Boosting Methods
Boosting부스팅 은 21세기부터 statistical learning의 주요한 모델로 사용되고 있는 방법이다. 초기에는 분류 모델에 주로 이용되었으나, 회귀 문제에까지 확장되어 사용된다. Boosting 방법들의 핵심 아이디어는 기본적인 Ensemble 기법, 즉 overfitting 가능성이 작은 weak classifier 여러개를 결합시킨 것을 바탕으로 예측을 진행하는 알고리즘이다. 그러나 Ensemble과의 차이점은, 이러한 weak classifier가 sequential로 이루어진다는 것인데 이는 하나의 classifier의 결과를 이용해 다음 classifier의 결과를 순차적으로 개선시키자는 아이디어이다.
Basic Idea of Boosting
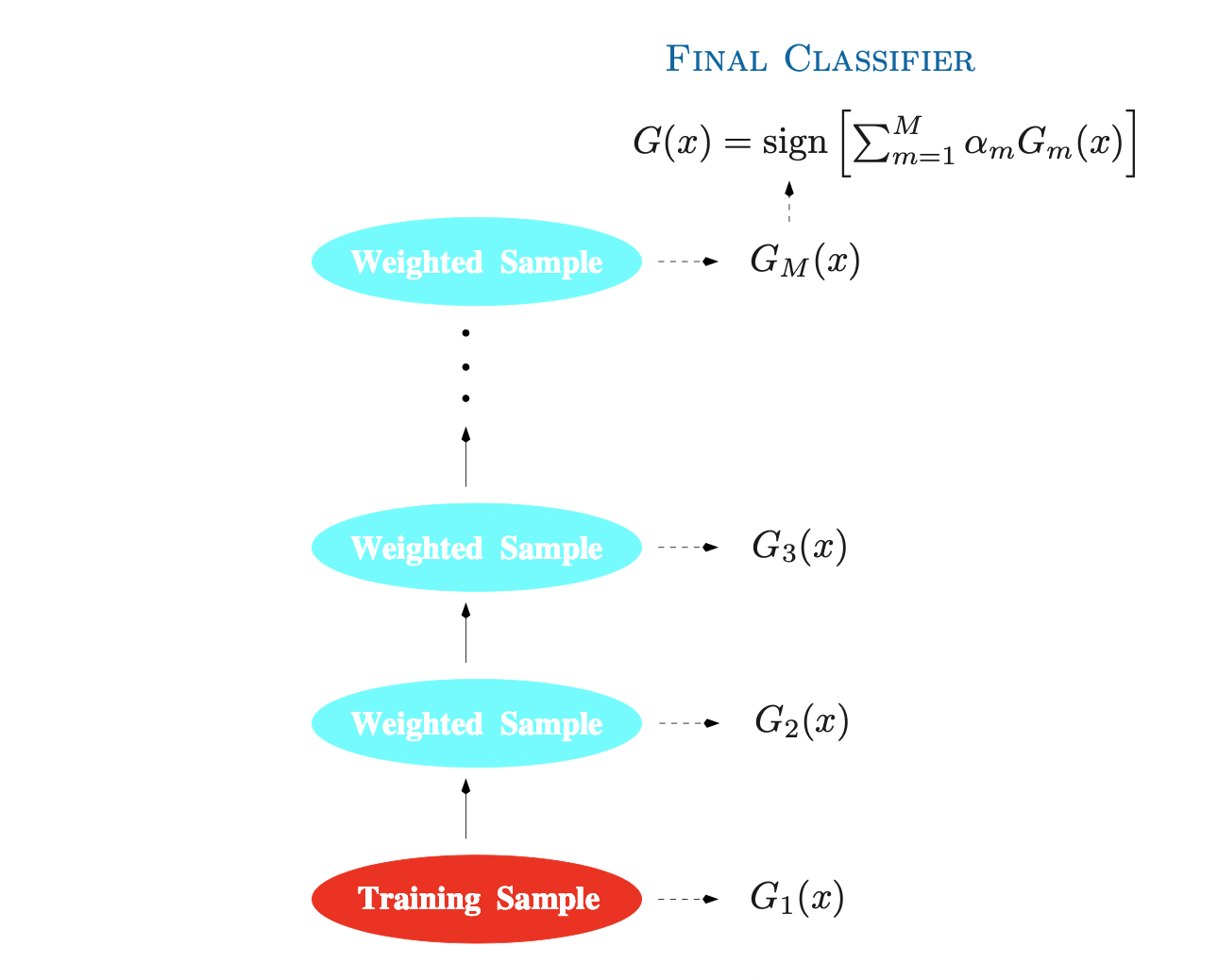
위 그림은 가장 대표적인 boosting algorithm인 AdaBoost.M1의 알고리즘을 나타낸 그림이다. 우선 AdaBoost 알고리즘을 바탕으로 boosting의 기본적인 학습과정을 살펴보도록 하자. 이진 분류 문제가 주어졌다고 가정하고, 반응변수가 Y∈{−1,1} 로 코딩되어있다고 하자. 예측변수는 벡터 X로 주어지며 이때 분류기 G(X)는 반응변수의 예측값 Y^∈{−1,1} 을 생성한다. 그러면 Training sample에 대한 오차를
err=N1i=1∑NI(yi=G(xi))
로 정의할 수 있고, 예측값에 대한 기대오차(Expected error rate)는 EXY[I(Y=G(X))] 가 된다.
앞서 간단히 설명한 것 처럼, Boosting 알고리즘은 weak classifier들의 sequence Gm(X) 를 생성하는 것인데, 여기서 weak 하다는 말은 오차율이 random guessing보다 미약하게나마 나은 것을 의미한다. 하지만 각 classifier 단계마다 데이터에 대한 가중치를 부여하여 이를 개선시켜나가고, 결과적으로 sequence의 모든 분류기를 합쳐 다음과 같은 최종 예측값을 도출한다.
G(x)=sgn(m=1∑MαmGm(x))
여기서 각 분류기의 예측값들에 대한 가중치 α1,…,αM 의 경우 boosting algorithm을 통해 계산되며, 가중치를 곱하는 이유는 분류기의 열이 점차 개선되는 형태를 취하기 때문에, 좀 더 정확한 분류결과에 많은 가중치를 주기 위함이다.
반면, 분류기가 개선되는 과정과 동시에 훈련 데이터에 대한 변화도 발생한다. 이는 분류기와 비슷하게, 데이터셋의 각 관측값 (xi,yi),i=1,…,N 에 대해 가중치observation weight wi를 적용하는 방식이다. 다만, 첫 분류기에서는 데이터셋의 모든 관측값에 대해 동일한 wi=1/N의 가중치가 적용되고 이후의 과정에서는 각 observation weight들이 개별적으로 수정된다. m번째 단계에서, 이전 단계의 분류기 Gm−1(x) 에 의해 잘못 분류된 관측값들에 대해서는 observation weight를 증가시키고, 옳게 분류된 관측값들의 weight는 감소시킨다. 이러한 일련의 과정으로 정확한 분류가 어려운 관측값의 영향력이 커지며 분류기들은 그러한 데이터(이전에 잘못 분류된)들에 대해 좀 더 포커스를 맞추는 과정이 형성된다.
AdaBoost.M1.
앞서 설명한 Boosting 알고리즘인 AdaBoost의 구체적인 알고리즘은 다음과 같다.
-
observation weight들의 초기 설정 : wi=1/N,i=1,…,N
-
m=1,…M 에 대해 다음 과정을 반복한다.
-
각 관측값들에 wi를 적용한 데이터로 분류기 Gm(x)를 fitting한다.
-
errm=∑i=1Nwi∑i=1NwiI(yi=Gm(xi))
의 값을 계산한다(예측에 오류가 있는 가중치들의 비율).
-
분류기들의 가중치 αm=log((1−errm/errm)) 을 구한다.
-
observation weight들을 개선한다 :
wi←wi⋅exp[αm⋅I(yi=Gm(xi))]
-
최종 분류기 G(x)=sgn(∑m=1MαmGm(x)) 를 출력한다.
AdaBoost.M1 알고리즘은 Discrete AdaBoost로도 알려져있는데, 이는 base classifier, 즉 boosting의 기초를 이루는 개별 분류기들이 discrete class -1, 1을 출력하기 때문이다. 만일 base classifier가 probability와 같이 실수값을 취한다면, 이는 Real AdaBoost가 된다.
Boosting and Basis expansion
이전에 Spline Regression과 관련된 게시글에서 basis expansion에 대해 다루었던 적이 있었다. 이는 예측변수 matrix에 대해 새로운 변수를 추가하거나 기존 변수들을 대체하는 방식으로, 변환 hm 들에 대해 선형모형을(여기서 γm은 각 basis function의 모수를 의미한다 : ex. tree의 경우 split variable과 split point들을 의미함)
f(X)=m=1∑Mβmhm(X:γm)
로 표현하는 방식을 의미한다. 그런데, 이는 앞서 살펴본 Boosting의 표현식과 유사하다. 즉, 각 basis function hm 대신에 개별 분류기 Gm(X) 를 대입하면 boosting 알고리즘과 basis expansion의 형태가 동일하다는 것을 확인할 수 있다. 일반적으로, basis expansion을 이용한 모델들은 training data 전체에 걸쳐 loss값의 평균을 구하고, 이를 최소화하는 방식으로 훈련이 이루어진다. 즉,
{βm,γm}1Mmini=1∑NL(yi,m=1∑Mβmhm(xi:γm))(1)
의 형태로 최적화 과정이 이루어진다. 이때 대부분의 손실함수 L(y,f(x))와 각 basis function hm 들에 대해서 식 (1)의 최적화 과정은 꽤 복잡한 최적화 알고리즘을 요구한다.
Forward Stagewise Additive Modeling
Forward Stagewise additive modeling 방법은 위 식 (1)에 대한 최적화 문제의 근사치를 제공하는 방법 중 하나인데, 이는 연속적으로(sequentially) 기존 β,γ 값들의 조정 없이 새로운 basis function을 추가하는 알고리즘이다. 자세한 알고리즘은 다음과 같다.
Forward Stagewise Additive Modeling
-
f0(x)=0 으로 초기화한다.
-
m=1,…,M 에 대해 다음을 반복한다.
-
(βm,γm)=argβ,γmini=1∑NL(yi,fm−1(xi)+βhm(xi:γ))
-
fm(x)=fm−1(x)+βmh(x:γm) 으로 둔다.
예를 들어, squared loss가 사용되는 경우 L(yi,fm−1(xi)+βh(xi:γ))=(eim−βh(xi:γ))2 가 되는데 eim은 i번째 관측값에 대한 현재 모델에서의 residual을 의미한다. 즉, squared loss에 대해서는 새로이 추가되는 항 βmh(x:γm) 은 현재 residual에 적합된 항이 된다.
AdaBoost and Forward Stagewise Additive Modeling
앞서 Forward Stagewise Additive Modeling 알고리즘에 대해 살펴보았는데, 다음과 같은 손실함수
L(y,f(x))=exp(−yf(x))
를 정의하면 forward stagewise additive modeling과 AdaBoost.M1 이 동일한 알고리즘을 보일 수 있다. AdaBoost 알고리즘에서는 각 basis function에 개별 분류기 Gm(x)∈{−1,1} 이 대응되었다. 이를 Forward Stagewise Additive Modeling 알고리즘에 대입시키면, 새로이 추가되는 계수는
(βm,Gm)=argβ,Gmini=1∑Nexp[−yi(fm−1(xi)+βG(xi))]
로 주어진다. wi(m)=exp(−yifm−1(xi)) 로 두면 이는 각 parameter β나 분류기 G에 종속되지 않으므로, 위 식을
(βm,Gm)=argβ,Gmini=1∑Nwi(m)exp(−βyiG(xi))(2)
로 다시 쓸 수 있다. 이때, 각 단계의 가중치 wi(m)이 이전단계의 모델 fm−1(xi) 에만 의존하므로 이는 AdaBoost 알고리즘에서 전 단계의 분류기 결과를 통해 가중치를 업데이트 하는 과정과 대응할 수 있다. 이제 위 식 (2)에 대한 최적화 해를 다음과 같이 구해보도록 하자.
우선 식 (2)의 우변은 다음과 같이 표현되는데,
e−β⋅yi=G(xi)∑wi(m)+eβ⋅yi=G(xi)∑wi(m)=(eβ−e−β)⋅i=1∑Nwi(m)I(yi=G(xi))+e−β⋅i=1∑Nwi(m)
여기서 β>0 을 임의로 고정하면
Gm=argGmini=1∑Nwi(m)I(yi=G(xi))
와 같은 형태로 Gm에 대한 최적화 문제를 얻을 수 있다. 또한, 이를 이용해
errm=∑i=1Nwi(m)∑i=1Nwi(m)I(yi=Gm(xi))
와 같이 minimized weighted error rate를 설정하면 β에 대한 최적해는
βm=21logerrm1−errm
으로 구해지는 것은 쉽게 보일 수 있다.
위와 같이 구한 최적해로 모델의 update 과정
fm(x)=fm−1(x)+βmGm(x)
를 가중치 wi에 대한 update 과정으로 다음과 같이 다시 쓸 수 있다.
wi(m+1)=wi(m)⋅e−βmyiGm(xi)
여기서 −yiGm(xi)=2I(yi=Gm(xi))−1 의 관계를 이용하면(쉽게 생각가능하다)
wi(m+1)=wi(m)⋅eαmI(yi=Gm(xi))⋅e−βm
이 되고, αm=2βm 은 AdaBoost에서의 분류기 가중치를 의미한다. 즉, 살펴본 것과 같이 AdaBoost.M1 알고리즘은 Exponential Loss criterion에 대해 Forward stagewise additive modeling을 이용한 최적화 알고리즘과 동일하다.
