1. 제조분야
1. 스마트팩토리
- 오작동 모니터링
- 제품 성능 모의 실험 digital twin
가상의 공장에서 모의 실험 - 데이터 기반 의사결정 최적화
2. 공정 자동화
- 공정 효율 증대
- 재고관리 및 물류자동화
3. 인공지능 적용 위해 필요한 점
- 해당 도메인에서의 확실한 목표 확립
- 데이터 분석 전문가와의 지속적 커뮤니케이션
- 인공지능에 필요한 데이터를 확보할 수 있는 환경 조성 (데이터 수집의 중요성)
4. 실습. 데이터 확인하고 머신러닝 모델 학습하기
이번 실습에서는 반도체 공정 센서 데이터를 살펴보고 인공지능 모델을 학습하는 과정을 수행해 보겠습니다.
- 개요
복잡한 현대 반도체 제조 공정은 일반적으로 센서 및 공정 측정 지점에서 수집된 신호 혹은 변수 모니터링을 통해 일관된 감시를 받습니다.
그러나 이러한 모든 신호가 특정 모니터링 시스템에서 똑같이 가치가 있는 것은 아닙니다. 측정된 신호에는 유용한 정보, 관련 없는 정보 및 노이즈의 조합이 포함됩니다.
이번 실습에서는 제조 과정에서 나올 수 있는 공정 이상을 머신러닝을 사용하여 예측해볼 것입니다.
- 실습 데이터 구조
반도체를 제조하는 공정에서 590개의 센서가 시간 별로 기록한 데이터 샘플 1,567개가 아래와 같이 주어졌습니다.

Pass/Fail 칼럼은 타임 스탬프 별로 간단한 통과 실패율을 나타내며 여기서 –1은 통과(정상)에 해당하고 1은 실패(이상)에 해당합니다.
즉, 이 데이터 테이블은 592개의 칼럼(590개의 센서, 1개의 테스트 통과 결과, 1개의 시간 데이터)과 1,567개의 로우(행) 으로 구성되어 있는 것입니다.
위 데이터를 기반으로 머신러닝 학습을 수행하여, 불량 반도체가 제조될 수 있는 공정 이상 유무를 예측하여 봅시다.
지시사항
1. 아래 코드를 사용하여 데이터를 읽고 처리하는 과정을 수행해보세요.
ma.preprocess()
2. 아래 코드를 사용하여 학습을 수행시켜보세요.
ma.train(x_train_us, y_train_us)
-
실행 버튼을 눌러 출력된 데이터를 확인하고 학습 진행 과정을 확인해보세요.
-
제출 버튼을 눌러 데이터를 처리하고, 학습을 시키는 코드를 올바르게 작성하였는지 확인해보세요.
import machine as ma
def main():
"""
지시사항 1번. 데이터를 읽고 처리하는 코드를 작성해보세요.
"""
x_train_us, x_test_us, y_train_us, y_test_us = ma.preprocess()
"""
지시사항 2번. 학습을 수행시켜보세요.
"""
model = ma.train(x_train_us, y_train_us)
if __name__ == "__main__":
main()
machine.py
import numpy as np
import pandas as pd
import sys
from tqdm import trange
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('fivethirtyeight')
# to avoid warnings
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import xgboost as xgb
from xgboost.sklearn import XGBClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import confusion_matrix, accuracy_score, f1_score, precision_score, recall_score, average_precision_score
from elice_utils import EliceUtils
elice_utils = EliceUtils()
def preprocess():
print("데이터 읽는 중...")
data = pd.read_csv('data/uci-secom.csv')
print("읽어 온 데이터를 출력합니다.")
print(data)
#print(data.isnull().sum())
#print("결측 데이터 값을 처리합니다.")
data = data.replace(np.NaN, 0)
#print(data.isnull().sum())
# 쓸모없는 데이터 지우기
data = data.drop(columns = ['Time'], axis = 1)
# 타겟 데이터 분리
x = data.iloc[:,:590]
y = data.iloc[:, 590]
print("\n학습용 데이터와 테스트용 데이터로 분리 합니다.")
# Under sampling 수행
failed_tests = np.array(data[data['Pass/Fail'] == 1].index)
no_failed_tests = len(failed_tests)
normal_indices = data[data['Pass/Fail'] == -1]
no_normal_indices = len(normal_indices)
np.random.seed(10)
random_normal_indices = np.random.choice(no_normal_indices, size = no_failed_tests, replace = True)
random_normal_indices = np.array(random_normal_indices)
under_sample = np.concatenate([failed_tests, random_normal_indices])
undersample_data = data.iloc[under_sample, :]
x = undersample_data.iloc[:, undersample_data.columns != 'Pass/Fail']
y = undersample_data.iloc[:, undersample_data.columns == 'Pass/Fail']
y = np.ravel(y)
x_train_us, x_test_us, y_train_us, y_test_us = train_test_split(x, y, test_size = 0.2, random_state = 4)
print("학습용 데이터 크기: {}".format(x_train_us.shape))
print("테스트용 데이터 크기: {}".format(x_test_us.shape))
return x_train_us, x_test_us, y_train_us, y_test_us
def train(x_train_us, y_train_us):
print("학습을 수행합니다.")
model = XGBClassifier(random_state=2)
# 파라미터 튜닝
parameters = [{'max_depth' : [1, 2, 3, 4, 5, 6]}]
grid_search = GridSearchCV(estimator = model, param_grid = parameters, scoring = 'recall', cv = 4, n_jobs = -1)
import pickle
for j in trange(5000,file=sys.stdout, leave=False, unit_scale=True, desc='학습 진행률'):
with open('model.pkl', 'rb') as f:
model = pickle.load(f)
print("학습 완료")
return model5. 실습. 학습 모델 평가하기
재현율 확인하기
인공지능과 머신러닝을 활용하여 모델을 만들고 나면, 해당 모델이 얼마나 정확히 값을 예측하는지를 평가할 수 있습니다.
이번 실습에서의 모델 퍼포먼스는 재현율(recall score)이라는 값을 통하여 평가해보도록 하겠습니다.
재현율은 모델이 실제 예측할 값을 얼마나 정확히 예측(재현)했는지를 설명하는 지표인데, 실습 환경의 실행 버튼을 눌러 확인해보면 94.7% 라는 유의미한 재현율을 확인해볼 수 있습니다.
높은 재현율을 가진 머신러닝 모델을 만들면 산업 현장에서, 기계가 이상 작동을 하는지에 대해 높은 신뢰도로 미리 확인해볼 수 있기 때문에 경영 환경에 큰 효과를 가져올 수 있습니다.
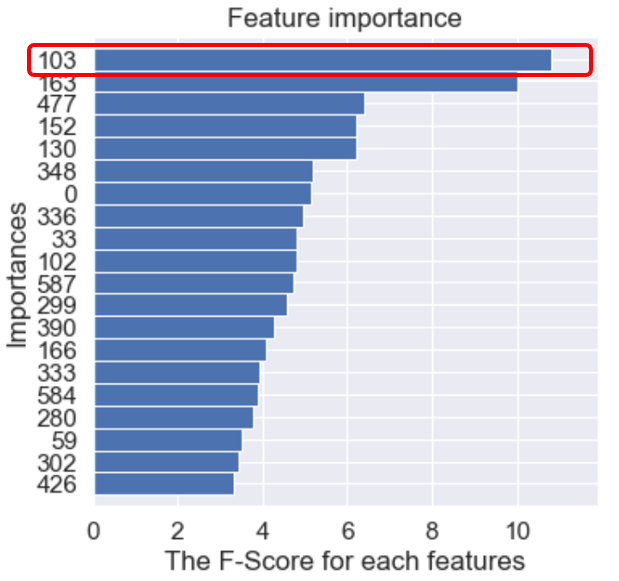
특성 중요도 확인하기
공장의 센서 데이터로 인공지능 모델을 학습시키면, 단순한 예측 정확도 이상의 지표를 추가로 확인할 수 있습니다.
특성 중요도(feature importance)가 대표적입니다. 이 사례에서 특성 중요도는 인공지능 모델이 기계의 이상 작동을 감지하는 데에 어떤 센서가 가장 중요했는지를 나타냅니다.
우리가 학습시킨 인공지능 모델은 이 사례에서 103번 센서와 163번 센서가 공정 이상을 탐지하는 데에 가장 중요하다고 알려주고 있습니다. 따라서 데이터 과학을 활용하면 해당 센서들을 우선으로 하여 공정 개선 작업을 진행해볼 수 있겠습니다.
지시사항
1. 아래 코드를 사용하여 예측 정확도 결과를 출력해보세요.
ma.evaluation()
2. 실행 버튼을 눌러 결과를 확인해 봅시다.
3. 제출 버튼을 눌러 결과를 출력하는 코드를 올바르게 작성하였는지 확인해보세요.
- Tips
해당 실습에서 해석하기 쉽게 정의한 재현율(recall score) 은 다음의 의미를 가지고 있습니다.
defectp=정확히예측한불량품수량
defectr=실제불량품수량
recall=defectp/defectr
import machine as ma
def main():
"""
지시사항 1번. 예측 정확도 결과를 출력해보세요.
"""
ma.evaluation()
if __name__ == "__main__":
main()
def evaluation():
x_train_us, x_test_us, y_train_us, y_test_us = preprocess()
model = train(x_train_us, y_train_us)
# 테스트 데이터 예측
y_pred = model.predict(x_test_us)
print('평가 지표인 recall score를 출력합니다.: ', recall_score(y_test_us, y_pred), '\n')
print("센서들의 중요도를 출력합니다.")
xgb.plot_importance(model, height = 1, grid = True, importance_type = 'gain', show_values = False, max_num_features = 20)
plt.rcParams['figure.figsize'] = (10, 15)
plt.xlabel('The importance score for each features')
plt.ylabel('Features')
plt.savefig("result1.png")
elice_utils.send_image("result1.png")6. 실습. 공정 이상 예측하기
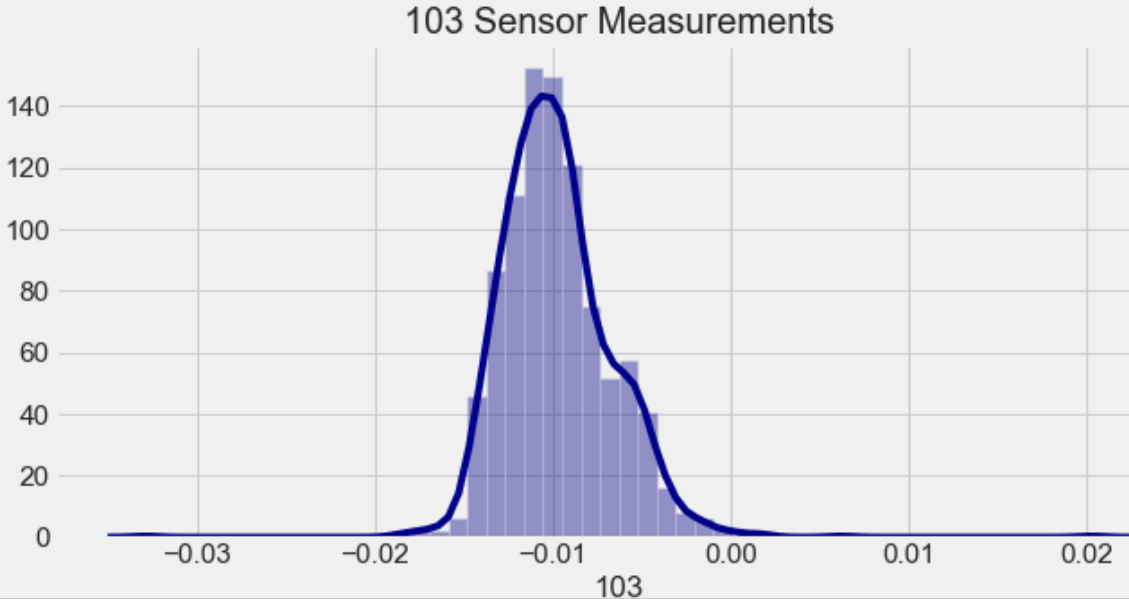
이전 실습의 학습 결과를 통하여 103번 센서의 관측 값이 중요하다는 것을 알아보았습니다.
이번 실습에서는 103번 센서의 값을 조절 했을 때 공정 이상이 발생할 지를 학습된 인공지능 모델을 사용하여 예측하여 봅시다.
아래는 103번 센서의 관측치 값들의 분포를 나타낸 그래프입니다.
지시사항
1. None을 지우고 103 번 센서의 관측치 값을 직접 입력하고자 합니다. value_103_sensor에 정상 범위의 값-0.02이상 0이하를 입력하세요.
-
실행 버튼을 눌러 결과를 확인해보세요.
-
제출 버튼을 눌러 정상 범위의 값을 올바르게 입력했는지 확인해보세요.
Tips
정상 범위 밖의 값을 입력한 후 실행 버튼을 눌러 결과를 확인해보세요.
import machine as ma
def main():
"""
지시사항 1번. 103번 센서값인 아래의 value_103_sensor 값을 바꾸어보세요.
"""
value_103_sensor = -0.01
# 예측을 진행하는 코드입니다.
ma.predict(value_103_sensor)
if __name__ == "__main__":
main()
