1. 소개
이 글은 cs230(스탠포드 강의) 8강 내용을 바탕으로 요약한 글이다. 앤드류 응 교수님의 논문을 효율적으로 읽는 방법과 ML / DL 분야에서 어떤 직장을 골라야 할지에 대한 조언을 담고 있다. 강의 원본을 보고 싶다면 유튜브에 cs230 lecture 8이라고 치면 찾을 수 있다.
2. 논문 리뷰하는 법
우리가 논문을 처음 접할 때 범하는 가장 대표적인 오류가 맨 처음부터 모든 단어를 읽고 이해해야 한다고 생각하는 것이다. 교수님은 이러한 읽기 방식은 그닥 추천하지 않으신다고 한다. 지금부터 추천하신 방식을 소개하겠다. 아래에 등장하는 퍼센트는 이해한 것/읽은 것의 비율을 나타낸 것이다.
1) 읽고 싶은 논문의 리스트를 만든다.
2) 논문을 하나씩 정독하는 것이 아니라, 정리한 리스트의 논문을 왔다갔다 하며 읽는다.
3) 처음에는 모든 논문을 10%정도만 이해한다는 생각으로 가볍게 읽는다.
4) 3번을 반복하다 중요한 논문을 찾았다고 치자. 그러면 이 논문에 시간을 쓰고. 모든 것을 이해하려고 노력한다.
5) 논문의 citation paper들이 있으면 이것들도 다 읽어본다.
6) 이 과정을 마치고 다시 리스트로 돌아와서 2~5번을 반복한다.
교수님은 특정 분야의 논문을 몇 개 읽었는지가 나의 이해도를 판단하는 대략적인 척도가 된다고 하셨다.
-15~20개: 분야에 대한 기본적인 이해가 있고, 알고리즘들을 실생활에 적용해 볼 수 있는 상태
-50~100개: 분야에 대한 이해도가 꽤 높은 상태, 이 분야와 관련된 연구를 할 수 있을 만한 상태
위와 같이 이해도를 가늠해 볼 수 있을 것 같다. 이제 위의 10%를 읽으라는 말이 무슨 뜻인지 자세히 살펴보자.
하나의 논문을 읽는 순서
마찬가지로 하나의 논문을 읽을 때도 처음부터 끝까지 정독하는 것은 좋지 않은 방법이다. 여러 번에 걸쳐 읽는 것이 좋은 방법이고, 읽을 때마다 집중해서 보는 부분들을 달리하면서 보는 것이 가장 효율적이라고 한다.
1) 제목, abstract, 도표를 중심으로 보기
딥러닝 논문은 보통 도표에 저자가 주장하고자 하는 바가 압축되어 드러난다고 한다.
2) Introduction, Conclusion, 도표를 중심으로 보기
이미 1번에서 봤지만, 도표를 한 번 더 유심히 살펴보고 위에 언급하지 않은 나머지 내용도 훑어본다.
3) 수학 식을 제외한 나머지를 읽어본다.
4) 모든 내용을 읽되, 이해가 안되는 부분은 넘어간다.
이러한 과정을 거쳐 논문을 읽고, 내가 잘 이해했는지 확인해보는 과정을 거쳐야 한다. 다음 질문들을 자신에게 물어보고 논문을 이해했는지 자가진단 해보자.
자가진단 질문
1) 저자가 무엇을 이루고자 했는가?
2) 논문이 제시한 방법의 주된 내용들은 무엇인가?
3) 논문 내용을 내가 어떻게 사용할 수 있나?
4) 내가 또 알아보고 싶은 레퍼런스들에는 뭐가 있나?
위 4가지 질문에 대한 답을 할 수 있다면, 논문에 대한 이해를 제대로 한 것이다.
3. 논문 읽는 곳/ 수식/ 코딩
1) 논문 읽는 곳
- 트위터: 연구자들 사이에서 좋은 AI 관련 논문/ 정보들을 공유한다고 한다.
- ML subreddit: www.reddit.com
- 각종 학회: NIPS/ ICML/ ICLR
- arXiv: 논문을 주제별로 찾아볼 수 있는 사이트이다.
2) 수식
논문에 나오는 수식들을 먼저 이해하고, 백지에 그 식의 유도과정을 다시 적어보는 것도 좋은 습관이라고 한다. 나의 수식이나 알고리즘을 만들어 연구에 적용할 때 큰 도움이 된다고 한다.
3) 코딩
논문에 있는 open source 코드를 다운로드 받아 살펴본 후, 처음부터 구현해본다. 이것 또한 논문 내용을 더 깊게 이해할 수 있게 해준다.
가장 중요한 것은 단기간에 많은 양을 읽는 것이 아니라 꾸준히 논문을 읽는 것이다.
4. Career Advice
1) 회사에서 원하는 역량
- ML 코딩/ skills
- 의미있는 결과물
여기서 중요한 것은 이론적인 지식과 코딩 실력이 둘 다 있어야 한다는 것이다.
2) 역량에 대한 구체적 설명
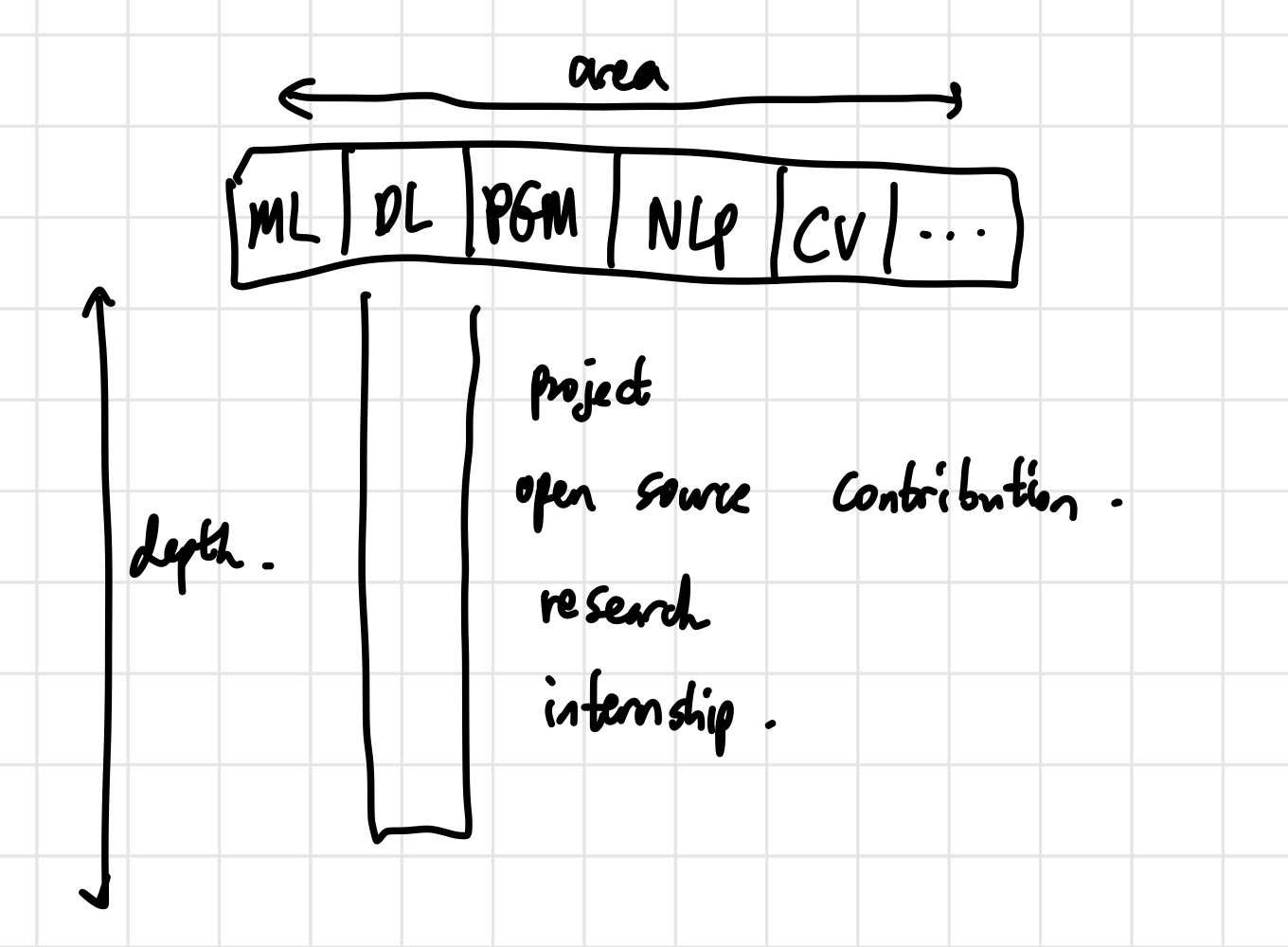
위의 사진은 AI Engineer가 갖추어야 할 역량을 T자로 나타낸 것이다. 전반적인 AI에 대한 지식을 갖추고, 그중 적어도 하나의 분야에서는 깊게 파보는 것에서부터 경쟁력이 나온다고 한다. 가로축에 해당하는 부분은 학교에서 듣는 강의와 논문을 읽으면서 충당할 수 있다. 여기서 마음에 드는 분야 하나를 골라서 의미 있는 프로젝트를 하는 것이다. 그러나 간단한 프로젝트를 하라는 말은 아니다. 10개의 따분한 프로젝트보다 1개의 제대로 된 프로젝트가 더 낫다는 것이다.
특히 딥러닝 분야에서의 역량은 단기간에 만들어지는 것이 아니다. 그렇기 때문에 꾸준히 공부하는 것이 중요하다.
3) 회사를 고를 때
- 능력 있는 사람들과 일하라.
- 내 매니저가 누구인지 알아보라.(나와 가장 많은 상호작용을 할 것이기 때문에 중요한 요소이다)
- 브랜드의 이름값에 매달리지 마라. (내가 어떤 팀에 들어가는지가 더 중요하다.)
예를 들어 50000명의 직원 중 AI team은 300명 정도 있는 대기업이 있다고 치자. 여기서 내가 어떤 일을 하게 될지가 가장 중요하게 따져야 할 가치이다. 회사가 만약 내가 어떤 팀에 들어가게 될지, 어떤 프로젝트에 투입될 지 자세히 알려주지 않는다면, 그 프로젝트는 다들 기피하는 프로젝트일 가능성이 높다. 결국 내가 이 회사에 들어가게 된다면 배우는 것 없이 시간만 날릴 수도 있다는 이야기이다.
더불어, 소수의 팀에서 일하는 것이 나의 성장에는 더 도움이 될 수도 있다고 한다. 사람이 적으면 그만큼 내가 중요한 일을 하게 될 가능성이 높아지기 때문이다. 커리어를 쌓는 초기 단계에서는 내가 어디를 가던지 가장 많이 배울 수 있고, 중요한 일을 하는 포지션에 가는 것이 좋다고 한다. 그리고 꼭 큰 AI회사가 아니더라도, 다양한 분야에 AI가 적용될 수 있기 때문에 AI를 필요로 하는 분야들을 찾아보고 지원하는 것이 중요해 보인다.
교수님의 조언을 요약하자면, 내가 최대한 많은 것을 배울 수 있고, 중요한 일을 해 성장할 수 있는 곳을 고르되, 회사 이름에 매달리지 말고 내가 일하게 될 팀의 상황을 보라는 것이다.
5. 정리
논문을 읽는 방법을 찾아보다 강의를 우연히 보게 되었는데, 커리어에 대한 조언까지 들을 수 있어 의미가 있었던 것 같다. 사실 난 그냥 논문을 처음부터 끝까지 정독할 생각이었기 때문에, 교수님이 바보 같은 짓이라고 할 때마다 뜨끔했던 것 같다. 아무튼 논문 리스트나 뽑으러 가야겠다.
