Scikit-learn
1.인공지능

AI의 정의 기계가 사람의 지능을 모방하게 하는 기술 구현 방법별 분류 규칙 기반(Rule-base)도메인 지식을 바탕으로 규칙을 만듬데이터 학습 기반수 많은 데이터를 통해 규칙을 스스로 찾음 머신러닝데이터 학습 기반의 인공지능 분야딥러닝인공신
2.(Scikit-learn) 데이터 전처리
\*\*결측치 처리\*\*행 / 열 단위 제거가능성이 높은 값으로 대체수치형: 평균, 중앙값범주형: 최빈값ML 알고리즘에 의한 추정이상치(Outlier) 처리오류값: 결측치로 처리극단치유지결측치 변환그 값의 MAX, MIN값으로 대체Feature 타입 별 전처리범주형
3.(Scikit-learn) 데이터 셋 분할과 검증
Hold out 방식train, validation, test로 데이터를 나누어 성능을 검증하는 방식데이터가 적을 경우 이상치에 크게 영향을 받을 수 있음K-겹 교차검증K개의 값으로 나누어 검증과 학습을 반복한다.KFold: 데이터 순서대로 분할StratifiedKFo
4.(Scikit-learn) Decision tree
독립 변수의 조건에 따라 종속 변수를 분리하는 모델기본 구현 방식데이터 셋 분할 및 결과 평가혼동 행렬을 통한 평가복잡도 제어max_depth: 트리의 최대 깊이max_leaf_nodes : 리프노드의 최대 개수max_features: 최대 사용할 Feature의 개수
5.(Scikit-learn) K-최근접 이웃(KNN K-nearest Neighbors)
정의데이터들 간의 거리를 측정해 가장 가까운 K개의 데이터셋의 레이블을 참조해 분류/예측한다.거리 측정 방식유클리디안 거리(Euclidean_distance)일반적인 직선거리맨하탄 거리 (Manhattan distance)|𝑎1−𝑏1|+|𝑎2−𝑏2|기본 구현Pi
6.(Scikit-learn) Grid Search 하이퍼파라미터 튜닝
GridSearchCV지정한 하이퍼파라미터를 모두 검증하는 방식RandomizedSearchCV지정된 하이퍼파라미터중 일부를 검증하는 방식결과 조회Test set 평가
7.(Scikit-learn) Binary classification 평가
시각화혼동행렬 시각화Graphviz를 통한 tree구조 시각화평가정확도(Accuracy)모든 값에서 예측한 것 중 실제 값과 일치하는 비율정밀도(Precision)Positive(양성)으로 예측 한 것 중 실제 Positive(양성)인 비율재현률(Recall)실제 Po
8.(Scikit-learn) Graphviz를 통한 tree구조 시각화
환경설정다운로드https://graphviz.org/download/설치시 자동으로 환경변수 설정됨라이브러리 설치시각화
9.(Scikit-learn) 과적합
일반화(Generalization)새로운 데이터셋에 대하여 좋은 예측 결과를 보여주는 경우과소적합(Underfitting)훈련 데이터와 테스트 데이터 모두에서 성능이 안 좋은 경우과대적합(Overfitting)훈련 데이터에 대한 예측 성능은 너무 좋지만, 일반성이 떨어
10.(Scikit-learn) 분류 평가 지표
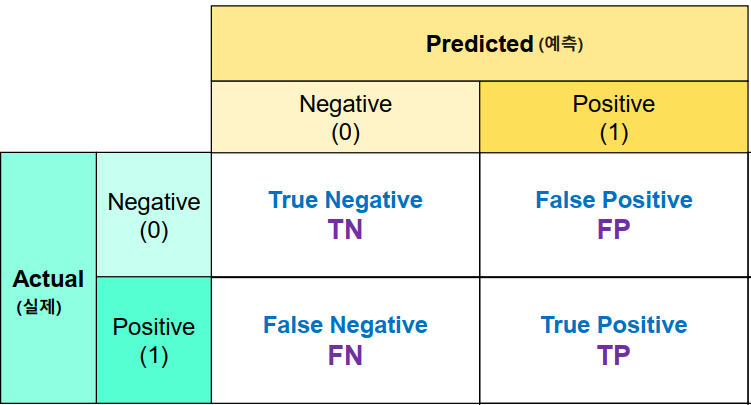
혼동 행렬(Confusion Marix)실제 값(정답)과 예측 한 것을 표로 만든 평가표분류의 예측 결과가 몇개나 맞고 틀렸는지를 확인할 때 사용한다.함수: confusion_matrix(정답, 모델예측값)결과의 0번축: 실제 class, 1번 축: 예측 classTP