CNN의 등장 배경: ANN의 한계
-
인공지능이 사람처럼 이미지를 보고 분류했으면 좋겠다!
-
ANN을 이미지에 적용 (이미지를 숫자로 바꿔 ANN에 넣음)
예: 32×32 크기의 RGB 이미지 (CIFAR-10, 컴퓨터에게 사물 인식 방법을 가르치는 데 사용할 수 있는 이미지 세트)
→[32×32×3]= 3072차원 벡터 -
이 벡터를 그대로 ANN의 입력으로 사용
-
문제 ①
ANN의 연결 방식인 FC layer (입력 노드 하나 ↔ 모든 다음 노드) 때문에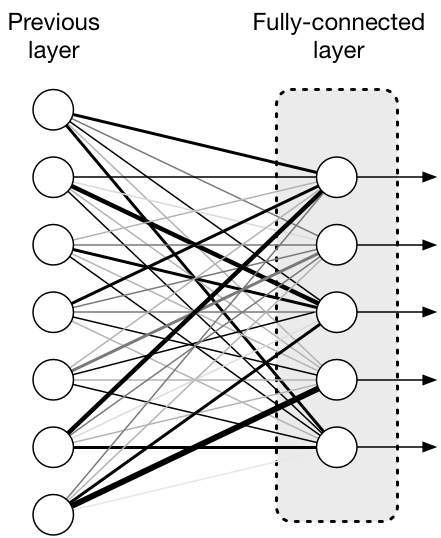 입력: 3072
입력: 3072
은닉층: 1000개 뉴런
→ 가중치 개수 = 3072000개 😨- 파라미터가 너무 많음
- 학습 느려짐
- 비용 ↑
-
문제 ②
ANN은- 픽셀의 위치 관계
- 인접한 픽셀끼리의 연관성
- 위/아래/왼쪽/오른쪽 정보
를 전혀 고려하지 않기 때문에 공간 구조를 전혀 알 수 없다.
→ 이미지 분석에 매우 부적합하다. -
문제 ③
같은 고양이 사진이라도 위치가 조금만 바뀌면 픽셀 값이 크게 달라지므로 ANN은 이를 완전히 다른 입력으로 인식한다.
- 사람: "그냥 X와 기울어진 X네."
- ANN: "전혀 다른 숫자 배열이네."
CNN의 핵심 아이디어

-
신경과학 연구 결과: 시각 피질의 각 단계는 특정 정보를 추출할 수 있는 다양한 필터가 구비되어 있으며, 각 단계에서 얻어진 정보는 다음 단계에서 종합이 되면서 좀 더 고차원적인 정보 추출이 가능해진다.
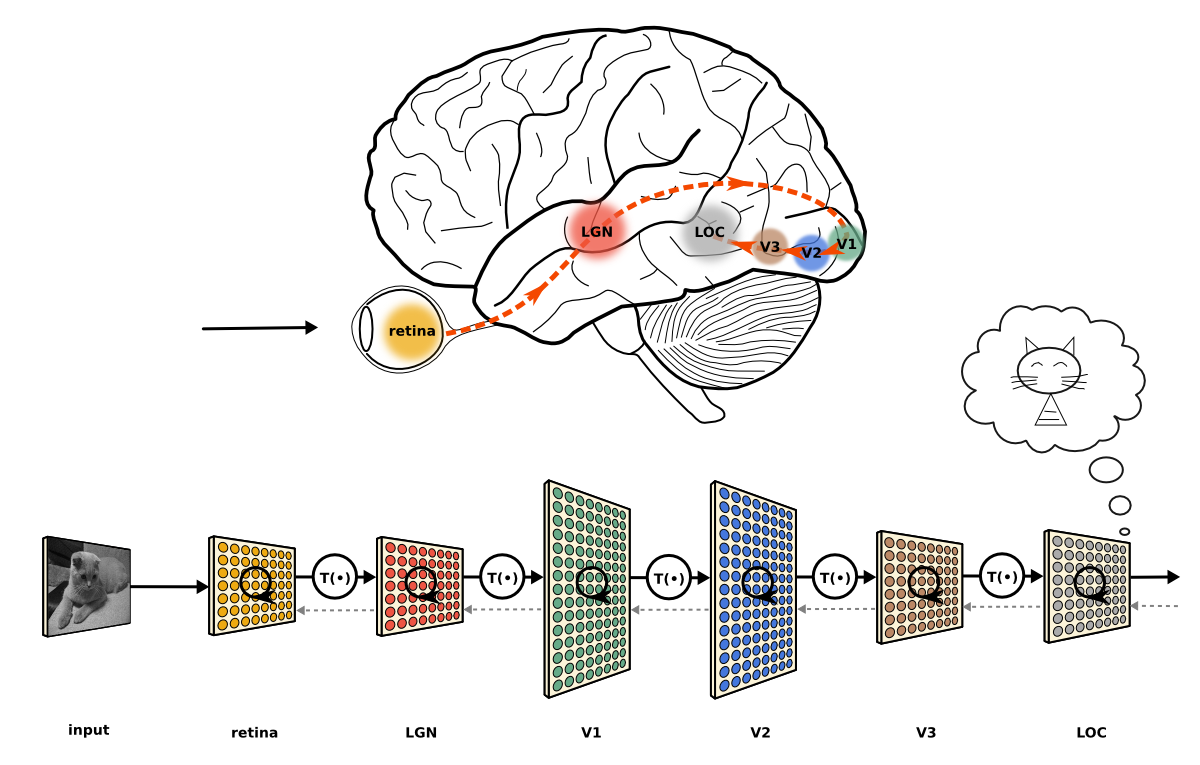
- Local connectivity
- 뉴런 하나가 이미지 전체를 보지 않음
- 작은 영역만 봄
- 지역적인 패턴만 집중해서 학습
- Local connectivity
-
특징은 위치와 무관하게 재사용된다.
- = input
- = output
- = 가중치 (무슨 특징을 얼마나 반영할지의 강도) (기울기)
- = 편향 (기준점 조정) (y절편)
CNN의 학습 대상은 이다.
- 가중치(weight) 공유
- 같은 필터(가중치 집합)를 이미지 전체에 적용
- 같은 특징을 어디서든 탐지 가능
- 파라미터 수 대폭 감소
즉, CNN은 이미지의 공간 구조를 보존하면서 국소적인 특징을 자동으로 학습하도록 설계된 신경망이라고 할 수 있다.
일반 신경망과 달리 CNN의 레이어는 뉴런이 width, height, depth의 3차원으로 배열된다. (CIFAR-10의 경우 [32×32×3], 3은 RGB 채널)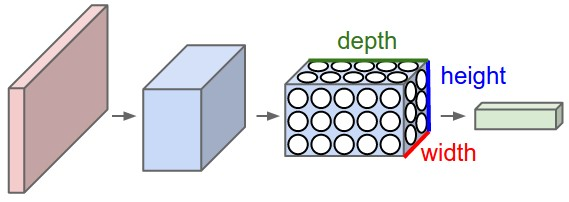 CIFAR-10의 최종 출력 레이어는
CIFAR-10의 최종 출력 레이어는 [1×1×10] 크기를 갖게 된다. 왜냐하면 CNN 아키텍처의 최종 단계에서는 전체 이미지를 depth 방향으로 배열된 단일 클래스 점수 벡터로 축소하기 때문이다.
CNN을 구성하는 Layer들


먼저 예시를 통해 전체적인 흐름을 가져가고, 각 층에 대해 상세히 알아보겠다. 계속 CIFAR-10의 예시를 통해 이해해보자.
-
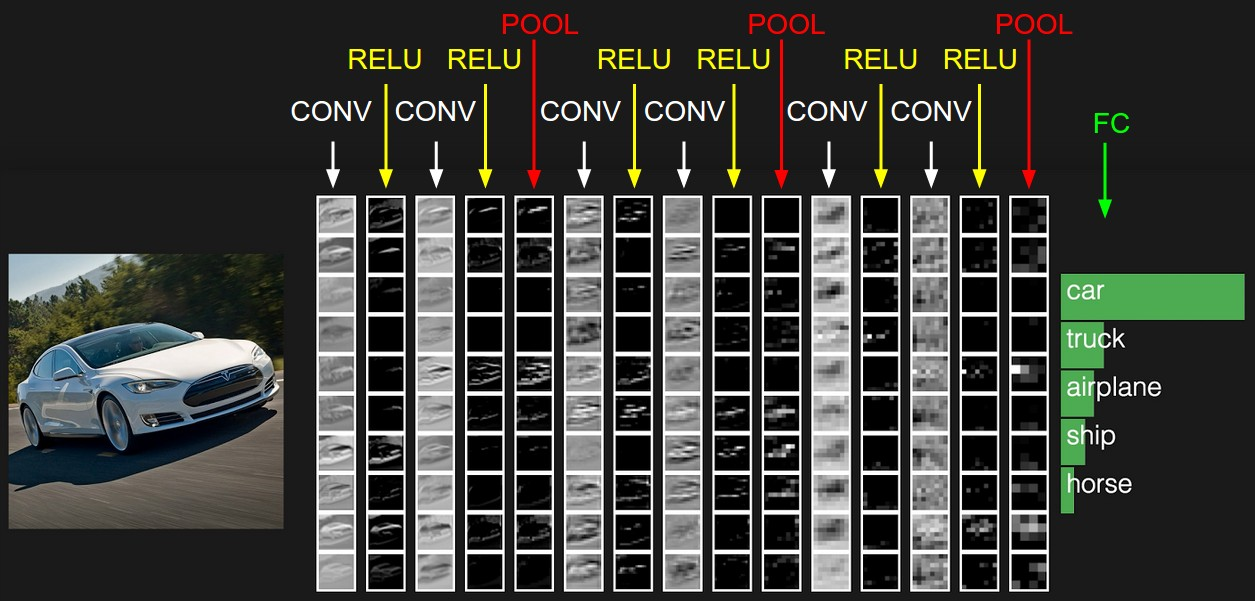
CIFAR-10 classification이
[INPUT - CONV - RELU - POOL -FC]의 아키텍처를 가지는 예시-
입력층(INPUT)
[32×32×3]은 이미지의 원시 픽셀 값을 담고 있다. (width 32, height 32, RGB 3개 채널) CNN은 입력을 벡터가 아닌, 공간 구조를 가진 텐서로 취급한다. 이 구조를 끝까지 최대한 유지하려는 것이 CNN의 철학이다. -
CONV층은 입력 이미지의 국소 영역(local region)에 연결된 뉴런들의 출력을 계산한다. (엣지, 모서리, 패턴, 질감 등 국소적인 feature를 추출) 각 뉴런은 자신과 연결된 작은 입력 영역과 가중치 사이의 내적(dot product)을 수행한다. 예를 들어, 만약 12개의 필터를 사용한다면, 이 CONV층의 출력은
[32×32×12]크기의 볼륨이 된다. -
RELU층은 와 같은 요소별(element-wise) 활성화 함수(activation function)를 적용하여, 0보다 작은 값은 모두 0으로 만들고 양수 값만 남긴다. 이 연산은 값만 바꾸고 크기는 바꾸지 않기 때문에, 출력 볼륨의 크기는 여전히
[32×32×12]이다. -
POOLING층은 공간적인 차원(가로, 세로)에 대해 down sampling을 수행한다. 이를 통해 데이터의 크기를 줄이게 되며, 예를 들어 출력 볼륨의 크기는
[16×16×12]가 될 수 있다. -
FC(Fully-Connected)층은 최종적으로 각 클래스에 대한 점수(class score)를 계산한다. 그 결과 출력은
[1×1×10]크기의 볼륨이 되며, 이 10개의 값은 CIFAR-10 데이터셋에 포함된 10개 클래스 각각에 대한 점수를 의미한다. 일반적인 신경망과 마찬가지로, 이 층의 각 뉴런은 이전 층의 모든 값들과 연결되어 있다.
-
전형적인 CNN은 다음과 같은 레이어들의 조합으로 이루어져 있다.
Input
→ Convolution
→ Non Linear Activation (대표 함수: ReLU)
→ Pooling
→ (위 3개 반복)
→ Flatten
→ Fully Connected
→ Output (Softmax / Regression)Convolution Layer
합성곱
CNN에 대해 이해하기 위해서는 먼저 이름에 들어있는 '합성곱'에 대해 알고 넘어가야 한다. 합성곱은 곱셈과 덧셈만 할 줄 알면 수행할 수 있는 매우 단순한 연산이다.
합성곱 연산을 위해서는 input data와 filter가 필요하다. 합성곱 연산 = input data에 filter를 적용하는 것
합성곱 연산 = input data에 filter를 적용하는 것
이때, 필터의 매개변수가 가중치()에 해당한다.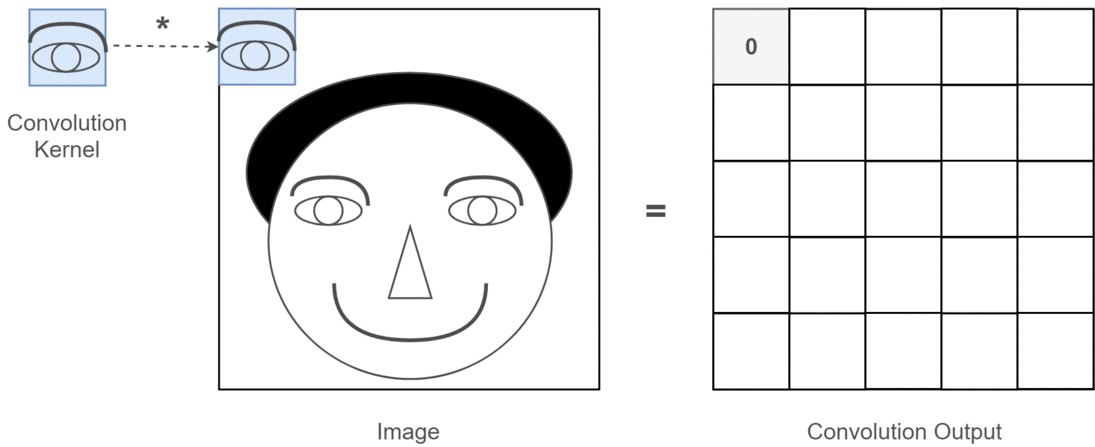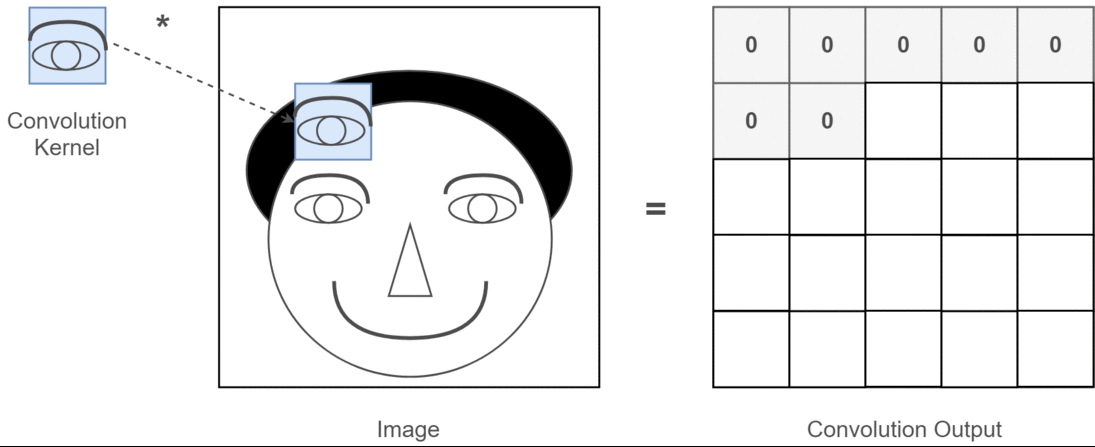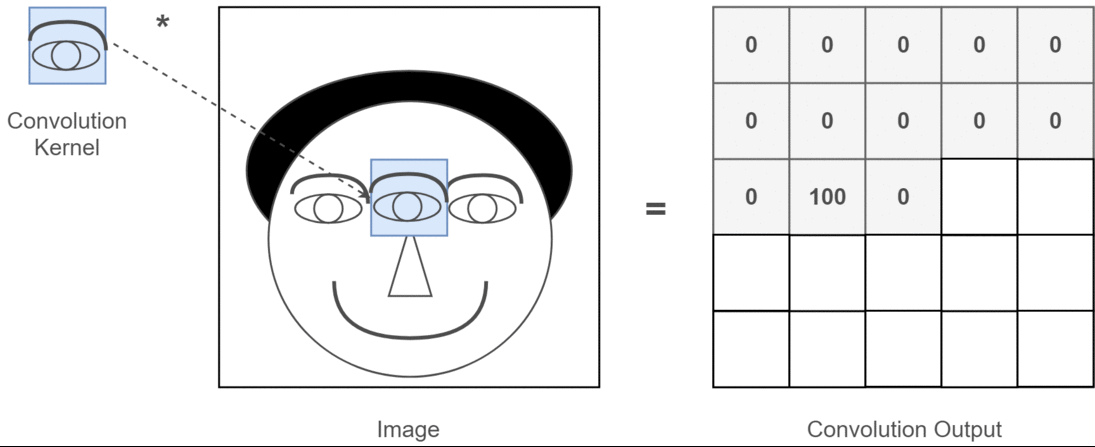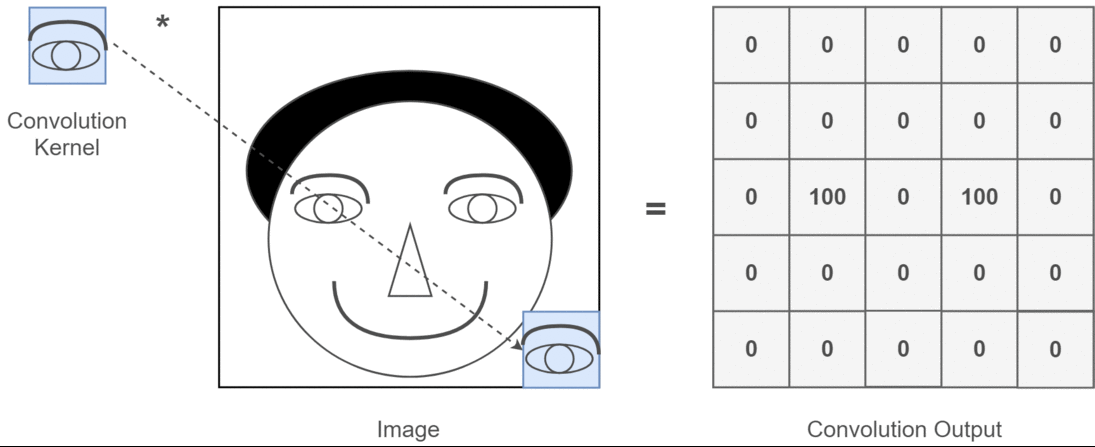
- 필터(커널)의 윈도우를 일정한 간격으로 이동해가며 적용한다.
- 입력과 필터에서 대응하는 원소끼리 곱한 후 총합을 구한다.
- 결과를 출력의 해당 장소에 저장한다.
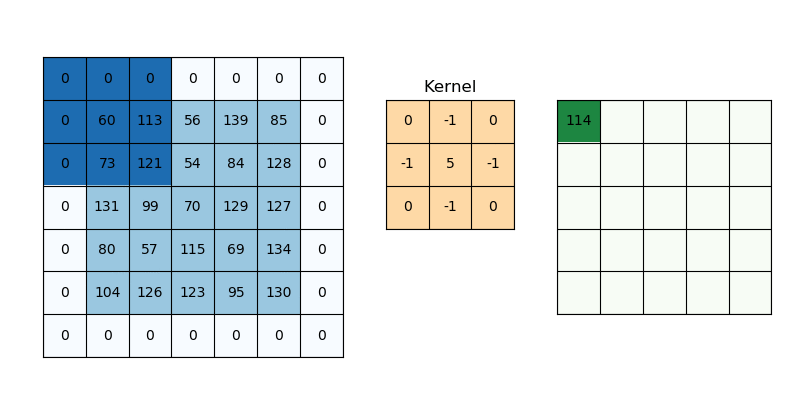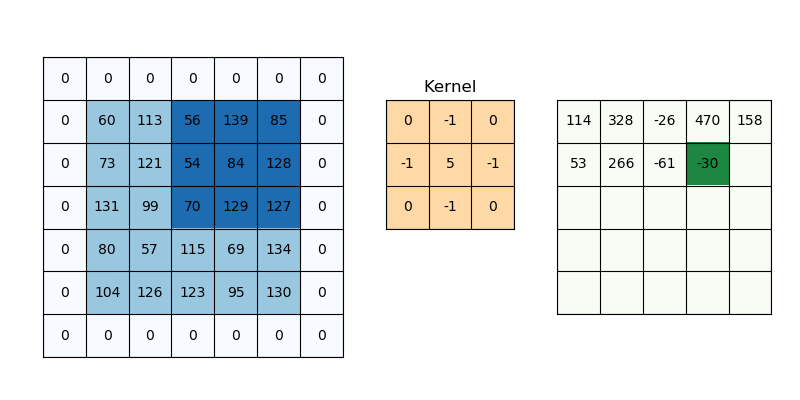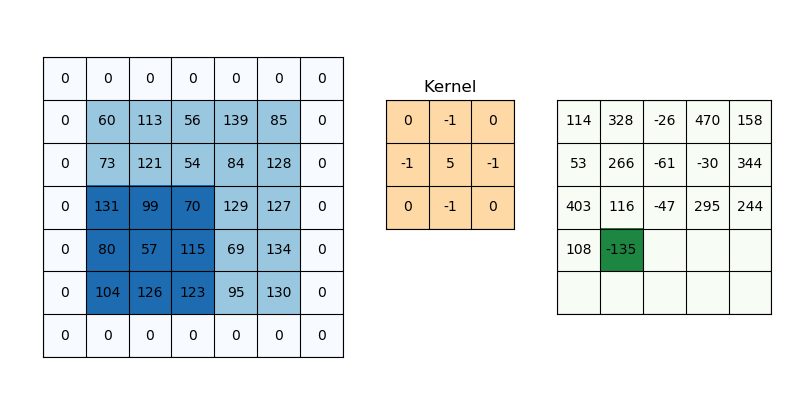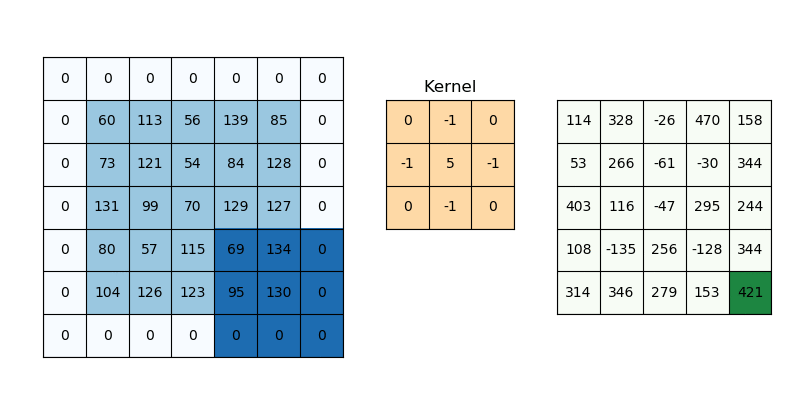
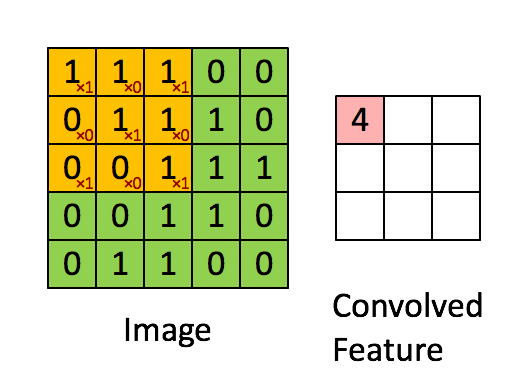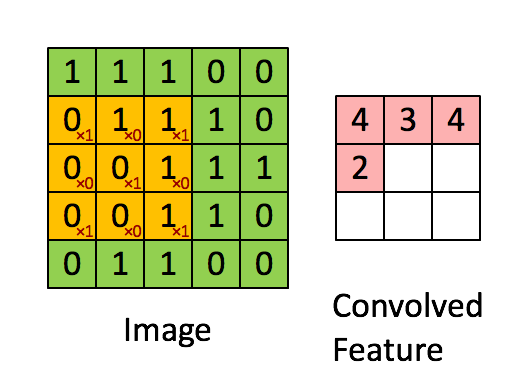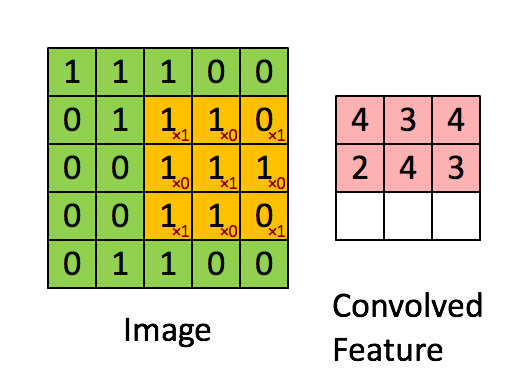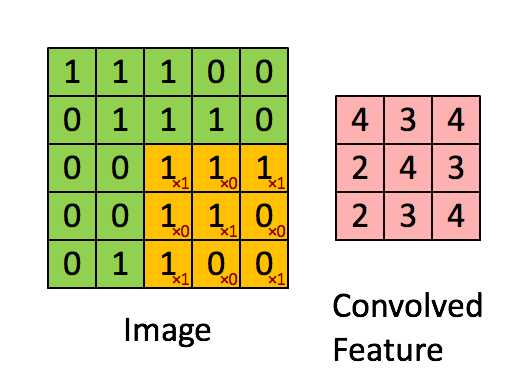 즉, convolution 과정은 위 예시에서
즉, convolution 과정은 위 예시에서 [1 0 1; 0 1 0; 1 0 1] 3×3 행렬을 우리가 만든 커널(필터)이라고 가정할 때, 위와 같이 커널을 사용해 이미지 데이터를 훑어서(sweep) 이 데이터를 다른 행렬의 형태로 변형시키는 것을 말한다. 이미지를 쭉 지나가면서 이미지의 부분 부분이 필터와 얼마나 일치하는지를 계산하는 것이다. convolution 과정을 거쳐서 좌측의 5×5 행렬이 우측의 3x3 행렬이 되었다.
방금의 예시에서는 필터의 크기가 3×3이었지만, 필터의 크기는 자유자재로 지정할 수 있으며 한 칸씩 이동하던 단위 역시 자유자재로 바꿀 수 있다. 이 이동하는 단위를 stride(건너뛰기)라고 부른다. 참고로 convolution 연산에서 자주 사용되는 필터의 크기는 3×3, 5×5, 7×7 등의 홀수 크기이다.
하나의 이미지에 대해서 여러 개의 필터를 적용할 수 있으며, 필터 하나 당 입력 이미지 전체에 대한 필터의 일치 정도가 나오는데 이를 활성화 지도(activation map) 또는 특성 지도(feature map)라고 부른다. 하나의 이미지에 필터를 3개 사용한다면 feature map 역시 3개가 생성되는 식이다. feature map의 크기는 입력 이미지와 필터의 크기, stride 크기에 따라 결정되는데 입력 이미지의 크기를 , 필터의 크기를 , stride를 라고 하면 활성화 지도 의 크기는 다음 식과 같다. 는 바닥 함수를 뜻하며, 내림 함수, 버림 함수라고도 한다.
 쉽게 얘기하자면 convolution은 주위 값들을 반영해 중앙의 값을 변화시키는 일이라고 할 수 있다. 여기서 핵심은, CNN은 목적하는 작업의 성공률이 높아지는 쪽으로 이미지를 변형해 간다는 것이다. 예를 들어 목적 작업이 classification이라면 classification의 precision이 높아지는 쪽으로 2차 이미지를 생성한다. CNN은 원본 이미지를 입력 받으면 다양한 커널(필터) 행렬을 이요해 여러 개의 feature map을 생성하고, 이를 연쇄적으로 진행해 classificaiton을 진행한다. 여기서 중요한 점은, 이 '커널 행렬'이 학습이 가능한 요소라는 것이다.
쉽게 얘기하자면 convolution은 주위 값들을 반영해 중앙의 값을 변화시키는 일이라고 할 수 있다. 여기서 핵심은, CNN은 목적하는 작업의 성공률이 높아지는 쪽으로 이미지를 변형해 간다는 것이다. 예를 들어 목적 작업이 classification이라면 classification의 precision이 높아지는 쪽으로 2차 이미지를 생성한다. CNN은 원본 이미지를 입력 받으면 다양한 커널(필터) 행렬을 이요해 여러 개의 feature map을 생성하고, 이를 연쇄적으로 진행해 classificaiton을 진행한다. 여기서 중요한 점은, 이 '커널 행렬'이 학습이 가능한 요소라는 것이다.
Padding
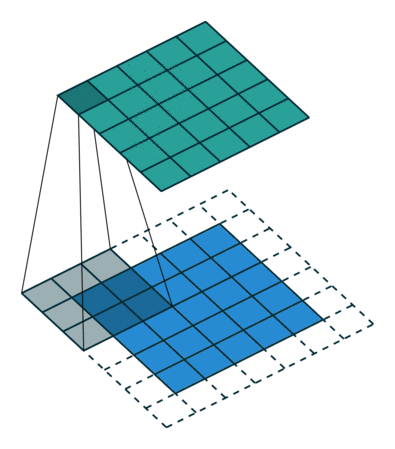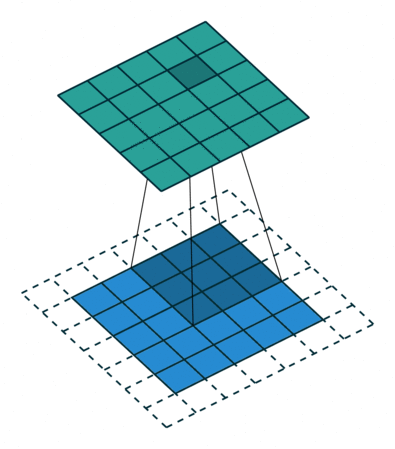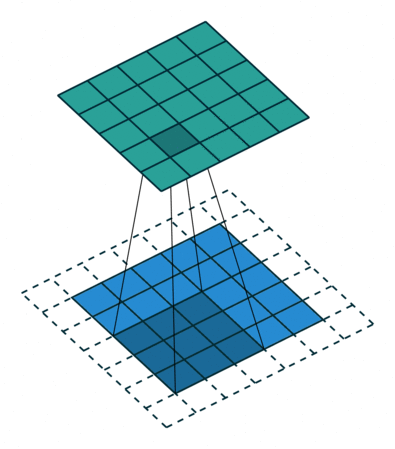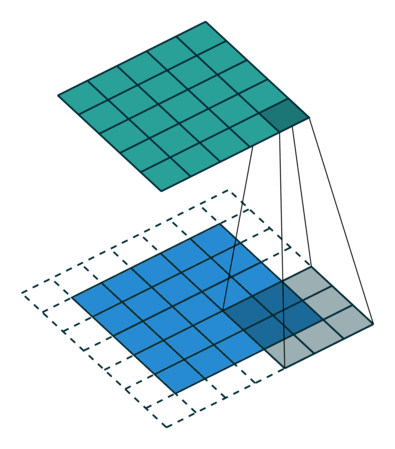
그런데, convolution 과정을 거치면서 이미지의 크기는 점점 작아지게 된다. 결국 심층 신경망의 깊이가 깊어질수록 정보 손실이 커진다. 게다가 이미지의 가장자리에 있는 픽셀들은 필터와 겹치는 영역이 적기 때문에 충분히 활용되지 못하는 문제도 있다.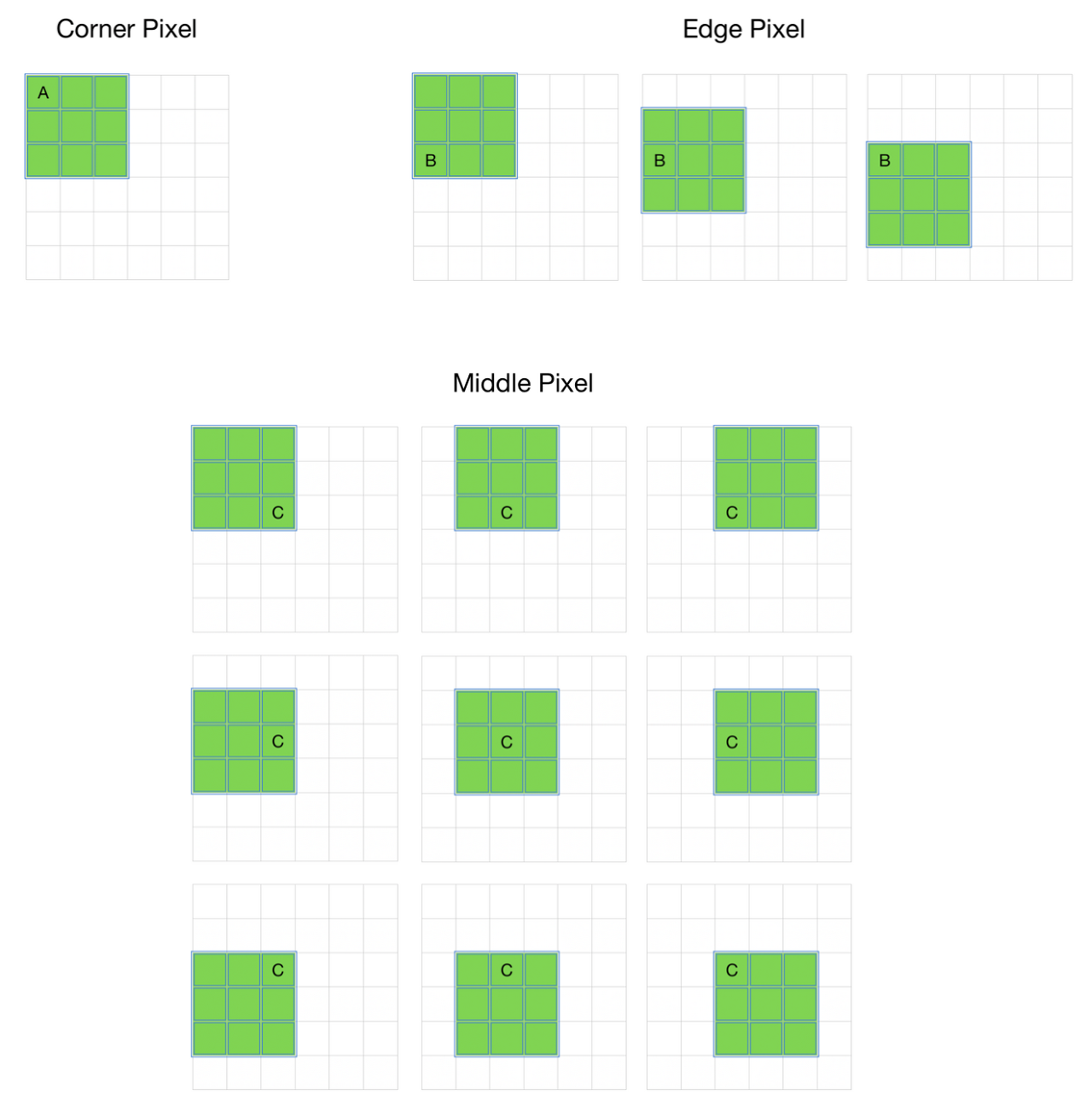
이러한 문제를 해결하기 위해 padding(테두리)을 사용한다. 패딩을 추가하면 더욱 정확한 이미지 분석이 가능해진다. 동시에 패딩은 이미지의 가장자리의 위치를 알려주는 역할을 하기도 한다. 보통 0으로 채워진 픽셀(zero padding)을 사용한다.
Non Linear Activation Function
Q. 비선형 함수가 왜 필요한가?
A. 레이어가 많아져도 linear면 깊게 쓸 이유가 없기 때문이다.
선형 함수 위에 선형 함수를 아무리 쌓아도, 결과는 결국 하나의 선형 함수가 된다. 레이어가 1개든 10개든 100개든 전부 하나의 와 동일하다는 뜻이다.
CONV, POOL(MAX를 제외하면 거의), FC 자체는 모두 선형 연산이다. 만약 ReLU 같은 비선형 활성화 함수가 없다면 CNN 전체 네트워크는 결국 하나의 큰 선형 변환이 되고 말 것이다.
대표적인 활성화 함수로는 ReLU, Leaky ReLU, Sigmoid, Tanh가 있다.
Sigmoid
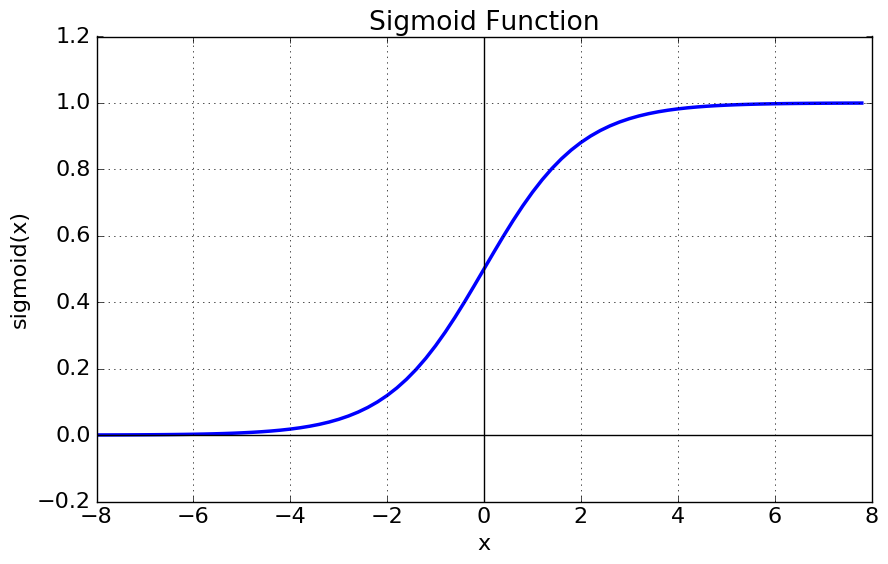
- 출력 범위:
(0, 1) - 확률처럼 해석 가능
단점
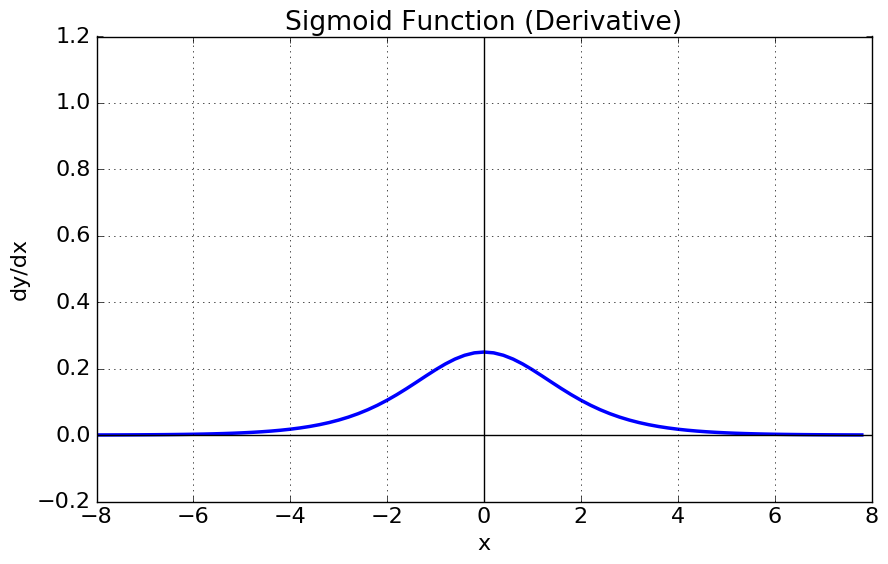
- gradient vanishing 문제
- 미분함수에 대해 일정 값 이상 커질 시 미분값이 소실되는 현상
- 입력이 크거나 작으면 기울기 ≈ 0
- 함수값 중심이 0이 아님
- 학습이 느려질 수 있음
이 때문에 최근에는 자주 사용하지 않는다.
Tanh (Hyperbolic Tangent)
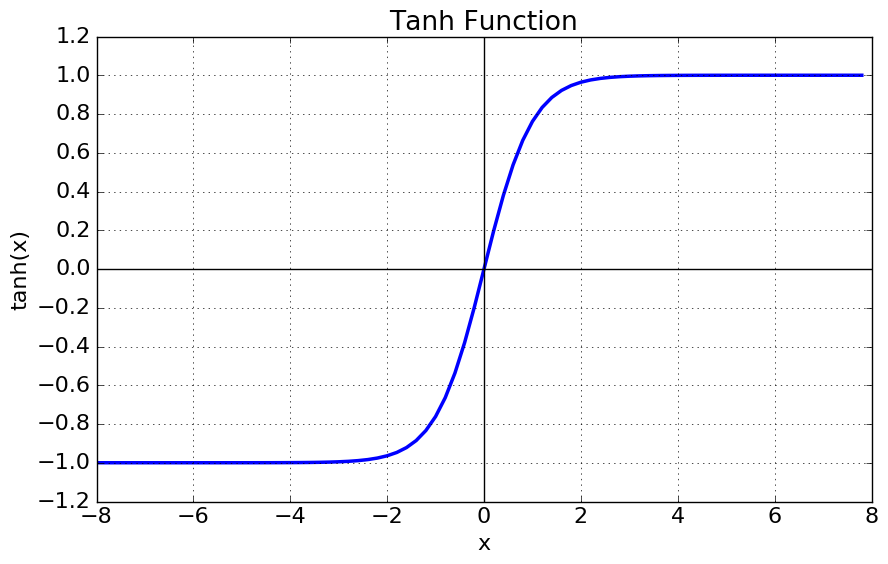
- 출력 범위:
(-1, 1) - sigmoid의 개선판 느낌
- 출력이 0 중심 → sigmoid의 최적화 과정이 느려지는 문제 해결
단점
- 여전히 남아있는 gradient vanishing 문제
ReLU (Rectified Linear Unit)
최근 가장 많이 사용되는 활성화 함수이다.
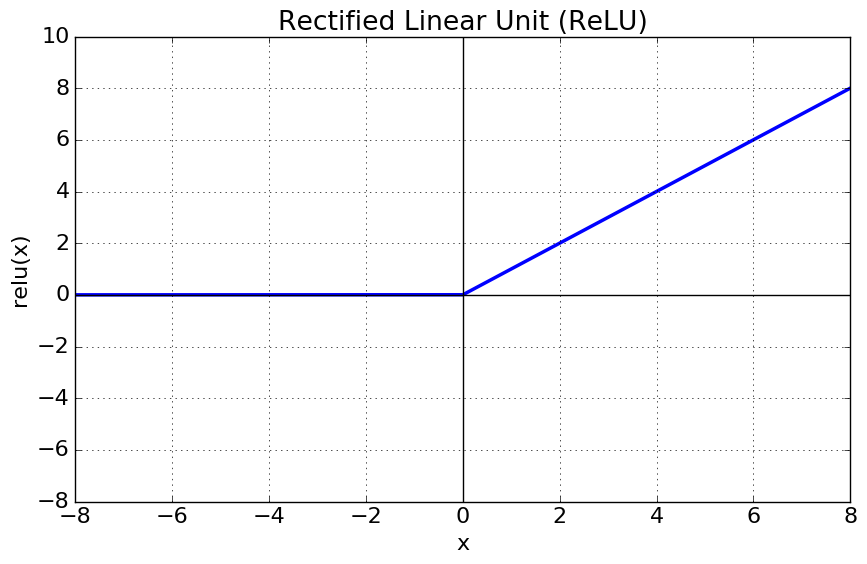
- x>0이면 기울기가 1인 직선
- 역전파 시 기울기가 그대로 전달되므로 학습 속도가 매우 빠름
- x≤0이면 함수값 0
- 연산 비용이 크지 않고, 구현이 간단함
단점
- Dying Neuron 현상
- 어느 순간 큰 손실이 발생하여 가중치와 편차가 마이너스로 떨어지는 경우, 어떠한 입력값이 들어와도 활성화 값이 0이 되는 현상
- 예: 가중치와 편향이 음수로 크게 이동하고 입력이 -1 ~ 1로 정규화된 경우에서는 어떤 입력이 와도 이므로 해당 뉴런은 영원히 업데이트 되지 않는다.
- x<0인 값들에 대해서는 함수값이 모두 0이므로 뉴런이 죽을 수 있음
Leaky ReLU
Dying Neuron 문제를 해결하기 위해 나온 ReLU의 변형된 형태
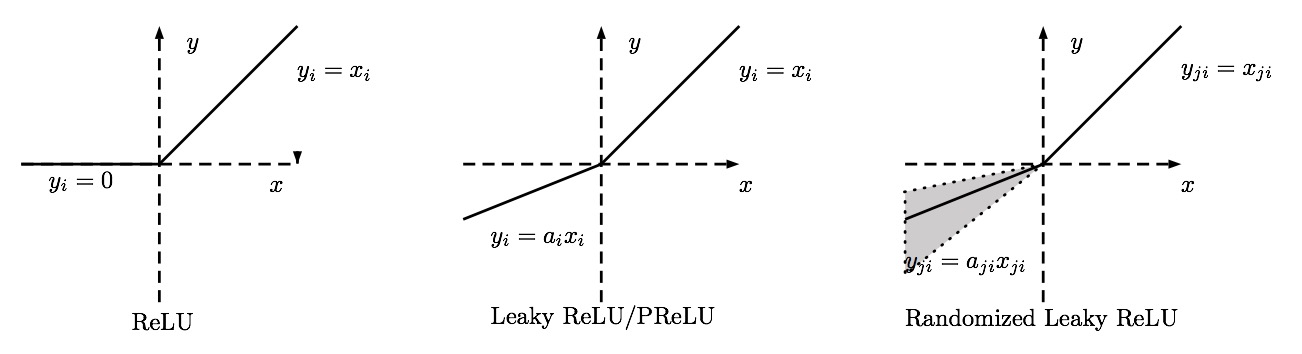
- 0 이하의 자극이 들어왔을 때도 활성화 값이 전달되게 함
- 이렇게 되면 역전파가 일어날 때 0 이하인 부분에서는 가중치가 양의 방향으로 업데이트되고 0보다 큰 부분에서는 음의 방향으로 업데이트되므로 다잉 뉴런 현상을 방지할 수 있음
단점
- 가 하이퍼파라미터가 됨
- 파라미터
- 모델이 학습을 통해 직접 바꾸는 값
- 데이터로부터 자동 학습
- 역전파로 업데이트
- 예: , , 필터 값
- 하이퍼파라미터
- 사람이 미리 설정해주는 학습 설정값
- 학습 중 자동으로 바뀌지 않음
- 실험 · 튜닝으로 결정
- 예: 학습률, 레이어 수, 필터 크기, 활성화 함수 종류
- 최적 는 문제마다 다름
Pooling Layer
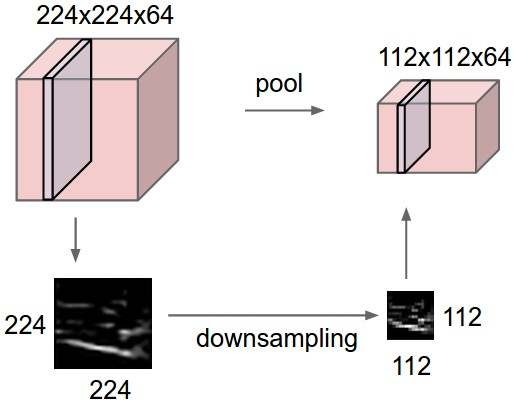 CNN에서는 일반적으로 연속된 CONV 층들 사이에 주기적으로 POOL층을 삽입한다. POOL층의 주요 목적은 representation의 spatial size(가로, 세로)를 점진적으로 줄이는 것이다. 이를 통해 네트워크 내의 파라미터 수와 연산량을 감소시킬 수 있으며, 결과적으로 overfitting*을 억제하는 효과도 얻을 수 있다.
CNN에서는 일반적으로 연속된 CONV 층들 사이에 주기적으로 POOL층을 삽입한다. POOL층의 주요 목적은 representation의 spatial size(가로, 세로)를 점진적으로 줄이는 것이다. 이를 통해 네트워크 내의 파라미터 수와 연산량을 감소시킬 수 있으며, 결과적으로 overfitting*을 억제하는 효과도 얻을 수 있다.
*overfitting
모델이 학습 데이터는 너무 잘 외우지만, 새로운 데이터에서는 성능이 급격히 떨어지는 현상. training accuracy는 매우 높으나 test accuracy가 낮다는 특징이 있다.
- overfitting 발생 원인
- 모델이 너무 복잡한 경우
- 파라미터 수가 많음
- 자유도가 너무 큼
- 데이터의 노이즈까지 학습
- 데이터가 적을 때
- 샘플 수 << 파라미터 수
- 우연한 패턴을 진짜 규칙으로 착각
- 학습을 너무 오래했을 때
- CNN이 overfitting을 줄이는 이유
- 가중치 공유
- 같은 필터를 전체 이미지에 사용
- 파라미터 수 대폭 감소
- pooling
- 세부 정보 제거
- 중요한 특징만 유지
- local connectivity
- 국소 패턴 중심 학습
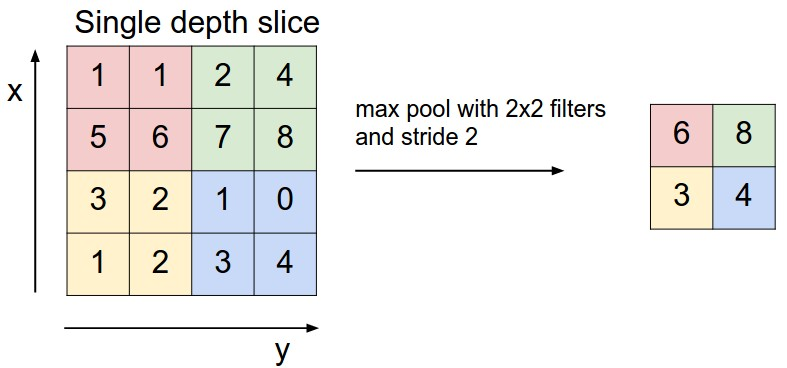 일반적인 방식은 MAX 연산(max pooling)을 사용하는 것이며, 2×2 크기의 필터를 스트라이드 2로 적용하는 방식이 가장 흔하다. 이 경우 입력의 각 깊이(depth) 슬라이스에 대해 가로와 세로 방향 모두에서 2배씩 다운샘플링이 이루어지며, 전체 활성값의 75%가 제거된다. 이때 각 MAX 연산은 해당 깊이(depth) 슬라이스의 작은 2×2 영역 안에 있는 4개의 값 중 최댓값 하나를 선택하는 방식으로 이루어진다. 중요한 점은 깊이(depth) 차원은 변하지 않는다는 것이다.
일반적인 방식은 MAX 연산(max pooling)을 사용하는 것이며, 2×2 크기의 필터를 스트라이드 2로 적용하는 방식이 가장 흔하다. 이 경우 입력의 각 깊이(depth) 슬라이스에 대해 가로와 세로 방향 모두에서 2배씩 다운샘플링이 이루어지며, 전체 활성값의 75%가 제거된다. 이때 각 MAX 연산은 해당 깊이(depth) 슬라이스의 작은 2×2 영역 안에 있는 4개의 값 중 최댓값 하나를 선택하는 방식으로 이루어진다. 중요한 점은 깊이(depth) 차원은 변하지 않는다는 것이다.
MAX 풀링 외에도 Average 풀링, L2-norm 풀링과 같은 연산도 수행할 수 있다.
- 입력으로 크기 의 볼륨을 받는다.
- 두 개의 하이퍼파라미터가 필요하다.
- spatial size (filter size)
- stride
- 출력으로 크기 의 볼륨을 생성하며, 다음과 같이 계산된다.
- 입력에 대해 고정된 연산을 수행하므로, 학습되는 파라미터는 전혀 없다.
- 풀링 레이어에서는 일반적으로 zero-padding을 사용하지 않는다.
Fully-Connected Layer (FC Layer)
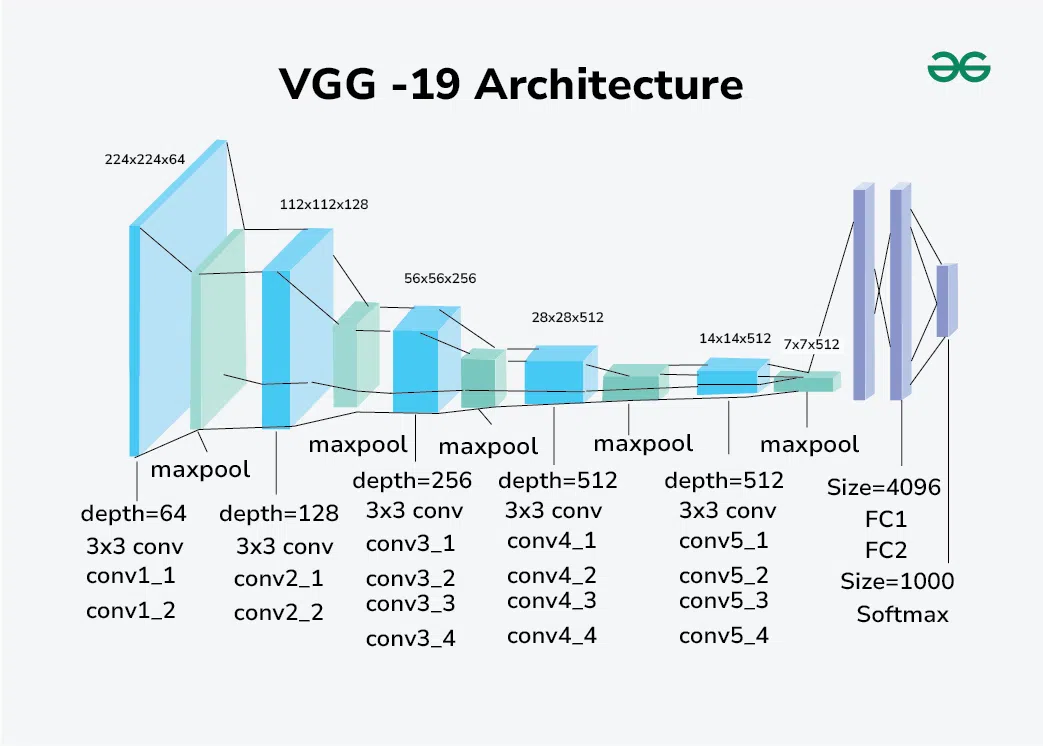
CONV, RELU, POOL 레이어에서 이미지의 feature를 뽑아내고, FC 레이어에서 뽑아낸 특징들을 종합해 최종 판단을 내린다.
Flatten (Stretch)
2차원/3차원을 1차원으로 펼친다.
- CONV층의 출력은 보통
[높이×너비×채널]이다. - 하지만 FC 레이어는 수학적으로 , 입력이 1차원 벡터여야 한다.
- 그래서
[7×7×512]→25088 × 1로 펼친다.- 값을 바꾸는 게 아니라 모양만 바꾼다.
flatten 된 벡터가 들어오면 FC층 안에서는 무슨 일이 일어날까?
예를 들어 이런 결과가 나온다. → [2.3, 0.7, -1.2, 3.8, 0.1]
이 값들의 의미는 각 클래스에 대한 점수(score)이다. (클수록 이 클래스일 가능성이 높은 것)
Softmax
그럼 softmax가 왜 필요할까?
FC 출력(score)은
- 해석하기 어렵고
- 비교하기 어렵고
- 확률처럼 말할 수 없다!
→ 그래서 고양이일 확률이 몇인데..?고양이: 3.8 개: 2.3 비행기: -1.2
softmax는 score를 사람이 이해할 수 있는 확률로 바꿔주는 함수이다.
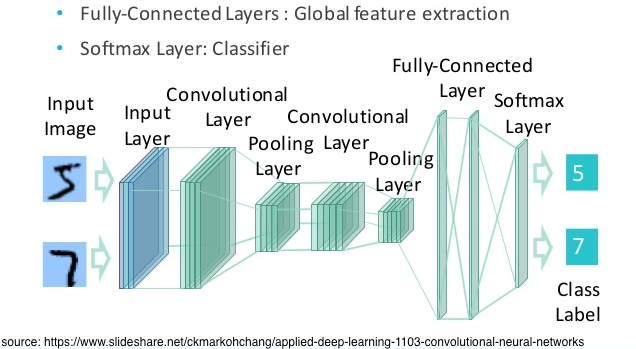
- 점수가 큰 클래스는 더 크게
- 점수가 작은 클래스는 더 작게
- 모든 값을 0~1 사이로 만들고
- 전부 더하면 1이 되도록 만든다.
→ 이 이미지는 고양이일 확률이 72%고양이: 0.72 개: 0.22 비행기: 0.01
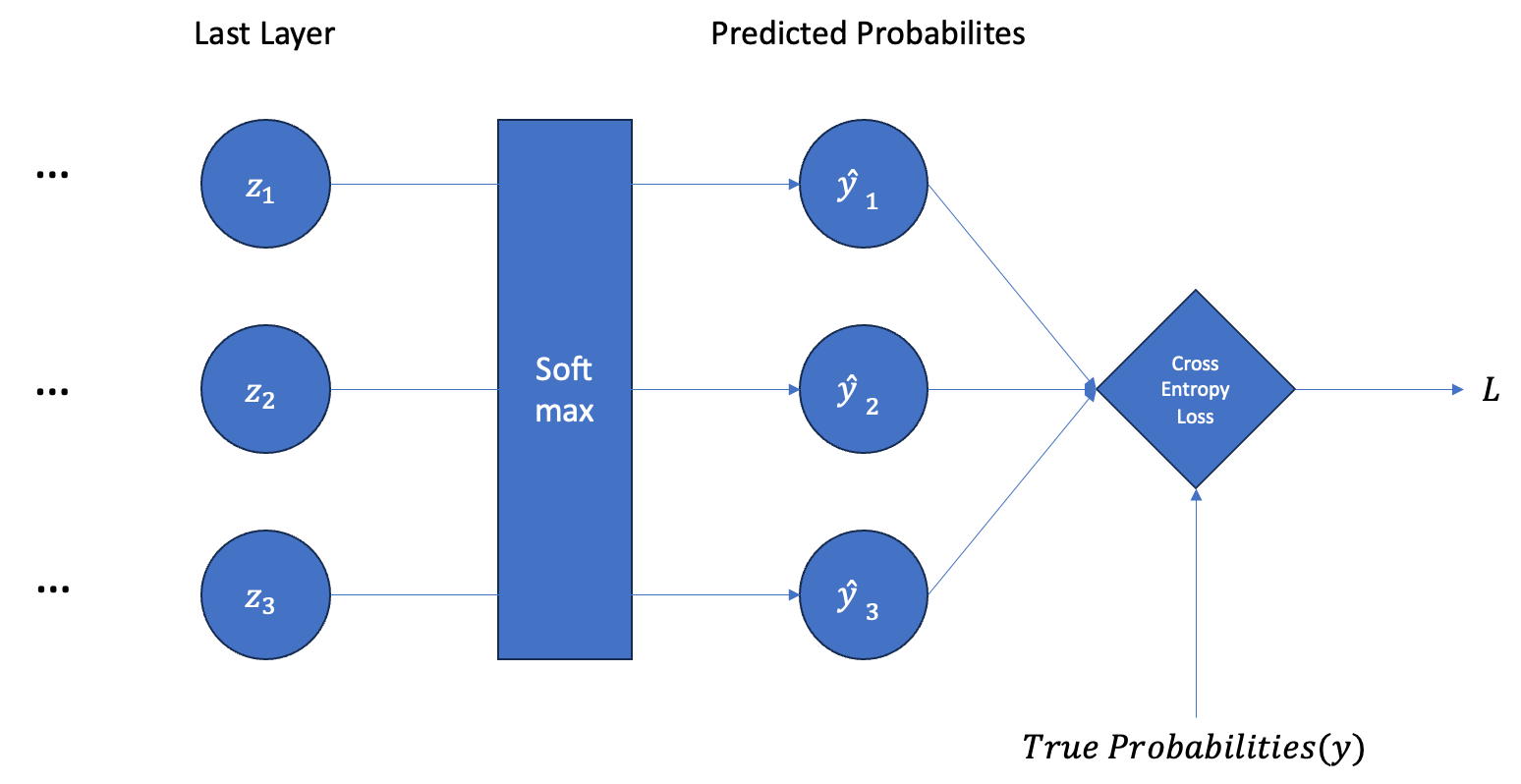
Cross Entropy
softmax를 적용하고 실제 레이블 값과 비교하여 cross entropy loss를 계산한다. softmax를 통해 마지막 레이어의 출력값을 확률값으로 변환할 수 있고, cross entropy를 통해 실제 분포와 확률값이 얼마나 차이나는지 측정할 수 있다.
Reference
- https://cs231n.github.io/convolutional-networks/
- https://blog.naver.com/laonple/222307148325
- https://blog.naver.com/jinwooo_hong/221194232894
- https://velog.io/@rnjsdb72/%EB%B0%91%EB%B0%94%EB%8B%A5%EB%B6%80%ED%84%B0-%EC%8B%9C%EC%9E%91%ED%95%98%EB%8A%94-%EB%94%A5%EB%9F%AC%EB%8B%9D1-04.-%ED%95%A9%EC%84%B1%EA%B3%B1-%EC%8B%A0%EA%B2%BD%EB%A7%9DCNN
- https://www.hanbit.co.kr/channel/view.html?cmscode=CMS5905215904
- https://reniew.github.io/12/
- https://modulabs.co.kr/blog/padding-cnn-basic
- https://velog.io/@hjk1996/Cross-Entropy%EC%99%80-Softmax%EC%9D%98-%EB%AF%B8%EB%B6%84
