1. 워드 임베딩 Word Embedding 정의
Bag of words
의 치명적 단점 -> 토큰의 의미가 숫자에 반영되어있지 않음. (단순 숫자)
CNN에서 픽셀별 데이터를 필터를 통해 특징을 추출해냈듯이, 워드 임베딩을 해서 의미를 부여
Embedding table을 통해서 변환
Bag of word의 인덱스에 따라 해당되는 벡터를 가져와서 매핑
어머니 - 0: [1,3,0,-2,0,0]
아버지 - 1: [2,2,0,-1,0,0]
친구 - 2: [0,0,1,-1,-2,0]
1) 토큰 특징을 설명하고 싶은 건데, 이 특징을 설명하기 위해 '벡터'를 사용함. 이 벡터라는 것을 사용하게 되면 벡터간의 유사도를 구할 수 있고, 연산도 가능
두 벡터 사이의 값으로 두 토큰의 의미가 얼마나 비슷한지를 알 수가 있는 등!
cos유사도 같은 것을 이용해서 유사도를 수치로 구할 수 있고, 그냥 봐도 아버지/어머니의 벡터는 친구보다 더 유사하게 구성되어있음을 알 수 있음.
Word Embedding:
단순하게 Bag of Words의 인덱스로 정의된 토큰들에게 의미를 부여하는 방식
단어의 특징을 나타내기 위해 워드 임베딩을 한다.
2. 기존 다층 퍼셉트론 신경망의 자연어 분류 방식
이미지에서도 픽셀값을 그냥 가로로 잘라서 1차원으로 변환해서 넣으면 특징을 잡을 수 없는 문제가 있었듯이,
자연어처리에서도 1차원으로 변환하는 과정에서 임베딩의 의미와 토큰 간의 순서, 관계를 적용할 수 없게 되어서 문제가 있었음.
자연어 문장을 기존 MLP 모델에 적용시키기에는 한계가 있음.
-> RNN 모델이 나옴
3. 자연어 분류를 위한 순환 신경망 Recurrent Neural Netowrk RNN
기존 퍼셉트론 계산과 비슷하게 X 입력 데이터를 받아 Y를 출력
X에 임베딩 벡터 하나가 들어감.
그것에 대해 Y값 하나가 나오는데 벡터가 나올 수도 있고 0~1 사이의 값이 나올 수도 있음
4. 순환 신경망의 입출력 구조
독특한 특징: 출력값을 두갈래로 나뉘어 신경망에게 '기억'하는 기능을 부여
결과물 말고도 h라는 값을 또 하나 만듦, 이 h라는 값이 두번째 토큰이 들어올 때 걔랑 같이 RNN에 다시 들어감(같이 들어가서 계산)
전에 사용했던 안녕에 대한 정보가 전달되는 것
RNN의 학습을 할 때의 특징: 전에 사용했던 토큰에 대한 값을 가져와서 다음 토큰에 영향을 미친다.
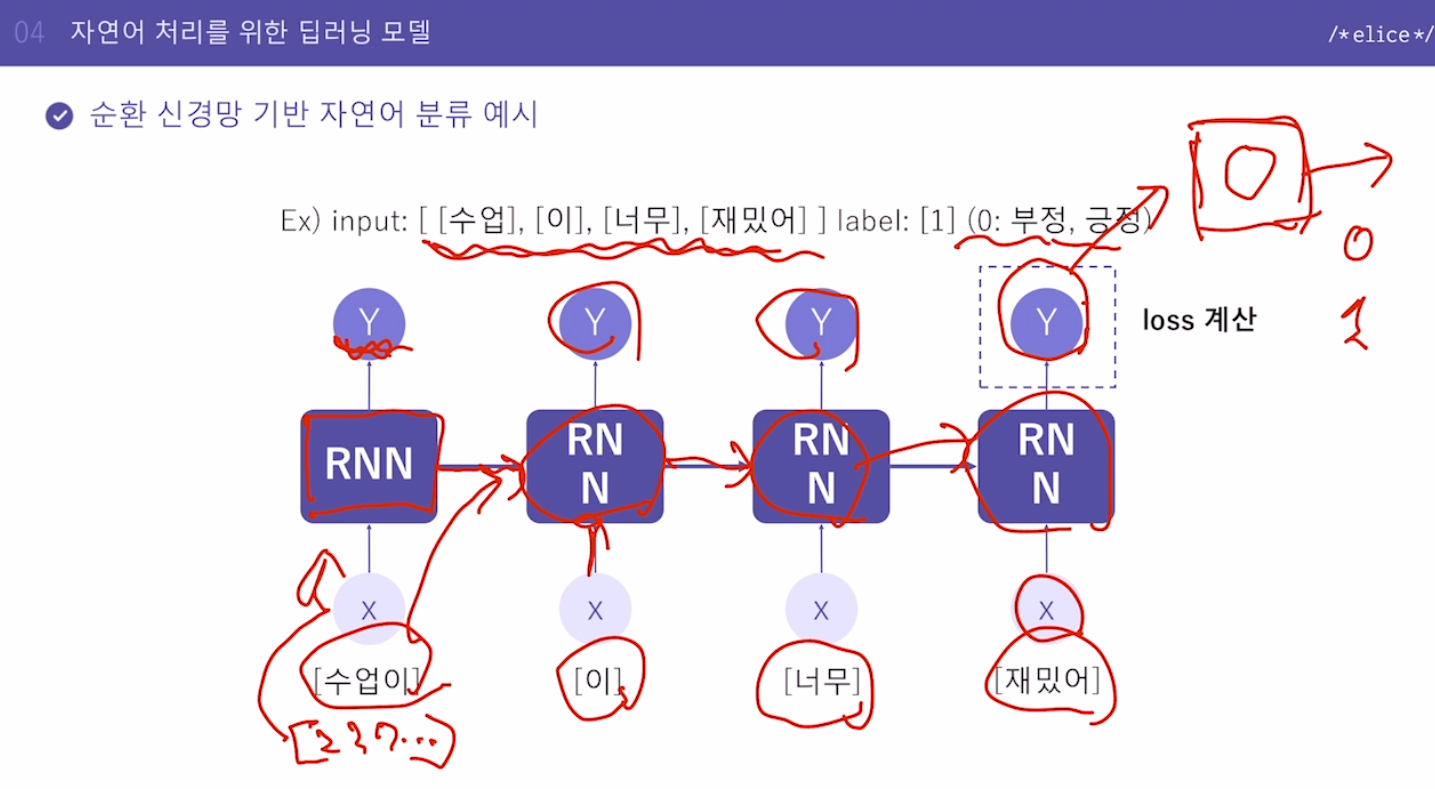
5. 순환 신경망 기반 자연어 분류 예시
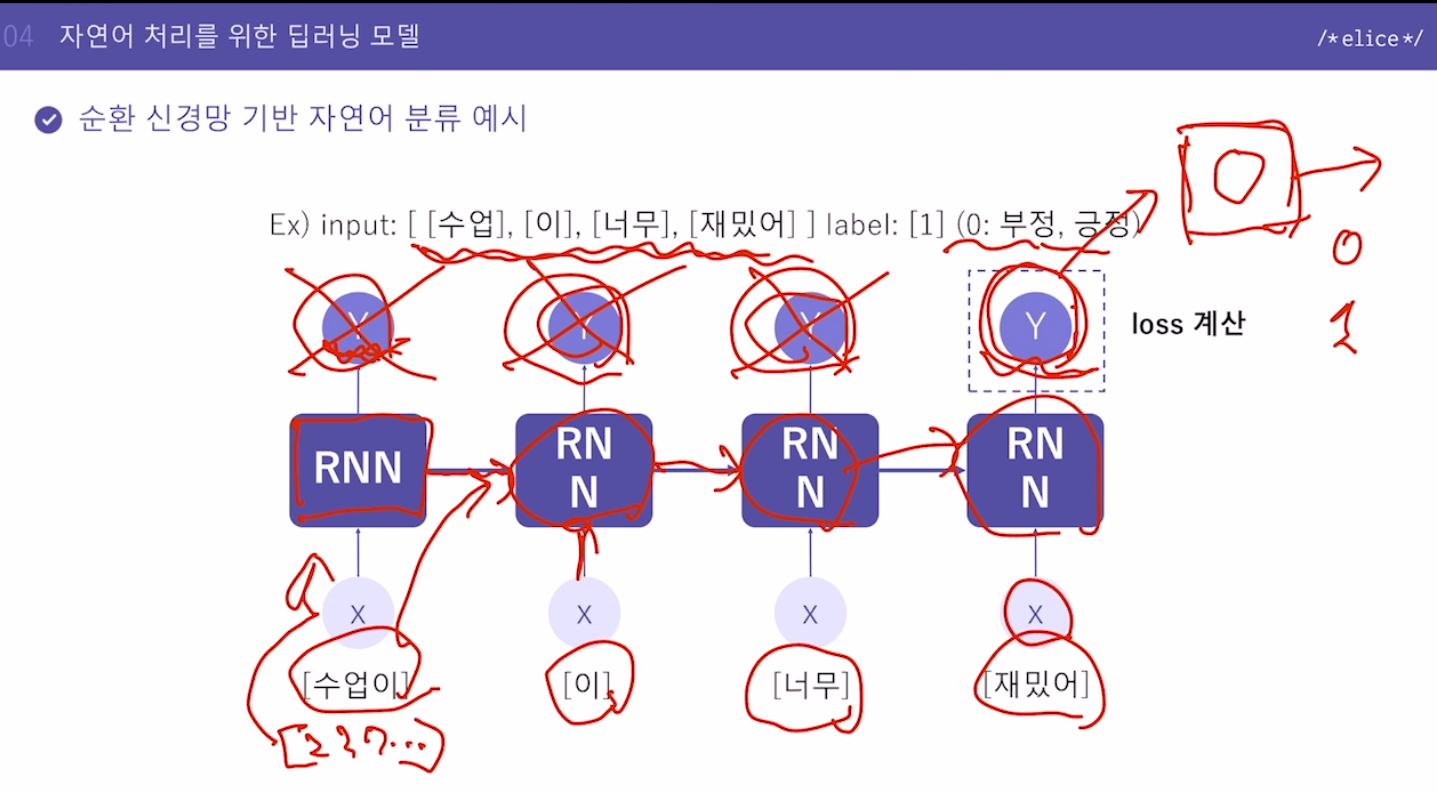
마지막에 나온 Y값만 가지고 Fully-Connected Layer에 넣어서 긍정인지 부정인지 계산
6. 정리
자연어 전처리된 데이터 -> 임베딩(특징 뽑기) -> RNN(딥러닝모델,기억하는모델) -> 활성함수(분류/멀티클래스는 softmax 등, 단일은 sigmoid, 회귀같은 경우에는 activation함수 없이 뽑아내도 되고, Loss는 MSE등 활용해서 하면 됨)
임베딩은 토큰의 특징을 찾아내고,
RNN이 전 토큰의 영향을 받으며 학습한다.
7. 순환 신경망 기반 다양한 자연어 처리 기술
- Image captioning
image -> CNN특징 -> RNN -> 캡션
RNN: 레이블을 시퀀스 형태의 레이블로 만들 수 있다는 큰 특징
(아웃풋들을 다 잇게 되면 문장으로 만들 수 있음)
-
챗봇
자연어 문장이 들어왔을 때 자연어로 만들어주는. -
다양한 모델
RNN은 가장 기본적인 신경망이고 단점을 보완하는
LSTM
GRU
TRANSFO~
다양하게 더 나은 성능의 모델들이 나오고 있음.
8. 실습. 영화 리뷰 긍정/부정 분류 RNN 모델 - 모델 학습
전 처리한 데이터를 바탕으로 RNN 모델을 구현하고 학습을 수행해보겠습니다.
Keras에서 RNN 모델을 만들기 위해 필요한 함수/라이브러리
일반적으로 RNN 모델은 입력층으로 Embedding 레이어를 먼저 쌓고, RNN 레이어를 몇 개 쌓은 다음, 이후 Dense 레이어를 더 쌓아 완성합니다.
임베딩 레이어
tf.keras.layers.Embedding(input_dim, output_dim, input_length)
: 들어온 문장을 단어 임베딩(embedding)하는 레이어
- input_dim: 들어올 단어의 개수
- output_dim: 결과로 나올 임베딩 벡터의 크기(차원)
- input_length: 들어오는 단어 벡터의 크기
RNN 레이어
tf.keras.layers.SimpleRNN(units)
: 단순 RNN 레이어
- units: 레이어의 노드 수
지시사항
RNN 모델을 구현합니다.
- 임베딩 레이어 다음으로 SimpleRNN을 사용하여 RNN 레이어를 쌓고 노드의 개수는 5개로 설정합니다.
import json
import numpy as np
import tensorflow as tf
import data_process
from keras.datasets import imdb
from keras.preprocessing import sequence
import logging, os
logging.disable(logging.WARNING)
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
# 동일한 실행 결과 확인을 위한 코드입니다.
np.random.seed(123)
tf.random.set_seed(123)
# 학습용 및 평가용 데이터를 불러오고 샘플 문장을 출력합니다.
X_train, y_train, X_test, y_test = data_process.imdb_data_load()
max_review_length = 300
# 패딩을 수행합니다.
X_train = sequence.pad_sequences(X_train, maxlen=max_review_length, padding='post')
X_test = sequence.pad_sequences(X_test, maxlen=max_review_length, padding='post')
embedding_vector_length = 32
"""
1. 모델을 구현합니다.
임베딩 레이어 다음으로 `SimpleRNN`을 사용하여 RNN 레이어를 쌓고 노드의 개수는 5개로 설정합니다.
Dense 레이어는 0, 1 분류이기에 노드를 1개로 하고 activation을 'sigmoid'로 설정되어 있습니다.
"""
model = tf.keras.models.Sequential([
tf.keras.layers.Embedding(1000, embedding_vector_length, input_length = max_review_length),
tf.keras.layers.SimpleRNN(5),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# 모델을 확인합니다.
print(model.summary())
# 학습 방법을 설정합니다.
model.compile(loss = 'binary_crossentropy', optimizer = 'adam', metrics = ['accuracy'])
# 학습을 수행합니다.
model_history = model.fit(X_train, y_train, epochs = 3, verbose = 2)9. 실습. 영화 리뷰 긍정/부정 분류 RNN 모델 - 평가 및 예측
이번 실습에서는 RNN 모델을 평가하고 예측해보겠습니다.
Keras에서 RNN 모델의 평가 및 예측을 위해 필요한 함수/메서드
평가 방법
model.evaluate(X, Y)
evaluate() 메서드는 학습된 모델을 바탕으로 입력한 feature 데이터 X와 label Y의 loss 값과 metrics 값을 출력합니다.
예측 방법
model.predict(X)
X 데이터의 예측 label 값을 출력합니다.
지시사항
1. evaluate 메서드를 사용하여 평가용 데이터를 활용하여 모델을 평가합니다.
- loss와 accuracy를 계산하고 loss, test_acc에 저장합니다.
- predict 메서드를 사용하여 평가용 데이터에 대한 예측 결과를 predictions에 저장합니다.
import json
import numpy as np
import tensorflow as tf
import data_process
from keras.datasets import imdb
from keras.preprocessing import sequence
import logging, os
logging.disable(logging.WARNING)
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
# 동일한 실행 결과 확인을 위한 코드입니다.
np.random.seed(123)
tf.random.set_seed(123)
# 학습용 및 평가용 데이터를 불러오고 샘플 문장을 출력합니다.
X_train, y_train, X_test, y_test = data_process.imdb_data_load()
max_review_length = 300
# 패딩을 수행합니다.
X_train = sequence.pad_sequences(X_train, maxlen=max_review_length, padding='post')
X_test = sequence.pad_sequences(X_test, maxlen=max_review_length, padding='post')
embedding_vector_length = 32
# 모델을 구현합니다.
model = tf.keras.models.Sequential([
tf.keras.layers.Embedding(1000, embedding_vector_length, input_length = max_review_length),
tf.keras.layers.SimpleRNN(5),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# 모델을 확인합니다.
print(model.summary())
# 학습 방법을 설정합니다.
model.compile(loss = 'binary_crossentropy', optimizer = 'adam', metrics = ['accuracy'])
# 학습을 수행합니다.
model_history = model.fit(X_train, y_train, epochs = 5, verbose = 2)
"""
1. 평가용 데이터를 활용하여 모델을 평가합니다.
loss와 accuracy를 계산하고 loss, test_acc에 저장합니다.
"""
loss, test_acc = model.evaluate(X_test, y_test, verbose = 0)
"""
2. 평가용 데이터에 대한 예측 결과를 predictions에 저장합니다.
"""
predictions = model.predict(X_test)
# 모델 평가 및 예측 결과를 출력합니다.
print('\nTest Loss : {:.4f} | Test Accuracy : {}'.format(loss, test_acc))
print('예측한 Test Data 클래스 : ',1 if predictions[0]>=0.5 else 0)
print('실제 Test Data 클래스 : ',1 if y_test[0]>=0.5 else 0)
