필수적으로 알고가기
-
**discriminative(판별 모델) vs generative model(생성 모델)**
-
참고 사이트 : https://ratsgo.github.io/generative model/2017/12/17/compare/
discriminative model
discriminative model 이란 Input Data : X가 주어질 때 레이블 Y가 나타날 조건부확률 p(Y|X)를 직접적으로 반환하는 모델이다. 이는 레이블 정보가 있어야 하기에 지도학습(Supervised Learning) 에 해당하며, X의 레이블을 잘 구분하는 decision boundary(결정경계)를 학습하는 것이 주 목적이다.
-
일반적으로, 데이터양이 충분하다면 좋은 성능을 낸다.
-
선형회귀, 로지스틱회귀가 discriminative model의 한 예이다.
Generative model
generative model 이란 input Data : X 가 생성되는 두 개의 확률모형 p(Y), p(X|Y)으로 정의하고, 베이즈룰을 사용해 p(Y|X)를 간접적으로 도출하는 모델이다. 이 모델은 레이블이 있어도, 없어도 둘 다 구축할 수 있다. 또한 범주의 분포(distribution)을 학습하는 것이 주 목적이다.
-
레이블 있는 경우 : 지도학습기반 Generative model, 선형판별분석이 대표 사례
-
레이블 없는 경우 : 비지도학습기반 Genrative model, 가우시안믹스처모델, 토픽모델링이 대표 사례
<특징>
discriminative model 에 비해 가정이 많다. → 가정이 잘맞으면 적은 데이터로도 좋은 예측 성능을 보여줌.
학습데이터가 많을 수록 discriminative model과 비슷한 성능을 낸다.
p(X|Y)를 구축하기에 X를 샘플링할 수 있다.
data distribution (데이터 분포)
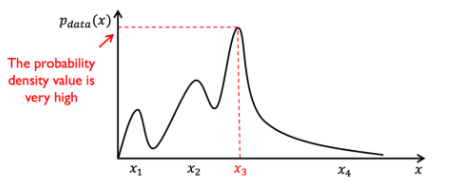
우리가 가지고 있는 데이터셋이 여러 인종들의 머리 색에 대한 사진이면 ,각 머리색은 x축을 기준으로 검정색이 X3이럐 백인은 X4일 것이다. 그럼 Pdata(x)는 금발로 갈 수록 더 낮다.
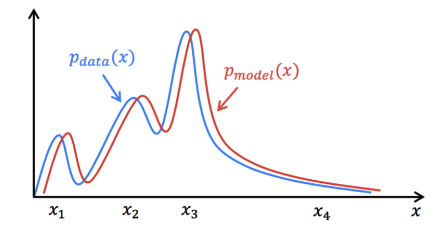
Genrative model의 목적은 데이터 분포를 학습시키는 것, 즉 우리가 구축하는 모델에 데이터를 넣으면 실제 데이터의 확률에 가깝게 반환하여, 정말 유사한 데이터만 드는 것이다.
Deep Genrative Model
개념 : 딥러닝을 활용한 Genrative model 즉, data의 distribution을 학습하고, 이로부터 새로운 데이터 X를 생성하는 것이 목적
-
본문 소개
0. Genrative model 구분
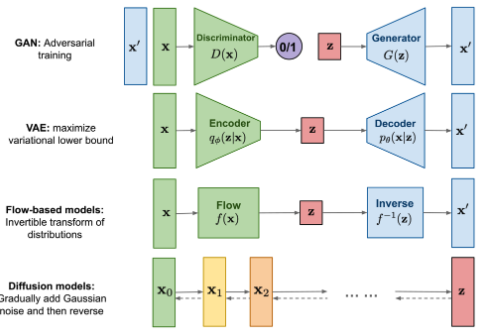
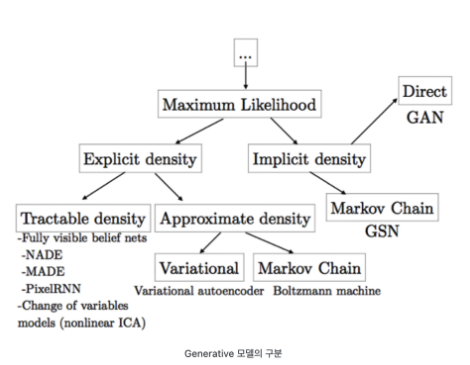 Genrative model이 되게 많다. 우리는 여기서 VAE와 GAN에 대해 알아볼 것이다.
Genrative model이 되게 많다. 우리는 여기서 VAE와 GAN에 대해 알아볼 것이다.
1. Variational Auto-Encoder (VAE) → “ 꿩 대신 닭이다!”
💡 VAE : 이미 우리가 잘 알고 있으면서, 다루기 쉬운 분포 중 최대한 비슷한 분포를 찾아내 활용하자.VAE란, Genrative Model에서 우리가 쉽게 알기 어려운 Posterior(사후확률) 분포인 p(z|x)를 다루기 쉬운 분포로 approximation(근사)하는 변분법적 추론을 활용한 딥러닝 생성모델이다. 구조 : Encoder / Decoder
구조 : Encoder / Decoder
Encoder : 입력 데이터 x를 요약해 잠재변수 z를 만들어냄
Decoder : 잠재변수 z를 다시 최대한 x와 유사한 x’로 만듦
-
수학적 모델링
💡 P 대신 Q를 잘 학습시켜 x와 비슷한 x’를 만들면된다. P(Z|X)를 대신해 Q(Z|X;%)를 구한다. 여기서 %는 VAE 모델이 학습을 통해 얻는 최적 파라미터 값. 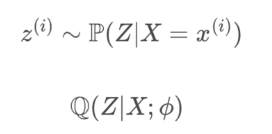
딥러닝 모델 역시 데이터 학습을 위한 방향이 중요하다. 생성 모델에서는 ‘생성’이라는 목적에 맞게 학습 방향을 알려주는 장치(KL)이 필요하다. VAE에서는 KL(Kullback-Leibler) Divergence(쿨백-라이블러 발산) 를 이용해 모델이 얼마나 잘 학습하고 있는지 알려준다.
-
만약 데이터의 분포를 완벽하게 학습하였다면 KL Divergence는 0이 된다.
-
만약 잘 학습하지 못한다면 점점 커짐(아예 학습못하면 무한대로가겟죠?)
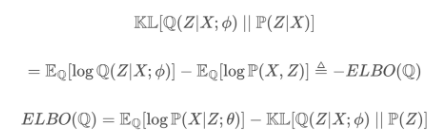 쿨백 라이블러 발산 식,
쿨백 라이블러 발산 식, 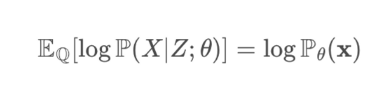
참고
-
ELBO (=Evidence Lower Bound) ↔ KL Divergence와 음의 관계를 가짐
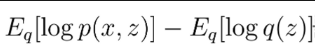 위의 식이 ELBO이다.
위의 식이 ELBO이다.역할 : 우리가 관찰한 output data P(z|x)가 다루기 힘든 분포를 이룰 떄 이를 조금 더 다루기 쉬운 분포은 Q(x)로 대신 표현하려 하는 과정에서 KL Divgence를 최소화하기 위해 사용한다.
-
장점 : 안정적인 학습이 가능하다.
단점 : Blur가 많이 낀다.

2. Genrative Adversarial Networks (=GAN)
VAE의 단점인 blur 이슈에 대해 해결해줄 GAN이 등장하게 됨, GAN은 현재 Genrative Model 하면 떠오르는 대표적인 방법으로 자리잡음.
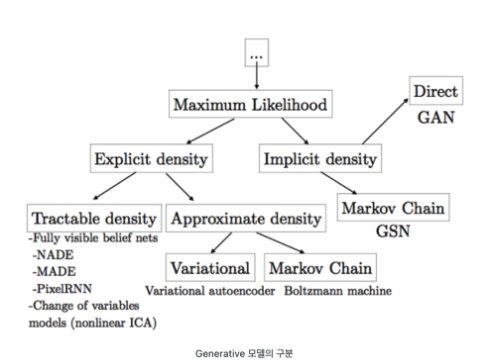
위에서 보는 것 처럼 GAN은 Implictit 방식이다. 상단의 Genrative model 구분을 보면 VAE와 다르게 Implicit density에서 유래된 것을 알 수 있는데 간접적인(Implicity) 방식은 어떤 모델에 대해 틀을 명확히 정의하는 것이 아닌 확률 분포를 알기 위해 sample을 뽑는 방법을 얘기한다.
- GAN 특징
- GAN은 어떤 확률 모델(Density)를 정의하지 않아도, 모델(Generator) 자체가 만드는 분포로부터 sample을 생성할 수 있다.
- Explicit density 방식의 경우 모델을 확실하게 정의하고 있어, 비교적으로 모델의 움직임이나 예측이 쉬운 반면, 우리가 아는 것 이상으로는 결과를 알 수 없다는 것이 한계이다. 그러나 GAN은 확률 모델을 정의하지 않기 떄문에 예측 불가능한(=예상외로 괜찮은?) 결과값이 나올 수 있다.
- GAN은 VAE와 다르게 정규분포(Normal Distribution)과 같은 가정이 포함되지 않고 유연하게 데이터 분포를 학습할 수 있다.
- GAN 구조
생성자(Genrerator) / 식별자(Discriminator)
→ 생성자 G과 식별자 D가 서로 경쟁하는 방식으로 학습이 이루어짐
생성자 : 식별자를 속이기 위해 더 나은 결과물을 만드는 방식으로 학습이 이루어짐
식별자 : 생성자가 만들어낸 결과물과 실제 데이터를 구분하기 위한 능력을 키우는 방식으로 학습이 이루어짐
- GAN과 관련된 위조지폐범이야기
GAN에 대한 이야기를 하면 빠지지 않는 이야기가 존재한다. 바로 ‘위조지폐범 이야기’이다. 위조지폐범(Generatory)는 경찰(Discriminator)를 속이기 위한 위조지폐를 만드려고 한다. 처음 위조지폐범이 만드는 위조지폐는 수준이 매우 떨어진 위조 지폐로 인해 경찰이 가짜임을 쉽게 구분할 것이다. 그렇기에 위조지폐범은 경찰을 속이기 위해 더욱 노력할 것이고, 그 수준이 점차 올라가며 정교하고, 진짜와 거의 유사한 지폐를 만들 것이다. 결국 위조지폐범은 갈수록 실제와 비슷한 위조지폐를 만드는 실력이 클 것이다.
-
수학적 모델링
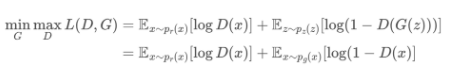
x는 원본 데이터(진짜 지폐)이며 z는 가짜 데이터(위조 지폐)이다.
D(경찰)의 입장에서 실제 데이터 x를 입력하면 높은 확률이 나오도록하고 (D(x) 를 높임), 가짜 데이터 z를 입력하면 확률이 낮아지도록 (1-D(G(z)))를 낮춤 → D(G(z))를 높임) 학습한다.
-
식별자입장에서의 공식 → 최대한 V(D)가 최대가 되도록 노력한다.
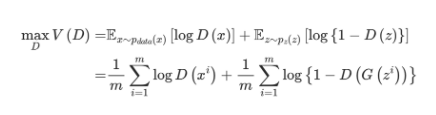
-
생성자입장에서의 공식 → V(G)가 최소가 되도록 한다.
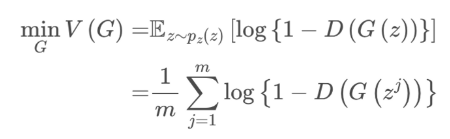
-
- GAN 단점
- 균형있는 학습이 어렵기에, G,D에 대해 둘 다 학습시키는 것이기에 잘 학습시키는 것이 매우 어렵다.
- 보통 만족스럽지 않은 결과물을 생성할 떄가 많다고 한다.
참고 및 의견
VAE 논문 , **Auto-Encoding Variational Bayes,**
https://arxiv.org/abs/1312.6114
