지도 학습과 Decision Tree
활용하고자 하는 데이터가 있다면 -> 데이터를 전처리하고 -> 전처리된 데이터에 가장 적합한 머신러닝 기법을 적용합니다.
지도 학습 (Supervised Learning)
지도 학습의 정의: 데이터 & Label, 두개의 구성을 모두 활용하고 있는 머신러닝 기법
지도 학습의 목표: 새로운 데이터가 주어졌을 때 그 데이터의 Label을 결정해 주는 것
Decision Tree
Decision Tree는 적용되는 응용 분야에 따라 사용자가 마음대로 변환해서 사용할 수 있는 알고리즘입니다.
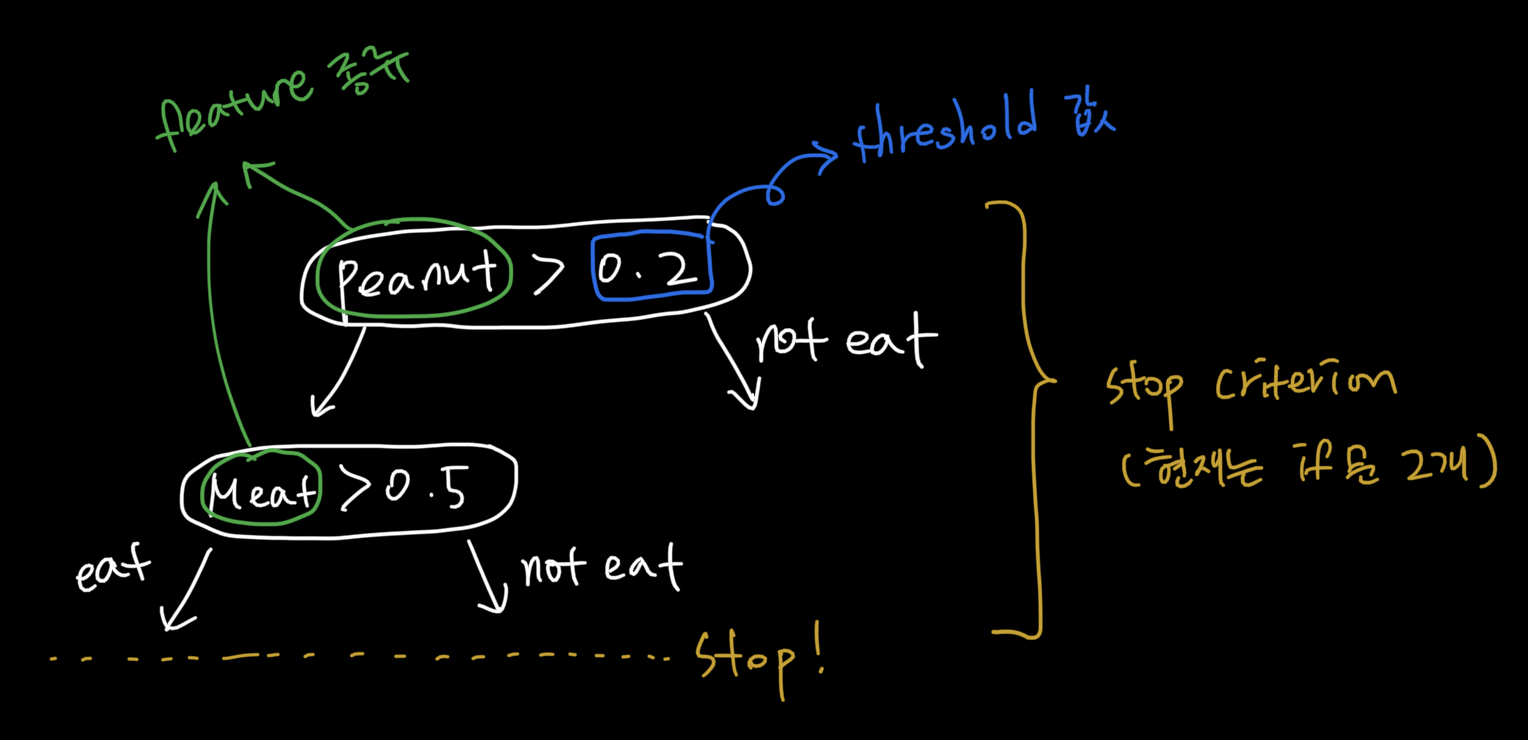
-
Decision Tree는 feature의 종류, threshold 값, stop criterion 을 설정하는 방식에 따라 정말 다양하게 구현될 수 있습니다.
-
따라서 학습할 데이터를 가장 잘 표현하는 Decision Tree를 찾는 것이 중요합니다.
그렇다면 feature, threshold 값 등 우리는 어떻게 값을 설정해야 할까요?
-
주어진 데이터를 최적으로 나누는 방법
-
주어진 데이터를 두 개로 나누는데 나뉜 데이터의 개수가 서로 비슷하도록 나누는 방법
-
나눴을 때 정확도가 가장 높은 방향으로 나누는 방법
-
나눴을 때 단 한개의 샘플만 한쪽으로 가고 나머지 샘플은 반대쪽으로 빠지게 하는 방법
-
단점
-
트리의 높이가 너무 높아집니다.
-
트리가 한쪽으로 쏠립니다.
-
스플릿을 많이 해야 합니다.
-
-
-
split 계산
n개의 샘플, d개의 features, k개의 thresholds 라면 만큼 계산해야 합니다.
계산량이 너무 많을 것 같은데...?
-
모든 feature를 사용하지 않고 features를 랜덤하게 결정
-
threshold 를 2~3 개정도로 적게 나누기
위의 방법으로 계산량을 줄일 수 있습니다.
일반적으로 greedy recursive splitting 전략을 사용합니다.
