[2022] YOLOv7 : Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
Paper Review
0. Background
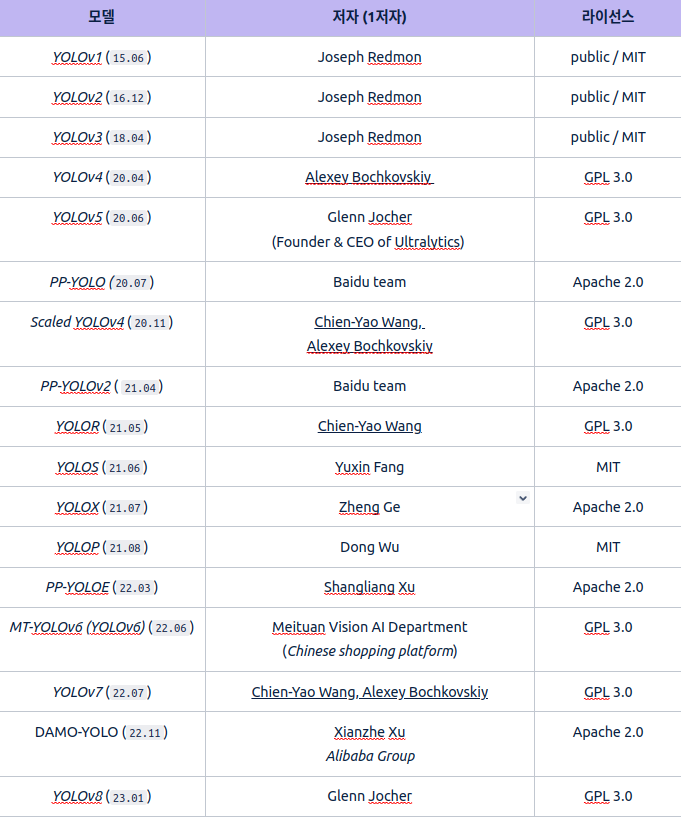
YOLO Timeline
()는 최초 submission 기준
WongKinYiuentered the CV research stage with aCross Stage Partial networks`, which allowed YOLOv4 and YOLOv5 to build more efficient backbones.
Bag-of-Freebies vs Bag-of-Specials
Bag-of-Freebies

YOLOv4 에서 제안됐던 기법
Data augmentation, Loss function, Regularization 등 학습에 관여하는 요소로, training cost를 증가시켜서 정확도를 높이는 방법들을 의미
inference 과정 중에 추가 계산 비용을 발생시키지 않으면서 학습 네트워크의 성능을 향상시키기 위해 조합하여 사용할 수있는 여러 가지 기법들을 의미
Bag-of-Specials
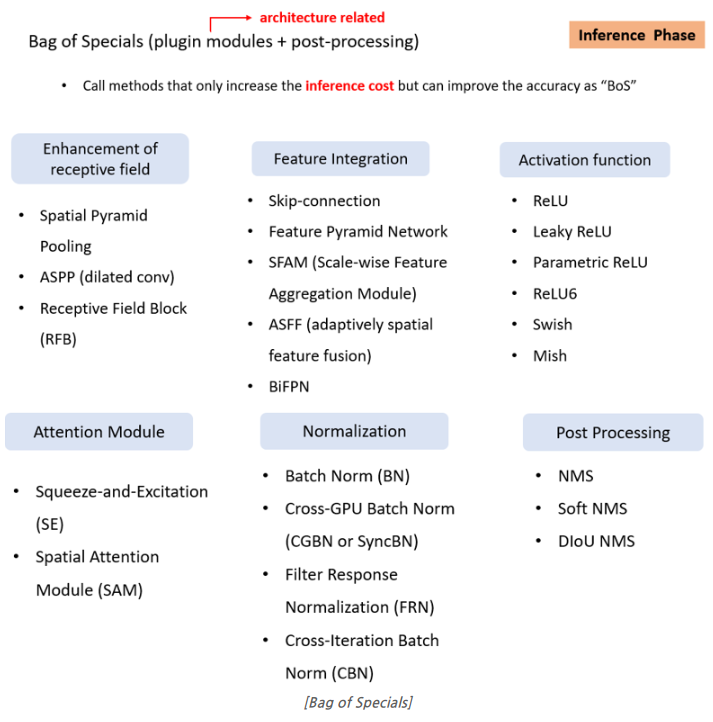
BoF & BoS 둘 다 YOLOv4 에서 언급됐던 기법들
Architecture 관점에서의 기법들이 주를 이루고, post-processing도 포함이 돼있음
오직 Inference Cost만 증가시켜서 정확도를 높이는 기법들을 의미
BoF는 학습 전체와 관련된 느낌이라면 BoS는 학습에서는 Forward pass만 영향을 주고, 학습된 모델의 Inference 하는 부분에 관여하는 것이 차이
BoF의 특성들은 탐지 속도를 저하시키지 않으면서 정확도를 향상시킴
YOLOv7이 전 YOLO versions보다 속도와 정확도가 둘 다 향상된 이유
Maror methods proposed
Architecture
- Extended-ELAN
- Compound Model scaling (model scaling for concatenation-based models)
Bag-of-Freebies
- Model re-parameterization
- Dynamic label assignment
- etc
1. Introduction
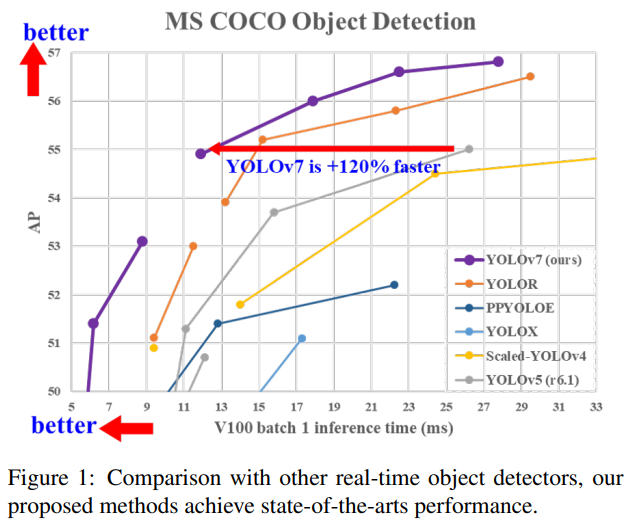
YOLOv7 은 5 ~ 160 FPS 범위 기준 속도와 정확도 측면에서 현존하는 모든 object detectors를 능가했다고 합니다.
GPU V100에서 30 FPS 이상의 모든 real-time object detectors 중에서 56.8% AP로 가장 높은 정확도를 달성한다고 합니다.
YOLOv7-E6은
transformer based detector인 SWIN-L Cascade-Mask R-CNN보다 509%의 속도, 2%의 정확도가 향샹됐습니다.
Convolution 기반 검출기인 ConvNeXt-XL Cascade-Mask R-CNN보다 551%의 속도, 0.7%의 정확도가 향상됐습니다.
저자들은 최근 real-time object detection의 성능 향상을 위한 mainstream을 크게 2가지로 정의합니다.
-
Improving the inference speed (on edge CPU : e.g. MCUNet, NanoDet)
-
Designing efficient architecture (strategy to optimize the architecture)
그러나 YOLOv7의 저자들은 이러한 흐름과 다소 다른 개발 방향을 제시합니다.
Inference Cost를 증가시키지 않으면서 Object Detection의 정확도를 향상시키기 위한 최적화된 모듈과 최적화 방법들에 focusing을 한다고 합니다. (Training Cost는 강화될 수 있다고도 합니다)
이러한 모듈과 방법들을 Trainable Bag-of-Freebies 이라고 부릅니다.
어떤 Trainable BoF를 제안했을까??
최근에 model re-prameterization과 dynamic label assignment가 network training과 object detection 분야에서 중요한 토픽이 되어왔다.
따라서 저자들도 상기 기법들의 효율적인 방법을 제안한다.
for Model Re-parameterization
model re-parameterization 전략들을 서로 다른 네트워크의 레이어에 적용할 수 있는 gradient propagation path 개념으로 분석했다.
그리하여 Planned Re-Parameterized Model 제안
for dynamic label assignment
저자들은 multiple output layers를 사용하여 모델을 학습하게 될 경우 “각각 다른 branches에서 나온 outputs에서 확인되는 dynamic targets은 어떻게 label assigning하지?”의 문제 고민
그리하여 multiple output layers가 있는 모델에 dynamic label을 할당하는 coarse-to-fine lead guided label assignment 제안
위의 두가지 bof가 큰 contribution을 가지며 이 외에도 아래 섹션에서 자잘한 방법들이 소개됨
또한 model scailing에 있어서 자체적으로 parameter와 computation을 고려한 방법을 제시하여 다양한 계열의 yolov7 제공
2. Related Work
2-1. Real-time object detectors
SOTA object detectors들은 보통 다음과 특성들이 요구된다.
- 더 빠르고 강력한 네트워크 아키텍처
- 더 효과적인 기능 통합 방법
- 더 정확한 detection 방법
- 더 robust한 loss fucntion
- 더 효과적인 label assignment 방법
- 더 효과적인 학습 방법
본 논문은 추가적인 데이터나 큰 모델이 요구되는 self-supervised learning이나 knowledge distillation를 다루지 않는다.
대신
4,5,6와 관련된 SOTA methods에서 파생된 이슈들을 다루는new trainable bag-of-freebies를 다룰 것이다.
2-2.Model re-parameterization
Model re-parameterization 기법은 multiple computational modules을 inference 단계에서 하나로 병합한다.
Model re-parameterization은 하나의 ensemble technique로 간주될 수 있으며, 이를 2가지의 카테고리로 나눌 수 있다.
-
Model-level ensemble
-
최종 inference model을 얻기 위해 2가지의 practice가 있습니다.
-
서로 다른 training data로 동일한 여러 모델을 훈련한 다음, 이 학습된 모델들의 가중치를 평균화
-
각각 다른 iteration number에서 모델의 가중치의 가중 평균을 수행
-
-
Module-level ensemble
-
최근에 더 인기가 있는 연구 이슈
-
이 기법은 training하면서 module을 동일하거나 다른 module branches로 분할하고, inference하면서 multiple branched modules를 완전히 동등한 module로 통합하는 것
-
하지만 제안된 모든 re-parameterized module을 다른 아키텍처에 완벽히 적용할 수 있는 것은 아님
-
이러한 점을 상기하며 저자들은 new re-parameterization module과 다양한 아키텍처 관련 application strategies를 제안함
2-3. Model Scaling
Model scaling은 이미 설계된 모델을 scale up 또는 scale down하여 다른 computing devices에 fit하게 만드는 방법이다.
Model scaling 방법은 일반적으로 network parameters, computation, inference speed, accuracy에 대한 양호한 트레이드 오프를 가지기 위해서 resolution (size of input image), depth (number of layer), width (number of channel), stage (number of feature pyramid)와 같은 다양한 scaling factor를 사용한다.
Network Architecture Search (NAS)는 일반적으로 사용되는 model scaling method 중 하나이다.
-
NAS는 복잡한 규칙들을 정의하지 않고도 자동으로 search space로부터 적합한 scaling factors를 찾는다.
-
하지만 NAS의 단점은 model scaling fa그 이유는 대부분의 인기있는 NAS 아키텍처는 상관 관ctor search를 완료하기 위해 너무 많은 연산량을 요구한다는 것이다.
researcher는 parameters와 operation의 양과 scaling factor 와의 관계를 분석하여 일부 규칙들을 직접 추정하여 model scaling에 요구되는 scaling factor를 구한다.
문헌에 따르면, 거의 모든 model scaling methods가 각 scaling factor를 독립적으로 분석하며, compound scaling 기법도 scaling factor를 독립적으로 최적화한다.
상관 관계가 많이 없는 scaling factors들을 다루기 때문이다.
저자들은 DenseNet 또는 VoVNet과 같은 concatenation 기반 모델들이 depth가 scale될 때 input width of some layers가 변경하는 것을 보았다.
- 제안된 아키텍처는 concatenation 기반이기 때문에, 이 모델에 대해 새로운 compound scaling method를 설계해야한다.
3. Architecture
3-1. Extended efficient layer aggregation networks
효율적인 아키텍처 설계에 관한 대부분의 문헌 에서, 주로 고려해야할 사항은 parameter의 개수, 연산량 그리고 computational density라고 한다.
- 메모리 접근 비용의 특성에서부터
입출력 채널 비율,아키텍처의 분기 수,element-wise 연산에서네트워크 inference speed에 대한 영향을 분석했다.
추가적으로 activation에서 model scaling을 수행할 때 , convolutional layers의 출력 tensor 안의 요소 수를 고려해야 한다.

Figure 2(b)의 CSPVoVNet는 VoVNet을 변형시킨 구조이다. 앞서 언급한 기본적인 설계 문제들을 고려할 뿐만 아니라, CSPVoVNet의 아키텍처가 다른 layers들의 weights가 다양한 features들을 학습하도록 gradient path도 분석한다.
상기 언급한 gradient analysis approach는 추론을 더 빠르고 정확하게 한다.
Figure 2(c)의 ELAN은 “효율적인 네트워크를 설계하하려면 어떻게 해야되는가?” 를 고려한 모델이다.
그들은 가장 짧고 가장 긴 gradient path를 컨트롤함으로써, 더 깊은 네트워크가 효과적으로 학습하고 수렴할 수 있다고 결론을 내렸다.
본 논문에서는 ELAN을 기반으로 한 확장 모델인 Extended-ELAN (E-ELAN)을 제안한다.
-
large scale ELAN는 gradient path length와 computational blocks의 스택 수와 관계없이 안정적인 상태에 도달했다.
-
만약 더 많은 computation blocks이 무제한으로 쌓인다면, 이 안정된 상태가 파괴될 수 있고, 파라미터 이용률이 낮아질 것이다.
제안된 E-ELAN은 기존의 gradient path를 파괴하지 않고 네트워크의 학습 능력을 지속적으로 향상시키기 위해서 expand, shuffle, merge cardinality를 사용한다.
-
아키텍처 측면에서, E-ELAN은 computaitonal block만 변경이 되고, transition layer의 아키텍처는 완전히 변경되지 않는다.
-
우리의 전략은 group convolution을 사용해서 computational blocks의 채널과 카디널리티를 확장하는 것이다.
프로세스
-
computational layer의 모든
computational blocks에 동일한 group parameter와 channel multiplier를 적용하고, -
각 computational block에 의해 계산된 feature map은 설정된 group parameter
g에 따라서g groups으로 섞인 다음, 함께 연결된다 -
이 때, 각 그룹의 feature map에 있는 채널 수는 기존 아키텍처의 채널 수와 동일하다
-
마지막으로, merge cardinality를 수행하기 위해서 feature maps의 g groups을 추가한다.
-
기존 ELAN의 아키텍처 설계를 유지하는 것 외에도 computational blocks의 다른 그룹들이 보다 다양한 features를 학습할 수 있도록 가이드 할 수 있다.
3-2. Model scaling for concatenation-based models
Model scaling의 주요 목적은 모델의 일부 속성을 조정하고 서로 다른 inference speed의 요구를 충족하기 위해서 서로 다른 scale의 모델들을 만드는 것이다.
예를 들면, EfficientNet scaling은 width (quantity of channel), depth, resolution을 고려했고, scaled-YOLOv4 같은 경우는 stage 수를 조정했다.
-
이러한 방법들은 주로 PlainNet이나 ResNet과 같은 아키텍처에서 사용된다
-
이러한 아키텍처가 scaling up이나 scaling down을 수행할 때, 각 layer의 in-degree와 out-degree는 변경되지 않으므로, 우리는 scaling factor가 parameters와 computation에 미치는 영향을 독립적으로 분석할 수 있다.
그러나, 이러한 방법들이 concatenation 기반의 아키텍처에 적용된다면, scaling up or down on depth를 수행할 때, 그림 3 (a), (b)와 같이 concatenation-based computation block 다음에 있는 translation layer의 in-degree가 감소하거나 증가하는 것을 볼 수 있다.
위의 현상을 통해서 concatenation-based model은 서로 다른 scaling factors를 별도로 분석할 수 없고 같이 고려해야된다는 것을 볼 수 있다.
-
예를 들어 scaling up depth는 transition layer의 input channel과 output channel 사이의 비율 변화를 유발하여 모델의 하드웨어 사용량을 감소시킬 수 있다.
-
따라서 concatenation-based model을 위한 compound model scaling을 제안해야 한다.
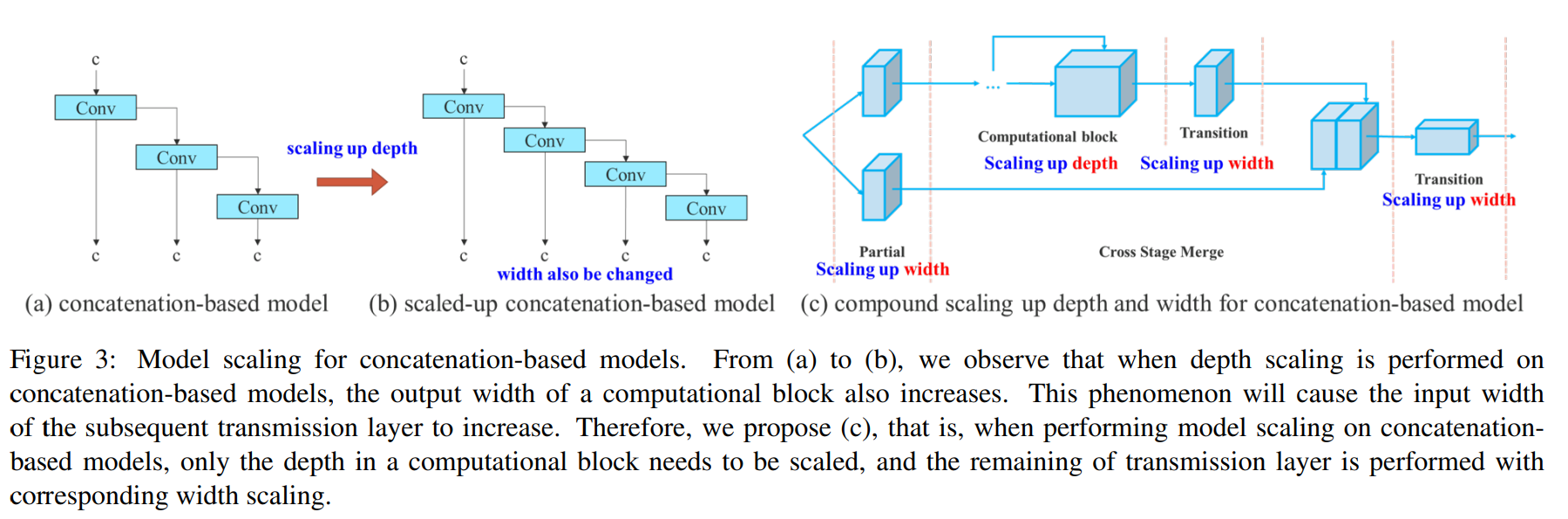
-
computational block의 depth factor를 조정할 때, 그 block의 output channel 변화도 계산해야 한다.
-
그 다음, translation layer에 동일한 변화량으로 width factor scaling을 수행한다.
-
그 결과는
figure 3(c)에서 확인할 수 있다.
우리가 제안하는 compound scaling method는 모델의 초기 설계시 모델이 가지고 있던 특성을 유지하고 최적의 구조를 유지할 수 있다.
4. Trainable bag-of-freebies
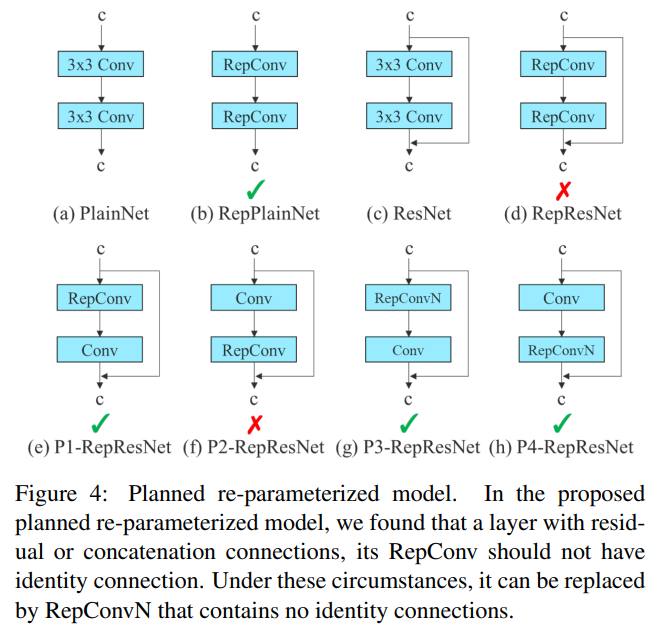
4-1. Planned re-parameterized convolution
💡 Model re-parameterization?? 💡
Training시에 여러 개의 layer(Conv or BN)들을 학습하고, Inference 시에는 해당 layer들을 하나로 결합
대표적 예시 모델
RepVGG, Conv-BN folding
YOLOv7에서는 RepVGG를 약간 변형시킨 상태의 re-parameterization 방법 제안
YOLOv7은 RepVGG의 변형을 사용
RepVGG는 reparameterization 방법을 사용한 것
-
Training시에는 병렬적으로 여러 개의 Convolution layer와 Batch Normalization layer를 학습 -
Inference시에 해당 layers를 하나의 Convolution layer로 “reparameterization” (fusing)
RepConv는 VGG에서 훌륭한 성능을 보여줬지만, ResNet, DenseNet과 다른 아키텍처들에 적용했을 때, 정확도가 크게 저하된다.
따라서 우리는 gradient flow propagation paths를 이용하여 re-parameterized convolution이 어떻게 다른 네트워크와 결합해야되는지 분석한다.
이에 따라, planned re-parameterized convolution을 설계했다.
RepConv는 실제로 3 x 3 convolution, 1 x 1 convolution, identity connection를 하나의 convolution layer에 결합한다.
-
RepConv와 다른 아키텍처의 조합 및 해당 성능을 분석한 후, RepConv의 identity connection이 RenNet의 잔차와 DenseNet의 연결을 파괴하여 서로 다른 feature maps에 기존보다 더 다양한 gradients를 제공하게 된다.
-
이러한 이유로, RepConv without identity connection (RepConvN)을 사용하여 planned re-parameterized convolution을 설계한다.
-
우리가 생각했을 때, residual 혹은 concatenation이 있는 convolution layer가 re-parameterized layer로 대체될 때, identity connection이 없어야 한다.
-
figure 4는 PlainNet과 ResNet에서 사용되는 우리가 설계한 planned re-parameterized convolution의 예를 보여준다. -
Residual-based model과 concatenation-based model에서 진행했던 planned re-parameterized convolution 실험은 ablation study에서 나올 것이다.
-
4-2. Coarse for auxiliary and fine for lead loss
Deep Supervision은 deep networks를 훈련하는데 자주 사용되는 기술이다.
-
이것의 주요한 개념은 네트워크 중간 계층에 extra auxiliary head를 추가하고, assistant loss를 가이드로 하는 얕은 network 가중치를 추가하는 것
-
일반적으로 잘 수렴하는 ResNet 및 DenseNet과 같은 아키텍처 경우도 deep supervision 은 여전히 많은 tasks에서 모델의 성능을 크게 향상 시킬 수 있다.
-
figure5와 (a) & (b)는 각각 supervision의 유무에 따른 아키텍처를 보여준다.
-
본 논문에서는 final Label Assignment ouput을 담당하는 head를 lead head라고 하고, 학습을 보조하는데 사용되는 헤드를 auxiliary head라고 한다.
Label Assignment에 대해 discuss하려고 한다.
💡 Soft label ?? 💡
실제 라벨이 가장 높은 확률값을 가지되, 정답이 아닌 클래스들도 작은 확률을 나눠갖도록 하는 것이 soft label이다.
- 이렇게 label smoothing을 사용하면 딥러닝 모델이 예측결과에 대해 over confident해지는 현상을 완화할 수 있다.
YOLO label assignment에서 bounding box와 ground truth의 IoU를 objectness의 soft label로 사용하여 오직 ground truth만 사용한 것보다 성능 향상
과거에는 deep network 학습에서 레이블 할당은 일반적으로 gt를 직접 참조하고 주어진 규칙에 따라 hard label을 생성했다.
하지만 최근 몇 년 동안, object detection을 예로 들면, 연구자들이 네트워크에서 생성된 예측 결과의 quality와 분포를 사용한 다음, gt와 함께 몇 가지 계산과 최적화 방법들을 사용하여 신뢰할 수 있는 soft label을 고려한다.
본 논문에서는, 네트워크 예측 결과를 gt와 함께 고려한 다음 soft label을 할당하는 메커니즘을 “label assigner”라고 한다.
Deep Supervision은 auxiliary head 또는 lead head의 상황과 관계없이 목표에 대한 학습을 할 필요가 있다.
- 대부분의 label assignment 방법들은 lead head와 auxiliary head와 같이 2가지 heads가 동시에 있을 경우 soft label 생성 불가능
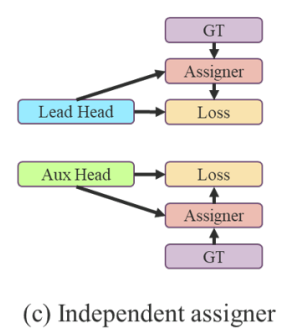
Soft Label을 생성하지 못하는 lead head와 auxiliary head를 독립적으로 계산하는 label assignment (기존 연구)
soft label assigner와 관련된 기술들을 개발하는 동안, 우리는 우연적으로 새롭게 파생된 이슈 “soft label을 auxiliary head와 lead head에 할당하는 방법”을 발견했다.
우리가 아는 한, 지금까지 관련 문헌들은 이 이슈를 탐구하지 않았다.
현재 가장 인기 있는 방법의 결과는 figure 5 (c)에서 확인할 수 있다.
auxiliary head와 lead head를 분리한 후, 그것들의 자체 예측 결과와 gt를 사용하여 label assignment를 수행한다.
본 논문에서 제안된 방법은 lead head 예측에 의해 auxiliary head와 lead head 양쪽을 다 가이드하는 새로운 label assignment이다.
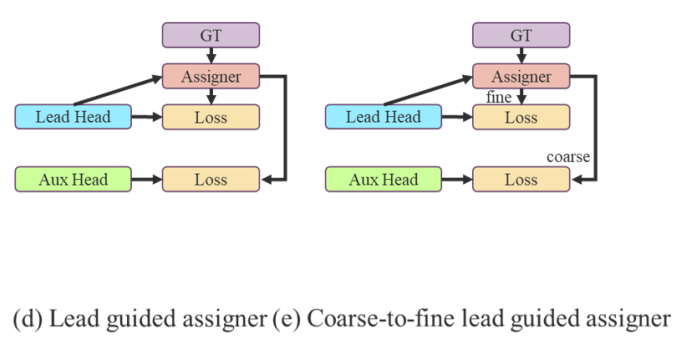
다시 말해서, auxiliary head와 lead head 학습에 사용되는 각각의 coarse-to-fine hierarchical labels를 생성하기 위해 lead head 예측을 지침으로 삼는다.
제안된 두 가지 deep supervision label assignment strategies는 figure 5 (d)와 (e)에서 각각 확인할 수 있다.
-
Lead head guided label assginer
-
Coarse-to-fine lead head guided label assigner
Lead head guided label assigner
Lead head guided label assigner는 주로 lead head의 예측 결과와 gt를 기반으로 계산되고, 최적화 프로세스를 통해서soft label을 생성한다.- 이러한 soft label set은 auxiliary head와 lead head 양쪽 모두에 대한 target training model로써 사용된다.
- 그 이유는, lead head가 상대적으로 학습 능력이 강하기 때문에, lead head로부터 생성된 soft label이 source data와 target 간의 분포와 상관관계를 더 잘 나타내기 때문이다.
- 이러한 학습을 우리는 일종의 generalized residual learning으로 볼 수 있다.
- Shallower auxiliary가 lead head가 학습한 정보를 직접 할 수 있게 함으로써, lead head는 아직 학습되지 않은 residual information을 학습하는데 더 집중할 수 있게 된다.
Coarse-to-fine lead head guided label assigner
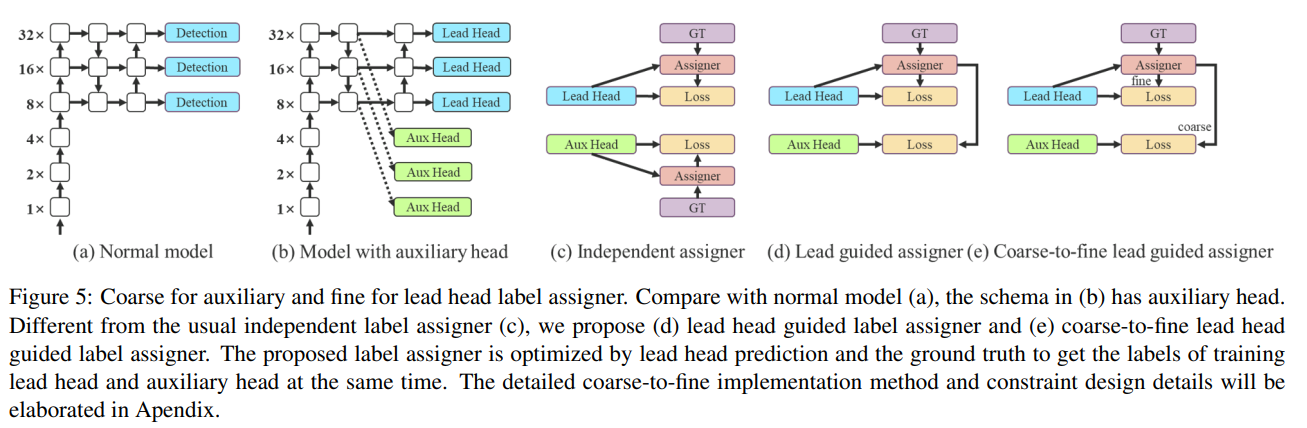
-
coarse-to-fine lead head guided label assigner도 또한 lead head와 gt의 예측 결과를 사용하여 soft label을 생성한다.
-
그러나 그 과정에서 다른 두 가지 soft label인 coarse label과 fine label을 생성한다.
- Fine label은
- lead head guided label assigner에 의해 생성된 soft label과 동일
- Main Loss로 사용
- Coarse label은
- posivitive sample assignment process의 constarints를 완화하는 방법으로 grids를 좀 더 positive target으로 여겨지도록 해서 생성됨
- 그 이유는 auxiliary head의 학습 능력이 lead head에 비해 강하지 않기 때문이며, 학습해야 할 정보가 손실되지 않도록 하기 위해서 object detection task 내 auxiliary head의 recall을 최적화하는데 집중할 것이기 때문이다.
- Lead head의 출력은 최종 출력으로 높은 recall 결과를 필터링할 수 있습니다.
- 하지만, 만약 coarse label의 추가적인 가중치가 fine label에 근접할 경우, 최종 예측에서 bad prior가 발생할 수 있다.
- 그러므로, 이러한 extra coarse positive grid가 영향을 덜 받도록 하기 위해, decoder에 제한 사항을 둠으로써 extra coarse positive grids가 soft label을 완벽하게 생성할 수 없게 했다.
- 상기 언급한 메커니즘은 fine label과 coarse label의 중요성이 학습 과정에서 동적으로 조정되게 하고, fine label의 optimizable upper bound가 항상 coarse label보다 높게 만든다
- Fine label은
4-3.Other trainable bag-of-freebies
3가지의 추가적인 bof를 훈련할 때 사용하였다. 이러한 bofs의 훈련 디테일은 Appendix에서 확인할 수 있다.
Batch normalization in conv-bn-activation topology(배치)
- 주로 bn layer를 convolution layer에 직접 연결한다
- 이러는 목적은 bn의 평균과 분산을 inference stage에서 convoluation layer의 bias와 weight에 통합하는 것
Implicit knowledge
- convolution feature map과 결합된 YOLOR의 Implicit knowledge는 inference stage에서 pre-computing을 통해 벡터로 단순화시킬 수 있다.
- 이 벡터는 이전 혹은 다음 conv layer의 bias와 weight와 결합될 수 있다.
EMA (Exponential Moving Average) Model
- 최종 inference model로써 전적으로 EMA 모델 사용
5. Experiments
5-1. Experimental setup
-
Microsoft COCO dataset 사용
-
모든 실험은 pre-trained model을 사용하지 않음
-
Train : train 2017 set / 검증 및 하이퍼 파라미터 선택을 위해 val 2017 set / test 2017 test
- 자세한 학습 파라미터 설정은 부록에 명시돼있음.
Edge GPU 용 모델 : YOLOv7-tiny
normal GPU 용 모델 : YOLOv7
cloud GPU 용 모델 : YOLOv7-W6
YOLOv7-X
- neck에 stack scaling을 하고, 제안된 compounding scaling method를 사용하여 전체 모델의 width (채널 수)와 depth을 scaling-up함
YOLOv7-E6 & YOLOv7-D6
- YOLOv7-W6의 경우, 새롭게 제안된 compound scaling method 사용하여 e6, d6
YOLOv7-E6E
- YOLOv7-E6에 E-ELAN을 적용
Activation Function
-
YOLOv7-tiny → leaky ReLU (edge GPU-oriented architecture)
-
Others → SiLU
각 모델에 대한 scaling factor에 대한 설명은 부록에 있다.
5-2. Baseline
-
YOLO 이전 버전 (v4, scaled-v4)과 yolor을 baseline으로 선택한다.
-
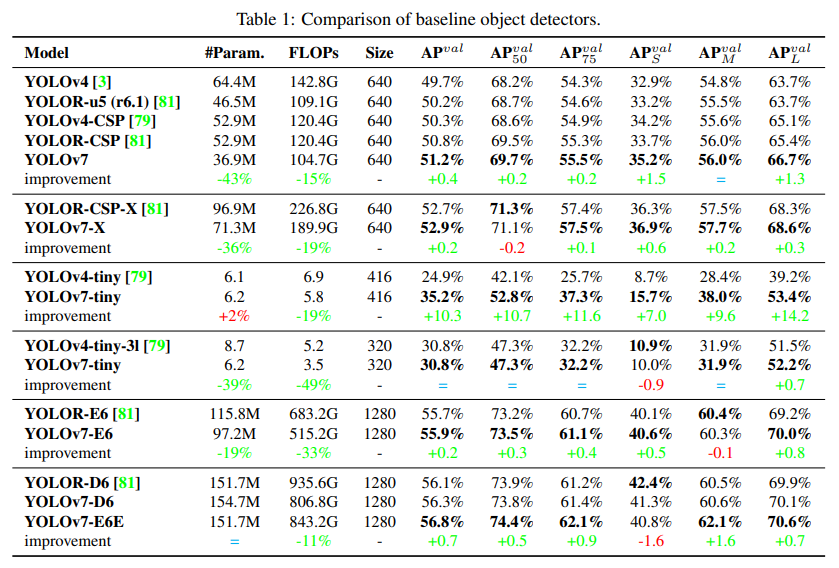
표1은 제안된 yolov7 모델과 동일한 설정으로 학습된 baseline의 비교를 보여준다. -
결과
-
YOLOv4와 비교할 경우, YOLOv7은 파라미터가 75% 감소하고, 계산이 36% 줄었으며, AP가 1.5%더 높은 것을 볼 수 있음 -
SOTA YOLOR-CSP와 비교할 경우, YOLOv7의 파라미터가 43% 적고, 15% 연산량이 줄고, 0.4% AP가 더 높다.
-
작은 모델의 성능에서는, YOLOv4-tiny-31과 비교하면, YOLOv7은 parameter 수를 39% 줄이고, 계산양을 49% 줄였지만 같은 AP를 유지한다.
-
cloud GPU 모델에서, 이 모델은 parameter 수를 19% 줄이고, 계산량을 33% 줄이면서, 여전히 더 높은 AP를 가질 수 있다.
-
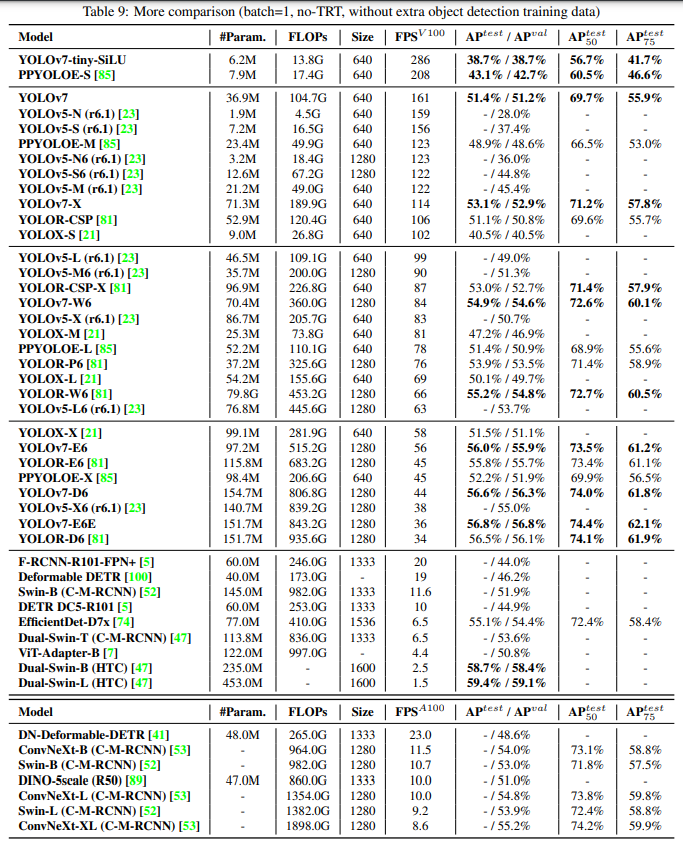
5-3. Comparison with state-of-the-arts
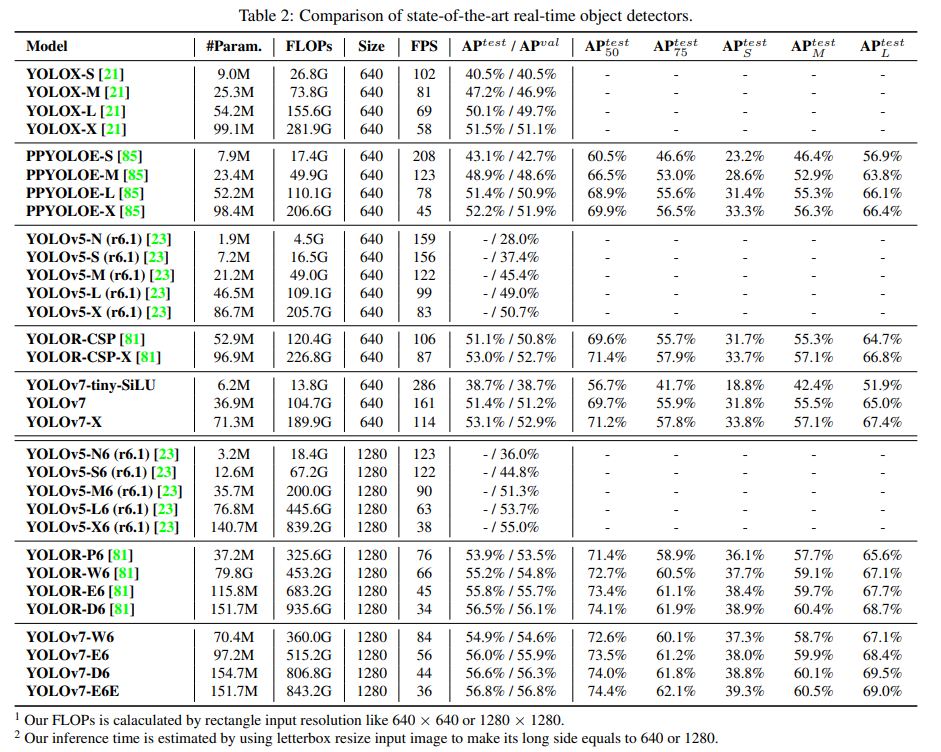
제안된 방법과 general GPU와 mobild GPU에 대한 SOTA object detector를 비교하고, 그 결과를 표2에 나타내었다.
표2의 결과로부터 제안된 방법이 완전히 최고 속도 및 정확성 trade-off를 가지고 있다는 것을 알 수 있다.
비교
-
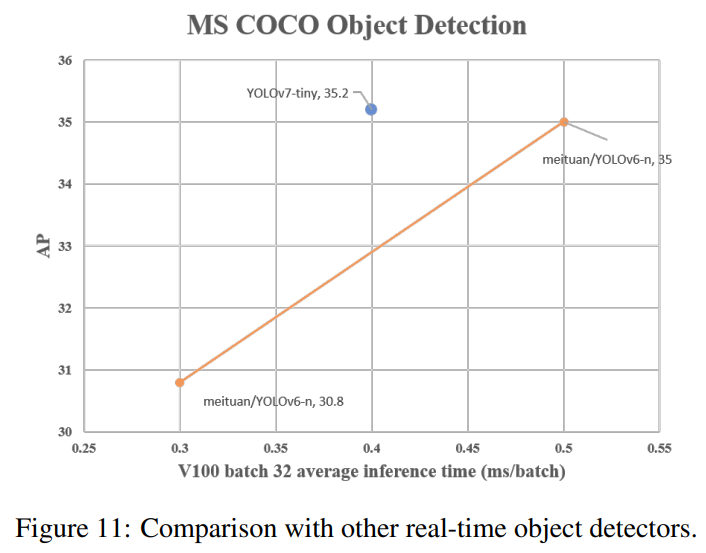
YOLOv7-tiny-SiLUvsYOLOv5-N- 127 fps가 더 빠르고, 10.7% AP가 더 정확함
-
YOLOv7vsPPYOLOE-L-
yolo v7은 161 fps와 51.4% AP를 가짐
-
pp는 78 fps와 동일한 AP를 가짐
-
파라미터 사용 측면에서
YOLOv7이 41% lessthan ppyoloe-l
-
-
YOLOv7-XvsYOLOv5-L-
yolov7-x 114 fps // yolov5-l 99fps
-
yolov7-x이 3.9% AP 향상
-
-
YOLOv7-Xvs비슷한 규모의 YOLOv5-X-
inference speed는 YOLOv7-X가 31fps 빠르다
-
parameter와 계산량 측면에서
YOLOv7-X이 파라미터 22% , 연산량 8% 감소 / AP 2.2% 향상
-
-
YOLOv7vsYOLORwith resolution 1280-
inference speed는 YOLOv7-W6이 YOLOR-P6보다 6fps 빠르고, detection rate도 1% AP가 증가했다.
-
YOLOv7-D6은 YOLOR-E6에 가까운 inference speed를 가지지만, 0.8% AP가 높다. -
YOLOv7-E6은 YOLOR-D6에 가까운 inference speed를 가지지만, 0.3% AP가 높다.
-
5-4. Ablation Study
5.4.1 Proposed Compound Scaling Method
-
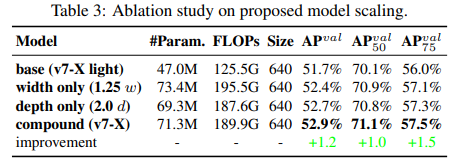
Table 3을 보면 서로 다른 scaling strategies for scaling up에 대한 결과가 나와있다.
-
그 중에서, 우리가 제안한 compound scaling method는 computational block의 depth를 1.5배까지 scale up하고, transition block의 width는 1.25배까지 scale up한다.
-
만약 우리의 방법이 width만 scale up하는 것과 비교를 하면, 더 적은 파라미터와 연산량으로 AP 0.5%를 향상할 수 있다.
-
만약 우리의 방법이 depth만 scale up하는 것과 비교를 하면 우리는 파라미터 개수를 2.9%까지, 연산량을 1.2%까지 늘리면서 AP 0.2% 향상이 된다.
-
Table 3은 우리가 제안한 compound scaling strategy가 파라미터를 효율적으로 사용할 수 있게 하고, 연산을 효율적으로 할 수 있다는 것을 보여준다.
5.4.2 Proposed planned re-parameterized model
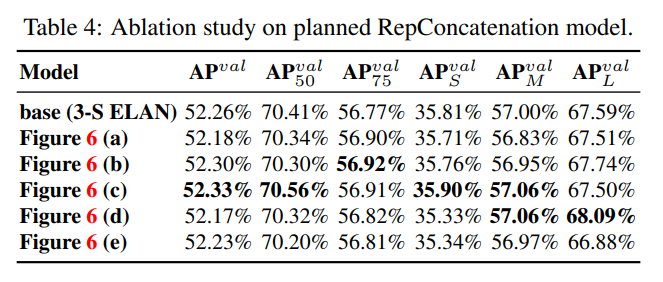
-
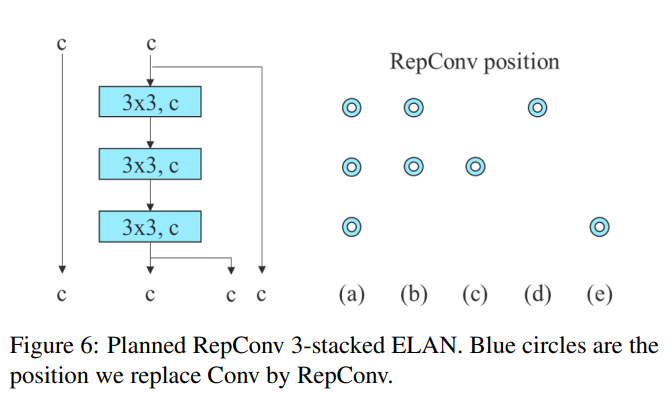
우리가 제안한 planned re-parameterized model의 일반화 능력을 검증하기 위해서 concatenation-based model로 3-stacked ELAN을 선택했고, residual-based model로 CSPDarknet을 선택해서 각각 검증에 사용했다.
-
Concatenation-based model 실험에서, 3-stacked ELAN에 있는 서로 다른 포지션의 3x3 convolution layers를 RepConv로 대체했고, detailed configuration은 Figure 6에서 확인 가능하다.
- Table 4에서 우리가 제안한 planned re-parameterized model이 모두 AP 값이 높다는 것을 볼 수 있다.
-
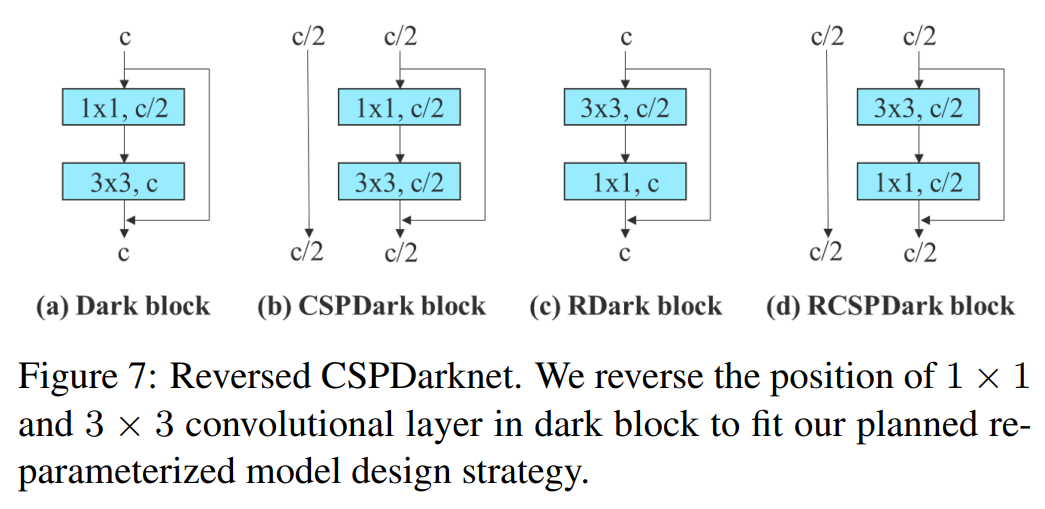
Residual-based model 실험에서, 기존의 dark block (in CSPDarknet)이 우리가 설계한 strategy에 맞는 3 x 3 convolution block이 없기 때문에, 우리가 추가적으로 실험을 위해 reversed dark block을 설계했다.
-
구조는 Figure 7에서 확인할 수 있다.
-
CSPDarknet의 dark block과 Reversed dark block이 정확하게 같은 파라미터 개수와 연산량을 가지기 때문에, 비교 결과를 신뢰할 수 있다.
-
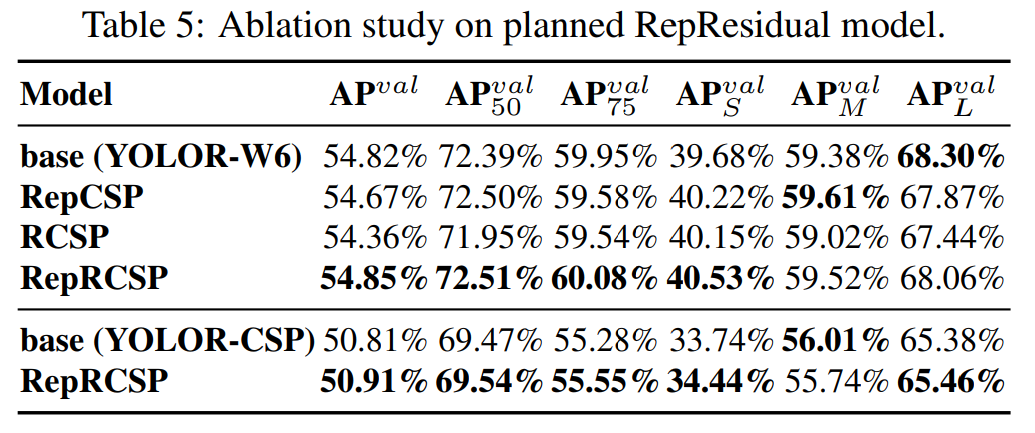
-
Table 5를 보면 우리가 제안한 planned re-parameterized model이 똑같이 residual-based model에도 효과가 있음을 명확히 확인할 수 있다. -
우리는 또한
RepCSPResNet의 구조가 우리의 디자인 패턴에도 적합한 것을 발견했다.
5.4.3 Proposed assistant loss for auxiliary head
-
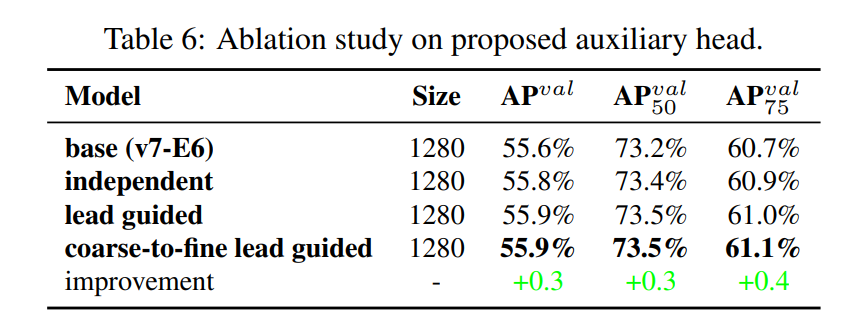
Auxiliary head를 위한 assistant loss 실험에서, 일반적이고 독립적인 lead head label 할당과 auxiliary head 방법들과 비교했고, 제안했던 두 가지의 lead guided label assignment methods를 비교했다.
-
모든 비교 결과를 Table 6에서 볼 수 있다.
-
assistant loss를 증가시킨 어느 모델이나 전반적인 성능이 명백하게 향상했음을 볼 수 있다.
-
추가적으로, 우리가 제안한 AP,AP50,AP75 지표에서 우리가 제안한 lead guided label assignment strategy가 general independent label assignment strategy보다 더 좋은 성능을 보인다.
-
제안한 Coarse for assistant and fine for lead label assignment strategy에서 관해선, 모든 케이스에서 최고의 결과를 보인다.
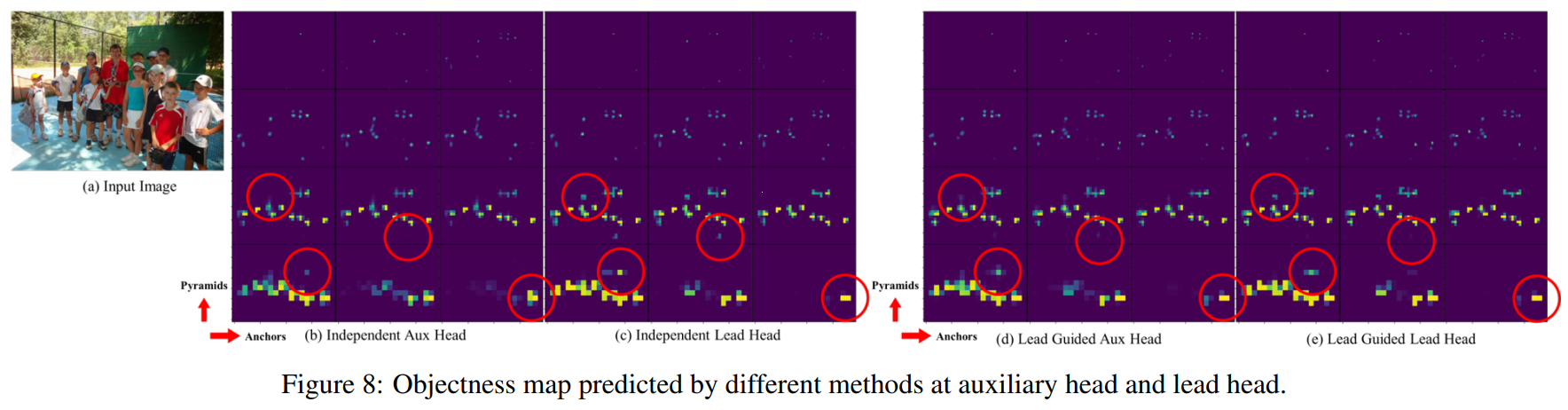
-
Figure 8에서 각기 auxiliary head와 lead head의 각기 다른 방법으로 예측된 objectness map을 확인할 수 있다.
- Figure 8에서 우리는 만약, auxiliary head가 lead guided soft label을 학습하면, lead head가 일관된 target의 남은(잔여)의 정보들을 추출하는데 많이 도움을 주는 것을 볼 수 있다.
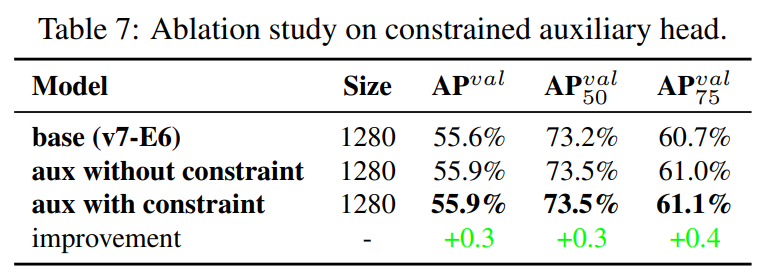
-
Auxiliary head의 decoder에 대해 우리가 제안한 coarse-to-fine lead guided label assignment의 효과를 분석했다.
-
upper bound constraint을 도입 유무 차이의 결과를 비교했다.
-
Table에 있는 수치로 결과를 판단해봤을 때, objectness의 upper bound를 물체의 중심으로부터의 거리에 의해 제한되게 하는 것이 더 좋은 성능을 보였다.
-
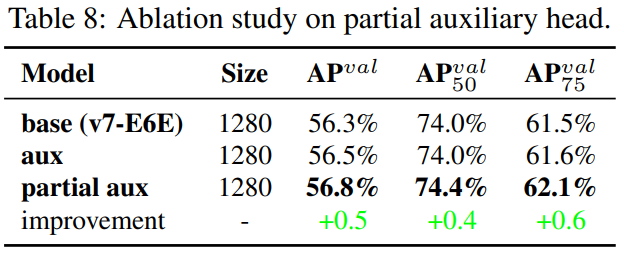
-
YOLOv7은 object detection 결과를 종합적으로 예측하기 위해 multiple pyramids를 사용하기 때문에, auxiliary head를 직접적으로 학습을 위해 중간 layer에 있는 pyramid에 연결할 수 있다.
- 이러한 학습은 다음 레벨 피라미드 예측에서 손실될 수 있는 정보들을 보전할 수 있다.
-
위에서 언급한 이유들로, 우리는 제안한 E-ELAN 아키텍처 안에 partial auxiliary head를 설계했다.
-
우리의 시도는 cardinality를 merge하기 전에 auxiliary head를 그 뒤에 있는 여러 feature map 중 하나에 연결하는 것이고, 이러한 연결은 assistant loss에 의해 직접적으로 업데이트되지 않는 새롭게 생성된 여러 feature maps들의 weight를 만들 수 있게 한다.
-
우리의 이러한 설계는 lead head의 각 피라미드가 각기 다른 사이즈의 물체들로부터 여전히 정보를 얻을 수 있게 해준다.
-
Table 8은 coarse-to-fine lead guided와 partial coarse-to-fine guided methods, 이 두 방법으로부터 얻은 결과를 보여준다.
- 명백하게도 partial coarse-to-fine lead guided method가 더 좋은 auxiliary effect를 가진다.
6. Conclusions
본 논문에서는 real time object detector의 새로운 아키텍처와 model scaling method를 제안한다.
또한, object detection method의 진화하는 과정이 새로운 연구 주제를 생성한다는 것을 발견하였다.
연구 과정에서 re-parameterized module의 교체 문제와 동적 레이블 할당 문제를 발견하였다.
이러한 문제를 해결하기 위해, object detection의 정확도를 향상시키는 trainable bag-of-freebies method를 제안한다.
위 내용을 바탕으로, SOTA object detection 시스템인 YOLOv7 시리즈를 개발했다.
7. Acknowledgments
National Center for High performance Computing (NCHC) provided computational and storage resources (Taiwan's cloud technology services)
8. More comparison
 YOLOv7은 5 ~ 160 FPS 범위 기준 속도와 정확도 측면에서 현존하는 모든 object detectors를 능가
YOLOv7은 5 ~ 160 FPS 범위 기준 속도와 정확도 측면에서 현존하는 모든 object detectors를 능가
Pretrained Weight 사용 XX → trained MS COCO dataset
with baselines
GPU V100에서 30 FPS 이상의 모든 real-time object detectors 중에서 56.8% AP로 가장 높은 정확도를 달성
YOLOv7-E6은
transformer based detector인 SWIN-L Cascade-Mask R-CNN보다 509%의 속도, 2%의 정확도가 향샹
Convolution 기반 검출기인 ConvNeXt-XL Cascade-Mask R-CNN보다 551%의 속도, 0.7%의 정확도가 향상
References
