Naver AI Tech
1.Naver AI Tech 7기 합격 후기

군대 문제 때문에 어쩔 수 없이 2024년 3월부터 휴학을 하게 되었다. 의미 없이 시간을 보내기엔 너무 아깝기도 하고, 전공 지식 또한 부족한 편이기 때문에 1년을 잘 보내기 위한 계획을 세웠다. 일단 내가 관심 있어하는 CV 분야의 기초가 없었기 때문에
2024년 8월 5일
2.네이버 AI Tech 이후의 계획

기존의 계획은 네이버 부스트캠프를 하면서도 꾸준히 블로그에 기록을 남기려고 했으나, 정신이 없어 급한대로 노션에만 정리를 하고 넘어가게 되었다. 이제 부캠이 끝난만큼, 이후의 계획을 세워야 할 필요성을 느꼈다. 개인 사정으로 인해 지금부터 1달의 계획만 세우고,
2025년 2월 19일
3.Multi-modal Learning (1) - Multi-modal Feature Representation
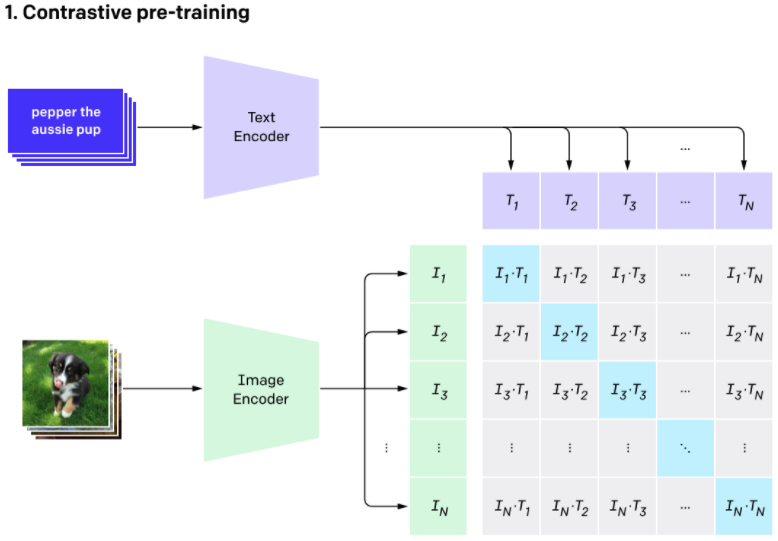
    AI Tech 이후는 최신 기술들에 대해 알아보기로 했다. 여러 분야가 있지만, 내가 관심이 특히 더 많이 갔던 Multi-modal Learning이다. 그래서 Multi-modal에 대한 논문들을 읽기 전에, 대략적인 개요를 먼저 살펴보려고 한
2025년 3월 15일
4.Multi-modal Learning (2) - Vision-Language Models

    이전 글에 이어서 Multi-modal learning에 대해서 살펴보려고 한다. 특히 이번 글은 VLM(Vision-Language Model)에 집중한다. 1편 글은 아래 링크를 타고 가면 된다. Multi-modal Learning (1) -
2025년 3월 18일