1. 혼동행렬 Confusion Matrix
True Positive TP: 실제 Positive인 값을 Positive라고 예측(정답)
True Negative TN: 실제 Negative인 값을 Negative라고 예측(정답)
False Positive FP: 실제 Negative인 값을 Positive라고 예측(오답) - 1형 오류(라고도 부름)
False Negative FN: 실제 Positive인 값을 Negative라고 예측(오답) - 2형 오류
혼동행렬을 구하게 되면 어떤 걸 잘 맞췄고 어떤 걸 틀렸는지 알 수 있음.
2. 정확도 Accuracy
전체 데이터 중에서 제대로 분류된 데이터의 비율.
모델이 얼마나 정확하게 분류하는지를 나타냄
일반적으로 분류 모델의 주요 평가방법으로 사용됨.
그러나, 클래스 비율이 불균형할 경우 평가지표의 신뢰성을 잃을 가능성이 있음
Accuracy = TP+TN / P+N
P: TP+FN
N: TN+FP
3. 정밀도 PRECISION
모델이 Positive라고 분류한 데이터 중에서
실제로 Positive인 데이터의 비율
Negative가 중요한 경우
(즉, 실제로 Negative인 데이터를 Positive라고 판단하면 안되는 경우)
사용되는 지표
정밀도(Precision) = TP / TP+FP
Negative가 중요한 경우 - 예시
스팸 메일 판결을 위한 분류 문제
해당 메일이 스팸일 경우 Positive,
스팸이 아닐 경우(일반 메일일 경우) Negative
일반 메일을 스팸으로 잘못! 예측했을 경우
중요한 메일을 전달받지 못하는 상황이 발생할 수 있음
이럴 때 '정밀도'가 중요함.
4. 재현율 Recall, TPR)
실제로 Positive인 데이터 중에서
모델이 Positive로 분류한 데이터의 비율
Positive가 중요한 경우
즉, 실제로 Positive인 데이터를 Negative라고 판단하면 안되는 경우 사용되는 지표
Recall = TP / TP+FN = TP / P
Positive가 중요한 경우
악성 종양 여부 판결을 위한 검사
악성 종양일 경우 Positive,
악성 종양이 아닐 경우 즉, 양성 종양일 경우 Negative
악성 종양(Positive)을 양성 종양(Negatvie)로 잘못 예측했을 경우
제때 치료를 받지 못하게 되어 생명이 위급해질 수 있음!
5. 다양한 분류 지표의 활용
분류 목적에 따라 다양한 지표를 계산하여 평가
- 분류 결과를 전체적으로 보고 싶다면 -> 혼동행렬(Confusion Matrix)
- 정답을 얼마나 잘 맞췄는지 -> 정확도(Accuracy)
- FP 또는 FN의 중요도가 높다면 -> 정밀도(Precision), 재현율(Recall)
추구하는 문제와 목적에 따라, 적절한 분류 지표를 활용, 사용할 수 있다.
6. 실습1 - confusion matrix
혼동 행렬(Confusion matrix)
혼동 행렬(Confusion matrix)은 분류 문제에서 모델을 학습시킨 뒤, 모델에서 데이터의 X값을 집어넣어 얻은 예상되는 y값과, 실제 데이터의 y값을 비교하여 정확히 분류 되었는지 확인하는 메트릭(metric)이라고 할 수 있습니다.
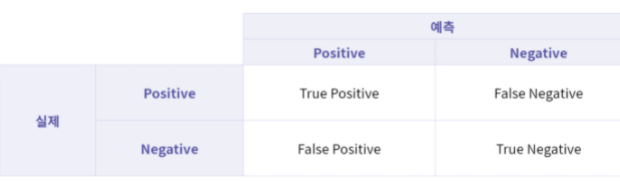
위 표가 바로 혼동 행렬이며, 각 표에 속한 값은 다음을 의미합니다.
True Positive (TP) : 실제 값은 Positive, 예측된 값도 Positive.
False Positive (FP) : 실제 값은 Negative, 예측된 값은 Positive.
False Negative (FN) : 실제 값은 Positive, 예측된 값은 Negative.
True Negative (TN) : 실제 값은 Negative, 예측된 값도 Negative.
sklearn 안에는 위 4개 평가 값을 얻기 위해 사용할 수 있는 기능이 정의되어 있습니다.
이번 실습에서는 2개의 클래스를 가진 분류 데이터를 이용하여 혼동 행렬을 직접 출력해보고,확인해보도록 하겠습니다.
혼동 행렬을 위한 사이킷런 함수/라이브러리
confusion_matrix(y_true, y_pred)
: Confusion matrix의 값을 np.ndarray로 반환해줍니다.
데이터 정보
load_breast_cancer 유방암 유무 판별 데이터를 불러오는 함수
X(Feature 데이터) : 30개의 환자 데이터
Y(Label 데이터) : 0 음성(악성), 1 양성(정상)
지시사항
confusion_matrix를 사용하여 test_Y에 대한 confusion matrix를 계산하여 cm에 저장해봅시다.
import numpy as np
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn import tree
from sklearn.metrics import confusion_matrix
from sklearn.utils.multiclass import unique_labels
from elice_utils import EliceUtils
elice_utils = EliceUtils()
# sklearn에 저장된 데이터를 불러 옵니다.
X, Y = load_breast_cancer(return_X_y = True)
X = np.array(X)
Y = np.array(Y)
# 데이터 정보를 출력합니다
print('전체 샘플 개수: ',len(X))
print('X의 feature 개수: ',len(X[0]))
# 학습용 평가용 데이터로 분리합니다
train_X, test_X, train_Y, test_Y = train_test_split(X, Y, test_size=0.2, random_state = 42)
# 분리된 평가용 데이터 정보를 출력합니다
print('평가용 샘플 개수: ',len(test_Y))
print('클래스 0인 평가용 샘플 개수: ',len(test_Y)-sum(test_Y))
print('클래스 1인 평가용 샘플 개수: ',sum(test_Y),'\n')
# DTmodel에 의사결정나무 모델을 초기화 하고 학습합니다
DTmodel = DecisionTreeClassifier()
DTmodel.fit(train_X, train_Y)
# test_X을 바탕으로 예측한 값을 저장합니다
y_pred = DTmodel.predict(test_X)
"""
1. 혼동 행렬을 계산합니다
"""
cm = confusion_matrix(test_Y, y_pred)
print('Confusion Matrix : \n {}'.format(cm))
# 혼동 행렬을 출력합니다
fig = plt.figure(figsize=(5,5))
ax = sns.heatmap(cm, annot=True)
ax.set(title='Confusion Matrix',
ylabel='True label',
xlabel='Predicted label')
fig.savefig("decistion_tree.png")
elice_utils.send_image("decistion_tree.png")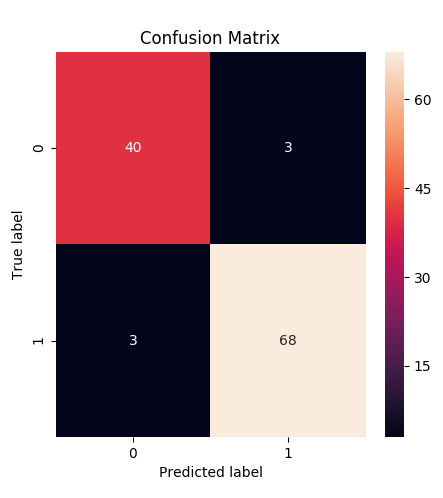
7. 실습2 - 정확도Accuracy 계산하기
실습1의 결과를 바탕으로 분류 성능에 간단하면서도 중요한 정확도를 계산하여 모델의 성능을 판별해보겠습니다.
이번 실습에서는 학습용 데이터와 평가용 데이터의 정확도를 계산하고 그 성능을 비교해보겠습니다.
정확도 계산을 위한 사이킷런 함수/라이브러리
DTmodel.score(train_X, train_Y)
: train_X 데이터에 대한 정확도(accuracy) 값을 계산합니다.
데이터 정보
load_breast_cancer 유방암 유무 판별 데이터를 불러오는 함수
X(Feature 데이터) : 30개의 환자 데이터
Y(Label 데이터) : 0 음성(악성), 1 양성(정상)
지시사항
score를 사용하여 train_X에 대한 정확도를 계산하여 acc_train에 저장해봅시다.
score를 사용하여 test_X에 대한 정확도를 계산하여 acc_test에 저장해봅시다.
Tips!
accuracy_score(Y_true, Y_pred)을 이용하여 정확도를 구할 수 있습니다. Y_true,Y_pred는 각각 실제값과 예측값을 의미합니다.
import numpy as np
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn import tree
from sklearn.metrics import confusion_matrix
from sklearn.utils.multiclass import unique_labels
from elice_utils import EliceUtils
elice_utils = EliceUtils()
# sklearn에 저장된 데이터를 불러 옵니다.
X, Y = load_breast_cancer(return_X_y = True)
X = np.array(X)
Y = np.array(Y)
# 학습용 평가용 데이터로 분리합니다
train_X, test_X, train_Y, test_Y = train_test_split(X, Y, test_size=0.2, random_state = 42)
# 분리된 데이터 정보를 출력합니다
print('학습용 샘플 개수: ',len(train_Y))
print('클래스 0인 학습용 샘플 개수: ',len(train_Y)-sum(train_Y))
print('클래스 1인 학습용 샘플 개수: ',sum(train_Y),'\n')
print('평가용 샘플 개수: ',len(test_Y))
print('클래스 0인 평가용 샘플 개수: ',len(test_Y)-sum(test_Y))
print('클래스 1인 평가용 샘플 개수: ',sum(test_Y),'\n')
# DTmodel에 의사결정나무 모델을 초기화 하고 학습합니다
DTmodel = DecisionTreeClassifier()
DTmodel.fit(train_X, train_Y)
# 예측한 값을 저장합니다
y_pred_train = DTmodel.predict(train_X)
y_pred_test = DTmodel.predict(test_X)
# 혼동 행렬을 계산합니다
cm_train = confusion_matrix(train_Y, y_pred_train)
cm_test = confusion_matrix(test_Y, y_pred_test)
print('train_X Confusion Matrix : \n {}'.format(cm_train))
print('test_X Confusion Matrix : \n {}'.format(cm_test))
"""
1. 정확도를 계산합니다.
"""
acc_train = DTmodel.score(train_X, train_Y)
acc_test = DTmodel.score(test_X, test_Y)
acc_train_2 = accuracy_score(train_Y, y_pred_train)
acc_test_2 = accuracy_score(test_Y, y_pred_test)
# 정확도를 출력합니다.
print('train_X Accuracy: %f' % (acc_train))
print('test_X Accuracy: %f' % (acc_test))
print('train_X Accuracy: %f' % (acc_train_2))
print('test_X Accuracy: %f' % (acc_test_2))
DTmodel.score 를 이용할 때는 예측에 사용할 X값과 실제 Y값 데이터를 차례로 넣으면 되고,
accuracy_score 를 이용할 때는 실제 Y값, 예측한 Y값 데이터를 차례로 넣으면 된다.
8. 실습3 - 정밀도(Precision), 재현율(Recall) 계산하기
실습2의 결과를 바탕으로 분류 지표 중 정밀도와 재현율을 계산하여 모델의 성능을 판별해보겠습니다.
이번 실습에서는 학습용 데이터와 평가용 데이터의 정밀도와 재현율을 계산하고 그 성능을 비교해보겠습니다.
정밀도와 재현율 계산을 위한 사이킷런 함수/라이브러리
precision_score(train_Y, y_pred_train)
: 학습용 데이터에 대한 정밀도(precision) 값을 계산합니다.
recall_score(train_Y, y_pred_train)
: 학습용 데이터에 대한 재현율(recall) 값을 계산합니다.
데이터 정보
load_breast_cancer 유방암 유무 판별 데이터를 불러오는 함수
X(Feature 데이터) : 30개의 환자 데이터
Y(Label 데이터) : 0 음성(악성), 1 양성(정상)
지시사항
precision_score를 사용하여 학습용, 평가용 데이터에 대한 정밀도를 계산하여 precision_train, precision_test에 저장해봅시다.
recall_score를 사용하여학습용, 평가용 데이터에 대한 재현율을 계산하여 recall_train, recall_test에 저장해봅시다.
import numpy as np
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn import tree
from sklearn.metrics import confusion_matrix
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from elice_utils import EliceUtils
elice_utils = EliceUtils()
# sklearn에 저장된 데이터를 불러 옵니다.
X, Y = load_breast_cancer(return_X_y = True)
X = np.array(X)
Y = np.array(Y)
# 학습용 평가용 데이터로 분리합니다
train_X, test_X, train_Y, test_Y = train_test_split(X, Y, test_size=0.2, random_state = 42)
# DTmodel에 의사결정나무 모델을 초기화 하고 학습합니다
DTmodel = DecisionTreeClassifier()
DTmodel.fit(train_X, train_Y)
# 예측한 값을 저장합니다
y_pred_train = DTmodel.predict(train_X)
y_pred_test = DTmodel.predict(test_X)
# 혼동 행렬을 계산합니다
cm_train = confusion_matrix(train_Y, y_pred_train)
cm_test = confusion_matrix(test_Y, y_pred_test)
print('train_X Confusion Matrix : \n {}'.format(cm_train))
print('test_X Confusion Matrix : \n {}'.format(cm_test),'\n')
"""
1. 정밀도를 계산합니다.
"""
precision_train = precision_score(train_Y, y_pred_train)
precision_test = precision_score(test_Y, y_pred_test)
# 정밀도를 출력합니다.
print('train_X Precision: %f' % (precision_train))
print('test_X Precision: %f' % (precision_test),'\n')
"""
2. 재현율을 계산합니다.
"""
recall_train = recall_score(train_Y, y_pred_train)
recall_test = recall_score(test_Y, y_pred_test
# 재현율을 출력합니다.
print('train_X Recall: %f' % (recall_train))
print('test_X Recall: %f' % (recall_test))