Author : Karen Simonyan & Andrew Zisserman
Abstract
Abstract를 통해 저자가 강조하는 키워드는 'large scale image recognition', '3x3 convolution filter', 'increasing depth'로 볼 수 있을거 같습니다.
한 문장으로 요약하면 "3x3 conv filter를 통해 기존 CNN 모델의 layer의 갯수를 (deep하게) 늘렸고 (increasing depth), 이것이 large-scale image recognition에서도 좋은 결과를 얻게 만들었다" 정도가 될 것 같습니다.

1. Introduction
Introduction에서는 앞서 abstract에서 언급한 내용을 반복해서 말하고 있습니다.
CNN layer의 Depth를 중점적으로 보고 연구를 진행했다고 설명하고 있습니다.
이전에는 conv filter size가 조금씩 다르긴 했는데, 여기에서는 모든 layer에 3x3 conv filter를 동일하게 적용하고 있다고 설명하고 있습니다.

저자는 이 논문의 방향성을 아래와 같이 제시하고 있습니다.
Sect2에서 VGGNet의 구조(configuration)에 대해서 설명하고, Sect3에서 VGGNet 모델의 training 방식과 classification test 작업을 어떻게 진행했는지에 대해서 설명한다고 합니다.
그리고 마지막으로 저자가 앞서 언급한 내용들에 대해서 종합적인 결론 내려고 하는것 같습니다.


2. ConvNet Configurations
2.1 Architecture
VGGNet의 기본설정
Input image
- Input image size는 224x224로 고정한다.
- Input image (Training dataset)에 대한 Preprocessing은 RGB mean value를 빼주는것만 적용한다. (RGB mean value란 이미지 상에 pixel들이 갖고 있는 R,G,B 각각의 값들의 평균을 의미해요)
Conv layer
- 여기서는 3x3 conv filter를 사용한다.
(3x3이 left, right, up, down을 고려할 수 있는 최소한의 receptive filed이기 때문이다) - 하지만 1x1 conv filter도 사용한다.
- conv filter의 stride는 1이고, 연산시 padding이 적용된다.
Pooling layer
- max pooling은 conv layer 다음에 적용되고 총 5개의 max pooling layer로 구성된다.
pooling 연산은 2x2 size&stride=2로 구성된다.
FC(Fully-Connected) layer
- 처음 두 FC-layer는 총 4096 channel로 이루어 져있다.
그 외
- 모든 hidden layer에는 ReLU activation function이 적용된다.
- AlexNet에서 사용된 LRN 기법은 VGGNet 저자가 실험했을때 성능 향상도 없는데다가 메모리 소모 및 연산량을 늘리기 때문에 사용하지 않았다.

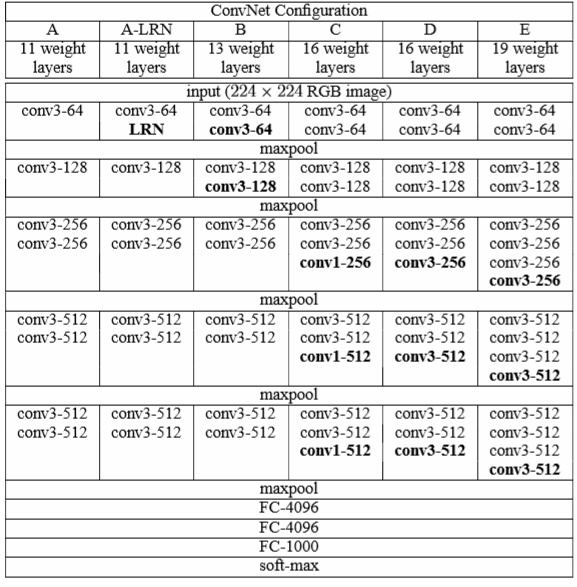
2.2 Configurations
Configuration에서는 depth에 따라 VGG 모델을 조금씩 변형시켜 연구를 진행했다고 언급하고 있으며,
모델명은 A~E라고 정의했고, 각각 layer가 16~19를 이루고 있다고 설명하고 있습니다.

Table 1.
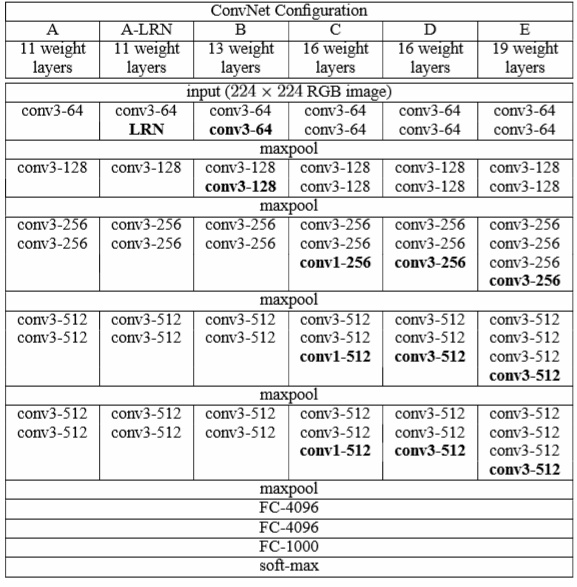
사진2. Table 1의 VGG E 모델

추가적으로 depth가 늘어나도 parameter가 줄어들었다는 것을 보여주고 있습니다.
Table2

사진3

2.3 Discussion
저자는 Discussion에서 small size filter인 3x3 conv filter를 사용한 이유를 설명하고 있습니다.
간단하게는 3x3 conv filter 2개를 사용하는 것이 하나의 5x5 conv filter를 사용하는 것과 같은 효과를 불러온다고 설명하고 있는데
예를들어, 입력 feature map ‘A’라고 가정할게요. Feature map ‘A’에 첫 번째 3x3 conv filter를 통해
나온 feature map ‘B’에 두 번째 3x3 conv filter를 적용한 것이, 애초에 feature map ‘A’를 5x5 conv filter를 적용하는 것과 같은 receptive field 효과를 불러 일으킨다는 뜻입니다.
그래서 5x5 conv filter를 3x3 conv 2개로 나누어(factorizing) 사용한다고 설명하고 있습니다.

좀더 자세한 내용은 아래 글에서 설명하고 있습니다.
여기서는 3개의 3x3 conv filter와 1개의 7x7 conv filter를 비교하면서 설명하고 있습니다.
먼저 각각의 conv filter를 하게 되면 ReLU라는 activation function을 거치게 됩니다.
그렇게 되면 non-linear한 문제를 좀 더 잘 풀 수 있게 되요 (이에 대한 이유는 여기 링크를 참고해주세요).
그래서 더 많은 conv filter를 사용하게 되면 여러개의 non linear function인 ReLU를 더 많이 사용할 수 있다는 장점이 있습니다.
사진4
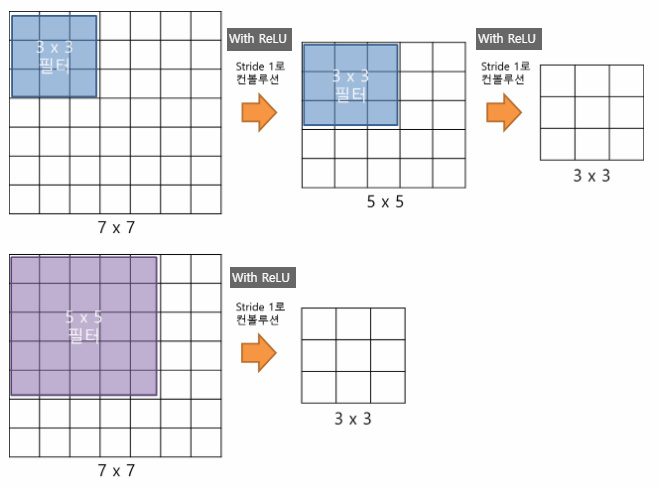

두 번째로는 3x3 conv filter를 사용하는 conv layer를 2번 사용되는 것이 7x7 conv filter를 한 개 사용하는 conv layer보다 연산시 적용되는 parameter수가 줄어든다는 점입니다.
그리고 이렇게 줄어든 parameter들은 overfitting을 줄여주는데 도움을 줍니다.
(parameter가 줄어드는데 overfitting이 줄어드는 이유는 여기 링크의 '바나나' 예시를 참고하세요)
앞서 얻어진 feature map의 개수가 64개이고 128개의 3x3x64 conv filter로 연산하면, 3x3x64x128 parameter가 필요함

VGG C 모델같은 경우에는 1x1 conv를 두어 non-linear 성격을 좀 더 강화시켰다고 합니다.

3. Classification Framework
VGG 모델을 어떻게 학습시켰고 어떻게 test 했는지를 상세하게 설명하고 있습니다.
3.1 Training
Training을 위해 hyper-parameter를 어떻게 설정했는지 설명하고 있습니다.
Cost function: Multinomial logistic regression objective = Cross Entropy
Mini-batch: Batch size 256
Optimizer: Momentum=0.9
Regularization: L2 Regularization = & Dropout = 0.5
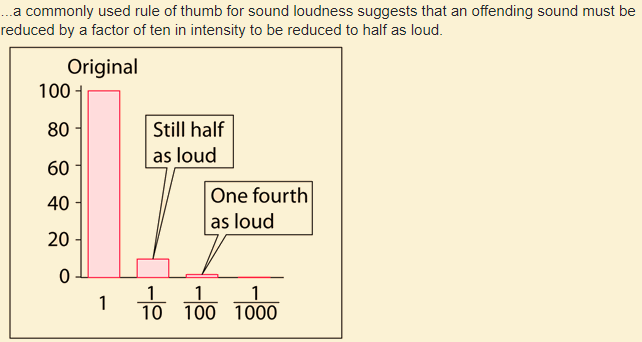
Learning rate: → validation error rate이 높아질수록 1/10 씩 ( ) 감소시킴
사진5. A factor of 10

AlexNet보다도 더 깊고 parameter도 좀 더 많지만 더 적은 epoch를 기록했다고 언급하고 있습니다.
그 이유는 implicit regularisation(암묵적 정규화)와 pre-initialisation(사전 초기화) 때문이라고 언급하고 있습니다.
Implicit regularisation은 앞선 눈문중에 "This can be seen as imposing a regularisation on the 7x7 conv"라는 부분을 말하고 있는건데요.
7x7 한 개보다 3개의 3x3 conv filter에 적용되는 parameter가 더 적기 때문에 이를 implicit regularisation이라고 언급하고 있어요 (explicit regularization(명시적 정규화)은 'dropout=0.5'라고 볼 수 있겠네요.
왜냐하면 논문에서 명시적으로 regularization 방식을 dropout으로 쓴다고 언급하고 있으니까요)

Pre-initialisation하는 방식은 먼저 VGG A 모델 (16 layer)를 학습하고,
다음 B,C,D,E 모델들을 구성할때 A 모델에 학습된 layer들을 가져다 쓰는 방식으로 진행되었습니다.
자세하게는 A모델의 처음 4개 conv layer와 마지막 3개 FC layer를 사용했다고 합니다.
이러한 방법을 통해 최적의 초기값을 설정해주어 학습을 좀 더 용이하게 만들었던것 같습니다.
(초기값과 관련된 내용은 여기 링크를 참고해주세요.)
Training image size
VGG 모델을 학습시킬 때 제일 처음하는 것은 training image를 VGG 모델의 input size에 맞게 바뀌어주어야 한다는점입니다.

예를 들어 S = 256이라고 한다면, 아래 사진처럼 training image의 넓이, 높이 중에서 더 작은 side를 256으로 줄여줍니다.
이때 aspect ratio를 유지하면서 나머지 side도 rescaling해주는데 이러한 방식을 "isotropically-rescaled(동위원소 축척의)" 했다고 말합니다.
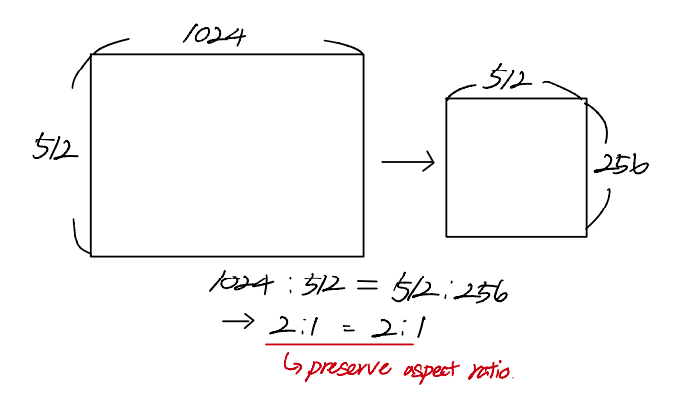
이렇게 isotropically-rescaled training image
(ex: 위의 이미지에서 512x256) 에서 224X224 size로 random하게 crop을 해주게 됩니다.
사실 S값을 설정하는 두 가지 방식이 있습니다.
첫 번째가 'single-scale training' 방식입니다.
이 방식은 S를 256 or 384로 고정시켜 사용하는 방식이에요. 처음에 S = 256으로 설정하여 학습시킨 VGG 모델의 가중치값들을 기반으로 S = 384으로 설정하여 다시 학습시킵니다.
S = 256에서 이미 많은 학습이 진행된 상태이기 때문에 S = 384로 설정하고 학습할때는 learning rate를 줄여주고 학습을 시켜줍니다.

또 다른 방식은 multi-scale training 방식입니다.
이번에는 S를 고정시키지 않고 256 ~ 512 값들 중에서 random하게 값을 설정해줍니다.
보통 객체들이 모두 같은 사이즈가 아니라 각각 다를 수 있기 때문에 이렇게 random하게 multi-scale로 학습시키게 해주면 학습효과가 더 좋아질 수 있습니다.

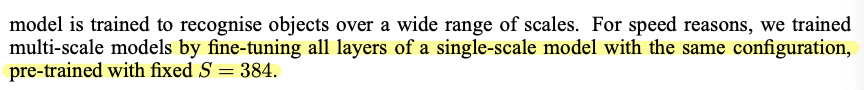
그리고 보통 이러한 Data augmentation 방식을 Scale jittering이라고도 합니다.
사진6

이러한 multi-scale을 학습시킬 때에는 앞선 single scale training 방식 (S = 256 or 384)을 진행한 VGG model로 fine tuning 시키게 됩니다.
3.2 Testing
Test image size
Training image가 rescaling되는것 처럼 VGG 모델을 test할 때도 rescaling 됩니다.
Training image를 rescaling 할때 기준이되는 값을 S라고 했다면, test image를 rescaling 할때 기준이 되는 값은 Q라고 합니다.
이때 Q = S일 필요는 없는데, training image에서 설정된 S값 마다 다른 Q를 적용하면 VGG 모델의 성능이 좋아진다고 하네요. (아마 여기서 말하는 test image는 training 중간중간에 validation하는 validation image dataset을 의미하는거 같네요 → 4.Classification Experiments 부분에서 Dataset 부분을 보니 validation dataset을 test dataset으로 간주하여 사용했다고 하네요.)

VGGNet 모델은 Training 할때와 중간중간 overfitting을 막기위해 Testing(Validation)할때 쓰이는 CNN 구조가 약간 다릅니다.
Test시에는 training시 사용되던 첫 번째 FC layer를 7X7 conv layer로 바꾸고,
마지막 두 FC layer를 1X1 conv layer로 바꾸었어요. 이것을 통해 whole (uncropped) image에 적용시킬 수 있다고 설명하고 있습니다.
이 부분에 대한 설명을 조금 풀어서 아래에 하겠습니다.

먼저 아래 왼쪽 그림을 feature map이 FC layer로 들어가기 전에 flatten하는 순서를 보여주고 있습니다.
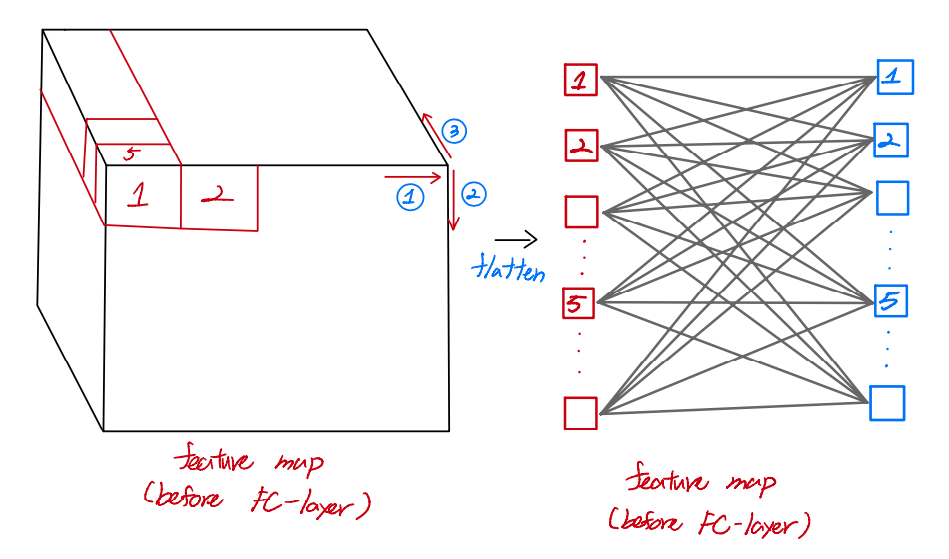
그리고 아래 그림은 1x1 conv filter를 적용하는게 어떻게 Fully connected layer와 연산구조가 비슷한건지 보여주고 있습니다.
아래와 같이 연산을 하면 결국 flatten하는 순서만 바뀌고 구조자체는 FC layer와 동일하게 바뀝니다.
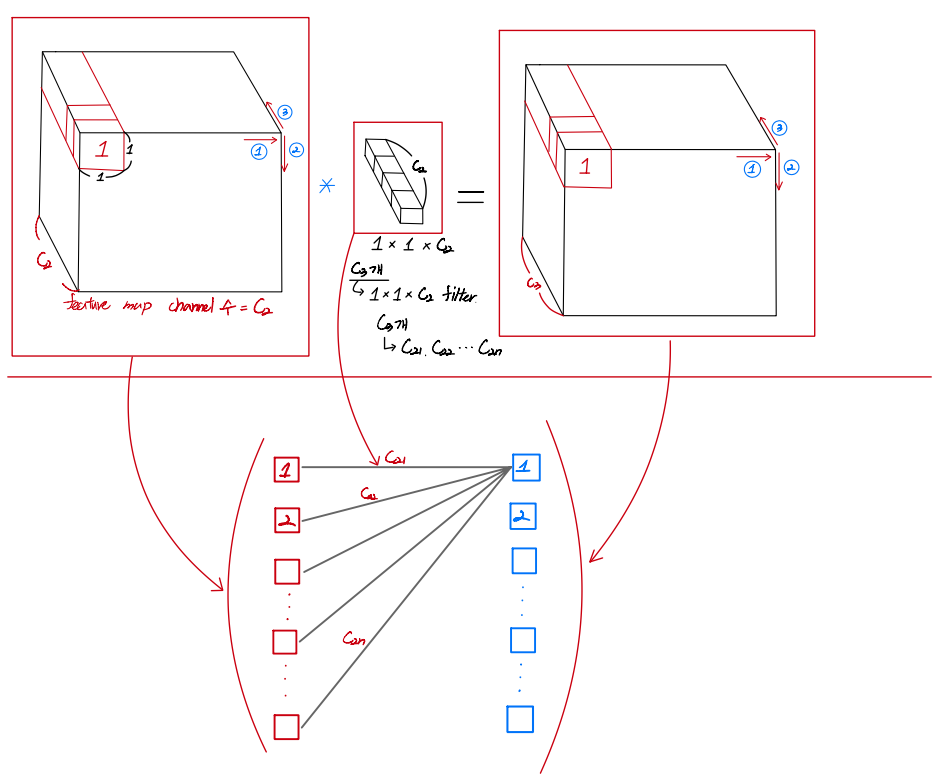
그렇다면 아래 사진처럼 training시 갖고 있던 FC layer를 1x1 conv filter를 가진 conv layer로 바꿔줄 수 있습니다.
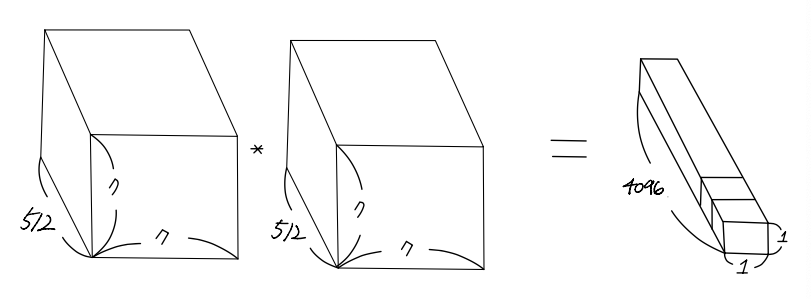
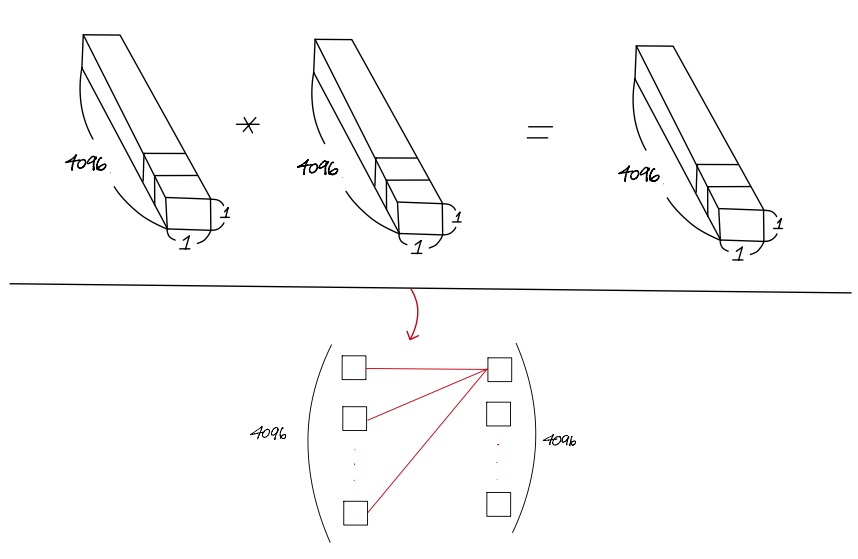
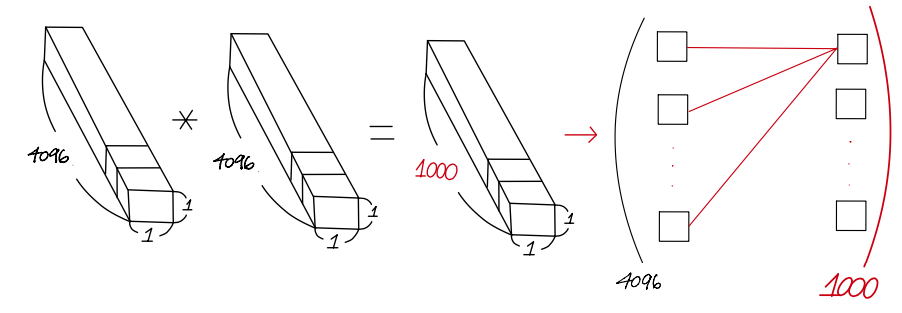
사진7. 왼쪽 Test시 VGGNet 구조, 오른쪽 Training시 VGGNet 구조.
왼쪽 이미지의 7x7x512 maxpooling 이후, 7x7 conv layer가 적용된 결과가 이미지에 나타납니다.
왼쪽이미지상에서는 FC-connted라고 표현했지만 실제로 3개의 1x1 conv layer라는 결과를 볼 수 있습니다.
논문에서 "The resulting fully-convolutional net is then applied to the whole (uncropped) image. The result is a class score map with the number of channels equal to the number of classes, and a variable spatial resolution, dependent on the image size. Finally, to obtain a fixed size vector of class scores for the image, the class score map is spatially averaged (sum-pooled)." 라고 언급된 부분에서 많은 혼동이 있을 수 있는데 이 부분에 대해서 잘 살펴보도록 하겠습니다.
Training시에는 crop하는 방법을 쓰지만, Test 시에는 FC layer를 conv layer( = fully-convolutional net)으로 바꿔주어 uncropped image를 사용해도 된다고 나와 있습니다.
당연히 FC layer는 MLP( 다중 퍼셉트론 : Multi-Layer Perceptron ) 개념으로써 입력 노드가 hyperparameter로 정해져 있기 때문에 항상 입력 노드(size)가 동일해야 합니다.
하지만 conv 연산에서는 그런 제약이 없어지게 됩니다.
그런데, 기존 crop을 통해 얻은 224x224 입력 image size가 VGG model에 입력되었을 때 classifier에 해당하는 부분 (FC layer가 1x1 conv layer로 바뀐 부분) 을 거친 최종 output feature map size가 입력 image size에 따라 서로 달라질겁니다.
사진8
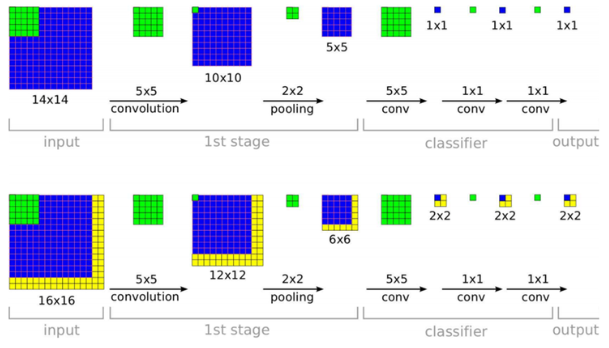
이때 output feature map size가 1x1이 아닌 경우에는 계산을 어떻게 하게 될까요?
예를들어, 224x224 이미지 사이즈가 들어왔을때는 '사진8'의 위쪽에 위치 한 그림처럼 classifier 단계(1x1 conv filter가 적용되기 시작하는 부분)에서 1x1 conv filter가 feature map에 알맞게 적용되는 것을 볼 수 있지만, 아래에 위치한 그림에서는 1x1 conv filter가 feature map size와 다르다는 것을 알 수 있습니다.
만약 큰 이미지가 입력으로 들어오게 되면 1x1 conv filter를 적용할 때 feature map size가 1x1이 아니고 7x7이 될 수도 있습니다.
논문에서 언급한 "The result is a class score map with the number of channels equal to the number of classes, and a variable spatial resolution, dependent on the image size."의 의미는 1x1 conv filter(layer)를 거치고 softmax에 들어가기 직전의 output feature map size가 이미지 크기에 따라 달라지는데, 아래와 같은 예에서는 7x7x1000 의 output feature map size를 얻을 수도 있다는 말과 같습니다.
이때 7x7 output feature map을 class score map이라고 한답니다.
이렇게 얻은 7x7 class score map은 1000개(channel)를 얻게 됩니다.
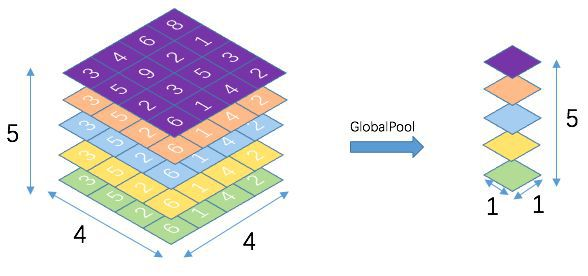
이때 각각의 7x7 feature map은 "spatially averaged (mean or average pooling)"을 하게 됩니다.
( 사실 논문에서는 sum pooling이라고 언급해서 pooling연산 할때 feature map을 더해주는게 아닌가라는 생각도 해봤는데 sum pooling에 대한 정확한 정의를 찾기도 힘들었고 코드들을 보면 GAP(Global Average pooling)을 사용하는것 같아 저는 mean or average pooling을 한다고 해석했습니다. )
사진9
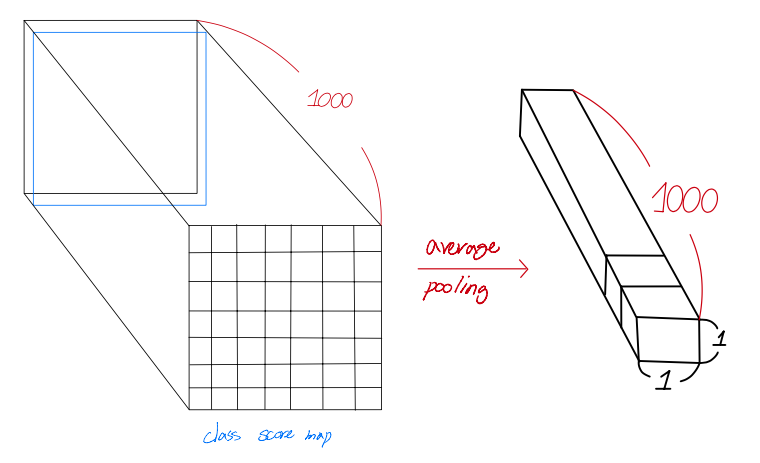
사진10. GAP
위와 같은 작업을 수행하되 softmax 이후에 flipped image와 original image의 평균값을 통해 최종 score (final)를 출력하게 됩니다.
AlexNet에서는 Test할때 1개의 이미지에 대해서 좌상단, 우상단, 가운데, 좌하단, 우하단으로 crop을 하고 각각 crop 된 이미지를 좌, 우 반전을 시켜 10 augmented images를 사용하게 됩니다.
이러한 10 augmented images에 대해 평균을 취하는 방식으로 최종 score를 출력했습니다.
(Softmax의 결과 확률값이 나오는데 각각의 class에서 나오는 10개의 값들에 대해 평균을 취한것이죠).
그렇기 때문에 속도가 매우 느려지게 되는것이죠.
하지만, FC layer를 1x1 conv layer로 대체하고 약간의 큰 사이즈의 이미지를 넣어주고 학습을 시켰고
data augmentation도 horizontal flipping만 적용했는데도 좋은 효과를 얻어냈다고 언급하고 있습니다.
이러한 Fully convolutional network로 구성되어 있을때에는 dense estimation을 적용했다고 하는데요
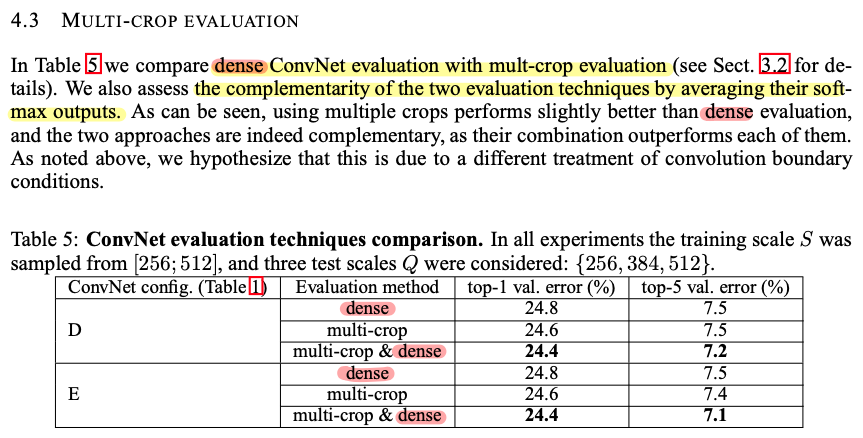
VGGNet 저자는 GoogLeNet에서 사용한 multi-crop 방식이 좋은 성능을 보였다는것을 인지하고 VGGNet에서 사용한 dense evaluation 방식을 보완(complementary)하기 위해 multi-crop evaluation 방식 또한 사용했다고 합니다.
나중에는 multi-crop evaluation과 dense evaluation을 적절하게 섞어 test(validation)을 진행했는데
이러한 방식의 evaluation 기법이 좋은 결과를 내었다고 언급하고 있습니다.

3.3 Implementation Details
4. Classification Experiments
이 부분에서는 실제 classification 실험(experiments) 결과를 보여주고 있습니다.
간단하게 dataset은 ILSVRC를 사용했고, top-1 결과는 multi-class classification error이고
top-5결과는 기존 ILSVRC에서 요구하는 test(evaluation) 기준을 사용했다고 합니다.

대부분 실험에서 validation set을 test set으로 사용하고 있다고 언급하고 있습니다.

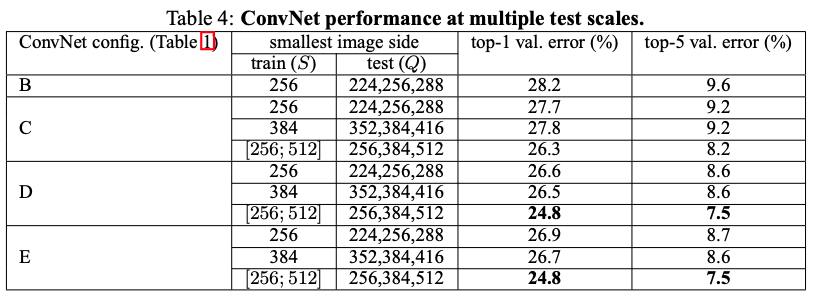
4.1 Single Scale Evaluation
Single scale Evaluation이란 test시 image size(scale)가 고정되어 있는것을 의미 합니다.
앞서 training image size를 설정해주는데 2가지 방식이 있다고 했습니다.
첫 번째는 training image size(S) 256 or 384 로 fix시켜주는 single scaling training 방식과,
256~512 size에서 random하게 골라 multi-scaling training 방식이 있습니다.
Single scaling training 방식을 선택했을때에는 S = Q size로 test image size가 고정(single scale)되고, multi-scaling trailing 방식에서는 0.5 (256+512) = 384로 고정됩니다.

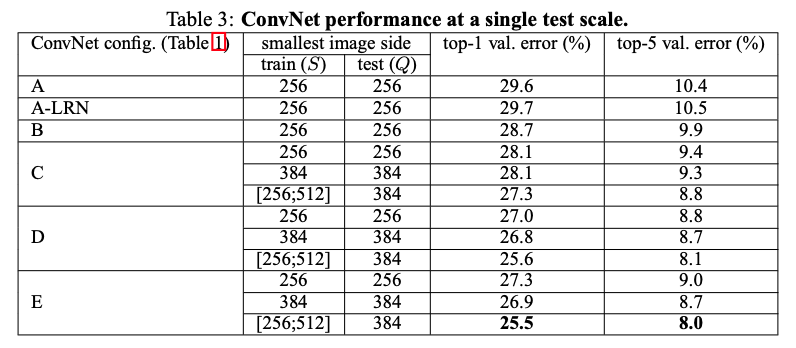
AlexNet에서 사용되는 Local Response Normalization 기법을 사용한 모델 (A-LRN)과 그렇지 않은 모델 (A)간의 성능차가 나지 않았기 때문에 B 모델을 사용할때부터는 LRN을 사용하지 않았다고 합니다.

또한, 아래의 테이블에서 볼 수 있듯이, 1x1 conv filter를 사용하고 있는 C 모델보다 3x3 conv filter를 사용한 D 모델의 성능이 더 좋게 나온것을 알 수 있습니다.
저자는 그 이유를 1x1 conv filter를 사용하면 non linearity를 더 잘 표현할 수 있게 되지만,
3x3 conv filter 가 spatial context (공간 or 위치정보)의 특징을 더 잘 추출해주기 때문에 3x3 conv filter를 사용하는것이 좋다라고 언급하고 있어요. (또한 layer를 19에서 error rate이 정체 되어있다고 이야기하는거 보면 19 layer보다 더 깊이 layer를 쌓고 진행을 했었던거 같아요)


4.2 Multi-Scale Evaluation
Multi-scale evaluation은 test이미지를 multi scale로 설정하여 evaluation한 방식을 이야기 합니다.
그래서 아래 테이블을 보시면 하나의 S 사이즈에 대해 여러 test image로 evaluation을 하는것을 볼 수 있습니다

4.3 Multi-Crop Evaluation
앞서 언급했던 dense evaluation 방식으로 validation을 진행한 결과와 multi-crop evaluation방식으로 validation을 진행한 결과에 대해서 언급하고 있습니다.
또한 multi-crop evaluation결과와 dense evaluation의 평균을 통해 두 방식을 적절하게 섞은 새로운 방식(=ConvNet fusion)으로 validation한 결과를 보여주고 있습니다.
4.4 ConvNet Fusion
4.5 Comparison with the state of the art
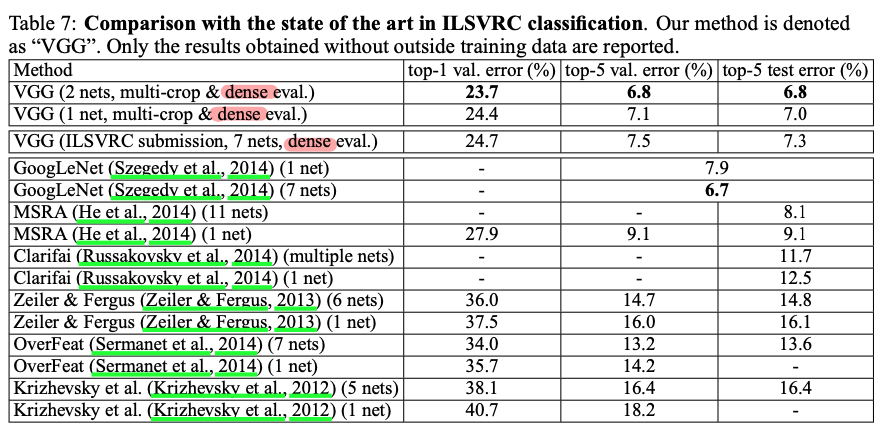
저자는 ILSVRC 대회에 모델성능을 제출할시 7개 모들의 ensemble 기법을 적용했습니다.
나중에 대회가 끝나고 자체 실험에서 단 2개의 모델 (D,E) 만 ensemble한 결과가 더 좋았다고 언급하고 있습니다. (앙상블관련 개념은 아래 영상 or 링크를 참고해주세요)
https://www.youtube.com/watch?v=c62uTWdhhMw

최종적으로 2014 ILSVRC에 출시된 classification 모델들과 경합한 결과를 보여주고 있습니다.
VGGNet 이 대회에서 2등을 차지하게 되었습니다.
5. Conclusion
Reference
https://bskyvision.com/504
https://m.blog.naver.com/laonple/221259295035
https://daechu.tistory.com/10
https://oi.readthedocs.io/en/latest/computer_vision/cnn/vggnet.html
https://velog.io/@dyckjs30/VggNet
https://89douner.tistory.com/61
https://minjoos.tistory.com/6
https://deep-learning-study.tistory.com/398
https://ysbstudy.tistory.com/3
https://arclab.tistory.com/160
https://blog.naver.com/laonple/220738560542
https://blog.naver.com/laonple/220749876381