Visualizing and Understanding Convolutional Networks
Matthew D. Zeiler, Rob Fergus
Abstract
Large Convolutional Network model들은 ImageNet bench-mark에서 인상적인 분류성능을 보여주었다. 그러나 이러한 모델들이 왜 좋은 성능을 보이는지, 또는 어떻게 그것이 개선될 수 있는지에 대한 명확한 이해를 없기 때문에 이러한 문제를 해당 논문에서 다룬다.
Matthew D. Zeiler의 연혁
Matthew Zeiler는 뉴욕대를 다니는 동안 CNN을 보다 잘 이해할 수 있는 “Visualizing 기법”을 최초로 개발했으며, 2011년에 “Adaptive Deconvolutional Networks for Mid and High-level Feature Learning” 이라는 논문을 발표한다.
출처 : Part Ⅴ. Best CNN Architecture 4. ZFNet_1 라온피플 머신러닝 아카데미
ZFnet이란?
CNN, 특히 layer가 여러 개인 DNN의 경우, 무슨 원리로 그렇게 좋은 결과를 낼 수 있는지, CNN의 구조를 결정하는 hyper-parameter는 어떻게 설정을 할 것인지, 또는 자신들이 개발한 구조가 과연 최적인지 판가름하는 것은 너무 어렵다.
AlexNet의 경우 2개의 GPU를 사용하여 학습을 하는데 일주일 이상이 걸리는데, 10개가 넘는 hyper-parameter의 조합 중 최고를 찾아낸다는 것아 과연 가능한 일일까?
좋은 결과는 얻었지만, 이론적으로 설명하기가 어렵고, 최적의 구조인지도 확신할 수도 없는 상황이기 때문에 뭔가 CNN을 보다 잘 이해할 수 있는 수단이 필요했으며, Matthew Zeiler는 이것을 “Visualizing 기법"을 사용하여 해결하려는 시도를 하였다.
이것에 관련된 주요 개념은 2011년에 이미 발표를 하였으며, 2012년 AlexNet의 결과가 reference로 만들어지자, 2013년 논문 발표를 통해 자신들의 연구 결과가 효과적임을 입증하였다.
이후 많은 연구자들이 Zeiler의 논문에 자극을 받아 “Visualizing 기법”을 변형/발전 시키는 논문을 발표하게 된다.
이 중 2개만 소개하면 아래와 같다.
- Visualizing Convolutional Neural Networks for Image Classification (2015, Danel Brukner)
- Delving Deep into Convolutional Nets (2014, Ken Chatfield)
어찌보면, ZFNet은 특정구조를 가리키는개념이 아니라, CNN을 보다 잘 이해할 수있는기법을 가리키는개념으로 이해하는 것이 좋을것 같다.
실제 논문에서도 새로운 구조를 발표했다기 보다는 AlexNet의 기본 구조를 자신들의 Visualizing 기법을 통해 개선할 수 있음을 보여줬다.
결과적으로 보면, 많은 수의 hyper-parameter를 최적화 함에 있어 시간이나 기타 다른 이유로 인해, AlexNet 연구자들이 더 좋은 구조를 설계할 수 있음을 보임으로써 자신들의 연구의 탁월함을 보여준 셈이 된다.
출처 : Part Ⅴ. Best CNN Architecture 4. ZFNet [1] - 라온피플 머신러닝 아카데미
작성자 : AI VISION 라온피플
ZFnet - Deconvolution을 이용한 Visualization
CNN의 동작을 잘 이해하려면, 중간 layer에서 feature의 activity가 어떻게 되는지를 알 수 있어야 한다. 그런데 중간 layer의 동작은 보기가 어려우니, 이 activity를 다시 입력 이미지 공간에 mapping을 시키는 기법이 바로 “Visualizing 기법”의 핵심이 된다.
CNN 구조는 여러 개의 convolutional layer를 기반으로 하고 있는데, 중간 단계 layer에서는 이전 feature map으로부터 데이터를 받아, 그것에 대해 filtering(convolution)을 수행하여 현단계의 feature-map을 만들어내고,정류(ReLU) 장치를 통과 시킨 후, Pooling을 수행하는 아래 그림과 같은 방식을 취한다.
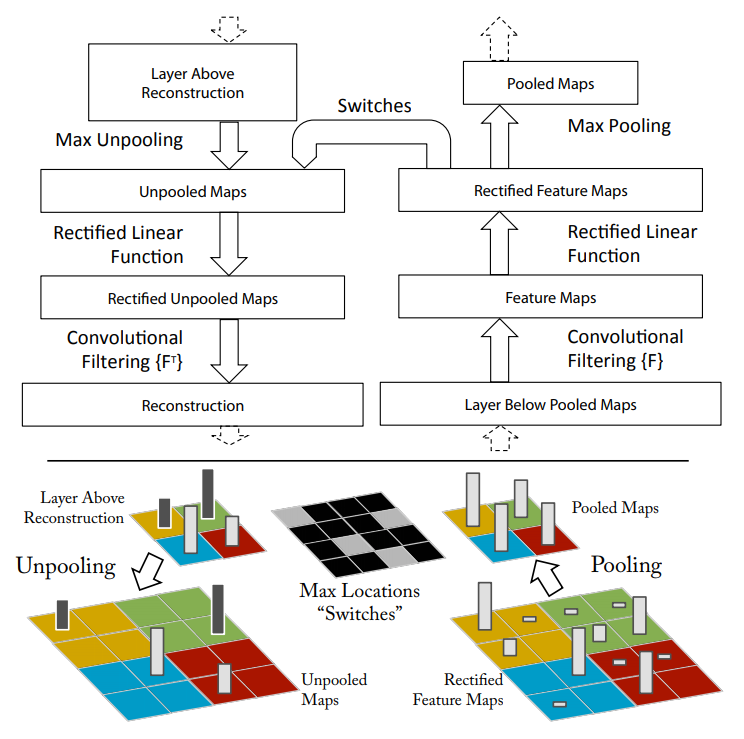
특정 feature의 activity가 입력 이미지에서 어떻게 mapping 되는지를 이해하려면, 위 과정을 역(reverse)으로 수행하면 된다.
그런데 여기에서 가장 문제가 되는 부분이 max-pooling 에 대한 역(reverse)를 구하는 것이다.
Max-pooling 단계는 주변에서 가장 강한 자극만을 다음 단으로 전달을 하기 때문에, 역방향으로 진행을 할 때는 어떤 위치에 있는 신호가 가장 강한 신호인지 파악할 수 있는 방법이 없다.
여기에서 ZFNet 개발팀의 번득이는 아이디어가 들어가게 된다.
이 사람들은 “switch”라고 명명한 개념을 생각해냈다.
이 switch는 가장 강한 자극의 위치 정보를 갖고 있는 일종의 꼬리표(flag)라고 보면 된다.
가장 강한 자극의 위치 정보를 갖고 있기 때문에, 역으로 un-pooling을 수행할 때는 switch 정보를 활용하여 가장 강한 자극의 위치로 정확하게 찾아갈 수 있다.
원래는 가장 강한 자극 이외의 값들도 있었지만, max-pooling을 수행하면서 사라졌기 때문에,
이 방법의 단점은 가장 강한 자극(feature)에 대한 영향만 파악이 가능하다는 점이다.
아래 그림을 보면, 녹색 화살표가 가리키는 자극은 강하지 않기 때문에 max-pooling을 수행하면서 오른쪽 빨간색 화살표처럼 사라진다.

다음 과정은 ReLU의 역과정을 수행하여야 하는데, ReLU의 경우 앞선 클래스에서도 살펴봤지만, 음의 값을 갖는 것들은 0으로 정류(rectify) 하고 0이상 값들은 그대로 pass 시키기 때문에, 역과정을 수행할 때 양의 값들은 문제가 없고, 0 이하의 값들만 정류되었기 때문에 복원할 방법이 없다.
그렇지만 이들의 연구 결과에 따르면 영향이 미미 하다고 한다.
다음 과정은 filter에 대한 inverse filter 연산을 수행하는 것이다.
이 과정은 가역이 가능한 과정이기 때문에 특별히 문제가 될 것이 없다.
이렇게 Deconvolution을 수행하면, 정확하게 입력과 같은 상태로 mapping이 되는 것은 아니지만, 가장 강한 자극(feature)가 입력 영상에 어떻게 mapping되는지를 확인할 수 있으며, 이렇게 결과를 시각적으로 확인을 할 수 있기 때문에 CNN에 대하여 더 잘 이해를 할 수 있고, 한 걸음 더 나아가 어떤 구조가 최적의 구조인지를 좀 더 잘 결정할 수 있게 된다.
중간 피처 레이어(intermediate feature layer)의 기능과 분류기의 작동(operation)에 대한 통찰력을 제공하는 새로운 시각화 기술을 소개한다. 이러한 시각화를 통해 Krizhevsky 등을 능가하는 모델 아키텍처를 찾을 수 있다.
해당 저자는 성능 기여를 발견하기 위해서 하나씩 레이어를 제거하는 과정을 거쳤다.
소프트맥스 분류기가 재교육되면 Caltech-101 및 Caltech-256 데이터 세트에서 최신 결과를 설득력 있게 능가한다.
1. Introdution
1990년대 LeCun의 연구를 통해서 CNN이 손글씨 인식이나 face detection등의 task에 우수한 성능을 보인 것이 소개됨
2012년에 Alexnet이 PASCAL VOC 데이터 셋에 대하여 차등모델에 비해 약10%나 향상된 정확도를 보였는데,
극적인 성능향상은 다음의 세가지 요인에 의하여 이루어질 수 있었음
-
레이블링된 수백만개의 샘플들로 구성된 굉장히 큰 규모의 학습셋 제공이 가능해짐 (빅데이터의 제공)
-
강력한 GPU파워가 제공되어 굉장히 큰 규모의 모델들의 학습이 practical해짐.
-
Dropout과 같은 모델을 Regularization(정규화)하는 좋은 전략들이 연구됨
이러한 진보적인 발전에 비하여 이러한 복잡한 모델들이 어떻게 behavior하고 어떻게 좋은 성능을 얻는지, 내부적으로 어떻게 동작하는지에 대한 Insight(통찰력)가 굉장히 부족함
위와 같은 이유로 인해서, 기존의 개발은 시행착오(trial-and-error)를 거쳐가며 진행할 수 밖에 없었지만, 시각화(visualization technique)를 사용함으로써 극복하였다고, 해당 논문에서 언급하고 있으며, 이들이 제안하는 시각화 기법은 Zeiler가 제안한 Deconvolution Network를 사용하여 입력 Pixel 공간에 feature activation(기능 활성화)을 투영시키는 방법
분류를 하는데 어느 부분이 중요한 역할을 하는지 알기 위해 입력 이미지의 일부를 가리고(occlude) 분류기의 출력이 얼마나 민감하게 변화하는지 분석하는 연구를 수행함
1.1 Related Work
네트워크의 내부를 직관적으로 알기위해서 시각화가 많이 사용되나, 대부분 Pixel공간으로 투영이 가능한 1번째 layer에 제한이 되어있다.
상위레이어를 시각화 하는 방법 중 하나는 unit의 activation(활성화)을 최대화 하기 위하여 이미지 공간의 gradient descent(경사 하강 법)를 수행하여 각 unit의 최적의 stimuli(자극)를 찾아내는 것이지만, careful initialization(신중한 초기화)이 요구되며, unit의 불변*에 대한 어떠한 정보도 제공받지 못하는 단점이 있다.
Unit's Generalization
패턴인식의 관점에서 Ideal한 feature란 robust하고 selective한 feature를 말합니다. Hidden layer의 Unit들은 feature detector로 해석될 수 있으며, 이는 hidden unit이 표현하는 feature가 현재 입력에 존재하는 경우 strongly respond하고 현재 입력에 부재하는 경우 weakly respond하는 경향을 보이는 것을 의미합니다.
Invariant 한 뉴런이라는 것은 입력이 특정 변환들을 거치게 되더라도 해당 feature로의 high response를 유지하는 것을 의미합니다. ( 예를 들면, 어떤 뉴런이 얼굴의 특징을 탐지하는 뉴런이라고 할때, 얼굴이 Rotate되더라도 response를 잘 해내는 것이라고 할 수 있습니다. )
Measuring Invariances in Deep Networks_논문 참고
상위레이어를 시각화 하는 또 다른 연구로, 주어진 unit의 Hessian이 최적의 response에 얼마나 수치적으로 연산될 수 있음으로써 invariance(불변)함에 대한 insight(통찰력)를 제공해주는지에 대한 연구가 있었음 (상위 레이어들에 대해 invariance(불변)함이 너무 극도로 복잡하여 단순한 2차 근사로는 계산해내기가 굉장히 어려운 문제가 있음)
본 논문에서는 학습 데이터셋에 대하여 어떤 패턴이 feature map을 activate시키는지 보이기 위해 invariance(불변)를 non-parametric(비모수)한 관점에서 제공한 기법을 연구함
본 논문의 관점은 본 논문에서 사용하는 Convolution layer 대신 Convnet의 Fully connected layer로부터 투영하여 saliency map을 얻는 기법과 상당히 유사하다고 볼 수 있음
2. Approach
본 논문에서는 표준 fully supervised convent모델인 Alexnet을 사용함
2.1 Visualization with a Deconvnet
CNN의 동작을 이해하기 위해서는 중간의 hidden layer들의 feature activity에 대한 해석이 요구됨에 따라서, 이러한 activity들을 input space로 다시 mapping시키는 Deconvolutional Network에 기반한 기법을 보임
Deconvnet은 convnet과 같은 component(filtering, pooling)등을 사용하지만 역으로 수행되는 네트워크.
즉, pixel이 feature로 mapping되는 과정의 반대과정이라고 생각하면 됨
그림 1. Unpooling을 통해 feature map을 image로 reconstruction하는 과정
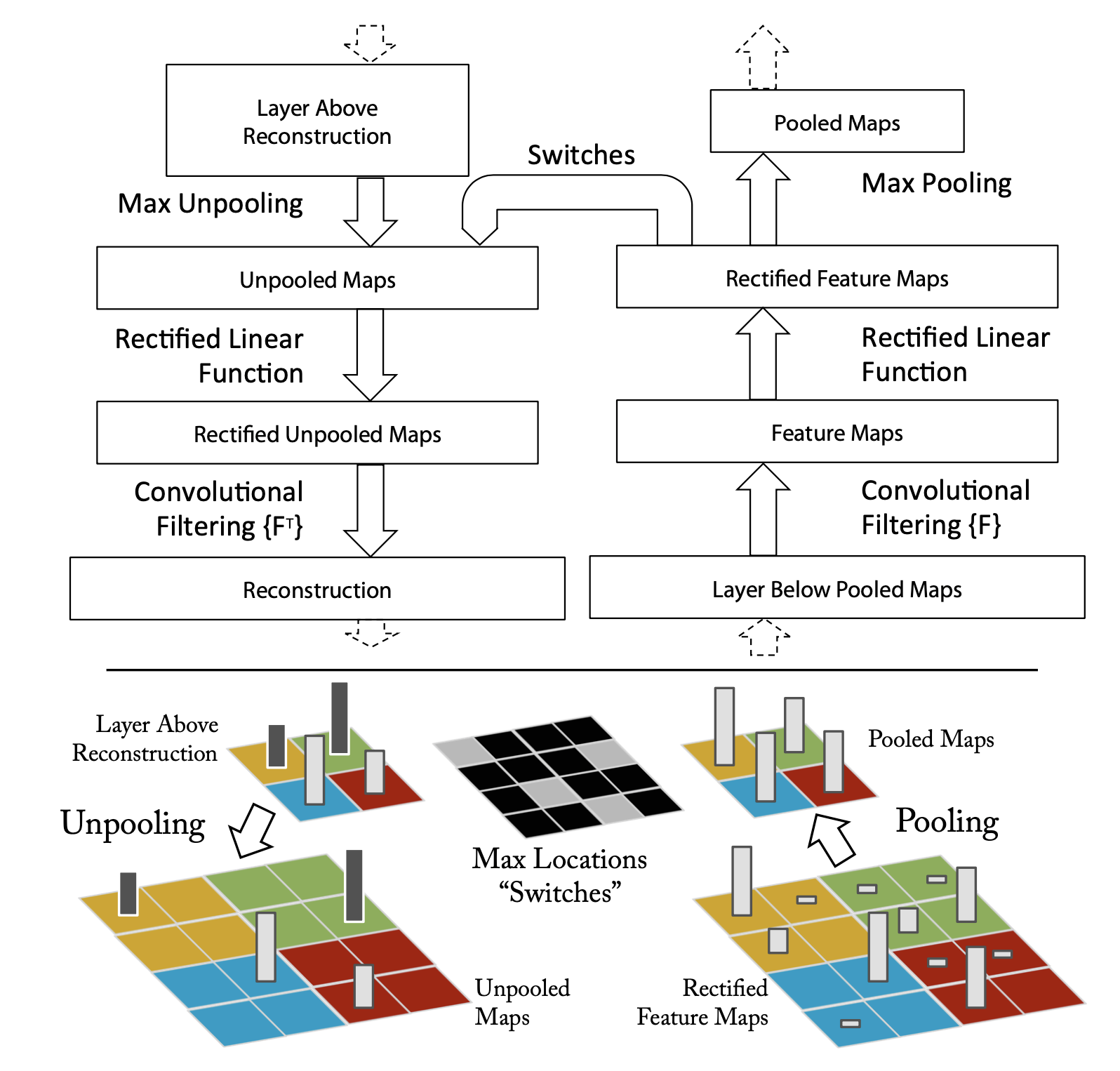
Convnet을 examine하기 위하여, deconvnet이 각각의 layer에 부착되며(그림 1 참고), Image pixel들까지 다시 되돌아오는 경로가 제공됨
시각화 과정 순서
- 입력 Image가 convnet에 제공되고 feature가 각 layer를 통과하여 계산됨.
- 주어진 convnet의 activation을 examine하기 위해서 layer 내의 모든 activation들을 0으로 setting하고 feature map을 통과하게함으로써 부착된 deconvnet layer의 입력이 되도록 함
- Unpooling을 수행
- Rectification을 수행
- Filtering을 수행하여 layer아래의 activity들을 reconstruct해줌으로써 선택된 activation의 시각화를 수행
1. Unpooling
Convnet에서 Maxpooling 연산은 non-invertible(역을 계산할 수 없는)한 연산
→ Maxpooling은 영역 내의 가장 큰 값을 취하고 나머지는 버리는 연산이기 때문에, 이에 대한 역으로의 연산은 정보의 소실로 불가능
하지만, 각 pooling 영역의 maxima값의 location(위치) 정보들을 저장한 것을 switch variable(스위치 변수)의 집합이라고 표현하는데 이 set of switch variables(스위치 변수 세트)를 기록함으로써 inverse(역)를 근사하는 값을 얻어낼 수 있음.
Deconvnet에서 Unpooling 연산은 이러한 switch들을 layer로부터 reconstruction(재건)하는 과정에서 적절한 위치를 잡게 해줌으로써 stimulus(자극)의 구조를 보존하도록 하는 역할을 함
2. Rectification
본 논문에서 사용한 Convnet은 비선형 relu 함수로써, feature map들이 rectify(바로 잡다) 됨으로써 feature map들이 항상 positive한 상태를 보장 받음 따라서 각 레이어에 대한 유효한 feature reconstruction(기능 재구성)을 얻기 위해서는 비선형함수인 relu에 reconstruct(재구성)된 신호를 통과시켜야함
3. Filtering
Convnet은 이전 layer로부터 feature map들을 convolve하기 위해 학습된 filter들을 사용 이를 근사하게 inverse(역) 하기 위하여 deconvnet은 같은 filter들의 transposed(전치)된 버전을 사용(Auto encoder나 RBM같은)
하지만, 레이어 아래의 출력이 아니라 rectified(정류)된 map들에 적용
(이는 각 필터를 수직과 수평적으로 flipping하는 것을 의미)
Unpooling의 과정에 대한 예시.
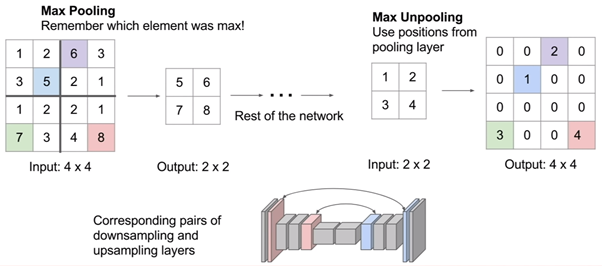
Transpose의 과정을 나타내는 그림.

3. Training Details
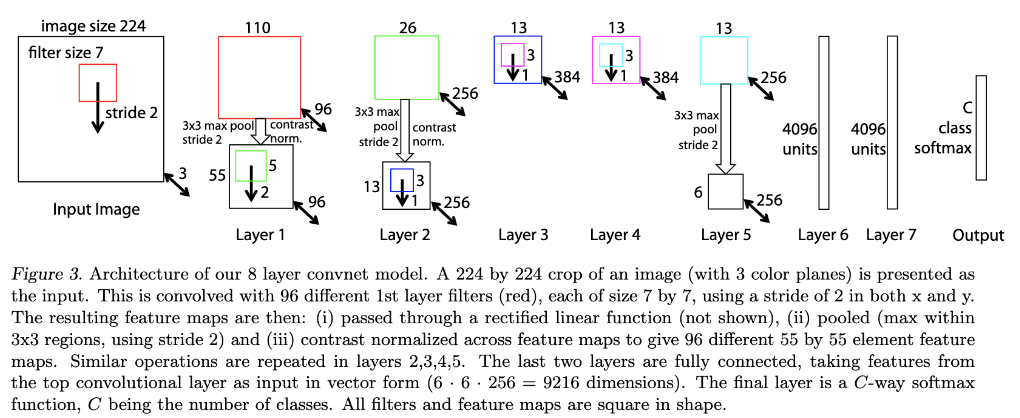
- ImageNet 데이터셋의 분류 수행을 위하여 AlexNet모델을 사용
(단, 3,4,5번째 레이어의 sparse connection을 dense connection으로 대체함) - AlexNet모델은 ImageNet 2012데이터셋을 기반으로 학습 (1.3m개의 이미지, 1000개 클래스)
- 입력크기는 256x256으로 먼저 cropping을 수행한 후, 224x224로 sub cropping을 수행
- 128 minibatch size를 기반으로 SGD로 학습, learning rate은 0.01로 두고 annealing(가열 냉각)을 함
- 학습하는 도중 첫번째 레이어의 시각화를 수행하면, 일부가 dominate(지배)하는 것을 확인할 수 있음
→ 이를 해결하기 위해 convolutional layer의 각 filter를 renormalize(재 정규화)함 - 70 epoch이후 학습을 멈추고 12일간 GTX580으로 학습시킴
4. Convnet Visualization
아래의 Figure 2.는 각 layer별 얻은 feature map에서 가장 강한 특징 9개만을 보여주며, 그에 해당하는 원본 이미지를 보여주고 있습니다. 각 layer별 학습이 되면서 어떤 feature를 추출하는지 알 수 있으며 다음과 같습니다.
- Layer 1,2 : edge나 color처럼 low-level feature를 시각화 하고 있습니다.
- Layer 3 : 더 복잡한 invariance(항상성)를 가지거나, texture를 보여주는 feature에 대해 시각화 하고 있습니다.
- Layer 4 : 사물이나 개체의 일부분을 보여주는 feature를 시각화 하고 있습니다. (개의 얼굴, 새의 다리)
- Layer 5 : 사물이나 개체의 위치 및 자세 변화를 포함하는 전체 모습을 시각화 하고 있습니다.
Layer 1 ( lower-level feature ) ~ Layer 5 (high-level feature)
그림2

4.1 Architecture Selection
4.2 Occlusion Sensitivity
4.3 Correspondence Analysis
1) AlexNet 3,4,5 sparse connection을 dense connection으로 변경
2) 1st layer filter size, stride 변경
- filter size: 11x11 -> 7x7
- stride: 4 -> 2 또한 layer 6,7에 Dropout(0.5)를 적용하였습니다. 그 외의 하이퍼 파라메터입니다.
- learning rate : 0.01
- momentum : 0.9
- initialization of all weights : 0.01, biases : 0
아래의 Figure 4.에서 알 수 있듯이 layer가 깊어질 수록 feature 생성 및 시각화 되려면, 학습 epochs가 어느 정도 진행되어야 함을 보여주고 있습니다. 40 epochs이상 되어야 feature가 선명해지고 있는데, 이러한 시각화를 통해 학습에 적절한 epochs 수도 결정할 수 있게 됩니다. ZFNet에서는 70 epochs까지 학습을 진행하였습니다.

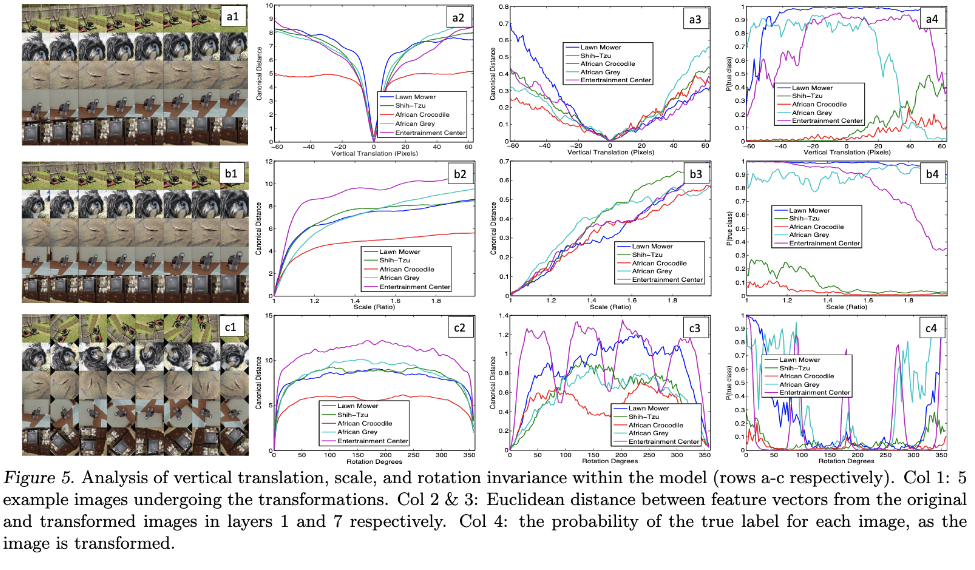
Figure 5.를 보면 이동, 크기, 회전에 있어서도 CNN의 특징중 하나인 invariance한 특성을 볼 수 있습니다. 마지막 layer로 갈수록 이동, 크기, 회전에 큰 영향을 받지 않고, 원본 이미지가 어떤 것인지 식별하게 됩니다. 유클리디안 거리를 원본과 변환된 이미지에 대해 측정한 결과 초반 layer단에서는 거리가 큰값이 나오지만 마지막 layer로 갈수록 거리값이 작아지는 것을 볼 수 있습니다
AlexNet 대비 아키텍쳐 구조를 변경하면서 성능 향상을 시도하였는데, 아래의 Figure 6. 처럼 layer 1의 filter size, stride를 변경후 시각화된 feature를 보면 AlexNet대비 feature수가 (b), (c)비교에서 알 수 있듯이 증가하였습니다. 그리고 (d), (e) 처럼 feature들이 선명해지고, anti-aliasing 현상이 없어지는 것을 볼 수 있습니다.

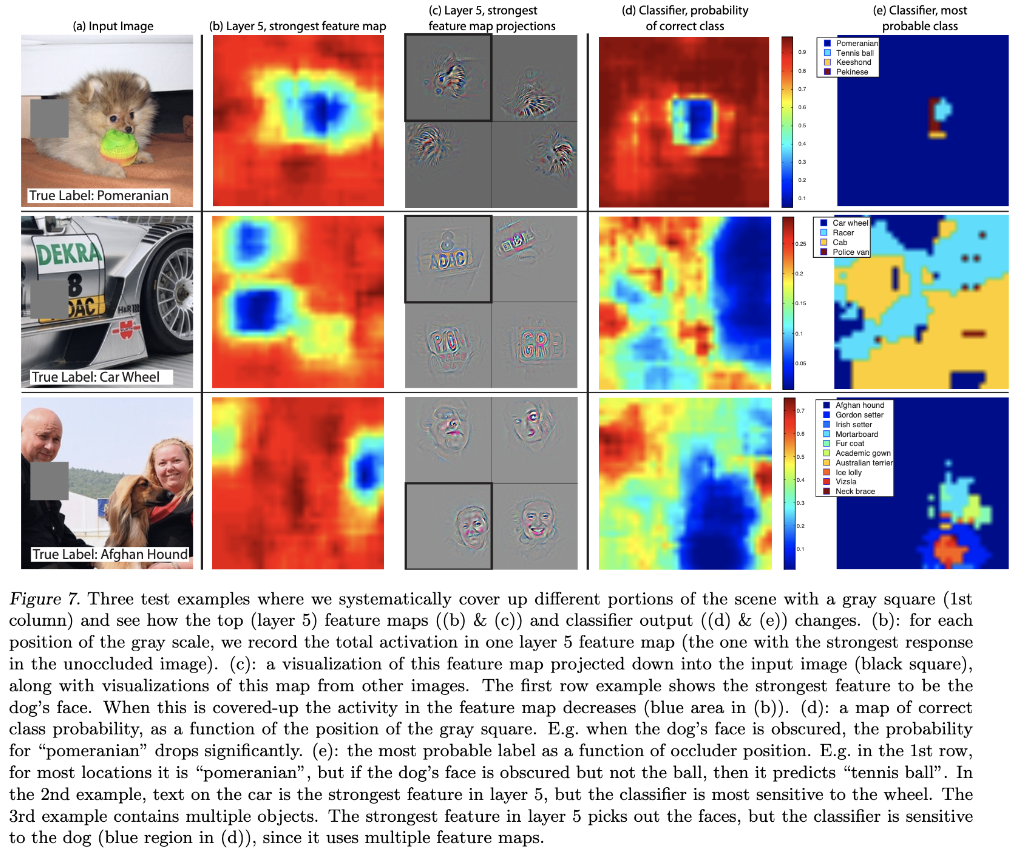
또한 아래의 그림7에서 볼 수 있듯이, 이미지에 있어서 개체의 위치를 인식하는지도 본 논문에서는 실험하였는데, 이미지를 대표하는 특징이 있는 부분을 회색 박스로 가리면, 인식율이 떨어짐을 확인하였습니다. (Figure 7)[
5. Experiments
5.1 ImageNet 2012
5.2 Feature Generalization
5.3 Feature Analysis
6. Discussion
Acknowledgments
References
https://blog.naver.com/laonple/220673615573
https://arclab.tistory.com/164
https://deepapple.tistory.com/14
https://wiserloner.tistory.com/1150
https://dataplay.tistory.com/29