OverFeat : InIntegrated Recognition, Localization and Detection using Convolutional Networks
Paper review
💡 Dense evaluation은 Yann LeCun의 지도하에 Pierre Sermanet이 발표한 논문 “OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks”에 처음 소개가 되었다.
CNN의 classifier로 흔히 사용되는 Fully-connected layer를 1x1 convolution 개념으로 사용하게 되면, 고정된 이미지뿐만 아니라 다양한 크기의 이미지를 sliding window 방식으로 처리할 수 있으며, feature extraction 블락의 맨 마지막 단에 오는 max-pooling layer의 전후 처리 방식을 조금만 바꾸면, 기존 CNN 방식보다 보다 조밀하게(dense) feature extraction, localization 및 detection을 수행할 수 있게 된다. 물론 multi-crop 방식보다 연산량 관점에서 매우 효율적이다.
Author : Pierre Sermanet, David Eigen, Xiang Zhang, Michael Mathieu, Rob Fergus, Yann LeCun
Abstract
OverFeat과 다른 알고리즘 비교
OverFeat은 classification, localization 및 detection에 대한 통합 프레임워크를 제공하는 것을 목표로 개발이 되었으며, 2013년 ILSVRC 대회에서 localization 부문에서 1위를 차지하였고, classification과 detection 분야에서도 우수한 성적(각각 4위와 3위)을 보였다.
2012년 ILSVRC에서 우승을 차지한 AlexNet은 classification 분야는 상세한 설명을 하고 있지만, localization에 대한 설명은 거의 없으며, 2013년부터 새롭게 대회에 추가된 detection 분야는 고려하고 있지 않다.
OverFeat 설계팀은 classification, localization 및 detection 각 분야에 ConvNet을 효과적으로 사용할 수 있음을 보여주는 것을 논문의 목표로 삼았다. 실제로 2013년에 ILSVRC에서 3분야에 모두 출전한 팀은 OverFeat 팀이 유일하다.
그런데 Classification 분야에서는 뒤에 GoogLeNet, VGGNet 및 ResNet과 같은 구조가 속속 발표되면서 역시 관심에서 멀어지게 된다.
또한 시기적으로는 OverFeat의 발표시점보다 늦지만, 2013년에 발표된 R-CNN이 selective search 방법을 적용하여 OverFeat보다 큰 성능차를 보이면서, OverFeat의 가치가 빛을 잃게 된다.
OverFeat는 1-pass로 연산이 가능한 구조를 취하고 있기 때문에, 약 2000여개의 후보 영역에 ConvNet 연산을 해야 하는 R-CNN 보다 연산량 관점에서 효과적이었으며, 뒤에 R-CNN의 문제점을 해결한 SPPNet 설계자들에게 힌트가 되었을 것 같다.
SPPNet 역시 1-pass 구조를 취하고 있는데, 이들은 OverFeat이 사용한 dense evaluation방법보다 더 진보된 Spatial Pyramid Pooling(SPP) 방식을 사용한다.
1. Introduction
본 논문의 요점은 이미지에서 물체를 동시에 분류, 위치 및 감지하기 위해 컨볼루션 네트워크를 훈련시키면 모든 작업의 분류 정확도와 탐지 및 지역화 정확도를 향상시킬 수 있음을 보여주는 것이다.
이 논문은 단일 ConvNet으로 객체 감지, 인식 및 지역화에 대한 새로운 통합 접근법을 제안한다.
우리는 또한 예측된 경계 상자를 축적하여 지역화와 탐지를 위한 새로운 방법을 소개한다.
우리는 많은 현지화 예측을 결합함으로써 배경 샘플에 대한 훈련 없이 탐지를 수행할 수 있으며 시간이 많이 걸리고 복잡한 부트스트래핑 훈련 패스를 피할 수 있음을 제안한다.
배경에 대한 교육을 받지 않으면 네트워크는 높은 정확도를 위해 긍정적인 클래스에만 집중할 수 있습니다.
2. Vision Tasks
classification은 특정 대상이 영상 내에 존재하는지 여부를 판단하는 것을 말하며, 보통은 5개의 후보를 추정하고 그것을 ground-truth와 비교하여 판단한다. 5개의 후보 중 하나가 ground-truth와 맞는 것이 있으면 맞는 것으로 보며, 이것을 top-5 에러율로 표현하여 classification의 성능을 비교하는 지표로 삼는다. 아래 그림은 leopard 를 제대로 인식할 수 있는지 확인하는 것이다.

localization은 bounding box를 통해 물체의 존재하는 영역까지 파악하는 것을 말하며, classification과 같은 학습 데이터를 사용하고 최대 5개까지 bounding box를 통해 후보를 내고 ground-truth와 비교하여 50% 이상 영역이 일치하면 맞는 것으로 본다. 성능 지표는 에러율(error rate)이다.

detection은 classification/localization과 달리 200class 학습 데이터를 사용하며, 영상 내에 존재하는 object를 가능한 많이 추정을 하며, 경우에 따라서 없는 경우는 0이 되어야 하고, 추정이 틀린 false positive에 대해서는 감점을 준다. 보통은 mAP(mean Average Precision)으로 결과를 나타낸다.

3. Classification
3.1 Model Design and Training
- ImageNet 2012 데이터셋을 사용(1.2 million images and Class = 1,000 classes)
- 고정된 입력데이터 사이즈를 갖는 모델을 사용(256 pixels라고 언급되어있는데, 256 x 256의 이미지를 의미하는 듯 합니다.)
- 221x221크기의 5 Random Crop과 그에 대한 좌우 반전 영상을 사용
- Batch Size는 128
- Weights Random Initialize
- Momentum SGD(stochastic gradient descent) 사용 (momentum parameter는 0.6)
- wegith decay 사용
- learning rate는 로 시작해서, (30, 50, 60, 70, 80) epoch마다 0.5 factor씩 줄여나감
- Fully Connected Layer(6th, 7th에 대해서)Dropout 사용(factor 0.5)
- Convolution Layer(1th ~ 5th)는 Activation function으로 ReLU 사용
하지만, 다음과 같은 차이점 3가지가 있다.
1. 대조 정규화는 사용되지 않는다.
2. 풀링 영역은 비분할이다.
3. 우리의 모델은 더 작은 보폭 (4개 대신 2개) 덕분에 더 큰 1단 및 2단 피쳐 맵을 가지고 있다.
( 보폭이 클수록 속도에는 유리하지만 정확도는 떨어진다. ) - Convolution Layer(1th ~ 5th)를 Feature Extractor라고 부르고, Accurate model과 fast model로 나눔
OverFeat은 fast와 accurate 2개의 model이 있으며, fast model은 AlexNet과 마찬가지로 5 layer의 convolution layer/pooling layer 및 3개의 fully connected layer로 구성이 된다. Accurate model은 연산 시간은 좀 더 걸리더라도 정확도 향상을 위해 convolution/pooling layer가 1개 더 추가가 되었다. 아래 표는 fast model 구조에 대한 것이다.
Table 1. fast model
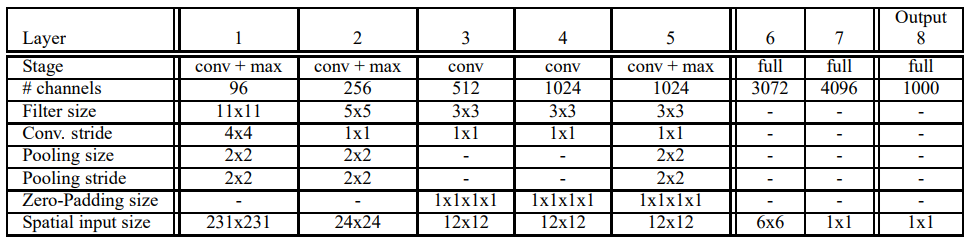
위 표에서 볼 수 있는 것처럼, 전형적인 구조를 취하고 있으며, VGGNet의 주장처럼, LRN(Local Response Normalization)은 별 효과가 없다고 하여 사용하지 않고 있으며, AlexNet과 같은 overlapped pooling 대신에 non-overlapped pooling 방식을 사용하고 있다.
3.3 Multi-scale dense evaluation
학습(Training) 방법
Classification은 학습에는 모든 학습 영상을 256 크기로 scaling 하고 221x221 크기로 multi-crop을 한다.
AlexNet과 마찬가지로 코너에서 4개 중앙에서 1개, 총 5개의 영상을 무작위로 고르고, 이것들과 좌우반전 영상 총 10개의 영상을 학습 영상으로 사용한다.
이렇게 사용하면, 영상의 많은 부분을 무시하게 되고, 과도하게 컴퓨팅 연산을 수행하게됩니다. 논문에서 저자는 Convolutional Network를 사용하게 되면, 전체 이미지를 각위치 및 다양한 스케일에서 조밀하게(Densely)하게 탐색할 수 있다고 합니다.
저자가 제안한 방식을 따르면, 효율력이 좋아지면서 견고해진다고 합니다.
CNN을 계속 통과시키다보면, Image에서의 큰 Pixel의 덩어리가 subsampling이 되서, subsampling ratio에 따라 작게 변합니다.
만약에 subsampling ratio가 36이라면 CNN의 마지막 레이어에의 feature map의 1 pixel은 원본 이미지의 36pixel에 대해서 이야기하는 값이 됩니다.
이렇게 되면 최종 feature map이 원본 이미지에 대해서 표현하는 해상도가 너무 포괄적이게 되는데, 논문에서는 객체와 feature map사이의 정렬(align)이 안맞는다고 표현합니다.
논문에서는 이렇게 되면 네트워크의 성능이 10-view보다 떨어진다고 이야기합니다.
저자는 이 문제를 해결하려고 Fast image scanning with deep max-pooling convolutional neural networks의 논문과 유사한 접근을 했다고 합니다.
Fast image scanning with deep max-pooling convolutional neural network의 저자는 max-pooling이 해당 View Field안에서 제일 큰값만 가져다 쓰는데,
그러면 이전 Convolution 연산에서 다른 연산부분은 무시하고 downsampling하는 것이기 때문에, 표현력이 많이 낮아진다고 생각하는 것 같다고 느꼈습니다.
그래서 max-pooling을 다른식으로 써서 이전 Convolution 연산값들을 조금 더 챙겨가보자 하는게, Fast image scanning with deep max-pooling convolutional neural network 논문의 핵심 컨셉이라고 생각하며,
해당 논문의 저자는 기존 max-pooling기법을 따르는게 아니라 제안한 방식으로 feature map들의 fragment를 설정하고 그에 대해서 max-pooling을 진행하는 것이 핵심입니다.
이렇게하면, 제한된 View Field안에서만 max-pooling이 진행되는 것이 아니고, 모든 feature map의 pixel값들에 대해서 공평하게 max-pooling될 기회가 주어지기 때문에 네트워크의 표현력이 좋다진다고 이야기하는 것 같습니다.
OverFeat 저자는 여기에서 컨셉을 얻어서 Feature Extractor(Convolutional Layer 1~5th)에서 나온 feature map을 0~2까지 shift를 해서 fragments를 얻고 그에 대해서 max-pooling & Fully Connected layer에 통과시켜서 출력맵을 얻고, 이를 Concatenate해서 조밀한 출력값을 얻겠다는 것 같습니다.
Testing 방법
OverFeat은 muti-crop voting 방식 대신에 dense evaluation 방식을 사용하였다. Multi-corp voting을 사용하는 경우는 서로 겹치는 부분이 있더라도 ConvNet 연산을 전부 새롭게 해야 되지만, dense evaluation 방식을 사용하여 이 문제를 해결하였다. (Dense evaluation : filter 적용시 차원이 크게 줄어드는 것을 방지하기 위해 offset을 두어 filter를 여러번 적용함)
Dense evaluation 방식의 개념은 다음 그림과 같다. 이 그림은 이해를 돕기 위해 1차원으로 표시한 것이다.
- 그림3에 대한 설명
만약 Feature extractor에서 마지막 레이어(5번째)에 왔을 때, feature Map이 6x6이라고 할 때, accurate 모델과 같은 max-pooling kernel 3x3, stride 3x3을 적용하면, max-pooling은 아래의 그림과 같이 수행되게 됩니다.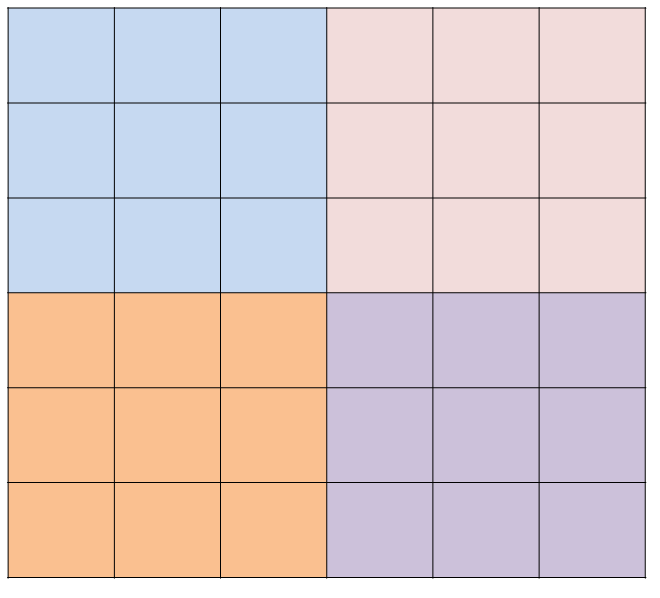 하지만 그림 3에서 이야기하는 바는 만약에 왼쪽 상단의 Pooling의 경우만 생각해보면 아래의 그림과 같이 적용하자는 이야기입니다. feature map에서 다양한 multi-scale voting을 해야겠으니, max-pooling시, view field를 x, y좌표로 {0,1,2}씩 shift해서 max-pooling을 하고, 그 결과를 고정된 Fully Connected Layer에 Sliding Windows 방식으로 넣어서, dense evaluation이라는 것을 통해서, 조금 더 해상력이 좋아진 결과를 얻고, 각 fragment들의 pooling 결과를 어떻게 Concatenate 할 것인지에 대한 내용이 Figure 3에 대한 내용이었습니다. 기존의 max-pooling을 써서 Fully Connected Layer에 넣을 때는, Pooling된 feature map에서 하나의 pixel이 원본 영상의 36pixel을 의미해서 해상력이 매우 안좋은데, 제안된 방식으로 Sliding Windows 방식으로 Multi-scale voting을 하게 되면, feature map의 1pixel의 12pixel에 대응하게 되어 해상력이 좋아진다고 이야기를 합니다.
하지만 그림 3에서 이야기하는 바는 만약에 왼쪽 상단의 Pooling의 경우만 생각해보면 아래의 그림과 같이 적용하자는 이야기입니다. feature map에서 다양한 multi-scale voting을 해야겠으니, max-pooling시, view field를 x, y좌표로 {0,1,2}씩 shift해서 max-pooling을 하고, 그 결과를 고정된 Fully Connected Layer에 Sliding Windows 방식으로 넣어서, dense evaluation이라는 것을 통해서, 조금 더 해상력이 좋아진 결과를 얻고, 각 fragment들의 pooling 결과를 어떻게 Concatenate 할 것인지에 대한 내용이 Figure 3에 대한 내용이었습니다. 기존의 max-pooling을 써서 Fully Connected Layer에 넣을 때는, Pooling된 feature map에서 하나의 pixel이 원본 영상의 36pixel을 의미해서 해상력이 매우 안좋은데, 제안된 방식으로 Sliding Windows 방식으로 Multi-scale voting을 하게 되면, feature map의 1pixel의 12pixel에 대응하게 되어 해상력이 좋아진다고 이야기를 합니다. 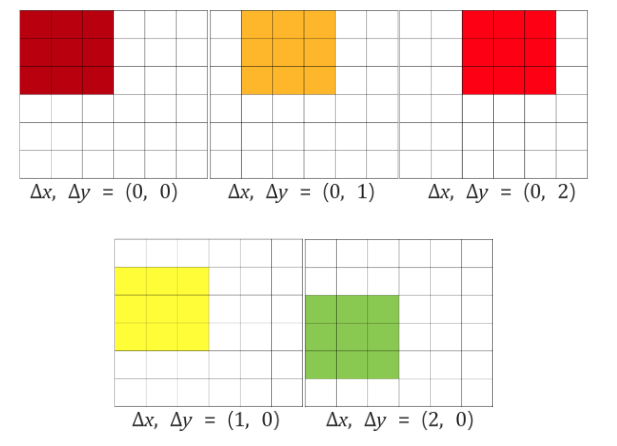
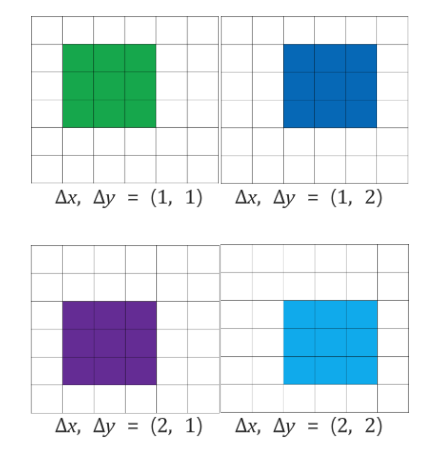
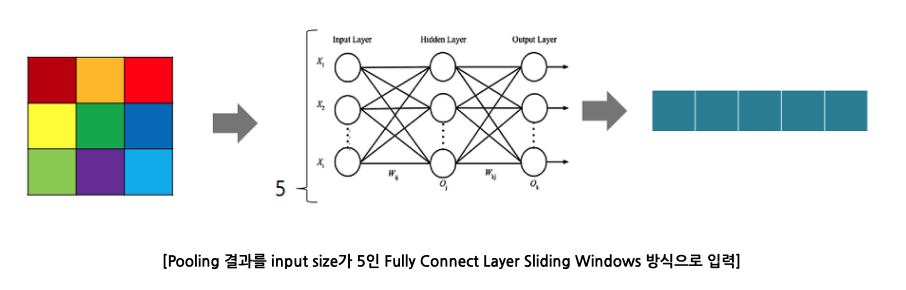
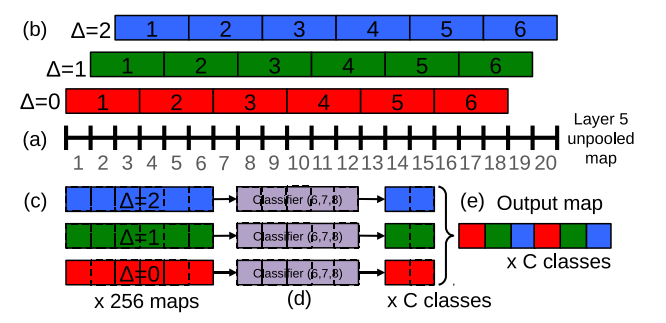
그림3
그림 3: 스케일 2의 y 차원을 예로 들어 분류를 위한 출력 맵 계산의 1D 그림(스케일링)
(a): 20픽셀 풀링되지 않은 레이어 5 피쳐 맵.
(b): ∆ = {0, 1, 2} 픽셀(각각 적색, 녹색, 청색)의 오프셋을 사용하여 잘리지 않는 3픽셀 그룹에 대한 최대 풀링.
(c): 6픽셀 풀링 맵이 서로 다른 ∆에 대해 나타납니다.
(d) : 5픽셀 분류기(층 6,7)는 풀링된 맵에 슬라이딩 윈도우 방식으로 적용되며, ∆당 C 맵별로 2픽셀을 산출한다.
(e): C 출력 맵에 의해 6픽셀로 재형성됩니다.
만약에 최종 max-pooling layer에 총 20개의 데이터가 있고, 이것에 대해 3x1 non-overlapped pooling을 한다고 해보자. Pooling을 거치고 나면 데이터의 양이 1/3로 줄어드는 것뿐만 아니라, resolution 역시 1/3 로 줄어들기 때문에 위치의 정확도도 그만큼 떨어지게 된다.
그런데 위 그림처럼, offset Δ를 1 데이터 단위로 하게 되면, 1 데이터 간격으로 각각 pooling을 진행하고, 그 결과를 Classifier에 적용을 하게 되면, pooling 이전의 해상도를 유지할 수 있어, pooling 이후 1번만 classifier 연산을 하는 것에 비해 훨씬 조밀한 검사(dense evaluation)을 할 수 있게 되는 것이다.
아래는 accurate model의 구성을 보여주는 그림이다.
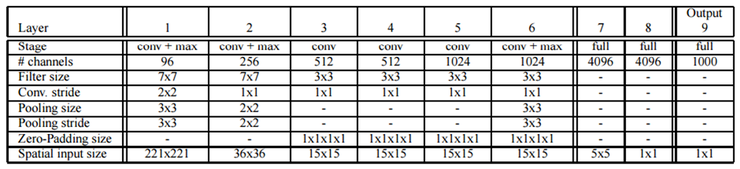
Accurate model에서 stride 부분을 주목해서 살펴보면, Layer 1에서 conv와 pooling을 거치면 영상의 크기가 1/6로 줄어든다.
Layer2를 거치면 다시 1/2로 줄어들고, Layer6의 pooling을 거치면, 다시 1/3이 줄어들어 전체적으로 Layer6를 거치고 나면, Layer7의 classifier로 입력의 1 픽셀은 실제 입력 영상의 36픽셀에 해당하게 된다.
OverFeat의 입력 영상의 크기가 221x221인 것을 감안하면, Layer7의 1 픽셀의 해상도가 36픽셀에 해당하기 때문에 너무 간격이 듬성 듬성하게 된다.
그래서 OverFeat 설계자가 고려한 부분은 classifier에 연결되는 Layer6의 pooling 부분에 주목을 하였다. Pooling의 stride가 3x3이기 때문에 pooling 단 앞단의 해상도는 36픽셀이 아니라 12 픽셀 수준이 되며, pooling 이전 단 기준으로 1픽셀씩 offset을 갖고 pooling을 수행하면 classifier로 들어가는 데이터의 양은 결과적으로 3x3, 즉 9배만큼 많아지지만, 해상력은 그만큼 좋아지게 된다.
OverFeat에서 설계팀은 Fully-connected layer에 대한 해석을 다르게 하였다. LeCun이 FC layer에 대해 언급한 유명한 말은 다음과 같다.
In Convolutional Nets, there is no such thing as "fully-connected layers". There are only convolution layers with 1x1 convolution kernels and a full connection table.
LeCun은 FC-layer를 1x1 convolution으로 이해를 하고 있다. LeCun의 말처럼, FC-layer를 1x1 convolution으로 본다면, conv/pooling layer를 처리할 때와 과 마찬가지로 sliding window 개념을 적용할 수 있다.
그간 ConvNet 설계자들이 어려워했던 부분은 convolution 부분은 영상의 크기에 상관없이 적용이 가능하지만, Fully-connected layer 부분은 fixed size를 갖고 있기 때문에 sliding window 개념이 아니라, ConvNet 앞단에서 fixed size를 고려한 crop을 수행하고 항상 FC layer 앞단에는 동일한 크기의 feature map이 확보되도록 하였다.
그렇지만, FC layer가 개념적으로 보면 1x1 convolution으로 볼 수 있기 때문에 이제는 FC-layer 앞단의 feature-map 크기에 연연해 할 이유가 없어지는 것이다.
3.4 Results
아래는 OverFeat의 실험 결과이다.
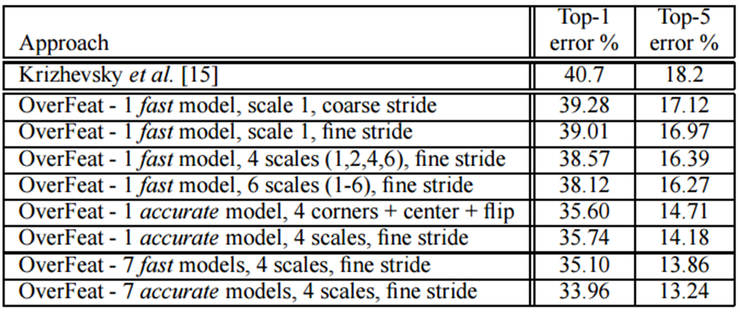
이 결과를 보면, model voting과 4 scale, dense evaluation을 사용한 경우 top-5 에러율이 13.24로 상당히 좋은 결과를 낸다는 것을 알 수 있다. Dense evaluation을 사용하면, 겹치는 부분에 대한 연산을 공유할 수 있어 전반적으로 연산량이 크게 줄어든다. Grid 크기에 대한 우려가 있을 수 있지만, grid 크기를 연산량과 고려하여 적절한 수준으로 유지하면 결과가 좋다.
Localization 결과는 아래 그림과 같다.
3.5 ConvNets and Sliding Window Effciency
이 개념을 2차원 구조를 갖는 영상에 적용하게 되면, 간단하게 예시를 하면 아래 그림과 같다.
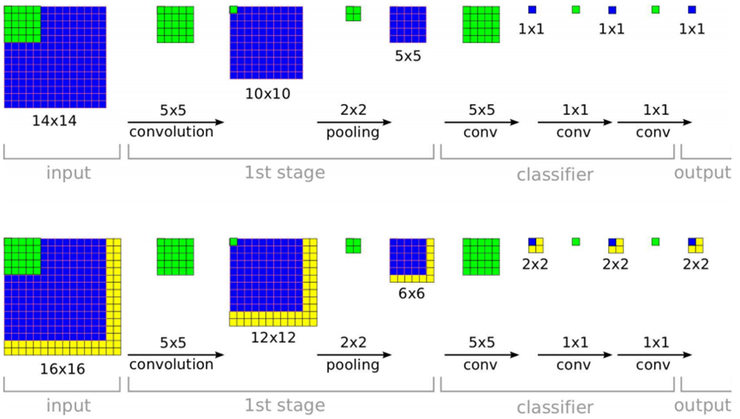
상단은 학습 과정을 보여준다. 입력 이미지의 크기가 14x14인 경우에 conv/pooling을 거처 최종적으로 5x5 크기를 얻은 후 classifier를 거쳐 학습을 한다. 하단은 입력 영상보다 크기가 큰 16x16 영상을 test 입력으로 사용하게 된다면, FC-layer 앞단에서는 6x6 크기의 feature-map이 얻어지고, 이것은 sliding window 개념으로 해석하면, 5x5 window 4개가 있는 것으로 볼 수 있고, 최종적으로 2x2 차원의 최종 출력을 얻게 된다.
이 개념이 확보되었으므로 이제는 큰 이미지의 특정 위치를 무작위로 선택하는 것이 아니라 일정한 resolution 단위로 선택을 할 수 있게 된다. 또한 영상의 scale이 바뀌더라도, 바뀐 scale에 맞춰 sliding window를 움직이면서 결과를 얻으면 된다.
4. Localization
4.1 Generating Predictions
4.2 Regressor Training
아래 그림은 4개의 scale에 대해 dense evaluation을 보여주는 그림이다. Scale에 따라 특정 대상이 나타났다가 사라질 수 있으며, voting 개념을 활용하여 대상을 classification 및 localization 시킬 수 있다.


Localization은 대상의 위치나 형태에 맞춰 bounding box까지 학습을 해줘야 한다. Classification과 동일한 학습이미지에 대해 bounding box까지 있는 ground-truth 데이터를 이용해 localization을 학습시킨다.
Classification과 많은 부분을 공유하며, 최종단에 있는 classifier 부분을 bounding box regression network로 치환해주고, bounding box를 각각의 위치 및 scale에 맞게 학습을 시킨다.
아래 그림은 동일 영상에 대해 voting에 의해 특정 대상이 검출되고 대상에 맞춰 bounding box를 찾아주는 것을 보여주는 그림이다.
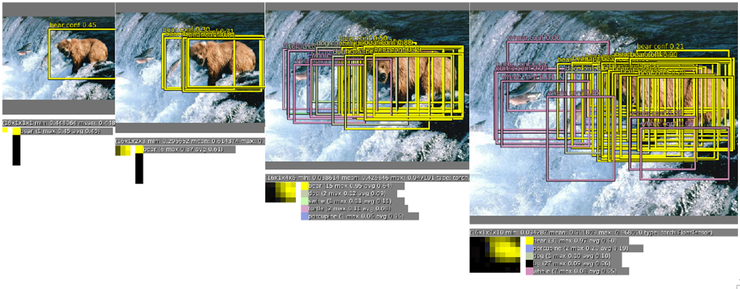

crop의 경우처럼 원 학습 영상으로부터 영상을 잘라낸 후 그것들을 각각 ConvNet에 적용시키는 방식이 아니라, 큰 영상에 대해 곧바로 ConvNet을 적용하고 일정한 픽셀 간격(grid)으로 마치 sliding window를 적용하듯이 결과를 끌어낼 수 있어, 연산량 관점에서는 매우 효율적이지만, grid 크기 문제로 인해서 학습 결과가 약간 떨어질 수 있다. 그러므로 crop과 dense evaluation을 상보적으로(complementary) 섞어 사용하면 더 성능이 좋아진다.
그림7

이렇게, 최종 Bounding Box의 좌표를 얻게되면, 최종 출력은 위의 그림과 같은 형태로 출력되게 됩니다. 그럼 이제 이중에, 어떤 Box가 Object에 제일 적합하냐를 찾아야하는데, 아래와 같은 방법으로 결정될 수 있습니다. 먼저 Classifier에서 출력된 N개의 클래스 벡터집합에서 제일 score가 높은 class를 해당 object로 할당합니다. 모든 스케일에 대해서 검출된 Box를 특정 bin에 넣고 그 중에 2개를 뽑아서, GT Box와 IOU와 Center Point의 차이에 대한 유클리디언 거리가 제일 작은지에 대한 match_score를 먹여서 어느 일정값보다 높으면 해당 Object에 대한 Box를 해당 Box로 고정하고, 그렇지 않다면, Center Point와 각 width, height에 대한 평균값을 설정해서 해당 bin에서 사용했던 box를 제거하고, 새로 합쳐진 Box를 넣어주고 이를 반복합니다.
4.3 Combining Predictions
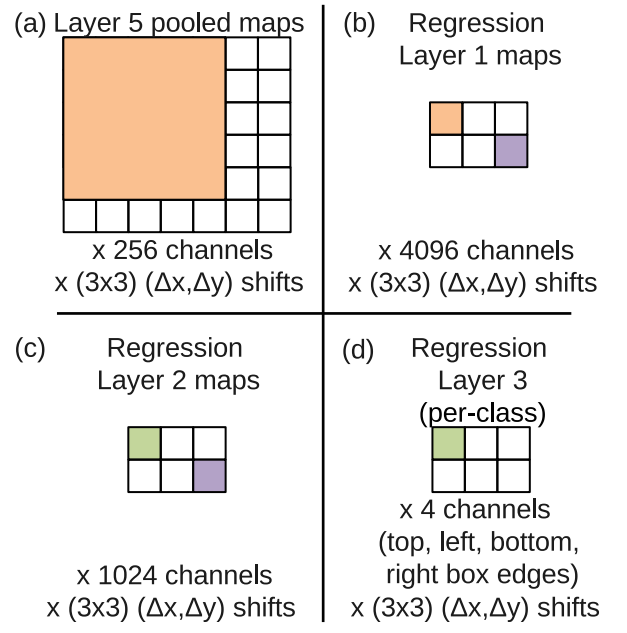
아래의 그림과 같이 논문에서 Figure 8에 나타나있는 그림은 OverFeat으로 추가적인 Boxing Regression Network에 대해 설명한 그림입니다.
(a)의 Layer 5 pooled maps는 feature extractor를 통과하고 나온, max-pooling 이전의 feature map이고, feature map의 size는 7x6입니다. 여기에서 ∆x, ∆y의 max-pooling을 진행할 건데, feature map의 height가 더 내려갈 수 없으니 결과론적으로 최종 pooling된 feature map이 3x2의 크기가 될 수 밖에 없습니다. 이를 Fully Connected Layer를 통과시키면, 256 채널에서 4096, 1024채널로 변경되다가, 최종 출력은 3x2x4의 tensor가 됩니다. 여기서 3x4는 공간적 정보를 의미하고 4채널은 박스의 (xmin, ymin, xmax, ymax)를 의미하게됩니다.
Voting 방식은 다음과 같은 알고리즘으로 구성되며, 최종 경계상자와 분류를 수행하게 됩니다.

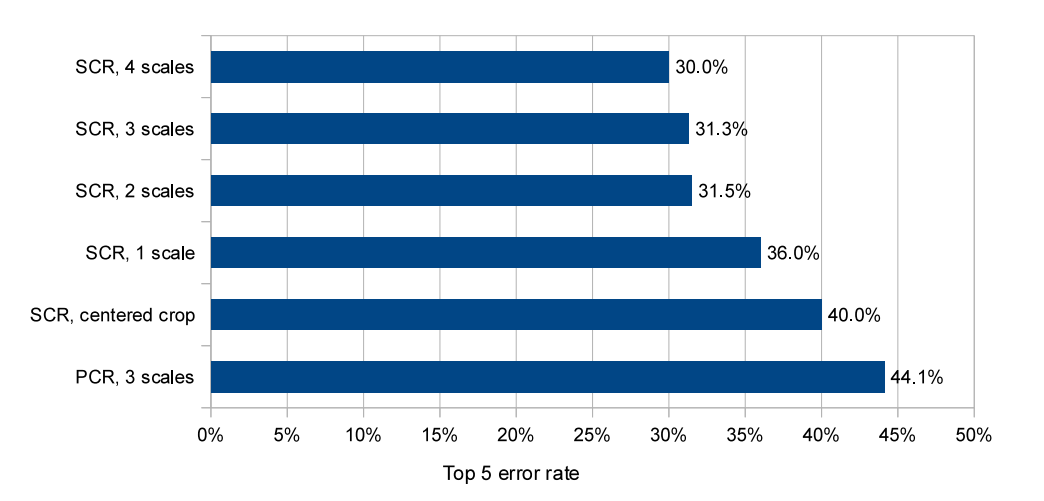
그림 9: ILSVRC12 유효성 검사 세트에 대한 현지화 실험. 우리는 다양한 척도를 실험하고 단일 클래스 회귀 분석(SCR) 또는 클래스당 회귀 분석(PCR)을 사용하여 실험한다.
4.4 Experiments
ImageNet 2012 데이터 셋에 적용하여서 이에 대한 결과가 그림9에 나와 있다.
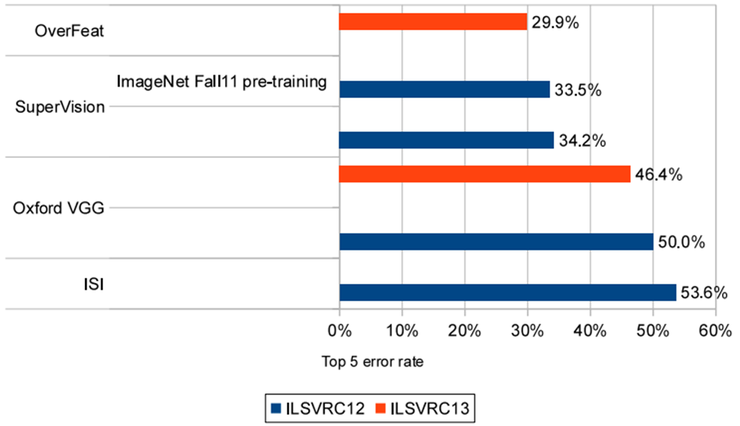
그림10은 2012년과 2013년 결과를 보여준다. ( 시험 데이터는 동일하다. )
그림9의 SCR만 사용한 회귀 네트워크는 40%의 오류율을 달성하며, 이 부분은 멀티스케일 및 다중 뷰 접근 방식의 우수한 성능을 얻는데 매우 중요했다.
모든 공간 위치의 회귀 분석 예측을 두 가지 척도로 결합함으로써 31.5%라는 훨씬 더 나은 오류율을 달성하며,
3차 및 4차 척도를 추가하면 성능이 30.0% 오류로 향상되는 것을 볼 수 있다.
각 클래스에 대해 다른 최상위 계층을 사용하는 것은 성능이 우수하지 않음을 볼 수 있다.
해당 원인에 대한 이유는 훈련 세트에 경계 상자에 주석을 단 클래스당 예가 상대적으로 적은
반면, 네트워크는 1000배 더 많은 최상위 매개 변수를 가지고 있어 훈련이 부족하기 때문일 수 있다.
유사한 등급에서만 매개 변수를 공유함으로써 이 접근 방식을 개선할 수 있다.
5. Detection
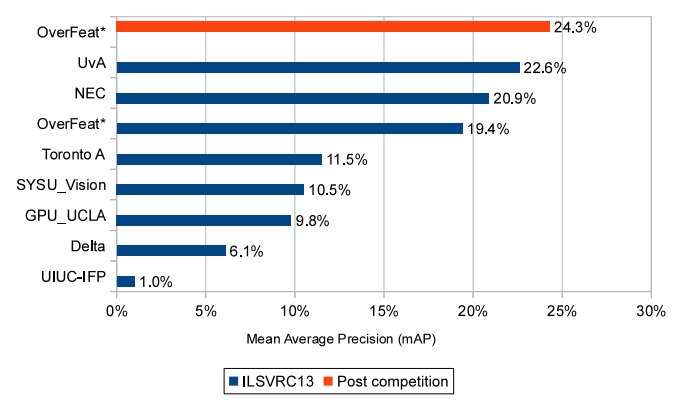
Detection 분야는 대회를 마치고 다시 개선한 결과에서는 mAP가 24.3%로 1위를 차지할 수 있었지만, 결과적으로 좀 뒤에 나온 R-CNN이 동일 데이터 set에 대해 큰 폭으로 성능 차이를 보이게 되어 의미가 많이 퇴색해졌다.
그림10
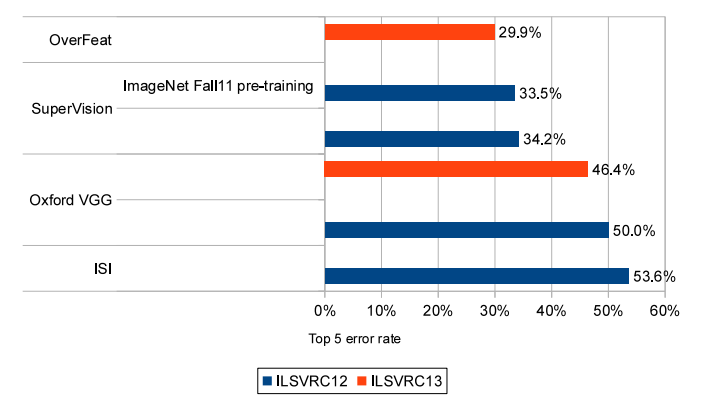
그림11
6. Discussion
💡 앞서 살펴본 것처럼, OverFeat는 ConvNet의 fully-connected layer를 1x1 convolution 개념으로 볼 수 있다는 점을 이용하여 연산량 절감 차원에서는 효과적이었지만, 근본적으로는 deeper network 이상의 성능을 얻을 수는 없었다. 하지만 ConvNet을 이용하여 localization/detection까지 통합 시도를 했다는 점에서 의미가 있고, 1년 뒤에 마이크로소프트 팀에서 발표할 SPPNet에 맥이 닿아 있다는 점에서 의미가 있는 것 같다. SPPNet은 dense evaluation 대신에 spatial pyramid pooling을 적용하여 detection 의 성능과 속도를 모두 개선시킬 수 있었다.
분류, 지역화 및 탐지에 사용할 수 있는 다중 스케일 슬라이딩 윈도우 접근 방식을 제시하였다.
우리는 이것을 ILSVRC 2013 데이터 세트에 적용했고, 현재 4위이다.
분류, 지역화 1위, 탐지 1위. 우리 논문의 두 번째 중요한 기여는 ConvNet을 탐지 및 로컬라이제이션 작업에 효과적으로 사용할 수 있는 방법을 설명하고 있습니다. 이것들이었다.
[15]에서는 다루지 않았으며, 따라서 우리는 ImageNet 2012의 맥락에서 이 작업을 수행할 수 있는 방법을 최초로 설명합니다. 우리가 제안하는 계획은 다음을 위해 설계된 네트워크에 대한 상당한 수정을 포함한다.
분류, 그러나 ConvNets가 이러한 더 어려운 작업을 수행할 수 있음을 명확히 보여준다.
2013년 ILSVRC 대회에서 우리의 현지화 접근법이 승리했고 모든 것을 크게 앞질렀다.
2012년 및 2013년 접근 방식. 이 탐지 모델은 대회 기간 동안 최고의 성능을 발휘했으며,
경기 후 결과에서 1위를 차지했다. 우리는 다음을 수행할 수 있는 통합 파이프라인을 제안했습니다.
완전히 직접 학습된 공통 기능 추출 기반을 공유하면서 다양한 작업을 수행합니다.
화소로부터 우리의 접근 방식은 몇 가지 면에서 여전히 개선될 수 있다.
(i) 현지화를 위해 우리는 현재 존재하지 않습니다. 전체 네트워크를 통해 백프로핑합니다.
이렇게 하면 성능이 향상될 가능성이 높습니다.
(ii) 우리는 다음 항목에 대한 교차점-결합(OIU) 기준을 직접 최적화하는 대신 §2 손실 사용 성능을 측정합니다. IOU는 일부 중복이 있을 경우 여전히 차별화 가능하기 때문에 손실을 이것으로 교환하는 것이 가능해야 합니다.
(iii) 경계 상자의 대체 매개변수화는 다음과 같다.
네트워크 교육에 도움이 되는 출력물을 장식하는 데 도움이 됩니다.
[15] A. Krizhevsky, I. Sutskever, and G. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, 2012.
Reference
https://arclab.tistory.com/226
https://dhhwang89.tistory.com/135
https://blog.naver.com/laonple/220752877630