
ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks
[Abstract]
SRGAN은 single image super-resolution에서 현실적인 질감을 만들어낼 수 있긴 하지만 종종 이상한 인공적인 디테일들도 함께 만들어낸다. 저자는 시각적인 품질을 더욱 향상시키기 위해 SRGAN 네트워크 구조와 adverarial loss, perceptual loss 이 3가지 기본 요소를 연구하였고, 그 결과를 통해 더욱 성능이 향상된 SRGAN 즉, Enhanced SRGAN (ESRGAN)을 제안하게 되었다. 특히, 저자들은 기존 SRGAN에 있던 Batch Normalization을 없앤 Residual-in-Residual Dense Block(RRDB)를 도입했고, relativistic GAN으로부터 아이디어를 얻어 Discriminator가 절대값 대신 relative realness를 예측하도록 했다.
마지막으로 저자는 활성화(avtivation) 전에 feature들을 사용함으로써 perceptural loss를 개선하였고, 이를 통해 밝기 일관성과 질감 복원에 대해 강력한 supervision을 제공할 수 있었다.
ESRGAN은 일관성 있게 SRGAN 보다 더욱 현실적이고 자연스러운 질감을 가져 시각적인 품질이 좋았고, PIRM2018-SR Challenge에서 1등을 수상하였다.
[Proposed Methods]
저자의 주 목표는 SR에 대해 종합적인 지각 품질을 향상시키는 것이다.
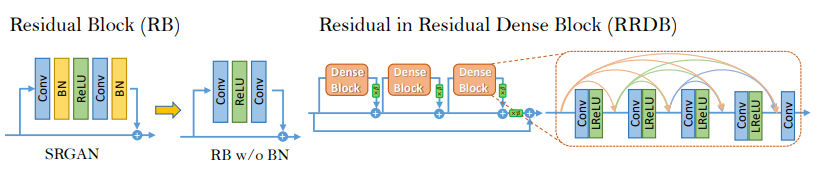
1. Network Architecture
SRGAN에 의해 복원된 이미지의 품질을 더욱 향상시키기 위해 저자는 생성자(Generator)의 구조에서 2가지를 수정하였다.
① 모든 Batch Normalizaion(BN) layer들을 제거하였다.
② 기존의 basic block을 multi-level residual network와 dense connection들을 결합한 Residual-in-Residual Dense Block(RRDB)로 대체하였다.
- Removing BN layer
BN layer들은 학습하는 동안 한 batch에서 평균과 분산을 사용하여 특징들을 정규화시키고, 테스트하는 동안 전체 학습 dataset으로부터 추정된 평균과 분산을 사용한다.
학습 datasets의 통계치와 테스트 datasets의 통계치가 서로 많이 다르면 BN layer들은 이상한 인공물들(artifacts)을 만들어내는 경향이 있고 일반화 능력을 제한하는데, 더 깊고 GAN framework에서 학습된 네트워크일수록 이러한 인공물들을 더 만들어내는 것처럼 보였다. 따라서 저자들은 안정적인 학습과 일관된 성능을 위해 BN layer를 제거하였고, 이로 인해 일반화 능력이 향상되고, 계산 복작성과 메모리 사용량이 감소되었다.
- Residual-in-Residual Dense Block (RRDB)
저자들은 SRGAN의 구조를 유지하며 새로운 RRDB를 사용하였다. RRDB는 기존 SRGAN의 residual block 보다 더 깊고 더 복잡한 구조이며, 메인 경로에서 dense block을 사용하는데, 이로 인해 네트워크 용량(capacity)은 더욱 커지게 된다.
향상된 구조 외에도, 저자들은 매우 깊은 네트워크를 학습시키는 것을 용의하게 하기 위해 몇몇의 기술들을 이용했다.
① Residual scaling
- 불안정성을 방지하기 위해 메인 경로에 추가하기 전에 0과 1 사이의 상수를 곱하여 residuals 스케일 축소를 한다.
② Smaller initialization
- residual 구조는 초기 매개변수 분산이 작을 수록 더욱 쉽게 학습시킬 수 있다.
2. Relativistic Discriminator
저자들은 또한 Relativistic GAN 기반의 판별자(Discriminator)를 개선하였다. 하나의 input 이미지(x)가 진짜이고 자연스러운 것일 확률을 추정하는 SRGAN의 기본 판별자(D)와는 다르게, relativistic discriminator는 진짜 이미지(Xr)가 가짜 이미지(Xf) 보다 상대적으로 더 현실적일 확률을 예측한다.
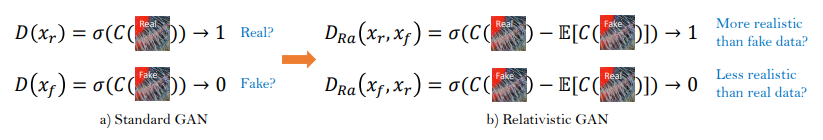
- Relativistic average Discriminator loss
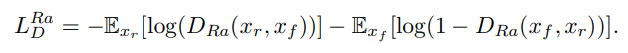
- Adversarial loss for Generator
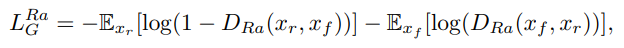
3. Perceptual Loss
저자들은 활성화(activation) 전에 feature들을 제한함으로써 SRGAN보다 더욱 효과적인 perceptual loss(Lpercep)를 개발하였고, 이를 통해 기존의 2가지 문제점을 해결하였다.
① 매우 깊은 네트워크 후에 활성화된 features들은 매우 sparse함으로, 질 낮은 성능으로 이어진다.
② 활성화 후 feature들을 사용하는 것은 ground-truth 이미지와 비교했을 때 일관성 없는 복원된 밝기를 야기한다.
- Total loss for generator
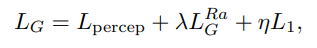
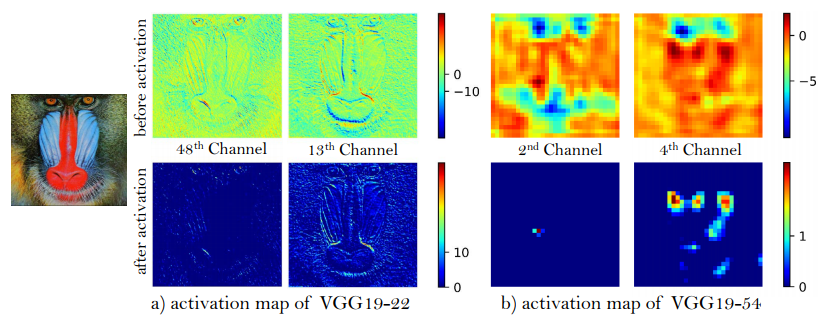
활성화 후 대부분의 feature들은 소극적(inactive)으로 된 반면, 활성화 전 feature들은 더 많은 정보들을 가지고 있다.
4. Network Interpolation
저자들은 GAN 기반 방법의 이상한 noise를 제거함과 동시에 양호한 지각 품질을 유지하기 위해 유연하고 효과적인 전략으로 network interpolation을 제안했다. 구체적으로, 먼저 PSNR-oriented network(Gpsnr)을 학습한 후, 미세한 조정(fine-tuning)을 통해 GAN-based network(Ggan)를 얻었다. 저자들은 보간된 모델 Ginterp를 도출하기 위해 두 네트워크의 모든 해당 매개변수들을 보간했다.
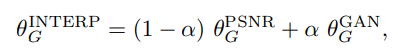
'θ INTERP G', 'θ PSNR G', 'θ GAN G'은 각각 Ginterp, Gpsnr, Ggan의 매개변수들이며, α ∈ [0, 1]는 보간 매개변수이다.
해당 network interpolation에는 두 가지 장점이 있다.
① 인공물(artifacts) 생성 없이 어느 실현가능한 α에 대해 의미 있는 결과를 만들어낼 수 있다.
② 모델을 재학습시킬 필요없이 지속적으로 지각 품질과 정확도의 균형을 유지할 수 있다.
[Experiment results]

[Conclusion]
-
이전의 SR 방법들 보다 일관되게 지각 품질이 더 좋은 ESRGAN 모델을 제안했고, 이 방법은 PIRM-SR Challenge에서 1등을 차지했다.
-
BN layers가 없는 여러 RDDB block들을 가진 새로운 구조를 만들어 냈으며, residual scaling과 samller initialization을 포함한 유용한 기술들은 제안된 깊은 모델의 학습을 용의하게 하기 위해 사용되었다.
-
판별자(Discriminator)로서 한 이미지가 다른 이미지보다 더 현실적인지 아닌지를 판단하는 것을 학습하는 relativistic GAN을 사용했는데, 생성자(Generator)가 보다 상세한 질감을 복구할 수 있도록 도와준다.
-
활성화 전에 feature들을 사용하여 perceptual loss를 개선했는데, 이는 강한 supervision을 제공하며, 이로 인해 정확한 밝기와 현실적인 질감들을 더 잘 복원한다.
