Selecting data for modeling
import pandas as pd
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
# melbourne_data에 저장된 컬럼(feature)을 출력할 수 있습니다.
melbourne_data.columns-
melbourne_data와 iowa_data의 column 구성이 다르다.
-
column 구성을 같게 만들어주기 위해서 아래와 같은 코드를 실행합니다. (인덱스가 0인 column 지우기)
# dropna drops missing values (think of na as "not available")
melbourne_data = melbourne_data.dropna(axis=0)Selecting the prediction target
예측하고자 하는 값은 Price입니다. 따라서 아래와 같이 코드를 작성합니다.
y = melbourne_data.PriceChoosing features
예측에 사용할 columns을 선택합시다.
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude', 'Longtitude']
X = melbourne_data[melbourne_features]House Price를 예측하기 위해서 .descibe()와 .head()를 사용할 것입니다. (.head() 상위 rows 몇 개를 보여줍니다.)
Building your model
Scikit-learn을 활용하여 Model을 생성합니다.
모델을 사용하는 방법
-
Define: 무슨 모델을 사용할건지 정해봅시다.
-
Fit: 데이터로부터 패턴을 파악합시다. (ex: 집의 가격이 높을 때는 데이터에 어떤 특징이 있고, 집의 가격이 낮을 때는 데이터에 어떤 특징이 있는 파악합시다.)
-
Predict
-
Evaluate: 모델의 정확도를 측정합니다.
아래 코드는 Decision Tree를 활용하여 모델을 만들고 Fitting 하는 예제입니다.
from sklearn.tree import DecisionTreeRegressor
# Define model. Specify a number for random_state to ensure same results each run
melbourne_model = DecisionTreeRegressor(random_state=1)
# Fit model
melbourne_model.fit(X, y)아래 코드는 Fitting을 완료한 Decision Tree 모델의 예측 결과를 보기 위함입니다. (예측 값을 얻기 위한 데이터(X.head())는 fitting을 위해 사용된 데이터를 활용합니다.)
print("Making predictions for the following 5 houses:")
print(X.head())
print("The predictions are")
print(melbourne_model.predict(X.head()))Exercise
Step 1: Specify prediction target
y = home_data.SalePrice- Dataframe으로부터 원하는 target을 추출하기 위해서는 dot-notation을 활용합니다.
Step 2: Create
- 예측 모델에 사용할 features를 선택합니다.
feature_names = ['LotArea', 'YearBuilt', '1stFlrSF', '2ndFlrSF', 'FullBath', 'BedroomAbvGr', 'TotRmsAbvGrd']- 선택한 features를 포함하는 Dataframe을 생성합니다.
X = home_data[feature_names]- 생성한 feature Dataframe을 확인해봅니다.
# 데이터 요약 출력
X.describe()
# 데이터 샘플(row index: 0 ~ 4) 5개 확인
X.head()Step 3: Specify and fit model
- Decision Tree model(
iowa_model)을 선언합니다.
from sklearn.tree import DecisionTreeRegressor
iowa_model = DecisionTreeRegressor(random_state=1)iowa_model을 훈련합니다.
iowa_model.fit(X, y)Step 4: Make predictions
predictions = iowa_model.predict(X)잘 분류하는지 조금 더 정확하게 알아보기 위해서 아래와 같은 코드를 실행하였고 결과를 첨부합니다.
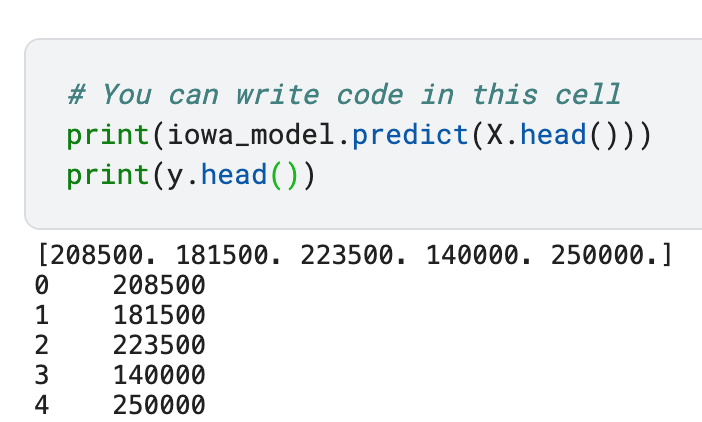
# 샘플 5개에 대한 예측 결과
print(iowa_model.predict(X.head()))
# 샘플 5개에 대한 실제 값
print(y.head())아래 그림을 보면 예측값과 원래 값이 똑같음을 알 수 있습니다.

개발자가 되고싶읍니다...