이번에 살펴볼 논문은 Nature 지에 실린 LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton. "Deep learning." Nature 521.7553 (2015): 436-444이다. 딥러닝에 대한 전체적인 개요를 소개하는 논문인 것 같다. 논문을 리뷰하는 방식을 어떻게 해야될 지 잘 모르겠어서 고민을 많이 하고, 다른 분들이 정리하신 블로그도 살펴봤다. 그런데 논문의 모든 내용을 블로그에서 다 다루기에는 시간을 너무 많이 뺏길 것 같아 그냥 다음 4가지 질문에 대한 답을 정리하는 느낌으로 리뷰해보려고 한다.
1) 저자가 무엇을 이루고자 했는가?
2) 논문이 제시한 방법의 주된 내용들은 무엇인가?
3) 논문 내용을 내가 어떻게 사용할 수 있나?
4) 내가 또 알아보고 싶은 레퍼런스들에는 뭐가 있나?
위 4개의 질문들은 앤드류 응 교수님의 강의에서 나온 자가진단 질문들이다. 만약 이 4가지 내용에 대한 답을 할 수 있으면, 논문을 잘 이해했다는 뜻이다. 그렇기 때문에 4가지 질문에 대해 답하는 형식으로 리뷰를 진행하겠다.
1. 저자는 무엇을 이루고자 했는가?
먼저 알아야 할 것은 이 논문이 review article이라는 점이다. 딥러닝에 대한 전체적인 개요, 사용되는 개념들을 잘 정리해 놓았다. 저자는 새로운 걸 알아냈다기보다, 존재하는 딥러닝 지식들을 정리해주었다. 논문에서는Supervised, Unsupervised Learning부터 Backpropagation, CNN, Language processing, RNN 등에 대해 다루고, 딥러닝의 미래 전망에 대해서도 짧게 정리해준다. DL의 가장 기본적인 뼈대를 다루고 있어서 기초들 다시 한 번 다지기에 좋은 논문인 것 같다. 정리하자면, 저자는 여기서 뭔가 이루려고 하기보단 기존에 연구된 내용에 대한 review를 일목요연하게 정리해줬다는 것에 의의가 있는 것 같다.
2. 논문이 제시한 방법의 주된 내용들은 무엇인가?
위에서 얘기했듯이 review article이기 때문에 워낙 다양한 주제들을 다뤘다. 그렇기 때문에 내가 새로 알게 되었거나, 참신했던 부분들을 다시 한번 리뷰하겠다 .
1) DL 모델의 classification
첫 번째로 살펴볼 것은 딥러닝 모델이 어떻게 classification을 하게 되는지에 대한 직관적인 그림이다. classification이 되는 과정은 알고 있었지만, 이 그림을 통해 더 확실하게 이해할 수 있게 된 것 같다.
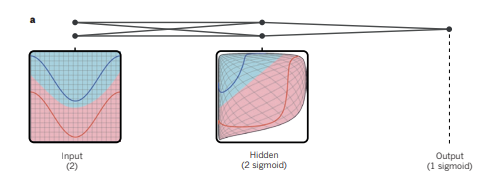
input data가 들어오면, 모델은 hidden layer들에서 non-linear한 방식으로 input data에 distortion을 가해 마지막 layer에서 data의 class들이 linearly seperable하게 될 수 있도록 만든다. 물론 실제로 사용되는 모델은 위의 2개의 input unit, 2개의 hidden unit, 1개의 output unit으로 구성된 모델보다 훨씬 복잡하지만, 이해를 위해서는 좋은 그림인 것 같다.
Image classification의 예시를 살펴보자. 5-20개의 non-linear layer들을 거치다 보면, 전통적인 방식으로는 classification이 어려웠던 사모예드와 흰 늑대를 구별하는 문제같은 것들이 해결된다고 한다. layer들을 거치며 모델은 복잡한 식을 만들어 구별하기 어려웠던 미묘한 차이들에 예민해지고, 사진의 배경, 포즈, 조명과 같이 classification에 중요하지 않은 것에는 무감각해진다고 한다.
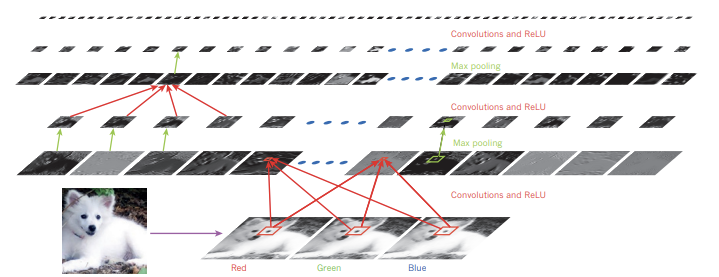
또, lower level feature들은 oriented edge detector와 같이 행동하는 경향 또한 보인다고 한다.
2) CNN(Convolutional Neural Networks)
DL 분야에서 굉장히 많이 사용되는 네트워크 중 하나이다. 이렇게 많이 사용되는 이유는 훈련시키기 쉽다는 장점도 있지만, 크게 4가지가 있다고 한다. (Local connectivity, shared weights, pooling, use of many layers) 여기서 Local connectivity가 중요하다. CNN과 항상 붙어다니는 용어 중 하나로, 특정 layer의 영역이 이전 layer의 작은 부분과 연결되어 있다는 뜻이다. 그렇기 때문에 FC Layer에 비해 사용되는 파라미터 수가 적어질 수 있었던 것이다.
3) Language Processing/ RNN
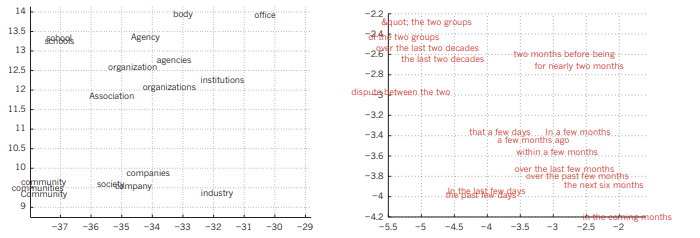
요새 핫한 NLP와 관련이 있는 주제이기도 하다. 학습할 단어들을 one hot encoding을 통해 표현하고, (벡터의 원소 중 하나만 1이고, 나머지는 0으로 표기하여 단어들을 표현하는 방식이다.) 어떤 단어가 주어졌을 때 다음에 나올 법한 단어를 예측하는 방식으로 모델이 작동한다. 학습 과정에서 neural network는 같이 사용되는 단어들의 연관성에 대해 알아서 학습하는 모습을 보였다. 그래서 훈련된 데이터의 vector space를 보면, 같이 사용되는 경향이 있는 단어들은 서로 가까이 위치하는 것을 볼 수 있었다.
그리고 연구를 통해 RNN이 이러한 문제들에 좋은 성능을 낸다는 것을 알게 되었다. 아래는 RNN의 구조를 나타낸 사진이다.
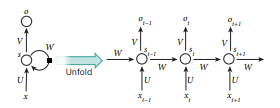
layer들이 깊어지면 깊어질수록 훈련하기 어려워지는 RNN의 특성을 보완하기 위해 LSTM(Long Short Term Memory) 과 같은 방식이 나오기도 했다. 이 방법은 Machine Translation에서 굉장히 좋은 성능을 낸다고 한다.
3. 논문 내용을 내가 어떻게 사용할 수 있나?
review article이기 때문에 이 질문은 생략하겠다.
4. 내가 알아보고 싶은 레퍼런스들은 어떤 것이 있나?
1) Glorot, X., Bordes, A. & Bengio. Y. Deep sparse rectifier neural networks. In Proc. 14th International Conference on Artificial Intelligence and Statistics 315–323 (2011).
-> Deep neural network들을 훈련 시킬 때 ReLU를 사용하면 training 속도가 눈에 띄게 빨라진다는 것을 밝혔다.
2) Hochreiter, S. & Schmidhuber, J. Long short-term memory. Neural Comput. 9, 1735–1780 (1997).
-> 수업시간에도 간단하게 LSTM에 대해 배웠지만, 자세히 알아보고 싶다.
5. 결론
내가 얼마나 알고 있는지 돌아볼 수 있는 논문이었던 것 같다. 기초적인 내용을 다루고 있기 때문에, 마지막에 있는 논문 리스트들을 보고 차근차근 읽어보는 것도 나쁘지 않을 것 같다. (어차피 다 중요한 논문들이라 나중에 읽게 될 것이다.)
