1. 기존 다층 퍼셉트론 기반 신경망의 이미지 처리 방식
우선 이미지의 픽셀값 배열은 2차원 데이터 -> 2차원배열을 입력값으로 넣을 수 없으므로 1차원배열로 변환해야함
변환방법: 6X6 배열이라면, row 1의 데이터 6개를 순서대로 넣고, row 2의 데이터 6개를 그 다음 순서대로 넣고, 총 36개 데이터가 있는 1차원 데이터로 변환
극도로 많은 수의 파라미터가 필요해짐
이미지를 한줄씩 가로로 잘라내서 보는 거나 다름없기 때문에 사진상의 특징들을 인지하기가 거의 불가능해짐
뒤집힌 사진 등 이미지에 변화가 있을 경우, 사람이 봤을 땐 똑같은 고양이지만, 1차원으로 변환된 데이터에서는 완전히 새로운 데이터가 되어버림
2. 합성곱 신경망(Convolution Neural Network CNN)
작은 필터를 순환시키는 방식
이미지의 패턴이 아닌 '특징'을 중점으로 인식
픽셀 단위가 아닌 특징 단위로 파악
이미지가 뒤집혀있다고 해도 판단하기 쉬움.
이미지 처리에서 매우 성능이 좋아짐.
3. 합성곱 신경망의 구조
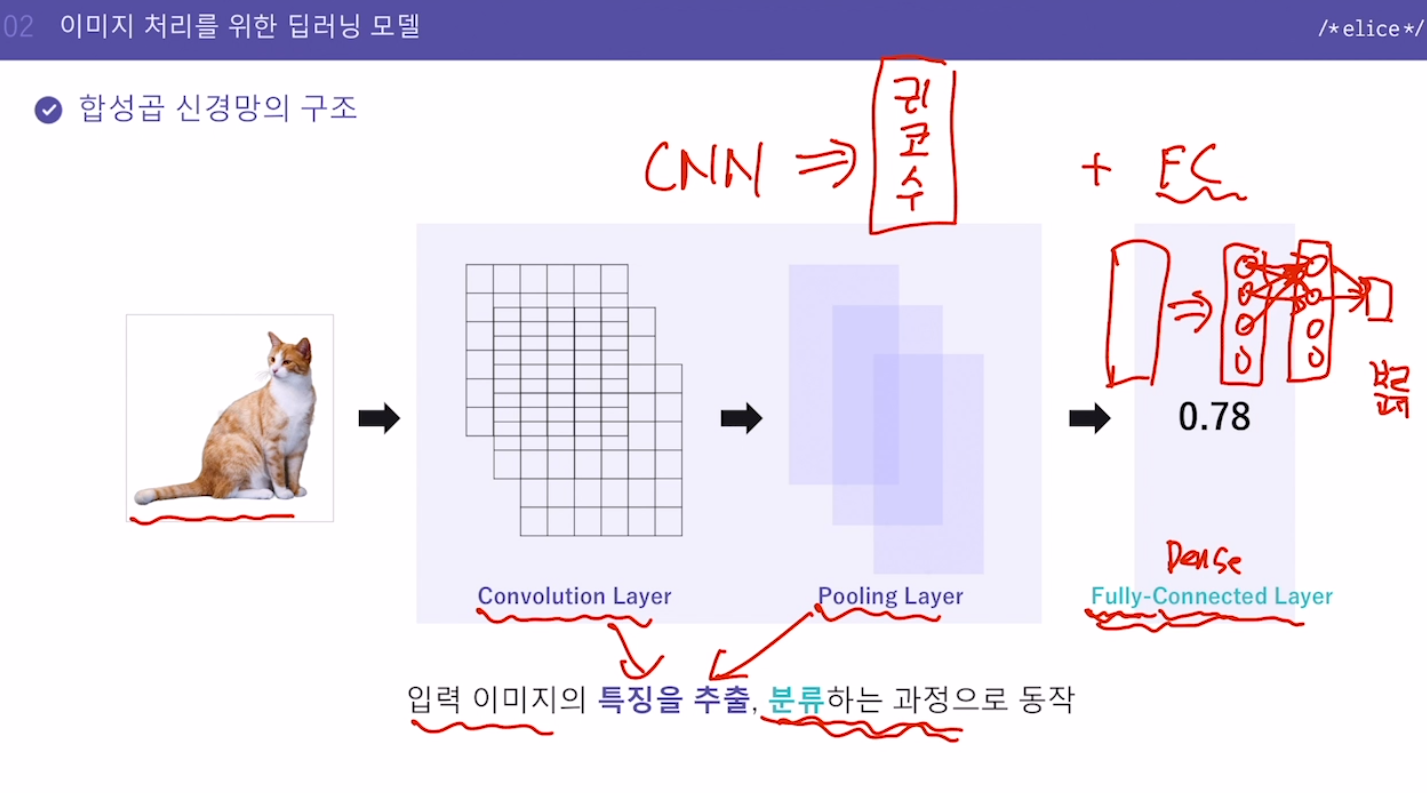
입력 이미지의 특징을 추출(CNN), 분류(FC)하는 과정으로 동작
FC는 Dense라고도 함, 우리가 기존 배웠던 모델. 다 각각 연결돼있다는 의미에서 Fully-Connected
- Convolution Layer
이미지에서 어떤 특징이 있는지를 구하는 과정
필터가 이미지를 이동하며 새로운 이미지(피쳐맵)를 생성
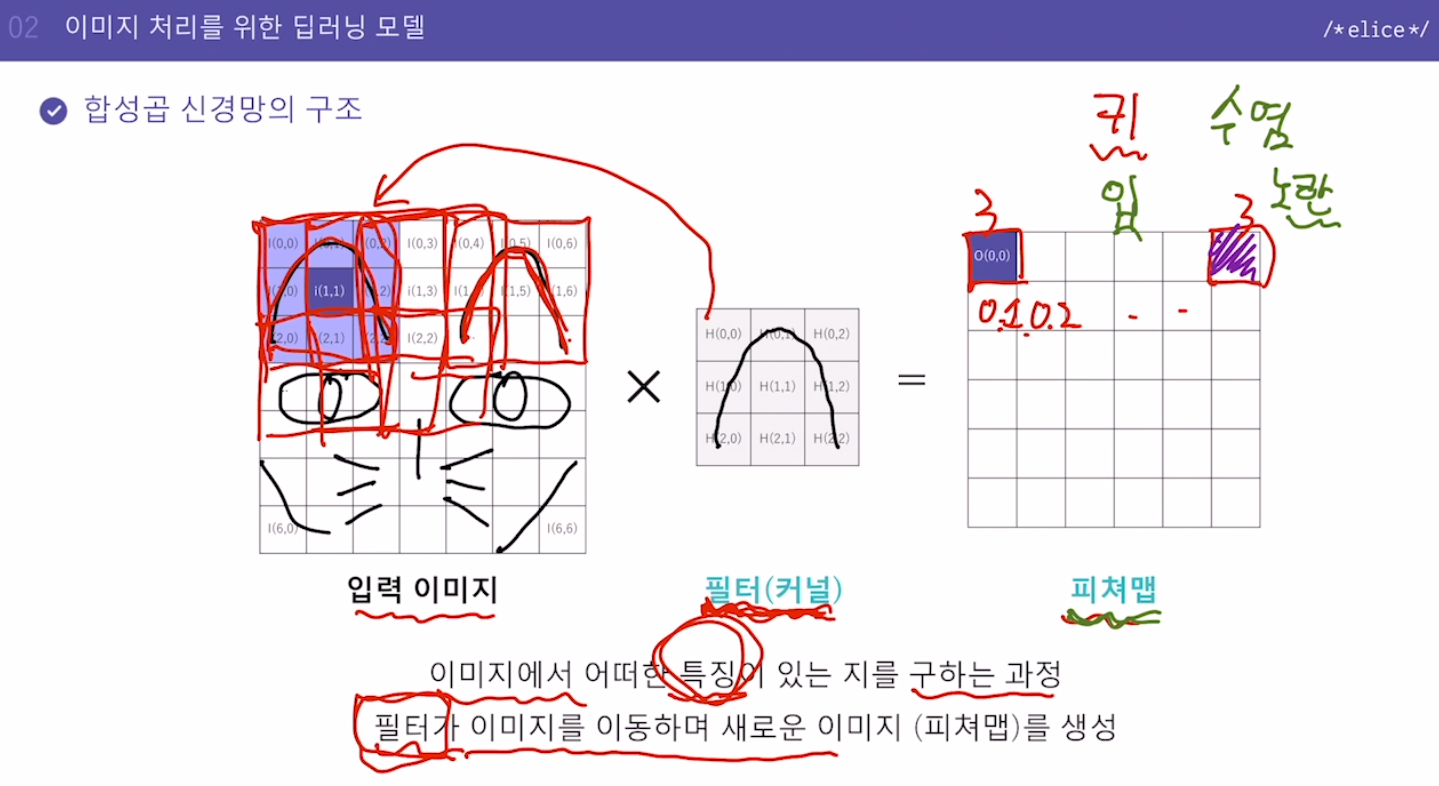
예를 들어 고양이귀 필터를 만들어서 해당 필터를 적용해가면서 이미지에 필터에 해당하는 이미지가 있는지 검사
각 적용마다 어느 정도로 매칭됐는지에 대한 값을 구하고, 매칭이 제대로 되는 곳에서 가장 높은 값이 나오게 되는데, 이 매칭값에 대한 지도가 피쳐맵
이미지에서 귀가 어디에 분포하고 있는지 확인할 수 있는 피쳐맵
수많은 필터들을 만들어서 필터에 대한 피쳐맵을 뽑을 수 있음
피쳐맵 => 필터에 있는 이미지와 비슷한 것이 있는지를 판단하고 그 위치를 확인
- 피쳐맵의 크기 변형: Padding, Striding
Padding: 피쳐맵의 크기가 원본이미지의 크기와 달라지는 것을 보정하기 위해, 원본 이미지의 상하좌우에 한줄씩 추가(0 값을 가진 픽셀 추가)
Striding: 필터를 이동시키는 거리(Stride) 설정
처음에 옆으로 한칸씩 이동하면서 검사(필터적용)하는 게 아니라 2칸이나 3칸씩 이동하면서 검사 가능
- Pooling Layer
피쳐맵을 구한 다음에 하는 작업
피쳐맵의 사이즈를 줄이게 된다.
줄이면서 이미지의 왜곡의 영향(노이즈)를 축소하는 과정
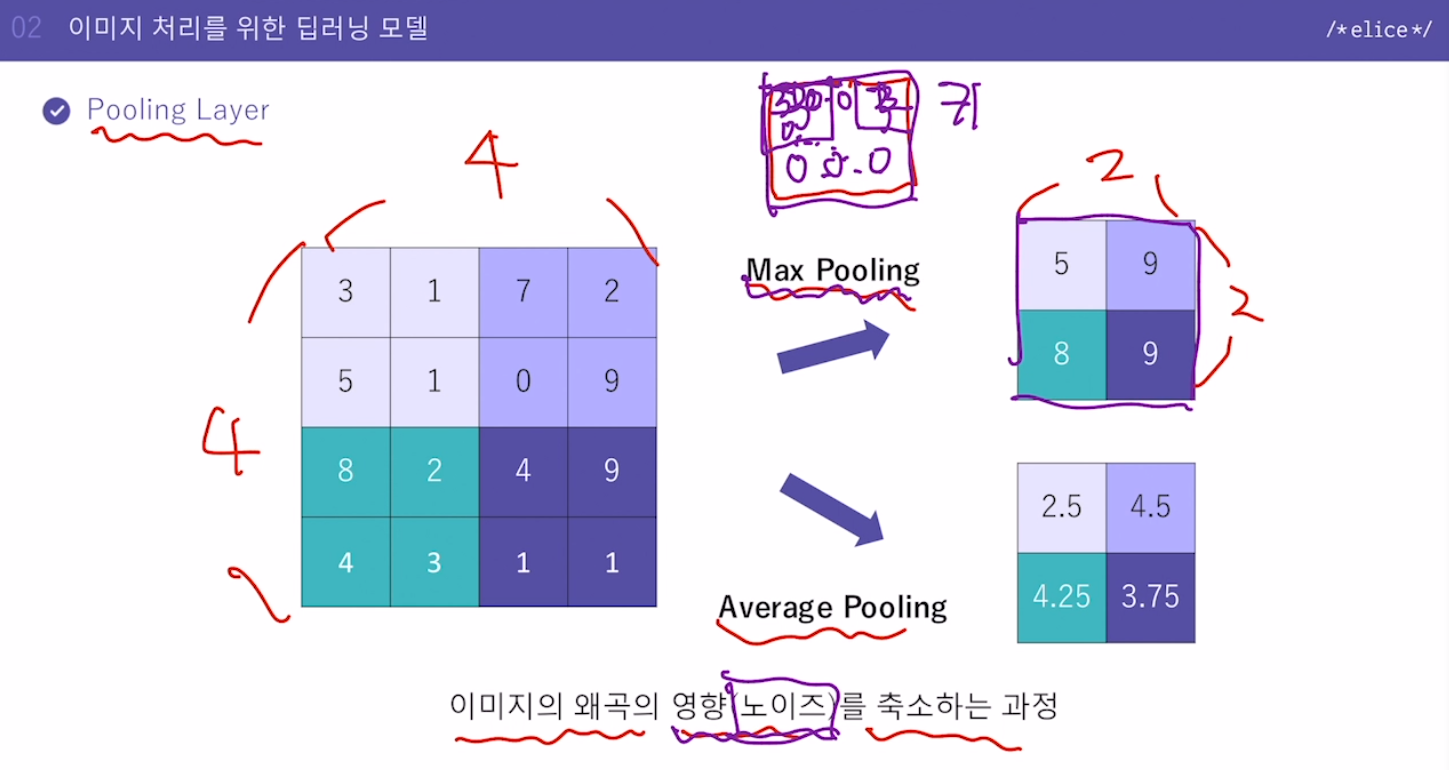
중요한 정보만 남기고 나머지는 없앤다. 노이즈 없애고 정보 압축. (귀 필터로 만든 피쳐맵에서 중요한 것은 귀가 있었냐 없었냐 어디쯤에 있었냐 정도뿐임)
Average Pooling보다는 Max Pooling이 자주 사용됨(가장 큰 것을 대표값으로)
- Fully Connected Layer
추출된 특징을 사용하여 이미지를 분류
CNN 레이어를 통해 원본이미지였던 것이 특징들을 가지고 피쳐맵이 만들어짐
예:
귀 필터 피쳐맵
입 필터 피쳐맵
기타 등등
이것들을 다시 1차원 배열로 만듦
각각의 특징들이 정리된 형태로 1차원 벡터가 만들어지기 때문에 이것을 사용해서 분류를 할 수가 있다.
- 분류를 위한 Softmax 활성화 함수
고양이인지 아닌지로만 결과를 내는 게 아니라
강아지일 확률 고양이일 확률 토끼일 확률 등 다양한 예측을 해내야할 때는 Softmax
마지막 계층에 Softmax 활성화 함수 사용
각각은 확률값이고 결과로 나온 값을 다 더하면 1, 각 값은 0보다 크거나 같다.
이 중 가장 큰 확률을 가진 값이 결과적으로 예측값.
-
정리
합성곱(특징) -> 풀링(이미지사이즈 축소, 노이즈 감소) -> 활성화함수(FC, 분류)이것을 N번 반복할 수 있다.
풀링을 통해 영역의 크기가 작아지기 때문에 빠른 학습 가능.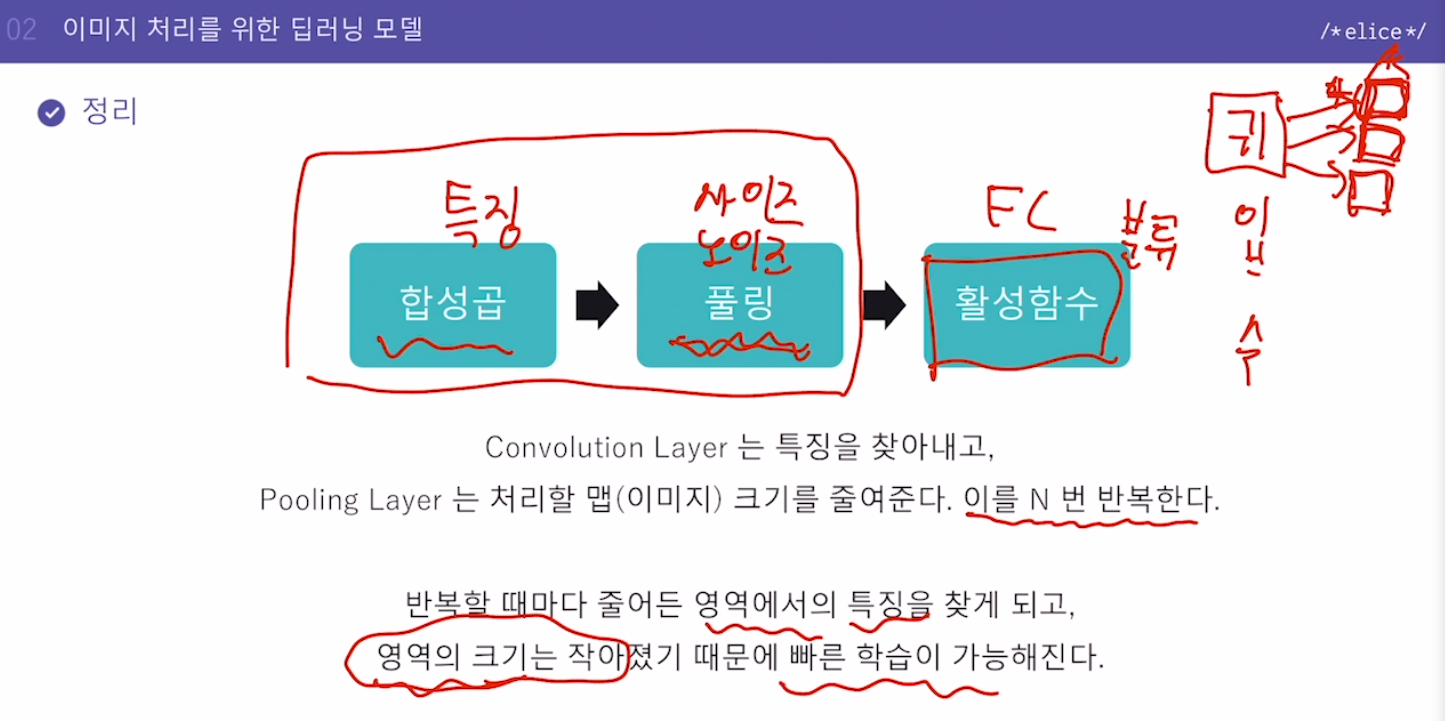
-
합성곱 신경망 기반 다양한 이미지 처리 기술
Object detection & segmentation
물체 인식 (한 사진에 있는 여러 물체를 인식)Super resolution(SR) 해상도 높이기
4. 실습. MNIST 분류 CNN 모델 - 모델 구현
이번 실습에서는 CNN 모델을 구현하고 학습해보겠습니다.

Keras에서 CNN 모델을 만들기 위해 필요한 함수/메서드
- CNN 레이어
tf.keras.layers.Conv2D(filters, kernel_size, activation, padding)
: 입력 이미지의 특징, 즉 처리할 특징 맵(map)을 추출하는 레이어입니다.
filters : 필터(커널) 개수
kernel_size : 필터(커널)의 크기
activation : 활성화 함수
padding : 이미지가 필터를 거칠 때 그 크기가 줄어드는 것을 방지하기 위해서 가장자리에 0의 값을 가지는 픽셀을 넣을 것인지 말 것인지를 결정하는 변수. ‘SAME’ 또는 ‘VALID’
- Maxpool 레이어
tf.keras.layers.MaxPool2D(padding)
: 처리할 특징 맵(map)의 크기를 줄여주는 레이어입니다.
padding : ‘SAME’ 또는 ‘VALID’
-
Flatten 레이어
tf.keras.layers.Flatten()
: Convolution layer 또는 MaxPooling layer의 결과는 N차원의 텐서 형태입니다. 이를 1차원으로 평평하게 만들어줍니다. -
Dense 레이어
tf.keras.layers.Dense(node, activation)
node : 노드(뉴런) 개수
activation : 활성화 함수
지시사항
keras를 활용하여 CNN 모델을 설정합니다.
분류 모델에 맞게 마지막 레이어의 노드 수는 10개, activation 함수는 ‘softmax’로 설정합니다.
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from visual import *
from elice_utils import EliceUtils
elice_utils = EliceUtils()
import logging, os
logging.disable(logging.WARNING)
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
# 동일한 실행 결과 확인을 위한 코드입니다.
np.random.seed(123)
tf.random.set_seed(123)
# MNIST 데이터 세트를 불러옵니다.
mnist = tf.keras.datasets.mnist
# MNIST 데이터 세트를 Train set과 Test set으로 나누어 줍니다.
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# Train 데이터 5000개와 Test 데이터 1000개를 사용합니다.
train_images, train_labels = train_images[:5000], train_labels[:5000]
test_images, test_labels = test_images[:1000], test_labels[:1000]
# CNN 모델의 입력으로 사용할 수 있도록 (샘플개수, 가로픽셀, 세로픽셀, 1) 형태로 변환합니다.
train_images = tf.expand_dims(train_images, -1)
test_images = tf.expand_dims(test_images, -1)
"""
1. CNN 모델을 설정합니다.
분류 모델에 맞게 마지막 레이어의 노드 수는 10개, activation 함수는 'softmax'로 설정합니다.
"""
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters = 32, kernel_size = (3,3), activation = 'relu', padding = 'SAME', input_shape = (28,28,1)),
tf.keras.layers.MaxPool2D(padding = 'SAME'),
tf.keras.layers.Conv2D(filters = 32, kernel_size = (3,3), activation = 'relu', padding = 'SAME'),
tf.keras.layers.MaxPool2D(padding = 'SAME'),
tf.keras.layers.Conv2D(filters = 32, kernel_size = (3,3), activation = 'relu', padding = 'SAME'),
tf.keras.layers.MaxPool2D(padding = 'SAME'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation = 'relu'),
tf.keras.layers.Dense(10, activation = 'softmax')
])
# CNN 모델 구조를 출력합니다.
print(model.summary())
# CNN 모델의 학습 방법을 설정합니다.
model.compile(loss = 'sparse_categorical_crossentropy',
optimizer = 'adam',
metrics = ['accuracy'])
# 학습을 수행합니다.
history = model.fit(train_images, train_labels, epochs = 20, batch_size = 512)
# 학습 결과를 출력합니다.
Visulaize([('CNN', history)], 'loss')5. 실습. MNIST 분류 CNN 모델 - 평가 및 예측
이어서 이번 실습에서는 CNN 모델을 평가하고 예측해보겠습니다.
Keras에서 CNN 모델의 평가 및 예측을 위해 필요한 함수/메서드
평가 방법
model.evaluate(X, Y)
evaluate() 메서드는 학습된 모델을 바탕으로 입력한 feature 데이터 X와 label Y의 loss 값과 metrics 값을 출력합니다.
예측 방법
model.predict_classes(X)
X 데이터의 예측 label 값을 출력합니다.
지시사항
1. evaluate 메서드와 평가용 데이터를 사용하여 모델을 평가합니다.
- loss와 accuracy를 계산하고 loss, test_acc에 저장합니다.
- predict_classes 메서드를 사용하여 평가용 데이터에 대한 예측 결과를 predictions에 저장합니다.
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from visual import *
from plotter import *
from elice_utils import EliceUtils
elice_utils = EliceUtils()
import logging, os
logging.disable(logging.WARNING)
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
# 동일한 실행 결과 확인을 위한 코드입니다.
np.random.seed(123)
tf.random.set_seed(123)
# MNIST 데이터 세트를 불러옵니다.
mnist = tf.keras.datasets.mnist
# MNIST 데이터 세트를 Train set과 Test set으로 나누어 줍니다.
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# Train 데이터 5000개와 Test 데이터 1000개를 사용합니다.
train_images, train_labels = train_images[:5000], train_labels[:5000]
test_images, test_labels = test_images[:1000], test_labels[:1000]
# CNN 모델의 입력으로 사용할 수 있도록 (샘플개수, 가로픽셀, 세로픽셀, 1) 형태로 변환합니다.
train_images = tf.expand_dims(train_images, -1)
test_images = tf.expand_dims(test_images, -1)
# CNN 모델을 설정합니다.
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters = 32, kernel_size = (3,3), activation = 'relu', padding = 'SAME', input_shape = (28,28,1)),
tf.keras.layers.MaxPool2D(padding = 'SAME'),
tf.keras.layers.Conv2D(filters = 32, kernel_size = (3,3), activation = 'relu', padding = 'SAME'),
tf.keras.layers.MaxPool2D(padding = 'SAME'),
tf.keras.layers.Conv2D(filters = 32, kernel_size = (3,3), activation = 'relu', padding = 'SAME'),
tf.keras.layers.MaxPool2D(padding = 'SAME'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation = 'relu'),
tf.keras.layers.Dense(10, activation = 'softmax')
])
# CNN 모델 구조를 출력합니다.
print(model.summary())
# CNN 모델의 학습 방법을 설정합니다.
model.compile(loss = 'sparse_categorical_crossentropy',
optimizer = 'adam',
metrics = ['accuracy'])
# 학습을 수행합니다.
history = model.fit(train_images, train_labels, epochs = 10, batch_size = 128, verbose = 2)
Visulaize([('CNN', history)], 'loss')
"""
1. 평가용 데이터를 활용하여 모델을 평가합니다.
loss와 accuracy를 계산하고 loss, test_acc에 저장합니다.
"""
loss, test_acc = model.evaluate(test_images, test_labels, verbose = 0)
"""
2. 평가용 데이터에 대한 예측 결과를 predictions에 저장합니다.
"""
predictions = model.predict_classes(test_images)
# 모델 평가 및 예측 결과를 출력합니다.
print('\nTest Loss : {:.4f} | Test Accuracy : {}'.format(loss, test_acc))
print('예측한 Test Data 클래스 : ',predictions[:10])
print('실제 : ', test_labels[:10])
# 평가용 데이터에 대한 레이어 결과를 시각화합니다.
Plotter(test_images, model)
