input image
| Tasks | size (pixels) | datasets |
|---|---|---|
| Detection | 640 | COCO |
| Detection | 640 | Image V7 |
| Segmentation | 640 | COCO |
| Pose | 640 | COCO |
| OBB | 1024 | DOTAv1 |
| Classification | 224 | ImageNet |
classification
class ClassificationTrainer(BaseTrainer):
def __init__(self, cfg=DEFAULT_CFG, overrides=None, _callbacks=None):
if overrides is None:
overrides = {}
overrides["task"] = "classify"
if overrides.get("imgsz") is None:
overrides["imgsz"] = 224
super().__init__(cfg, overrides, _callbacks)
overrides["imgsz"] = 224
detection
class DetectionTrainer(BaseTrainer):
def build_dataset(self, img_path, mode="train", batch=None):
gs = max(int(de_parallel(self.model).stride.max() if self.model else 0), 32)
return build_yolo_dataset(
self.args,
img_path,
batch,
self.data,
mode=mode,
rect=mode == "val",
stride=gs
)
...# data.build
def build_yolo_dataset(cfg,
img_path,
batch,
data,
mode="train",
rect=False,
stride=32,
multi_modal=False):
"""Build YOLO Dataset."""
dataset = YOLOMultiModalDataset if multi_modal else YOLODataset
...# YOLODataset : yolo.detect.DetectionTrainer
class YOLODataset(BaseDataset):
...
class BaseDataset(Dataset):
"""
imgsz (int, optional): Image size. Defaults to 640.
"""
def __init__(
self,
img_path,
imgsz=640,
...imgsz=640
remaining tasks
# segmentation
class SegmentationTrainer(yolo.detect.DetectionTrainer):
# pose
class PoseTrainer(yolo.detect.DetectionTrainer):
# OBB
class OBBTrainer(yolo.detect.DetectionTrainer):
inheritance yolo.detect.DetectionTrainer
OBB (Oriented Bounding Box) task 의 default input size 는 1024 로 fix 된건 없지만, 학습 시에 설정 된 듯 하다. input image size 는 조절 가능하니.. 일단 넘어는 것으로..
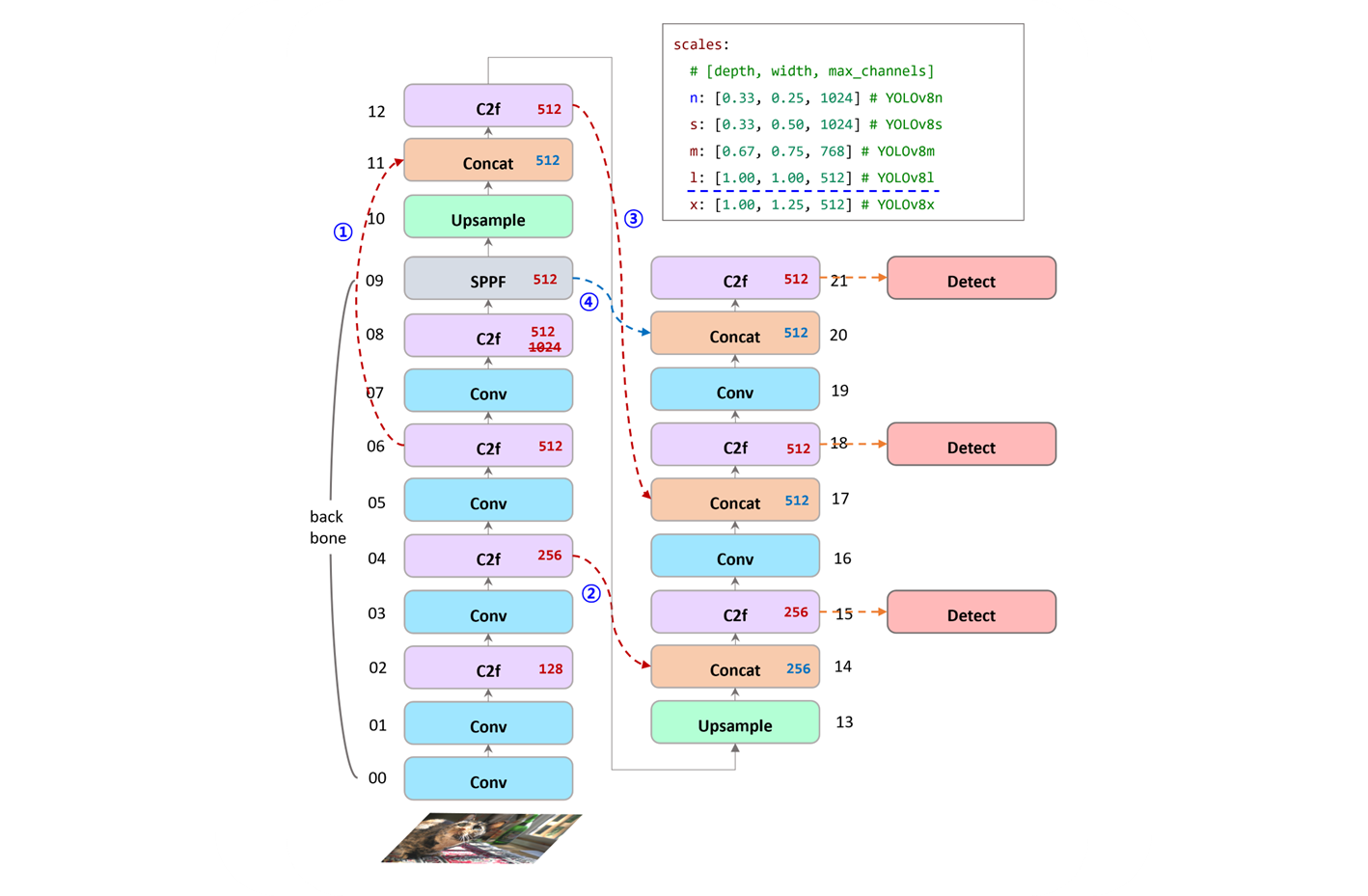
backbone
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9[block] Conv
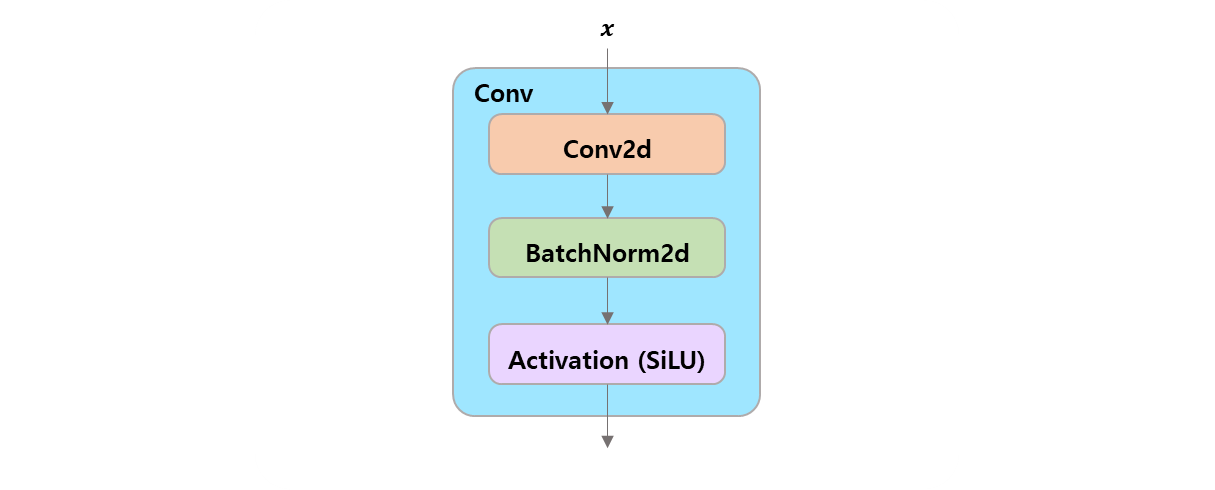
class Conv(nn.Module):
"""
Standard convolution with args(
ch_in, ch_out, kernel, stride, padding, groups, dilation, activation
).
"""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))[block] Bottleneck
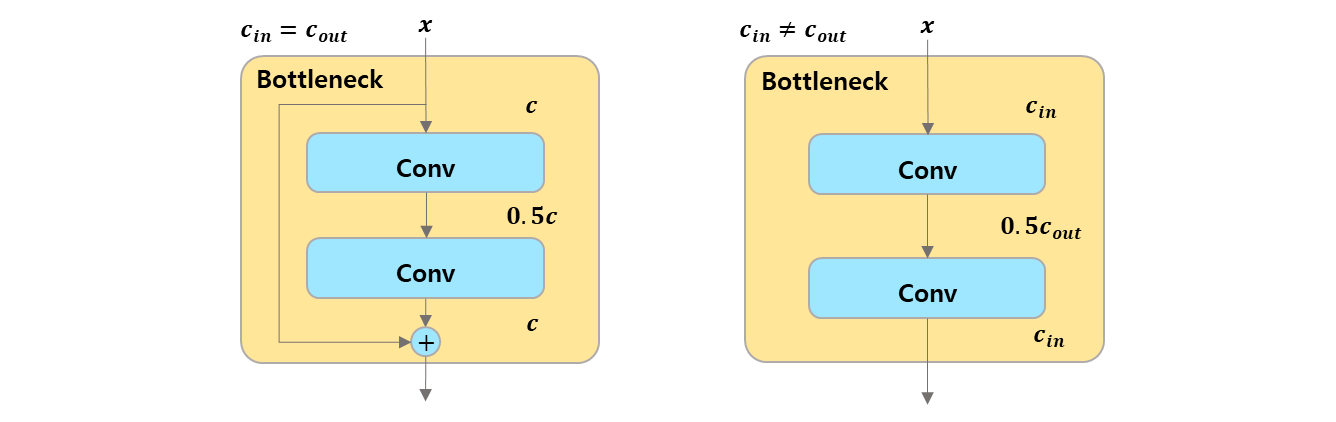
class Bottleneck(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""
Initializes a bottleneck module with given input/output channels, shortcut option,
group, kernels, and expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))[block] C2f
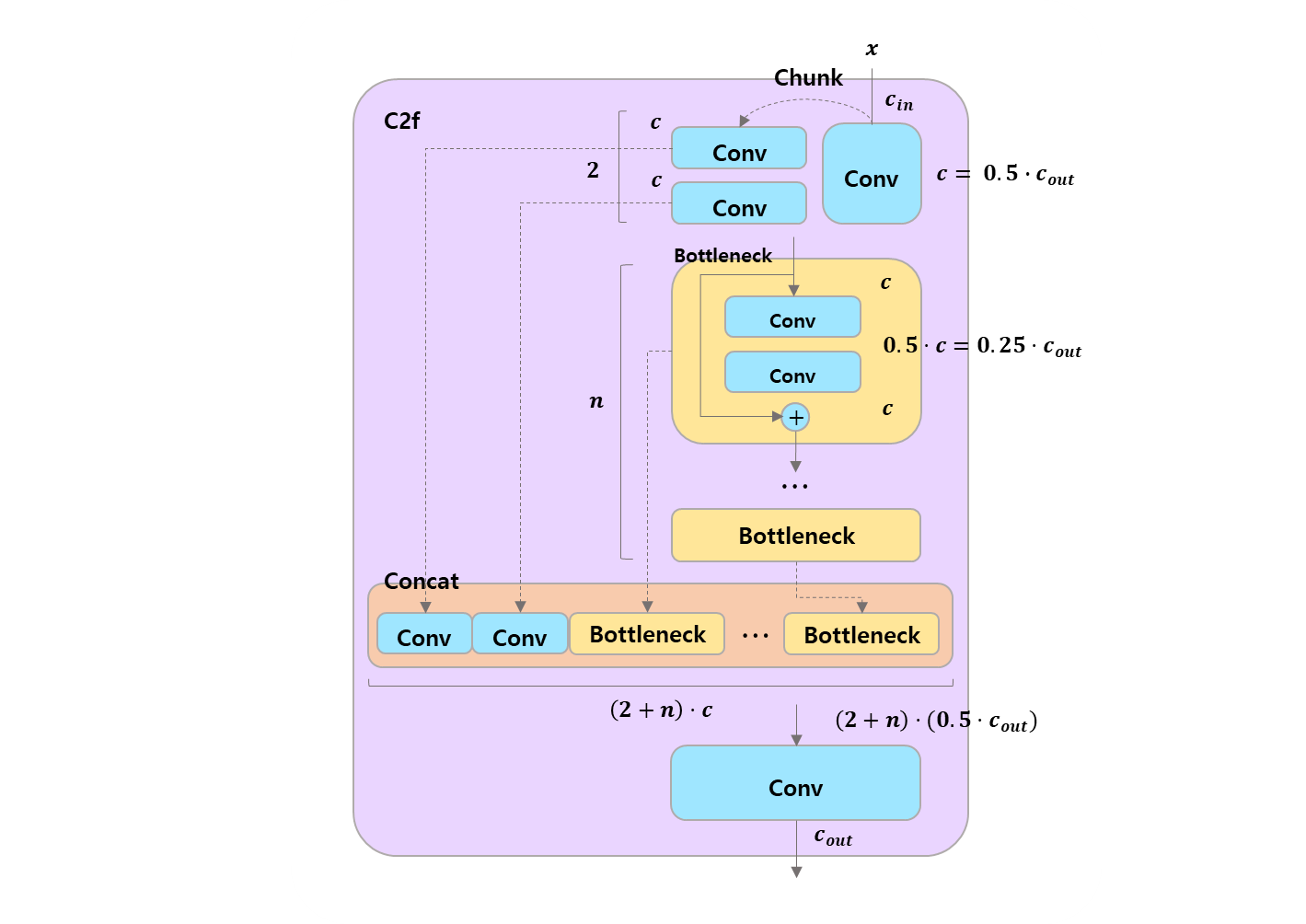
class C2f(nn.Module):
"""
Faster Implementation of CSP Bottleneck with 2 convolutions.
"""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""
Initialize CSP bottleneck layer with two convolutions with arguments
ch_in, ch_out, number, shortcut, groups, expansion.
"""
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(
Bottleneck(
self.c, self.c, shortcut, g, k=((3, 3), (3, 3)
), e=1.0) for _ in range(n)
)
def forward(self, x):
"""Forward pass through C2f layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))optional act=FReLU(c2) 이런 내용은 keep 해두는 것이 좋다.
-
개인적으로 Sigmoid 형태를 가져가는
SiLU와 Gaussian error function 을 이식한GeLU를 좋아하는 편이고,differentiable하고negative value를 가져가는 편이 좋다고 생각한다. -
FReLU가 Flexible Rectified Linear Units 이라면...- FReLU 처럼 음수 값을 가져가면, 으로 누르지 않고 미분 형태를 띠게 해주는 형태가 더 낫지 않나..
FReLU는 좀 아쉬운 부분이 있다. 차라리ReLU를 써서 feature selection 개념으로 날려버리는 것이..
- FReLU 처럼 음수 값을 가져가면, 으로 누르지 않고 미분 형태를 띠게 해주는 형태가 더 낫지 않나..
-
그렇다면, 여기서의
FReLU는 Funnel Activation 이라 생각한다.yolo v5 에 들어있네.. wandb.ai with yolov5
class FReLU(nn.Module): """FReLU activation https://arxiv.org/abs/2007.11824.""" def __init__(self, c1, k=3): # ch_in, kernel """Initializes FReLU activation with channel `c1` and kernel size `k`.""" super().__init__() self.conv = nn.Conv2d(c1, c1, k, 1, 1, groups=c1, bias=False) self.bn = nn.BatchNorm2d(c1) def forward(self, x): """ Applies FReLU activation with max operation between input and BN-convolved input. https://arxiv.org/abs/2007.11824 """ return torch.max(x, self.bn(self.conv(x)))
[block] SPPF
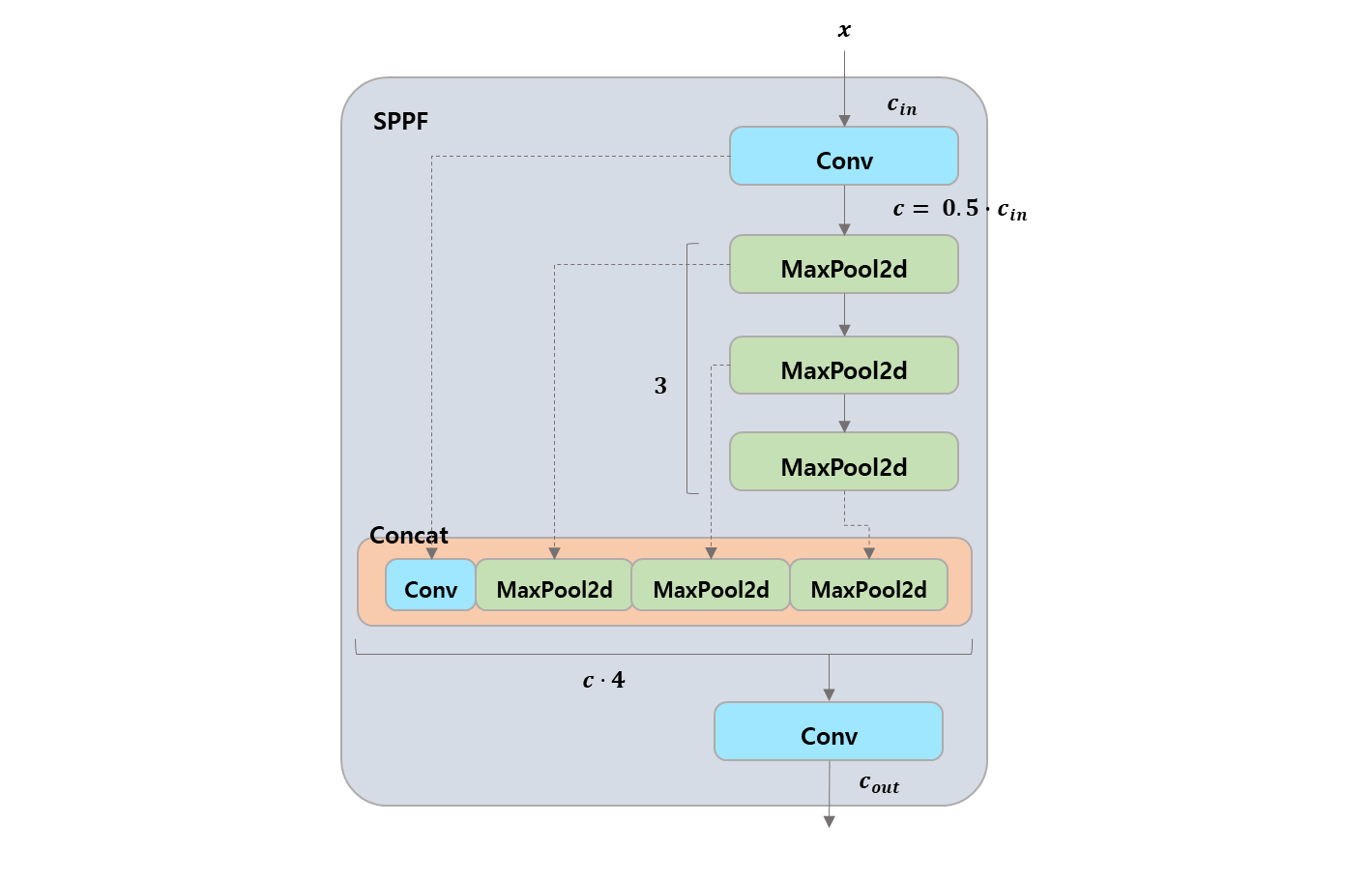
class SPPF(nn.Module):
"""
Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher.
"""
def __init__(self, c1, c2, k=5):
"""
Initializes the SPPF layer with given input/output channels and kernel size.
This module is equivalent to SPP(k=(5, 9, 13)).
"""
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
"""Forward pass through Ghost Convolution block."""
y = [self.cv1(x)]
y.extend(self.m(y[-1]) for _ in range(3))
return self.cv2(torch.cat(y, 1))about these blocks..
Bottleneck으로 compressed data 를 하여 feature 의 중요도를 가져가고,- 이전의 정보를 잃지 않고, block 안의 element matrices 를
ModuleList로 펼쳐서, - channel 을 한대 모아서 concatenation 하여 전체를 Conv 로 합치는 작업을 반복.
결론은
Bottleneck으로 필요한 데이터를 추출하고, 그 당시 학습된 모든 matrices 를 모아서Conv하나로 묶어서 CNN 의 주변 요소들을 잘 가져오려는 방법론으로 느껴진다.
head
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)- 각 layer 들을 유기적으로 연결시켜주는 mapping 의 역할 정도로 볼 수 있다.
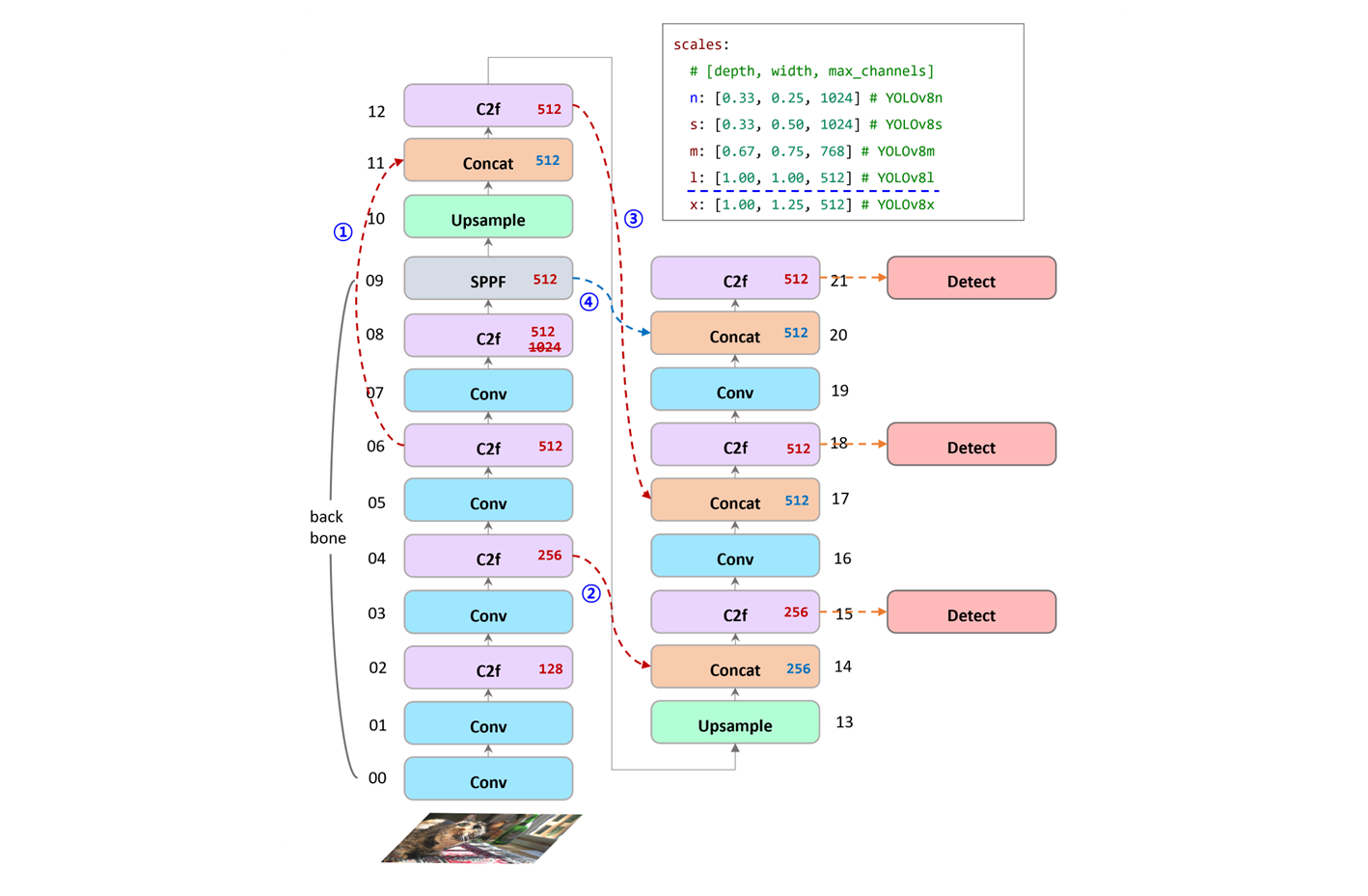
-
특이사항은 설정의
# 7-P5/32, # 21 (P5/32-large)에서 C2f,[1024]로 설정 되었지만,scales "l", "x"설정을 보면 max 가 512 여서 제한에 걸린다. -
backbone :
[00 ~ 09], head :[10 ~ 21]이고, Detect 는 다음 포스트에서 다룰 예정이다. 코드와 내용을 보고, 중요성을 느껴서 따로 분리하는 것이 맞다고 생각했다.
번호의 감각적인 느낌을 설명하자면,
- backbone 에서 4 개의
C2f중 3번째의 block 을 가져와서 잊지 않게 복습 한다. - backbone 에서 4 개의
C2f중 2번째의 block 을 가져와서 초심을 잃지 않는다. - head 에서 배운, 진도가 나아간 내용도 까먹지 않게 복습 한다.
- SPPF 로 backbone 의 마지막 layer 로 3 연속
MaxPool2d한 내용을 마지막C2f전에 데려와서 final part 를 구성한다.
nn.Upsample은 당연히, feature 의 size 를 up 시킬때 사용한다.
result
전체적인 구조를 보고
-
backbone
각 blocks 의 matrices 를 feature reduction 을 잘하면서, feature extraction 를 잘할까? 에 대한 고민이라면..
-
head
깊어진 layers 에 이전 배움을 잊지 않기 위해 이전에 잘 학습된
Cf2를 적절하게 가져와서 까먹지 않게 구조화 한다..
랄까?
next post...
이번 포스트로, 다음으로 넘어가기 전, 적으면 한 번, 많으면 세 번정도 추가될 듯하다. keep 해둔 내용들이 많고, 특히 Detect class 같은 경우는
- DFL (Distribution Focal Loss)
- box, cls 의 구분된 내용과 loss
- anchor box 관련 내용
등 여러모로 더 다뤄 볼 예정이다.
