Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
Abstract
기존의 CNN 아키텍쳐들은 모두 입력 이미지가 고정되어야 했습니다. (ex. 224 x 224) 그렇기 때문에 신경망을 통과시키기 위해서는 이미지를 고정된 크기로 크롭하거나 비율을 조정(warp)해야 했습니다.
하지만 이렇게 되면 물체의 일부분이 잘리거나, 본래의 생김새와 달라지는 문제점이 있습니다.
1. Introduction
💡 "입력 이미지의 크기나 비율에 관계 없이 CNN을 학습 시킬 수는 없을까?"
그림1 SPPNet 핵심 아이디어
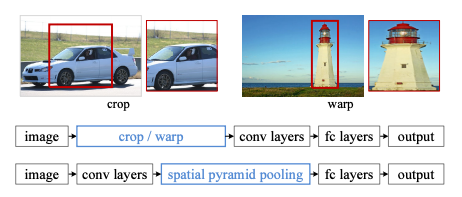
Convolution 필터들은 사실 입력 이미지가 고정될 필요가 없습니다. sliding window 방식으로 작동하기 때문에, 입력 이미지의 크기나 비율에 관계 없이 작동합니다. 입력 이미지 크기의 고정이 필요한 이유는 바로 컨볼루션 레이어들 다음에 이어지는 fully connected layer가 고정된 크기의 입력을 받기 때문입니다. 여기서 Spatial Pyramid Pooling(이하 SPP)이 제안됩니다.
💡 "입력 이미지의 크기에 관계 없이 Conv layer들을 통과시키고, FC layer 통과 전에 피쳐 맵들을 동일한 크기로 조절해주는 pooling을 적용하자!"
입력 이미지의 크기를 조절하지 않은 채로 컨볼루션을 진행하면 원본 이미지의 특징을 고스란히 간직한 피쳐 맵을 얻을 수 있습니다.
또한 사물의 크기 변화에 더 견고한 모델을 얻을 수 있다는 것이 저자들의 주장입니다.
또한 이는 Image Classification이나 Object Detection과 같은 여러 테스크들에 일반적으로 적용할 수 있다는 장점이 있습니다.
전체 알고리즘은 다음과 같습니다.
1. 먼저 전체 이미지를 미리 학습된 CNN을 통과시켜 피쳐맵을 추출합니다.
2. Selective Search를 통해서 찾은 각각의 RoI들은 제 각기 크기와 비율이 다릅니다. 이에 SPP를 적용하여 고정된 크기의 feature vector를 추출합니다.
3. 그 다음 fully connected layer들을 통과 시킵니다.
4. 앞서 추출한 벡터로 각 이미지 클래스 별로 binary SVM Classifier를 학습시킵니다.
(SVM : Support Vector Machine)
5. 마찬가지로 앞서 추출한 벡터로 bounding box regressor를 학습시킵니다.
본 논문의 가장 핵심은 Spatial Pyramid Pooling을 통해서 각기 크기가 다른 CNN 피쳐맵 인풋으로부터 고정된 크기의 feature vector를 뽑아내는 것에 있습니다. 그 이후의 접근 방식은 R-CNN과 거의 동일합니다. 그렇다면 SPP에 대해서 좀 더 자세히 알아보고, Object Detection에서는 어떻게 적용되는 지 알아보겠습니다.
2. Deep Networks with Spatial Pyramid Pooling
2.1 Convolutional Layers and Feature Maps
그림2

conv5 층의 어떤 필터들에 의해 생성된 것임.
그림2-(c) 는 ImageNet dataset에서 이런 필터들에 의해 가장 강하게 activate된 이미지를 보여줌
- Crop/warp를 하지 않았으므로 feature map의 크기가 다름
- 화살표는 feature의 강한 응답을 가리킴
- 필터는 의미가 있는 내용들에 대해 activate됨
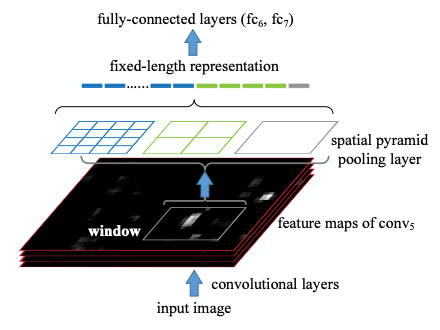
2.2 The Spatial Pyramid Pooling Layer
그림3 Spatial Pyramid Pooling Structure
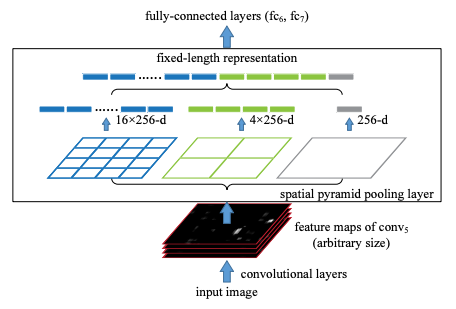
먼저 Conv Layer들을 거쳐거 추출된 피쳐맵을 인풋으로 받습니다.
그리고 이를 미리 정해져 있는 영역으로 나누어 줍니다. 위의 예시에서는 미리 4x4, 2x2, 1x1 세 가지 영역을 제공하며, 각각을 하나의 피라미드라고 부릅니다.
즉, 해당 예시에서는 3개의 피라미드를 설정한 것입니다. 피라미드의 한 칸을 bin 이라고 합니다.
예를 들어 입력이 64 x 64 x 256 크기의 피쳐 맵이 들어온다고 했을 때, 4x4의 피라미드의 bin의 크기는 16x16이 됩니다.
💡 분할 크기 (4-level Spatial Pyramid)
50 bins : {66, 33, 22, 11} → 12,800(25650)-dimension representations
30 bins : {44, 33, 22, 11} → 7,680(25630)-dimension repersentations
→ stride를 각각의 크기 별로 따로 적용하였다.
이제 각 bin에서 가장 큰 값만 추출하는 max pooling을 수행하고, 그 결과를 쭉 이어붙여 줍니다.
입력 피쳐맵의 채널 크기(conv5 layer에서 출력한 feature map의 filter 수)를 k, bin의 개수를 M(사전의 설정한)이라고 했을 때 SPP의 최종 아웃풋은 kM 차원의 벡터입니다.
위의 예시에서 k = 256(채널 크기), M = (16(44) + 4(22) + 1(1*1)) = 21 이 됩니다.
SPP layer는 256 * 21차원의 벡터를 출력합니다.
정리해보면 입력 이미지의 크기와는 상관없이 미리 설정한 bin의 개수와 CNN 채널 값으로 SPP의 출력이 결정되므로, 항상 동일한 크기의 결과를 리턴한다고 볼 수 있습니다.
이를 통해 다양한 입력 이미지 크기를 입력받아 다양한 feature map size가 생성되고 SPP layer를 거쳐서 고정된 크기의 벡터가 생성됩니다.
실제 실험에서 저자들은 1x1, 2x2, 3x3, 6x6 총 4개의 피라미드로 SPP를 적용합니다.
💡 1. Convolution 을 거친 feature map들을 input으로 받음
2. 피라미드 라고 부르는 각각의 영역으로 나누어줌 (위 그림에선 4x4, 2x2, 1x1)
3. 각각의 영역에서 max pooling을 수행 후 이를 이어붙힌다.
4. 최종 output은 kM차원의 벡터 / k = 256, M = (16 + 4 + 1) = 21
입력 사이즈가 다양하므로 conv5에서 출력하는 feature map의 크기도 다양하게 됩니다.
다양한 feature에서 pooling의 window size와 stride 만을 조절하여 출력 크기를 결정합니다.
window size = ceiling(feature map size / pooling size)
stride = floor(feature map size / pooling size) 로 계산하면 어떠한 feature map 크기가 오더라도 고정된 pyramid size를 얻을 수 있습니다.
2.3 Training the Network
그림4 13x13 feature map에서 각각의 pooling의 window size, stride를 계산한 표

[pool3x3]의 window size = ceiling(13 / 3) = 5, stride = floor(13 / 3) = 4 로 설정되었습니다.
💡 Single-size training = 224x224 size {3x3, 2x2, 1x1} SPP 사용
Multi-size training = 180x180, 224x224 size 학습
180-Network와 224-Network의 출력은 동일하다.
→ 나누고, 평균을 구해서 뽑기 때문이다.
입력 이미지의 크기와는 상관없이 미리 설정한 bin의 개수와 CNN 채널 값으로 SPP의 출력이 결정되므로, 항상 동일한 크기의 결과를 리턴한다고 볼 수 있습니다.
→ Network Switching 방법 : Epoch 1은 180-Network, Epoch 2는 224-Network의 과정을 반복
SPPnet을 거친 feature에 softmax를 수행하여 분류에 사용
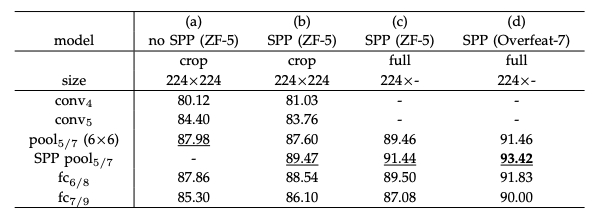
테이블1

ZFNet과 AlexNet은 Convolution Layer가 5개.
추가 자료. SPPNet 작동 방식
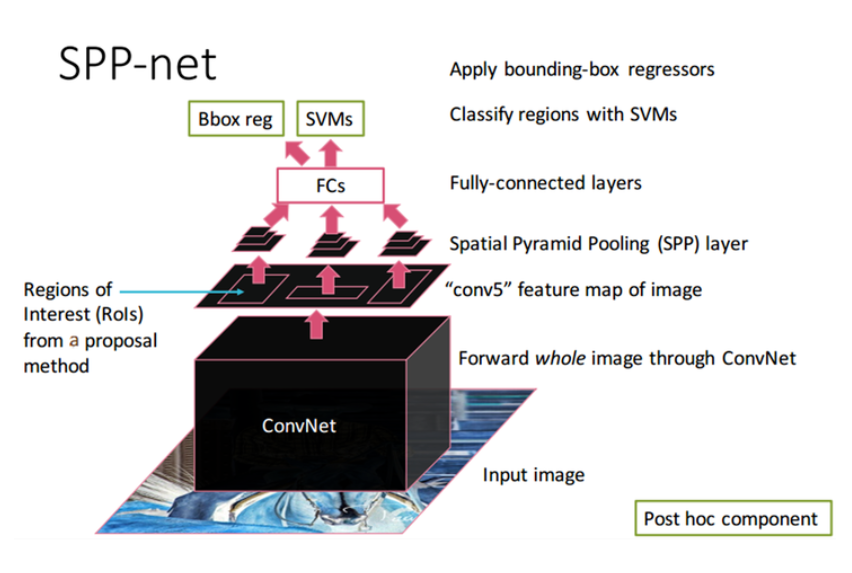
- Selective Search를 사용하여 약 2000개의 region proposals를 생성합니다.
- 이미지를 CNN에 통과시켜 feature map을 얻습니다.
- 각 region proposal로 경계가 제한된 feature map을 SPP layer에 전달합니다.
- SPP layer를 적용하여 얻은 고정된 벡터 크기(representation)를 FC layer에 전달합니다.
- SVM으로 카테고리를 분류합니다.
- Bounding box regression으로 bounding box 크기를 조정하고 non-maximum suppression을 사용하여 최종 bounding box를 선별합니다.
3. SPP-Net for Image Classification
3.1 Experiments on ImageNet 2012 Classification
3.1.1 Baseline Network Architectures
3.1.2 Multi-level Pooling Improves Accuracy
테이블2
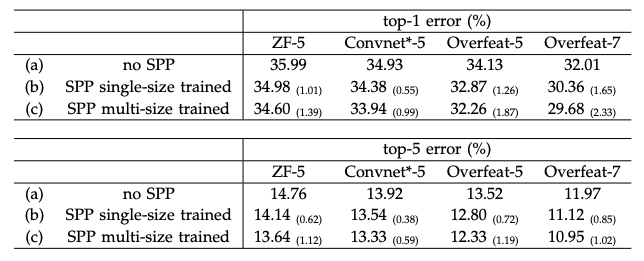
SPP를 적용한 모델과 그렇지 않은 모델의 비교이다. CNN의 구조와 관계 없이 보장된 성능 향상을 보여준다. Multi-size로 훈련한 모델이 성능이 더 좋다.
테이블3
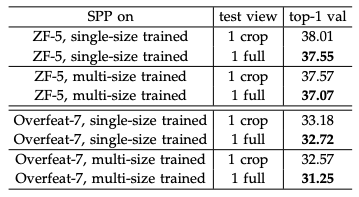
Input size에 제한이 없기 때문에 cropping이나 warpping 을 거치지 않은 full-image를 넣는 것이 가능하다. 위의 표를 보면 full-image를 넣은 경우가 성능이 더 좋은 것을 확인할 수 있다.
3.1.3 Multi-size Training Improves Accuracy
3.1.4 Full-image Representations Improve Accuracy
3.1.5 Multi-view Testing on Feature Maps
테이블4
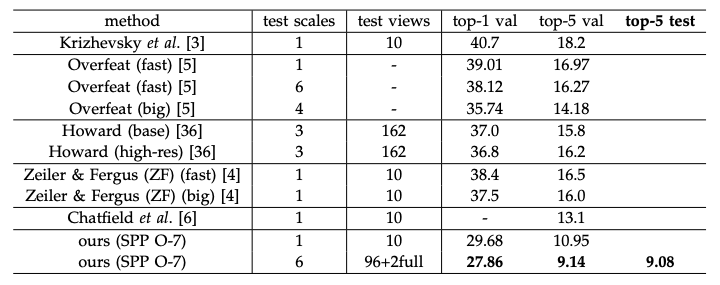
3.1.6 Summary and Results for ILSVRC 2014
테이블5
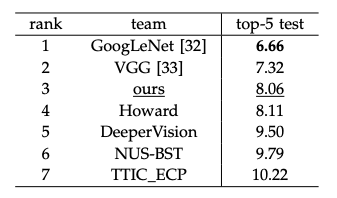
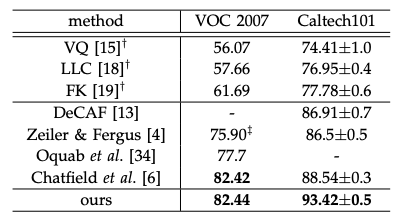
3.2 Experiments on VOC 2007 Classification
테이블6
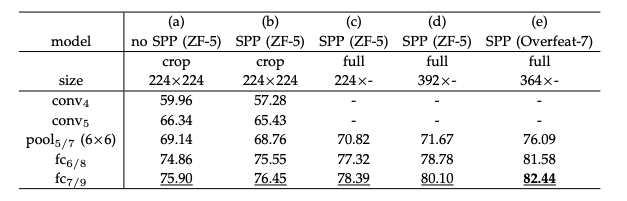
테이블7
3.3 Experiments on Caltech101
테이블8
4. SPP-NET FOR OBJECT DETECTION
그림5 SPP in Object Detection
Object Detection에 SPP를 적용할 수 있습니다. 먼저 저자들은 R-CNN의 문제점을 지적하며 SPP를 이용한 더 효율적인 object detection을 제안합니다. R-CNN은 Selective Search로 찾은 2천개의 물체 영역을 모두 고정 크기로 조절한 다음, 미리 학습된 CNN 모델을 통과시켜 feature를 추출합니다. 때문에 속도가 느릴 수 밖에 없습니다.
반면 SPPNet은 입력 이미지를 그대로 CNN에 통과시켜 피쳐 맵을 추출한 다음, 그 feature map에서 2천개의 물체 영역을 찾아 SPP를 적용하여 고정된 크기의 feature를 얻어냅니다. 그리고 이를 FC와 SVM Classifier에 통과시킵니다.
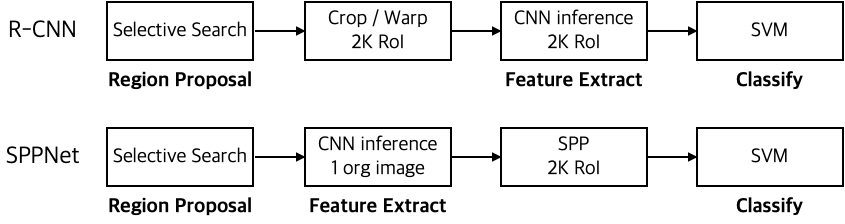
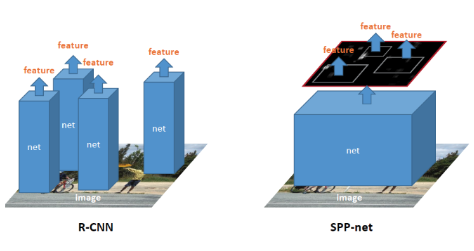
💡 R-CNN은 Selective Search로 찾은 2000개의 영역을 모두 고정 크기로 조절한 후, CNN 모델을 통과시켜 feature를 추출함
→ 때문에 시간이 오래 걸린다는 단점이 발생한다.
SPPNet은 입력 이미지를 그대로 CNN에 통과시켜 feature map을 추출한 후 feature map에서 2000개의 영역을 찾아 SPP를 적용하여 고정된 크기의 feature를 얻어냄
→ SPPNet은 CNN을 이미지에 한번만 적용하여 속도가 빠르다.
→ CNN으로 생성된 feature map에서 selective search를 적용하여 생성된 window에서 특징을 추출합니다.
→ feature map에서 임의의 크기 window로 특징 추출이 가능합니다.
→ 입력 이미지의 scale, size, aspect ratio에 영향을 받지 않습니다.
4.1 Detection Algorithm
4.2 Detection Results
테이블9
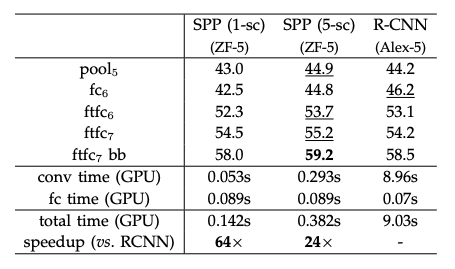
테이블10

비슷한 성능을 보여주지만 SPP를 적용하는 편이 속도가 훨씬 빠르다.
4.3 Complexity and Running Time
테이블11
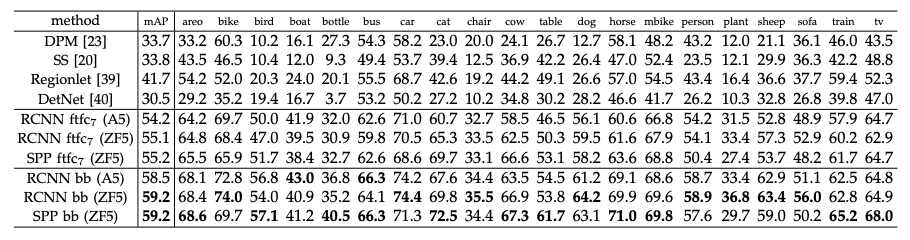
테이블12

4.4 Model Combination for Detection
4.5 ILSVRC 2014 Detection
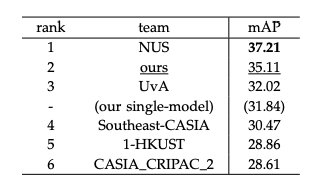
테이블13
5. CONCLUSION
그림6

SPPNet은 다른 크기, 다른 사이즈, 다른 종횡비를 다루기 위한 유연한 방법이다.
Classification과 Detection에서 높은 정확성, 특히 DNN 기반의 Detection을 크게 빠르게 해주었다.
한계점
SPPNet은 기존 R-CNN이 모든 RoI에 대해서 CNN inference를 한다는 문제점을 획기적으로 개선하였지만 여전히 한계점이 있습니다.
-
end-to-end 방식이 아니라 학습에 여러 단계가 필요하다. (fine-tuning, SVM training, Bounding Box Regression)
-
여전히 최종 클래시피케이션은 binary SVM, Region Proposal은 Selective Search를 이용한다.
-
fine tuning 시에 SPP를 거치기 이전의 Conv 레이어들을 학습 시키지 못한다. 단지 그 뒤에 Fully Connnected Layer만 학습시킨다.
여기서 세 번째 한계점에 대해서 저자들은 "for simplicity" 라고만 설명이 되어 있습니다. 이 뒤에 이어지는 Fast R-CNN 논문에서는 앞서 언급된 SPPNet의 한계점을 대폭 개선한 접근 방법이 소개됩니다.
Refererce
https://n1094.tistory.com/30
https://deep-learning-study.tistory.com/445
https://blackchopin.github.io/imagerecognition/Pyramid_pooling/
https://yun905.tistory.com/19
https://throwexception.tistory.com/1237
https://yeomko.tistory.com/14