이전 글에 이어서 Multi-modal learning에 대해서 살펴보려고 한다. 특히 이번 글은 VLM(Vision-Language Model)에 집중한다. 1편 글은 아래 링크를 타고 가면 된다.
Multi-modal Learning (1) - Multi-modal Feature Representation
1. VLM (Vision-Language Model)
1) Toward AGI (Artificial General Intelligence)
인간의 cognition(인지)는 perception(지각)과 higher cognitive process로 이루어져 있다. AI에서 perception에 대한 연구는 많이 진행되었고 어느 정도 발전이 되었지만, cognition에 대한 부분은 어려움이 많았다. 그러던 중 LLM이 등장하며 연구자들은 확률 기반이지만, 나름의 사고가 가능한 LLM으로 cognition에 대한 문제들을 해결해보려고 노력했다. 그러나 LLM만으로는 실제 세계와 상호작용하고 세상을 이해하기 어려웠다. 그래서 연구자들은 LLM의 눈과 귀가 될 수 있는 Multi-modal interface를 연구하기 시작했다. 그 중에서 눈을 달아준 것이 Vision-Language Model인 셈이다.
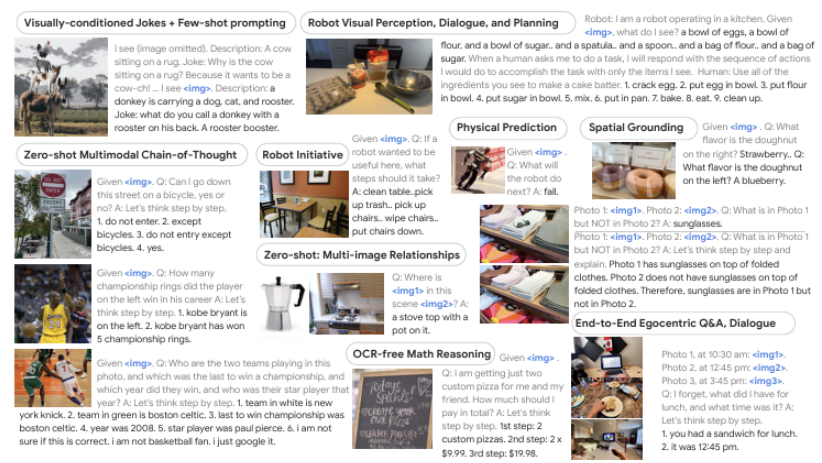
VLM은 활용도가 굉장히 높다. 예시의 사진은 PaLM-E라는 모델인데, OCR, 현재 상황에 대한 QA 등 다양한 곳에 쓰이는 것을 볼 수 있다. 이와 같이, 인공지능이 점차 General한 지식을 가지며 인간과 유사한 지능을 가지는 AGI오 관련된 연구가 활발히 진행되고 있다.
2) Early Vision-Language Models
Multi-modal을 다룬 첫 번째 글에서 각 modality의 feature space를 어떻게 사용하냐에 ㄸ라 matching, translating, referencing으로 나눌 수 있다고 언급했었다. VLM은 이 중에 modality끼리 서로의 데이터를 참조하며 reasoning 하는 referencing에 해당한다. VLM의 경우, visual data와 text data가 서로 참조하면서 reasoning을 하는 상황이 만들어질 것이다.
i) Show, attend and tell
첫 번째로 살펴볼 논문은 "Show, attend and tell"이다. Transformer의 self-attention이 나오기 전, attention이라는 개념이 처음 등장한 논문들 중 하나이다. 주어진 이미지에 대해서 중요한 부분을 참고해 caption을 생성하는 모델이다.

논문에서 제시한 예시들을 보면, 이미지 내의 caption 생성에 중요한 부분을 참고하는 것을 볼 수 있다. 모델의 구조를 자세히 살펴보자.
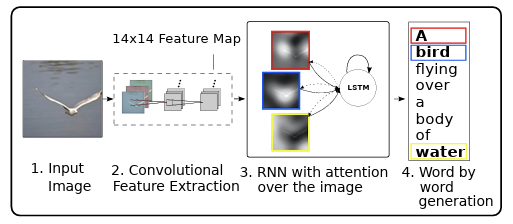
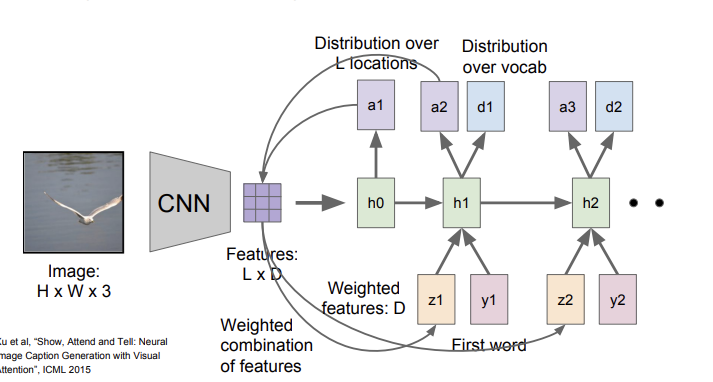
먼저 input image가 들어오면, CNN을 이용해 feature를 뽑는다. 그리고 LSTM을 사용해 attention map과 단어 단위의 generation을 한다. 아래 사진에서 a는 이미지의 어떤 부분에 집중하면 좋을 지 알려주는 attention map을 의미하고, h는 LSTM의 hidden state, d는 단어들의 분포를 의미한다. 또, z는 weighted feature를, y는 word token을 의미한다. 여기서 weighted feature란 의 식을 가지고 계산되는, CNN의 feature 와 attention map 의 weighted sum을 의미한다. 이렇게 계산되는 는 이전에 생성된 단어와 함께 그 다음 hidden state의 input으로 주어지고, hidden state는 attention map과 단어 분포를 생성한다. 이런 식으로 단어 단위의 generation이 이루어지는 것이다.
ii) Transformer: Attention is All You Need
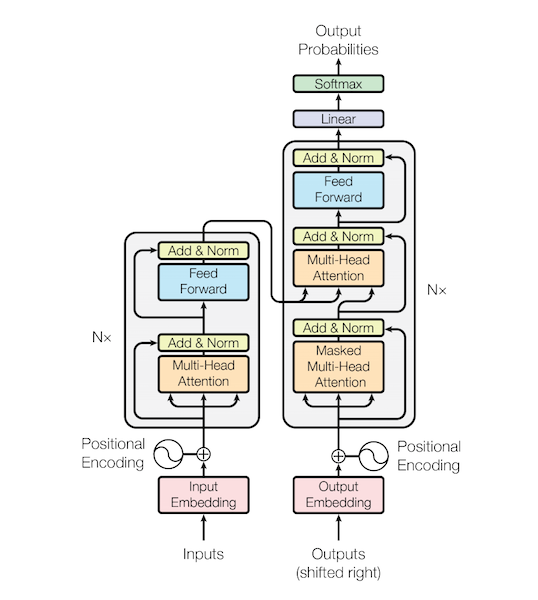
다음으로 살펴볼 모델은 굉장히 유명한 transformer이다. Show, attend and tell에서 사용된 RNN 기반의 모델이나 CNN을 사용하지 않고, self-attention mechanism을 사용한 것이 포인트다. Show, attend and tell에서 사용한 attention이 implicit하게 들어있는 것이다. Self-attention을 사용함으로써 Long-term dependency 문제를 해결했다. 현재는 text뿐만 아니라 vision이나 다른 분야에도 많이 사용되는 architecture이다.
iii) Flamingo : a Visual Language Model for Few-Shot Learning
다음은 transformer 이후에 나온 Flamingo라는 VLM이다. 모델에게 우리가 수행하고 싶은 task에 대한 few-shot (image, text) pair를 주고, 우리가 output을 얻기를 원하는 text를 주면, 모델이 답을 해주는 형식이다. 논문의 저자들은 아래와 같은 예시를 보여준다. 사진을 보면 Input Prompt에 3개의 열이 있는데, 왼쪽 2개의 열이 few-shot example이다. 이를 모델에게 알려주고 왼쪽에서 3번째 열에 이미지와 약간의 text를 제공하면, 모델이 text를 완성해주는 형식인 것이다.

이제 Flamingo의 구조를 살펴보자.
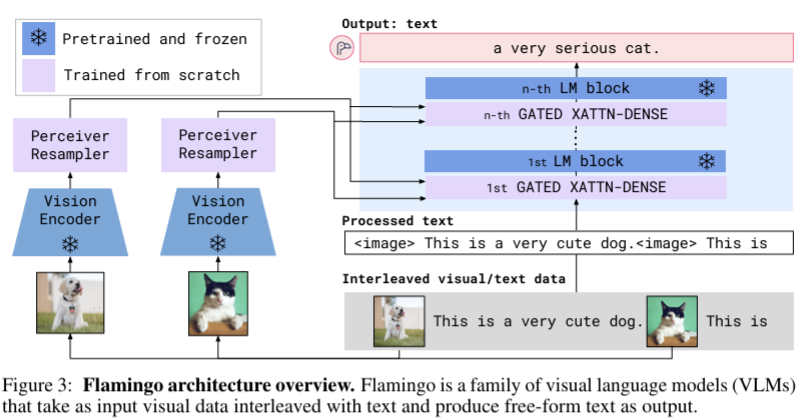
위 사진에서 연보라색 layer는 learnable layer, 파란색은 pre-train 후에 freeze 해 놓은 layer들을 의미한다. 또한, 사진 상의 LM은 Chinchilla이다. 먼저, visual data, 즉 image에 대한 처리를 살펴보자. text-image pair 중에서 image를 강력한 visual encoder(freeze 상태)에 넣어 visual feature를 얻는다. 그런데 여기서 문제가 생긴다. Visual feature들은 가변적이다. 이미지의 크기에 따라 feature의 크기가 바뀔 수도 있기 때문이다. 따라서 논문의 저자들은 perceiver resampler를 통해 fixed size visual token을 만들어준다. 여기에서도 self-attention이 사용된다. 그리고 나서 이를 LM에 전달하게 된다.
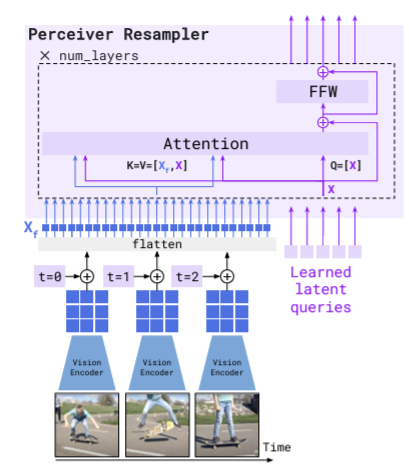
위의 사진은 Perceiver resampler의 구조도이다. 주목해서 볼 부분은 Learned Latent Queries이다. 정해진 개수만큼 query를 할당하고, 이를 학습한다. 이러한 과정을 통해 video나 다양한 크기의 가변적인 image들을 다룰 때, 이들의 input size와 관계없이 항상 같은 크기의 token이 출력하는 것이다.
이제 text data의 처리를 알아볼 차례이다.
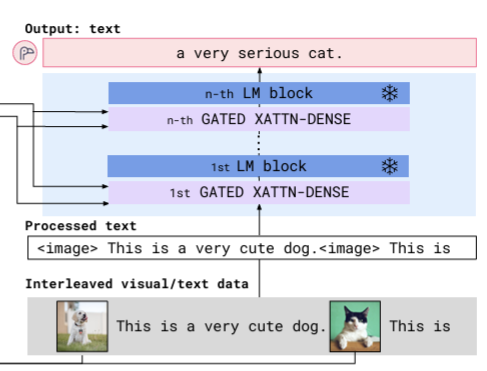
여기서 특징적으로 볼만한 부분은 Gated Cross attention Layer이다. (위 사진에서 GATED XATTN-DENSE로 표기되어 있음.)
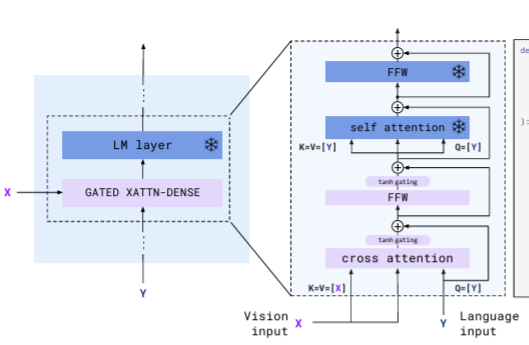
하나의 block의 내부를 보면 위의 사진과 같다. 기존의 LM layer는 사진에서 핑크색 부분을 제외한 부분이었다. 우리가 흔히 아는 Self-attention + FFW 의 조합이다. flamingo는 기존 layer들은 freeze하고, 이 사이사이에 learnable한 cross-attention layer를 끼워넣는 방식을 채택했다. perceiver resampler를 통해 얻은 visual feature와 language(text) input이 cross atttention layer의 input으로 들어가게 되고, 이후 FFW layer를 거친다. 구조도를 자세히 보면 tanh gating layer가 있다. 이 layer는 0으로 초기화하는데, 이는 visual feature와 language feature가 잘 섞이도록 하기 위해서이다. tanh layer를 0으로 초기화하면, 학습 초기에는 visual feature의 영향이 전혀 없다. skip connection으로 language input만 더해지기 때문이다. 학습이 진행되면서 tanh가 update되고, 서서히 visual feature도 학습에 영향을 주기 시작한다. 이렇듯 tanh는 서서히 visual feature가 흘러 들어오도록 유도하는 역할을 한다.
학습 결과, Flamingo는 아래 사진처럼 Multi-image visual dialog와 같은 task도 수행 가능하다. cross-attention을 통해 적은 data로 빠르게 학습할 수 있는 VLM이라는 점, 일부 layer만 learnable하게 만들어 경제적이고 adapting에 유용하다는 점이 Flamingo의 장점이다.

2. LLaVA : Large Language and Vision Assistant
1) LLaVA overview
다음으로 살펴볼 모델은 LLaVA이다. LLaVA는 이미지가 주어졌을 때 이에 대한 discussion이 가능한 visual-reasoning model로, 간단하지만 강력한 구조를 가지고 있다.

2) Feature Alignment (Projection)
LLaVA의 구조는 아래와 같다.

Vision Encoder와 Language model이 있는 것은 이전 모델들과 비슷하지만, visual encoder에서 뽑은 visual feature들을 token으로 변환해주는 projection layer가 추가 된 것이 특징이다. training은 크게 2개의 step으로 구성된다.
3) Visual Instruction Tuning
step 1에서는 language model과 vision encoder는 freeze 해놓고, projection layer만 학습한다. 이때, Projection layer 훈련에 사용하는 데이터는 GPT를 이용해 생성한다.

MSCOCO 이미지와 caption, bounding box들이 GPT에게 제공되고, 이를 이용해 GPT는 conversation, detailed description, complex reasoning 3가지의 response를 생성한다.
Step 2에서는 vision encoder만 freeze하고, language model과 projection layer는 훈련시킨다. step 1에서 projection layer를 학습하고 나서 진행하는 일종의 fine-tuning이라고 볼수도 있다. visual data와 language data를 동시에 이해할 수 있도록 하기 위해서 language model도 fine-tuning한다.
3. InstructBLIP : Towards General-purpose Vision-Language Models with Instruction Tuning
1) InstructionBLIP Overview
이번 모델은 InstuctBLIP이라는 모델이다. LLaVA와 유사한 디자인을 가지고 있는 것이 특징이다.
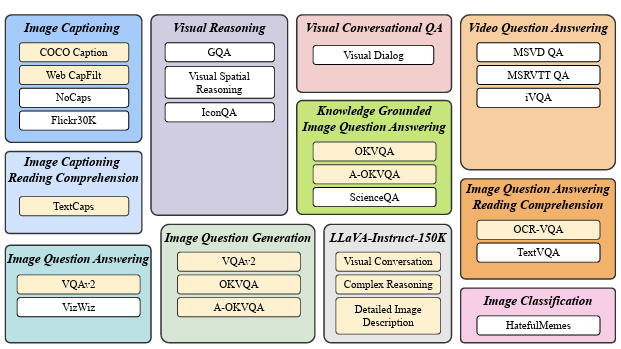
InstructionBLIP은 다양한 VQA와 captioning task에 맞게 훈련이 이루어진다. 크게 보면 이미지가 주어졌을 때, 그에 대한 discussion을 하는 task라고 생각할 수 있다.
2) Feature Alignment (Q-Former)
이제 InstructionBLIP의 모듈 네트워크들에 대해 알아보자. 특히 Q-former가 집중적으로 살펴볼 만한 포인트이다.
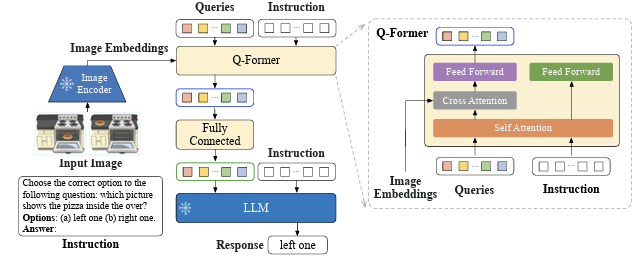
위에서 LLaVA와 비슷한 구조를 가지고 있다고 했는데, LLaVA의 Linear Projection layer가 InstructionBLIP의 Q-former와 유사한 역할을 한다. 모델의 input으로 image embedding과 instruction이 들어가고, 마지막에 LLM을 통한 response가 나오는 구조이다. Image Encoder는 pre-train 후 freeze해서 사용하는데, input image로부터 image embedding을 뽑고 이를 Q-former에 전달하게 된다.
다음은 visual feature와 text token을 연결하는 모듈인 Q-former를 보자. Q-Former의 input으로 Learnable Query(사진에서의 Queries)와 Instuction을 받고, output으로 fixed length query를 뱉는다. Q-Former의 주요한 역할은 image embedding을 LM이 이해할 수 있는 token으로 변환하는 것이다. 사전에 정의되어 있는 개수만큼 사용해 fixed length output으로 나오게끔 유도한다는 점이 Flamingo의 perceiver와 유사하다. 그러나 Q-Former는 Instruction을 추가로 사용해 instruction과 연관이 높은 visual feature를 변환해서 넘겨주도록 설계했다는 점은 다르다.
이렇게 fixed length output을 얻고 Fully Connected Layer에 통과시켜 LLM이 이해할 수 있는 형태로 visual token들을 변환하게 된다. FCL을 타고 나온 output query들을 Instruction과 concat 시킨 후 pretrained & frozen LLM에 넣어주고, response를 얻는다.

위의 사진에서 우측의 Q-Former 내부 구조를 보면, Learnable Query와 Instruction이 Self-Attention Layer를 통과하며 instruction에 condition된 output query를 얻게 된다. 이 query가 cross-attention layer를 통과하며 query가 자신이 집중해야 부분이 어디인지에 대한 정보를 학습하게 된다.
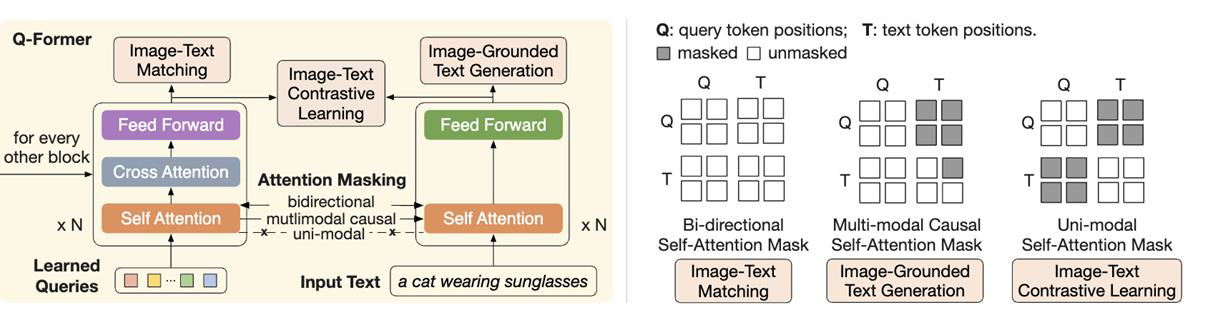
이 사진은 BLIP-2에서 나온 구조도인데, Q-Former 이해에 많은 도움을 준다. 정확히 Instruction과 Image feature가 언제 섞이는지에 대한 정보를 확인할 수 있다. 가장 왼쪽의 Image-Text Matching은 Bi-directional 과정으로, visual feature와 text token의 정보가 공유된다. Image-Grounded Text Generation은 text에 집중하지만, 이미지에 대한 정보도 어느 정도 있는 asymmetric masking을 사용한다. visual feature에 대한 정보가 text로 넘어올 수 있게 설계한 것이다. 마지막으로 Image-Text Contrastive Learning은 text는 text끼리, visual은 visual feature끼리만 self-attention을 진행한다. 이렇게 독립적인 feature를 얻고 contrastive learning을 진행하기 위함이다.
3) Variations of InstructBLIP
InstructionBLIP의 다양한 형태가 존재하는데, X-InstructionBLIP도 그 중 하나이다.

어떠한 Modality라도 받을 수 있도록 설계한 것이 특징이다.
4. Other Visual Reasoning
지금까지 살펴본 모델들은 어느 정도 공통된 패턴이 존재한다. pre-trained & frozen image encoder를 이용해 image feature를 뽑고, text와의 정보를 유기적으로 연결하기 위해 adapter를 학습하는 패턴이었다. 이제부터 살펴볼 모델들은 이러한 패턴과는 다른 방식으로 설계되었다.
1) Visual Programming : Compositional visual reasoning without training
Visual Programming은 제공된 이미지를 텍스트에 맞게 바꾸려면 어떻게 분해하고 재합성하면 좋을 지에 대한 절차를 계획하고, 이를 프로그래밍하는 방법론을 제안했다.

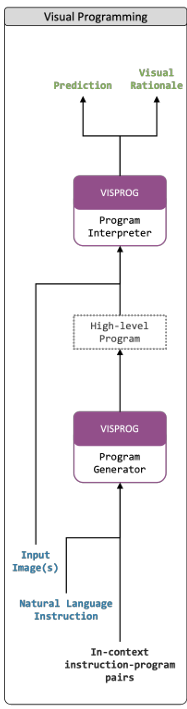
LLM으로는 GPT-3를 사용하는데, 추가적인 학습은 하지 않는다. Instruction과 in-context instruction-program pair를 GPT에 input으로 주고, GPT는 이를 바탕으로 프로그램을 생성한다. 여기서 input image를 condition으로 제공하고, Program interpreter를 통해 결과를 얻는다.
위에서 언급되는 In-context learning은 example을 통해 task가 어떻게 수행되는지에 대한 정보를 제공하고, 이후에 우리가 해결하고 싶은 문제에 대한 prompt를 주면, 알맞은 response를 내는 방식이다.

Visual Programming에서는 in-context learning이 아래와 같이 진행된다.

핑크색의 텍스트처럼 program의 예시를 주고, 파란색의 텍스트와 같이 내가 수행하고 싶은 task에 대한 instruction을 준다. 그러면 GPT-3를 통해 문제를 해결하는데 필요한 프로그램이 출력되는 것이다.
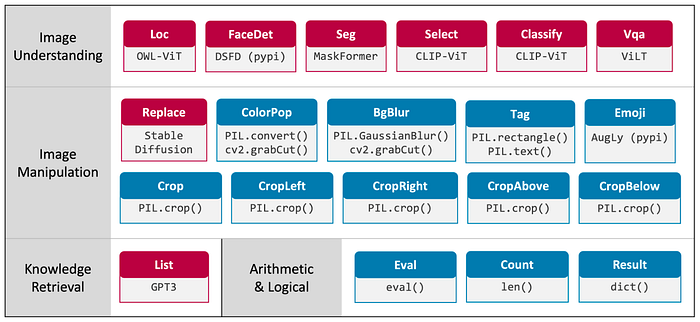
프로그램이 출력될 때는 위의 사진처럼 미리 정의된 라이브러리들을 사용한다.
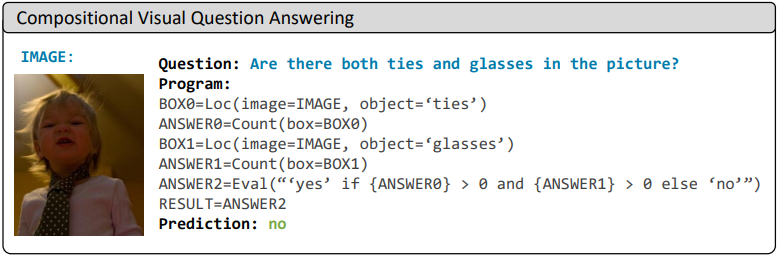


Visual Programming을 사용하면 위의 예시들과 같이 다양한 task들이 가능하다.
2) PaLM-E : An Embodied Multimodal Language Model
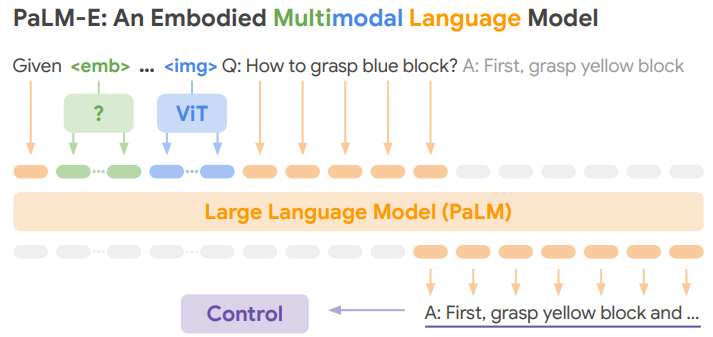
PaLM-E를 사용하면, text generation 후 robot 제어를 위한 signal로 변환하는 것 또한 가능하다. 이와 같이 로봇을 위한 agent 개발이 앞으로 유망할 것으로 예측된다고 한다.
