Summary
DEtection TRansformer (DETR) introduces a transformer-based approach to object detection, redefining it as a direct set prediction problem. Unlike many other modern detectors which rely on predefined anchor boxes and non-maximum suppression (NMS), DETR utilizes bipartite matching and transformers to directly predict objects in an end-to-end fashion.
Key Innovations:
- Set-based global loss: Ensures unique predictions via bipartite matching.
- Transformer encoder-decoder architecture: Captures global context via self-attention and processes object queries in parallel, eliminating the need for sequential region-based detection pipelines.
Introduction
Object detection has traditionally relied on hand-designed components such as predefined anchor boxes, IoU-based matching, and NMS. These methods have been widely successful but come with several challenges:
Limitations of Traditional Object Detectors
-
Predefined Anchor Boxes:
- Require careful tuning for each dataset.
- Increase computational complexity and introduce hyperparameter sensitivity.
-
Complex Post-Processing Steps:
- These challenges call for a model that eliminates heuristic-based matching and post-processing.
- IoU-based Matching: IoU-based matching assigns multiple bounding boxes to the same object based on heuristics, leading to inconsistencies during training.
- NMS: Required to remove redundant predictions but introduces heuristic decision rules.
DETR: A Set Prediction Approach
DETR redefines object detection as a set prediction problem, eliminating the need for anchors and post-processing. Instead of relying on region proposals and IoU-based assignment, DETR directly predicts a fixed-size set of objects in a single forward pass.
DETR
Key Innovations of DETR
By treating object detection as a direct set prediction problem, DETR simplifies the detection pipeline while ensuring unique, permutation-invariant predictions.
-
Anchor-Free and Post-Processing-Free:
- No predefined anchor boxes.
- No need for NMS, as predictions are uniquely assigned.
-
Permutation Invariance & Set Prediction:
- Non-autoregressive decoding: DETR predicts all objects at once without relying on sequence order.
- Unlike traditional detectors, DETR treats predictions as an unordered set, ensuring order-invariant training.
- However, since there is no predefined order, we need a way to associate predicted objects with ground-truth objects.
-
Bipartite Matching via the Hungarian Algorithm:
- DETR uses bipartite matching (Hungarian algorithm) to assign predictions to ground-truth objects.
- Since the number of detected objects can vary, DETR selects the best-matching predictions out of a fixed number of queries.
- One-to-one matching ensures that each object is assigned to a single prediction, eliminating the need for NMS.
DETR Architecture
The DETR model
- A set prediction loss (bipartite matching loss)
- Architecture that predicts a set of objects and models their relation
Object detection set prediction loss
The loss computation in DETR is divided into two main stages:
1. Matching: Assigning predicted objects to ground-truth objects using bipartite matching.
2. Hungarian Loss Computation: Calculating the classification and bounding box losses based on the matched pairs.
1. Matching Stage
DETR generates a fixed number (N) of object queries, which are then matched to ground-truth objects using bipartite matching (Hungarian algorithm).
- Number of object queries (N) ≥ number of ground-truth objects
→ If there are fewer ground-truth objects, "no object" class is assigned to the extra predictions.
Matching Cost Computation

The Hungarian algorithm calculates the matching cost to determine the optimal assignment between predictions and ground-truth objects. The matching cost considers:
- Classification score: The probability of predicting the correct class.
- Bounding box similarity: Based on IoU between predicted and ground-truth boxes.
This matching process serves the same role as heuristic-based assignment rules in traditional object detectors (e.g., anchor-based models), but ensures one-to-one matching without duplicates.
2. Hungarian Loss Computation
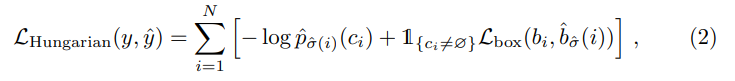
Once the matching is determined, DETR computes the Hungarian Loss, which consists of two components:
(1) Classification Loss
- Uses Negative Log-Likelihood (NLL) Loss to optimize class predictions.
- Ensures that each predicted object is classified correctly.
- Includes an additional "no object" class to handle unmatched predictions.
(2) Bounding Box Loss
Since DETR directly predicts bounding boxes without using anchors, it requires a stable loss function that balances different object sizes.
To achieve this, DETR combines two loss functions:
- L1 Loss: Minimizes the direct difference between predicted and ground-truth box coordinates.
- Generalized IoU (GIoU) Loss: Addresses scale differences and ensures stability.
These two losses are linearly combined and normalized by the number of ground-truth objects in the batch.
Why Use Generalized IoU Loss?
- L1 Loss alone is scale-dependent, meaning smaller objects may have lower absolute errors but higher relative errors.
- GIoU Loss introduces scale invariance, helping the model generalize better across different object sizes.
- Combining L1 and GIoU Loss ensures both precise localization and scale robustness in bounding box regression.
DETR contains three main components
- CNN backbone: using ResNet50 as a backbone network to extract a compact feature representation
- Encoder-decoder transformer
- Feed Forward Network (FFN): makes the final detection prediction

Backbone Network
- Starting from the initial image: getting image feature map
- Backbone generates a lower-resolution activation map (e.g., C=2048, H = H0/32, W = W0/32)
Encoder-decoder Transformer
-
Encoder
- 1x1 convolution reduces the channel dimension of the high-level activation map new feature map z
- Each encoder layer has a standard architecture and consists of a Multi-Head Self Attention, FFN + fixed positional encoding that are added to the input of each attention layer
-
Decoder
- The decoder follows the standard transformer architecture:
- Multi-Head Self-Attention (MHA)
- Encoder-Decoder Cross-Attention Mechanism
- The decoder follows the standard transformer architecture:
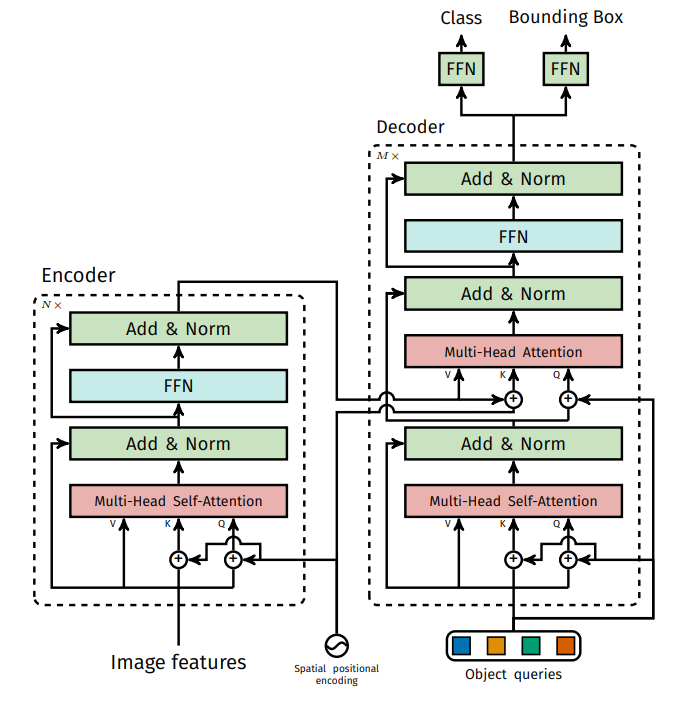
Unlike standard transformers, DETR’s decoder processes all N objects in parallel at each decoder layer.
- Object Queries
- Learnable embeddings of size N, representing potential object detections.
- These embeddings interact with the encoded feature map to extract object-specific information.
The object queries are added to the input of each attention layer, transforming them into output embeddings, which are then decoded independently into:
- Bounding box coordinates
- Class labels
Feed Forward Network (FFN)
- A three-layer perceptron (MLP) with ReLU activation and hidden dimension d.
- A linear projection layer is used for final predictions.
- Predicts normalized bounding box coordinates (center, height, width) relative to the input image.
- A separate linear layer predicts class labels using a softmax function.
- A fixed-size set of N bounding boxes is produced, where N is typically much larger than the actual number of objects in the image.
- An additional special class label ("no object") is used to represent background regions.
Auxiliary decoding losses
- Auxiliary losses are applied during training to help the model output the correct number of objects per class.
- Hungarian loss and prediction FFNs are added after each decoder layer.
- All prediction FFNs share their parameters across decoder layers.
- A shared layer-normalization (LayerNorm) is used to normalize inputs to the prediction FFNs, ensuring consistent learning across decoder stages.
Performance
Comparison with Faster R-CNN
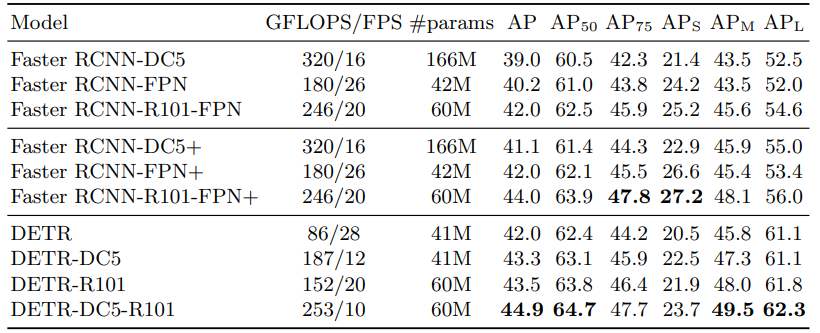
Despite its simplicity, DETR achieves competitive performance with Faster R-CNN, demonstrating that transformers can replace region-based object detection frameworks. However, notable differences exist:
- DETR excels at detecting large objects, benefiting from the non-local computations of the transformer.
- DETR struggles with small objects, as it lacks an explicit feature pyramid like FPN in Faster R-CNN.
- Training Efficiency: DETR requires longer training schedules but eliminates heuristic-based hyperparameter tuning.
Conclusion
DETR introduces a transformer-based object detection framework, marking a significant departure from traditional region-based architectures. This work highlights the importance of borrowing techniques from different research areas, such as leveraging self-attention mechanisms for object detection. While DETR shows strong performance on large objects, improving its ability to detect small objects remains a future research direction—similar to how FPN improved Faster R-CNN.
References
Carion N, et al. (2020). End-to-end object detection with transformers. European Conference on Computer Vision (ECCV). https://doi.org/10.1007/978-3-030-58452-8_13
