Blind Deconvolution이란?
Convolution에 사용된 충동반응함수(impulse response function)에 대한 명확한 지식(explicit knowledge)이 없는 Deconvolution을 말하며, 적절한 추정값(appropriate assumptions)을 input으로 넣고, output을 분석하여 충동반응(impulse response)을 추정(estimate)한다.
[Proposed Method]
- Neural Blind Deconvolution
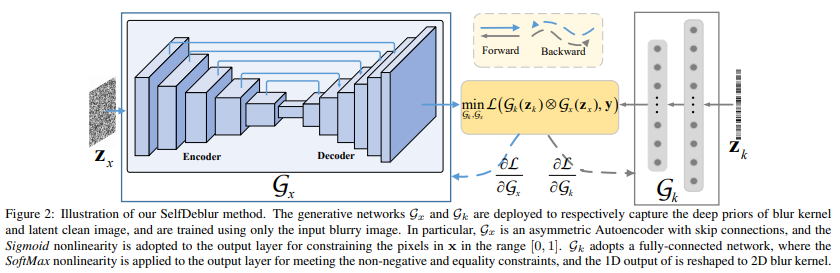
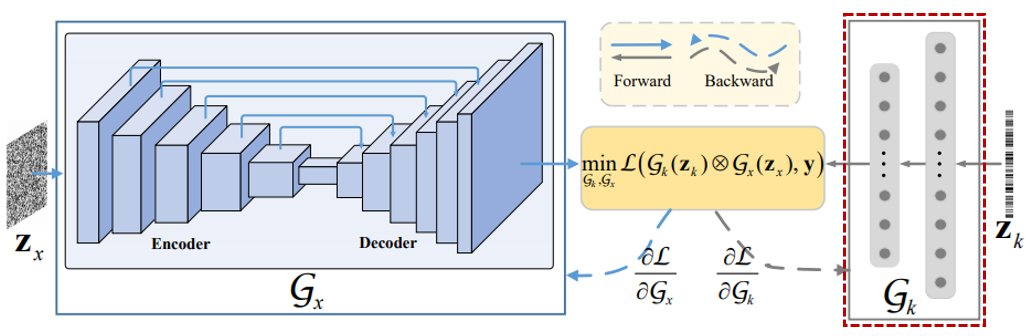
논문 Deep Image Prior(DIP)를 모티브(motive) 삼아 generative networks Gx와 Gk를 채택하여 Neural Blind Deconvolution model을 제안하였다.
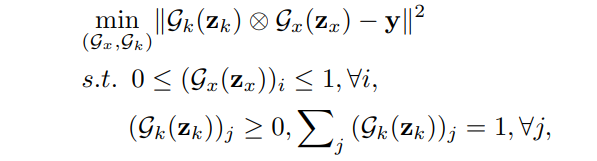
Zx와 Zk는 균등분포(uniform distribution)에서 sampling 되었고, 'i'와 'j'는 i번째, j번째 요소를 의미한다.
또한 Zk는 1D vector이며, Gk(Zk)는 blur kernel의 2D matrix를 얻기 위해 reshape된다.
그러나 neural blind deconvolution을 통해 해결해야 할 몇 가지 문제가 남아 있다.
- Deep Image Prior(DIP) network는 low-level image statistics를 capture하도록 설계되었고, blur kernels의 이전(prior)을 capture하는 데에는 제한이 있다. 그 결과 Double-DIP가 blind deconvolution에 대해 잘 수행되지 않는다는 것을 발견했다.
- non-negative와 equality constraints 때문에 Fast Motion Deblurring의 결과 모델은 제한된 nueral optimization 문제이며, 최적화하기 어렵다.
- 비록 generative networks Gx와 Gk가 image noise에 대해 높은 impedance를 주긴 하지만 DIP의 denoising 성능은 마지막 iterations 및 다른 최적화 실행에 대한 추가적인 averaging에 크게 의존한다.
그러나 이러한 경험적인 해결책은 둘 다 더 많은 계산 비용을 초래하며, 흐릿하고 noise가 있는 이미지들을 처리하기 위해 직접적으로 차용될 수 없다.
따라서 저자는 위의 1, 2번 문제들을 해결하기 위해 적절한 generative networks Gx와 Gk를 설계한 솔루션을 제시하였으며, 3번 문제에 대해서는 neural blind deconvolution model에서 noise level을 명확하게 고려하기 위해 extra TV regularizer와 regularization parameter를 도입했다.
[Generative Network Gx Architecture]
Gx = Image generator network
latent clean images는 보통 핵심적인 구조와 풍부한 질감을 포함하고 있으며, 충분한 modeling capacity를 갖기 위해 generative network Gx가 필요하다.
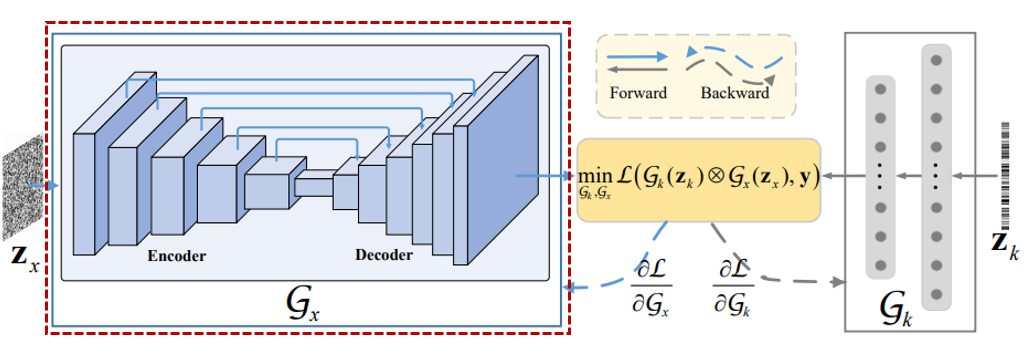
- Deep Image Prior(DIP) network
- Input : Zx sampled from uniform distribution
- Encoder-Decoder with skip connections
- Output layer : convolution -> Sigmoid => generate latent clean image

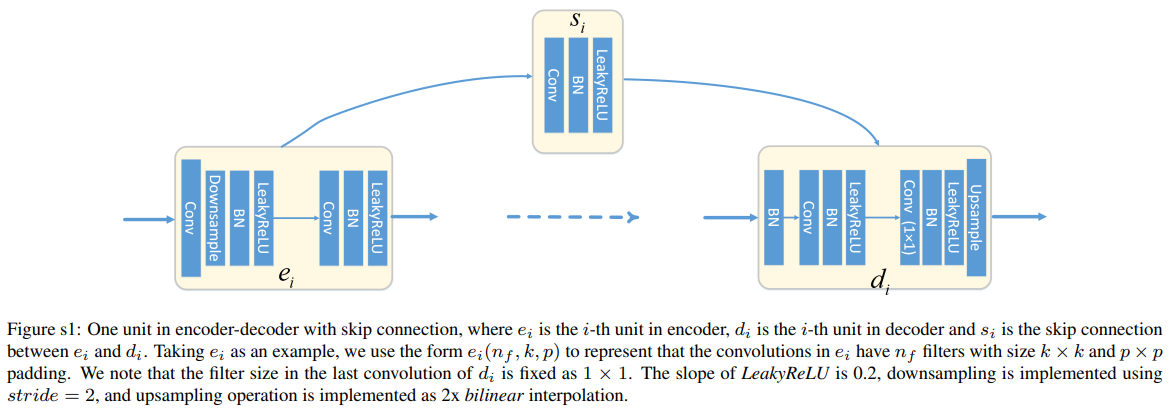
ei = i-th unit in encoder
di = i-th unit in decoder
si = skip connection between ei and di
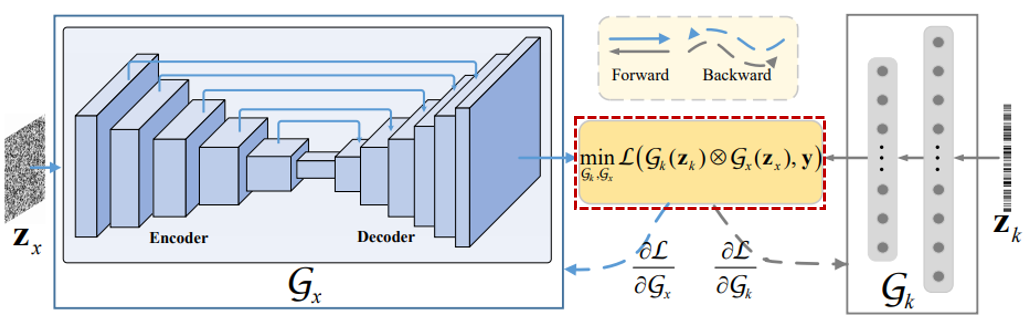
[Generative Network Gk Architecture]
Gk = characterize the prior on blur kernel
blur kernel k는 보통 latent clean image x보다 더 적은 information을 포함하며, 단순한 generative network에 의해 잘 생성될 수 있다.
저자는 Gk의 역할을 위해 fully-connected network(FCN)을 적용시켰다.
FCN Gk는 200 dimensions를 가진 1D noise Zk를 input으로 받고, 1,000개 nodes의 hidden layer와 K^2 nodes의 output layer를 가진 구조로 되어 있으며, non-negative와 equalitly constraints를 항상 만족할 수 있도록 Gk의 output layer에 SoftMax를 적용시켰다. 그 후 마지막에 K^2 entries의 1D output은 2D K^2 blur kernel로 reshape된다.
- Deep Image Prior(DIP) network
- Input : 1D noise Zk with 200 dimensions
- Fully Connected Network(FCN)
- Hidden layer : Linear -> ReLU
- Output layer : Linear -> SoftMax -> Reshape(1D->2D)

[Unconstrained Neural Blind Deconvolution with TV Regularization]
위의 generative networks Gx와 Gk를 이용하여 neural blind deconvolution을 unconstrained optimizaiton form으로 나타낼 수 있지만, 해당 결과 모델은 noise level과는 무관하기 때문에 non-negligible noise가 있는 blur images에서 성능이 저하되는 문제가 있다. 그래서 이 문제를 해결하고자 Gx와 TV regularization를 결합하여 image priors를 capture한다.
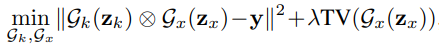
TV Regularization = Total Variation Regularization
λ = noise level(σ)에 의해 통제되는 정규화 파라미터(regularization parameter)
비록 generative network Gx가 더 powerful하지만 Gx와 또 다른 image prior의 혼합은 deconvolution 성능에 도움이 된다. 또한, regulization parameter λ와 관련된 noise level의 도입은 다양한 noise levels가 있는 흐릿한 images을 다룰 때 robustness를 더욱 향상시킬 수 있다.
- Optimization Algorithm
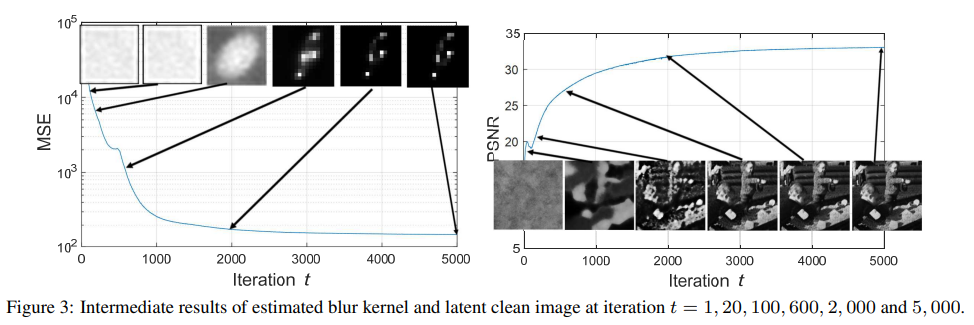
Double-DIP의 optimization process는 "zero-shot" self-supervised learning의 한 종류로 설명될 수 있는데, generative networks Gk와 Gx는 오직 test image(i.e., blurry image y)를 이용하여 학습되고, ground-truth clean image는 사용할 수 없다. 따라서 저자는 dubbed SelfDeblur 방법을 제시했고, SelfDeblur를 위한 두 가지 알고리즘으로 alternating optimizaiton과 joint optimization을 사용했다.
-
Alternating Optimization
전통적인 blind deconvolution의 alternating minimization step와 유사하게 Gk와 Gx의 network parameters도 alternating 방식으로 최적화될 수 있다.
알고리즘 A Neural Approch to Blind Motion Declurring에 요약된 바와 같이, Gk의 parameter들은 ADAM을 통해 Gx를 고정함으로써 업데이트 되며, 그 반대의 경우도 마찬가지이다.
특히, Gx나 Gk에 관한 gradient는 자동 미분법(automatic differentiation)을 사용하여 도출될 수 있다.
자동 미분 기법 A를 사용하여 Gk 및 Gx에 대한 구배를 도출할 수 있습니다. -
Joint Optimization
neural blind deconvolution은 제한 받지 않는 최적화이며, Gk 및 Gx의 강력한 modeling capacity는 사소한 delta kernel solution을 피하는 데 유용하다. 또한 제한 받지 않는 neural blind deconvolution은 매우 non-convex하며, alternating optimization은 안장지점(saddle point)에 고착될 수 있다. 따라서, SelfDeblur에서는 joint optimization이 alternating optimizaiton 보다 더 선호되며, joint optimization 알고리즘을 통해 Gk와 Gx의 parameter들은 공동으로 ADAM을 이용하여 업데이트될 수 있다.
[Experimental Results]