AI Tech 이후는 최신 기술들에 대해 알아보기로 했다. 여러 분야가 있지만, 내가 관심이 특히 더 많이 갔던 Multi-modal Learning이다. 그래서 Multi-modal에 대한 논문들을 읽기 전에, 대략적인 개요를 먼저 살펴보려고 한다. 양이 많아 두 개의 게시물로 나누어서 올려야 할 것 같다. 이 글은 내가 AI Tech를 들을 때 수강했던 Multi-modal 강의를 참고해서 작성했다.
1. Multi-modal Learning 개요
1) Modality
먼저, Multimodal이라는 단어의 뜻부터 살펴보자. Modal은 Modality에서 온 것으로, AI에서는 데이터의 형태나 종류를 의미한다. 후각, 오디오, 촉각, 텍스트, vision 등이 모두 modality의 예시이다. modality의 의미를 알았으니, Multi-modal은 아래와 같이 정의할 수 있다.
Multi-modal: 여러 개의 modality가 입력으로 주어지는 task
Uni-modal: 한 개의 modality가 입력으로 주어지는 task
소리(audio)와 visual data가 입력으로 들어오는 모델의 경우 multi-modal model이라고 할 수 있고, 우리가 그 동안 익히 봐왔던 소리만 입력으로 들어오거나 visual data만 입력으로 들어오는 모델은 uni-modal model이라고 볼 수 있다. 깔끔하게 audio와 visual data를 적재적소에 잘 사용해 성능이 굉장히 뛰어난 모델을 만들면 좋겠지만, 이는 쉽지 않은 문제이다.
2) Challenges
일반적인 Uni-modal model의 경우, input data로부터 feature를 생성하고, 이를 이용해 task를 해결한다. uni-modal이기 때문에, 하나의 feature representation만 생기게 된다. 그런데 Multi-modal로 넘어오게 되면, 여러 개의 input data를 이용하기 때문에, feature representation 또한 여러 개 생긴다. 여기서 여러 가지 문제가 생기게 된다.
i) modality 간의 representation의 차이
각 modality별로 데이터의 representation 형태가 달라 생기는 문제이다. 예를 들면, 이미지는 픽셀별로 0~255 사이의 값들이 모델에게 주어지고, 텍스트는 글자를 embedding vector로 바꾸어 모델에게 주어질 것이다. 이 두 data 형식을 같은 방식으로 처리하기는 어렵다. 이 때문에 multi-modal model의 network의 입력단 설계가 중요해진다.
ii) Heterogeneous 한 feature space 간의 정보 불균형
말이 좀 어려워 보이지만, 상황에 따라 modality 간의 정보량 차이가 있을 수 있다는 뜻이다. 예를 들어, "A man is sitting in a chair." 라는 텍스트가 있을 때, 이 문장을 이미지로 표현한다면 여러 가지의 경우로 표현할 수 있을 것이다. 남자의 자세, 의자의 각도, 의자의 종류 등 하나의 문장을 이미지로 표현 할 때, 이미지가 훨씬 다양한 정보들을 가질 수 있게 된다. 때문에 modality간의 1:N 관계가 나타나게 된다. (하나의 문장에 대해 N개의 이미지를 가지는 관계) 이것 또한 multi-modal model을 생각할 때 고려해야 할 문제이다.
iii) 특정 modality에 대한 편향
마지막 문제는 모델이 학습하기 쉬운 modality에만 치중해 학습을 할 수 있다는 것이다. 예를 들어 이미지와 소리의 데이터를 가지고 multi-modal model을 훈련시킬 때, 소리에는 노이즈가 끼는 등 학습에 어려움이 이미지보다 많으니, 이미지 데이터만 이용해 학습을 할 수도 있다. 이는 여러 modality에서 훈련시켜 더 좋은 성능을 얻으려는 우리의 의도와 다르다.
또, modality의 특성이 아니라 각 modality의 dimension의 차이에 따라 편향이 일어날 수도 있다. 여기서 각 modality를 라고 하고, 이들의 weight를 각각 라고 하자.
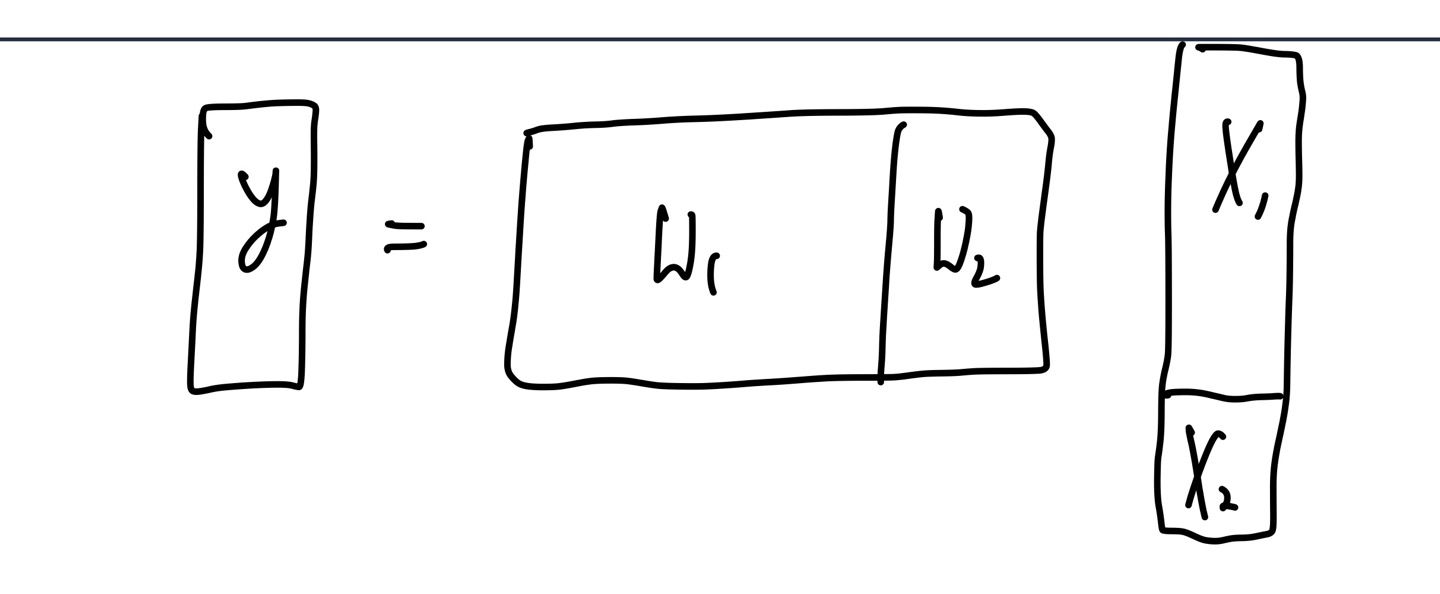
만약 위의 사진처럼 의 차원이 보다 많이 크다면, 차원을 맞춰주어야 하기 때문에 의 크기도 의 차원에 맞게 달라지게 된다. 우리가 결국 학습하는 것은 weight들이기 때문에, 학습할 때부터 의 parameter가 보다 많아지게 되고, 결국 modality가 최종 결과인 y에 더 많은 기여를 하게 된다. 이 또한 특정 modality에 편향되는 상황으로 볼 수 있다.
이러한 challenge들이 multi-modal learning을 어렵게 하지만, 만약 multi-modal learning이 가능하다면, 더 많은 장점을 얻을 수 있을 것이다.
3) 인간의 multi-sensory modality 처리 방법
AI 기술은 인간이 어떻게 정보를 처리하는지에서 영감을 많이 얻어 발전되어 왔다. Neural Network도 인간의 뇌 활동에서 아이디어를 얻었듯이 말이다. 우리 뇌의 활동 신호인 fMRI를 보면, 어떤 감각 기관을 사용하는지와 관계 없이 같은 개념을 인식할 때 모두 같은 fMRI 신호가 나타나는 것을 볼 수 있다. 예를 들면, 비행기라는 개념을 우리 뇌가 인식할 때, 눈을 사용하는 것과 귀로 비행기 소리를 듣는 것 모두 같은 fMRI 신호가 나타난다는 것이다. 이렇듯 우리의 뇌는 특정 개념에 대해 학습하면, 각각의 modality 정보를 하나의 concept space에 mapping해서 학습한다. 따라서 어떤 감각 기관으로 들어오는지와 관계 없이 항상 그 개념을 떠올리게 되는 것이다.
2. Multi-modal Data Representation
대략적인 multi-modal learning에 대한 개요를 살펴봤으니, 이제 데이터를 어떤 식으로 표현하는지에 대해 알아보자. visual data, text embedding, sound representation에 대해 차례대로 소개하려고 한다.
1) Visual Data
i) Image Data Structure
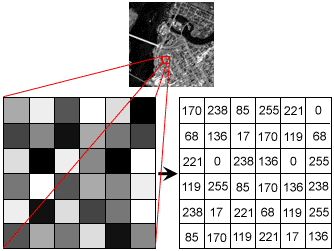
Visual Data 중에서 Image는 2D 혹은 3D 형태의 array로 표현할 수 있다. 통상적으로 각 픽셀 별로 0~255 사이의 intensity 값을 주어 표현한다. 이미지가 grayscale, 즉 흑백으로 이루어져 있는 경우 2D array로 표현되고, 컬러 사진인 경우 RGB 채널에 대한 값이 주어져 3D tensor로 표현하게 된다. 이때, 3D image의 각 차원은 (Height, Width, Channel)을 의미한다. (channel은 RGB channel을 의미하기 때문에 보통 3D 이미지는 (H,W,3) 의 형태를 갖는다.)
ii) Video Data Structure
Video Data는 이미지 프레임 여러 개를 쌓아놓은 것이다. 이미지랑 별 다를 게 없다. 컬러의 경우, (H,W,C,T) 4D tensor로 표현하게 된다. 이때, T는 time을 의미하며, 쉽게 말해 쌓은 frame의 개수이다.
iii) 3D Data Structure
3D data는 표현하는 방법이 굉장히 다양하다. 구체적으로는 Multi-view images, Voxel, Part assembly, Point cloud, mesh, Implicit Shape를 살펴보려고 한다.
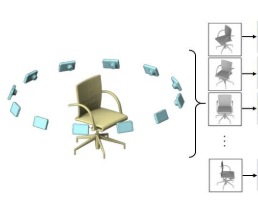
Multi - view image는 하나의 사물에 대해 여러 각도에서 사진을 찍어 3D로 rendering하는 기법이다.
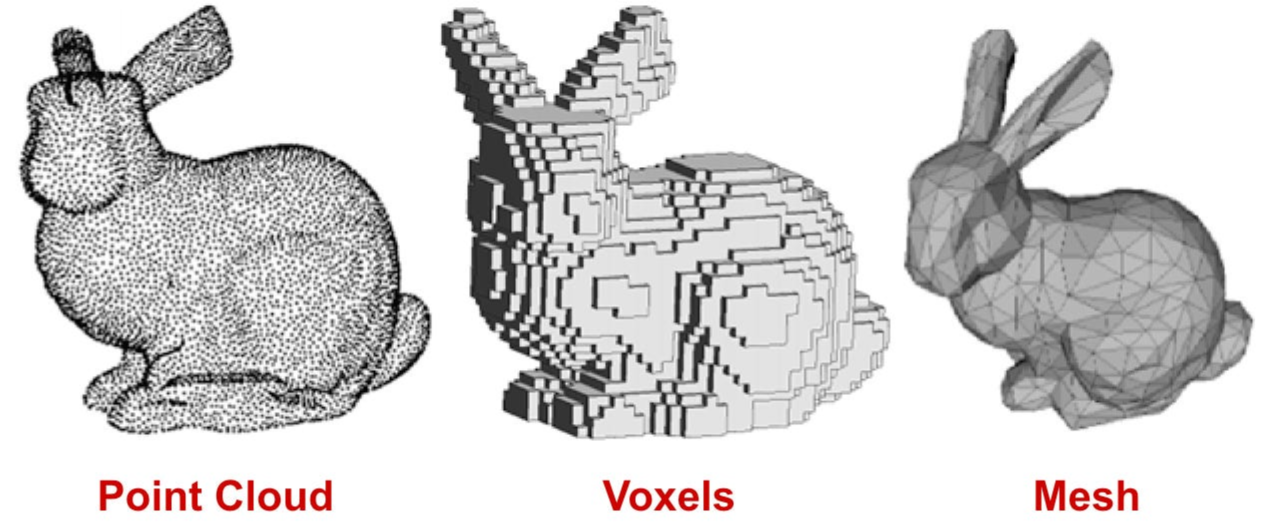
Part assembly는 mesh를 파트별로 나누어 처리하는 기법이다.

Implicit shape은 3D 영역 밖이냐 안이냐에 따라 값이 결정되는 방법이다. 라는 식이 있을 때, 이면 3D 영역 안, 이면 3D 영역 밖, 이면 3D 영역의 표면임을 의미한다.
2) Text Embedding
우리가 사용하는 텍스트, 즉 문자들은 ML에서 다루기가 어렵다. 따라서 단어나 token들을 dense vector들로 mapping해서 사용한다. 먼저 token과 tokenization에 대해 알아보자. token은 단어들을 숫자로 표현하는 것을 의미한다(Numerical representation of words). word dictionary와 같이 pre-fixed vector embedding의 형태를 가진다. tokenization은 텍스트 데이터를 작은 unit들, 즉 token들로 나누는 작업을 의미한다. 숫자의 형태가 텍스트보다 더 처리하기 편하기 때문에 숫자를 사용한다.
문장과 같은 input data가 들어오면, tokenizer를 통해 token 단위로 쪼개지고, 각 token에 id를 mapping한다. 결과적으로, input data는 token 단위로 쪼개지고, 각 token은 고유 id를 갖게 되는 것이다. 이후에 아래 사진과 같이 embedding layer를 통해 token id를 벡터로 변환하게 된다.
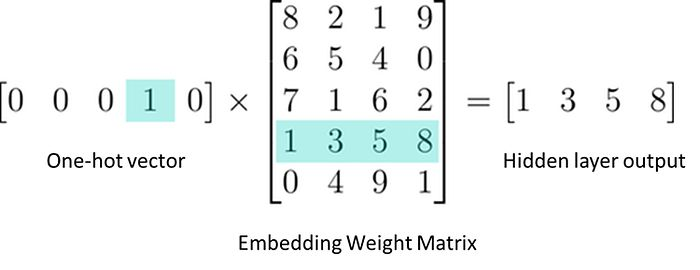
one-hot vector 형태로 indexing 되어 있는 token에 embedding weight matrix를 곱해주어 index에 해당하는 token embedding이 나오도록 해준다.
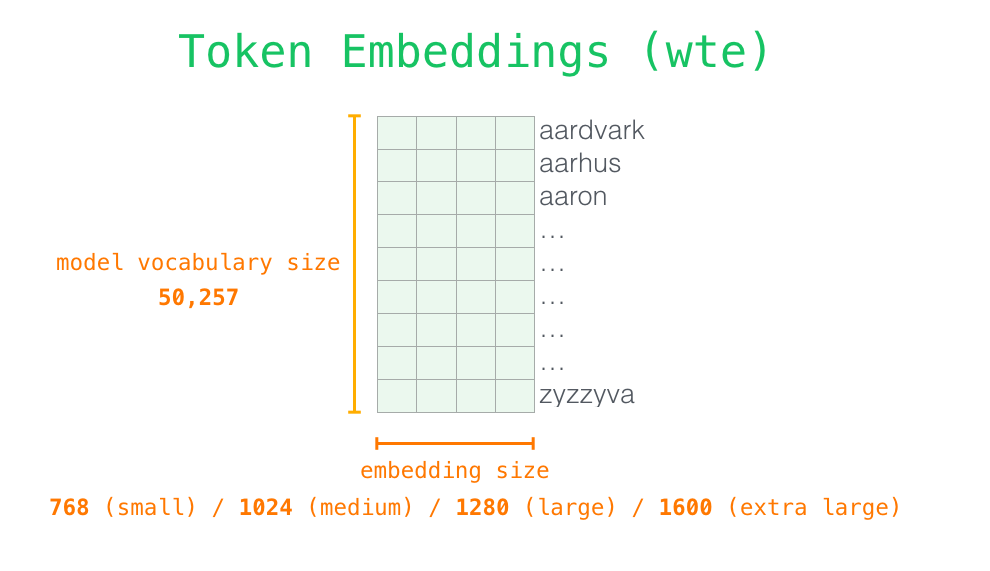
위의 사진처럼 사용되는 vocabulary를 미리 정의해놓고, embedding 사이즈를 결정해 최종 token embedding이 나오게 되는 것이다.
Word2Vec
고전적으로 embedding layer를 학습하는 방법 중 하나인 word2vec 중에 skip-gram 방식에 대해 알아보자.
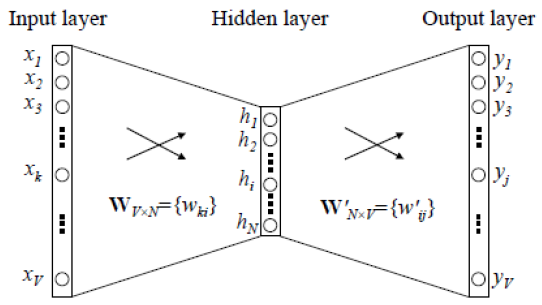
위의 사진처럼 의 weight를 가지는 embedding layer가 있고, 의 weight matrix를 가지는 decoding layer가 있다. 이때, input layer는 one-hot vector들로 구성되어 있다. 가 우리가 학습해야 하는 embedding matrix이고, output layer는 softmax 등을 이용해 예측한 단어 분포를 확률로 바꿔주는 역할을 한다. 이러한 구조를 통해 현재 단어의 앞, 뒤에 어떤 단어가 오는지 예측하는 것이다.
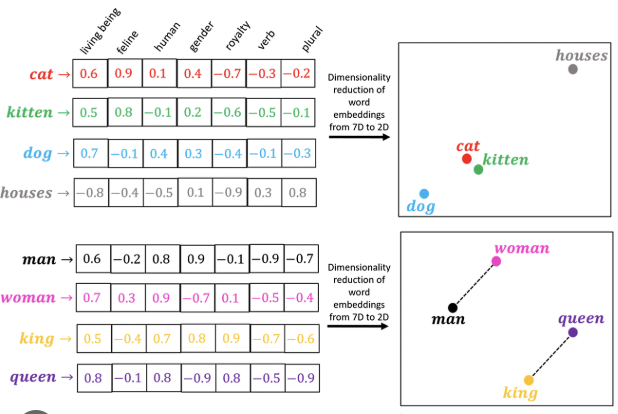
이와 같은 방식으로 학습을 진행하면, 단어들 간의 관계를 학습하기 때문에 일반화 성능이 뛰어나다. 위의 사진처럼 man과 woman의 관계를 학습해서, king과 queen의 관계도 잘 나타내는 것을 볼 수 있다. 이와 같이 semantic한 관계들을 잡을 수 있다는 점이 인상적이다.
3) Sound Representation
마지막으로 Sound Representation이다. 개인적으로 text나 visual data는 많이 접해보았으나, Sound data는 접해본 적이 없어서 신기했다. 크게 waveform, power spectrum, spectrogram을 살펴볼 것인데, 요새 많이 사용하는 것은 spectrogram이라고 한다. 그래서 waveform에서 power sprectrum을 통해 spectrogram을 얻는 과정을 다루어 보려고 한다.
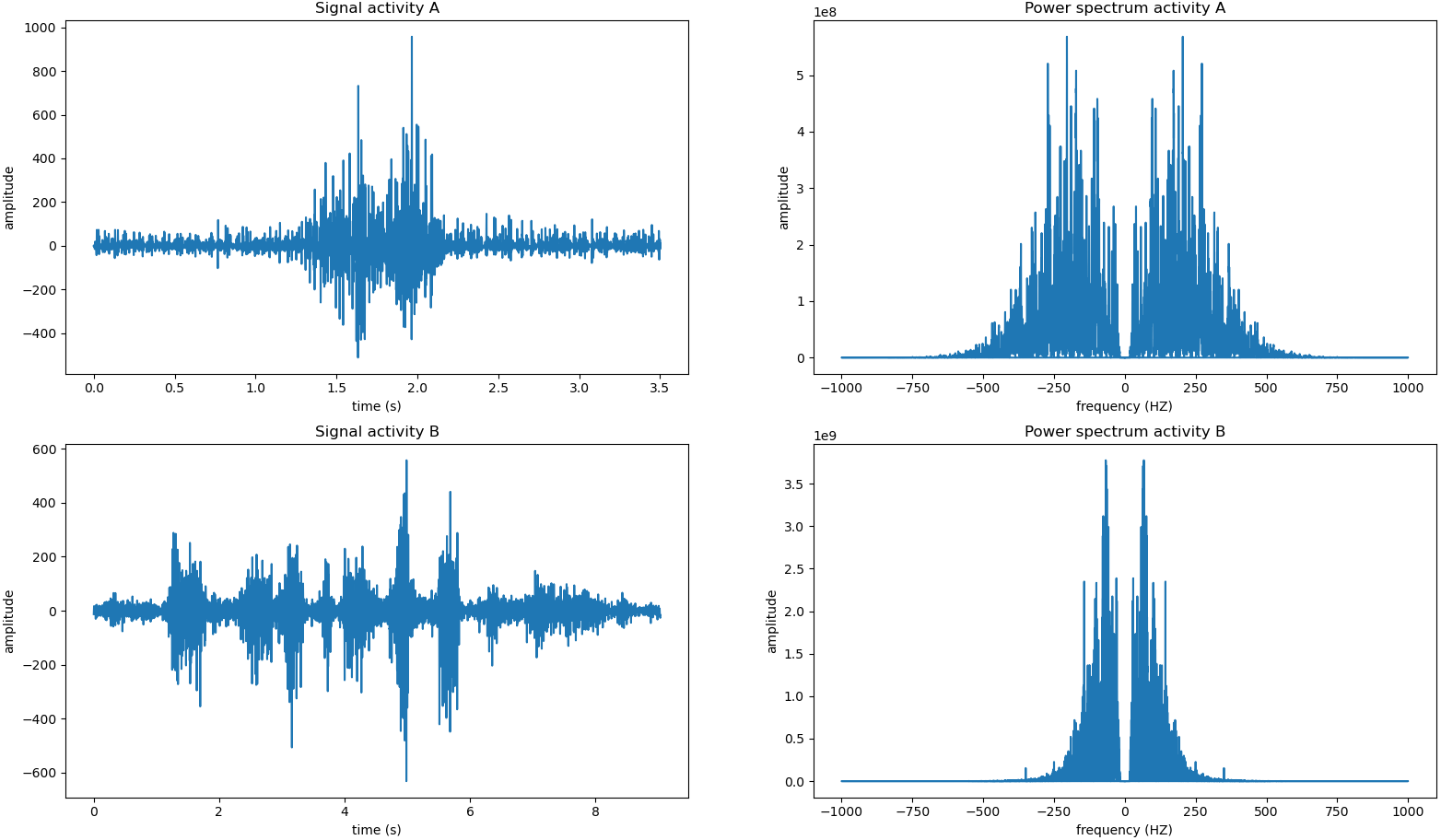
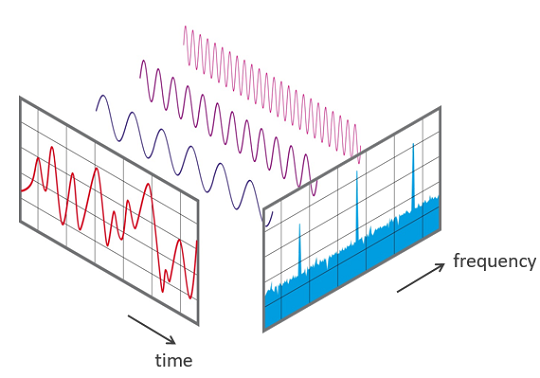
Fourier Transform이 어떻게 진행되는지 알아보자. time domain( ) -> frequency domain()으로 변환하는 것인데, sine 그래프와 를 내적하여 sine의 성분이 얼마나 들어있는지 측정한다. 그리고 sine 그래프의 주파수를 점차 높여가며 와 내적을 반복한다. 이러한 과정을 통해 power spectrum을 얻는다.
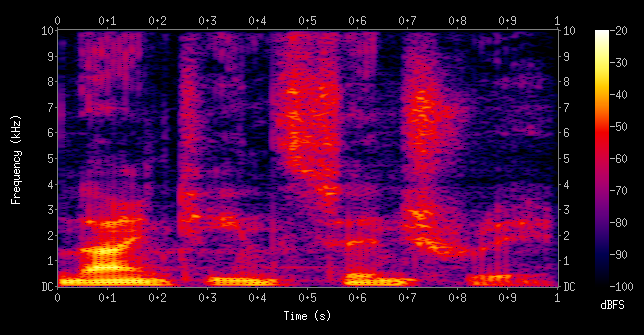
3. Multi-modal Alignment
이제 각 modality의 Feature space들을 어떻게 사용하는지에 따라 matching, translating, referencing의 방식들을 알아보려고 한다.
1) Joint Embedding
위에서 언급한 것들 중 matching에 해당하는 내용이다. 2개의 modality를 동일한 feature space로 embedding하는 것을 의미한다. image에 해당하는 feature가 주어지면 어울리는 text를 찾아주는 Image Tagging이나, text가 주어졌을 때 내용에 해당하는 이미지를 찾아주는 image retrieval 등이 application이다.
이러한 방식을 사용하는 대표적인 모델이 CLIP과 ImageBIND라는 모델이다. 더 자세히 살펴보자.
2) CLIP (Contrastive Language-Image Pre-training)
Image Recognition system을 예로 들어서 한 번 생각해보자. 가장 완벽한 시스템을 만들려면, 이 세상에 존재하는 모든 이미지를 다 기억할 수 있도록 저장해놓는 것이다. 그러나 현실에서는 모든 데이터를 모으는 것이 불가능하다. 그렇다면 현실에서 사용할 수 있는 좋은 방법에는 뭐가 있을까? 언제나 그렇듯, 어렵고 복잡해 보이는 문제는 Machine Learning의 Neural Network를 이용해서 해결한다. 데이터를 Neural Network에 압축해놓고 Image Recognition을 수행하는 것이다. 이것이 일반적인 방법인데, multi-modal에서는 어떻게 모델을 설계하는지 알아보자.
CLIP은 text와 image를 input으로 받으며, text를 이용해 visual concept를 배운다. 인터넷에서 얻은 4억개의 (image, text) pair를 가지고 훈련을 진행했다. 아래는 CLIP의 구조이다.
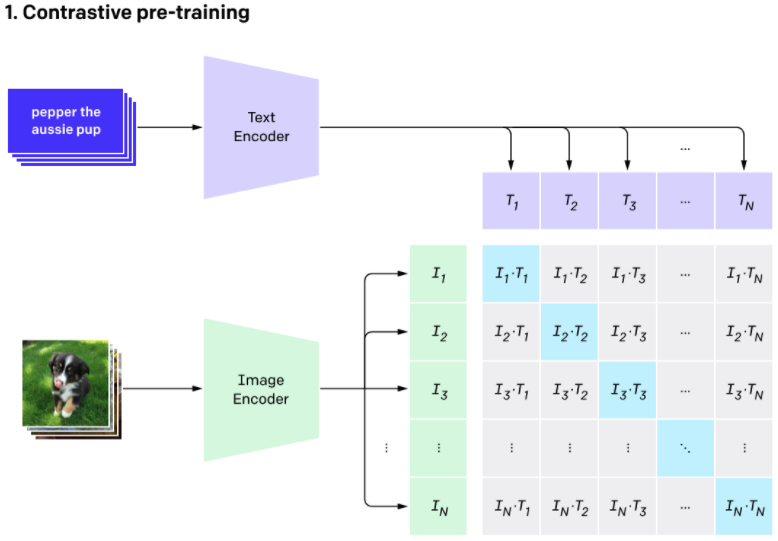
Image Encoder는 ViT-B 혹은 ResNet50를 사용하고, Text Encoder는 transformer를 사용한다. 위의 사진에서 은 image data의 feature embedding이고, 은 text data의 feature embedding이다. CLIP의 이름에서도 알 수 있듯이, Contrastive Learning을 사용한다. 유사한 개념은 거리를 가깝게, 그렇지 않은 개념은 멀게 학습하는 발법이다. 이렇게 학습하면 text에 맞는 image가 embedding space 내에서 가까운 거리에 놓이게 된다. 이때 중요한 것이, 이 두 개념의 유사도를 어떻게 측정할 지이다. CLIP에서는 cosine similarity를 사용한다.
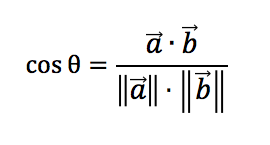
N개의 Image, N개의 Text pair에 대한 feature에서 모든 조합인 NxN 개의 cosine similarity를 계산하고, 이를 통해 유사한 개념들을 학습하게 된다. 당연히 contrastive learning의 목표는 N개의 정답 embedding pair에 대한 cosine similarity를 최대화하고, 정답이 아닌 나머지 pair들에 대해서는 최소화하는 것이다. Loss function은 cross entropy를 사용한다.

이런 식으로 학습한 CLIP은 다른 도메인에 대한 일반화 성능도 높다.

여러 가지 데이터셋에 대해서 zero-shot prediction을 했을 때 성능 개선이 이루어졌음을 알 수 있다. CLIP은 Image Captioning, Image Stylization with language, Image/video retrieval with text, text-to-image generation, CLIP-guided motion generation, CLIP-guided 3D object/mesh generation 등 다양한 분야에 적용되는 추세이다. 이렇게 CLIP이 적용된 모델들을 몇 개 살펴보자.
3) Image Captioning (1) - ZeroCap: Zero-shot Image-to-Text Generation for Visual Semantic Arithmetic
ZeroCap은 pre-trained CLIP을 이용해 Image Captioning을 하는 모델이다. 여기서 zero-shot은 모델이 test시 한 번도 보지 않은 데이터로 예측을 진행하는 방식을 의미한다. 크게 보면 ZeroCap의 구조는 CLIP+ GPT-2로 구성되어 있으며, 추가적인 training 없이 optimization만을 사용해 성능 개선을 이루었다. 이미지가 주어졌을 때 이미지에 맞는 caption을 생성하는 모델이고, ZeroCap은 이전의 caption generation보다 더 상세한 caption을 생성했다.

위의 사진들에 대한 caption을 생성한 것을 보면, 비교적 일반적이고 보편적인 caption을 생성하던 이전 모델들과는 달리, 케네디, 트럼프, 마리오 등 인물에 대한 정보도 제공함을 알 수 있다. 더 자세한 구조에 대해 알아보자.
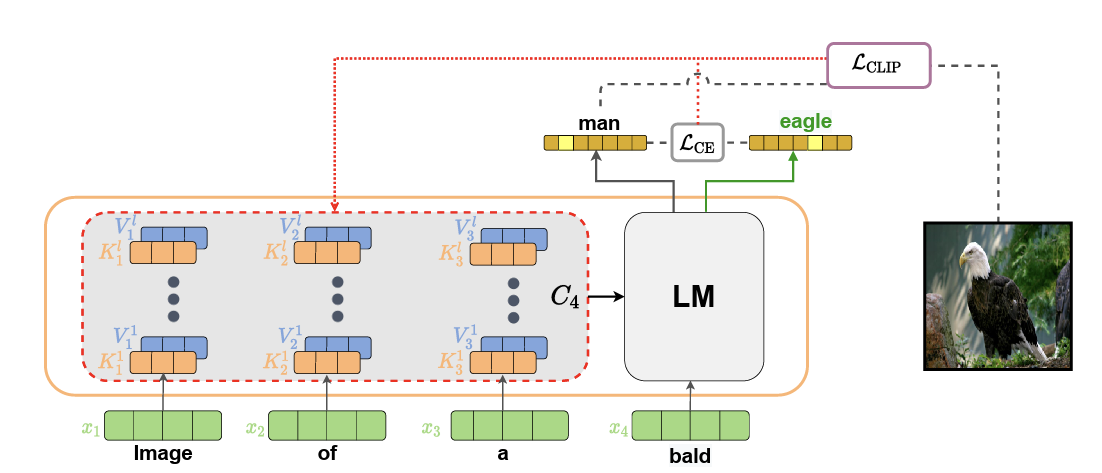
위에서 LM은 Language Model을 뜻하고, 여기서는 GPT-2를 사용했다. freeze 된 GPT-2를 사용해 이전 token들에 기반해 다음 token을 예측하게 된다. 예시에서는 Image, of, a, bald를 가지고 다음에 올 token을 예측하는 것이다. 사진에는 나오지 않았지만, GPT-2는 다음 token의 후보들을 확률에 기반에 뽑고, 가장 확률이 높은 값이 다음 token이 된다. 여기서 CLIP이 들어오게 된다. 을 이용해 이미지에 맞는 문장이 생성되는지에 대한 quality check를 하게 된다.
quality check라는 것을 별게 아니고, 이미지와 가장 높은 확률의 token이 잘 align 되어 있는지 확인하는 과정을 의미한다. 먼저, visual feature들을 고정시켜 놓는다. 그리고 GPT-2로부터 생성된 text를 CLIP의 text encoder에 넣는다. 이렇게 생성된 text feature를 visual feature와 비교한다. 만약 이미지와 text의 align이 잘 되어 있지 않다면, LM이나 CLIP의 parameter는 건들지 않고, context cache라는 것을 backprop을 통해 수정한다. 위의 사진을 보면 transformer의 구조에서 볼 수 있는 여러 개의 block들이 있다. 한 단어 한 단어 생성할 때마다 임의의 는 반복해서 쓰인다. 따라서 이들은 context cache에 넣어놓고, 이전의 의 embedding output을 추적하는데 사용할 수 있다. 따라서 backprop에 의해서 수정되는 것은 이 context cache이다.
Loss function으로는 , 즉 cross entropy loss를 사용하며, 다음에 나올 token의 distribution을 유지하기 위한 목적으로 사용된다. 구체적인 optimization 식은 이다. 는 image-text alignment를 위한 Image Correspondence term을 의미하고, 는 기존 language model의 distribution 유지를 위한 Language Fluency term을 의미한다. (: context, : 주어진 이미지, : Original distribution)
이렇게 학습을 하면, 아래와 같이 개선된 OCR 능력과 다양한 텍스트를 생성하는 zero-shot 결과를 얻을 수 있다.

4) Image Captioning (2) - StyleCLIP : Text-driven manipulation of StyleGAN imagery
ZeroCap에 이어 pre-trained CLIP을 이용하는 두 번째 Image Captioning model이다. 이 모델은 text를 입력 받아, 제공된 text에 맞게 이미지를 변형시키는 task를 다룬다. 모델을 자세히 살펴보기에 앞서 StyleGAN에 대해서 간단히 알아보자. StyleGAN은 GAN Architecture를 가지는, image의 style을 변화시켜주는 모델이다.

위의 사진과 같이, input image를 text에 맞게 변화시켜주는 것을 볼 수 있다. 이제 모델의 구조에 대해서 자세히 알아보자.
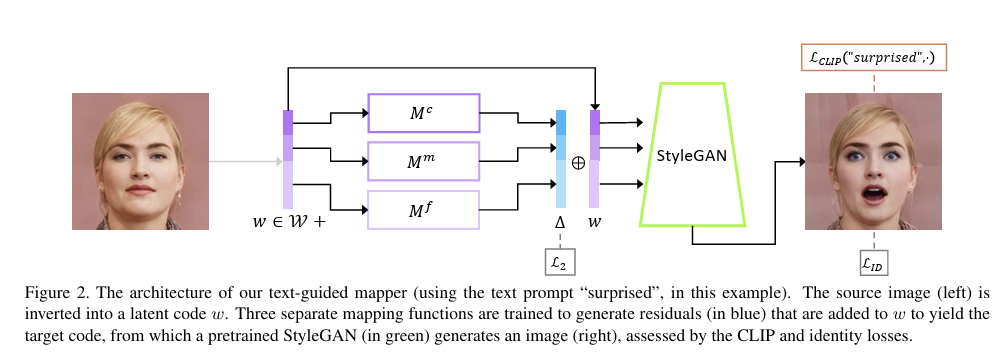
StyleCLIP의 구조는 위의 사진과 같다. mapping network(위의 구조도에서 StyleGAN을 제외한 모든 구조가 mapping network이다.)라는 구조가 등장한다. mapping network는 특정한 text prompt를 위해 훈련된다. text에서 제공하는 특성을 이미지에 반영함과 동시에 이미지의 기존 특성들을 보존할 수 있게 해준다. 먼저, input image를 latent code w로 변환한다. 그리고 구조도 상에서 파란색 벡터인 residual vector를 생성하기 위해 세 개의 mapping function들인 을 훈련한다. residual vector가 생성되면, w에 residual vector를 더해주고, 이를 pretrained StyleGAN에 전달해 text의 특성에 맞게 변환된 이미지가 생성된다. 은 변형된 이미지와 text prompt간의 cosine similarity를 최소화한다. 정확히는 CLIP의 text encode를 타고 나온 text feature와 StyleGAN의 visual feature 간의 cosine similarity를 계산하는 것이다. 는 pretrained face recognition model에 의해 계산되는 loss로, 기존 인물의 identity가 변하지 않고 text에서 언급된 특성만 변형될 수 있게 해준다. 마지막으로 는 mapping network output을 norm을 최소화하는 것으로, 기존 이미지의 특성이 보존될 수 있도록 해준다. 위의 예시는 얼굴들에 대해서만 결과값을 보여줬으나, 얼굴 이외의 것들에도 좋은 성능을 보여준다.

지금까지 본 모델들의 장점을 정리해보자. 먼저 추가적인 data가 필요 없다. 비용적인 측면에서 봤을 때 이는 엄청난 장점이다. 또, zero-shot으로 inference를 진행하기 때문에 test-time optimization만 하면 된다. 추가적인 training이 필요 없기 때문에 꽤나 경제적이다.
추가로, 상황 상 생략하지만 3D avatar에 pretrained CLIP을 적용한 CLIP-Actor라는 모델도 있다.
5) ImageBIND - One Embedding Space to Bind Them All
ImageBIND는 6개의 modality를 합쳐 하나의 joint embedding을 학습하기 위한 방법을 제시한 논문이다. image, text, audio, depth, thermal, IMU data 6개의 modality를 다룬다.

먼저 text와 image를 align 한 후 나머지 modality들을 학습한다는 점 말고는 CLIP과 유사하다. Loss function을 한 번 살펴보자. 이미 align된 pair를 이라고 하자 (는 Image, 은 다른 modality를 의미). 먼저 각 modality를 normalized embdiing으로 encoding한다. 식으로는 로 표현할 수 있다. 그리고 InfoNCE loss를 이용해 joint embedding을 최적화한다. ()

이렇게 ImageBIND를 이용하면 여러 가지 분야에서 적용이 가능하다. 위의 사진의 1번에서처럼 여러 modality를 이용해서 text를 생성하는 것이 가능해지는 것도 대표적인 예시이다.
4. Cross-modal Translation
cross-modal translation은 하나의 modality를 다른 modality로 번역하는 것이다. text나 sound를 image나 text로 바꾸는 것이 대표적인 cross-modal translation의 예시이다.
1) Text-to-Image Generation - DALL-E 2
text-to-image generation 분야에서 대표적인 모델인 DALL-E 2에 대해 알아보자. 이 모델은 CLIP과 diffusion 모델들을 이용해 text to image generation task를 다루었다.

CLIP을 미리 학습해놓고, diffusion model을 나중에 연결하는 모듈 방식의 접근을 보여준다.
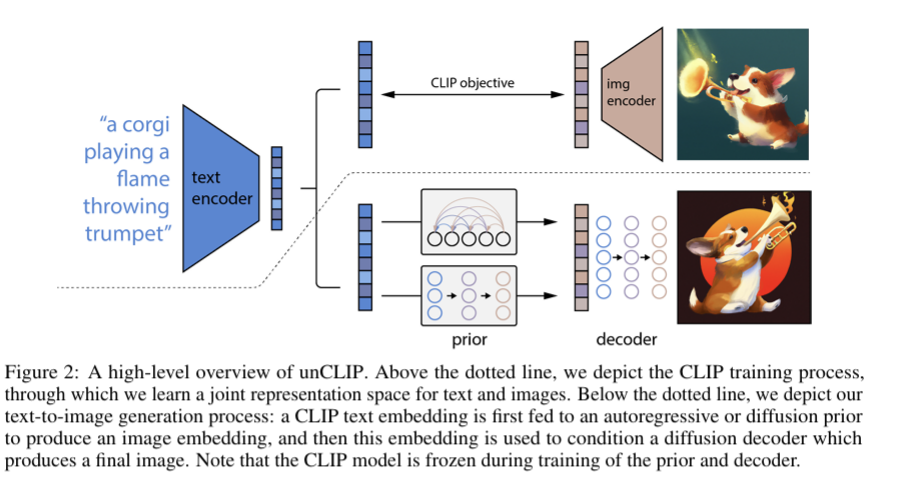
더 자세히 다루지는 않고, 이 정도까지만 하고 넘어가려고 한다.
2) Sound-to-Image synthesis
또 하나의 task는 소리로부터 이미지를 생성하는 것이다. 
이렇게 소리만으로 좋은 퀄리티의 사진들을 얻을 수 있다. Sound-to-Image는 전에도 언급했지만 어려운 task이다. 소리에 outlier가 있을 수도 있고, 기본적으로 audio와 visual이 가지는 modality의 gap이 존재하기 때문이다. 특히 소리는 들리는데 영상에서는 안 보이는 것의 경우, 모델 성능을 떨어뜨리는 원인이 될 수 있다.
3) Speech-to-Face synthesis
여러 task들을 보았지만, 가장 흥미로웠던 task이다. 목소리로부터 사람의 얼굴을 matching하는 기술이다. 아래의 사진은 speech to face 모델 중 하나인 Speech2face의 구조도이다.
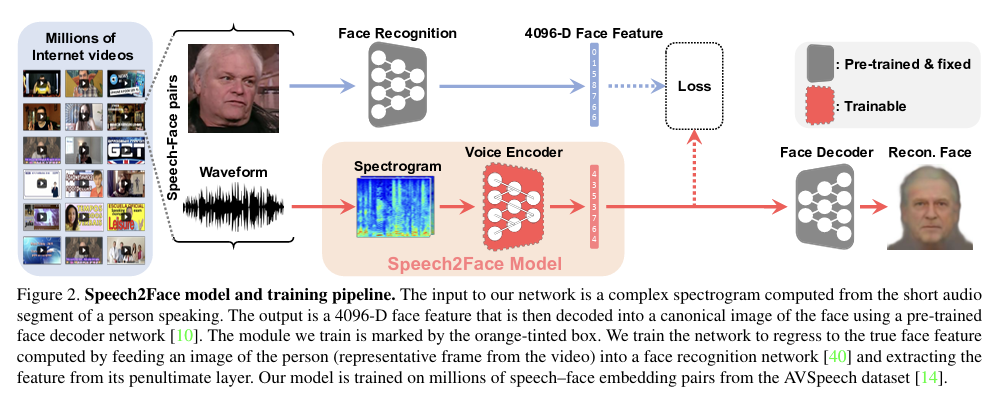
4) Image-to-Speech synthesis
Image-to-Speech synthesis는 말 그대로 image로부터 speech를 합성해내는 task이다. 자세한 내용은 생략한다.
5. 정리
이번 글에서는 Multi-modal Learning의 Feature Representation부터 다양한 modality들의 특성, 그리고 여러 가지 task들에 대해서 살펴봤다. 중요한 것은 어려워보이는 task도 문제를 쪼개서 module based approach를 적용했을 때 굉장히 효과적이었다는 것이었다. input modality와 output modality를 연결시켜주는 decoder를 잘 학습하는 방식같이 말이다.
multi-modal learning은 정리하면서도 느꼈지만, 내가 익숙한 CV보다는 훨씬 다양한 task들이 존재하고, 그만큼 공부량도 많이 차이가 날 것 같다는 생각이 든다. 내가 관심이 가는 task를 차근차근 찾아보는 것이 중요할 것 같다. 다음 글은 Multi-modal Learning 2편이 될 것이다.
