1.6강 복습
6강에서는 다양한 activation function, weight initialization, data preprocessing, batch normalization, hyperparameter search등을 배웠다. 여러가지 논의를 통해 Activation Function들 중 가장 먼저 시도해봐야 할 것은 ReLU라는 것을 알게 되었고, Weight의 초기화도 너무 크지도, 작지도 않게 초기화하기 위해 Xavier Initialization 같은 것들을 적용해야 한다는 것도 알게 되었다. 데이터 전처리를 통해 zero mean,zero centered로 데이터를 만들어 주는 것, 그리고 BN을 통해 learning rate나 weight initialization에 대한 의존도를 낮추는 법도 배우는 것 또한 배웠다. 마지막으로 hyperparameter를 찾을 때 범위를 점점 줄여가는 테크닉 또한 배울 수 있었다. 7강은 이어서 네트워크를 훈련하는 방법에 대해 배운다. 큰 주제들로는 optimizaiton을 더 간지나게 하는 방법들, 그리고 Regularization 중 dropout, 그리고 CNN 훈련에서 많이 사용하는 Transfer Learning이 있다.
2.Problem of SGD
우리가 주로 사용하는 Optimization으로는 SGD(Stochastic Gradient Descent) 가 있다. 데이터 하나의 gradient 계산을 할 때마다 update를 하는 방법이다. 그런데 이 방법은 문제가 많다.
1) Loss Update
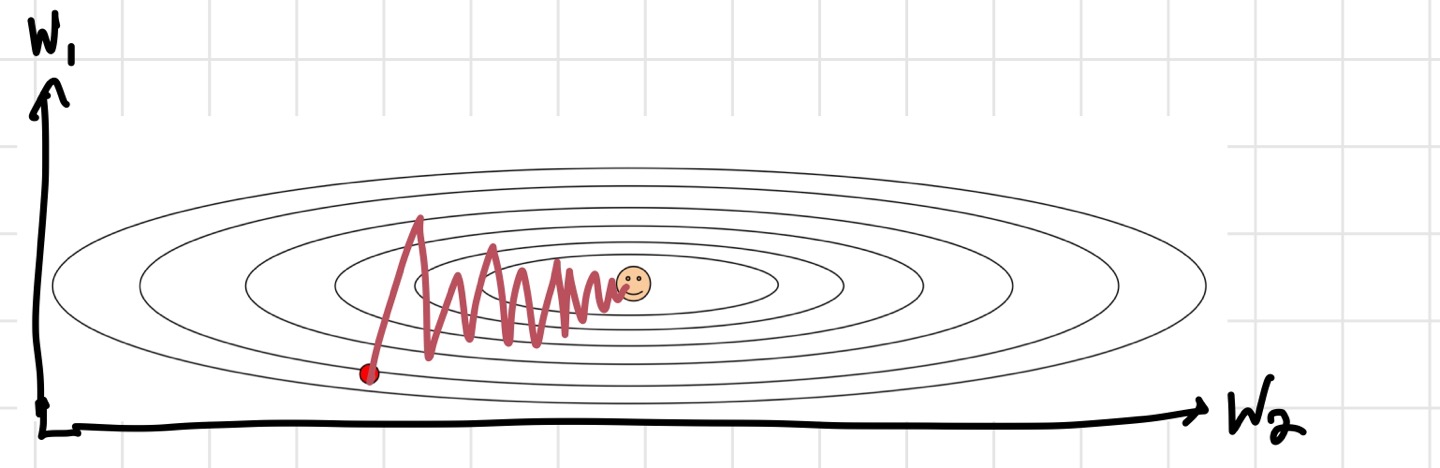
2) Local minima, saddle point

3) Noise
마지막 문제점은 mini-batch를 사용해서 오는 문제점이다. 원래 우리의 loss function은 전체 training set을 기준으로 정의되어 있었다. 그런데 실제로 이를 계산하려고 하니, 계산할 때의 비용이 너무 많이 들어가게 된다. 그렇기 때문에 mini batch를 이용해 계산을 하게 된 것이다. 그러나 mini batch를 통해 계산된 gradient들은 그 data의 진짜 gradient가 아닌 예측값이기 때문에, noise를 많이 갖고 있다. 그래서 최적화가 예쁘게 이루어지지 않는다고 한다.
위의 세 가지 문제점들을 해결하기 위해 더 좋은 optimization 테크닉이 필요하다.
3. Fancier Optimization
1) SGD+ momentum

기존의 SGD는 gradient를 계산해서 그대로 update에 반영했다. 그러나 SGD+ Momentum은 velocity라는 개념을 추가한다. velocity는 이전 gradient를 반영해서 현재 값에 대한 update를 진행할 수 있게 해준다. 이때, 이전 gradient를 얼마나 반영할 것인지 결정하는 파라미터가 rho이다. 원래 lr에 바로 곱해주었던 gradient를, 이제는 velocity를 업데이트하는데 사용한다. 그리고 나서 velocity를 이용해 x를 update하는 것이다. 이 방법을 사용하면 gradient 값이 0이어도 update가 가능하다. 공이 경사를 내려가면 가속도가 붙는 것 같이, velocity를 반영하면 앞에 언급한 saddle point나 local minima를 넘어갈 수 있지 않을까라는 아이디어라고 생각하면 될 것 같다. 실제로 조금 더 부드럽게 update가 진행되는 것을 볼 수 있다. 참고로, rho는 보통 0.9나 0.99를 많이 사용한다.
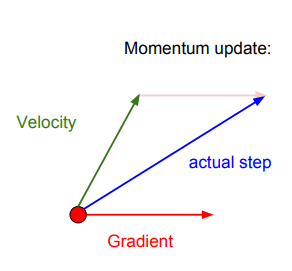
벡터로 보자면 이런 그림으로 표현할 수 있다.
2) Nesterov momentum
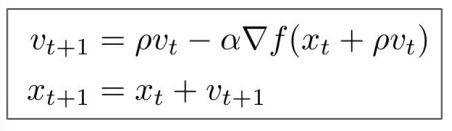
Nesterov momentum은 약간은 다른 아이디어에서 나온 것이다. 만약 velocity 값이 터무니 없는 값으로 나온다면 어떻게 할까?에 대한 해결책을 제시해준다. 터무니없는 velocity를 현재의 gradient 값을 통해 보정해 줄 수 있는 것이다. 더 자세히 얘기하자면, (현재의 velocity)-lr*(현재 velocity로 한 스텝 간 gradient)를 해줘서 보정 효과를 가져가겠다는 것이다.
대부분의 경우에 v는 0으로 초기화하는 것이 좋다. 그러나 계산의 복잡함 때문에 위의 식 대신에 변형한 식을 사용한다고 한다.
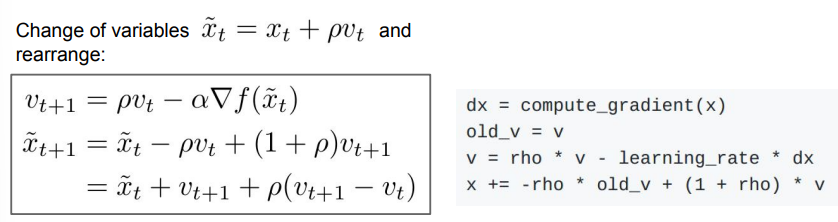
이렇게 식을 바꾸면 우리가 앞서 얘기했던 것들이 식에 담을 수 있게 된다. 변형된 식의 마지막 줄을 보자. 이전 위치+ 현재 velocity+ rho*(현재 velocity- 이전 velocity)이기 때문에, velocity의 error를 고쳐주는 효과를 준다.
3) AdaGrad
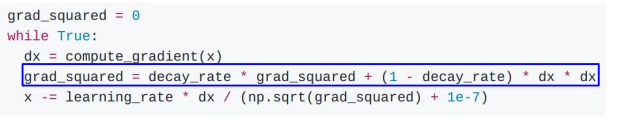
이 방법은 최적화 과정 중에 계산되는 모든 gradient들을 gradient_squared 라는 변수에 더해주는 방식을 사용한다. velocity term 대신에 gradient_squared가 들어온 것이다. 그리고 update시에 gradient_squared를 나눠주어 일종의 scaling을 해주는 방법이다.

코드를 보면, grad_squared에는 현재 gradient 값이 계속 더해지기 때문에 이전의 gradient들이 반영된다. 따라서 만약 현재 gradient가 크다면, 큰 값으로 나누어주기 때문에 업데이트가 작게 되고, 현재 gradient가 작다면 작은 값으로 나누어지기 때문에 업데이트가 크게 되는 것이다. 그러나 이 방법은 시간이 많이 지나고 나면, gradient_squared에 계속 gradient가 축적되기 때문에 더 큰 값으로 나눠지게 될 것이고, 그에 따라 update가 계속 작아지게 될 것이다.
4)RMS Prop
RMS Prop은 AdaGrad의 개선된 방법이라고 할 수 있다. 시간이 많이 지났을 때 update가 너무 느려지는 것을 해결하고자 decay_rate를 도입한다.
5)Adam
실전에서 가장 많이 사용하는 Adam이라는 방식이다. 위의 RMS prop과 momentum을 합친 방식이라고 생각하면 된다.

first moment 변수에서는 gradient에 대한 weighted sum을 하고, second moment에서 RMS Prop을 진행하는 것이다. 그런데 여기서 문제점은 코드가 맨 처음 돌 때 발생한다. decay rate를 보통 1에 가까운 수로 놓기 때문에, 첫 번째 업데이트를 한 후에도 second moment는 0에 가까울 것이다. 그러면 update시에 작은 수로 나눠지기 때문에 굉장히 큰 update가 진행될 것이다. 이를 해결하기 위해 bias correction을 한다.
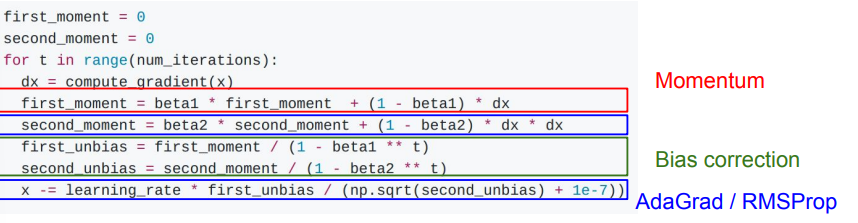
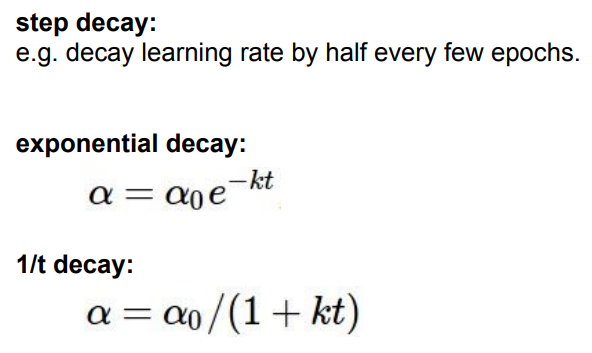
parameter의 초기화의 경우, 보통 beta1=0.9, beta2=0.999, lr=0.001 또는 0.0005로 놓고 시작한다고 한다. 물론 lr은 훈련 도중에 바꿀 수 있다. 몇번의 epoch마다 한 번씩 작아지게 할 수도 있고, exponential decay, 1/t decay 등을 사용할 수 있다. 제일 좋은 방법은, decay 없이 시작했다가, loss graph를 보고 decay 를 언제 사용하면 좋을 지 판단하는 것이라고 한다.
이 밖에도 First order, second order optimization도 있는데, 잘 쓰진 않는다. 그냥 Adam을 쓰는 것이 대부분의 경우에 가장 좋은 선택이다.
4. Model Ensembles
강의에서는 training score와 validation score의 차이가 많이 나는 경우를 피하는 것이 가장 중요하다고 강조한다. 그렇다고 또 너무 차이가 안나도 문제다. 둘의 차이가 적당하게 있는 것이 좋은데, 그것을 할 수 있는 방법 중 하나가 model ensemble이다. 각각 다른 여러 개의 모델들을 이용해 훈련시키고, test time 때 훈련시킨 각각의 모델들에 test data를 넣어 얻은 결과값들을 평균해서 최종 정확도를 계산하는 방식이다. 드라마틱한 성능 향상이 있진 않지만, 2%정도의 성능을 무조건 보장해주기 때문에 사용하면 좋은 테크닉이다.
또 다른 방법도 있다. ensemble의 일종이긴 한데, 여러 모델을 사용하는 것이라기보단 하나의 모델에서 cyclic learning rate(높은 lr와 낮은 lr을 반복)를 적용하는 것이다. 하나의 모델에서 여러 개의 수렴 포인트들을 얻어 이들의 평균을 계산하면 좋은 결과를 낼 수 있다.
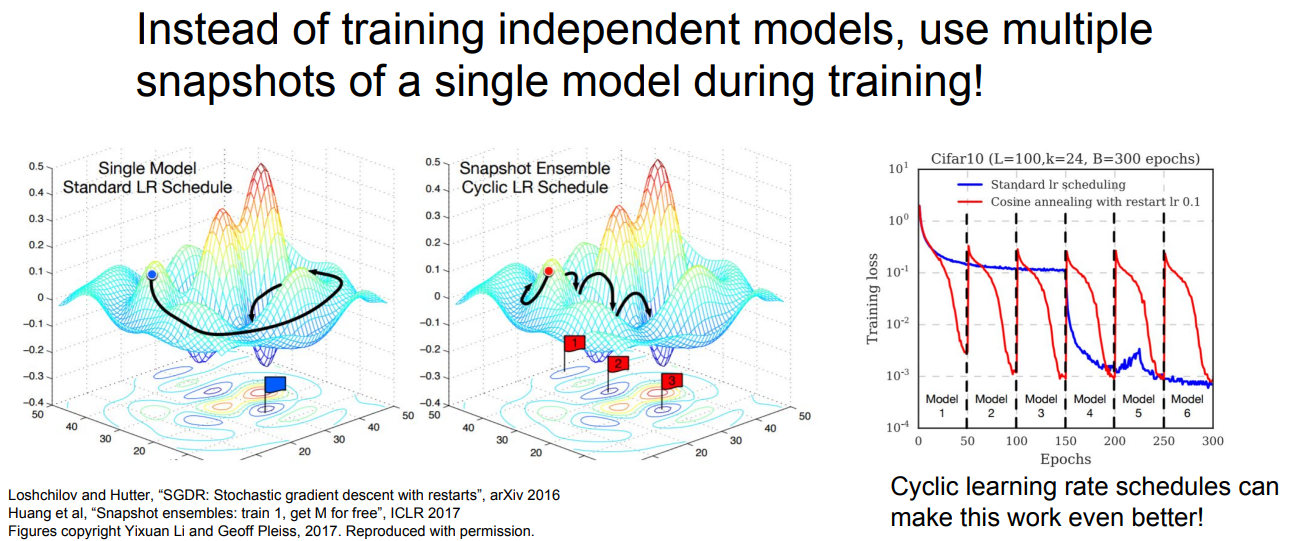
그렇다면 하나의 모델만 사용할 때 성능을 높일 수 있는 방법에는 뭐가 있을까? Regularization을 이용하면 된다. 우리가 이전에 배운 규제화에는 L1, L2 규제화 등이 있는데, Neural Network의 경우 파라미터 수가 너무 많기 때문에 적합한 방법은 아니다. 그렇기 때문에 NN에 적합한 방법을 사용한다.
5. Regularization
1) Dropout
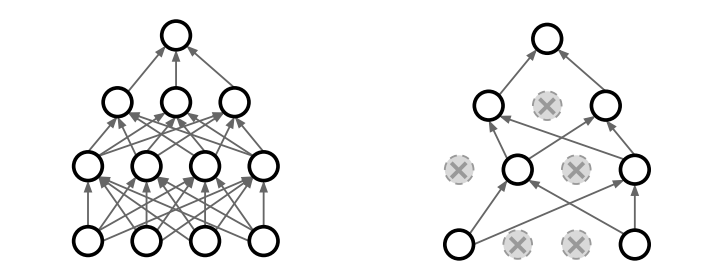
Dropout은 NN을 구성하고 있는 몇 개의 노드들을 랜덤하게 꺼서 모델을 훈련하는 것이다. 노드를 끈다는 것은 activation을 0으로 만든다는 뜻이다. 즉, 그림의 오른쪽처럼 노드 몇개를 제외시키고 훈련한다는 뜻이다. 원래 모델의 subset을 훈련에 사용한다고 생각할 수도 있다. 이 방법은 feature 끼리의 co-adaptation을 방지해 준다. 여기서 co-adaptation은 node끼리의 correlation이 생기는 것을 말한다. 쉽게 말하면 node들이 같은 기능을 하게 된다는 말이다. Dropout은 FCL에서 더 흔하게 사용한다.

그런데, 훈련시에는 랜덤하게 노드를 끄는 것은 도움이 되는데, 테스트를 할때에는 이러한 랜덤성이 전혀 도움이 되지 않는다. 테스트 시에는 정확도가 제일 중요하기 때문이다. 그렇기 때문에 test time에는 이런 랜덤함을 average out 해주는 것이 중요하다.
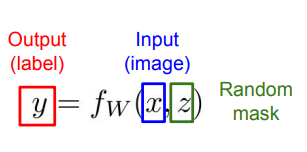
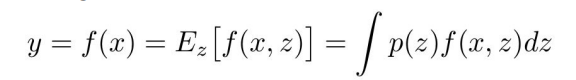
이런 식으로 구할 수 있지만, 인테그랄이 있는건 계산하기가 복잡하다. 그렇기 때문에 근사해서 값을 구한다.

위의 그림처럼 single neuron을 생각해보자. 이러한 경우, dropout의 경우의 수는 4가지이다. 노드를 끄는 걸 0, 키는 걸 1이라고 하면, dropout mask (p,q)=(0,0),(0,1),(1,0),(1,1) 의 경우가 나오는 것을 볼 수 있다. 이를 바탕으로 training시에 뉴런의 기댓값을 계산하면 위 사진의 식처럼 적분을 근사할 수 있다.

그러나 위에서 언급했듯이, test time에는 training time 때 곱해준 확률 값을 average out 해주어야 한다. 확률값 p를 곱해줘서 scaling 해주는 것이다. 여기서 test time을 줄이려면 test time때 p를 곱하지 않고, training time때 p로 나눠주는 방법을 사용할 수 있다.
이와 같이 training 때 randomess를 적용해서 overfitting을 방지하고 testing 때 이 randomness를 avreage out 해주는 테크닉은 regularization에서 많이 사용하는 테크닉이라고 한다.
2) Data Augmentation
Data Aungmentation은 가지고 있는 input data를 돌리고, 뒤집고, 대비나 밝기의 변화를 주어 다양성을 주는 것이다. 가지고 있는 데이터의 양이 부족할 때 사용할 수 있는 regularization 테크닉이다.
이 외에도 Batch Normalozation등 다양한 것이 있지만, 대부분의 경우 BN 정도만 사용하면 해결되고, 그래도 안될 경우에 Dropout 정도를 사용하면 overfitting을 해결할 수 있다고 한다.
6. Transfer Learning
CNN을 훈련시킬 때, 이미 훈련되어 있는 모델을 갖고와 조금만 더 훈련시켜주는 것이 transfer learning이다.

예를 들어, 작은 dataset을 훈련시키려고 하는 상황을 생각해보자. 이럴 경우에, 먼저 쉽게 구할 수 있는 ImageNet에서 훈련을 시킨 후, 그 모델의 가장 마지막 층만 우리가 관심있는 데이터셋의 클래스 개수에 맞게 바꿔준다. 즉, ImageNet에서 4096x1000이었던 matrix를 4096xC로 바꿔서 새로 초기화해줘야 한다는 뜻이다. 이렇게 하고 마지막 layer의 parameter들에 대해서만 training을 진행해준다.(그전의 parameter들은 고정시켜둔다.)
더 큰 데이터셋을 다루는 경우에는 네트워크 전체를 fine tuning을 해보는 것도 좋다. 마지막 층에서 파라미터들의 수렴이 이루어진 후, 전체 네트워크를 fine tuning 한다. 전체 네트워크의 파라미터들을 업데이트 한다고 하지만, 이미 ImageNet에서 parameter들이 훈련되어서 넘어온 것이기 때문에 조금씩만 바뀌면 괜찮은 성능을 낸다고 한다. 그렇기 때문에 원래보다 더 낮은 lr(원래 lr의 10분의 1로 시작하면 좋다고 한다)로 세팅을 하고 사용한다. 데이터셋이 더 클수록 fine tuning에 사용하는 layer 개수를 늘릴 수 있다.
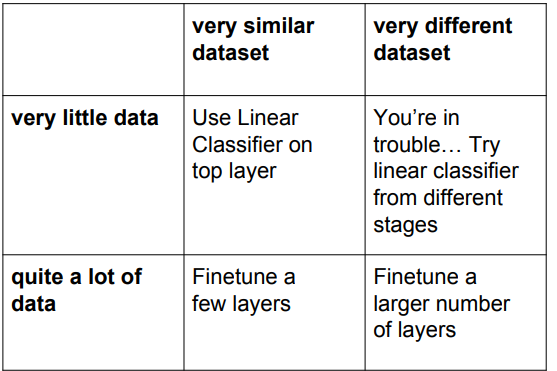
데이터 양과 데이터 유사도에 따른 대처 방법이다. transfer learning은 굉장히 많이 쓰이기 때문에 잘 알아놓는 것이 좋다.
7.결론
이번 강의도 처음에 볼 때는 굉장히 내용이 많고, 솔직히 모든 내용이 다 이해가 가지는 않았다. 많이 보며 이해하는 것이 중요할 것 같다.
