore) 방법 은
- GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection paper-link
저차원 공간에 gradients 를 투영 (projects) 하여 메모리 효율적인 방법으로 전체 파라미터 학습을 가능하게 한다 (facilitate) .
- GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection paper-link
-
low-rank adaptation ( LoRA ) 방법은
- LoRA: Low-Rank Adaptation of Large Language Models paper-link
모든 pre-trained weights 들을 freeze 하고, 지정된 layer 에 훈련 가능한 low-rank 행렬들의 쌍을 도입한다.
- LoRA: Low-Rank Adaptation of Large Language Models paper-link
-
quantized low-rank adaptation (QLoRA) 방법은
- QLoRA: Efficient Finetuning of Quantized LLMs paper-link
quantized (양자화) 와 결합하여, 메모리 사용량을 추가로 줄인다.
- QLoRA: Efficient Finetuning of Quantized LLMs paper-link
-
weight-decomposed low-rank adaptation (DoRA) 방법은
- DoRA: Weight-Decomposed Low-Rank Adaptation paper-link
pre-trained weights 를 크기 와 방향 요소로 분해하고, 방향 요소에만 LoRA 를 적용하여 LLMs 의 fine-tuning 을 향상시킨다.
- DoRA: Weight-Decomposed Low-Rank Adaptation paper-link
-
LoRA+ 방법은
- LoRA+: Efficient Low Rank Adaptation of Large Models paper-link
LoRA 의 차선책? 을 극복하기 위해 제안하였다..?
- LoRA+: Efficient Low Rank Adaptation of Large Models paper-link
2.2 Efficient Computation
Llama Factory 에서 다양한 효율적인 computational 기술들을 통합한다. 일반적으로 활용되는 기술들에는
- Mixed Precision Training Train With Mixed Precision
- activation checkpointing
- Training Deep Nets with Sublinear Memory Cost paper-link
- Training Deep Nets with Sublinear Memory Cost paper-link
가 포함된다.
attention layer 의 input-output ( IO ) 비용에 대한 실험에서 insights 를 도출한 flash attention 은
-
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness paper-link
attention 계산을 향상 시키기 위해 하드웨어 친화적인 접근 방식을 도입한다.
attention 은
-
LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models paper-link
block-sparse 어텐션 에서 context 를 확장하는 문제를 해결, fine-tuning 한 long-context LLMs 로 memory 사용량을 감소시킨다.
다양한 quantization 전략들은
- LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale paper-link
- GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers paper-link
- AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration paper-link
- Extreme Compression of Large Language Models via Additive Quantization paper-link
weights 에 대해 lower-precision ( FP32 → FP16 or INT8 ..) 를 활용하여 LLMs 의 메모리 요구를 줄인다. quantized 모델들의 fine-tuning 은 LoRA 와 같은 adapter 기반 기술로 제한된다.
아무래도 pre-training 한 base model 을 처음부터 학습 시킬 때 quantized 시킨다면 정보량을 너무 잃어버려서 제대로 학습이 되지 않을 것이라서, fine-tuning 할 때의 내용으로 한정하는 것이 맞다고 생각한다.
Unsloth 는 LoRA 의 backward propagation 을 구현하기 위해서
- Triton: An Intermediate Language and Compiler for Tiled Neural Network Computations www.eecs.harvard.edu
을 통합하여 gradient descent 하는 동안 floating-point operations (FLOPs) [ 부동 소수점 연산 ] 을 줄이고, 더 빠른 LoRA traning 으로 연결한다. Llama Factory 는 이 기술들을 LLM fine-tuning 의 효율성을 크게 향상키는 결합력있는 구조로 효과적으로 결합한다. 이러한 결과로 mixed precision 훈련 중에는 파라미터당 18 바이트 메모리 공간이 감소하고, bfloat16 훈련 중에 파라미터당 8 바이트에서 0.6 바이트로 메모리가 차지 하는 공간이 줄어든다.
3. Llama Factory Framework
LlamaFactory 는 ( Model Loader, Data Worker 와 Trainer ) 3개 main module 들로 구성한다.
- Model Loader 는 100 개 이상의 LLMs 를 지원하는 fine-tuning 을 하기 위한 다양한 architecture 를 준비한다.
- Data Worker 들은 50 개 이상의 dataset 을 지원하는 잘 설계된 파이프라인을 통해서 각기 다른 tasks 로부터 데이터를 처리한다.
- Trainer 는 효율적인 fine-tuning 방법들을 통합하여 각기 다른 tasks 와 datasets 를 이 모델들에 적용하여 4 가지 training 접근 방법을 제공한다.
Llama Board 는 위 모듈들에 대해서 친근한 시각적인 인터페이스를 제공하여, codeless 방법으로 개별 LLM fine-tuning 프로세스를 구성, 실행 하고 training 상태를 바로 모니터링 할 수 있도록 한다.
3.1 Model Loader
Model Loader 의 4 가지 구성 요소를 제시한다. (present)
- Model Initialization
- Model Patching
- Model Quantization
- Adapter Attaching
fine-tuning 시에 parameter 에서 float-point precision 을 처리하여 넓은 범위의 device 에 적용하는 접근 방식에 대한 설명도 더 나온다.
아마도 edge computing 범위까지의 장치를 말하는 듯 하다.
Model Initialization
모델들을 loading 하고 파라미터들을 초기화 하기 위해서 Transformers 의 AutoModel API 를 사용한다.
AutoModels — transformers 3.0.2 documentation
각기 다른 모델 구조들과 프레임워크를 호환하기 위해서 모델 등록을 하고, 모델의 각 layer 의 type 을 저장하여 이것에 의해, 효율적인 fine-tuning 을 좀 더 수월하게 이용할 수 있도록 한다. tokenizer 의 어휘 크기가 embedding layer 의 용량을 넘어가는 경우에는 layer 를 조정하고, “noisy mean” initialization 으로 새로운 파라미터들을 초기화한다.
여기서 “noisy mean” 이 뭐지?
RoPE ( Rotary Position Embedding ) scaling
- Extending Context Window of Large Language Models via Positional Interpolation paper-link
에 대한 scaling factor 를 결정하기 위해서 model 의 context 길이에 대한 최대 input sequence 길이의 비율로 계산한다.
Model Patching
Flash Attention 과 attention 을 가능하게 하기 위해서, 모델들의 forward 계산을 monkey patch 로 대신한다. Transformers 4.34.0 에서는 Flash Attention 이 지원 되므로, API 를 사용하여 Flash Attention 을 가능하게 한다. dynamic modules 의 과도한 분할을 예방하기 위해서, DeepSpeed ZeRO-3 에서 최적화 할 때, Mixture-of-Experts ( MoE ) block 을 leaf modules 로 설정한다.
동적 모듈과 과도한 분할 (excessive partitioning) 무슨 의미인지..
To prevent excessive partitioning of the dynamic modules, we set the mixture-of-experts (MoE) blocks as leaf modules when we optimize it under DeepSpeed ZeRO-3Keyword : DeepSpeed ZeRO-3
- DeepSpeed: System Optimizations Enable Training Deep Learning Models with Over 100 Billion Parameters paper-link, github
DeepSpeed 와 Zero 를 섞은 최적화로 보여진다.
Model Quantization
LLM.int8 를 사용하여 8 bits 또는 4 bits 로 Dynamically quantizing 하는 것은
- BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models paper-link
bitsandbytes libarary 를 통해서 할 수 있다. - github, huggingface
4-bit quantization 을 위해서 double quantization 과 4-bit 일반 float 을 QLoRA 로 활용한다.
-
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers paper-link
-
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration paper-link
-
Extreme Compression of Large Language Models via Additive Quantization paper-link
Additive Quantization of Language Models (AQLM)
을 포함한 Post-Training Quantization (PTQ) 방법들로 quantized 된 모델들의 fine-tuning 을 지원한다.
Adapter Attaching
adapter module 연결하기 위해 model 등록을 사용하여 적절한 layer 를 자동으로 식별한다.
여기서 말하는 adapter 는
- Parameter-Efficient Transfer Learning for NLP paper-link
이 논문을 참고 하면 된다.
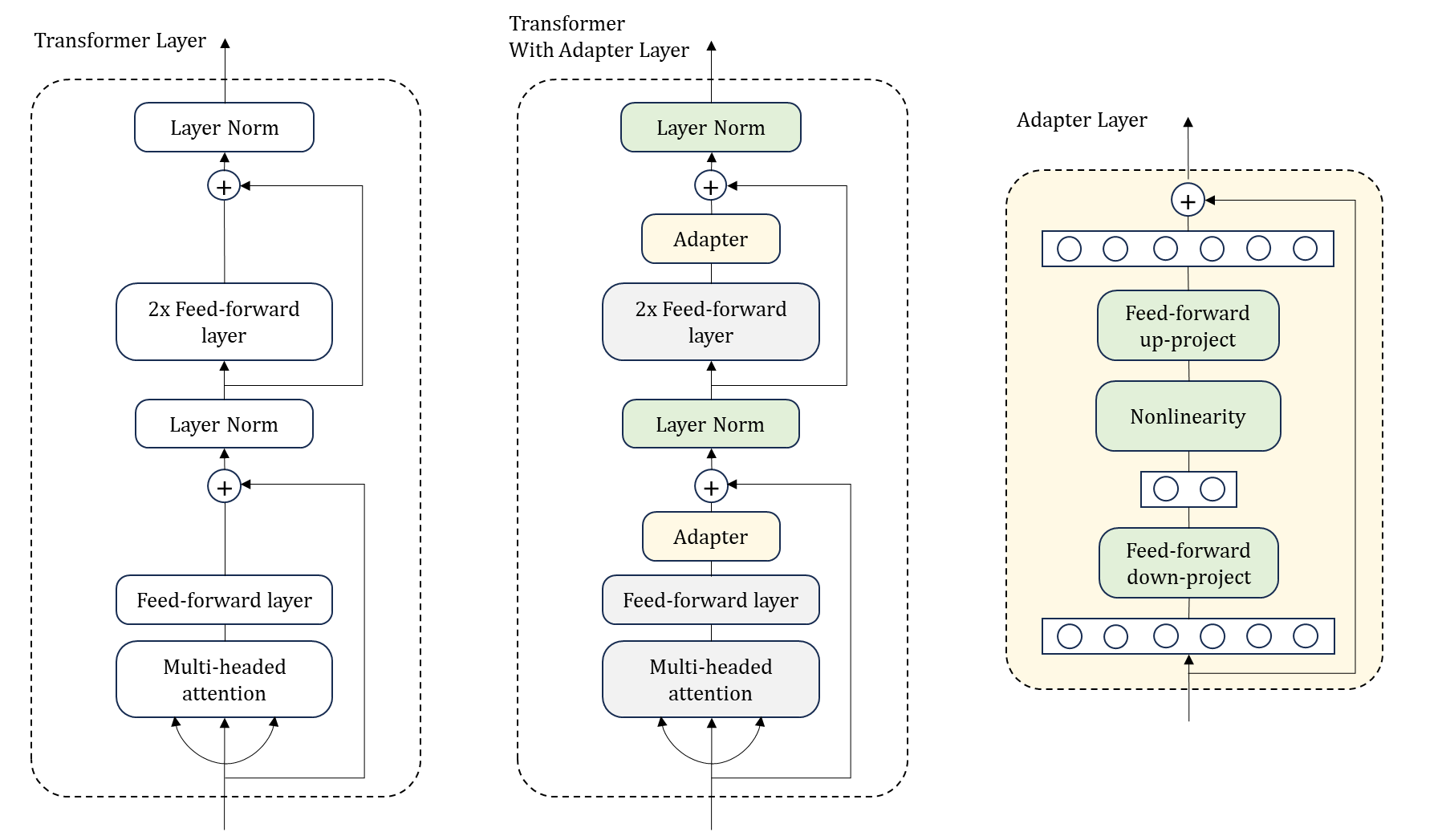
-
adapter module 의 구조, transformer 와 통합 한다.
-
adapter module 은 각 transformer layer 에
- Multi-headed attention → projection 이후 1개
- 2 개의 Feed-Forward layer 이후 1개
이렇게 총 2 개의 module 을 더한다.
adapter module 은 original 모델의 attention 과 Feed-forward layer 와 관계되는 몇 가지 parameter 들을 포함하는 bottleneck 으로 구성된다. adapter module 을 튜닝하는 동안, green layer 들은 downstream 데이터에 대해 훈련되고, 이것은 layer normalization 파라미터 와 최종 분류 레이어가 포함된다.
Adapters 는 기본적으로 메모리를 절약을 하기 위해 layers 의 subset 에 연결 되지만, 모든 linear layer 에 그들을 연결하면, 더 좋은 performance 를 낼 수 있다.
bottleneck 구조에
DWConv구조가 생각났다. denoise 를 하면서 dimension reduction 을 가져가는 느낌. 역시 LoRA 의 A 가 Adapter module 이다. 그러니, Link paper 도 QLoRA.
huggingface 의 PEFT ( Parameter Efficient Fine-Tuning ) library 는 PEFT LoRA, rsLoRA, DoRA 와 같은 Adapter 들을 연결하기 위해 매우 편리한 방법을 제공한다.
LoRA 를 accelerate 하기 위해서 backward 계산을 Unsloth 로 대신한다. Reinforcement Learning from Human Feedback (RLHF) 수행하기 위해, 각 token 의 표현을 scalar 에 mapping 하는 linear layer 인 value head 를 model 에 추가한다.
Precision Adaptation
장치의 기능을 기반으로 pre-trained 모델들의 floating-point 정밀도를 다룬다. NVIDIA GPU 의 경우, 계산 능력이 8.0 이상인 경우, bfloat16 정밀도를 사용한다. 그렇지 않으면 float16 을 채택한다.
일반적으로 float32 를 사용해야 하나, 현재 경량화 측면에서 (b)float16 를 선택하는 듯 하다. 그렇다고, training 시에 float16 을 사용하는 것은 무리가 있어 보이고, bfloat16 을 사용하는 것을 권장. 물론, float32 가 제일 좋지만, resource 문제가 있다면..
Ascend NPUs 와 AMD GPU 일 경우에는 float16 을 사용하고, non-CUDA 장치 일 경우에는 float32 를 사용한다. float16 정밀도로 bfloat16 모델을 loading 하면 overflow 이슈가 생길 수 있다. mixed precision training 에서 훈련 가능한 모든 파라미터들을 float32 로 세팅한다. bfloat16 훈련 에서는 훈련 가능한 파라미터들을 bfloat16 으로 유지한다.
3.2 Data Worker
데이터셋 로딩, 정렬, 병합, 전처리를 포함한 데이터 프로세싱 파이프라인을 개발했다. 각기 다른 작업들의 데이터 셋을 통일된 형식으로 규격화하여, 다양한 형식의 데이터 셋으로 모델들이 fine-tune 을 가능하게 만들었다..
Dataset Loading
데이터를 load 하기 위하여 huggingface 의 datasets 라이브러리를 활용한다. 이를 통해서 사용자들은 Hugging Face Hub 로부터 원격 데이터 셋을 로드 하거나, 스크립트 또는 파일들을 통해서 로컬 데이터 셋을 읽는다. datasets 라이브러리는 데이터 프로세싱 중, 메모리 오버해드를 크게 줄이고, Arrow 를 사용하여 샘플 쿼리를 가속화 한다.
Apache Arrow
- Arrow 는 언어, 플랫폼과 상관없이 memory 내 분석을 위한 개발 플랫폼.
- 대용량 데이터를 빠르게 처리 가능, pyarrow. Downloads 22 - Sample CSV Files / Data Sets for Testing (till 5 Million Records) - IBM HR Analytics for Attrition
import os import time import pandas as pd from pyarrow import csv FILE_PATH='./5000000_HRA_Records.csv' file_size = os.path.getsize(FILE_PATH) print(f"size [{round(file_size/pow(1024,2), 2)}] MB") print("using pure pandas") start = time.time() data = pd.read_csv(FILE_PATH) end = time.time() print(f"loading time : {end - start}") print("using pyarrow") start = time.time() data = csv.read_csv(FILE_PATH).to_pandas() end = time.time() print(f"loading time : {end - start}")
약 700M 데이터를 한번에 사용 할 때 loading 속도.size [738.43] MB using pure pandas loading time : 6.622596979141235 using pyarrow loading time : 1.8035457134246826
defalut 로 전체 데이터 셋을 로컬 디스크로 다운로드 하지만, 데이터 셋이 너무 큰 경우에는 다운로딩 없이 반복할 수 있는 데이터 셋 streaming 을 제공한다.
Data Aligning
데이터 형태를 통합하기 위해서 데이터 셋들의 구조를 특성화 하는 data description specification 을 설계한다. 예를 들어서 alpaca 데이터 셋은 3 개의 컬럼들 (instruction, input, output) 을 갖는다. 데이터 셋 들을 data description specification 에 따라 각기 다른 task 들과 호환되는 정해진 구조로 변환한다. 데이터 구조의 예시이다.
- Dataset structures in Llama Factory
Plain text [{"text": "..."}, {"text": "..."}] Alpaca-like data [{"instruction": "...", "input" : "...", "output": "..."}] ShareGPT-like data [{"conversations": [{"from": "human", "value": "..."}, {"from": "gpt", "value": "..."}]}] Preference data [{"instruction": "...", "input": "...", "output": ["...","..."]}]Standardized data {"prompt": [{"role": "...", "content": "..."}], "response": [{"role": "...", "content": "..."}], "system": "...", "tools": "..."}
Dataset Merging
통합된 데이터 셋 구조는 multiple 데이터 셋들을 병합하기 위한 효율적인 접근 방식을 제공한다. non-streaming 모드 ( 다운로드 방식 이겠지?) 일 경우, training 하는 동안 데이터 셋 들을 셔플하기 전에 간단하게 연결하기만 하면 된다. 그러나 streaming 모드에서는 단순히 데이터 셋들을 연결하기만 하면 shuffling 이 방해가 된다. 따라서 서로 다른 데이터 셋 들로부터 데이터 교대로 읽는 방법을 제공한다.
Dataset Pre-processing
Llama Factory 는 주로 챗 완성에 사용되는 text 생성 모델들을 fine-tuning 하기 위해 설계되었다. Chat template 은 이러한 모델들의 instruction-following 능력과 밀접한 관계가 있기 때문에, 이러한 모델들에 있어 중요한 요소이다. 따라서 모델 종류에 따라서 자동으로 선택될 수 있는 수십 개의 Chat template 을 제공한다. 토크나이저를 사용하여 chat template 을 적용한 후, 문장을 encode 한다. 기본적으로 완료시에 loss 만 계산하고, prompt 는 무시된다.
선택적으로 (Optionally) sequence packing 을 활용하여 training 시간을 줄일 수 있고,
- Efficient Sequence Packing without Cross-contamination: Accelerating Large Language Models without Impacting Performance paper-link
generative pre-training 을 수행할 때, 자동으로 활성화 된다. ( Appendix C 확인 )
3.3 Trainer
Efficient Training
기본 구성요소를 교체하여 LoRA+ 와 GaLore 를 포함한 state-of-the-art 의 효율적인 fine-tuning 방법들을 trainer 에 통합하였다. 이러한 training 접근 방식 (LoRA 계열) 은 trainer 와 독립적이므로, 다양한 작업에 쉽게 적용할 수 있다. pre-training 과 SFT (Supervised Fine-Tuning) 에는 Trasnformers 의 trainer 를 활용하고, RLHF 와 DPO 에는 TRL 에 trainer 를 채택한다.
- Transformer Reinforcement Learning (TRL) github
- Direct Preference Optimization: Your Language Model is Secretly a Reward Model (DPO) paper-link
The tailored data collators are leveraged to differentiate trainers of various training approaches. To match the input format of the trainer for preference data, we build 2n samples in a batch where the first n samples are chosen examples and the last n samples are rejected examples.Model-Sharing RLHF
고객 device 들에서 RLHF 를 훈련을 허용 하는 것은 LLM fine-tuning 에 있어 유용한 요소이지만, RLHF 훈련에는 4 가지 다른 모델들이 요구되어 어렵다. 이러한 문제를 해결하기 위해서, 한 개의 pre-trained 모델 만 가지고 전체 RLHF 훈련을 가능하게 하는 model-sharing RLHF 를 제안한다. 구체적으로 먼저 reward 모델링을 위한 objective 함수를 사용하여 adapter 와 value head 를 훈련하여 모델이 reward score 를 계산할 수 있도록 한다. 그리고 나서 다른 adapter 와 value head 를 초기화 하고, 그들을 PPO 알고리즘으로 훈련한다.
- PPO ( Proximal Policy Optimization Algorithms ) paper-link
- Training language models to follow instructions with human feedback paper-link
adapters 와 value head 는 training 도중 PEFT 의 set_adapter 와 disable_adapter API 를 통해 동적으로 전환되어 사전 훈련된 모델이 동시 policy, value, reference 와 reward 모델들 역할을 할 수 있다. 우리가 아는한, 고객 device 들에 RLHF 훈련을 지원하는 방법은 첫 번째 이다.
Distributed Training
distributed training 을 위해 trainers 를 DeepSpeed 와 결합할 수 있다. DeepSpeed ZeRO optimizer 를 활용하여 partitioning 또는 offloading 을 통해서 memory 소비를 더 줄일 수 있다. DeepSpeed video
3.4 Utilities
Accelerated Inference
inference 시간 동안 data worker 의 chat template 을 재사용하여 모델에 입력을 만든다. stream 디코딩을 지원하는 두 트랜스포머와 vLLM 를 사용하여 모델 출력 샘플 을 지원한다.
- Efficient Memory Management for Large Language Model Serving with PagedAttention paper-link
추가적으로 비동기식 LLM 엔진과 vLLM 의 paged 어텐션을 활용하여 높은 처리량의 동시 추론 서비스들을 제공하는 OpenAI 스타일 API 를 구현하여 fine tune 된 LLMs 를 다양한 어플리케이션들에 용이하게 배포할 수 있다.
Comprehensive Evaluation
BLEU-4 와 ROUGE 와 같은 text 유사성 점수 계산을 할 뿐 아니라
- BLEU: a Method for Automatic Evaluation of Machine Translation paper-link
- ROUGE: A Package for Automatic Evaluation of Summaries paper-link
MMLU, CMMLU, C-Eval 과 같은 choice tasks (선택 작업) 을 포함하여 LLMs 를 평가하기 위한 여러 개의 metric 들도 포함된다.
- MMLU: Measuring Massive Multitask Language Understanding paper-link
- CMMLU: Measuring massive multitask language understanding in Chinese paper-link
- C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models paper-link
3.5 LlamaBoard : A Unified Interface for LlamaFactory
LlamaBoard 는 어떠한 코딩 없이 LLMs 의 fine-tuning 을 customize 하기 위한 Gradio 기반에 통합 사용자 인터페이스이다.
- Gradio: Hassle-Free Sharing and Testing of ML Models in the Wild paper-link, Gradio
간결한 모델 fine-tuning 과 inference 서비스를 제공하여 사용자가 그들의 practice 에서 100 개 이상의 LLMs 와 50+ 개 이상의 dataset 를 쉽게 활용할 수 있도록 한다. LlamaBoard 는 아래와 같은 주목할 만한 특징을 가지고 있다.
Easy Configuration
Llama Board 는 web interface 로 상호작용을 통해 유저들이 fine-tuning 설정 값을 customize 할 수 있다. 많은 유저들로 추천되는 설정 값들에 대해서 default 값들로 제공하여 프로세스의 설정을 단순화 한다. 게다가 사용자들은 웹UI 에서 데이터셋 들을 미리보고 customized 포맷을 확인할 수 있다.
Monitorable Training
프로세스가 training 하는 동안, 사용자가 training 과정을 모니터링 할 수 있도록 training 로그들과 loss 커브들을 실시간으로 업데이트하고 시각화된다. 이 특징은 fine-tuning 과정을 분석하기 위한 가치있는 insights 를 제공한다.
Flexible Evaluation
Llama Board 는 데이터셋 들의 text 유사도 점수 계산을 지원하여, 모델을 자동적으로 평가하거나, 모델과의 채팅을 해서 인간 평가를 수행한다.
Multilingual Support
Llama Board 는 인터페이스 랜더링을 위해서 새로운 언어들의 통합을 가능하게 하고, 현지화 ( localization ) 파일들을 제공한다. 현재 영어, 러시아와 중국, 더 넓은 범위의 사용자들이 fine-tuning LLMs 을 위해서 Llama Board 를 활용할 수 있다.
4. Empirical Study
2 가지 관점 (perspective) 으로부터 Llama Factory 를 체계적으로 평가한다.
- 메모리 사용량, 처리량 (throughput), 그리고 복잡성의 측면에서의 training 효율성.
- downstream 작업들에 대한 adaptation 의 효율성.
4.1 Training Efficiency
Experimental Setup
3천 6백만 이상의 생물학적 문헌의 기록으로 구성된(comprises) PubMed 데이터 셋을 활용한다. (Doc) NCBI - WWW Error Blocked Diagnostic
training 예시를 구성하기 위해서 문헌의 abstract 로부터 약 400,000 개의 토큰을 추출한다. 다양하고 효율적인 fine-tuning 방법들을 갖춘 생성 pre-training 을 사용하여 Gemma-2B, Llama2-7B, Llama2-13B 를 fine-tune 하였다. full-tuning, freeze-tuning, GaLore, LoRA 와 4-bit QLoRA 의 결과를 비교하였다. fine-tuning 후에 다른 방법들의 효율성을 평가하기 위해서 traning 예시로 perplexity 를 계산했다. pre-trained 모델들의 perplexities 를 기준선으로써 통합한다.
Result
Llama Factory 에서 다른 fine-tuning 방법들을 사용하여 training 효율을 비교한다. 각 모델들의 GaLore, LoRA 와 QLora 마다 가장 최고의 결과의 모델을 bold 체를 사용했다.
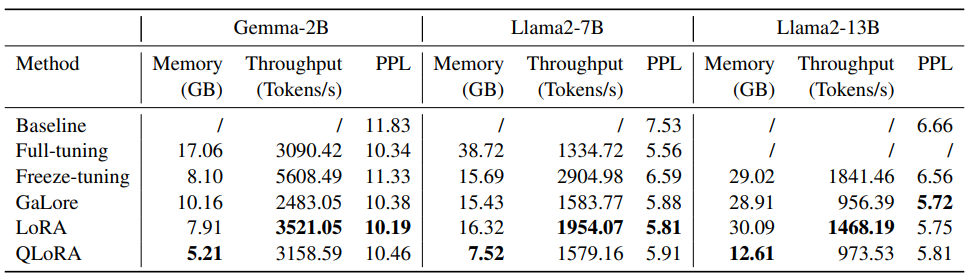
메모리 는 훈련하는 동안 소비되는 peak 메모리를 나타내고, 처리량은 초당 훈련된 token 의 수로 계산되고, PPL 은 training 예제에 대한 복잡성을 나타낸다. full-tuning Llama2-13B 는 메모리 overflow 가 발생하여 결과를 기록하지 않았다.
pre-trained 가중치가 낮은 precision 으로 표현되기 때문에 QLoRA 가 지속적으로 낮은 메모리를 갖는다는 것을 확했다. Unsloth 에 의해 LoRA layer 의 최적화를 활용하여 더 높은 처리량을 나타낸다. GaLore 는 큰 모델에서 낮는 PPL 을 달성하고, 작은 모델에서는 LoRA 의 이점을 달성한다.
4.2 Fine-Tuning on Downstream Tasks
Experimental Setup
다른 효과적인 fine-tuning 방법들의 효과를 평가하기 위해서, downstream tasks 로 fine-tuning 한 후에 다양한 모델들의 성능을 비교한다. 다양한 fine-tuning 방법들의 효율성을 평가하기 위해, 사용되는 데이터 셋 들에 대해 간단히 설명한다. 3 가지 대표적인 text 생성 task 들
-
CNN (Cable News Network) /DM (Daily Mail)
Abstractive Text Summarization Using Sequence-to-Sequence RNNs and Beyond paper-link- 4.3 CNN/Daily Mail Corpus 참조.
이 데이터 셋은 summary generation 태스크에 사용된다. CNN 으로부터 모은 영어 기사들과 Daily Mail 이다. 전체 30만개 이상의 샘플인 version 1.0.0 을 활용한다.
-
XSum (Extreme Summarization)
Don't Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization paper-link- The XSum Dataset 참조.
이 데이터 셋은 추상적인 summary generation 태스크에 사용된다. 전체 20 만개 이상의 영어 문서들과 한문장 요약들로 구성되어 있다.
-
AdGen (Advertising Text Generation)
Long and Diverse Text Generation with Planning-based Hierarchical Variational Model paper-link
- 5.1 Advertising Text Generation 참조.
이 데이서 셋은 모델이 주어진 키워드를 기반으로 광고 텍스트를 생성하기 위해 요구되는 10 만개 이상의 중국 데이터 셋이다.
각각 포함하여 2,000 개의 training set 예시와 1,000 개의 test set 예시를 구성한다. 여러 개의 "instruction-tune" 된 모델들을 선택하고, 다양한 fine-tuning 방법들을 사용하여 "sequence-to-sequence" 작업을에 따라서 fine-tune 을 한다. Full-Tuning 의 결과, GaLore, LoRA 와 4-bit QLoRA 의 결과들을 비교한다. 각 데이터 셋의 테스트 셋으로 ROUGE score 를 계산한다.
-
ROUGE score
ROUGE: A Package for Automatic Evaluation of Summaries www.microsoft.com
또한 원래의 instruction-tune 된 모델의 점수들을 기준선으로써 통합한다.
Results
LlamaFactory 에서 다른 fine-tuning 방법들을 사용하여 특정 tasks 에서 성능 ( ROUGE 를 기준으로 : in terms of ROUGE ) 을 비교 한다.

각 모델의 best 결과는 밑줄을 쳤고, 각 task 의 best 결과는 bold 체를 사용했다.각 dataset 의 downstream tasks 의 평가 결과를 보여준다. 각 LLM 과 데이터들에 대해 ROUGE-1, ROUGE-2, 그리고 ROUGE-L 의 점수를 평균내었다. GaLore 방법은 Gemma-7B 모델에 적용되지 않기 때문에 몇몇 결과들은 위 평가 결과에 포함하지 않는다.
결과에 가장 흥미로운 점은, LoRA 와 QLoRA 가 CNN/DM 과 AdGen 데이터셋들에서 Llama2-7B 와 ChatGLM3-6B 를 제외하고 대부분의 경우에서 가장 좋은 성능을 달성했다는 것이다. 이 현상은 특정 작업에서 LLM model 들을 적용할 때 이들과 같은 효율적인 fine-tuning 방법들의 효율성을 강조한다.
추가적으로 Mistral-7B 는 영어 데이터셋들에 더 좋은 성능을 보이는 반면, Qwen1.5-7B 모델은 중국 데이터 셋들에 높은 점수를 달성한다. 이 결과들은 fine-tune 된 모델들의 성능이 특정 언어의 고유한 능력 (inherent capabilities) 과도 연관이 되어 있음을 제시한다.
(Appendix) D. Experiment Details
D.1 Training Efficiency
memory foot print 를 줄이기 위해서 활성화 체크포인트? ( activation checkpoint ) 를 더불어 bfloat16 precision 에서 8-bit AdamW optimizer 를 사용하여 이 모델들을 fine-tune 하기 위해 learning rate 와 512 batch size 로 채택하였다.
- 8-bit Optimizers via Block-wise Quantization paper-link
freeze-tuning 에서는 모델의 마지막 3 개 decoder layer 만 미세 조정하였다. GaLore 에서는 rank 와 scale 을 128 과 2.0 으로 각각 (respectively) 설정하였다. For LoRA 와 QLorA 의 경우에는 모든 linear layers 에 adapters 를 연결하고, rank 와 alpha 를 128, 256 으로 설정한다. 모든 실험들은 a single NVIDIA A100 40GB GPU 로 돌린다. LoRA 와 QLoRa 를 위한 all experiments 와 Unsloth 에서 flash attention 을 활성화하였다.
D.2 Fine-Tuning on Downstream Tasks
이 실험에서 learning rate 은 를 채택한다. 최대 입력 크기를 2048, 배치 사이즈를 4 로 설정한다. fine-tuning model 은 memory foot print 를 줄이기 위해서 활성화 체크포인트? ( activation checkpoint ) 를 더불어 bfloat16 precision 에서 8-bit AdamW optimizer 를 사용한다.
GaLore 에서는 rank 와 scale 을 128 과 2.0 으로 각각 (respectively) 설정하였다. For LoRA 와 QLorA 의 경우에는 모든 linear layers 에 adapters 를 연결하고, rank 와 alpha 를 128, 256 으로 설정한다. 모든 실험들은 a single NVIDIA A100 40GB GPU 로 수행 가능하고, all experiments 에서 flash attention 을 활성화하였다.
