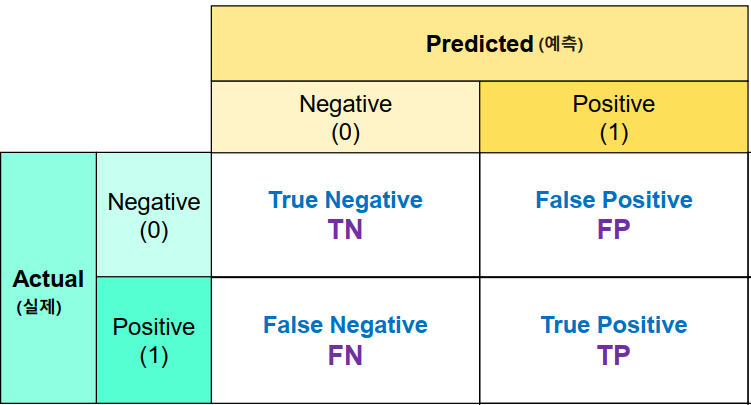
혼동 행렬(Confusion Marix)
-
실제 값(정답)과 예측 한 것을 표로 만든 평가표
- 분류의 예측 결과가 몇개나 맞고 틀렸는지를 확인할 때 사용한다.
-
함수: confusion_matrix(정답, 모델예측값)
-
결과의 0번축: 실제 class, 1번 축: 예측 class
-
TP(True Positive)
- 양성으로 예측했는데 맞은 개수
-
TN(True Negative)
- 음성으로 예측했는데 맞은 개수
-
FP(False Positive)
- 양성으로 예측했는데 틀린 개수
- 음성을 양성으로 예측
-
FN(False Negative)
- 음성으로 예측했는데 틀린 개수
- 양성을 음성으로 예측
이진 분류 평가지표
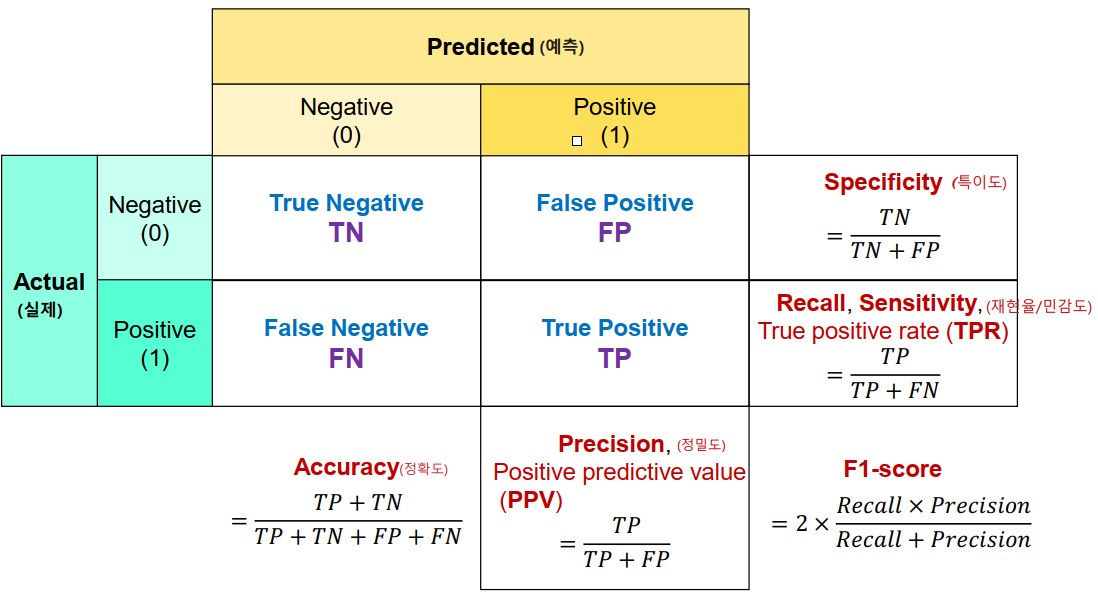
- Accuracy (정확도)
- 전체 데이터 중에 맞게 예측한 것의 비율
- Accuracy(정확도)는 이진분류 뿐아니라 모든 분류의 기본 평가방식이다.
양성(Positive) 예측력 측정 평가지표
-
Recall/Sensitivity(재현율/민감도)
- 실제 Positive(양성)인 것 중에 Positive(양성)로 예측 한 것의 비율
- TPR(True Positive Rate) 이라고도 한다.
- ex) 스팸 메일 중 스팸메일로 예측한 비율. 금융사기 데이터 중 사기로 예측한 비율
-
Precision(정밀도)
- Positive(양성)으로 예측 한 것 중 실제 Positive(양성)인 비율
- PPV(Positive Predictive Value) 라고도 한다.
- ex) 스팸메일로 예측한 것 중 스팸메일의 비율. 금융 사기로 예측한 것 중 금융사기인 것의 비율
-
F1 점수
- 정밀도와 재현율의 조화평균 점수
- recall과 precision이 비슷할 수록 높은 값을 가지게 된다. F1 score가 높다는 것은 recall과 precision이 한쪽으로 치우쳐저 있이 않고 둘다 좋다고 판단할 수 있는 근거가 된다.
음성(Negative) 예측력 측정 평가지표
- Specificity(특이도)
- 실제 Negative(음성)인 것들 중 Negative(음성)으로 맞게 예측 한 것의 비율
- TNR(True Negative Rate) 라고도 한다.
- Fall out(위양성률)
- 실제 Negative(음성)인 것들 중 Positive(양성)으로 잘못 예측한 것의 비율.
1 - 특이도 - FPR (False Positive Rate) 라고도 한다.
- 실제 Negative(음성)인 것들 중 Positive(양성)으로 잘못 예측한 것의 비율.
각 평가 지표 계산
from sklearn.metrics import (confusion_matrix, ConfusionMatrixDisplay, plot_confusion_matrix, accuracy_score,
recall_score, precision_score, f1_score)
# 혼동행렬
print(confusion_matrix(y_train, pred_train))
# 혼동행렬 시각화
plot_confusion_matrix(dummy_model,
x_test, y_test,
display_labels=["Neg", "Pos"],
cmap='Blues')
# 지표 계산
print('accuracy:', accuracy_score(y_train, pred_train))
print('recall:', recall_score(y_train, pred_train))
print('precision:', precision_score(y_train, pred_train))
print('f1 score:', f1_score(y_train, pred_train))
# recall, precision, f1-score를 한번에 보여주는 함수
from sklearn.metrics import classification_report
result = classification_report(y_train, pred_train_tree)
print(result)
- 임계값(Threshold)
- 모델이 분류 Label을 결정할 때 기준이 되는 확률 기준값.
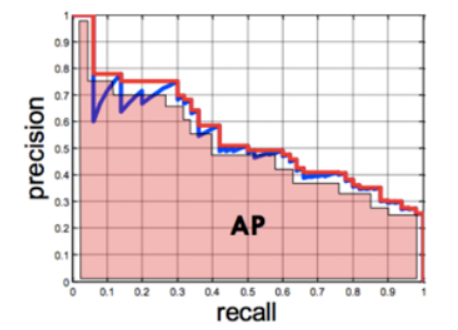
PR Curve와 AP Score
- Positive 확률 0~1사이의 모든 임계값에 대하여 재현율(recall)과 정밀도(precision)의 변화를 이용한 평가 지표
- X축에 재현율, Y축에 정밀도를 놓고 임계값이 1 → 0 변화할때 두 값의 변화를 선그래프로 그린다.
- AP Score: PR Curve의 선아래 면적을 계산한 값
from sklearn.metrics import precision_recall_curve
precision_list, recall_list, threshold_list = precision_recall_curve(y_test, pred_test_proba[:,1])ROC curve(Receiver Operating Characteristic Curve)와 AUC(Area Under the Curve) score
-
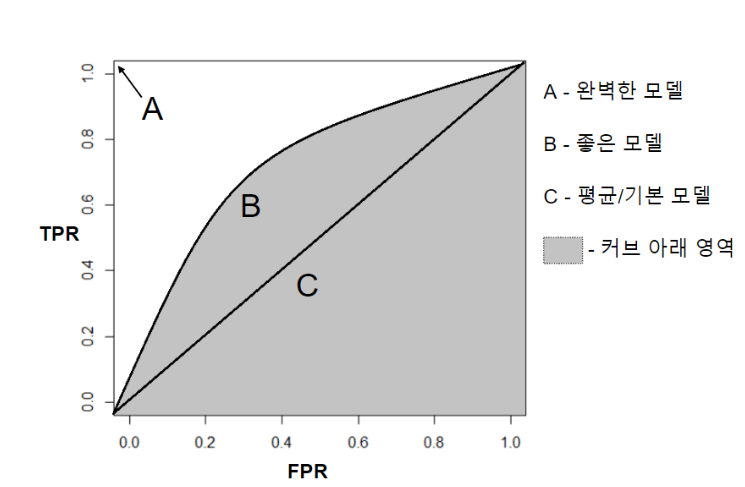
ROC Curve
- 2진 분류의 모델 성능 평가 지표 중 하나.
- FPR을 X축, TPR을 Y축으로 놓고 임계값을 변경해서 FPR이 변할 때 TPR이 어떻게 변하는지 나타내는 곡선.
- FPR과 TPR의 변화는 비례해서 변화한다.
- 낮은 임계값에서 큰 임계값으로 변경하면 높은 값에서 낮은 값으로 같이 변화한다.
-
AUC Score
- ROC Curve의 결과를 점수화(수치화) 하는 함수로 ROC Curve 아래쪽 면적을 계산한다.
