논문 제목 : Fast R-CNN
저자 : Ross Girshick
연도 : 2015
1. Introduction
Fast-RCNN 모델은 기존 R-CNN 모델의 한계점을 극복하고자 제안된 모델입니다.
기존 R-CNN 모델은 다음과 같은 한계점이 있었습니다.
1. ROI(Region of Interest)마다 CNN 연산을 함으로써 속도 저하
- Test time이 매우 느리다. 모든 ROI를 CNN에 넣어야 하기 때문에 2,000번의 CNN 연산이 필요하다.
- 때문에 training과 testing 과정에서 많은 시간이 필요
2. multi-stage pipelines으로써 모델을 한번에 학습시키지 못함
- 전체 아키텍처에서 SVM, Regressor 모듈이 CNN과 분리되어 있다.
- CNN은 feature만 추출하고 고정되므로 SVM과 Bounding Box Regression은 따로 동작
- CNN은 고정되어 있기 떄문에, SVM과 Bounding Box Regression까지 forwarding 한 뒤, CNN feature extractor를 업데이트 할 수 없다.
- end-to-end 방식으로 학습할 수 없다. 때문에 정확도가 낮다.
- Computation을 Share하지 않음
3. AlexNet을 그대로 사용하기 위해 Image를 224x224 크기로 강제로 warping 시켰기 때문에 이미지 변형으로 인한 성능 손실이 존재
위 문제점들을 극복하기 위해 Fast R-CNN이 제안되었습니다.
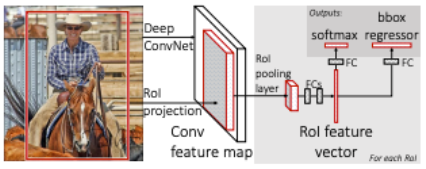
ROI PoolingCNN특징 추출부터classification,bounding box regression까지 하나의 모델에서 학습
2. Fast R-CNN
2-1. Introduction
R-CNN 모델은 2000장의 region proposals를 CNN 모델에 입력시켜 각각에 대하여 독립적으로 학습시켜 많은 시간이 소요됩니다.
- Fast R-CNN은 이러한 문제를 개선하여 단
1장의 이미지를 입력받습니다.
Fast R-CNN의 주요 아이디어로는 ROI Pooling, Multi-task loss, Hierarchical Sampling, Truncated SVD이 있습니다.
-
ROI Pooling은 region proposals의 크기를 warp시킬 필요 없이
RoI(Region of Interest) pooling을 통해 고정된 크기의 feature vector를 fully connected layer(이하 fc layer)에 전달합니다. -
Multi-task loss는 모델을 개별적으로 학습시킬 필요 없이 한 번에 학습시킵니다.
- 이를 통해 학습 및 detection 시간이 크게 감소하였습니다.
주요 아이디어들을 하나씩 살펴보겠습니다.
ROI Pooling
RoI(Region of Interest) pooling은 feature map에서 region proposals에 해당하는 관심 영역(Region of Interest)을 지정한 크기의 grid로 나눈 후 max pooling을 수행하는 방법입니다.
각 channel별로 독립적으로 수행하며, 이 같은 방법을 통해 고정된 크기의 feature map을 출력하는 것이 가능합니다.
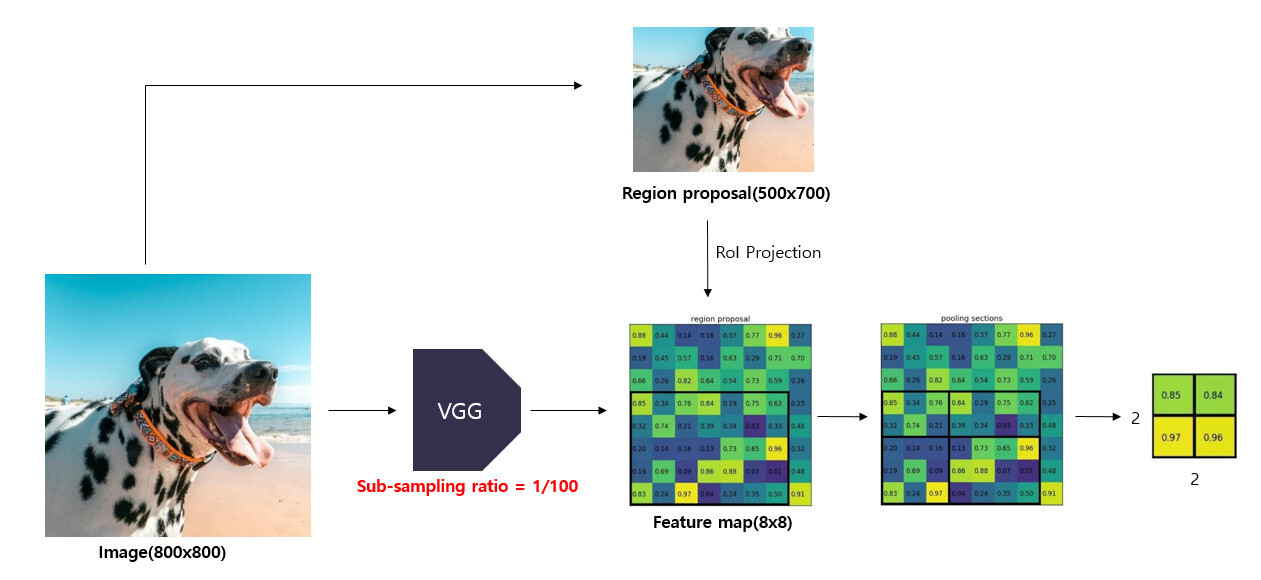
1. 원본 이미지를 CNN 모델에 통과시켜 feature map을 얻습니다.
- 800x800 크기의 이미지를
VGG모델에 입력하여 8x8 크기의 feature map을 얻습니다. - 이 때,
sub-sampling ratio = 1/100이라고 할 수 있습니다(여기서 말하는 subsampling은 pooling을 거치는 과정을 의미).
2. 원본 이미지에 대하여 Selective search 알고리즘을 적용하여 region proposals를 얻습니다.
- 원본 이미지에 Selective search 알고리즘을 적용하여 500x700 크기의 region proposal을 얻습니다.
3. feature map에서 각 region proposals에 해당하는 영역을 추출합니다.
-
Selective Search로 만들어놨던 ROI를 feature map에 projection(투영)합니다. 이 과정을
ROI Projection이라고 합니다. -
작아진 feature map에서
region proposals이encode(표현)하고 있는 부분을 찾기 위해 작아진 feature map에 맞게 region proposals를 투영해주는 과정이 필요합니다.-
이는 region proposal의 크기와 중심 좌표를
sub sampling ratio에 맞게 변경시켜줌으로써 가능합니다. -
Region proposal의 중심점 좌표, width, height와 sub-sampling ratio를 활용하여 feature map으로 투영시켜줍니다.
-
feature map에서 region proposal에 해당하는 5x7 영역을 추출합니다.
-
4. 추출한 RoI feature map을 지정한 sub-window(미리 설정한 HxW)의 크기에 맞게 grid로 나눠줍니다.
-
미리 설정한 HxW크기로 만들어주기 위해서
(h/H) * (w/H)크기만큼 grid를 RoI위에 만듭니다. -
추출한
5x7크기의 영역을 지정한2x2크기에 맞게 grid를 나눠줍니다.
5. grid의 각 셀에 대하여 max pooling을 수행하여 고정된 크기의 feature map을 얻습니다.
-
RoI를 grid크기로 split시킨 뒤 max pooling을 적용시켜 결국 각 grid 칸마다 하나의 값을 추출한다.
-
각 grid 셀마다 max pooling을 수행하여 2x2 크기의 feature map을 얻습니다.
위 작업을 통해 feature map에 투영했던 hxw크기의 RoI는 HxW크기의 고정된 feature vector로 변환됩니다.
- 미리 지정한 크기의
sub-window에서max pooling을 수행하다보니region proposal의 크기가 서로 달라도 고정된 크기의feature map을 얻을 수 있습니다.
💡 이렇게 RoI pooling을 적용함으로써 💡
"원래 이미지를 CNN에 통과시킨 후 나온 feature map에
이전에 생성한 RoI를 projection시키고, 이 RoI를
FC layer input 크기에 맞게 고정된 크기로 변형할 수가 있습니다."
따라서 더이상 2000번의 CNN연산이 필요하지 않고 1번의 CNN연산으로 속도를 대폭 높일 수 있었다.
Multi-task loss (end-to-end trainable)
Fast R-CNN은 Multi-task Loss를 사용해서 R-CNN의 2번째 문제였던 multi-stage pipeline으로 인해 3가지 모델을 독립적으로 학습해서 연산이 공유되지 않는 점을 해결했습니다.
💥 R-CNN에서는 CNN을 통과한 후, 각각 서로 다른 모델인
SVM(classification),bounding box regression(localization)안으로 들어가forward됐기 때문에 연산이 공유되지 않았다. 💥
bounding box regression은 CNN을 거치기 전의 region proposal 데이터가 input으로 들어가고
SVM은 CNN을 거친 후의 feature map이 input으로 들어가기에 연산이 겹치지 않는다.
Fast R-CNN 모델에서는 feature vector를 multi-task loss를 사용하여 Classifier와 Bounding box regressior을 동시에 학습시킵니다.
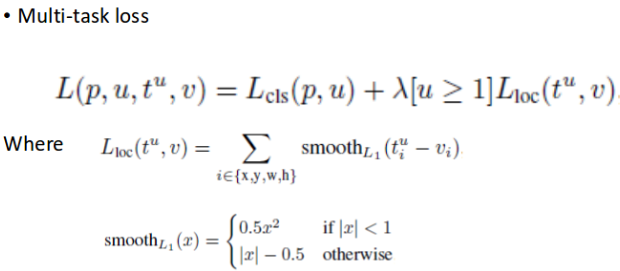
: (K+1)개의 class score
: ground truth class score
: 예측한 bounding box 좌표를 조정하는 값
: 실제 bounding box의 좌표값
: classfication loss(Log loss)
: regression loss (Smooth L1 loss)
💡 Smooth L1 Loss 💡
저자들은 실험 과정에서 라벨 값과 지나치게 차이가 많이 나는 outlier 예측 값에 대해 L2 distance로 계산하여 적용할 경우 gradient가 explode 해버리는 현상을 관찰했다고 합니다. 이를 방지하기 위해서 smooth_L1을 추가한 것입니다.
: 두 loss 사이의 가중치를 조정하는 balancing hyperparameter
- 개의 class를 분류한다고할 때,
배경을 포함한 (K+1)개의 class에 대하여 Classifier를 학습시켜줘야 함 - 는 positive sample인 경우 1, negative sample인 경우 0으로 설정되는 index parameter입니다.
L1 Loss는 R-CNN, SPPnet에서 사용한 L2 loss에 비해 outlier에 덜 민감하다는 장점이 있음- 로 사용
- multi-task loss는
0.8 ~ 1.1%mAP를 상승시키는 효과가 있다고 함
2-2. Architecture & Process
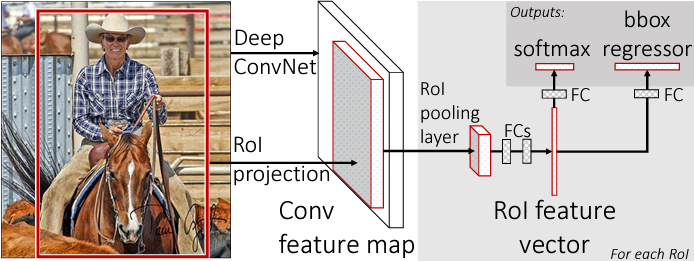
1. Initializing pre-trained network
feature map을 추출하기 위해 VGG16 모델을 사용합니다.
먼저 네트워크를 detection task에 맞게 변형시켜주는 과정이 필요합니다.
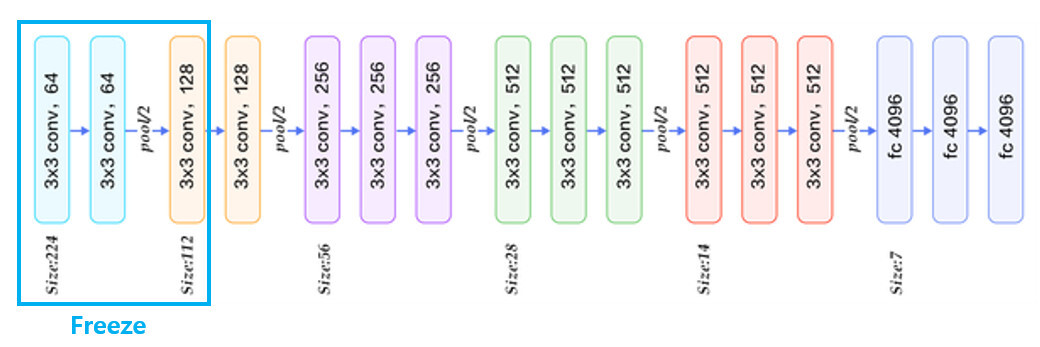
-
VGG16 모델의 마지막 max pooling layer를
RoI pooling layer로 대체해줍니다.- 이 때 RoI pooling을 통해 출력되는 feature map의 크기인
H,W는 후속 fc layer와 호환 가능하도록 크기인7x7로 설정해줍니다.
- 이 때 RoI pooling을 통해 출력되는 feature map의 크기인
-
네트워크의 마지막 fc layer를 2개의 fc layer로 대체합니다.
- 첫 번째 fc layer는 K개의 class와 배경을 포함한
(K+1)개의 output unit을 가지는 Classifier입니다. - 두 번째 fc layer는 각 class별로 bounding box의 좌표를 조정하여
(K+1) * 4개의 output unit을 가지는 bounding box regressor입니다.
- 첫 번째 fc layer는 K개의 class와 배경을 포함한
-
conv layer3까지의 가중치값은
고정(freeze)시켜주고, 이후 layer(conv layer4~ fc layer3)까지의 가중치값이 학습될 수 있도록fine tuning해줍니다.- 논문의 저자는 fc layer만 fine tuning했을 때보다 conv layer까지 포함시켜 학습시켰을 때 더 좋은 성능을 보였다고 합니다.
- 네트워크가 원본 이미지와 selective search 알고리즘을 통해 추출된 region proposals 집합을 입력으로 받을 수 있도록 변환시켜 줍니다.
2. region proposal by Selective search
원본 이미지에 대하여 Selective search 알고리즘을 적용하여 미리 region proposals를 추출합니다.
- 2000개의 region proposals이 생성됩니다.
3. Feature extraction(~layer13 pre-pooling) by VGG16
원본 이미지를 CNN에 통과시켜 feature map을 추출합니다.
- VGG16 모델에
224x224x3크기의 원본 이미지를 입력하고, layer13까지의 feature map을 추출합니다. - 마지막 pooling을 수행하기 전에
14x14크기의 feature map512개가 출력됩니다.
4. ROI Projection
Region proposals를 layer13을 통해 출력된 feature map에 대하여 RoI projection을 진행합니다.
- Selective Search로 찾았었던 RoI를
14x14x512 sized feature map크기에 맞춰서 projection시킵니다.
5. Max pooling by ROI Pooling
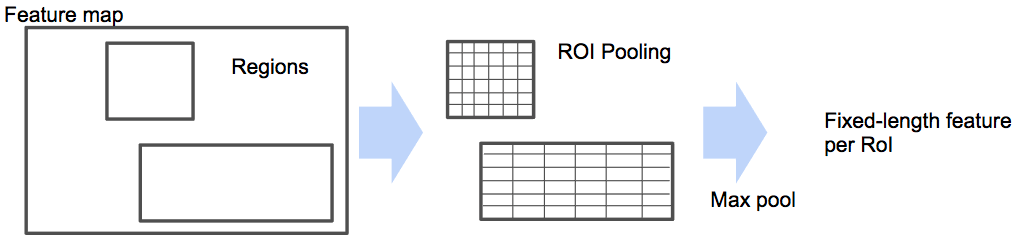
Projection시킨 ROI에 대해 ROI Pooling을 진행합니다.
RoI pooling layer는 VGG16의 마지막 pooling layer를 대체한 것입니다.
이 과정을 거쳐 고정된 7x7 크기의 feature map을 추출합니다.
Input : 14x14 sized 512 feature maps, 2,000 region proposals
Process : ROI Pooling
Output : 7x7x512 feature maps
6. Feature vector extraction by FC Layers
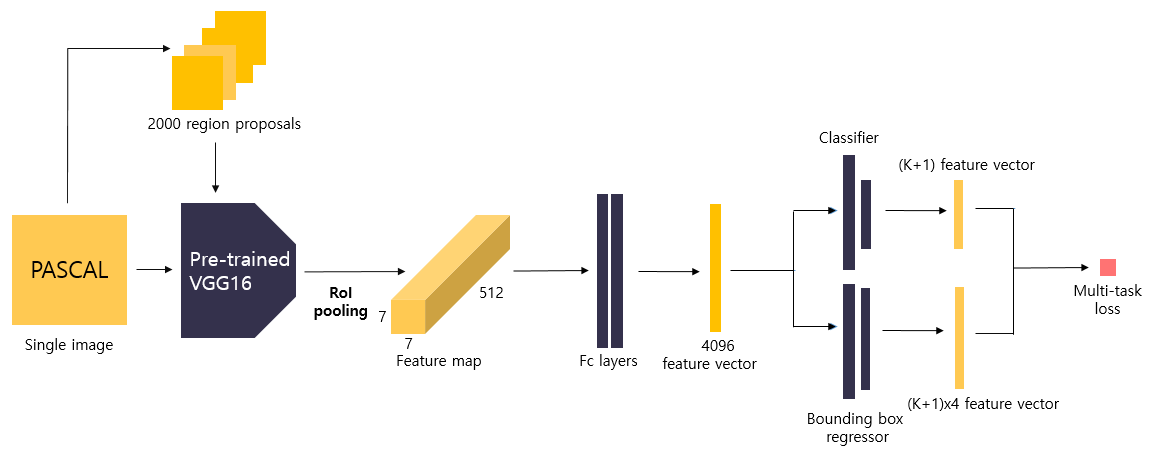
ROI Pooling으로 생성된 feature vector는 Fully Connected Layer를 통과하게 됩니다.
- region proposal별로
7x7x512(=25088)의 feature map을flatten합니다 - Fc layer에 입력하여 fc layer를 통해
4096 크기의 feature vector를 얻습니다.
Input : 7x7x512 sized feature map
Process : feature extraction by fc layers
Output : 4096 sized feature vector
7. Class prediction by Classifier
4096 sized feature vector는 softmax를 통과하여 ROI에 대해 object classification을 수행합니다.
- 4096 크기의 feature vector를 K개의 class와 배경을 포함하여
(K+1)개의 output unit을 가진 fc layer에 입력합니다. - 하나의 이미지에서 하나의 region proposal에 대한 class prediction을 출력합니다.
Input : 4096 sized feature vector
Process : class prediction by Classifier
Output :(K+1)sized vector (class score)
8. Detailed localization by Bounding box regressor
Bounding box regression을 통해 selective search로 찾은 box의 위치를 조정합니다
- 4096 크기의 feature vector를 class별로 bounding box의 좌표를 예측하도록
(K+1) x 4개의 output unit을 가진 fc layer에 입력합니다. - 하나의 이미지에서 하나의 region proposal에 대한 class별로 조정된 bounding box 좌표값을 출력합니다
Input : 4096 sized feature vector
Process : Detailed localization by Bounding box regressor
Output :(K+1) x 4sized vector
9. Train Classifier and Bounding box regressor by Multi-task loss
Multi-task loss를 사용하여 하나의 region proposal에 대한 Classifier와 Bounding box regressor의 loss를 반환합니다.
이후, Backpropagation을 통해 두 모델(Classifier, Bounding box regressor)을 한 번에 학습시킵니다.
Input :
(K+1)sized vector(class score),(K+1) x 4sized vector
Process : calculate loss by Multi-task loss function
Output : loss(Log loss + Smooth L1 loss)
3. Conclusion

Fast R-CNN은 R-CNN 모델보다 학습 속도가 9배 이상 빠르고, 이미지 한 장당 0.3초 (region proposals 추출 시간 포함)이 걸린다고 합니다.
성능 역시 Pascal VOC 2012 Challenge에서 약 66% mAP를 보이면서 성능 향상을 보여줬습니다.
Advantages
💡 Fast R-CNN은
ROI Pooling과Multi-task Loss를 도입함으로써
- ROI(Region of Interest)마다 CNN 연산을 함으로써 속도 저하의 원인인 2000 x CNN 연산을 1번의 CNN 연산으로 감소시켰습니다.
Multi-stage pipelines으로써 모델을 한번에 학습시키지 못하는 문제를 multi-task loss를 활용해서 End-to-End로 여러 모델을 학습시킬 수 있게 만들었습니다.
- ROI Pooling 측면에선, 변경된 feature vector가 결국 기존의 region proposal을 projection시킨 후 연산한 것이므로, 해당 output으로 classification과 bbox regression도 학습 가능합니다.
이 외에도 학습으로 인해 네트워크의 가중치값을 Backpropagation을 통해 update할 수 있다는 장점이 있습니다.
Disadvantages
R-CNN보다 훨씬 빠르다고는 하지만 여전히 느립니다.
- ROI를 생성하는 Selective Search 알고리즘은 CNN 외부에서 진행되므로 이 부분이 속도 저하 요인입니다.
- Region Proposal에만 2초가 소요됩니다.
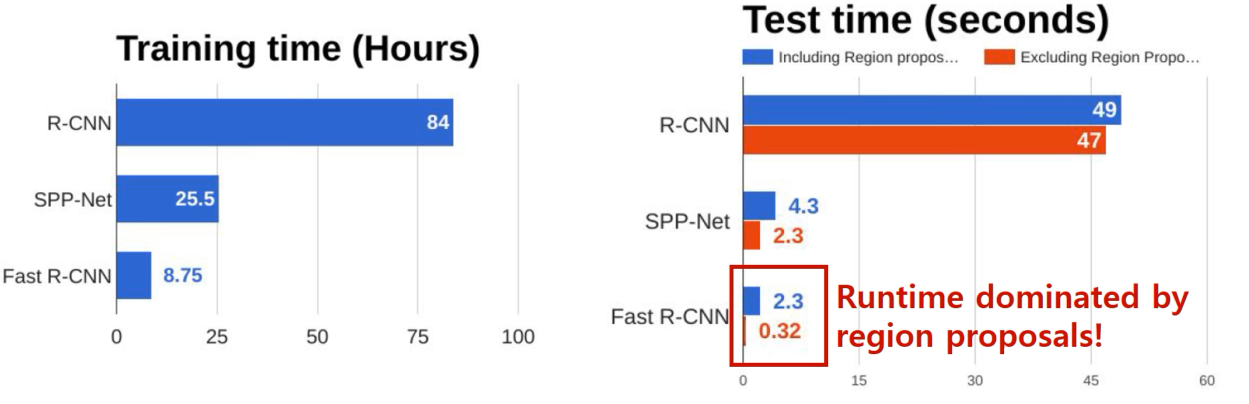
💡 위 문제를
ROI 생성을 CNN 내부에서 하는 RPN (Region Proposal Network)으로 해결한 Faster R-CNN이 제안됩니다." 💡
📔 References
