논문 제목 : Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
저자 : Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun
연도 : 2015
1. Background
Faster R-CNN은 이전 Fast R-CNN의 한계점이였던 Selective Search 알고리즘으로 ROI(Region of Interest)를 찾는 과정을 Network 외부에서 수행하는 문제점을 해결했습니다.
❗ 후보 영역 추출을 위해 사용되는 Selective search 알고리즘은 CPU 상에서 동작하고 이로 인해 네트워크에서 병목현상이 발생하게 됩니다. 그래서 속도도 느립니다.
Faster R-CNN은 이러한 문제를 해결하고자 후보 영역 추출 작업을 수행하는 네트워크인
Region Proposal Network(이하 RPN)를 도입합니다.
Faster R-CNN은 Selective Search를 Neural Network 구조로 변경함으로써,전 네트워크의 GPU 사용으로 빠른 training/inference를 가능하게 만들었습니다.
그리고 Object Detection의 전과정을 Deep Learning으로만 구성한 1번째 Object Detection Model로써, 진정한 End-to-End 학습을 가능하게 했습니다.
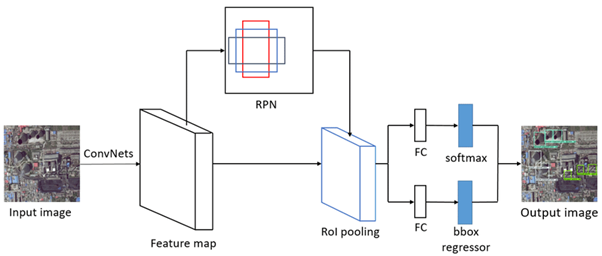
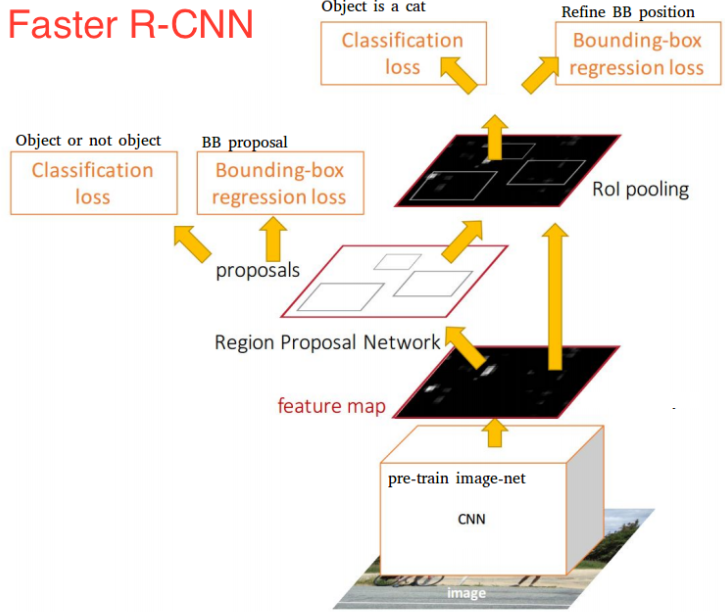
Faster R-CNN 모델은 간략하게 RPN + Fast R-CNN으로 설명할 수 있습니다.
- Fast R-CNN구조에서
conv feature map과RoI Pooling사이에 RoI를 생성하는Region Proposal Network가 추가된 구조입니다.
2. Faster R-CNN
2-1. Introduction
Faster R-CNN 모델의 주요 아이디어로는 크게 2가지가 있습니다.
- RPN (Region Proposal Network)
- RPN 내 Anchor Box 도입
주요 아이디어들을 하나씩 살펴보겠습니다.
1. Anchor Box
Selective Search를 대체하기 위해서 RPN 구현 이슈가 있습니다.
❔ 데이터로 주어질 피처는 pixel 값, Target은 Ground Truth Bounding Box인데 이를 이용해 어떻게 Selective Search 수준의 Region Proposal을 할 것인가❔
그래서 Faster R-CNN은 Object의 유무를 확인하는 후보 box인 Anchor Box를 사용합니다.
Backbone인 VGGNet에서 출력된 원본 이미지에 대한 feature map을 입력으로 받아서 수행됩니다.
<구성>
Dense Sampling
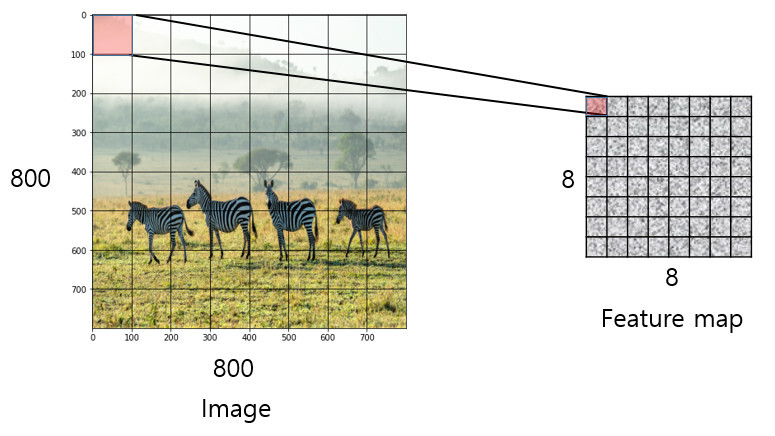
- 원본 이미지를 일정 간격의 grid로 나눠 각 grid cell을 bounding box로 간주하여 feature map에 encode하는
Dense Sampling 방식을 사용합니다. sub-sampling ratio를 기준으로 grid를 나누게 됩니다.💡 가령 원본 이미지의 크기가
800x800이며, sub-sampling ratio가1/100이라고 할 때, CNN 모델에 입력시켜 얻은 최종 feature map의 크기는8x8 (800x1/100)가 됩니다.여기서 feature map의 각 cell은 원본 이미지의 100x100만큼의 영역에 대한 정보를 함축하고 있다고 할 수 있습니다.
원본 이미지에서는 8x8개만큼의 bounding box가 생성된다고 볼 수 있습니다.
❗ 하지만 이처럼 고정된 크기(fixed size)의 bounding box를 사용할 경우, 다양한 크기의 객체를 포착하지 못할 수 있다는 문제가 있습니다 ❗
Anchor Boxes
-
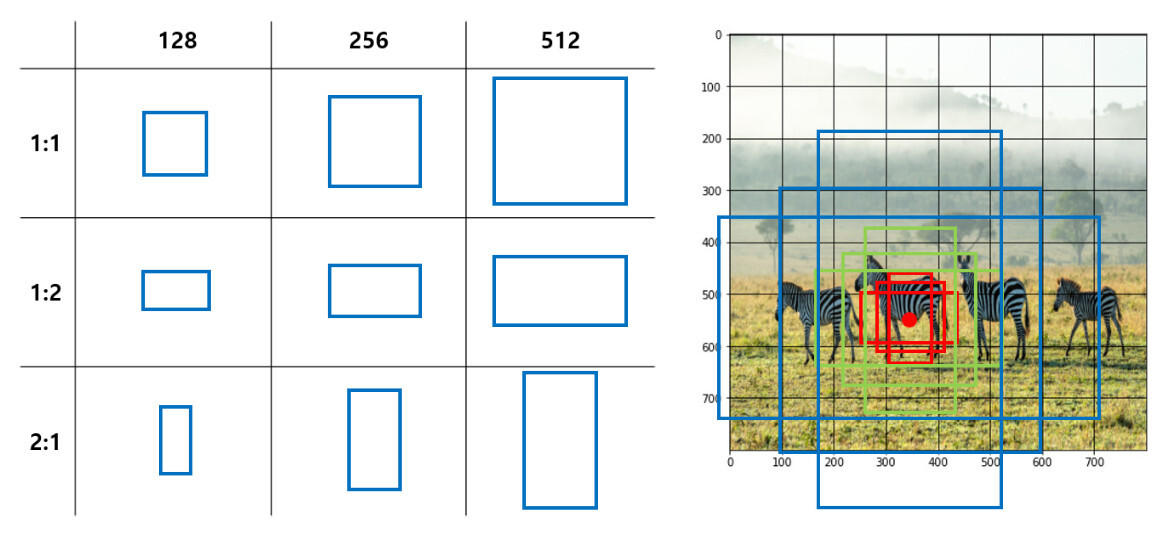
본 논문에서는 이러한 문제를 해결하고자 지정한 위치에 사전에 정의한 서로 다른 크기(scale)와 가로세로비(aspect ratio)를 가지는 bounding box인 Anchor box를 생성하여 다양한 크기의 객체를 포착하는 방법을 제시합니다.
-
논문에서
3가지 scale([128, 256, 512])과3가지 aspect ratio([1:1, 1:2, 2:1])를 가지는 총9개의 서로 다른 anchor box를 사전에 정의(pre-define)합니다.
여기서
scale은 anchor box의width(=),height(=)의 길이를,
aspect ratio는 width, height의 길이의 비율을 의미합니다.aspect ratio에 따른 width, height의 길이는 aspect ratio가 1:1일 때의 anchor box의 넓이를 유지한 채 구합니다.
- 예를 들어 scale이 이며, aspect ratio가 1:1일 때의 anchor box의 넓이는 입니다.
- 여기서 aspect ratio가 1:2, 즉 height가 width의 2배일 때 위와 같은 수식에 따라 width, height를 구합니다. aspect ratio가 2:1인 경우에도 마찬가지입니다.
-
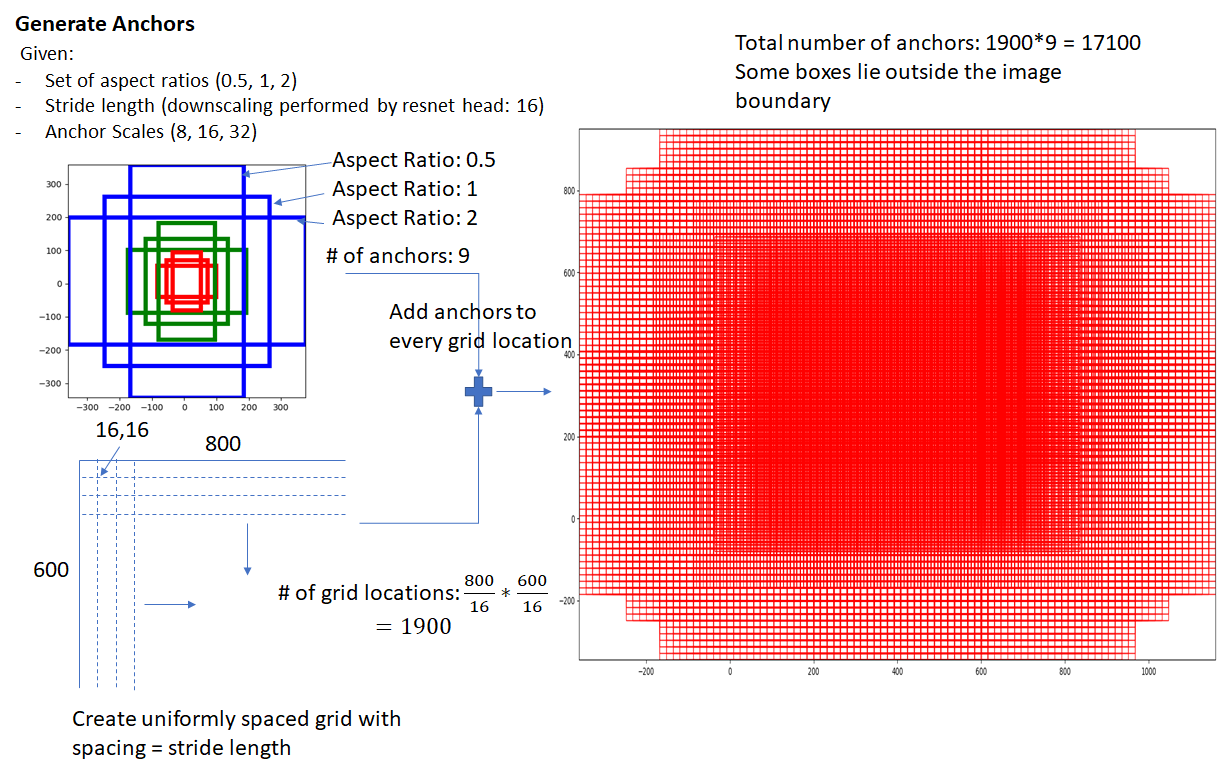
anchor box는 원본 이미지의 각
grid cell의 중심을 기준으로 생성합니다. -
원본 이미지에서
sub-sampling ratio를 기준으로 anchor box를 생성하는 기준점인 anchor를 고정합니다. 이 anchor를 기준으로 사전에 정의한 anchor box 9개를 생성합니다.
💡 위의 그림에서 원본 이미지의 크기는
600x800이며,sub-sampling ratio=1/16입니다.이 때 anchor가 생성되는 수는
1900(=600/16 x 800/16)이며, anchor box는 총17100(=1900 x 9)개가 생성됩니다.
- 이같은 방식을 사용할 경우, 기존에 고정된 크기의 bounding box를 사용할 때보다 9배 많은 bounding box를 생성하며, 보다 다양한 크기의 객체를 포착하는 것이 가능합니다.
2. RPN (Region Proposal Network)
RPN은 VGG16으로부터 feature map을 입력받아 region proposals를 추출하는 네트워크입니다.
-
feature map에 대하여 수많은 anchor box를 생성합니다.
-
anchor boxes에 대한 class score를 매기고, bounding box coefficient를 반환하는 역할을 합니다.
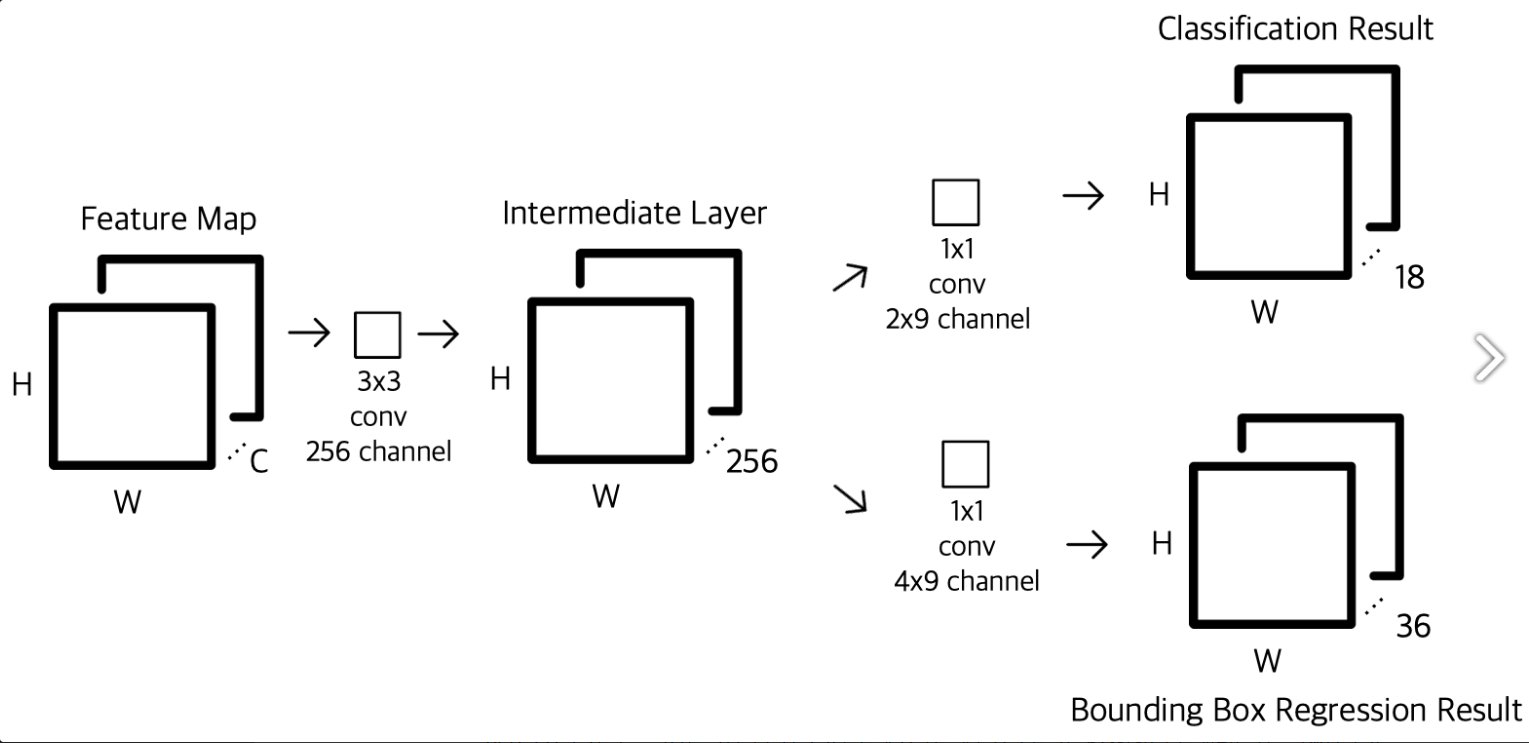
<RPN Flow>
1. 원본 이미지를 pre-trained된 VGG 모델에 입력하여 feature map 획득**
원본 이미지의 크기가
800x800이며, sub-sampling ratio가1/100이라고 했을 때8x8x512(c) 혹은 크기의 feature map이 생성됩니다.💡논문에서 ZF 모델은 256 채널, VGG 모델은 512 채널이라고 합니다.
2. 위에서 얻은 feature map에 대하여 3x3 conv를 256채널 혹은 512채널 연산을 적용 **
-
위 그림에서
intermediate layer에 해당합니다. -
이 때, feature map의 크기가 유지될 수 있도록
padding을 1로 설정합니다.
8x8x256or8x8x512feature map에 대하여 3x3 연산을 적용하여8x8x256or8x8x512 크기의 feature map이 출력됩니다.
3. class score를 매기기 위해서 feature map에 대하여 1x1 conv 연산을 적용**
💡
Fully Connected Layer가 아니라1 x 1 컨볼루션을 이용하여 계산하는 Fully Convolution Network의 특징을 갖습니다.
- 이는 입력 이미지의 크기에 상관없이 동작할 수 있도록 해줍니다.
-
출력하는 feature map의 channel 수가
2x9가 되도록 설정합니다.-
RPN에서는 후보 영역이 어떤 class에 해당하는지까지 구체적인 분류를 하지 않고 binary classification으로 객체가 포함되어 있는지 여부만을 분류합니다.
-
또한 anchor box를 각 grid cell마다
9개가 되도록 설정했습니다. -
따라서 channel 수는
2(object 여부 or not) x 9(anchor box 9개)가 됩니다
-
8x8x256or8x8x512크기의 feature map을 입력 받아
8x8x2x9크기의 feature map을 출력합니다.💡 H x W 상의 하나의 인덱스는 피쳐맵 상의 좌표를 의미하고, 그 아래 18개의 채널은 각각 해당 좌표를 앵커로 삼아 k개의 앵커 박스들이 object인지 아닌지에 대한 예측 값을 담고 있습니다.
💡 즉, 한번의 1x1 컨볼루션으로 H x W 개의 앵커 좌표들에 대한 예측을 모두 수행한 것입니다.
4. bounding box regressor를 얻기 위해 feature map에 대하여 1x1 conv 연산을 적용**
- 출력하는 feature map의 channel 수가
4(bounding box regressor)x9(anchor box 9개)가 되도록 설정합니다.
8x8x256or8x8x512크기의 feature map을 입력 받아8x8x4x9크기의 feature map을 출력합니다.
5.Region Proposal 추출**
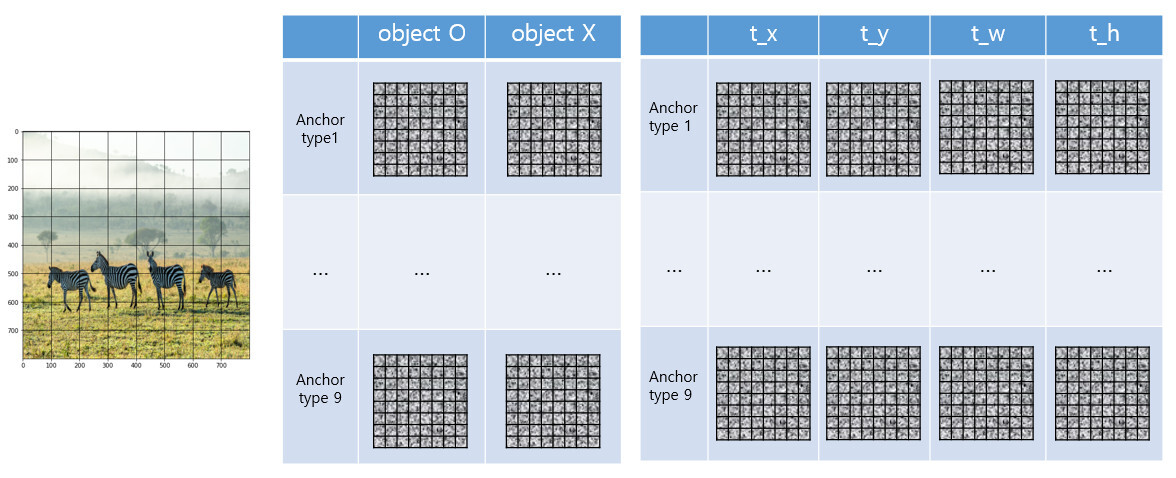
RPN의 출력 결과는 위와 같습니다.
-
좌측 표는 anchor box의 종류에 따라 객체 포함 여부를 나타낸 feature map입니다.
-
우측 표는 anchor box의 종류에 따라 bounding box regressor를 나타낸 feature map입니다.
8x8 grid cell마다 9개의 anchor box가 생성되어 총 576(=8x8x9)개의 region proposals가 추출됩니다.
- feature map을 통해 각각에 대한 객체 포함 여부와 bounding box regressor를 파악할 수 있습니다'
RoI를 계산
-
먼저 Classification을 통해서 얻은 물체일 확률 값들을 정렬한 다음, 높은 순으로 K개의 앵커만 추려냅니다.
-
그 다음 K개의 앵커들에 각각 Bounding box regression을 적용해줍니다
6. Non Maximum Suppression**

- class score에 따라 상위 N개의 region proposals만을 추출하고, Non maximum suppression을 적용
💡 NMS를 마친 후, 최적의 region proposals만을 Fast R-CNN에 전달합니다.
- 위 과정을 거쳐서 얻은 RoI를 VGG Backbone을 거친 다른 원본 이미지 feature map에
projectionRoI Pooling을 적용
2-2. Architecture
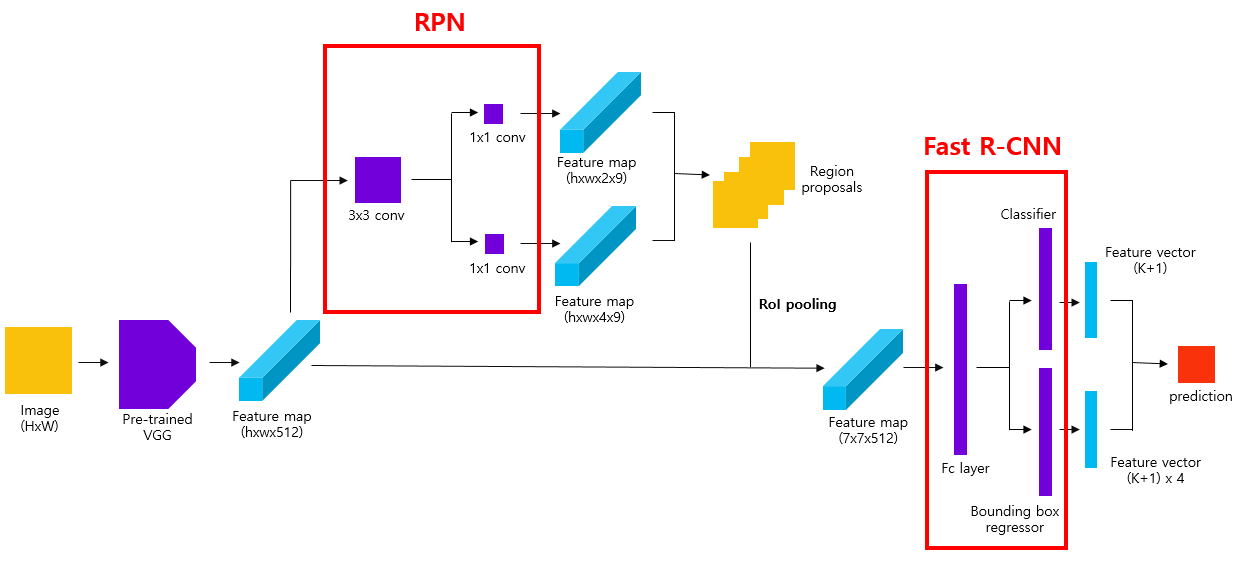
Faster R-CNN은 크게 RPN + Fast R-CNN이라고 할 수 있습니다.
💡
Fast R-CNN구조에서 conv feature map과 RoI Pooling 사이에RoI를 생성하는 Region Proposal Network가 추가된 구조입니다.
2-3. Loss Function (Multi-task Loss)
RPN은 앞서서 Classification과 Bouding Box Regression을 수행했습니다.
Loss Function은 이 두 가지 tasks에서 얻은 loss를 엮은 형태를 취하고 있습니다.
💡 RPN과 Fast R-CNN을 학습시키기 위해 Multi-task loss를 사용합니다.
하지만 RPN에서는 객체의 존재 여부만을 분류하는 반면, Fast R-CNN에서는 배경을 포함한 class를 분류한다는 점에서 차이가 있습니다.

① 는 번째 앵커 박스가 객체일 확률을 말합니다.
② 는 ground-truth label입니다.
- 앵커가 positive이면 1, negative이면 0입니다. negative라는 건 배경이라는 의미입니다.
③ 는 예측 경계 박스의 4가지 좌표값입니다.
④ 는 실제 경계 박스의 4가지 좌표값입니다.
⑤ 는 분류 손실을 나타냅니다.
- 두 가지 클래스(객체 vs. 객체가 아님)에 대한 로그 손실입니다.
⑥ 는 경계 박스 회귀 손실을 뜻합니다.
- 참고로 회귀 손실값은 positive 앵커 박스일 때만(객체 일 때만) 활성화됩니다.
- negative일 때, 곧 배경일 때는 경계 박스를 구할 필요가 없기 때문입니다.
- 회귀 손실에 x 가 포함되므로, 앵커 박스가 negative일 때는 이 값이 0이 됩니다
( = 앵커가 positive이면 1, negative이면 0).
분류 손실과 회귀 손실 모두 ⑦ 와 ⑧ 로 나눠서 정규화했습니다.
분류 손실, 회귀 손실 간 균형을 맞추기 위해 ⑨ λ 파라미터도 두었습니다.
- 본 논문에서는 = 256, = 2,400를 사용합니다.
- 그리고 = 10으로 설정해 분류 손실과 회귀 손실을 거의 같은 비중으로 취급합니다.
- = 1/256이고, = 10/2,400 = 1/240
2-4. Process
전반적인 프로세스는 위 RPN과 기존 Fast R-CNN 구조를 차용합니다.
3. Conclusion


Faster R-CNN 모델은 PASCAL VOC 2012 데이터셋에서 mAP 75.9%를 보이면서 Fast R-CNN 모델보다 더 높은 detection 성능을 보였습니다.
또한, Fast R-CNN 모델이 0.5fps(frame pre second)인 반면 Faster R-CNN 모델은 17fps를 보이며, 속도 면에서 10배가 향샹된 결과를 보였습니다.
하지만 논문의 저자는 detection 속도에 대해 "near real-time"이라고 언급하며, 실시간 detection에는 한계가 있음을 인정했습니다.
Advantages
진정한 의미의 end-to-end object detector
- Selective Search를 사용하여 계산해왔던 Region Proposal 단계를 Neural Network 안으로 끌어와서 모든 과정을 GPU로 학습
- 진정한 의미의 end-to-end object detection 모델을 제시
Fast R-CNN보다 빠른 속도
- Region Proposals 개수가 몇 배가 감소했는데 10배 향상된 fps를 보입니다.
또한 feature extraction에 사용하는 convolutional layer의 feature를 공유하면서 end-to-end로 학습시키는 것이 가능해졌습니다.
📔 References
