Visualizing and Understanding Convolutional Networks
Abstract
대형 컨볼루션 네트워크 모델은 최근 ImageNet 벤치마크에서 인상적인 분류 성능을 보여주었다(Krizhevsky et al., 2012).
그러나 그들이 왜 그렇게 좋은 성과를 내는지, 또는 어떻게 그것이 개선될 수 있는지에 대한 명확한 이해는 없다.
이 논문에서 우리는 두 가지 문제를 모두 다룬다.
중간 피처 레이어의 기능과 분류기의 작동에 대한 통찰력을 제공하는 새로운 시각화 기술을 소개한다.
진단 역할에 사용되는 이러한 시각화를 통해 Krizhevsky 등을 능가하는 모델 아키텍처를 찾을 수 있다.
자세한 내용은 ImageNet 분류 벤치마크에서 확인할 수 있습니다.
우리는 또한 다른 모델 계층에서 성능 기여를 발견하기 위해 절제 연구를 수행한다.
우리는 ImageNet 모델이 다른 데이터 세트에 잘 일반화됨을 보여준다.
소프트맥스 분류기가 재교육되면 Caltech-101 및 Caltech-256 데이터 세트에서 최신 결과를 설득력 있게 능가한다.
1. Introduction
1990년대 초 (르쿤 외, 1989년)에 의해 도입된 이후, 컨볼루션 네트워크(콘네트)는 손으로 쓴 숫자 분류와 얼굴 감지와 같은 작업에서 우수한 성능을 보여주었다.
작년에 여러 논문에서 더 까다로운 시각적 분류 작업에서 뛰어난 성능을 제공할 수 있다는 것을 보여주었다. (Ciresan et al., 2012)는 NORB 및 CIFAR-10 데이터 세트에서 최첨단 성능을 보여준다.
가장 주목할 만한 것은 (Krizhevsky et al., 2012)가 ImageNet 2012 분류 벤치마크에서 기록적인 성능을 보여주며, 2위 결과(26.1%)와 비교하여 16.4%의 오류율을 달성하였다.
(i) 수백만 개의 레이블링된 예제로 훨씬 더 큰 훈련 세트의 가용성,
(ii) 강력한 GPU 구현으로 매우 큰 모델의 훈련을 실용적으로 만들고
(iii) 드롭아웃(힌튼 외, 2012)과 같은 더 나은 모델 정규화 전략에 대한 이러한 새로운 관심의 원인이 있다.
이러한 고무적인 진전에도 불구하고, 이러한 복잡한 모델의 내부 작동과 동작, 또는 어떻게 그들이 그렇게 좋은 성능을 달성하는지 아는 것은 아직 거의 없다. 과학적인 관점에서 이것은 매우 불만족스럽다.
이러한 모델의 작동 방식과 이유를 명확히 이해하지 못하면 더 나은 모델의 개발은 시행착오로 전락하게 됩니다.
본 논문에서는 모델의 모든 계층에서 개별 특징 맵을 흥분시키는 입력 자극을 밝히는 시각화 기법을 소개한다.
또한 훈련 중 기능의 진화를 관찰하고 모델의 잠재적 문제를 진단할 수 있다.
우리가 제안하는 시각화 기술은 (Zeiler et al., 2011)가 제안한 대로 다층 디콘볼루션 네트워크(디콘넷)를 사용하여 기능 활성화를 입력 픽셀 공간에 다시 투영한다.
또한 입력 이미지의 일부를 차단하여 분류기 출력의 민감도 분석을 수행하여 분류에 중요한 장면 부분을 보여준다.
이러한 툴을 사용하여 (Krizhevsky et al., 2012)의 아키텍처에서 시작하여 ImageNet에서 결과를 능가하는 아키텍처를 탐색한다.
그런 다음 모델의 다른 데이터 세트에 대한 일반화 기능을 탐색하고 위에 있는 소프트맥스 분류기를 재교육한다.
이와 같이, 이것은 (힌튼 외, 2006) 및 다른 사람들에 의해 대중화된 감독되지 않은 사전 훈련 방법(Bengio 외, 2007; Vincent 외, 2008)과 대조되는 감독되지 않은 사전 훈련의 한 형태이다. (Donahue et al., 2013)에 의한 동시 작업에서도 콘넷 기능의 일반화 능력을 탐구한다.
1.1 Related Work
네트워크에 대한 직관을 얻기 위해 기능을 시각화하는 것은 일반적인 관행이지만, 대부분 픽셀 공간에 대한 투영이 가능한 1층으로 제한된다.
상위 계층에서는 그렇지 않으며 활동을 해석하는 방법이 제한적이다. (Erhan et al., 2009) 단위 활성화를 극대화하기 위해 이미지 공간에서 경사 하강을 수행하여 각 장치에 대한 최적의 자극을 찾는다.
이를 위해서는 신중한 초기화가 필요하며 장치의 불변성에 대한 어떠한 정보도 제공하지 않습니다. 후자의 단점에 의해 동기 부여되어 (Le et al., 2010) (Berkes & Wiskott, 2006)에 의해 아이디어를 확장) 특정 단위의 헤시안이 최적의 반응을 중심으로 수치적으로 계산되어 불변성에 대한 통찰력을 제공하는 방법을 보여준다.
문제는 상위 계층의 경우 분산이 매우 복잡하기 때문에 단순한 2차 근사치에 의해 잘 포착되지 않는다는 것이다.
대조적으로 우리의 접근 방식은 비모수적인 불변성 보기를 제공하여 훈련 세트의 어떤 패턴이 기능 맵을 활성화하는지 보여준다. (Donahue et al., 2013) 모델의 상위 계층에서 강력한 활성화를 담당하는 데이터 세트 내의 패치를 식별하는 시각화를 보여준다.
우리의 시각화는 단순히 입력 이미지의 크롭이 아니라 특정 기능 맵을 자극하는 각 패치 내의 구조를 드러내는 하향식 투영이라는 점에서 다르다.
2. Approach
우리는 (LeCun 등, 1989년) 및 (Krizhevsky 등, 2012년)에 의해 정의된 대로, 논문 전체에 걸쳐 표준 완전히 감독된 콘넷 모델을 사용한다.
이 모델들은 일련의 레이어를 통해 컬러 2D 입력 이미지 xi를 C 다른 클래스에 대한 확률 벡터 βi에 매핑한다. 각 레이어는
(i) 일련의 학습된 필터로 이전 레이어 출력(또는 첫 번째 레이어의 경우 입력 이미지)의 컨볼루션,
(ii) 정류된 선형 함수(relu(x) = max(x, 0);
(iii) [optional] 로컬 이웃에 대한 최대 풀링 및
(iv) [옵션] 로컬 대비로 구성된다.여러 기능 맵에서 응답을 정규화합니다.
이러한 작업에 대한 자세한 내용은 (Krizhevsky et al., 2012) 및 (Jarrett et al., 2009)를 참조하십시오.
네트워크의 상위 몇 계층은 기존의 완전히 연결된 네트워크이고 최종 계층은 소프트맥스 분류기이다.
그림 3은 우리의 많은 실험에 사용된 모델을 보여준다.
우리는 이러한 모델을 {x, y} 레이블이 지정된 N개의 큰 이미지 세트를 사용하여 훈련시킨다.
여기서 label yi는 실제 클래스를 나타내는 이산 변수이다.
이미지 분류에 적합한 교차 엔트로피 손실 함수는 µi와 yi를 비교하는 데 사용된다.
네트워크의 매개 변수(컨볼루션 레이어의 필터, 완전히 연결된 레이어의 가중치 행렬)는 네트워크 전체의 매개 변수와 관련하여 손실의 파생물을 역 전파하고 확률적 경사 하강을 통해 매개 변수를 업데이트함으로써 훈련된다.
교육에 대한 자세한 내용은 섹션 3에 나와 있습니다.
2.1 Visualization with a Deconvnet
convnet의 작동을 이해하려면 중간 계층에서 기능 활동을 해석해야 한다.
우리는 이러한 활동을 입력 픽셀 공간에 다시 매핑하는 새로운 방법을 제시하며, 기능 맵에서 원래 어떤 입력 패턴이 특정 활성화를 유발했는지 보여준다.
우리는 디콘볼루션 네트워크(디콘네트)를 사용하여 이 매핑을 수행한다(Zeiler et al., 2011).
디콘넷은 동일한 컴포넌트(필터링, 풀링)를 사용하는 콘넷 모델로 생각할 수 있지만 반대로 픽셀을 형상에 매핑하는 대신 그 반대이다. (Zeiler et al., 2011)에서는 디콘넷이 비지도 학습을 수행하는 방법으로 제안되었다.
여기서는 이미 훈련된 콘넷의 탐색처럼 학습 능력에서 사용되지 않는다.
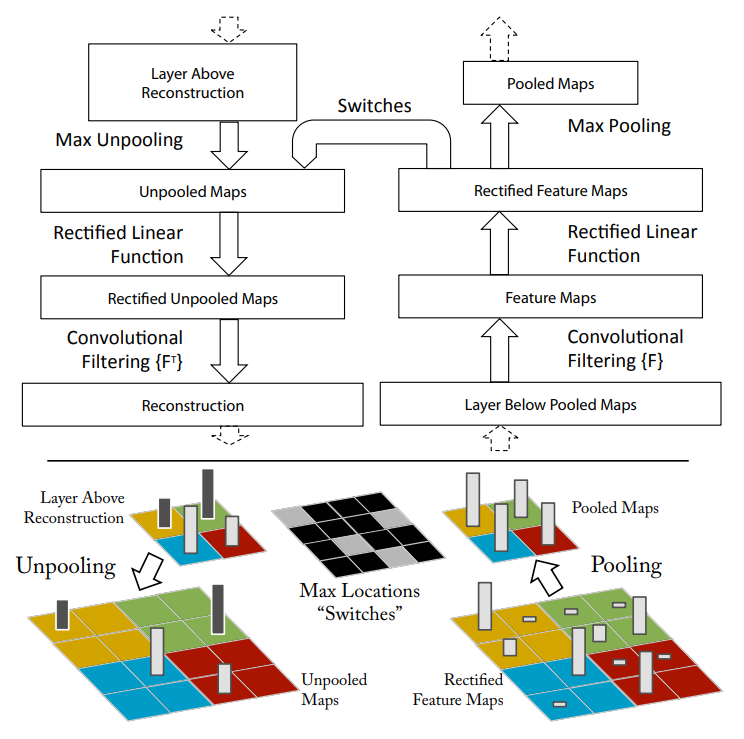
콘넷을 검사하기 위해 그림 1(위)에서 설명한 대로 디콘넷이 각 레이어에 연결되어 이미지 픽셀로 돌아가는 연속 경로를 제공한다.
시작하기 위해 입력 이미지는 컨베넷에 제시되고 계층 전체에 걸쳐 계산된 특징들이다.
주어진 콘넷 활성화를 조사하기 위해, 우리는 계층의 다른 모든 활성화를 0으로 설정하고 피처 맵을 연결된 디콘넷 계층에 입력으로 전달한다.
그런 다음 우리는 연속적으로 (i) unpool, (ii) 수정 및 (iii) 필터를 사용하여 선택한 활성화를 발생시킨 아래 계층의 활동을 재구성한다.
그런 다음 입력 픽셀 공간에 도달할 때까지 반복됩니다.
풀링 해제: convnet에서, 최대 풀링 연산은 되돌릴 수 없지만, 우리는 스위치 변수 집합에 각 풀링 영역 내의 최대 위치를 기록함으로써 대략적인 역수를 얻을 수 있다.
디콘넷에서, 언풀링 작업은 위의 계층에서 적절한 위치로 재구성을 배치하기 위해 이러한 스위치를 사용하여 자극의 구조를 보존한다. 절차 설명은 그림 1(하단)을 참조하십시오.
수리: convnet은 기능 맵을 수정하여 기능 맵이 항상 양수임을 보장하는 반복 비선형성을 사용합니다. 각 계층(양극성이어야 함)에서 유효한 형상 재구성을 얻기 위해 재구성된 신호를 반복 비선형성을 통해 전달한다.
필터링: convnet은 학습된 필터를 사용하여 이전 계층에서 기능 맵을 컨볼루션한다.
이를 뒤집기 위해 디콘넷은 동일한 필터의 전치된 버전을 사용하지만 아래 계층의 출력이 아닌 정류된 맵에 적용됩니다.
실제로 이는 각 필터를 수직 및 수평으로 뒤집는 것을 의미합니다.
상위 계층에서 아래로 투사하는 것은 상승하는 동안 콘넷의 최대 풀링에 의해 생성된 스위치 설정을 사용한다.
이러한 스위치 설정은 주어진 입력 이미지에 고유하므로, 단일 활성화에서 얻은 재구성은 기능 활성화에 대한 기여도에 따라 가중치가 부여된 구조를 가진 원래 입력 이미지의 작은 조각과 유사하다.
모델이 차별적으로 훈련되기 때문에, 그것들은 입력 이미지의 어떤 부분이 차별적인지를 암시적으로 보여준다.
이러한 투영법은 생성 공정이 포함되어 있지 않으므로 모형에서 추출한 표본이 아닙니다.
그림 1 맨 위: convnet 레이어(왼쪽)에 연결된 디콘넷 레이어(오른쪽)입니다.
디콘넷은 아래 계층에서 콘넷 기능의 대략적인 버전을 재구성한다.
아래쪽: 디콘넷에서 풀링하는 동안 각 풀링 영역(색상 영역)의 로컬 최대 위치를 기록하는 스위치를 사용한 풀링 해제 작업의 그림입니다.
3. Training Details
우리는 이제 섹션 4에서 시각화될 대규모 콘넷 모델을 설명한다.
그림 3에 표시된 아키텍처는 ImageNet 분류에 사용되는 아키텍처(Krizhevsky et al., 2012)와 유사합니다.
한 가지 차이점은 (2개의 GPU로 분할되는 모델 때문에) Krizhevsky의 계층 3,4,5에 사용된 희소 연결이 우리 모델에서 조밀한 연결로 대체된다는 것이다.
제4.1절에 설명한 것처럼 그림 6의 시각화를 검사한 후 계층 1과 2와 관련된 다른 중요한 차이가 이루어졌다.
이 모델은 ImageNet 2012 교육 세트(130만 개의 이미지, 1000개의 다른 클래스에 분산됨)에서 훈련되었다.
각 RGB 영상은 최소 치수 크기를 256으로 조정하고, 중앙 256x256 영역을 자르고, 픽셀당 평균(모든 영상에서)을 뺀 다음, 224x224 크기(수평 플립이 없는 코너 + 센터)의 10개의 다른 하위 크롭을 사용하여 사전 처리되었다.
최소 배치 크기가 128인 확률적 경사 하강은 0.9의 모멘텀 항과 함께 10-2의 학습 속도로 시작하여 매개 변수를 업데이트하는 데 사용되었다.
검증 오류가 발생할 경우 교육 전반에 걸쳐 학습 속도를 수동으로 해제합니다.
드롭아웃(Hinton et al., 2012)은 0.5의 비율로 완전히 연결된 계층(6과 7)에서 사용된다.
모든 가중치는 10-2로 초기화되고 치우침은 0으로 설정됩니다.
훈련 중 첫 번째 레이어 필터를 시각화하면 그림 6(a)에 표시된 것처럼 이들 중 일부가 지배한다는 것을 알 수 있다. 이를 방지하기 위해, 우리는 RMS 값이 이 고정 반지름에 대한 고정 반지름 10-1을 초과하는 컨볼루션 레이어의 각 필터를 정규화했다.
이는 특히 입력 영상이 대략 [-128,128] 범위에 있는 모델의 첫 번째 레이어에서 중요하다. (Krizhevsky et al., 2012)와 같이, 우리는 훈련 세트 크기를 증가시키기 위해 각 훈련 예제의 여러 가지 다른 작물과 플립을 생산한다. (Krizhevsky et al., 2012)를 기반으로 한 구현을 사용하여 단일 GTX580 GPU에서 약 12일이 걸린 70epo 이후 훈련을 중단했다.
4. Convnet Visualization
섹션 3에 설명된 모델을 사용하여 이제 디콘넷을 사용하여 ImageNet 검증 세트에서 기능 활성화를 시각화합니다.
기능 시각화: 그림 2는 교육이 완료되면 모델의 기능 시각화를 보여줍니다.
그러나 특정 기능 맵에 대해 가장 강력한 단일 활성화를 보여주는 대신 상위 9개 활성화를 보여준다.
각각을 픽셀 공간으로 개별적으로 투사하면 주어진 형상 맵을 흥분시키는 서로 다른 구조가 드러나므로 입력 변형에 대한 불변성을 보여준다.
이러한 시각화 외에도 해당 이미지 패치를 보여준다.
후자는 각 패치 내의 차별적 구조에만 초점을 맞추기 때문에 이러한 변화는 시각화보다 더 크다.
예를 들어, 계층 5, 행 1, 콜 2에서 패치는 공통점이 거의 없는 것처럼 보이지만, 시각화를 통해 이 특정 기능 맵은 전경 개체가 아닌 배경의 잔디를 중점적으로 다루고 있음을 알 수 있다.
그림 2 완전히 훈련된 모델의 특징 시각화.
계층 2-5의 경우, 우리는 디콘볼루션 네트워크 접근 방식을 사용하여 픽셀 공간에 투영된 검증 데이터에 걸친 기능 맵의 임의의 하위 집합에서 상위 9개 활성화를 보여준다.
우리의 재구성은 모델의 샘플이 아니라, 주어진 형상 맵에서 높은 활성화를 일으키는 검증 세트에서 재구성된 패턴이다. 각 기능 맵에 대해 해당 이미지 패치도 표시합니다.
참고: (i) 각 특징 맵 내의 강력한 그룹화, (ii) 상위 계층에서 더 큰 불변성 및
(iii) 개의 눈과 코(레이어 4, 1행, 콜스 1)와 같은 이미지의 차별적인 부분을 과장한다.
전자 형태로 가장 잘 보입니다.

각 계층의 투영은 네트워크에 있는 형상의 계층적 특성을 보여준다.
레이어 2는 코너 및 기타 가장자리/색상 접합부에 반응합니다.
계층 3은 유사한 질감(예: 망사 패턴(1행, 콜 1); 텍스트(R2, C4)))을 캡처하여 더 복잡한 분산을 가진다.
계층 4는 유의한 변동을 보여주지만 보다 세분화된 형태이다: 개면(R1,C1); 새다리(R4,C2).
레이어 5는 키보드(R1, C11)와 개(R4)와 같이 자세 변화가 큰 전체 물체를 보여준다.
훈련 중의 특징 진화: 그림 4는 픽셀 공간에 다시 투영된 주어진 특징 맵 내에서 (모든 훈련 예에서) 가장 강력한 활성화의 훈련 동안의 진행을 시각화한다. 갑작스런 외모 점프는 가장 강력한 활성화가 시작되는 이미지의 변화에서 비롯된다.
모델의 하위 계층은 몇 개의 시간 내에 수렴되는 것을 볼 수 있다.
그러나 상위 계층은 상당한 시간(40-50) 후에만 발전하므로 모델이 완전히 융합될 때까지 훈련할 필요가 있음을 보여준다.
형상 불변성: 그림 5는 변환되지 않은 형상에 비해 모델의 상단 및 하단 레이어에서 형상 벡터의 변화를 살펴보면서 다양한 도에 따라 변환, 회전 및 스케일링되는 5개의 샘플 영상을 보여준다.
작은 변환은 모델의 첫 번째 계층에서 극적인 영향을 미치지만 최상위 피쳐 계층에서는 덜 영향을 미치므로 변환 및 확장에 대해 준선형이 된다.
네트워크 출력은 변환 및 확장에 대해 안정적입니다.
일반적으로 회전 대칭이 있는 객체(예: 엔터테인먼트 센터)를 제외하고 출력은 회전과 불변하지 않습니다.
4.1 Architecture Selection
훈련된 모델의 시각화는 그 작동에 대한 통찰력을 제공하지만, 우선 좋은 아키텍처를 선택하는 데도 도움이 될 수 있다. 크리제프스키 외 연구진들의 첫 번째와 두 번째 층을 시각화함으로써. 의 아키텍처 (그림 6(b) & (d)), 다양한 문제가 명백하다.
첫 번째 레이어 필터는 중간 주파수에 대한 적용 범위가 거의 없는 극도로 높은 주파수와 낮은 주파수 정보가 혼합된 것이다.
또한, 2층 시각화는 1층 컨볼루션에서 사용된 큰 보폭 4에 의해 야기된 앨리어싱 아티팩트를 보여준다.
이러한 문제를 해결하기 위해, 우리는 (i) 11x11에서 7x7로 첫 번째 레이어 필터 크기를 줄였고,
(ii) 컨볼루션 2의 보폭을 4가 아닌 4로 만들었다.
이 새로운 아키텍처는 그림 6(c) 및 (e)에 표시된 것처럼 1계층과 2계층 특징에서 훨씬 더 많은 정보를 유지한다. 더욱 중요한 것은 5.1절과 같이 분류 성능을 향상시킨다는 점이다.
4.2 Occlusion Sensitivity
이미지 분류 접근법과 함께, 자연스러운 질문은 모델이 이미지에서 객체의 위치를 진정으로 식별하는지 아니면 단지 주변 컨텍스트를 사용하는지 여부이다.
그림 7은 입력 이미지의 다른 부분을 회색 사각형으로 체계적으로 막고 분류기의 출력을 모니터링하여 이 질문에 대답하려고 시도한다.
이 예들은 객체가 가려질 때 올바른 클래스의 확률이 현저히 떨어지기 때문에 모델이 장면 내에서 객체의 위치를 지정한다는 것을 분명히 보여준다.
그림 7은 또한 방해자 위치의 함수로서 이 지도에서의 활동(공간적 위치 위로 요약)과 더불어 최상위 컨볼루션 계층의 가장 강력한 기능 맵의 시각화를 보여준다. 오폐서가 시각화에 나타나는 이미지 영역을 덮으면 기능 맵에서 활동량이 크게 감소하는 것을 볼 수 있습니다.
이것은 시각화가 실제로 그 특징 맵을 자극하는 이미지 구조에 대응한다는 것을 보여주며, 따라서 그림 4와 그림 2에 표시된 다른 시각화를 검증한다.
4.3 Correspondence Analysis
심층 모델은 서로 다른 영상에서 특정 물체 부분 간의 통신을 설정하는 명시적 메커니즘이 없다는 점에서 기존의 많은 인식 접근법과 다르다(예: 얼굴은 눈과 코의 특별한 공간 구성을 가지고 있다).
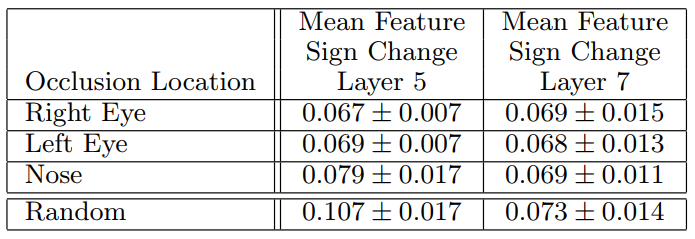
그러나 흥미로운 가능성은 심층 모델이 암묵적으로 그것들을 계산하고 있을 수 있다는 것이다. 이를 탐색하기 위해 정면 포즈로 무작위로 그려진 5개의 개 이미지를 촬영하고 각 이미지에서 얼굴의 동일한 부분을 체계적으로 마스크합니다(예: 모든 왼쪽 눈, 그림 8 참조).
각 이미지 i에 대해, 우리는 다음과 같이 계산한다: 여기서 와 는 각각 원래 이미지와 가려진 이미지에 대한 레이어 의 피쳐 벡터이다. 그런 다음 모든 관련 이미지 쌍(i, j):
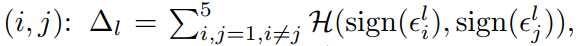
사이의 이 차이 벡터의 일관성을 측정한다.
여기서 H는 해밍 거리이다.
값이 작을수록 마스킹 작업으로 인한 변경의 일관성이 커지며, 따라서 서로 다른 영상에서 동일한 물체 부분 간의 더 엄격한 대응성이 나타납니다(즉, 왼쪽 눈을 차단하면 형상 표현이 일관된 방식으로 변경됨). 표 1에서는 레이어 = 5 및 = 7의 형상을 사용하여 얼굴의 세 부분(왼쪽 눈, 오른쪽 눈 및 코)에 대한 ∆ 점수를 객체의 임의의 부분과 비교한다. 레이어 5 특징에 대한 이러한 부분의 낮은 점수는 모형이 어느 정도의 대응성을 설정한다는 것을 보여준다.
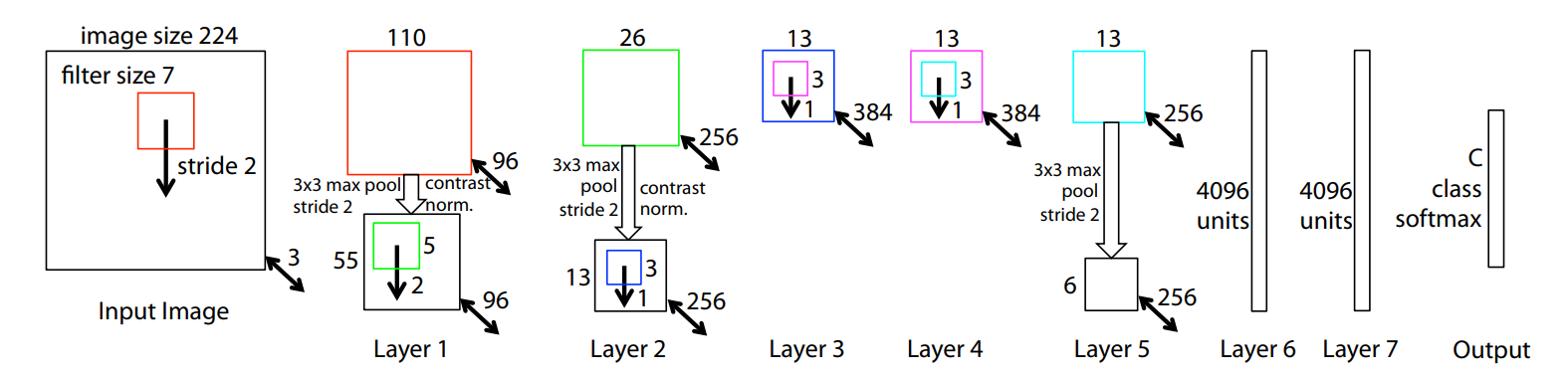
그림 3 8계층 콘넷 모델의 아키텍처. 3색 평면이 있는 이미지의 224 x 224 크롭이 입력으로 표시됩니다.
이는 x와 y에서 2의 보폭을 사용하여 각각 7x7 크기의 96개의 서로 다른 1층 필터(빨간색)와 융합된다. 그런 다음 결과 형상 맵은 (i) 정류 선형 함수(표시되지 않음), (ii) 풀링(3x3 영역 내 최대, 보폭 2를 사용하여) 형상 맵을 정규화하여 96개의 다른 55x55 요소 특성 맵을 제공한다.
유사한 연산이 2,3,4,5계층에서 반복된다.
마지막 두 계층은 완전히 연결되어 있으며, 최상위 컨볼루션 계층의 특징을 벡터 형태의 입력
(6 · 6 · 256 = 9216 치수)으로 사용한다.
마지막 레이어는 C-way softmax 함수이며, C는 클래스 수이다.
모든 필터와 피쳐 맵은 정사각형 모양입니다.

그림 4 훈련을 통해 무작위로 선택된 모델 피쳐 하위 집합의 진화. 각 계층의 기능은 다른 블록에 표시됩니다.
각 블록 내에서 [1,2,5,10,20,30,40,64] 에폭스에서 무작위로 선택된 기능 부분 집합을 보여준다.
시각화는 디콘넷 접근 방식을 사용하여 픽셀 공간으로 투사된 주어진 특징 맵에 대한 가장 강력한 활성화(모든 훈련 예)를 보여준다.
색 대비는 인위적으로 강화되었으며 이 수치는 전자 형태로 가장 잘 표시됩니다.
그림 5. 모형 내 수직 변환, 척도 및 회전 불변성 분석(각각 a-c 행)
Col 1: 변환 중인 영상 5개를 예로 들 수 있습니다.
Col 2와 3: 각각 레이어 1과 7에서 원래 영상과 변환된 영상 사이의 피처 벡터 사이의 유클리드 거리.
Col 4: 이미지가 변환될 때 각 이미지에 대한 참 레이블의 확률입니다.
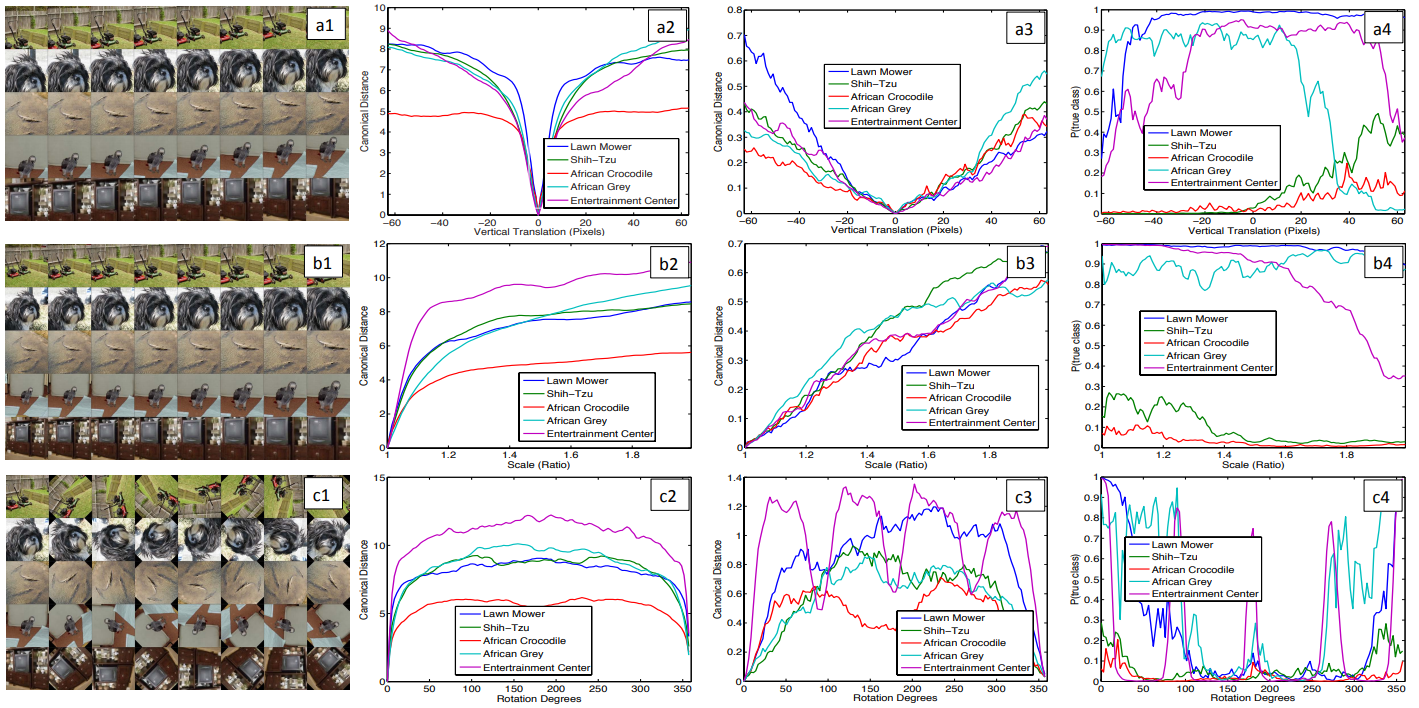
그림 6. (a): 기능 스케일 클리핑이 없는 1계층 기능 하나의 기능이 지배적이라는 점에 유의하십시오.
(b): (Krizhevsky et al., 2012)의 1번째 레이어 특징.
(c): 1단 기능. 보폭(2 대 4)과 필터 크기(7x7 대 11x11)가 작을수록 특색 있는 기능과 "죽은" 기능이 줄어듭니다.
(d): (Krizhevsky et al., 2012)의 두 번째 레이어 피쳐 시각화.
(e): 두 번째 레이어 기능의 시각화. (d)에서 볼 수 있는 앨리어싱 아티팩트가 없는 클리너입니다.

그림 7. 회색 사각형(1번째 열)으로 씬(scene)의 다른 부분을 체계적으로 커버하고 상단(레이어 5) 피처 매핑(b) 및 분류기 출력(d)이 어떻게 변경되는지 보는 세 가지 테스트 예제이다.
(b): 그레이 스케일의 각 위치에 대해, 우리는 하나의 레이어 5 피처 맵에 총 활성화(폐쇄되지 않은 영상에서 가장 강력한 응답을 가진 맵)을 기록합니다.
(c): 입력 이미지(검은색 사각형)에 투영된 이 기능 맵의 시각화 및 다른 이미지로부터의 이 맵의 시각화. 첫 번째 행 예제는 개의 얼굴이 될 수 있는 가장 강력한 특징을 보여줍니다. 이 작업이 완료되면 기능 맵의 활동이 감소합니다(b의 파란색 영역).
(d): 그레이 스퀘어 위치의 함수로서 올바른 클래스 확률의 지도입니다. 예를 들어 개의 얼굴이 가려질 때 "포메라니안"의 확률은 현저히 떨어집니다.
(e): 폐색기 위치의 함수로서 가장 가능성이 높은 라벨. 예를 들어, 첫 번째 줄에서는 대부분의 위치에 대해 "포메라니안"이지만, 개의 얼굴이 가려져 있지만 공이 보이지 않으면 "테니스 볼"을 예측한다. 두 번째 예에서 자동차의 텍스트는 레이어 5에서 가장 강력한 특징이지만 분류기는 휠에 가장 민감하다.
세 번째 예에는 여러 개체가 포함되어 있습니다. 레이어 5의 가장 강력한 형상은 얼굴을 선택하지만, 분류기는 복수의 형상 지도를 사용하기 때문에 도그(d)에 민감하다.
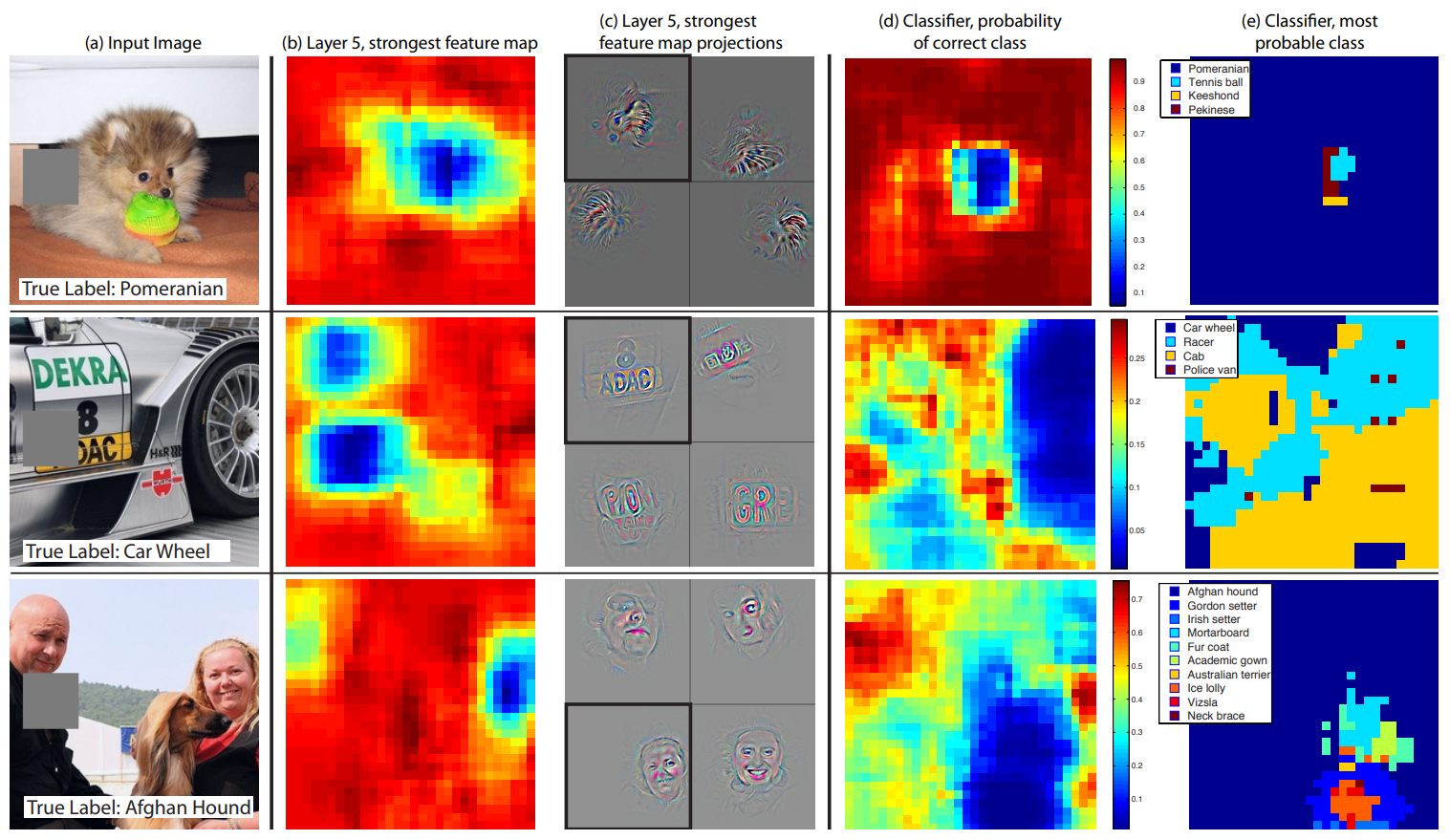
그림 8. 대응 실험에 사용되는 이미지입니다.
콜 1: 원본 이미지.
콜 2,3,4: 오른쪽 눈, 왼쪽 눈, 코가 각각 막힌다. 다른 열은 랜덤 관측 중단의 예를 보여 줍니다.

표 1. 5개의 도그 영상에서 서로 다른 객체 부품에 대한 대응 측도입니다. 눈과 코에 대한 낮은 점수(랜덤 객체 부분과 비교)는 모델이 모델의 5계층에서 어떤 형태의 부품 통신을 암시적으로 설정한다는 것을 보여준다. 레이어 7에서, 점수는 아마도 다른 종의 개를 구별하려는 상위 레이어들 때문에 더 비슷합니다.
5. Experiments
5.1 ImageNet 2012
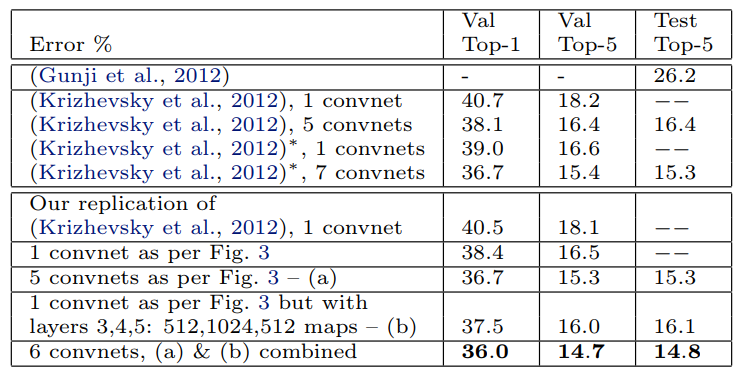
이 데이터 세트는 1.3으로 구성됩니다.M/50k/100k 교육/검증/테스트 예, 1000개 범주에 걸쳐 배포합니다. 표 2는 이 데이터 세트에 대한 우리의 결과를 보여준다. (Krizhevsky et al., 2012)에 지정된 정확한 아키텍처를 사용하여 검증 세트에서 결과를 복제하려고 한다.
ImageNet 2012 검증 세트에서 보고된 값의 0.1% 내에서 오류율이 달성됩니다.
다음으로 우리는 섹션 4.1(계층 1의 7×7 필터와 계층 1과 2의 2개의 보폭 2 컨볼루션)에 요약된 아키텍처 변경으로 모델의 성능을 분석한다.
그림 3에 표시된 이 모델은 (Krizhevsky et al., 2012)의 아키텍처를 크게 능가하여 단일 모델 결과를 1.7%(테스트 상위-5) 능가한다.
여러 모델을 결합하면 이 데이터 세트에 대해 가장 잘 게시된 성능인 14.8%의 테스트 오류를 얻습니다1(2012년 교육 세트만 사용함).
이 오류는 26.2% 오류를 얻은 ImageNet 2012 분류 과제에서 상위 비콘넷 항목의 절반에 가깝다는 점에 주목한다(군지 외, 2012).
- 이러한 성능은 최근 Imagnet 2013 대회에서 능가했습니다(http://www.image-net.org/.
표 2. ImageNet 2012 분류 오류율. ▼는 ImageNet 2011 및 2012 교육 세트 모두에서 학습된 모델을 나타냅니다.
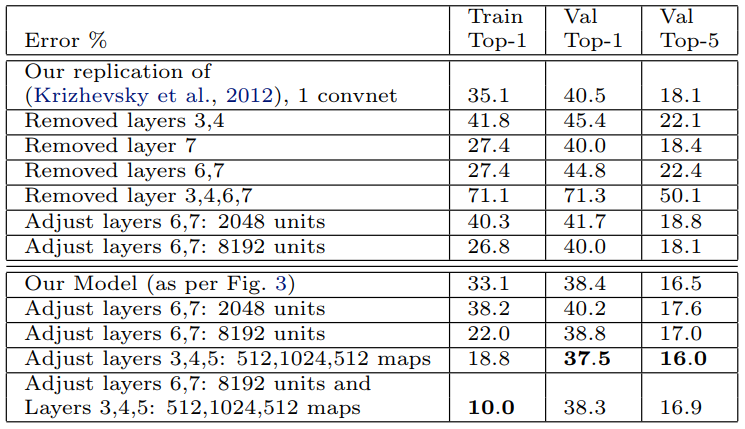
다양한 ImageNet 모델 크기: 표 3에서는 먼저 레이어의 크기를 조정하거나 완전히 제거하여 (Krizhevsky et al., 2012)의 아키텍처를 살펴본다.
각각의 경우, 모델은 수정된 아키텍처를 통해 처음부터 교육됩니다.
완전히 연결된 레이어(6.7)를 제거하면 오류가 약간 증가할 뿐입니다.
대부분의 모형 모수를 포함한다는 점에서 이는 놀라운 일이다.
중간 컨볼루션 레이어 중 두 개를 제거하면 오류율과 상대적으로 작은 차이가 발생한다.
그러나 중간 컨볼루션 레이어와 완전히 연결된 레이어를 모두 제거하면 성능이 크게 나쁜 4개 레이어만 있는 모델이 생성된다.
이는 우수한 성능을 얻기 위해 모델의 전체적인 깊이가 중요하다는 것을 암시할 수 있습니다.
표 3에서 우리는 그림 3에 나온 것처럼 우리의 모델을 수정한다. 완전히 연결된 계층의 크기를 변경해도 성능에 거의 차이가 없다( (Krizhevsky et al., 2012).
그러나 중간 컨볼루션 레이어의 크기를 늘리면 성능에 유용한 이점이 있다.
그러나 이러한 계층을 늘리는 동시에 완전히 연결된 계층을 확대하면 과적합 현상이 발생한다.
5.2 Feature Generalization
위의 실험은 최첨단 성능을 얻는 데 있어 ImageNet 모델의 컨볼루션 부분의 중요성을 보여준다.
이는 컨볼루션 계층에서 학습한 복잡한 불균형을 보여주는 그림 2의 시각화에 의해 뒷받침된다.
이제 우리는 칼텍-101(Feifi et al., 2006), 칼텍-256(Griffin et al., 2006) 및 파스칼 VOC 2012와 같은 다른 데이터 세트로 일반화하는 이러한 기능 추출 계층의 능력을 탐구한다.
이를 위해 ImageNet에서 훈련된 모델의 계층 1-7을 고정하고 새 데이터 세트의 훈련 이미지를 사용하여 (적절한 클래스 수에 대한) 새로운 소프트맥스 분류기를 상단에서 훈련시킨다.
소프트맥스는 비교적 적은 수의 매개 변수를 포함하므로 특정 데이터 세트의 경우와 마찬가지로 비교적 적은 수의 예에서 빠르게 훈련할 수 있다.
표 3. (Krizhevsky et al. 2012) 및 우리 모델에 대한 다양한 아키텍처 변경으로 ImageNet 2012 분류 오류율이 발생한다(그림 3 참조).
모델(소프트맥스)과 다른 접근 방식(일반적으로 선형 SVM)에 의해 사용되는 분류기는 복잡도가 비슷하므로 실험은 ImageNet에서 학습한 우리의 기능 표현을 다른 방법이 사용하는 수작업으로 만든 기능과 비교한다. 우리의 기능 표현과 수작업으로 조작된 기능 모두 Caltech 및 PASCAL 교육 세트를 넘어서는 이미지를 사용하여 설계되었다는 점에 유의해야 한다.
예를 들어, HOG 설명자의 초 매개 변수는 보행자 데이터 세트에 대한 체계적인 실험을 통해 결정되었다(Dalal & Triggs, 2005).
또한 처음부터 모델을 훈련시키는 두 번째 전략, 즉 레이어 1-7을 랜덤 값으로 재설정하고 데이터 세트의 훈련 이미지에 대해 소프트맥스뿐만 아니라 이들을 훈련시키는 두 번째 전략을 시도한다.
한 가지 문제는 Caltech 데이터 세트 중 일부가 ImageNet 교육 데이터에도 포함된 일부 이미지를 가지고 있다는 것이다.
정규화된 상관 관계를 사용하여, 우리는 이러한 몇 가지 "중첩" 이미지를 식별하고 이미지넷 훈련 세트에서 제거한 다음 이미지넷 모델을 재교육하여 열차/테스트 오염의 가능성을 피했다.
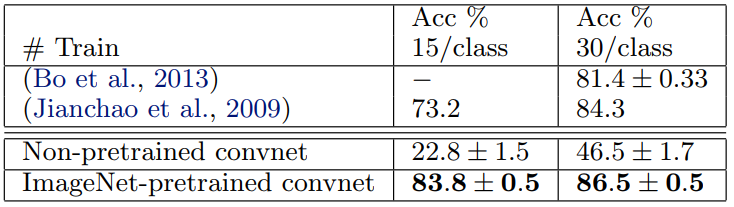
Caltech-101: (Fei-fee 등, 2006년)의 절차를 따르고 표 4의 클래스당 정확도의 평균을 보고하는 클래스당 최대 50개의 이미지를 대상으로 클래스당 15개 또는 30개의 이미지를 무작위로 선택하고 테스트한다. 30개의 이미지/클래스에 17분이 걸렸습니다.
사전 훈련된 모델은 (Bo et al., 2013)의 30개 이미지/클래스에 대해 보고된 최상의 결과를 2.2% 능가한다.
그러나 처음부터 훈련된 콘넷 모델은 46.5%밖에 달성하지 못했다.
- Caltech-101의 경우, 우리는 44개의 공통 이미지(총 9,144개의 이미지 중)를 발견했으며, 주어진 클래스에 대해 최대 10개의 겹침이 있다. Caltech-256의 경우 공통 이미지(전체 이미지 30,607개 중) 243개를 발견했으며, 주어진 클래스에 대해 최대 18개가 겹쳤다.
그림 9. 클래스당 훈련 이미지 수가 다양하기 때문에 Caltech-256 분류 성능이 달라집니다.
사전 훈련된 기능 추출기로 클래스당 6개의 교육 예만을 사용하여, 우리는 가장 잘 보고된 결과를 능가한다(Bo et al., 2013).
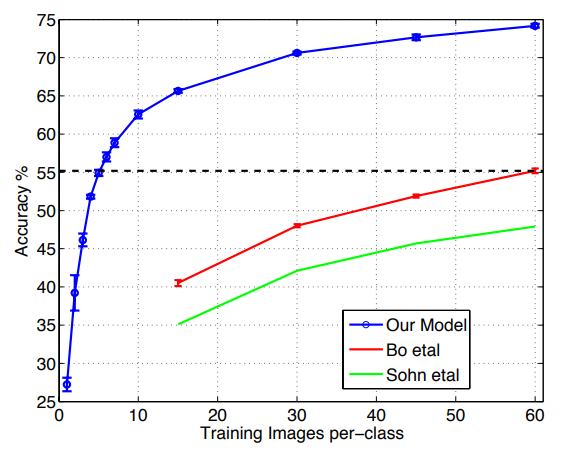
표 4. 우리의 콘넷 모델에 대한 Caltech-101 분류 정확도는 두 가지 선도적인 대체 접근법에 대한 것이다.
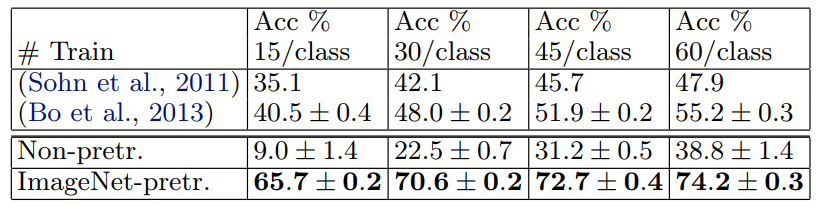
Caltech-256: 우리는 (Griffin et al., 2006)의 절차에 따라 클래스당 15, 30, 45 또는 60개의 훈련 이미지를 선택하고 표 5에 있는 클래스당 정확도의 평균을 보고한다.
우리의 ImageNet 사전 훈련된 모델은 Bo 등(Bo 등, 2013년)이 획득한 현재 최첨단 결과를 상당한 차이로 능가한다. 60개의 교육 이미지/클래스에 대해 74.2% 대 55.2%이다.
그러나 Caltech-101과 마찬가지로 처음부터 훈련된 모델은 성능이 떨어진다. 그림 9에서, 우리는 "원샷 학습"(Fei-fei 등, 2006) 체제를 탐구한다. 사전 훈련된 모델을 사용하면 10배의 이미지를 사용하여 선도적인 방법을 능가하는 단 6개의 Caltech-256 훈련 이미지가 필요하다. ImageNet 기능 추출기의 성능을 보여줍니다.
표 5. Caltech 256 분류 정확도.
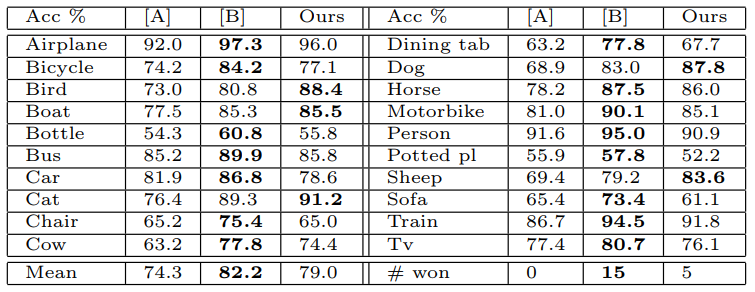
PASCAL 2012: 우리는 표준 훈련 및 검증 이미지를 사용하여 ImageNet 사전 훈련된 콘넷 위에 20방향 소프트맥스를 훈련시켰다.
PASCAL 이미지는 여러 개체를 포함할 수 있고 모델은 각 이미지에 대해 하나의 배타적 예측만 제공하므로 이것은 이상적인 것이 아니다.
표 6은 테스트 세트의 결과를 보여줍니다. PASCAL과 ImageNet 이미지는 본질적으로 상당히 다르며, 전자는 후자와는 달리 전체 장면입니다. 이것은 우리의 평균 성능이 선행(Yan et al., 2012) 결과보다 3.2% 낮다는 것을 설명할 수 있지만, 우리는 5개 클래스에서 때로는 큰 차이로 그들을 이겼다.
표 6. PASCAL 2012 분류 결과, 선도적인 두 가지 방법([A]= (Sande et al., 2012)과 [B] = (Yan et al., 2012))을 비교한다.
5.3 Feature Analysis
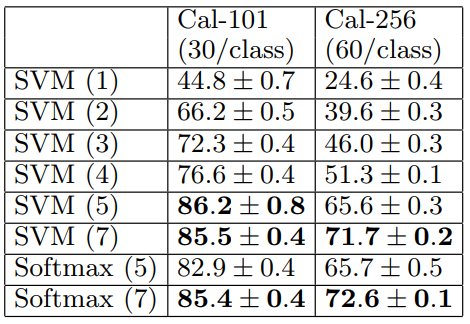
우리는 Imagenet 사전 훈련된 모델의 각 계층에서 특징이 얼마나 차별적인지를 탐구한다. ImageNet 모델에서 보존된 계층 수를 변경하여 이를 수행하고 선형 SVM 또는 소프트맥스 분류기를 맨 위에 배치한다. 표 7은 Caltech101과 Caltech-256에 대한 결과를 보여줍니다.
두 데이터 세트의 경우, 모든 계층을 사용하여 최상의 결과를 얻음으로써 모델을 상승시킬 때 꾸준한 개선을 볼 수 있다.
이는 기능 계층이 깊어질수록 점점 더 강력한 기능을 학습한다는 전제를 뒷받침한다.
표 7. ImageNet 사전 훈련된 콘넷 내의 각 피쳐 맵 계층에 포함된 차별적 정보의 분석.
우리는 convnet에서 다른 계층(괄호 안에 표시)에서 선형 SVM 또는 소프트맥스 기능을 훈련시킨다.
일반적으로 계층이 높을수록 더 차별적인 특징이 생성된다.
6. Discussion
이미지 분류를 위해 훈련된 대규모 컨볼루션 신경망 모델을 여러 가지 방법으로 탐색했다.
먼저 모델 내에서 활동을 시각화하는 새로운 방법을 제시하였다.
이것은 특징들이 무작위적이고 해석 불가능한 패턴과는 거리가 멀다는 것을 보여준다.
오히려, 그것들은 우리가 층을 올라갈 때 구성성, 증가하는 불변성 및 클래스 차별과 같이 직관적으로 바람직한 많은 속성을 보여준다.
우리는 또한 이러한 시각화를 사용하여 Krizhevsky et al. (Krizhevsky et al., 2012) 인상적인 ImageNet 2012 결과를 개선하는 등 더 나은 결과를 얻기 위해 모델의 문제를 디버깅하는 방법을 보여주었다.
그런 다음 일련의 폐색 실험을 통해 모델이 분류를 위해 훈련된 반면 이미지의 로컬 구조에 매우 민감하며 넓은 장면 컨텍스트만 사용하지 않는다는 것을 입증했다.
모델에 대한 절제 연구는 개별 섹션이 아닌 네트워크에 대한 최소 깊이를 갖는 것이 모델 성능에 필수적이라는 것을 보여주었다.
마지막으로 ImageNet 훈련 모델이 다른 데이터 세트에 대해 어떻게 일반화할 수 있는지 보여주었다.
Caltech-101과 Caltech-256의 경우 데이터 세트는 가장 잘 보고된 결과를 능가할 정도로 유사하다.
이 결과는 소규모 (즉, < 104) 훈련 세트를 사용하는 벤치마크의 효용성에 의문을 제기한다.
우리의 콘넷 모델은 PASCAL 데이터에 대해 덜 일반화되었으며, 아마도 데이터 세트 편향으로 고생하고 있을 것이다(토랄바 & 에프로스, 2011). 비록 작업에 대한 튜닝이 없음에도 불구하고 여전히 가장 잘 보고된 결과의 3.2% 이내였다.
예를 들어 이미지당 여러 개체를 허용하는 다른 손실 함수를 사용할 경우 성능이 향상될 수 있습니다.
이렇게 하면 네트워크도 자연스럽게 객체 탐지를 처리할 수 있다.
Acknowledgments
저자는 NSF 허가 IIS-1116923, Microsoft Research 및 Sloan Fellowship의 지원에 매우 감사한다.
References
- Bengio, Y., Lamblin, P., Popovici, D., and Larochelle, H. Greedy layer-wise training of deep networks. In NIPS, pp. 153–160, 2007.
- Berkes, P. and Wiskott, L. On the analysis and interpretation of inhomogeneous quadratic forms as receptive fields. Neural Computation, 2006.
- Bo, L., Ren, X., and Fox, D. Multipath sparse coding using hierarchical matching pursuit. In CVPR, 2013.
- Ciresan, D. C., Meier, J., and Schmidhuber, J. Multicolumn deep neural networks for image classification. In CVPR, 2012.
- Dalal, N. and Triggs, B. Histograms of oriented gradients for pedestrian detection. In CVPR, 2005.
- Donahue, J., Jia, Y., Vinyals, O., Hoffman, J., Zhang, N., Tzeng, E., and Darrell, T. DeCAF: A deep convolutional activation feature for generic visual recognition. In arXiv:1310.1531, 2013.
- Erhan, D., Bengio, Y., Courville, A., and Vincent, P. Visualizing higher-layer features of a deep network. In Technical report, University of Montreal, 2009.
- Fei-fei, L., Fergus, R., and Perona, P. One-shot learning of object categories. IEEE Trans. PAMI, 2006.
- Griffin, G., Holub, A., and Perona, P. The caltech 256. In Caltech Technical Report, 2006.
- Gunji, N., Higuchi, T., Yasumoto, K., Muraoka, H., Ushiku, Y., Harada, T., and Kuniyoshi, Y. Classification entry. In Imagenet Competition, 2012.
- Hinton, G. E., Osindero, S., and The, Y. A fast learning algorithm for deep belief nets. Neural Computation, 18:1527–1554, 2006.
- Hinton, G.E., Srivastave, N., Krizhevsky, A., Sutskever, I., and Salakhutdinov, R. R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv:1207.0580, 2012.
- Jarrett, K., Kavukcuoglu, K., Ranzato, M., and LeCun, Y. What is the best multi-stage architecture
for object recognition? In ICCV, 2009. - Jianchao, Y., Kai, Y., Yihong, G., and Thomas, H. Linear spatial pyramid matching using sparse coding for image classification. In CVPR, 2009.
- Krizhevsky, A., Sutskever, I., and Hinton, G.E. Imagenet classification with deep convolutional neural networks. In NIPS, 2012.
- Le, Q. V., Ngiam, J., Chen, Z., Chia, D., Koh, P., and Ng, A. Y. Tiled convolutional neural networks. In NIPS, 2010.
- LeCun, Y., Boser, B., Denker, J. S., Henderson, D., Howard, R. E., Hubbard, W., and Jackel, L. D. Backpropagation applied to handwritten zip code recognition. Neural Comput., 1(4):541–551, 1989.
- Sande, K., Uijlings, J., Snoek, C., and Smeulders, A. Hybrid coding for selective search. In PASCAL VOC Classification Challenge 2012, 2012.
- Sohn, K., Jung, D., Lee, H., and Hero III, A. Efficient learning of sparse, distributed, convolutional
feature representations for object recognition. In ICCV, 2011. - Torralba, A. and Efros, A. A. Unbiased look at dataset bias. In CVPR, 2011.
- Vincent, P., Larochelle, H., Bengio, Y., and Manzagol, P. A. Extracting and composing robust features with denoising autoencoders. In ICML, pp. 1096–1103, 2008.
- Yan, S., Dong, J., Chen, Q., Song, Z., Pan, Y., Xia, W., Huang, Z., Hua, Y., and Shen, S. Generalized hierarchical matching for sub-category aware object classification. In PASCAL VOC Classification Challenge 2012, 2012.
- Zeiler, M., Taylor, G., and Fergus, R. Adaptive deconvolutional networks for mid and high level feature learning. In ICCV, 2011.