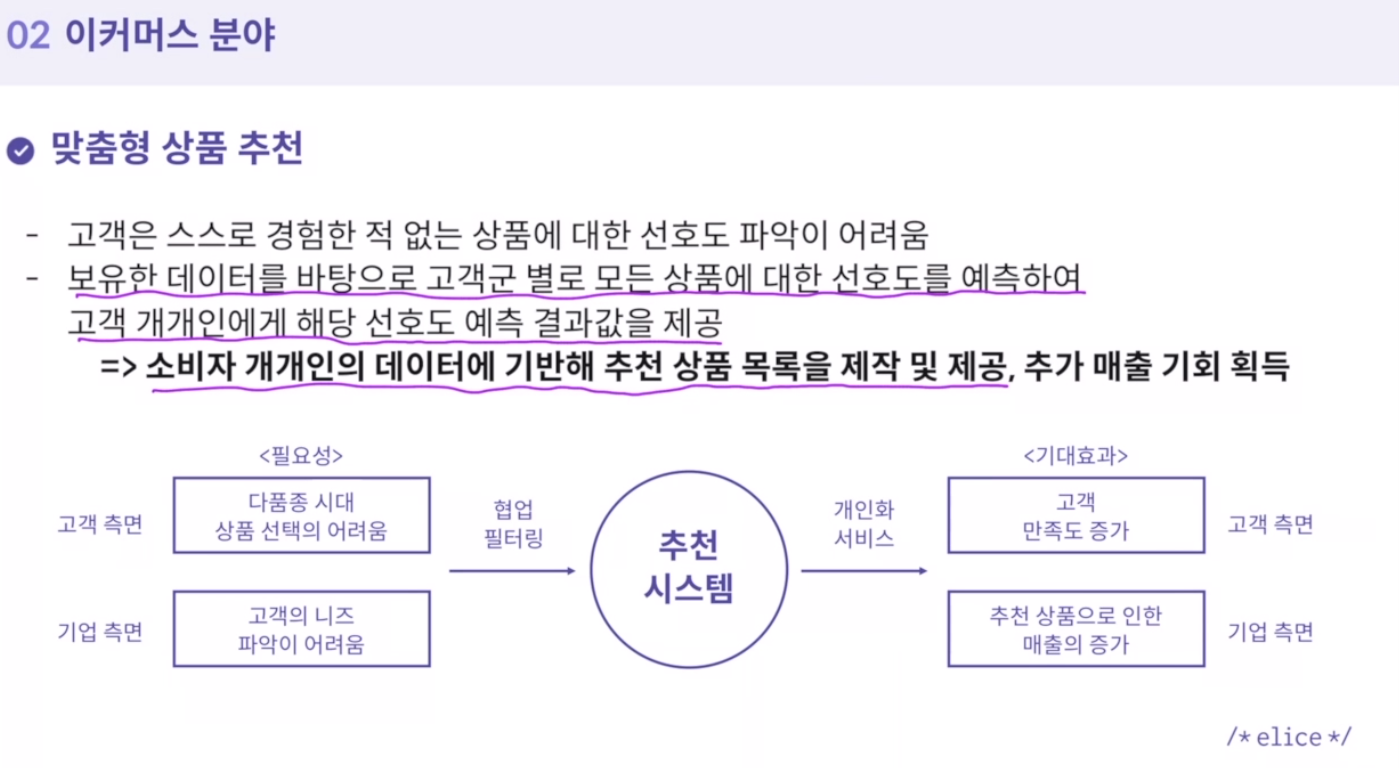
1. 맞춤형 상품 추천
- 고객은 스스로 경험한 적 없는 상품에 대한 선호도 파악이 어려움
2. 추천 알고리즘
-
미리 설정한 규칙 기반 추천이 아닌 고객 데이터에 따른 인공지능형 추천 알고리즘
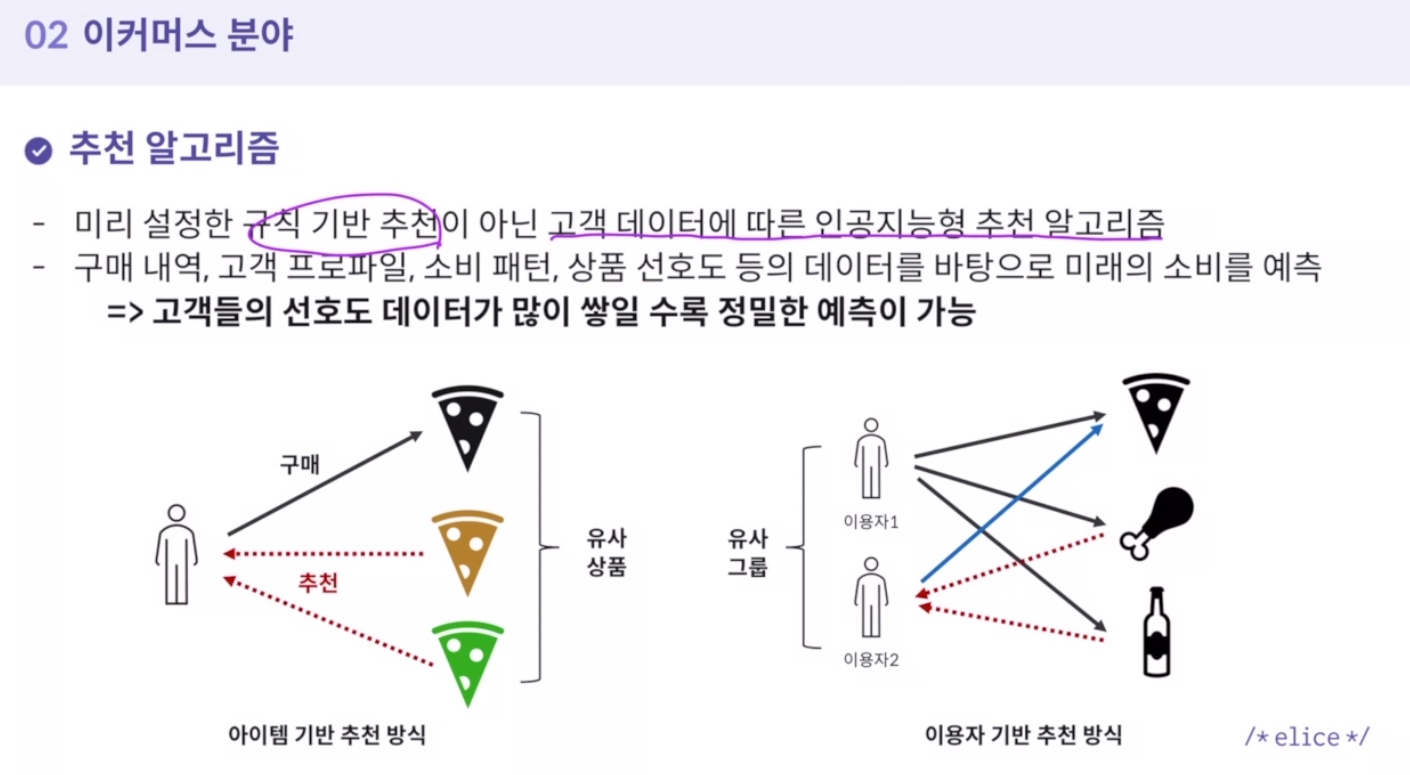
-
대표적: 유튜브 추천 알고리즘
대부분의 조회수가 추천 영상으로 발생
3. 개인화된 마케팅 전략
- 고객 개개인의 특성을 분석하여 소비자들 각각에 최적화된 서비스를 제공
-> AI를 활용하여 고객별 구매 성향을 예측하여 맞춤형 마케팅 메시지 도출 가능
4. 고객 편의 서비스 제공
- 쇼핑의 편의성을 높일 수 있도록 다양한 인공지능 기술을 활용한 서비스 제공
5. 실습. 웹사이트는 어떻게 나에게 맞는 상품을 추천하는가?
이번 실습에서는 넷플릭스 데이터를 살펴보고 인공지능 모델을 학습하는 과정을 수행해 보겠습니다.
유튜브 영상을 보고 있던 중 나도 모르게 새로운 영상을 추천 받으며 보고 있지 않나요?
웹상에서 운영되는 영상, 쇼핑, 광고 기업들은 여러분에게 새로운 상품을 보여주기 위하여 인공지능을 활용한 추천 알고리즘을 사용하고 있습니다.
데이터 구조 확인
2019년까지 업로드된 넷플릭스 데이터가 아래와 같이 주어졌습니다.
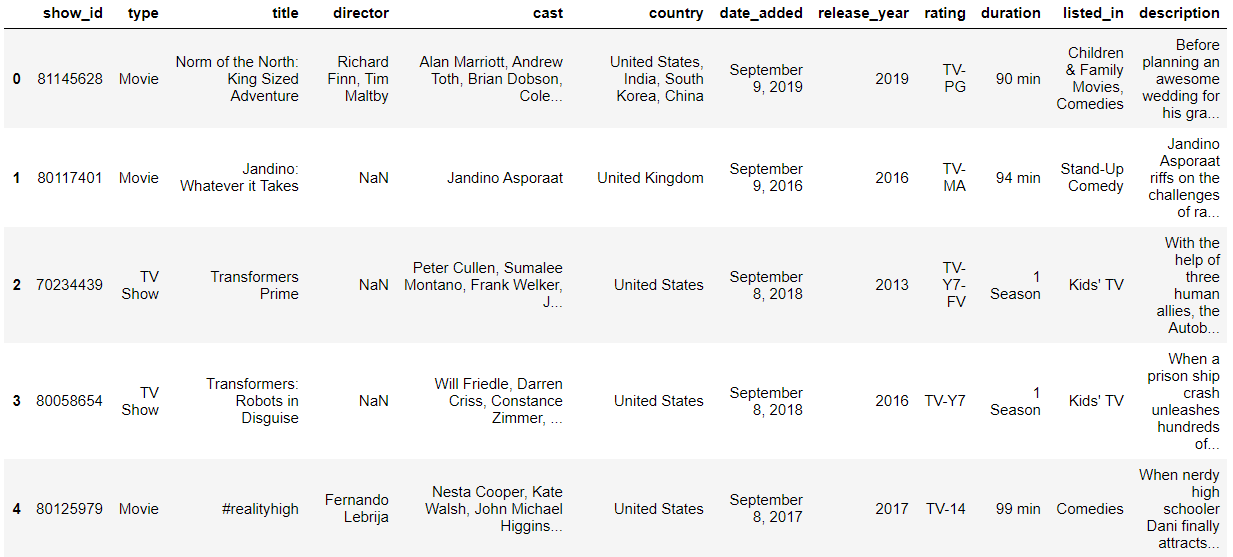
데이터에는 6234개의 콘텐츠에 대하여 12 가지 변수에 대한 값들이 저장되어 있습니다.
변수 의미
show_id 넷플릭스 콘텐츠 id
type 콘텐츠 타입
title 콘텐츠 제목
director 감독
cast 캐스팅된 배우
country 국가
date_added 업로드 된 날짜
release_year 배포된 연도
rating 콘텐츠 등급 ex) 전체 이용가
duration 콘텐츠 분량
listed_in 장르
description 줄거리 요약
데이터 학습
미리 설정된 학습 알고리즘을 활용해 이 데이터로 학습을 진행해보도록 하겠습니다.
지시사항
아래 코드를 사용하여 인공지능 모델 학습을 수행해보세요.
ma.preprocess()
실행 버튼을 눌러 결과를 확인해보세요.
제출 버튼을 눌러 학습을 수행하는 코드를 올바르게 작성하였는지 확인해보세요.
import machine as ma
def main():
"""
지시사항 1번. 인공지능 모델 학습을 수행해보세요.
"""
netflix_overall, cosine_sim, indices = ma.preprocess()
if __name__ == "__main__":
main()import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import sys
from tqdm import trange
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity
def clean_data(x):
return str.lower(x.replace(" ", ""))
def create_soup(x):
return x['title']+ ' ' + x['director'] + ' ' + x['cast'] + ' ' +x['listed_in']+' '+ x['description']
def preprocess():
pd.set_option('display.max_columns', None)
print("데이터 읽는 중...")
netflix_overall=pd.read_csv("data/netflix_titles.csv")
print("읽어 온 데이터를 출력합니다.")
print(netflix_overall)
filledna=netflix_overall.fillna('')
features=['title','director','cast','listed_in','description']
filledna=filledna[features]
for feature in features:
filledna[feature] = filledna[feature].apply(clean_data)
filledna['soup'] = filledna.apply(create_soup, axis=1)
count = CountVectorizer(stop_words='english')
count_matrix = count.fit_transform(filledna['soup'])
cosine_sim = cosine_similarity(count_matrix, count_matrix)
filledna=filledna.reset_index()
indices = pd.Series(filledna.index, index=filledna['title'])
print("학습을 수행합니다.")
for j in trange(20,file=sys.stdout, leave=False, unit_scale=True, desc='학습 진행률'):
cosine_sim = cosine_similarity(count_matrix, count_matrix)
print('학습이 완료되었습니다.')
return netflix_overall, cosine_sim, indices
6. 실습. 추천 알고리즘 결과 확인
이번 실습에서는 콘텐츠 기반의 추천 알고리즘을 사용하여 새로운 콘텐츠를 추천받아 보도록 하겠습니다.
콘텐츠 기반의 추천 알고리즘은 콘텐츠와 콘텐츠 간의 유사성을 학습하여 특정 콘텐츠를 선택했을 때, 유사성이 높은 콘텐츠들을 리스트 업 할 수 있습니다.
따라서 사용자의 과거 시청 콘텐츠 데이터가 주어진다면 이 콘텐츠들과 유사한 콘텐츠들을 추천할 수가 있습니다.
이번 실습에서는 넷플릭스의 영상 콘텐츠 데이터를 입력 했을 때 유사성을 바탕으로 가장 비슷한 상위 10개의 추천 콘텐츠를 출력해봅니다.
지시사항
우측 작은 따옴표 사이에 아래 예시 중 원하는 영화명을 골라 입력해보세요.
- Vagabond
- Pororo - The Little Penguin
- The Lord of the Rings: The Return of the King
- Larva
실행 버튼을 눌러 출력된 결과를 살펴 보세요.
제출 버튼을 눌러 추천 알고리즘의 결과가 올바르게 출력됐는지 확인해보세요.
import machine as ma
def main():
netflix_overall, cosine_sim, indices = ma.preprocess()
"""
지시사항 1번. 따옴표 사이에 들어가 있는 영화명을 지우고 왼쪽 지문의 예시 중 원하는 영화명을 입력해보세요.
"""
title = 'Pororo - The Little Penguin'
print("{}와 비슷한 넷플릭스 콘텐츠를 추천합니다.".format(title))
ma.get_recommendations_new(title, netflix_overall, cosine_sim, indices)
if __name__ == "__main__":
main()import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity
def clean_data(x):
return str.lower(x.replace(" ", ""))
def create_soup(x):
return x['title']+ ' ' + x['director'] + ' ' + x['cast'] + ' ' +x['listed_in']+' '+ x['description']
def preprocess():
netflix_overall=pd.read_csv("data/netflix_titles.csv")
filledna=netflix_overall.fillna('')
features=['title','director','cast','listed_in','description']
filledna=filledna[features]
for feature in features:
filledna[feature] = filledna[feature].apply(clean_data)
filledna['soup'] = filledna.apply(create_soup, axis=1)
count = CountVectorizer(stop_words='english')
count_matrix = count.fit_transform(filledna['soup'])
cosine_sim = cosine_similarity(count_matrix, count_matrix)
filledna=filledna.reset_index()
indices = pd.Series(filledna.index, index=filledna['title'])
return netflix_overall, cosine_sim, indices
def get_recommendations_new(title, netflix_overall, cosine_sim, indices):
pd.set_option('display.max_columns', None)
title=title.replace(' ','').lower()
try:
idx = indices[title]
sim_scores = list(enumerate(cosine_sim[idx]))
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
sim_scores = sim_scores[1:11]
movie_indices = [i[0] for i in sim_scores]
recomendation = netflix_overall[['title','country','release_year']].iloc[movie_indices]
sim_pd = pd.DataFrame(sim_scores)[[1]]
sim_pd = sim_pd.rename(columns={1:'Similiarity'})
recomendation = recomendation.reset_index(drop=True)
recomendation = pd.concat([recomendation, sim_pd], axis=1)
recomendation.index += 1
return print(recomendation)
except:
print("오류: 올바른 title 명을 적어주세요.")
