1. 우리 주변의 자연어 처리 예시
기계번역모델 - 구글번역, 유튜브 자동자막 등
음성인식 - 아이폰 시리, 네이버 클로바 등
2. 자연어 처리 과정
-
자연어 전 처리
Preprocessing -
단어 표현
Word Embedding -
모델 적용하기
Modeling (딥러닝 모델 적용)
3. 자연어 전 처리 방법
원 상태 그대로의 자연어는 전처리 과정이 필요함
굉장히 여러가지가 있지만 아래 세 가지에 대해 우선 알아보자
1. Noise canceling
2. Tokenizing
3. StopWord removal
4. 오류 교정(Noise Canceling)
자연어 문장의 스펠링 체크 및 띄어쓰기 오류 교정
기계가 오류 교정을 한다는 거 자체가 쉽지가 않음.
케이스 바이 케이스로 알려줘야하기 때문에.
또한 요새 인터넷에서 사용하는 자연어에서는 슬랭이나 줄임말같은 것이 굉장히 많이 쓰이기 때문에 이런 말들에 대해서 표준어로 어느 정도 변환을 해주어야 모델의 성능을 높일 수 있기 때문에, 오류 교정 과정이 쉽지가 않다.
클린한 데이터, 성능향상에 중요
5. 토큰화 Tokenizing
"딥러닝 기초 과목을 수강하고 있습니다."
=> ['딥','러닝','기초','과목','을','수강','하고','있습니다','.']
이 하나하나를 토큰이라고 함.
문장을 토큰(Token)으로 나눔
토큰은 어절, 단어 등으로 목적에 따라 다르게 정의
왜 토큰화?
자연어 문장을 그대로 딥러닝의 입력값으로 사용할 수 없음
수치로 변환해주어야함.
문장 전체를 숫자로 변환한다는 것 자체가 쉽지 않고,
일단 문장을 쪼개고 토큰으로 분리를 하면 토큰마다의 의미를 부여하고 수치로 변환하기가 더 쉽다.
6. 불용어 제거 StopWord removal
한국어 stopword(불용어) 예시)
아, 휴, 아이구, 아이쿠, 아이고, 쉿, 그렇지 않으면, 그러나, 그런데, 하지만, ...
불용어: 불필요한 단어를 의미
(상황과 모델에 따라 중요하지 않다고 생각하는 것들을 제거, 접속사가 중요하게 여겨질 경우에는 제거하지 않을 수 있음, 상황에 따라 달라짐)
7. Bag of Words
자연어 데이터를 수치형 데이터로 변환해야 하는데 그러기 위해 먼저 알아야하는 개념
토큰화된 자연어 데이터 리스트
['안녕','만나서','반가워'],
['안녕','나도','반가워']
-> 각각의 토큰들에 대해 번호를 부여(인덱스를 매핑)
['안녕':0, '만나서':1, '반가워':2,'나도':3]
인덱스를 매핑하는 방식은 큰 의미없음. 그냥 먼저 나오는대로 하나씩 넣음.
자연어 데이터에 속해있는 단어들의 가방
8. 토큰 시퀀스
Bag of Words에서 단어에 해당되는 인덱스로 변환
모든 문장의 길이를 맞추기 위해 기준보다 짧은 문장에는 패딩을 수행
이미지 전처리에서 해상도를 통일하듯, 자연어 데이터도 마찬가지로 통일해주어야함.
Padding : 데이터 길이를 맞추기 위한 쓸모없는 값
Bag of words에서 쓸모없는 값 하나를 padding값으로 할당
가장 긴 길이의 문장을 기준으로 나머지 문장들을 padding으로 맞추는데, 전체 데이터에서 한 문장만 유독 길거나 할 경우는 그 문장을 제외하거나 하기도 함.
9. 실습. 영화 리뷰 긍정/부정 분류 RNN 모델 - 데이터 전 처리
이번 실습에서는 영화 리뷰 데이터를 바탕으로 감정 분석을 하는 모델을 학습 시켜 보겠습니다. 영화 리뷰와 같은 자연어 자료는 곧 단어의 연속적인 배열로써, 시계열 자료라고 볼 수 있습니다. 즉, 시계열 자료(연속된 단어)를 이용해 리뷰에 내포된 감정(긍정, 부정)을 예측하는 분류기를 만들어 보겠습니다.
데이터셋은 IMDB 영화 리뷰 데이터 셋을 사용합니다. 훈련용 5,000개와 테스트용 1,000개로 이루어져 있으며, 레이블은 긍정/부정으로 두 가지입니다. 우선 자연어 데이터를 RNN 모델의 입력으로 사용할 수 있도록 데이터 전 처리를 수행해보겠습니다.
RNN을 위한 자연어 데이터 전 처리
RNN의 입력으로 사용하기 위해서는 자연어 데이터는 토큰화 및 여러 가지의 데이터 처리가 필요합니다. 아래와 같이 자연어 데이터가 준비되어 있다면 마지막으로 패딩을 수행하여 데이터의 크기를 통일해야합니다.
첫 번째 데이터 시퀀스:
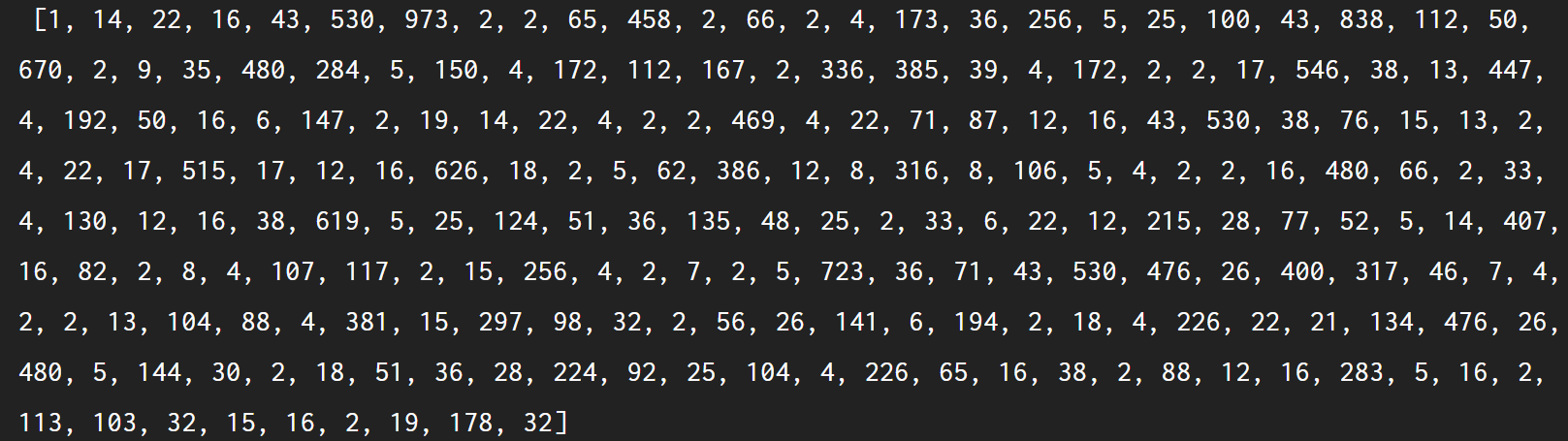
단어 사전:

sequence.pad_sequences(data, maxlen=300, padding='post')
:data 시퀀스의 크기가 maxlen인자보다 작으면 그 크기에 맞게 패딩을 추가합니다.
지시사항
인덱스로 변환된 X_train, X_test 시퀀스에 패딩을 수행하고 각각 X_train, X_test에 저장합니다.
시퀀스 최대 길이는 300으로 설정합니다.
import json
import numpy as np
import tensorflow as tf
import data_process
from keras.datasets import imdb
from keras.preprocessing import sequence
import logging, os
logging.disable(logging.WARNING)
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
# 학습용 및 평가용 데이터를 불러오고 샘플 문장을 출력합니다.
X_train, y_train, X_test, y_test = data_process.imdb_data_load()
"""
1. 인덱스로 변환된 X_train, X_test 시퀀스에 패딩을 수행하고 각각 X_train, X_test에 저장합니다.
시퀀스 최대 길이는 300으로 설정합니다.
"""
X_train = sequence.pad_sequences(X_train, maxlen=300, padding='post')
X_test = sequence.pad_sequences(X_test, maxlen=300, padding='post')
print("\n패딩을 추가한 첫 번째 X_train 데이터 샘플 토큰 인덱스 sequence: \n",X_train[0])