Attention Is All You Need (paper)
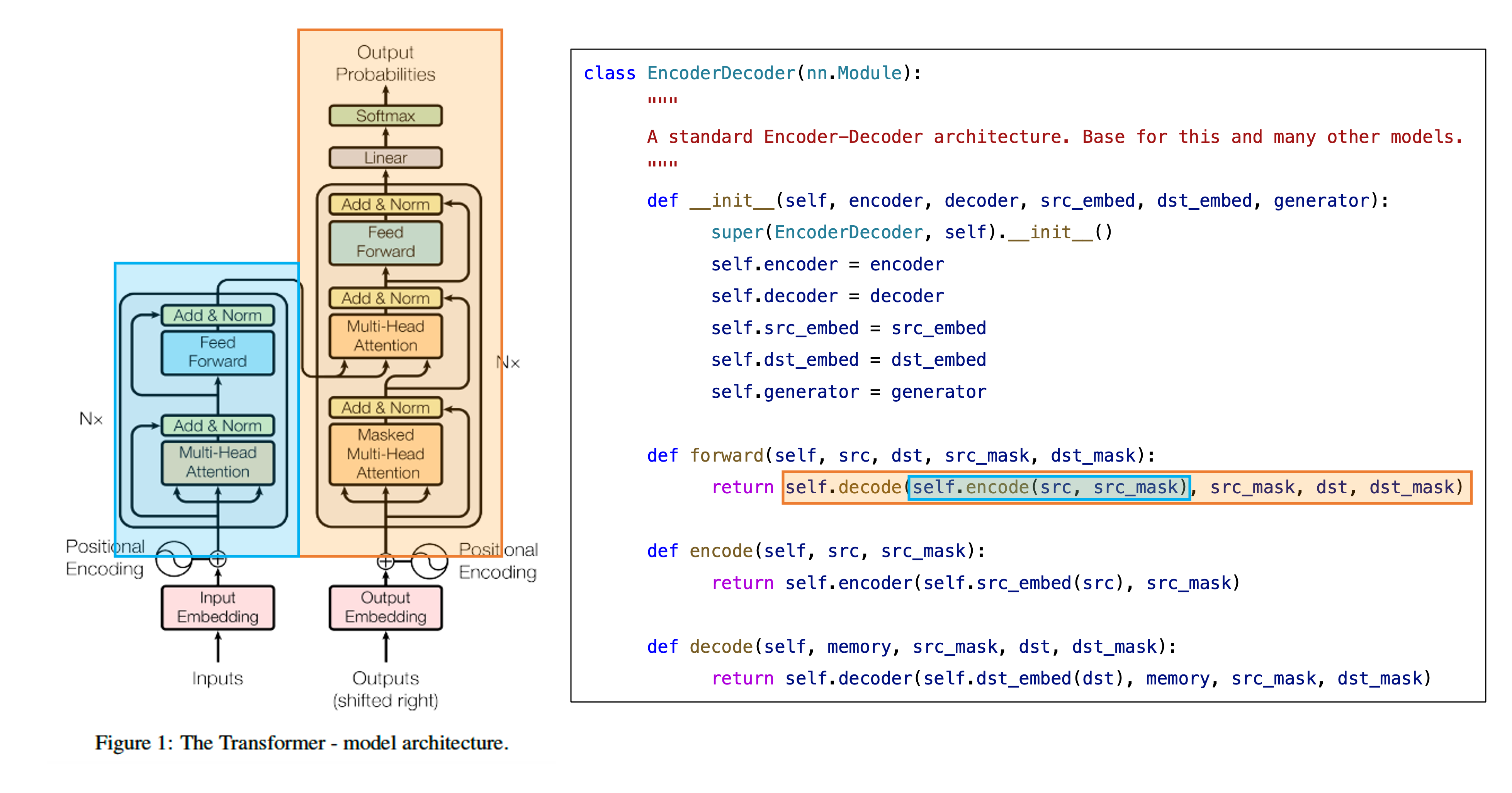
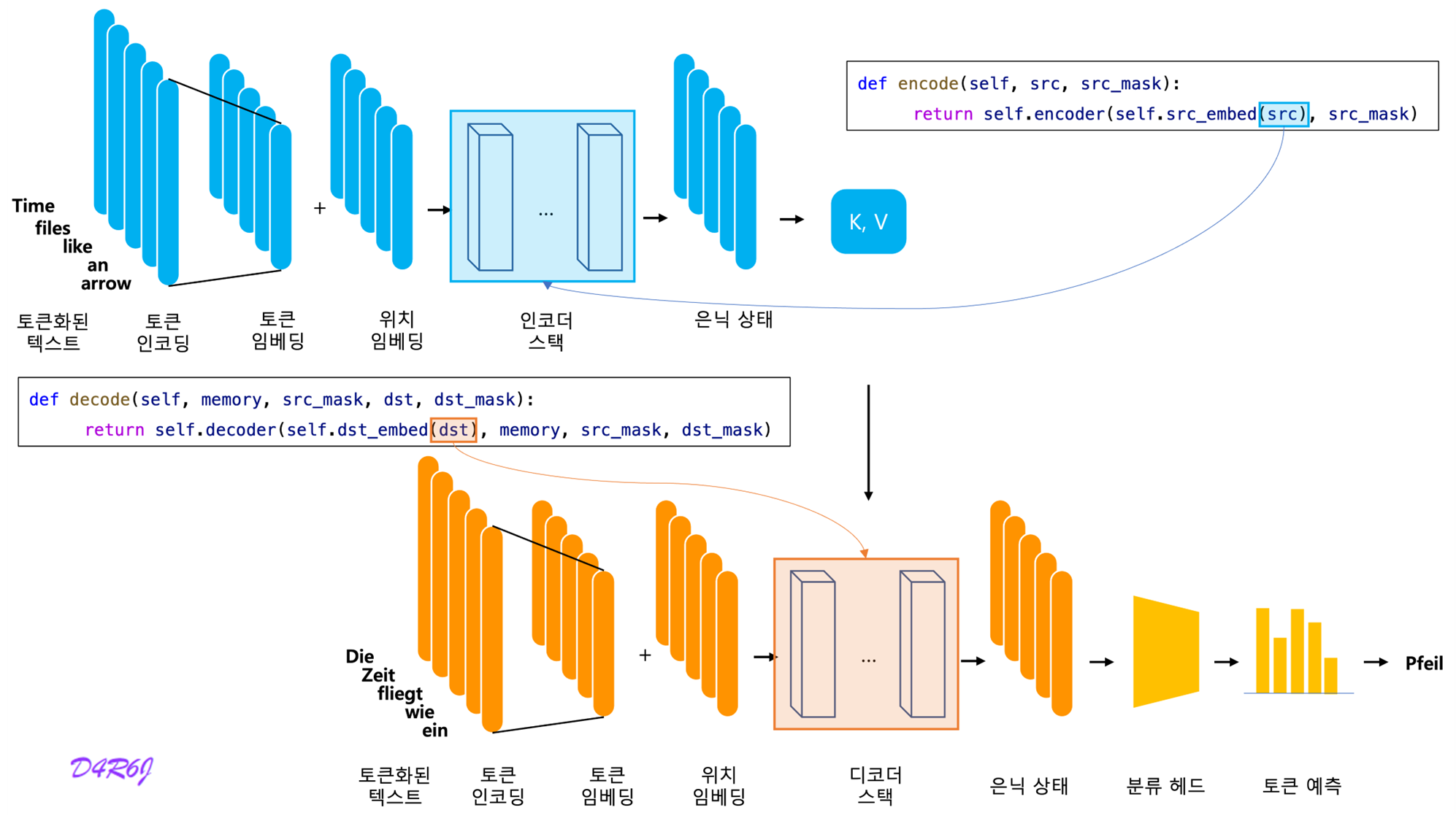
1. Model Architecture
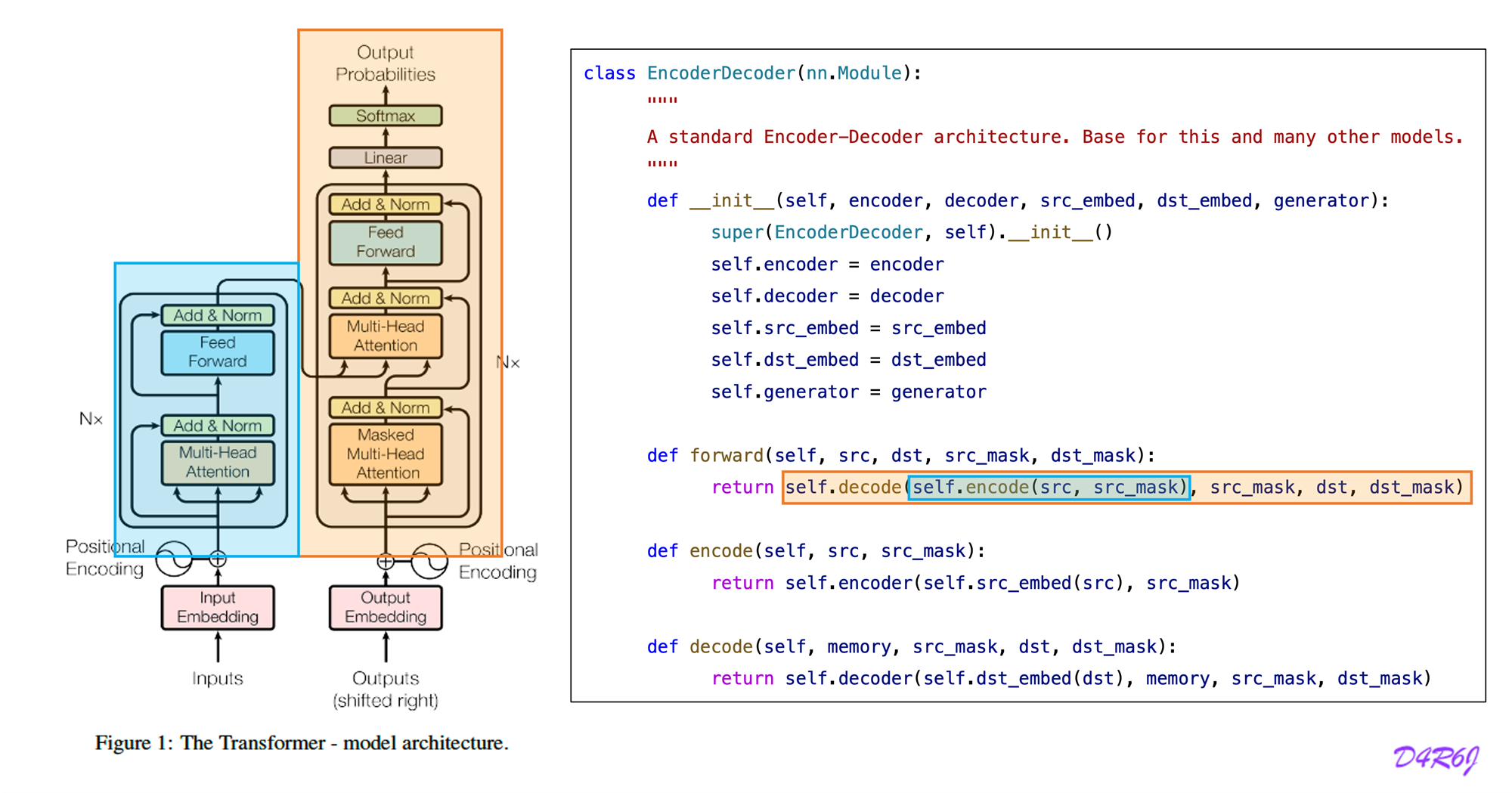
- Input sequence of symbol representation
- sequence of continuous representations
- Given , the decoder then generate an output sequence
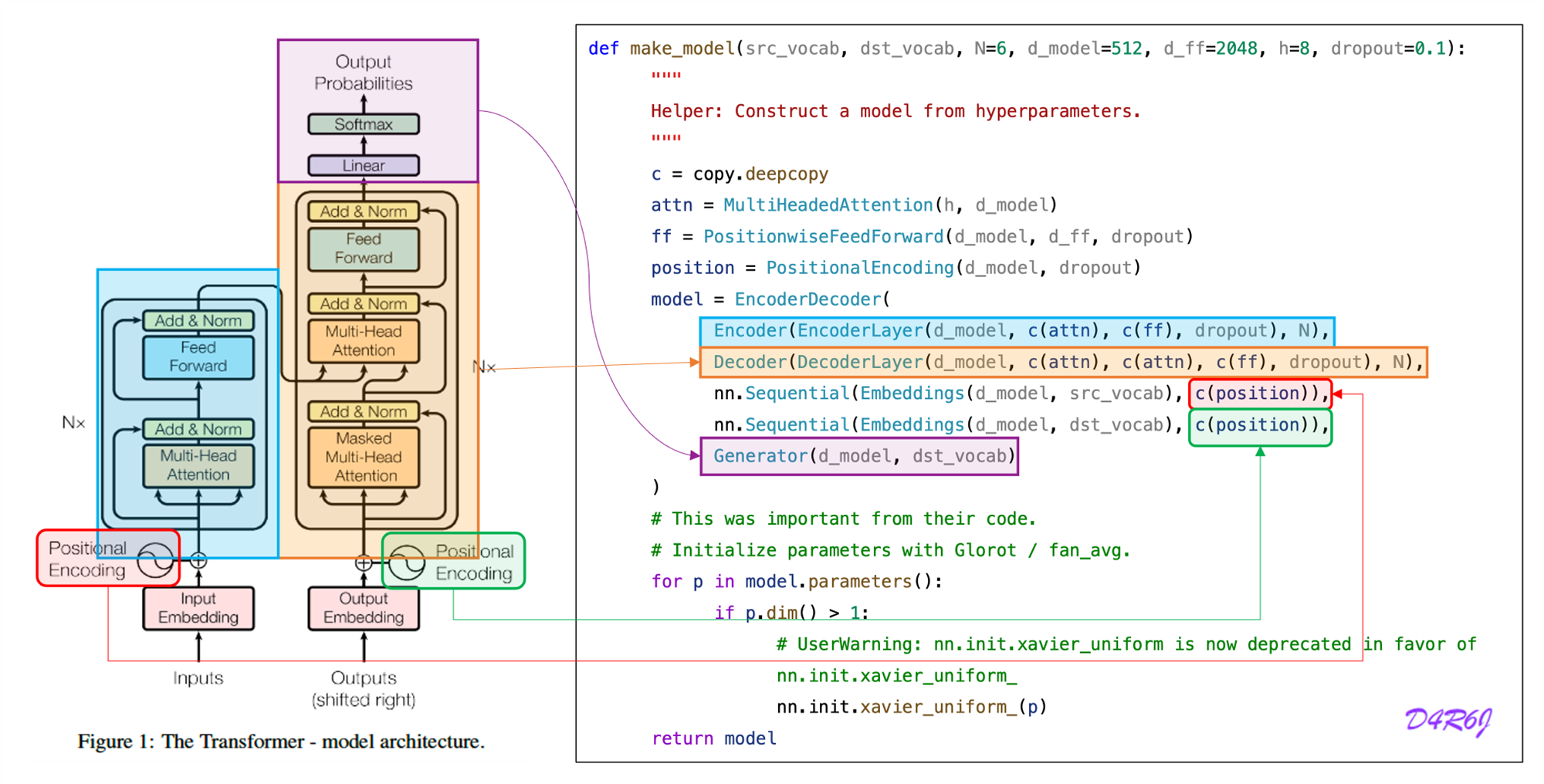
2. Encoder and Decoder Stacks
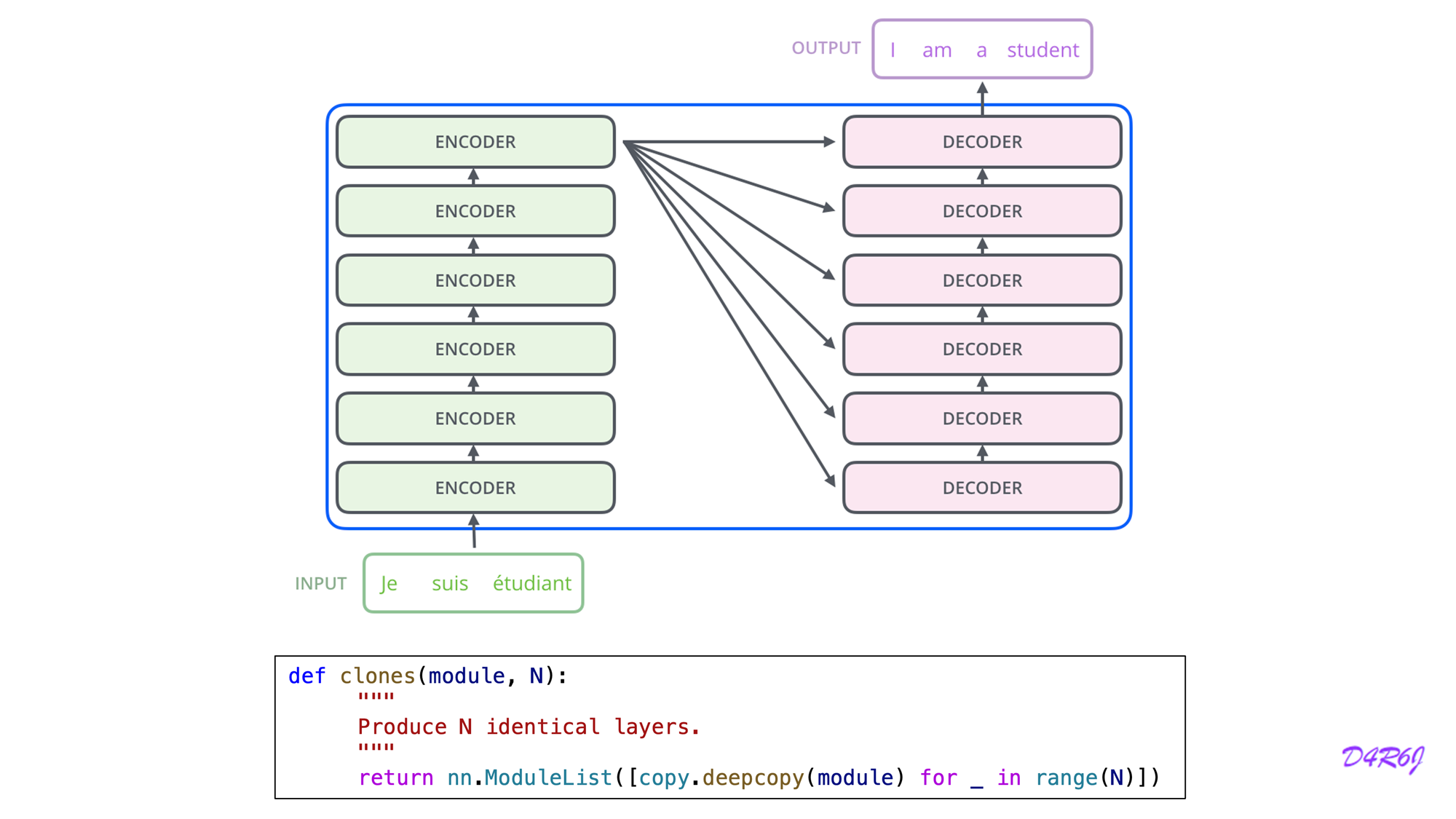
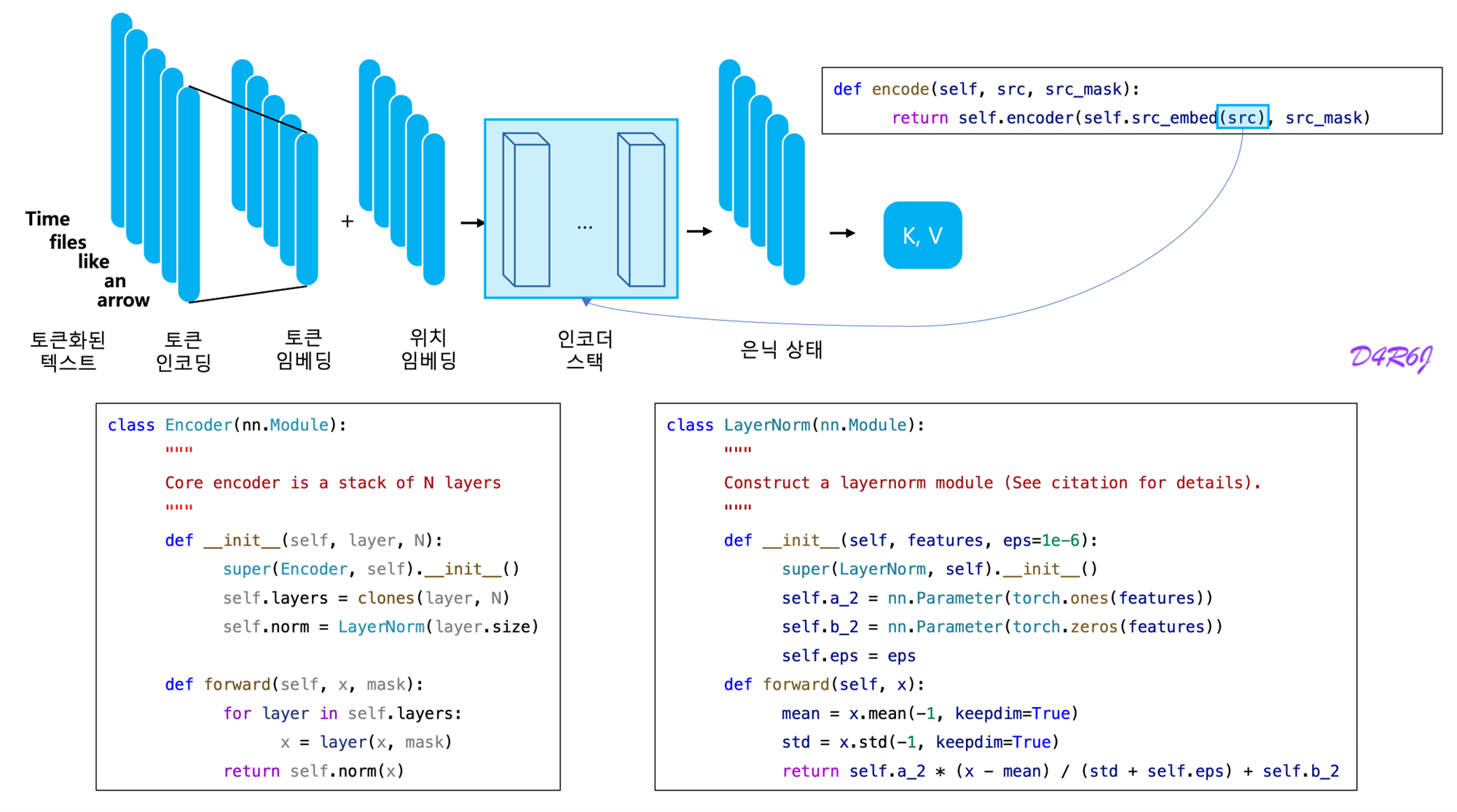
2-1. Encoder
- Encoder is composed of a stack of identical layers.
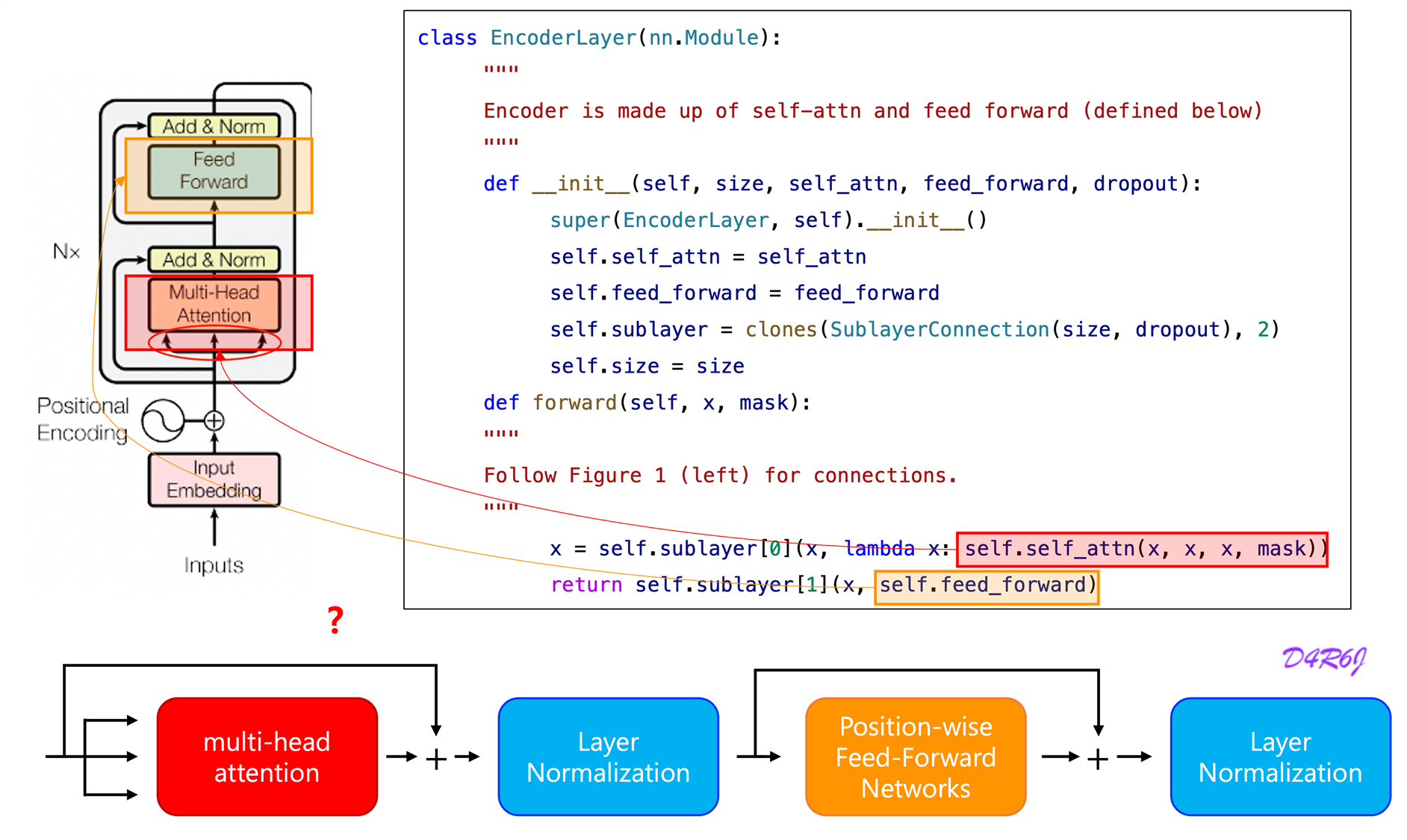
- A multi-head self-attention mechanism.
- simple, position-wise fully connected feed-forward network.
- Residual connection around each of the two sub-layers, followed by layer normalization.
- The output of each sub-layer is
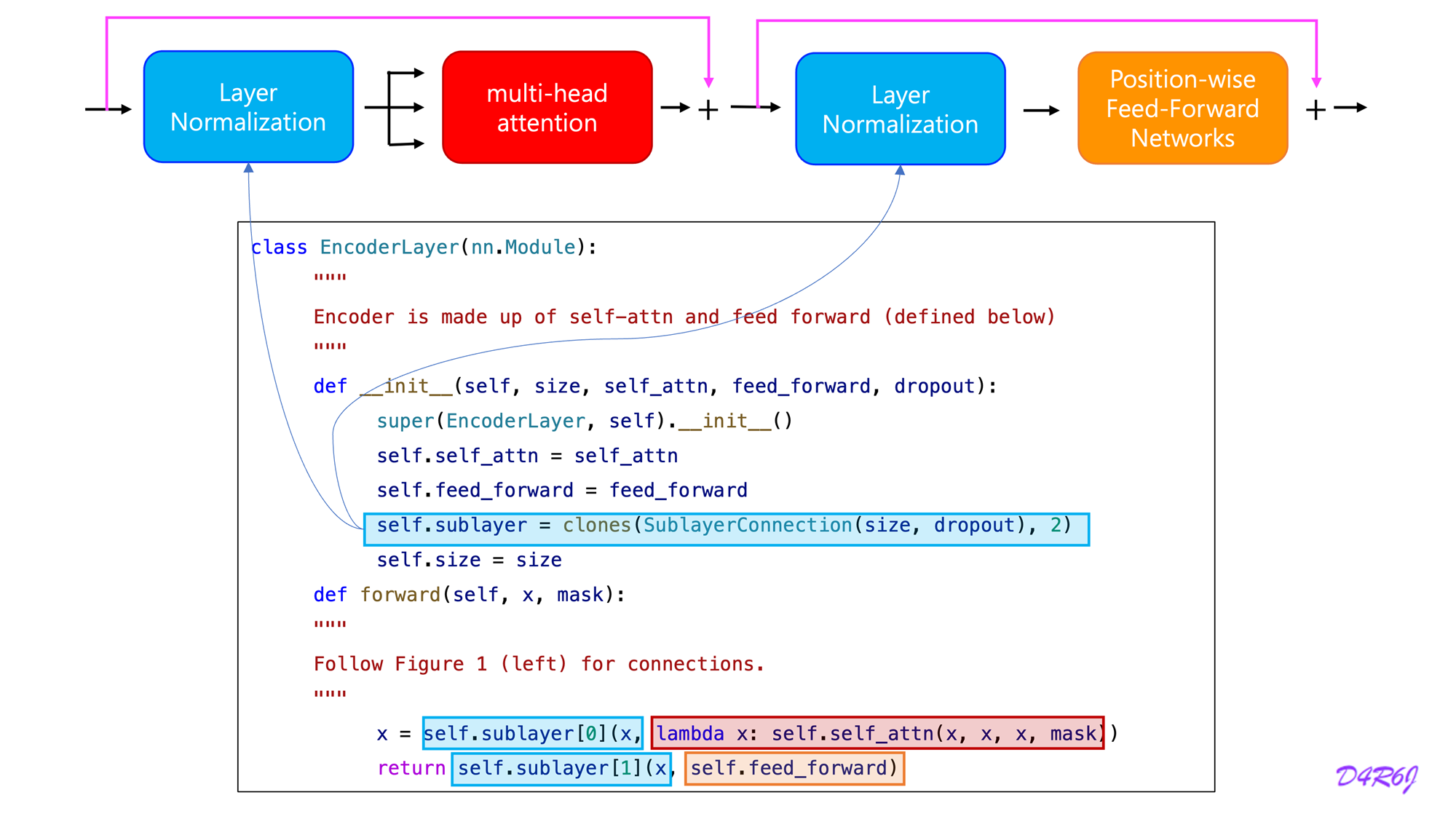
- To facilitate these residual connections, all sub-layers in the model, as well as the embedding layers, produce outputs of dimension
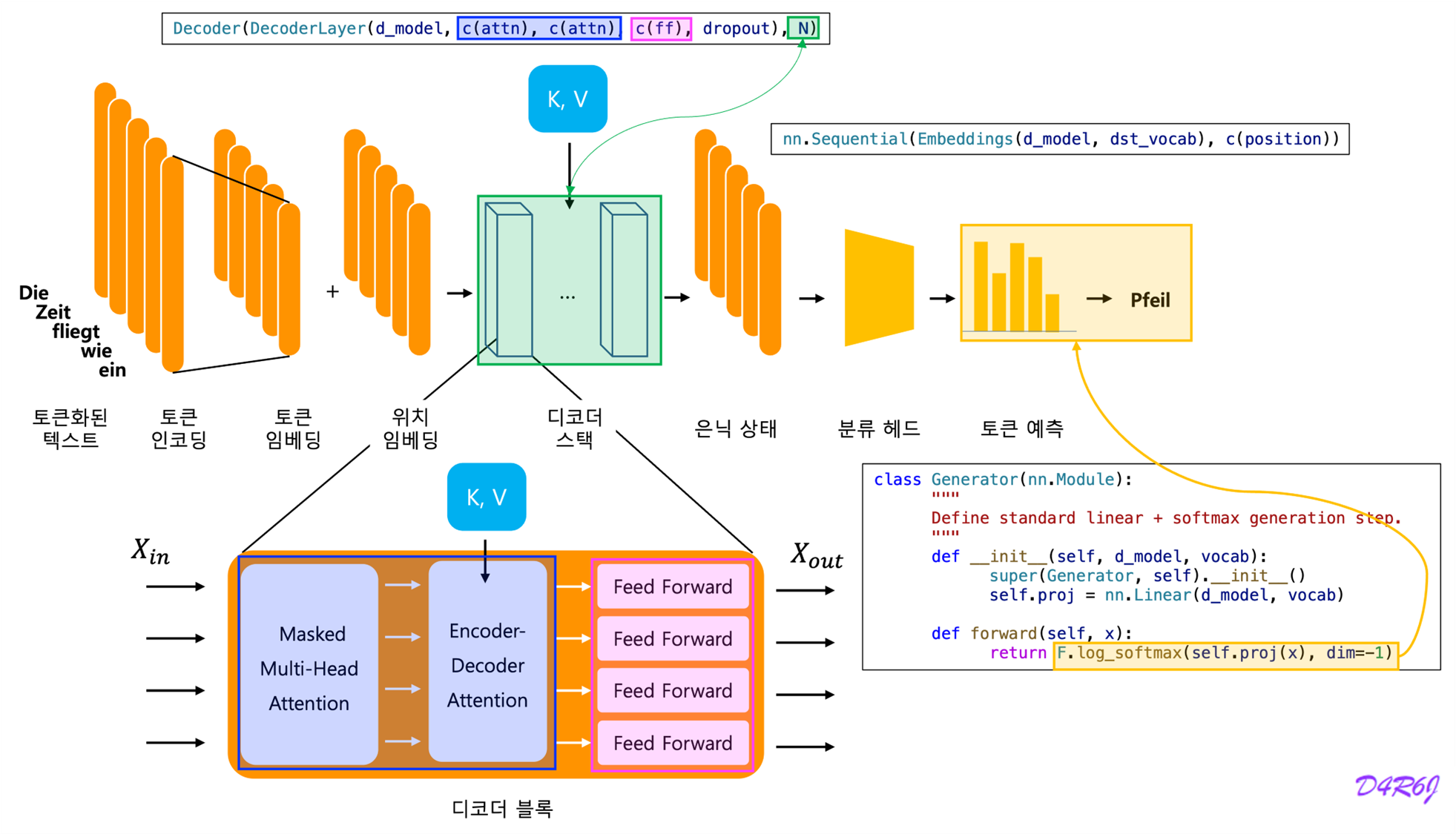
2-2. Decoder
- Decoder is also composed of a stack of identical layers.

- The decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack.
- This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position can depend only on the known outputs at positions less than .

3. Attention
- An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors.
- The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
3-1. Scaled Dot-Product Attention
- The queries simultaneously, packed together into a matrix .
- The keys and values are also packed together into matrices and .
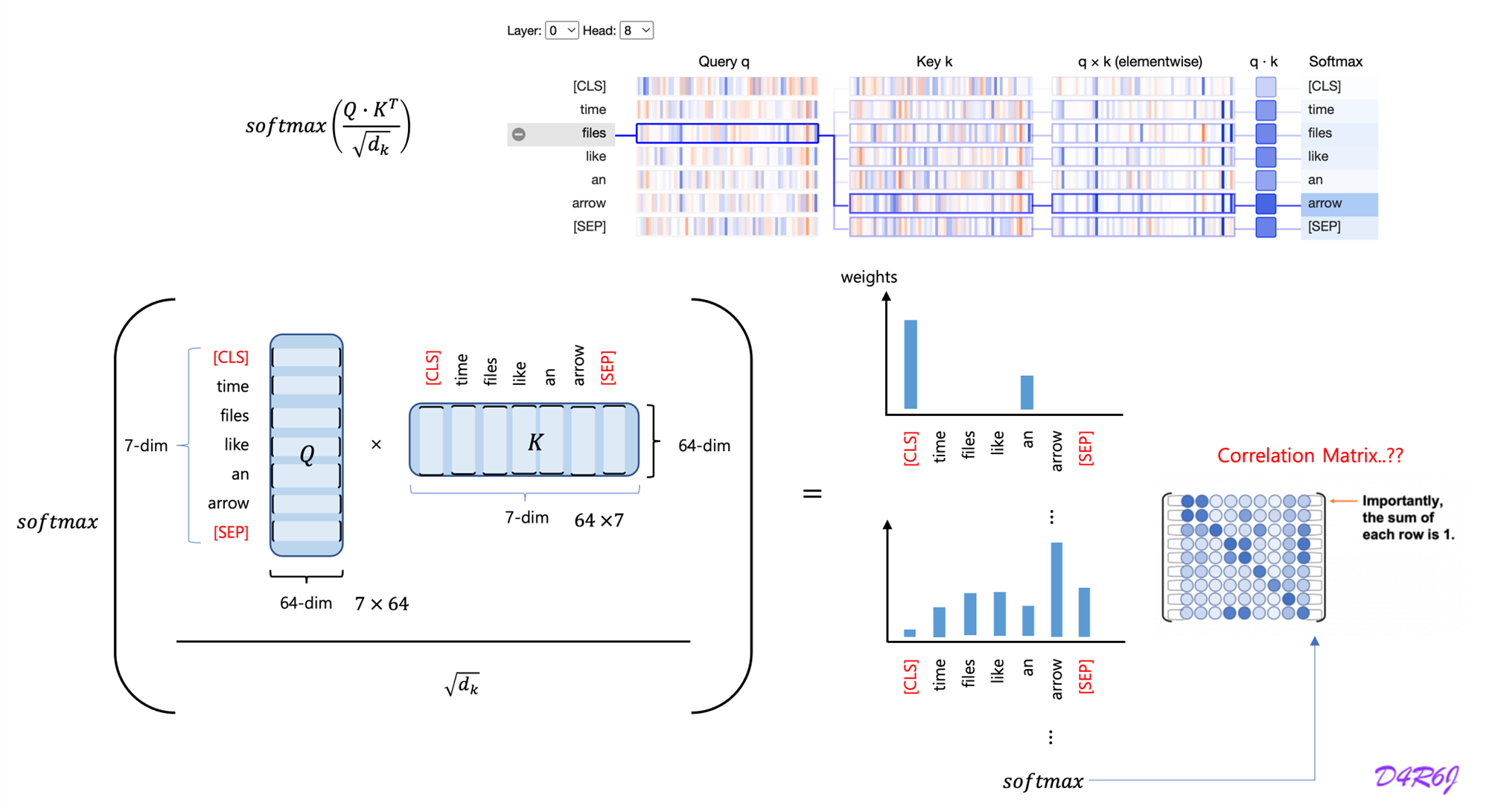
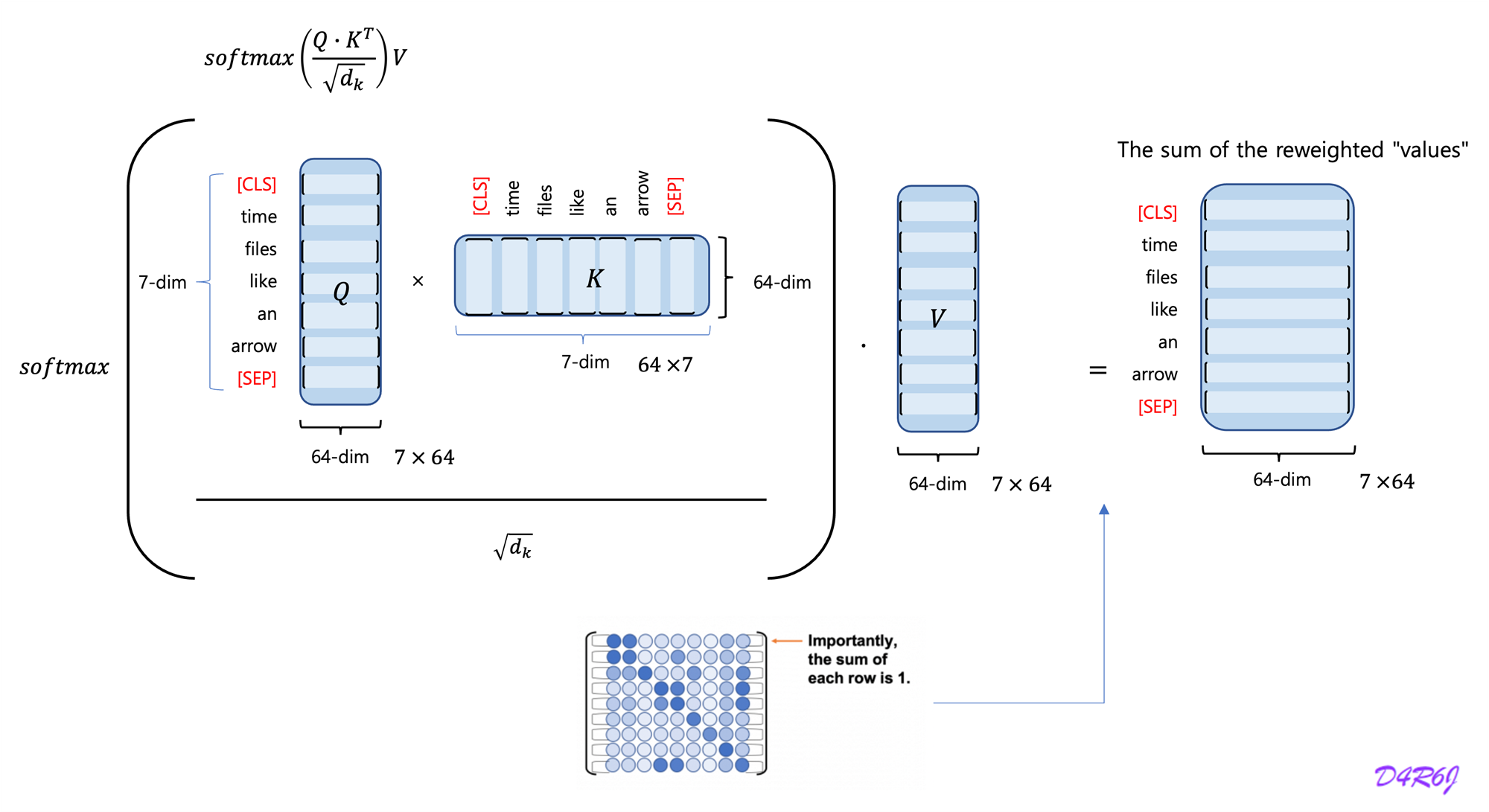
-
Large values of , the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients.to counteract this effect, we scale the dot products by
-
To illustrate why the dot products get large, assume that the components of and are independent random variables with mean and variance . Then their dot product, , has mean and variance .

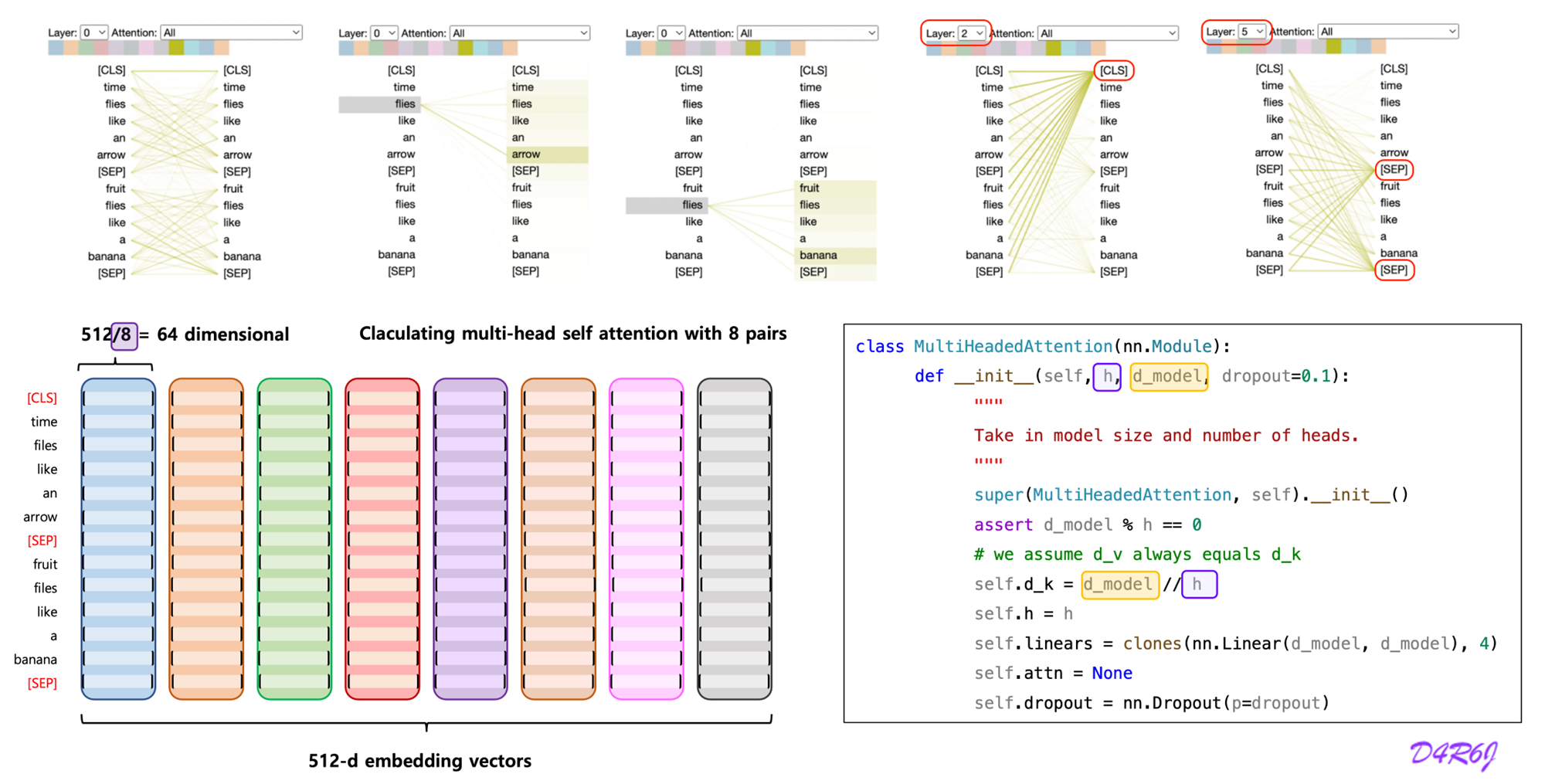
3-2. Multi-Head Attention
Multi-head attention allows the model to jointly attend to information from different representation subspace at different positions. with a single attention head, averaging inhibits this.
Where the projections are parameter matrices
and

In this work we employ parallel attention layers, or heads. For each of these we use Due to the reduced dimension of each head, the total computational cost is similar to that of single-head attention with full dimensionality.
4. Position-wise Feed-Forward Networks
In addition to attention sub-layers, each of the layers in our encoder and decoder contains a fully connected feed-forward network, which is applied to each position separately and identically . This consists of two linear transformations with a ReLU activation in between.
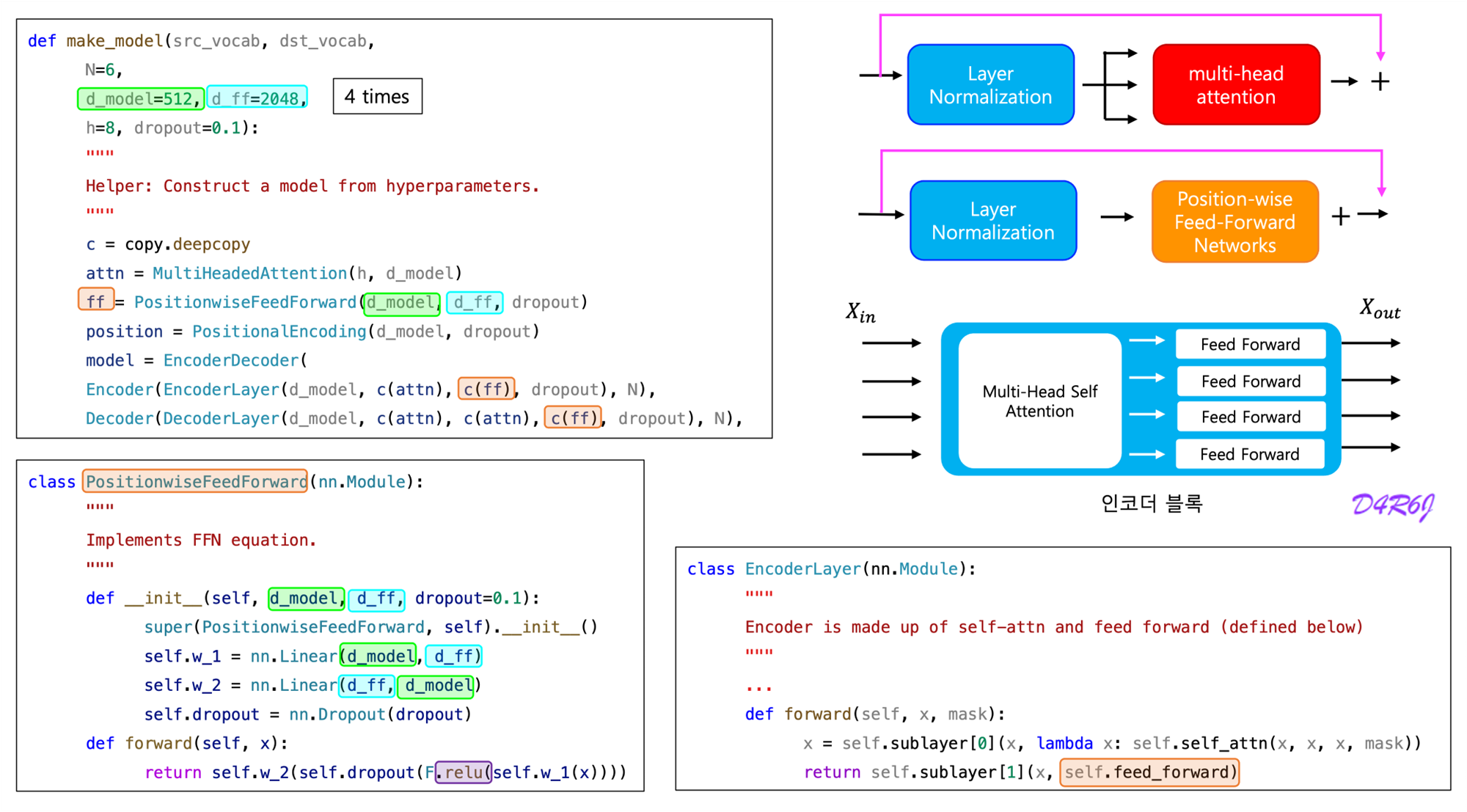
While the linear transformations are the same across different positions, they use different parameters from layer to layer. Another way of describing this is as two convolutions with kernel size . The dimensionality of input and output is and the inner-layer has dimensionality
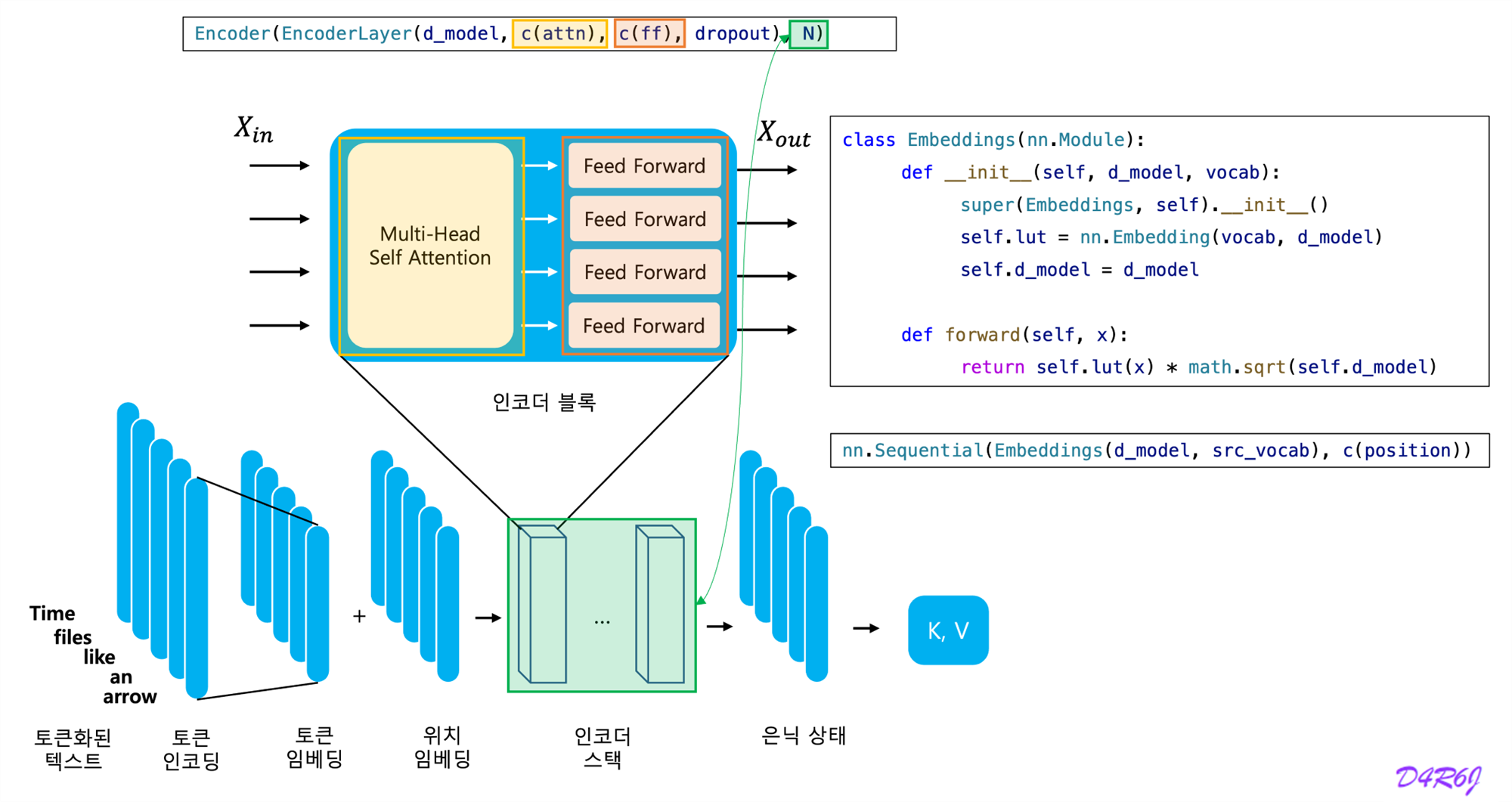
5. Embeddings and Softmax
-
learned embeddings to convert tokens and output tokens to vectors of dimension
-
The usual learned linear transformation and softmax function to convert the decoder output to predicted next-token probabilities.
-
share the same weight matrix between the two embedding layers and the pre-softmax linear transformation, similar to..

6. Positional Encoding
Since our model contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, we must inject some information about the relative or absolute position of the tokens in the sequence.
In this work, we use sine and cosine functions of different frequencies:
We chose this function because we hypothesized it would allow the model to easily learn to attend by relative positions, since for any fixed offset can be represented as a linear function of

7. Full Model