1. 5강 복습
지난 강의들에서 배운걸 총 복습해보자. 이제까지 식을 분리해서 computational graph를 그리는 법, 그리고 거기서의 back propagation에 대해 배웠다. 그 이후 Neural Network와 CNN에 대해서도 배웠다. CNN은 실제 input size보다 작은 필터를 모든 공간에 대해 돌려 output을 얻는 방식이었다. 이때 주의해야 할 점은 이 필터의 depth와 input의 depth는 같아야 한다는 것이다. 이 필터를 여러 장 추가할 수도 있는데, 필터 하나당 하나의 activation map을 얻는다. 그리고 Mini Batch SGD에 대해서도 배웠다.
2. Overview
이번 강의에서는 Training Neural Network라는 주제에 대해 다룬다. Activation function의 종류, data preprocessing, weight initialization, batch normalization, babysitting the learning process, hyperparameter optimization 순으로 살펴보자. 양이 진짜 역대급으로 많다...
3.Activation Function
Activation Function은 input의 weighed sum을 한 후, 우리가 원하는 신호들만 얻고, 나머지 관심 없는 부분을 죽이기 위해 사용하는 식이다. weighted sum에 nonlinearity를 적용해주는 부분이기도 하다. 종류는 Sigmoid, ReLU, tanh, ELU 등이 있다.
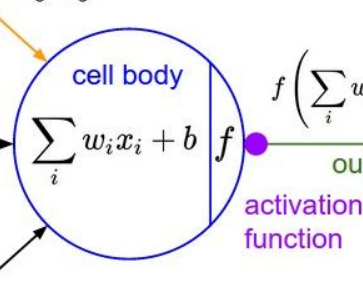
먼저 짚고 넘어가야 할 부분이 있다. 우리가 흔히 computational graph에서 사용하는 unit, 혹은 neuron은 input의 weighted sum에 activation function까지 계산한 것을 나타낸다. 그렇기 때문에 neuron에서 나오는 output은 activation까지 끝내고 나오는 것이다. 이 두 단계(weighted sum, activation function)를 구분하기 위해 보통 뉴런의 원 모양을 반으로 나누어서 사용한다. 아래 사진에서도 보면, 원의 왼쪽 부분은 weighted sum, 오른쪽은 activation function을 나타내고 있다. 이제 본격적으로 여러 activation function들을 살펴보자.
1) Sigmoid
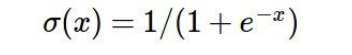
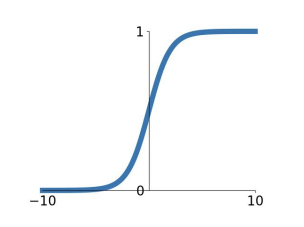
위의 식과 그래프가 sigmoid function이다. sigmoid는 weighted sum이 들어오면, [0,1] 범위 사이로 rescaling 해준다. x값이 크다면 1 근처로 갈 것이고, 작다면 0 근처로 가는 것이다. 그런데 sigmoid의 문제가 세 가지 정도 있다.
i) saturation problem (vanishing gradient): 앞으로 나올 대부분의 activation function들의 공통된 문제점이기도 하다. x가 너무 크거나 너무 작은 경우, 기울기가 0이 된다. 이 구간들을 saturated 되었다고 표현한다. 기울기가 0에 가깝기 때문에, gradient descent 시 update가 제대로 이루어지지 않는 상황이 나타난다. 이를 vanishing gradient problem 이라고 표현하기도 한다.
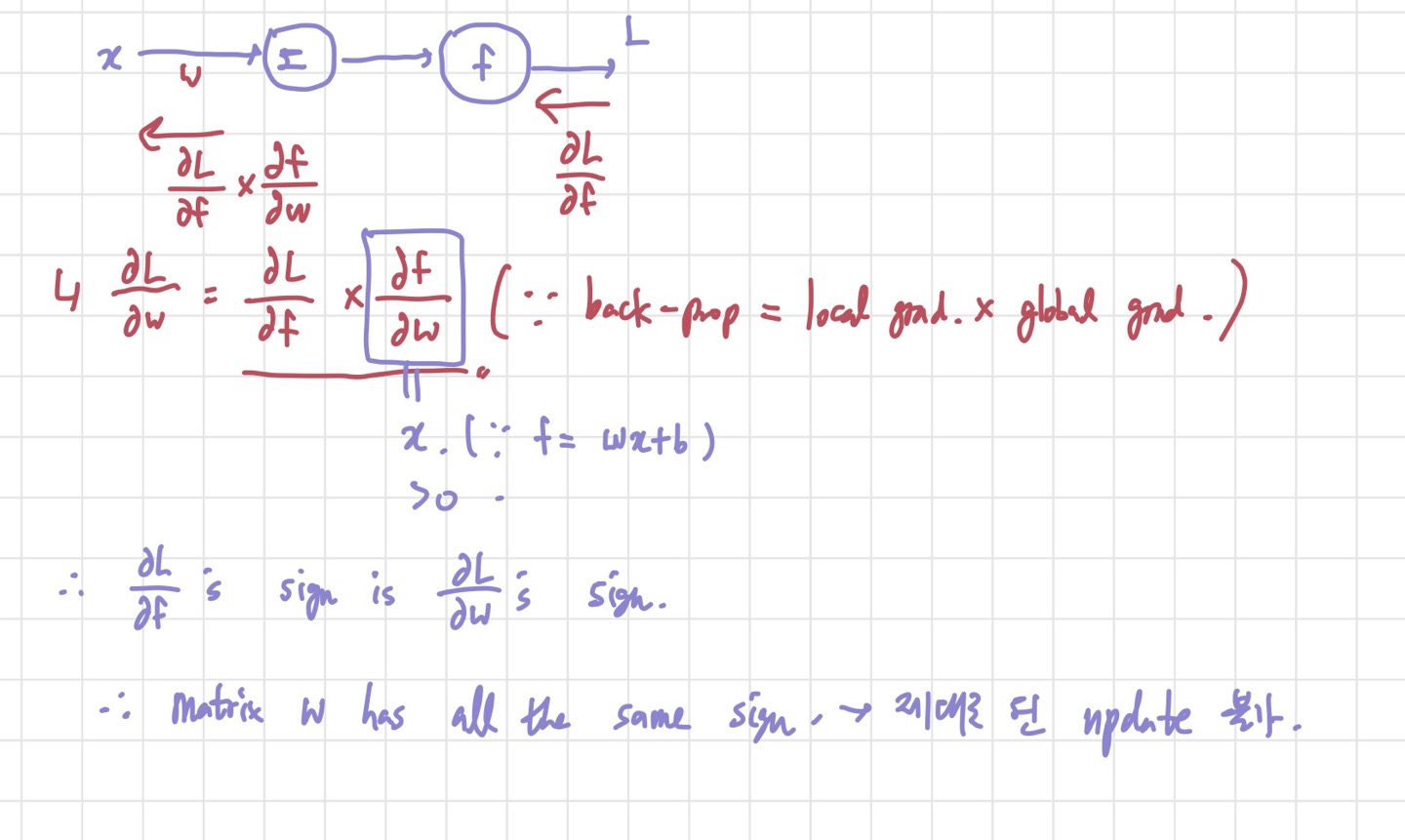
ii) output이 zero centered 되어 있지 않다:
뭐가 문제냐고 생각할 수 있지만, 이것도 결론적으로 update가 제대로 이루어지지 않는 원인으로 작용할 수 있다.
input의 모든 원소가 다 양수인 경우를 생각해보자. 그렇다면, forward pass가 다 끝나고 back propagation을 할 때, df/dw(여기서 f는 weighted sum을 뜻한다.)가 x이므로, dL/dw의 부호는 dL/df의 부호에 의해 결정되게 된다. dL/df는 양수 혹은 음수 모두 될 수 있기 때문에 w 행렬을 구성하는 원소들은 모두 양수이거나 모두 음수가 된다. 그러면 굉장히 비효울적인 update가 이루어진다. W 내의 모든 원소들이 + 방향 혹은 - 방향으로 같이 움직이기 때문이다. 이를 방지하기 위해 애초에 input을 zero mean data로 만든다면, w에 양수와 음수가 고루 존재하니 update가 비교적 잘 이루어질 수 있을 것이다.
iii) exp 연산이 비용이 많이 든다. - 이건 그렇게 큰 문제는 아니다.
이라는 것도 알아두면 좋다. 시그모이드의 미분을 시그모이드 함수만을 이용해서 나타내는 방법이다.
2) tanh(x)
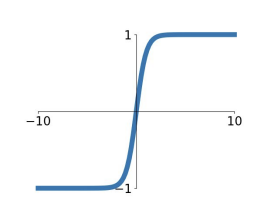
tanh도 sigmoid와 비슷한 형태이지만, 범위 [-1,1] 사이로 rescaling 해주고, output이 zero- centered라는 장점이 있다. 단 여전히 위에서 언급한 saturation problem은 여전히 존재한다. 의 관계성을 갖고 있기도 하다.
3) ReLU(Rectified Linear Unit)
ReLU의 식은 로 나타낼 수 있다. 가 음수라면 0이 나오고, 양수면 그대로(기울기가 1이다) 나오는 것이다.
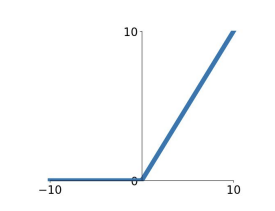
그래프를 그려보면 이렇다. 장점으로는 양수 범위에서는 saturation problem이 없다는 것, 그리고 실전에서 수렴 속도가 앞의 2개의 activation function보다는 빠른 것, 계산적 복잡도가 다른 activation function보다 낮다는 것 정도가 있다. 반면 단점은 zero-centered output이 아니라는 것과, 음수 영역에서는 여전히 zero gradient를 가져 saturation problem이 생긴다는 것이다.
4) Leaky ReLU
ReLU의 단점(saturation)을 조금 보완한 것이 Leaky ReLU이다.
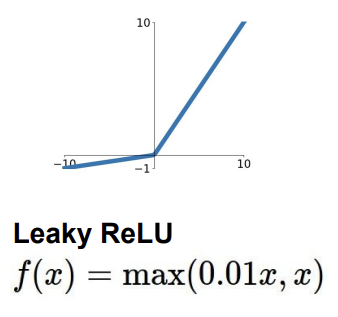
식과 그래프를 봐도 알 수 있듯이, 음수 범위에서 vanishing gradient 문제를 해결하기 위해 작은 기울기를 준 것이다. 이렇게 하면 saturation problem이 없어지게 된다.
추가로 PReLU도 있는데, 이는 로 표현할 수 있다. 기울기를 0.01로 고정하지 않아 Leaky ReLU보다 조금 더 유연한 계산을 할 수 있다는 것이 장점이다.
5) ELU(Exponential Linear Units)
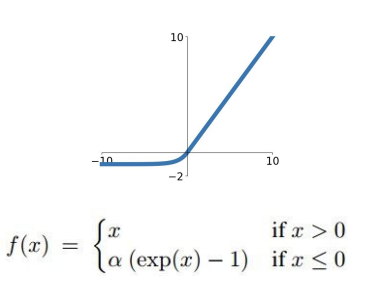
ELU는 ReLU의 장점을 가져오고, 음수일 때 exp 함수를 가져온 것이다. 위의 사진에서 알파도 hyperparameter이다.
6)Maxout
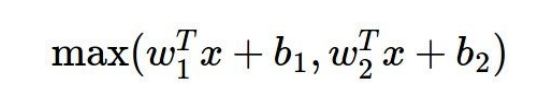
maxout은 이렇게 linear한 식 중에 최댓값을 뽑는 것을 말한다. saturation problem이 없다는 것이 장점이다. 그러나 계산량이 앞의 식들보다 많다는 것이 단점이다.
위의 식을 자세히 보면, Leaky ReLU와 ReLU의 generalized version임을 알 수 있다. ReLU의 경우, , 을 대입하면 얻을 수 있다. 이렇게 dying ReLU의 문제를 해결한 것이 maxout이다. 그러나 두 개의 식을 계산해봐야 하기 때문에 잘 계산량이 많다는 단점이 있다.
실전에서는 learning rate를 조심하며 ReLU를 사용하라고 한다. Leaky ReLu, maxout, ELU는 시도정도만 해보라고 한다. sigmoid는 거의 쓰이지 않는 추세이다.
어쨌든 대부분의 경우에 ReLU를 쓰는 것이 가장 좋은 결과값을 낸다고 한다.
**Normalization vs Standardization vs Regularization**
1) Normalization(정규화): 값의 범위를 0~1 사이의 값으로 rescaling하는 것.
ex)
2) Standardization(표준화): 값의 범위를 평균=0, 분산=1 이 되도록 변환.
3) Regularization(규제화): weight를 조정하는데 규제를 거는 법. ex) L1,L2...
실제로 딥러닝에서는 1~3의 표현 모두를 통틀어 정규화라고 부르기도 한다.
4. Data Preprocessing
Data Preprocessing(전처리)은 training을 할 때 가장 먼저 해야할 절차이다. 보통 zero-centered data로 만들거나 normalized data로 만든다. 머신러닝에서는 Normalization이 중요하지만, 영상 처리에서는 픽셀 값의 범위가 [0,255] 이기 때문에 굳이 normalization은 필요하지 않다. 그렇기 때문에 영상처리에서는 zero-centered data를 만드는 것에 집중한다. 이를 위해 평균 이미지를 input에서 뺀다거나, channel 별로(RGB) 평균을 구해 input 에서 빼는 방법 등이 있다. 비전 분야에서는 PCA나 variance normalization을 흔히 사용하진 않는다고 한다.
5. Weight Initialization
이제 weighted sum을 할 때 이용되는 값들의 초기화에 대해 알아보자. 어떤 값으로 초기화해야 할지에 대한 아이디어는 많을 수 있다. 강의에서는 weight를 다 0으로 초기화 할 경우부터 살펴본다. 결론은 하면 안된다고 하는데, 이유는 각각의 뉴런들이 다 똑같은 것을 배우기 때문이라고 한다. 즉, 뉴런 하나 가지고 결과를 도출하는 꼴인 것이다. weight를 다 똑같이 하면 똑같은 gradient를 갖게 되는 것이다. 그래서 다음으로는 크기가 작은 랜덤한 숫자들로 초기화하는 방법을 제안한다.

강의에서는 평균이 0인 가우시안 분포에서 무작위로 뽑는 방식을 제안한다. 그런데 숫자가 너무 작을 경우, network가 깊어질수록 문제가 되는 경우가 생긴다. weighted sum을 hidden layer를 지날 때마다 하는데, weight가 너무 작으면 계산을 거듭하며 intermediate output이 점점 작아지게 되고, 최종 output이 되기 전에 0으로 수렴할 가능성이 있기 때문이다. 이러면 back propagation 또한 제대로 할 수 없을 것이다.
이 문제를 해결하기 위해 위의 숫자보다는 조금 더 큰 weight를 무작위로 뽑아볼 수 있다.

이렇게 조금 커졌다. 이때의 문제는 (activation function이 tanh라고 가정했을 때), saturation problem이다. 실제로 논문을 보면 tanh의 결과값이 -1 혹은 1로만 나온다. 이때쯤 드는 생각이 '그러면 도대체 초기화를 어떻게 하라는 말인가?'이다. 그래서 강의에서는 위의 방법보다는 좋은 Xavier Initialization을 소개해준다.
6.Xavier Initialization
이것도 Weight Initialization의 일종이지만 중요해서 빼놨다.

일단 식은 이렇게 되는데, 가우시안 분포를 따르면서 (input, output) 크기의 행렬을 만든다. 그리고 그걸 input의 개수로 나누어준다. 이 식은 Neural Network에서 layer를 지날 때마다 input과 output의 분산을 같게 하려고 하다 보니 나온 식이다. 왜 input과 output의 분산이 같아야 할까? 분산이 안정되어 비슷한 크기를 가진다면, 앞에서 언급한 것 같이 vanishing gradient problem의 가능성을 작게 만들 수 있을 것이다. 그렇기 때문에 분산을 같게 만드는 것이 중요한 것이다. 식을 보자. 작은 랜덤 숫자들을 sqrt(input 개수)로 나눈다면 비교적 큰 weight들로 초기화 되는 결과를 얻을 수 있을 것이다.
Xavier Initialization은 sigmoid나 tanh에서는 좋은 효율성을 가지지만, ReLU에서는 성능이 조금 떨어지는 경향이 있다고 한다. 그래서 사용하는 것이 HE Initialization이다.
7. HE Initialization
엄청난 차이가 있는 것은 아니고, 위의 식에서 나눠주는 수 조금 바꾸면 된다.

8. Batch Normalization
우리는 가우시안 분포를 따르는 activation들을 원했다. BN은 activation들에게 바랄 것이 아니라, 우리가 직접 data에 관여해서 가우시안 분포를 따르게 하자는 취지에서 고안되었다. 현재 batch의 평균과 분산을 구해 훈련 처음부터 batch normalization을 취해준다는 뜻이다. 기본적인 식은 아래와 같다.

k는 각 차원을 뜻하는 변수이다. 차원별로 평균과 분산을 계산해서 normalization을 진행하는 것이다.
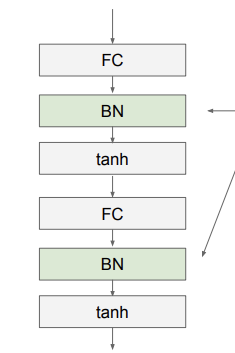
보통 activation function과 FC/CNN 사이에 BN을 진행한다고 한다. 그런데 여기서 더 유연하게 BN을 하려면 shifting parameter와 scaling parameter를 추가해 볼 수 있다.
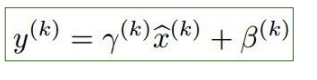
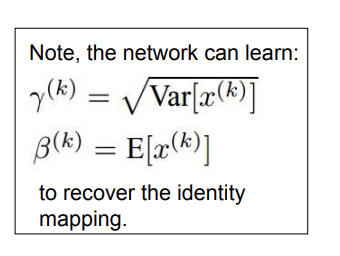
위의 식에서 감마가 scaling 값이고, 베타가 shifting 값이다. 이를 조절하면 satruration control에 용이하다. BN을 이용하면 tanh와 같은 activation의 경우 선형인 부분으로 input들을 강제하는 것으로도 볼 수 있다.
BN을 통해 gradient가 잘 통과될 수 있게 되고, 비교적 높은 learning rate 설정을 가능하게 한다. 그리고 초기화에 대한 의존도 또한 낮출 수 있다. 그리고 test set을 돌릴 때는 training 할때 사용한 평균과 분산을 사용한다고 한다.
9.Hyperparameter Optimization
다음은 내가 조정할 수 있는 파라미터인 Hyperparameter를 최적화하는 방법에 대해 다룬다. 들어가기 전에 learning process에서 알아낼 수 있는 정보들에 대해 소개하려고 한다.

위의 사진처럼 loss가 학습 과정에서 줄어들지 않는 경우, lr가 너무 작을 가능성이 있고, 반대의 경우도 마찬가지이다. 그리고 loss 값이 NaN으로 나오는 경우는 거의 대부분 너무 큰 lr 때문이라고 한다.
1) Cross validation + 범위 좁히기(?)
첫 번째 방법은 무작위 수로 초기화한 다음 cross validation을 해서 validation set에 대한 accuracy를 보는 것이다. 강의 슬라이드에서는 5 epoch 정도 돌려본 후 가장 성능이 좋은 파라미터 값들을 살펴본다. 그러면, 각각의 파라미터들의 범위를 대략적으로 잡을 수 있게 된다. 성능이 잘 나온 파라미터 값들보다 조금 작고 조금 큰 범위로 설정하면 더 상세하게 파라미터 값들을 찾을 수 있을 것이다. 5 epoch동안 대략적으로 성능이 잘 나오는 파라미터 값들을 뽑아보는 것이 아래의 사진이다.
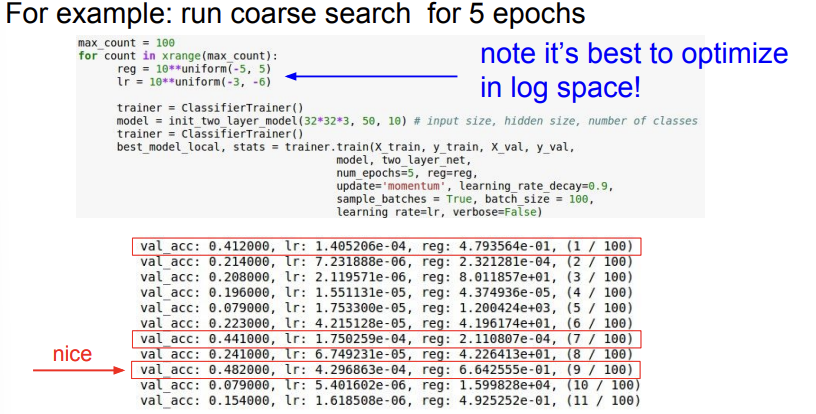
위에서 빨간 박스를 쳐 놓은 것이 성능이 그나마 잘 나온다. lr은 [e-04], reg는 [e-01,e-04] 범위 내일 때 성능이 잘 나온다.
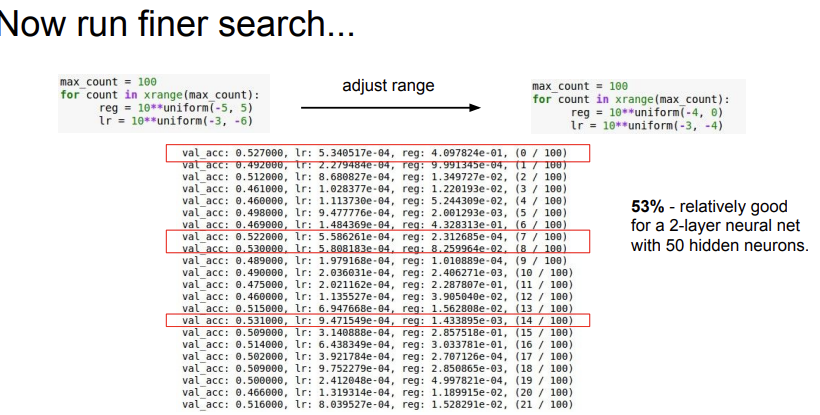
그래서 성능이 잘 나온 케이스를 포함하는 범위로 다시 범위를 정해주고(범위는 좁아진 것이다.) 더 정교한 파라미터 최적화를 지정해준다. 물론, 여기서도 주의할 점이 있다. 이렇게 범위를 좁혀줬어도, 양 끝 값을 조금 넘어가는 값들에서 최적 값이 나올 수도 있기 때문에, 범위를 조금 넘어가는 값들을 살펴볼 필요도 있다.
또 하나 loss explosion을 미리 알아보고 일찍 훈련을 중단시킬 수 있는 방법이 있다. 만약 loss가 이전 값보다 3배 이상 크게 나온다면 loss explosion으로 판단하고 프로그램을 일찍 종료시켜도 된다.
2) Random search, Grid search
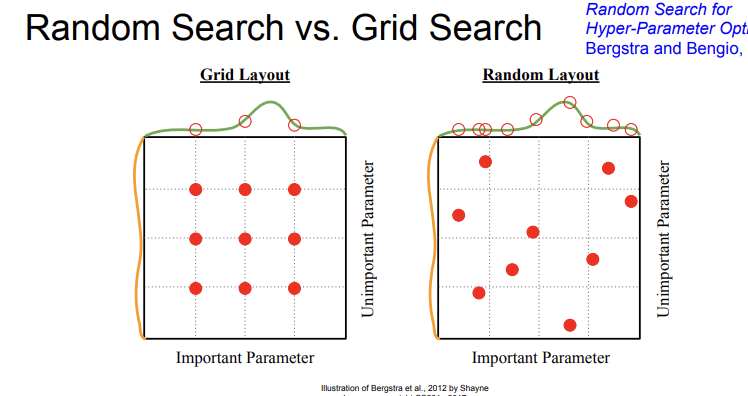
다음 방법은 무작위로 살펴보는 것이다. 무작위로 살펴보는 것에도 두가지 방식이 있는데, Grid Search는 일정한 간격을 두고 찾아보는 것이다. 그러나 Random Search는 간격을 두지 않는다. 그렇기 때문에 일반적으로 이 두가지 방식중에서는 Random Search를 선호한다고 한다. Grid Search에서 뛰어넘은 값들 중에 최적인 값들이 있을 수도 있기 때문이다.
10. Monitoring
1) Loss Curve 살펴보기
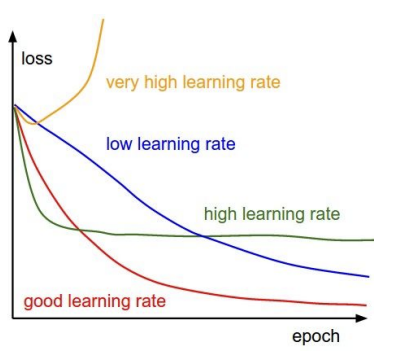
딥 러닝에서 시각화를 해서 뭔가 살펴보는 것이 굉장히 중요하다고 한다. 그래서 여러 가지를 살펴 볼 수 있는데, 그 첫 번째가 Loss Curve이다. 노란색 그래프의 경우, Exploding Loss가 나타난 경우이다. 이런 현상은 learning rate가 너무 높기 때문에 나타날 수 있기 때문에, learning rate을 좀 낮춤으로서 해결할 수 있다. 파란색 그래프 초록색 그래프도 그닥 좋지는 않은 경우이고, 빨간색 그래프처럼 서서히 떨어지며 수렴하는 것이 이상적이라고 한다.
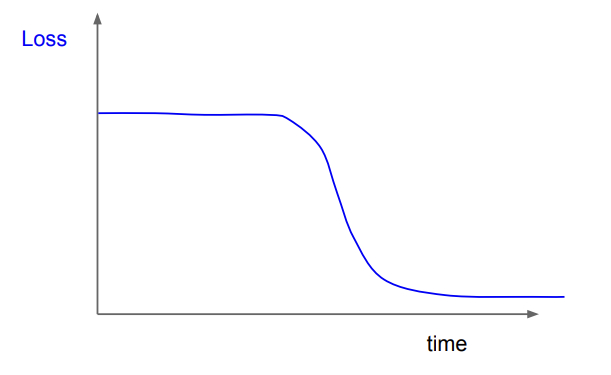
또한, 위 처럼 loss가 변하지 않다가 갑자기 급감하는 경우는, 초기화 문제라고 의심해 볼 수 있다. 초기화를 잘못해서 flat한 구간이 생기기 때문이다.
2) Accuracy
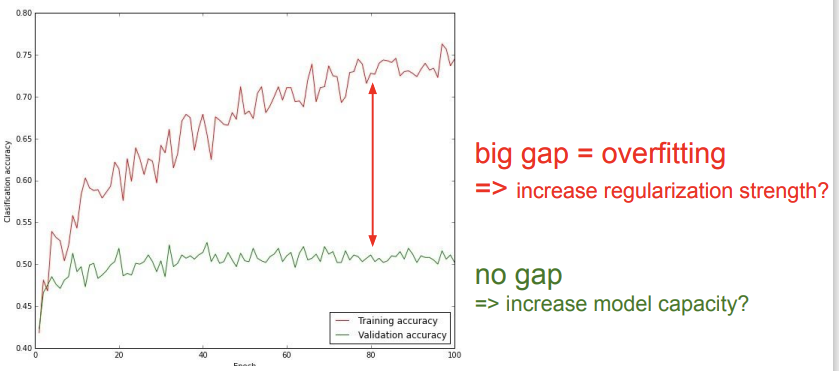
Training Accuracy와 Validation Accuracy를 비교해보는 것도 좋은 시각화 전략이 될 수 있다. 만약 둘의 차이가 크다면, (사진에서 빨간색 글씨의 경우) training data에 overfitting된 경우라고 볼 수 있다. 규제화 강도를 높이는 것이 해결책이 될 수 있다. 만약 둘의 차이가 너무 적다면, 모델의 복잡도를 높이는 것이 해결책이 될 수 있다고 한다.
3) ratio of weight updates/weight magnitudes
이 방법은 시각화해보는 것은 아니지만,우리가 파라미터 업데이트를 진행할 때 parameter가 업데이트 된 양과 원래 parameter 값의 비율이 0.001 정도가 되도록 노력해야 한다고 한다.

11. 결론
6강의 강의를 요약해보자. 강의에서는 Activation function의 경우 ReLU를 사용하고, image를 다룰때의 data preprocessing은 mean image를 빼주는 것 정도면 적당하다는 것, 그리고 weight initialization의 경우 Xavier Initialization을 사용하고, Batch Normalization을 사용하는 것도 좋은 방법이라는 것을 배웠다. 또한 Hyperparameter를 최적화하는 방식에 대해서도 알아볼 수 있었다.
다 중요한 내용들이라 주기적으로 복습해주어야 할 것 같다.
